
Как показала история, сеть из миллиардов связанных между собой документов — очень хрупкая и эфемерная система. Странички живут недолго. Если нашли интересную страницу, сайт или видео — нельзя просто сделать закладку и надеяться, что контент по ссылке останется доступен в будущем. Не останется. Информация исчезнет, ссылки изменятся, домены сменят владельцев, статьи на Хабре спрячут в черновики. У каждой страницы свой срок жизни. Ничто не вечно под луной, и ничего с этим не поделать.
К счастью, у нас есть инструменты, чтобы сохранить информацию на десятилетия. Свой персональный архив, полностью под контролем, со всеми сайтами и актуальными страницами. Отсюда никто ничего не удалит без вашего ведома, никогда.
Вымирание ссылок
Вымирание ссылок — известный феномен. У большинства СМИ и других организаций нет политики долговременного сохранения информации. Они просто публикуют веб-страницы — и забывают про них. На старые страницы всем плевать, сменят они адреса или исчезнут навсегда. Неудивительно, что именно так и происходит.
Анализ внешних ссылок New York Times с 1996 по 2019 годы показал вымирание ссылок на уровне примерно 6% в год. По итогу с 1996 года пропало около 70% веб-страниц.

Проверка ссылок в научных статьях показала вымирание 23—53% в статьях с 1993 по 1999 годы.

