

Типичный диалог на планировании:
Лид:
— Пользователи просят репликацию вот этих колонок в этих таблицах из продакшен базы в data lake.
Разработчик:
— Когда?
Лид:
— Вчера.
Запрос в таску, таску в спринт, а дальше вручную исследование входных данных, подготовка маппинга и миграций, верификация, развертывание, и спустя пару спринтов пользователь получит желаемые данные. А как нам ускорить этот процесс, ну скажем, до нескольких часов?
Всем привет! Меня зовут Семен Путников, я — инженер данных в DINS. Я работаю в команде, которая участвует в разработке инструментов управления и анализа больших данных для RingCentral. Под катом история о том, как мы решили проблему частой миграции данных для наших ETL и радуем пользователей быстрыми ответами на их запросы.
Постановка задачи
В начале моей истории есть ETL, экспортирующий данные из Salesforce в наш уютный data lake. Обогатив эти данные сведениями из других источников, мы можем, например, анализировать приток и отток пользователей.
Специфика работы с этой CRM-системой заключается в ограничениях платной подписки: есть лимит на объем выгружаемых объектов и их полей. Нам необходимо выгружать новые поля/объекты, проверять их ценность для бизнеса, а затем исключать те, что не оправдали себя. Такие периоды проверки необходимо проводить в сжатые сроки, чтобы получать новую актуальную аналитику и развивать основной продукт.
Но как выпускать релизы и обновлять ETL каждые две недели? Внедрение жесткого маппинга выгружаемых данных в код привело к тому, что нам приходилось часто выпускать релизы с обновленной конфигурацией. А это значит, каждый раз запускать комплексный процесс верификации и деплоя. Это отнимало много ресурсов и вносило большой объем мануальной работы. Не говоря уже о том, что в условиях, при которых необходимо поддерживать большой парк ETL процессов, выделять так много времени на один проект просто расточительно и невозможно.
Наша глобальная стратегия решения этой задачи была направлена на автоматизацию изменений конфигурации ETL. Забегая немного вперед, скажу, что с ростом интереса пользователей к выгружаемым данным, выросло и количество запросов на обновление. Но выбранное решение позволило отвечать на них за адекватное время.
План решения
Основная цель — сокращение времени доставки изменений в данные с помощью снижения роли мануальных действий в разработке, верификации и развертывании релизов.
Но перед тем как обсуждать архитектуру решения, необходимо чуть больше рассказать про структуру основного ETL-процесса.
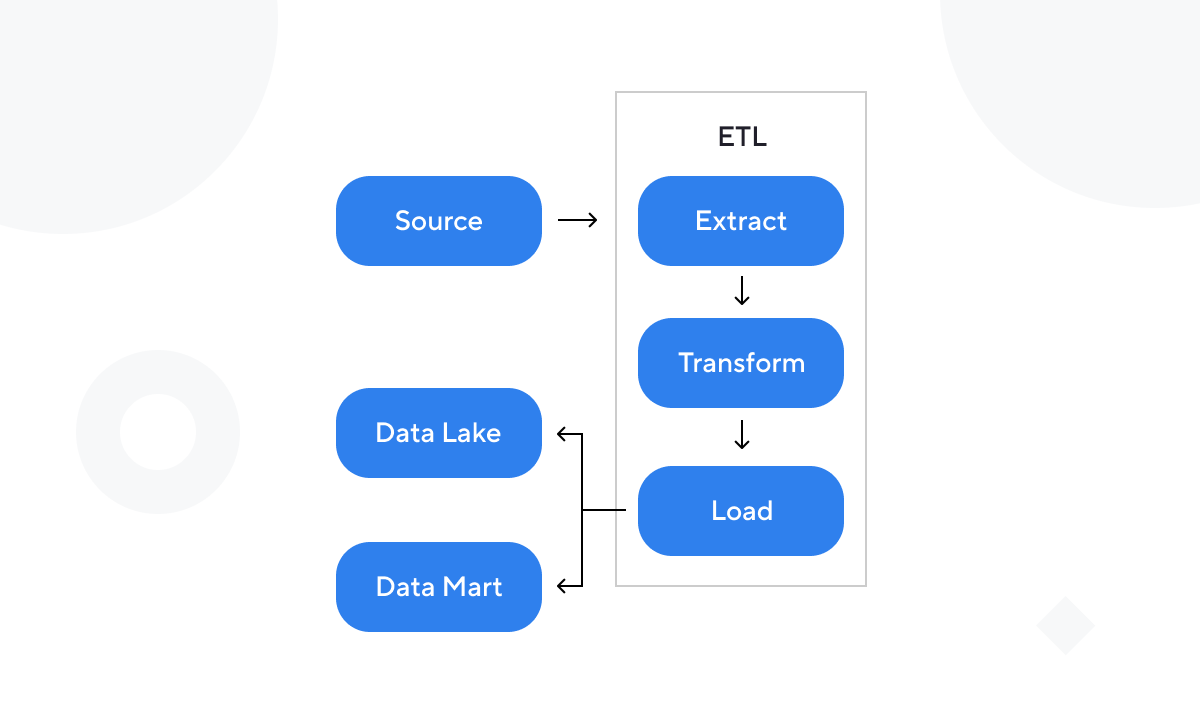
