

Всем привет!
Всё началось с того, что мы в Sber AI решили немного поизучать/почитать подробнее про хайповую нейронную сеть DALL·E и понять её потенциал возможностей, а также в чём заключается боттлнек – что же мешает генерить картинки хорошего качества и как можно попытаться улучшить работу модели?
Все автоэнкодеры важны, все автоэнкодеры нужны
О том, что такое автоэнкодеры (AE, VAE, CVAE и др.), уже много писали на Хабре и не только (можно почитать здесь, здесь и здесь), так что углубляться не будем. В двух словах: это нейронная сеть, состоящая из двух частей, – энкодера и декодера. Энкодер сжимает входной сигнал (например картинку) в какое-то скрытое состояние меньшей размерности. Декодер переводит скрытое состояние в исходный сигнал.
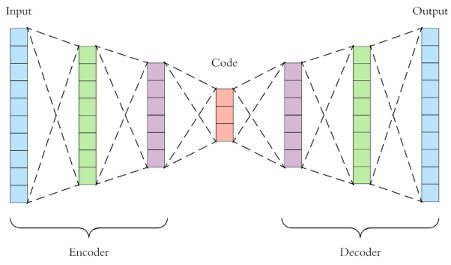
Таким образом, есть возможность «обучить» свой архиватор. Сами автоэнкодеры уже существуют давно, ими никого не удивишь. Однако фантазия исследователей позволяет и по сей день ставить занимательные эксперименты. Так, например, идея работы DALL·E пришла после создания так называемого VQ-VAE и последующего его улучшения в VQ-VAE 2, а потом ещё и в VQ-GAN).
Причём тут вообще DALL-E?
Краткая вводная для тех, кто ещё не в курсе. DALL·E – это нейронная сеть, которая создаёт изображения, основываясь на текстовом описании на естественном языке. Например, вот что она может создать по тексту «a snail made of harp» (улитка, сделанная из арфы).

Принцип работы DALL·E устроен довольно просто, его можно сравнить с хорошо известной генерацией текста «Sequence to Sequence» с помощью Transformer. Для генерации вместо привычных текстовых токенов используются токены пространства codebook, которые отображают скрытое дискретное состояние изображений после процедуры энкодинга VAE. В качестве трансформера используется одна из версий GPT-3 на 12 миллиардов параметров, а подают в него эмбеддинги текстового запроса на естественном языке и эмбеддинги codebook текущего состояния генерации изображения, конкатенированные между собой. Затем сгенерённая последовательность codebook подаётся в декодинг VAE, который восстанавливает изображение.
Таким образом, очевидным bottleneck’ом для данной архитектуры является автоэнкодер – если он не способен восстановить исходное изображение процедурой encode-decode с приемлемым качеством, то и DALL·E никогда не сможет сгенерить изображение хорошего качества.
Мы решили проверить качество на различных доменах некоторых опубликованных дискретных VAE и убедиться, что они действительно справляются со своей задачей.
А чем оригинальный энкодер не угодил?
Как уже было сказано выше, есть как хорошо генерируемые домены, так и плохо генерируемые. Так вот, мы решили сделать подборку изображений из датасета COCO по некоторым субъективно выбранным проблемным доменам. Затем с помощью этой подборки оценили качество на моделях:
“16384”: VQGAN ImageNet (f=16), 16384
“VAE”: DALL-E dVAE (f=8), 8192, GumbelQuantization
“gumbelf8”: VQGAN OpenImages (f=8), 8192, GumbelQuantization
“SBER-gumbelf8”: VQGAN SberData (f=8), 8192, GumbelQuantization
Последний из списка мы дообучали на собственных собранных данных. Стоит отметить, что все выбранные модели не видели датасет COCO в процессе обучения, и оценка на этом датасете достаточно честная и независимая. Естественно, для улучшения качества наши данные были дополнены примерами из этих доменов. Мы лишь дофайнтюнили предобученные модели из оригинального репозитория на одну эпоху с warmup learning rate до 1.5e-06.
Вы всё ещё обучаете с нуля? Тогда мы идём к вам!
Для оценки качества восстановленных изображений мы использовали метрики Inception Score (IS) и Fréchet inception distance (FID), к сожалению, первая статья по FID куда-то пропала, поэтому предлагаем посмотреть такой вариант.
Что такое IS и как его посчитать, можно почитать тут или тут. Если вкратце, то для расчёта используется всем известная модель нейронной сети Inception v3. С помощью неё оценивается вероятность принадлежности изображений каждому из 1000 классов. Затем все распределения вероятностей по одинаковым классам суммируются, считается KL-дивергенция между этими распределениями каждого индивидуального класса и средним общим распределением. Оценка принимает значения от 1 до N, где N – количество классов. Чем больше значения вероятностей принадлежности к каким-то классам и чем больше разнообразие этих классов, тем больше IS.
Похожая ситуация и с FID, подробное описание и расчёт тут тоже есть. Для FID, однако, уже необходим датасет, с которым можно сравнить сгенерённые картинки, в нашем случае это просто набор исходных картинок. Снова используется та же модель Inception, но уже без головы, и сравниваются распределения признаков оригинальных и сгенерённых изображений. Чем ближе распределения, тем больше наши картинки похожи на настоящие.
Дообучение на одну эпоху дало нам следующие результаты, поле all рассчитано как среднее взвешенное всех категорий на их количество:
IS (больше – лучше):
domain/model |
VAE |
16384 |
gumbelf8 |
SBER-gumbelf8 |
Original |
all |
11.133 |
13.647 |
15.203 |
15.316 |
15.278 |
indoor |
9.769 |
10.744 |
11.707 |
11.688 |
11.638 |
kitchen |
9.726 |
11.354 |
12.333 |
12.152 |
11.813 |
appliance |
5.705 |
6.024 |
6.154 |
6.199 |
5.890 |
electronic |
7.830 |
9.509 |
9.712 |
9.606 |
9.497 |
furniture |
10.861 |
13.346 |
14.500 |
14.531 |
14.592 |
outdoor |
8.163 |
9.520 |
10.668 |
10.293 |
10.451 |
sports |
7.467 |
8.544 |
8.814 |
8.841 |
8.962 |
food |
7.954 |
8.725 |
9.390 |
9.434 |
9.191 |
vehicle |
10.527 |
12.947 |
14.240 |
14.559 |
14.233 |
animal |
11.933 |
14.249 |
15.999 |
15.879 |
15.857 |
accessory |
9.399 |
11.687 |
13.117 |
13.388 |
13.228 |
person |
13.752 |
17.794 |
20.048 |
20.420 |
20.600 |
face |
11.903 |
14.987 |
16.986 |
17.489 |
17.584 |
text |
14.902 |
18.457 |
21.396 |
21.292 |
21.131 |
FID (меньше – лучше):
domain/model |
VAE |
16384 |
gumbelf8 |
SBER-gumbelf8 |
all |
59.753 |
38.912 |
30.304 |
30.136 |
indoor |
74.734 |
57.925 |
45.432 |
44.686 |
kitchen |
66.424 |
47.086 |
36.735 |
36.579 |
appliance |
80.359 |
70.604 |
53.225 |
52.064 |
electronic |
77.856 |
64.034 |
50.759 |
50.447 |
furniture |
53.438 |
38.204 |
29.510 |
29.569 |
outdoor |
91.932 |
58.877 |
46.309 |
45.287 |
sports |
65.540 |
39.961 |
32.219 |
31.756 |
food |
76.974 |
53.109 |
41.018 |
41.413 |
vehicle |
60.318 |
34.259 |
26.721 |
26.463 |
animal |
64.250 |
41.520 |
32.039 |
32.078 |
accessory |
79.843 |
56.311 |
44.660 |
44.454 |
person |
40.810 |
20.430 |
15.523 |
15.484 |
face |
54.153 |
34.109 |
26.663 |
26.750 |
text |
47.299 |
27.656 |
21.303 |
21.148 |
Также мы посмотрели, как Inception Score оценивает оригинальные изображения (без процедуры encode-decode). Интересно, что для данной метрики оригиналы выглядят менее естественными, чем то, что сгенерили некоторые автоэнкодеры (!). Вероятнее всего, мы уже упёрлись в возможности данной метрики, оценка с её помощью уже становится менее объективной. Предлагаем «дедовскими» методами (глазами) посмотреть на генерации. И вот что получилось с проблемными доменами: визуально качество заметно улучшилось для SBER-gumbelf8:
«Текст»