Проверка проводилась в 2001 году. Наверняка сейчас, двадцать лет спустя, в тех статьях осталось ещё меньше живых ссылок. В 2016 году другая проверка источников в научных статьях с 1997 по 2012 годы показала, что по 75% ссылкам контент исчез или изменился, а снапшоты в веб-архивах остались только для трети пропавших страниц.
Для решения этой проблемы был создан Архив интернета и знаменитая Машина времени (Wayback Machine). Мотивация такая, что мы обязаны сохранить существующий контент для будущих поколений, иначе он безвозвратно исчезнет.
Но в Архив интернета попадают далеко не все страницы. В кэш Google попадает больше, но там определённый срок хранения. И никакой гарантии, что сохранится именно нужная информация. Так что лучше взять дело в свои руки — и создать собственный архив.
Инструменты для веб-архивирования
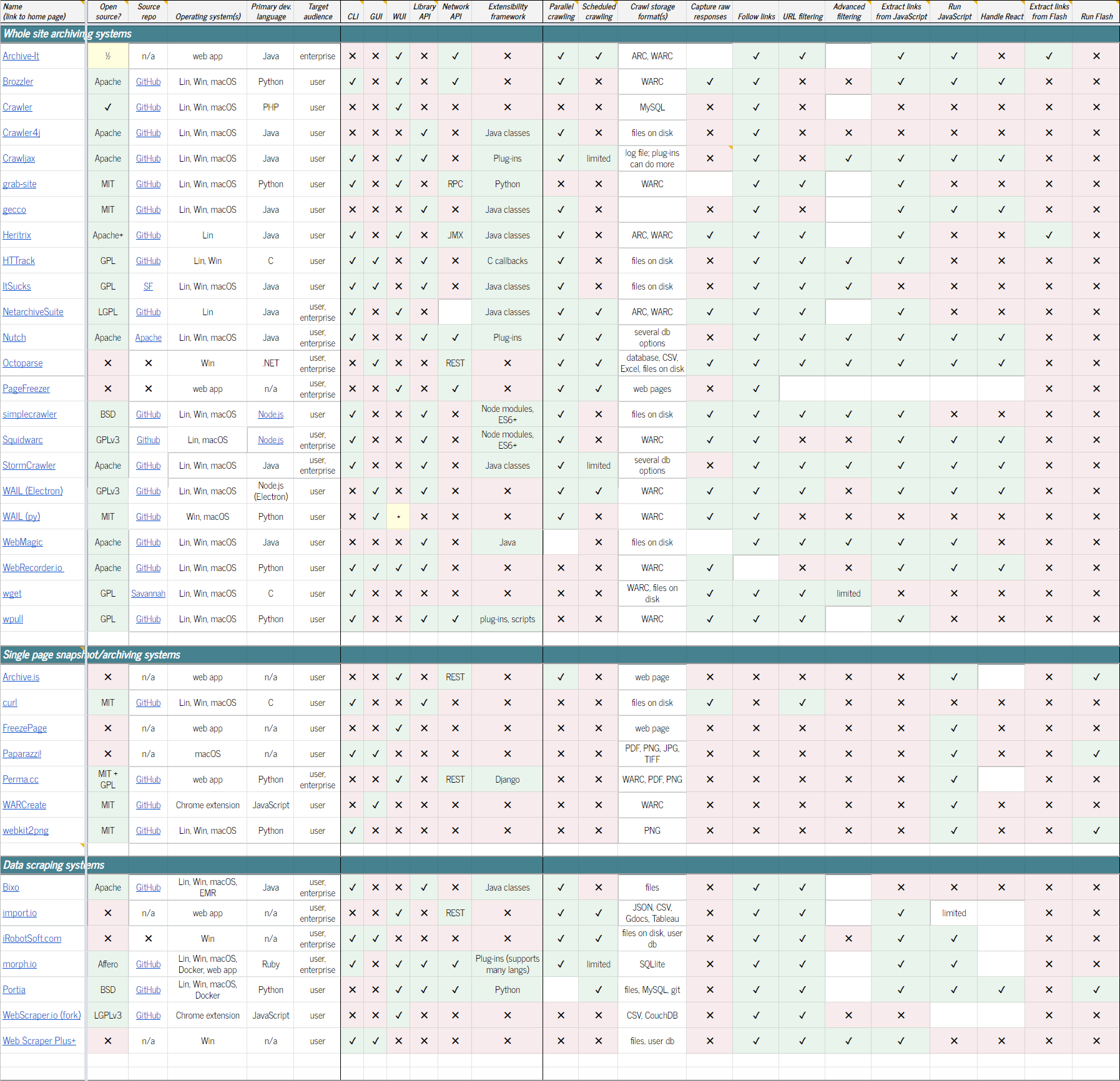