Архитектура ETL-процесса выглядит следующим образом:
экспорт данных из источника,
трансформация,
отгрузка в data lake,
реплицикация в data mart.
Каждый из вышеперечисленных этапов должен обладать метаинформацией о входных данных. Первый этап — чтобы выбирать необходимые поля объектов. Второй этап — чтобы приводить данные к типу, принятому в data lake. Третий и четвертый этапы — для миграции целевых таблиц под новые поля.
Конфигурация объекта
«Объект» в контексте данного процесса — это артефакт, содержащий всю необходимую информацию для обработки одной таблицы из источника. Рассмотрим подробнее.
Для выгрузки данных объект должен сообщить ETL название таблицы в источнике и имена желаемых полей. Также здесь опционально может добавляться информация, например, о типе загрузки: инкрементальная или полная загрузка. Тогда конфигурация будет выглядеть примерно так:
{
“source_object_name” : “users”,
“export_type” : “incremental”,
“fields” :
[
{“source_name” : “user_id”},
{“source_name” : “login”},
{“source_name” : “company_id”}
...
]
}На этапе трансформации ETL отображает поля на типы, информацию о которых также берет из объекта. Добавим эту информацию к нашей конфигурации:
{
“source_object_name” : “users”,
“export_type” : “incremental”,
“fields” :
[
{“source_name” : “user_id”, “datatype” : “bigint”},
{“source_name” : “login”, “datatype” : “string”},
{“source_name” : “company_id”, “datatype” : “bigint”}
...
]
}Чтобы аккуратно уложить выгруженные данные, необходимо подготовить целевые таблицы: настроить схему, партиционирование и другие возможные свойства. Частично схема таблицы сконфигурируется с помощью уже имеющейся метаинформации: возьмем типы данных, которые заполнили на предыдущем шаге. Однако мы хотим сохранить за собой возможность изменить имя поля в целевой базе. Дополним эту информацию в конфигурацию объекта.
{
“source_object_name” : “users”,
“target_object_name” : “users_stage”,
“export_type” : “incremental”,
“fields” :
[
{“source_name” : “user_id”,
“target_name” : “user_id_stage”,
“datatype” : “bigint”},
{“source_name” : “login”,
“target_name” : “login_stage”,
“datatype” : “string”},
{“source_name” : “company_id”,
“target_name” : “company_id_stage”,
“datatype” : “bigint”}
...
]
}Мы решили хранить конфигурацию в формате json, однако для решение основной задачи это не важно и может быть перенесено на другой формат. Также конфигурация может быть дополнена всеми необходимыми параметрами, специфичными для каждого отдельного процесса. Это делает данную концепцию портируемой под разные сценарии использования.