«Несколько людей»






«Лица»








Не моё, а общее
Мы хотим поделиться с вами тем, что у нас получилось. А именно – дообученными чекпоинтами и примерами кода, который поможет вам использовать эти модели. Всё это есть на Google-диске и в колабе, так что приятного использования!
Общая папка с моделями и ноутбуками.
На самом деле очень интересно, какие примеры у вас получатся. Спасибо, что дочитали до конца, и вперёд, к новым генерациям!
Команда: @denis_karachev, @shonenkov, @dendimitrov
Комментарии (6)

BelBES
05.10.2021 17:57Так а выводы то какие? Что мешает генерить качественные картинки и какой потенциал? :)
Таким образом, очевидным bottleneck’ом для данной архитектуры является автоэнкодер (VAE) – если он не способен восстановить исходное изображение процедурой encode-decode с приемлемым качеством, то и DALL·E никогда не сможет сгенерить изображение хорошего качества.
С VQVAE все +/- понятно и с генерацией картинок мы уже неплохо умеем работать, а вот все самое интересное у DALL-E определенно происходит в трансформере, который должен мапить текст в кодовую книгу. И исходя из статейных кратинок, там проблема явно не в рендеринге, а в том, что семантически оно рендерит ерунду. Но анализ этого вопроса остался за бортом :(
p.s. кстати, DALL-E - это уже прошлый век. Буквально недавно группа исследователей из Китая опубликовала свою работу CogView, и заявляется, что она бьет DALL-E по метрике FID. И в отличие от скрытных ребят из OpenAI, тут всё выложили в open source, включая снапшоты и можно покрутить в руках.

thedenk Автор
05.10.2021 19:34Качество генерируемых картинок в DALL-E безусловно зависит и от текстового энкодера тоже, но в данном случае мы решили улучшить именно проблемные домены декодера. Вы задаете абсолютно правильные вопросы, о которых стоит задуматься, но за рамками нашей статьи, спасибо!

romanzolotoi
13.10.2021 14:01очень интересно было почитать статью, не знал, что существуют такие нейронные сети, буду изучать этот вопрос
kenoma
Все хорошо, только VAE это вариационный аутоэнкодер и он топологически отличается от просто
аутоэнкодера.
thedenk Автор
Да, хорошее замечание, спасибо, поправил :)