Существует ряд опенсорсных программ для веб-архивирования. Возможно, самый полный список таких проектов собран здесь. Есть также таблица со сравнением функциональности инструментов. Вот небольшой список некоторых проектов:
Архивирование целых сайтов
-
Archive-It: курируемая служба веб-архивирования. Предлагает годовую подписку на доступ к своему веб-приложению с различными услугами: полнотекстовый поиск, краулинг контента с различной частотой, выдача отчётов и т. д.
-
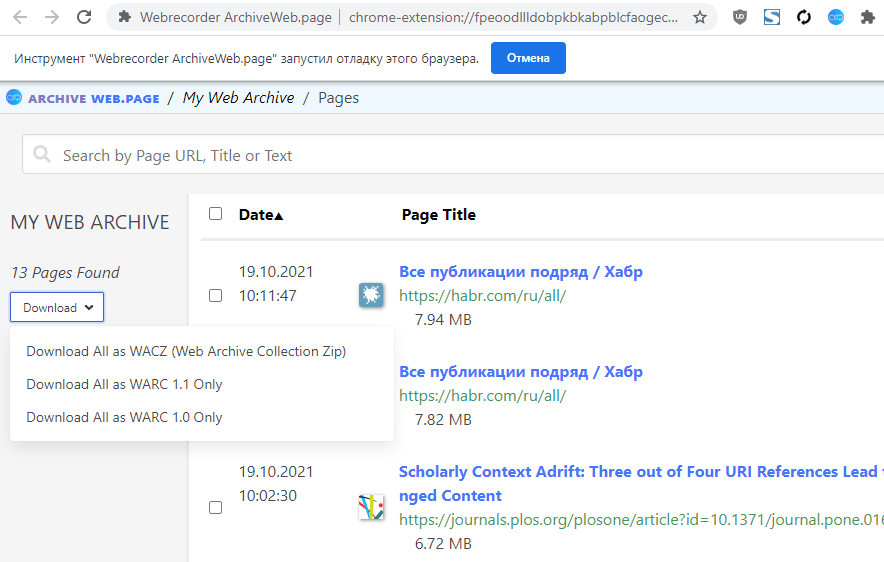
ArchiveWeb.page: десктопная программа и расширение для Chrome для создания веб-архивов. Расширение можно поставить на «запись», то есть на автоматическое сохранение всех страниц, которые открывались в браузере или в конкретной вкладке. Просматривать архивы в форматах WARC, WACZ, HAR или WBN можно даже в онлайне, для этого создан сайт ReplayWeb.page

