
Сперва вас напугаем самой структурой оператора SELECT в СУБД MySQL.Выглядит она вот так:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name' export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]Ну что, теперь приложим усилия чтоб это все разобрать и разложить по полкам.
[ALL | DISTINCT | DISTINCTROW ]
Используется чтоб убрать дубликаты. ALL установлено по умолчанию, поэтому его можно не писать. DISTINCTROW и DISTINCT одинаковы: select distinct name from adm_user;
[HIGH_PRIORITY]
Данный параметр устанавливает высокий приоритет в очереди запросов и выполняется с приоритетом выше чем команды обновления таблицы. Параметр не желателен, но если уж вы его используете, запросы должны выполняться очень быстро и немедленно.
[STRAIGHT_JOIN]
Позволяет увеличить скорость, если вы уверены что оптимизатор запросов производит объединение таблиц не оптимальным образом. Оптимизатор объединит таблицы в порядке перечисленном в выражении FROM.
[SQL_SMALL_RESULT]
Может ускорить выполнение запросов при совместном использовании с GROUP BY или DISTINCT. Данный параметр рекомендуется использовать только при небольшом наборе данных. MySQL использует быстрые временные таблицы для хранения результирующей таблицы вместо сортировки.
[SQL_BIG_RESULT]
Можно использовать с GROUP BY или DISTINCT. Сообщает оптимизатору что результат будет содержать большое количество строк. При необходимости MySQL будет использовать временные таблицы на диске, но предпочтения будут у сортировки а не созданию временной таблицы с ключом по элементам GROUP BY.
[SQL_BUFFER_RESULT]
Результат заносит во временную таблицу перед тем как начать их передачу клиенту. Таким образом MySQL может раньше снять блокировку с таблицы.
[SQL_CACHE | SQL_NO_CACHE]
Очень полезный параметр который позволяет хранить результаты в кэше запросов при использовании QUERY_CACHE_TYPE=2. При повторном выполнении одного и того же запроса (текст запроса одинаков), результат будет мгновенный из кэша.
Соответственно SQL_NO_CACHE - запрещает хранение в кэше.
[SQL_CALC_FOUND_ROWS]
Сразу скажу, параметр имеет смысл использовать вместе с параметром LIMIT. Указывая этот параметр MySQL подсчитает полное число строк, подходящих под условие запроса, и сохранит это значение в памяти. Получить это значение можно запросом: SELECT FOUND_ROWS();
select_expr [, select_expr ...]
Задает перечень полей которые необходимо вернуть результате.
Пример: SELECT 1 + 1, a.id, a.name FROM table a
table_references
В данном случае перечисляются таблицы из которых выбирается результат. Если их более одной, не забывайте объединять их. Как их правильно объединить я вам представлю в картинке на множестве, по мне это самый наглядный способ:
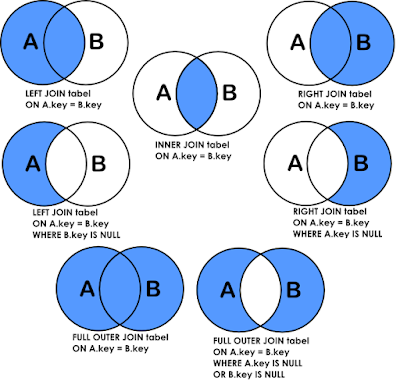
При необходимости также можно задавать какие индексы использовать а какие нет.
Пример представление одной таблицы:
your_name_table [[AS] alias]
your_name_table [[AS] alias]
[[USE INDEX (key_collection1)] |
[IGNORE INDEX (key_collection2)] |
FORCE INDEX (key_collection3)]]
, где
FORCE - использовать индекс всегда,
USE - если посчитает нужным оптимизатор MySQL,
IGNORE - игнорировать.