-
Brozzler: опенсорсная утилита, которая для скачивания контента использует настоящий браузер (Chrome или Chromium), а также youtube-dl и rethinkdb
-
Crawler
-
Crawler4j: опенсорсный краулер на Java с простым интерфейсом
-
grab-site: предварительно сконфигурированный опенсорсный граббер сайтов, граф ссылок хранит на диске, а не в памяти, поэтому может успешно скачать сайт даже с 10 млн страниц. Результат записывает в формате WARC
-
gecco
-
Heritrix
-
HTTrack
-
ItSucks (не поддерживается с 2010 года)
-
NetarchiveSuite: разработка Датской королевской библиотеки
-
Nutch: краулер с локальным поиском изначально создавался как альтернатива аналогичному корпоративному продукту Google
-
Octoparse: проприетарная платная программа, работает только под Windows
-
PageFreezer: ещё одна проприетарная система, веб-приложение, специализируется на автоматической архивации сайтов и соцсетей для юридических целей
-
simplecrawler: простой API для краулера, не поддерживается
-
Squidwarc: ещё один краулер, который работает через браузер (Chrome или Chromium), поэтому умеет выполнять скрипты и извлекать оттуда ссылки для краулинга
-
StormCrawler: опенсорсный SDK для построения распределённых, масштабируемых краулеров на Apache Storm
-
WAIL (Electron): Web Archiving Integration Layer (WAIL) — графический интерфейс работает поверх многих веб-архиваторов, чтобы упростить пользователям процесс сохранения и последующего просмотра веб-страниц
-
WAIL (py): версия на Python
-
WebMagic: масштабируемый фреймворк
-
Conifer (бывш. WebRecorder.io): выделил пользовательскую утилиту WebRecorder в отдельный опенсорсный проект, сам продвигает услугу облачного веб-архивирования с бесплатным лимитом 5 ГБ
-
wget: популярная утилита из набора GNU тоже умеет сохранять на диске веб-архивы в виде файлов WARC
- wpull: wget-совместимый веб-архиватор, написанный на Python
Архивирование отдельных страниц
-
Archive.is: общедоступный сервис для съёмки снапшотов страниц, которые получают новые URL, сохраняются в архиве для всеобщего просмотра
-
curl: известная утилита командной строки для скачивания страничек
-
FreezePage: веб-интерфейс для скачивания страничек, сохранять их можно в облаке или на диске
-
Paparazzi!: маленькая утилита под macOS, которая делает графические скриншоты страниц
-
Perma.cc: сокращатель ссылок и веб-архиватор позиционируется как инструмент для школьников, студентов, юристов и всех остальных, кто хочет получить надёжную ссылку на документ с гарантией, что он не исчезнет и не изменится
-
WARCreate: расширение Google Chrome, которое сохраняет любую страницу в формате Web ARChive (WARC)
-
webkit2png: утилита командной строки для сохранения скриншотов простой командой типа
webkit2png http://www.google.com/
Системы скрапинга данных
-
Import.io: платная корпоративная система для скрапинга преимущественно финансовой информации с интеграцией собранных данных в сторонний софт
-
iRobotSoft.com: персональный «менеджер», который автоматизирует рутинные ежедневные задачи в интернете: созданные «роботы» могут в том числе ходить по сайтам, кликать по ссылкам и собирать данные с веб-страниц
-
morph.io: инструментарий для написания скраперов на Ruby, Python, PHP, Perl и Node.js, коллекция более 10 800 публичных скраперов
-
Zyte (бывш. Scrapinghub): платный сервис дата-скрапинга через Extraction API
-
WebScraper.io: расширение Chrome и Firefox для удобного скрапинга, экспорт в CSV, XLSX и JSON. Поддерживает работу в облаке по расписанию, через API, с продвинутым парсингом и т. д.
Выбор данных для скрапинга в расширении Chrome
- Web Scraper Plus+: платный парсер под Windows, давно не поддерживается и даже не совместим с Windows 7
Сравнительную таблицу со всеми функциями см. ниже.
Отдельно стоит отметить приложения для хранения закладок с распределением по папкам, категориям, с тегами. Здесь же копии всех веб-страниц. Такие программы можно назвать «архивами закладок». Например, LinkAce или Wallabag.

LinkAce (платная)
ArchiveBox: личный архив
ArchiveBox — одно из самых функциональных решений для архивирования веб-страниц на своём хостинге. Программа отличается тем, что у неё одновременно есть и веб-интерфейс, и продвинутая утилита командной строки (официально поддерживаются macOS, Ubuntu/Debian и BSD). Скоро появится десктопное приложение на электроне под Linux, macOS и Windows (оно пока в альфе).
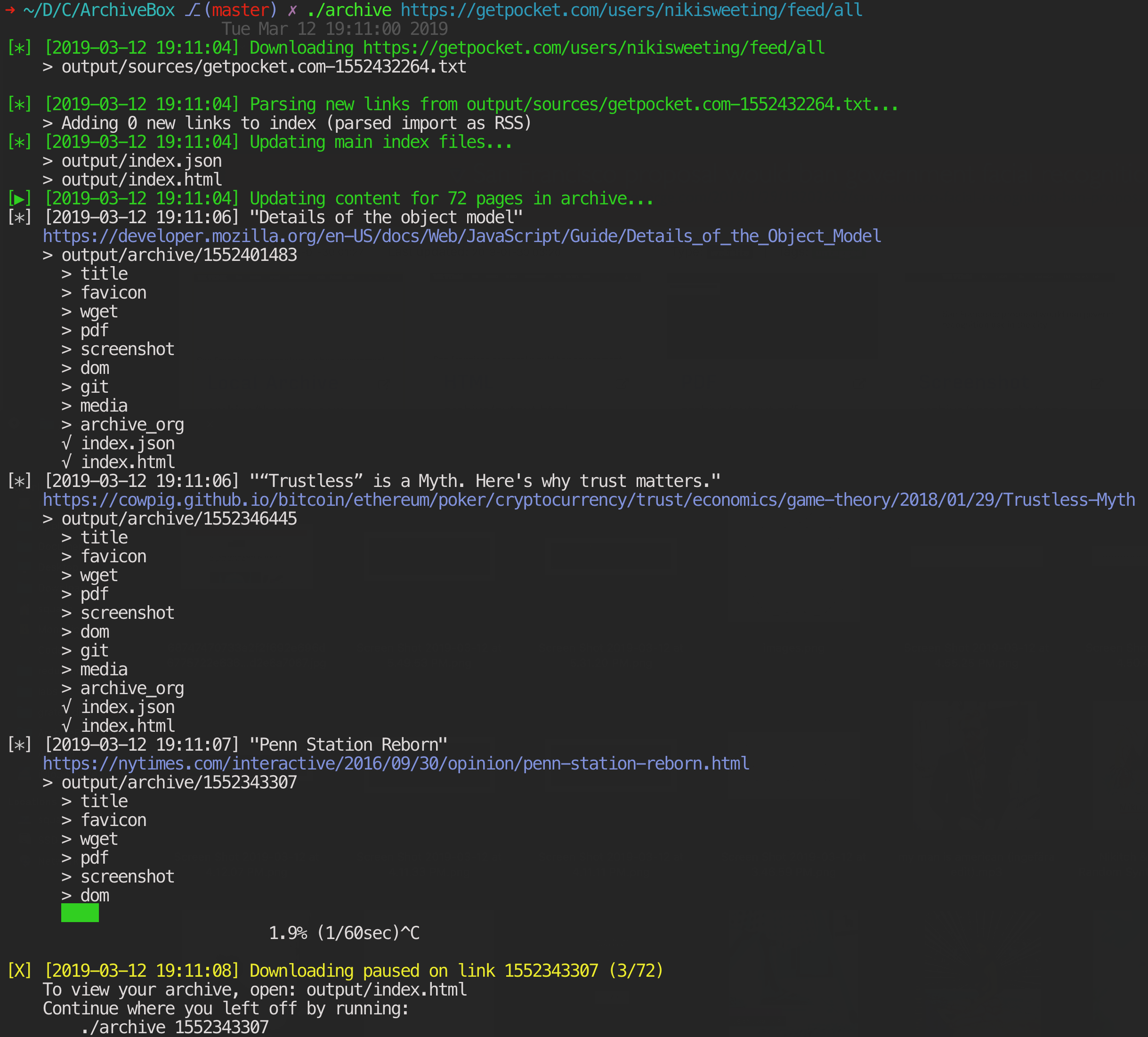
В ArchiveBox можно скинуть URL и указать формат сохранения: HTML, PDF, скриншот PNG или WARC. Автоматически сохраняется вся контекстная информация вроде заголовков, фавиконов и т. д. Грамотно скачивает медиафайлы с помощью youtube-dl, статьи (readability), код (git) и другие типы контента: всего около 12 модулей-экстракторов.
По умолчанию «для надёжности» все страницы вашего архива сохраняются также на archive.org. Опцию можно (и нужно) отключить.
См. также документацию по форматам сохранения и варианты конфигурации.
Инструмент командной строки работает очень просто.
Добавить ссылку в архив:
archivebox add 'https://example.com'Добавлять контент раз в день:
archivebox schedule --every=day --depth=1 https://example.com/rss.xmlАргумент
depth=1 означает, что сохраняется эта страница, а также все страницы, на которые она ссылается.Импорт списка адресов из истории посещённых страниц:
./bin/export-browser-history --chrome
archivebox add < output/sources/chrome_history.json
# или
./bin/export-browser-history --firefox
archivebox add < output/sources/firefox_history.json
# или
./bin/export-browser-history --safari
archivebox add < output/sources/safari_history.jsonИмпорт списка адресов из текстового файла:
cat urls_to_archive.txt | archivebox add
# или
archivebox add < urls_to_archive.txt
# или
curl https://getpocket.com/users/USERNAME/feed/all | archivebox addСамые популярные настройки из командной строки:
TIMEOUT=120 # default: 60 добавить больше секунд на скачивание для медленной сети или тормозного сайта CHECK_SSL_VALIDITY=True # default: False True = allow сохранение URL с некорректным SSL SAVE_ARCHIVE_DOT_ORG=False # default: True отключить дублирование на Archive.org MAX_MEDIA_SIZE=1500m # default: 750m увеличить/уменьшить максимальный размер файлов для youtube-dl PUBLIC_INDEX=True # default: True публичный доступ к индексу PUBLIC_SNAPSHOTS=True # default: True публичный доступ к страницам (снапшотам) PUBLIC_ADD_VIEW=False # default: False разрешение/запрет всем пользователям добавлять URL в архив
Как вариант, можно добавлять ссылки через веб-интерфейс на локалхосте:

Сервер с веб-интерфейсом тоже запускается из командной строки:
archivebox manage createsuperuser archivebox server 0.0.0.0:8000 # открыть http://127.0.0.1:8000 # опции, упомянутые выше archivebox config --set PUBLIC_INDEX=False archivebox config --set PUBLIC_SNAPSHOTS=False archivebox config --set PUBLIC_ADD_VIEW=False
По сохранённому архиву работает полнотекстовый поиск.
Накопители
На чём хранить личный архив? Теоретически можно сбрасывать архив на компакт-диски или магнитную ленту. Но с ними возникнет проблема поиска в реальном времени. Ведь это основная функция информационного архива — выдавать информацию мгновенно по запросу. Так что самым реалистичным вариантом видится информационное хранилище на HDD (с резервированием по типу RAID).
Многое зависит от объёмов архива. Если у вас скачаны все голливудские фильмы за последние 50 лет в разрешении 4K, то не остаётся вариантов, кроме магнитной ленты. Современные картриджи формата LTO-9 объёмом 45 терабайт стоят не очень дорого.

Копия памяти человека
Кто-то считает, что нужно сохранять в архиве всю информацию, какую человек когда-либо увидел или прочитал, в том числе фотографии, видеоролики, заметки, книги, веб-страницы, статьи. Возможно, даже записи с видеорегистратора, который постоянно работает и записывает всё, что происходит вокруг. Желательно свои мысли тоже записывать (в которых есть смысл).
Такой архив — это своеобразная «цифровая память» человека, копия его жизни, всех событий и воспоминаний, с полнотекстовым поиском. Цифровая копия всего, что попадало в мозг или возникало в нём самопроизвольно. Впрочем, это уже ближе к киберпанку.
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
- 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
- — 20% на выделенные серверы AMD Ryzen и Intel Core — HABRFIRSTDEDIC.
Доступно до 31 декабря 2021 г.
Комментарии (40)

slavius
03.11.2021 12:50-1https://habr.com/ru/company/vdsina/blog/550180/
Персональный интернет-архив без боли
ArchiveBox — продвинутый архиватор сайтов с огромным количеством поддерживаемых форматов и интерфейсов.
Возможности
Список сайтов можно подать на вход кучей разных способов (TXT, RSS, XML, JSON, CSV, SQL, HTML, Markdown, и т.д.), но самое интересное это импорт из всех основных браузеров (закладки, история) и «закладочных» сервисов (Pocket, Pinboard, Instapaper, Reddit Saved, OneTab и другие).
Хранение данных в HTML, JSON, PDF, PNG, и WARC — без самописных, проприетарных или новомодных форматов. При этом доступны и необычные методы экспорта, вроде извлечения текста (как в режиме Reader в браузерах) или Git-репозитория для скачанного со страницы кода.
Взаимодействие через терминал, веб-интерфейс, Python API, REST API и десктопное приложение (последние два варианта пока в альфе) на всех основных ОС (на винде нужен Docker или WSL)
Архивирование по расписанию (в сочетании с использованием истории браузера получается цепочка автосохранения всех посещённых сайтов)
Опционально — отправка URL на archive.org (чтобы иметь бэкап не только локально, но и на проверенных серверах)
Проект полностью опенсорсный, все надстройки опциональны и доустанавливаются в виде модулей. При отключенном экспорте в Internet Archive вообще все данные остаются на локальной машине, а при использовании Headless Chromium вместо Chrome можно обеспечить себе полную приватность.
Запланировано: использование JS-скриптов во время архивирования, для вырезания рекламы/попапов/разворачивания веток комментариев прямо на лету.
Уже работает, но нестабильно: сохранение контента за логином/пейволлом по кукам.
Ну а для локального хранения небольшого количества нужных страниц FireFox + PrintEditWE + SavePageWE

shovdmi
03.11.2021 13:51+1Я использую расширение для браузера Joplin Webclipper, который по сути часть Joplin app (https://joplinapp.org/) в которой веду базу знаний с заметками в формате markdown.
Что больше всего радует это работа и синхронизация баз между ПК и телефоном через Dropbox.

misharin
04.11.2021 12:38Тоже пользуюсь Joplin, однако для синхронизации использую Nextcloud - более приватно получается, когда на свой сервер сохраняешь.

dartraiden
04.11.2021 20:41более приватно получается
Я бы не сказал, что приватнее связки Dropbox+шифрование Joplin.
nobodysu
04.11.2021 21:01dartraiden
04.11.2021 21:36У меня 136 заметок. Из метаданных там видно только число файлов и дату их создания/изменения. Каким образом раскрытие этой информации ставит под угрозу мою приватность?
Эта информация ничего не даст атакующему. Какие-то заметки обновляются иногда, какие-то никогда, какие-то ежедневно. Можно даже предположить, что последняя это ToDo. Но что с того?

K0styan
05.11.2021 11:14У всех приличных заметочников есть клипперы: Evernote, OneNote, Notion. Есть и у Zotero, специализированного инструмента для хранения материалов.
Какие-то лучше работают, какие-то хуже, но в целом для персонального архива решений "из коробки" предостаточно.
shovdmi
05.11.2021 18:17всё так, но Joplin - opensource, бесплатные приложения для телефона, нет ограничений на объем или количество заметок. Облачная копия базы хранится не в облаке разработчика, и как следствие, бесплатные безлимитное хранилище в случае next cloud, либо объем вашего тарифного плана в случае dropbox.
За счет нет риска получить тыкву, если разработчик вдруг решит уменьшить количество бесплатных заметок, наложить санкции и т. д.