[WHERE where_condition]
Ключевое слово where говорит что далее пойдут условия отбора результата. Например выбрать всех у кого идентификатор более 10 и имя начинается с буквы "А" : SELECT * FROM table a where a.id > 10 and a.name like 'А%'
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
Этот оператор относится к группировки результатов. С данным оператором можно использовать только определенные функции (см.ниже). Например, подсчитаем какое количество людей имеют совпадения по имени. SELECT name, COUNT(id) FROM adm_user GROUP BY name;
Список групповых функций:
COUNT - количество величин со значением, не равным NULL
если добавить DISTINCT то будет количество различающихся величин со значением, не равным NULL.
SELECT name, COUNT(DISTINCT id) FROM adm_user GROUP BY name;
AVG(field) - среднее значение поля field,
MIN(field), MAX(field) - минимальное и максимальное значение поля.
SUM(field) - сумма величин поля field. Тут нужно быть внимательным, если возвращаемый набор данных пуст, то и функция вернет NULL!
STD(field) - среднеквадратичное отклонение значения в поля field.
BIT_OR(field) - побитовое ИЛИ для всех битов в field
BIT_AND(field) - побитовое И для всех битов в field.
Так же можно использовать [ASC | DESC], ... [WITH ROLLUP]. Это для того, чтоб выполнить групповую функция по каждой из групп но вместо себя будет подставлять NULL.
SELECT date_create, order_id, SUM(sum_price)
FROM sales
GROUP BY date_create, order_id WITH ROLLUP;
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
Limit или другими словами - постраничная навигация. Это означает что пользуясь данной конструкцией вы можете управлять количеством возвращаемых строк и границей отсчета этого результата. Пример, выбрать из таблицы третью четверку человек:
SELECT * FROM adm_user LIMIT 8, 4; # возвращает строки 9-12
также прошу заметить что offset не есть обязательным, если напишем так:
SELECT * FROM adm_user LIMIT 10;То это будет означать следующее: выбрать первые 10 человек.
[PROCEDURE procedure_name(argument_list)]
Даже не знаю пользуются ли этим, мне никогда не приходилось применять. Но все таки это есть и можно использовать. В MySQL есть возможность расширить определить процедуру написанную на C++, которая может обрабатывать в том числе и изменять данные до того как они будут переданы клиенту. Реализовать их очень просто - обратиться к специалисту, изложить суть, заплатить и получить желаемое.
[INTO OUTFILE 'file_name' export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
Используется для экспорта возвращаемых строк в файл на диске или присвоении их в переменные. Да и есть отличия OUTFILE от DUMPFILE тем, что DUMPFILE применяется для экспорта полей BLOB, фалов или каких либо бинарников. DUMPFILE не добавляет симфолы форматирования а сохраняет так как есть.
Пример:
Экспорт в файл:
select * from adm_users into outfile 'c:\\table_adm_users.csv';
Присвоение значения в переменную:
select id, name into @prm_id, @prm_name from adm_users;
[FOR UPDATE | LOCK IN SHARE MODE]
Данные флаги используются для блокировки выбираемых данных для использования согласованного чтения. К примеру, вы желаете добавить сотрудника в отдел продаж, но в этот момент этот отдел удалили, вот тут для избежания ошибки можно воспользоваться LOCK IN SHARE MODE что заблокирует отдел пока вы в него не добавите сотрудника.
SELECT * FROM depts d WHERE d = 'отдел продаж' LOCK IN SHARE MODE;
UPDATE adm_users SET adm_users.depts_id = 4 WHERE adm_users.id = 2015;
Многие разработчики создают отдельную таблицу для хранения своих генераторов, так вот в этом случае можно воспользоваться FOR UPDATE.Сперва считаем текущее значение генератора:
SELECT value FROM sys_generator WHERE name = 'system_generator' FOR UPDATE
А теперь обновим его прибавив единицу:
UPDATE sys_generator SET value = value + 1 WHERE name = 'system_generator'
Таким образом у нас не будет конфликтных ситуаций по генерации ключей.
Не хватает информации, опишите в комментарии, какой и я обязательно ее добавлю. Всем спасибо!