stargrave2
03.11.2021 16:22В качестве WARC-прокси/просмотрщика может выступать http://www.tofuproxy.stargrave.org, сам который использую. Динамическое добавление, удаление, индексирование, поддержка сегментированных .warc.gz/.warc.zst.
Sergey-Aleksandrovich
03.11.2021 17:48+3Странно, что в браузеры не встраивают функцию "добавить в архив" (по аналогии с добавить в закладки) - жмакнул кнопку и вот тебе копия страницы в локальном хранилище

Zalechi
04.11.2021 10:52Кстати, чем архив отличается от сохранения страницы браузером по CTRL+S?
Содержание не скачивает, только ссылки и тамбы?
Sergey-Aleksandrovich
04.11.2021 11:09Скачивает, и это тоже вариант. Только вопросом управление хранилищем занимаетесь вы (в какую папку, с каким именем, как потом найти). А если на уровне браузера по аналогии с закладками реализовать, то сохраненное лежит в папках браузера, доступно по тегам/наименованию и (потенциально) может синхронизироваться на разных устройствах, где браузер авторизован вашим аккаунтом.
Zalechi
04.11.2021 11:36Угу...
Тут не понял:
А если на уровне браузера по аналогии с закладками реализовать,
А ctrl+s на уровне ядра или браузера реализовано?
Sergey-Aleksandrovich
04.11.2021 11:40Ctrl+S это просто сохранить копию страницы на диск, как сохранить документ в вроде или екселе. А я говорю про сервис/фичу от браузера. Т.е. не "я ж сам все могу", а "вот у нас удобный встроеный сервис"
Zalechi
04.11.2021 11:45Ктрл+С вызывает функцую браузера выполняющую сохранение страницы, однако я не понимаю о какой фиче Вы говорите?
Sergey-Aleksandrovich
04.11.2021 12:03я не хочу думать о месте и структуре хранения - пусть браузер (его разработчики) выберут где и как оно хранится;
если сохранить файл на диск, то поиск нужного надо делать по файловой системе, а браузер в адресной строке не покажет сохраненные страницы после перемещения файлов, переустановки браузера или ОС - пусть браузер хранит и индексирует сохраненное самостоятельно;
я хочу иметь доступ к сохраненным копиям страниц с разных устройств (домашний комп, рабочий ноут, смартфон) - пусть браузер синхронизирует сохраненные страницы между моими устройствами.
Вот такую фичу я хочу

ComodoHacker
08.11.2021 12:47И все это, конечно же, бесплатно..
В Firefox это есть, называется Pocket.

Kirikekeks
03.11.2021 20:44+1elinx --dump "https://habr.com/ru/post" |gzip > o_web_archive.gz
zgrep 'шаман|buben|webarchive' /zabil/*. gz
Спасибо за статью. Просто есть еще вот такой способ, у которого тоже есть достоинства.

AlexanderS
03.11.2021 23:07Если у вас скачаны все голливудские фильмы за последние 50 лет в разрешении 4K, то не остаётся вариантов, кроме магнитной ленты. Современные картриджи формата LTO-9 объёмом 45 терабайт стоят не очень дорого.
Боюсь вы несколько ошибаетесь. 45 Тб — это с сжатием. А в реальности может получиться и все 18 Тб. Тоже немало, но цифра всё же уже не так впечатляет. Плюс LTO, тем более 9-ка, всё же технология уже достаточно тонкая и есть там некоторые проблемы с поиском привода, который бы нормально всё прочитал через много лет.QuAzI
05.11.2021 09:16А что бы вы посоветовали не сильно дорогое для SOHO? Именно с заделом "чтобы потом было проще прочитать"
AlexanderS
05.11.2021 12:30У меня нет такого опыта, чтобы советовать. Просто ко мне пару раз обращались именно с такой проблемой. А насколько она проблемная статистически я даже и не знаю, может это не так и страшно и всего у 0,001% встречается. В энтерпрайзе всё же пленка-то используется. С другой стороны в энтерпрайзе без проблем и в запас приводы покупают, да и могут денег отвалить за архивные модули. А в личных целях это будет непланируемое разорение. Я в своё время сделал ставку на обычные диски + Blu-Ray. Для операционного материала используется зеркальный RAID, для архивного — всё остальное, особо важное ещё и закатывается на 100 Гб болванки. Но тут всё зависит от объёмов. Да и 5 лет назад цены на диски-то были более гуманные.

Dee3
03.11.2021 23:15Добавил страничку в закладки.
У хабра же есть политика долговременного сохранения информации?Sergey-Aleksandrovich
04.11.2021 11:21Eсть такое понятие как "контрагентский риск" - все эти политики не более, чем "обещание".

aik
04.11.2021 10:39Формат warc лично я не особо понимаю, чем он лучше простого архива?
Всё равно приходится распаковывать для удобного использования.

Browning
04.11.2021 11:42Не устаю призывать: дамы и господа, пожалуйста, сохраняйте важные страницы не только себе, но и в Архив интернета. Кто-то в будущем скажет вам спасибо.

sakontwist
04.11.2021 15:39Сайты прекрасно сохраняются в Joplin с помощью его же плагина для браузеров.

QuAzI
05.11.2021 09:11archivebox выглядит интересно. А то сильно неудобно в FF каждый раз переключаться в Reader mode и оттуда в PDF "печатать" удобочитаемый контент (без смузистилей, баннеров и прочего).
Сохранность контента, конечно, печалит. Даже для контента который остался опубликован на хабре часто можно увидеть что скрины потеряны безвозвратно.
И отдельные вопросики с форматами хранения, чтобы это потом ещё и прочесть можно было нормально на любом подручном, в т.ч. на телефоне или е-книжке. Тут, мне кажется, не хватает возможности выгонять контент в Markdown или epub. У Instapaper есть возможность группу статей экспортнуть в epub - вот что-то такое же хочется видеть для хабра в формате "еженедельный дайджест"
up: что-то попробовал archivebox натравить на эту статью и с лёту обломался(
NeoCode
Пока я просто сохраняю нужные мне странички средствами браузера в mhtml. Сайтов, целиком пригодных к скачиванию, не так уж и много (обычно это какие-то авторские работы типа книг или методичек на университетских сайтах). Но для таких есть телепорт про и другие подобные программы.
А идеальная система - просто некая кнопка типа "лайка", аналогичная добавлению в закладки, по нажатию на которую страница сохраняется в оффлайне, добавляется в какие-то оффлайновые базы для поиска, и - в идеале - ставится на раздачу в децентрализованной сети.
nobodysu
Рекомендую SingleFile:
github.com/gildas-lormeau/SingleFile#install
NeoCode
Спасибо, для Firefox пригодится, а то там нет встроенного сохранения в mhtml
AlexanderS
Сколько ни пробовал подобных решений — в результате отказывался от них, обнаруживая косяки. Лучше уж сохранить по старинке и запаковать в zip. Оно как-то надежнее получается и для беспроблемного открытия в будущем. Сейчас проверил — в SingleFile на сохранённых страницах спойлеры, например, не работают.
Mike-M
Снимите галочку в настройках SingleFile: Other resources => remove scripts.
AlexanderS
Ух ты! Это я просмотрел, спасибо! Я в «Содержимое HTML» это ожидал увидеть.
А вот ещё такой вопрос. Спойлеры перед сохранением нужно открыть, иначе их содержимое не попадает в локальную копию. Я это приноровился делать через скрипт Greasemonkey через кликание на элементах спойлера требуемых сайтов. На особо медленных компах после рендеринга странички можно даже заметить закрывающиеся спойлеры) А как-то более цивилизованно эту проблему решить можно?
Mike-M
Вот с этим, увы, не подскажу.
Знаю лишь, что для многих спойлеров достаточно отключить настройку
remove scripts. При этом раскрывать спойлеры перед сохранением страницы не требуется: пример 1, пример 2.nobodysu
Ответ автора:
github.com/gildas-lormeau/SingleFile/issues/258
Mike-M
До сего дня пользовался попеременно расширением Save Page WE и печатью на PDF принтер.
Теперь — только SingleFile. Спасибо за рекомендацию!