Чтобы сделать ETL независимым от метаданных входных данных, мы выделили конфигурации объектов, относящихся к данному процессу, в отдельный артефакт со своим релизным и верификационным циклом. Мы называем его «конфигурацией ETL».

От слов к делу
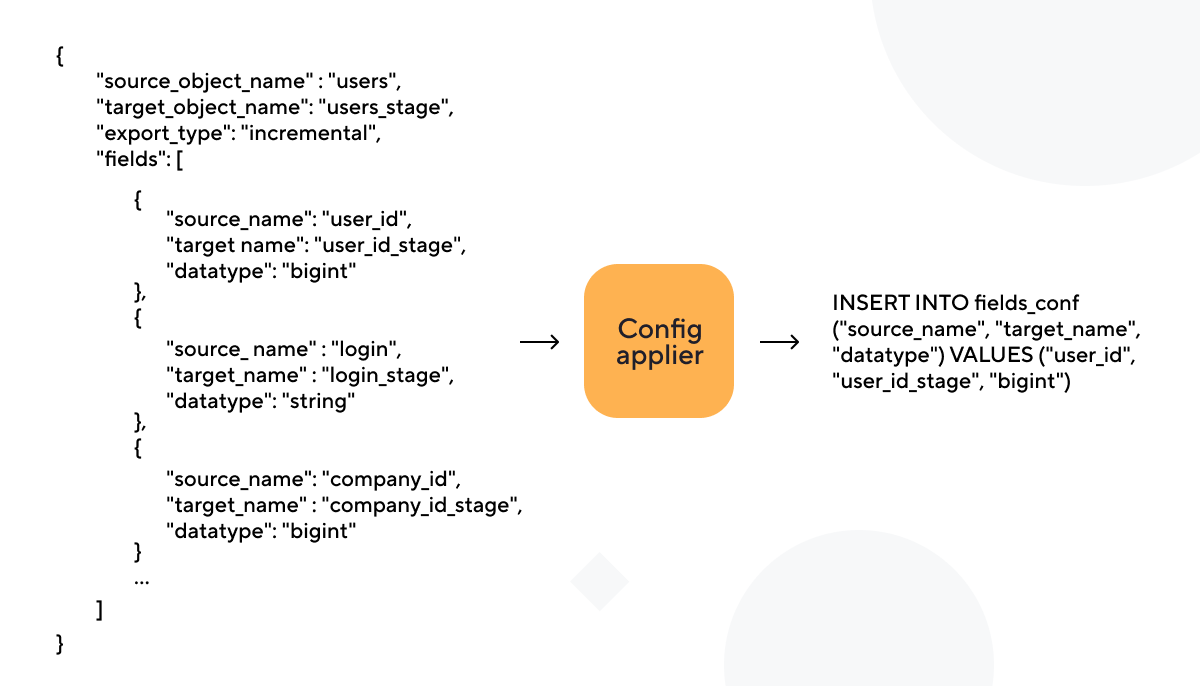
Первый архитектурный компонент — это config applier. Он переносит сериализованную конфигурацию объекта на реляционную модель в базу данных. Мы для этого используем PostgreSQL.
Конфигурации не заменяют друг друга, а версионируются. Это позволяет нам сохранять историю изменений. Перед каждым запуском ETL сверяется с метаданными в базе и получает актуальную конфигурацию.
Помимо основной задачи на данном этапе происходит валидирование конфигурации в соответствии с принятыми правилами.
Первое правило клуба хороших конфигов — количество фичей в новой конфигурации должно быть больше или равно количеству фичей в старой конфигурации. Однако поля можно помечать как «невыгружаемые». Это правило ограждает нас от проблемы миграции схемы исторических данных: целевой таблице проще понять, куда отображать данные со старой схемой без коллизии имен.
Второе правило — каждая версия конфигурации должна обладать минимальным необходимым списком параметров для процесса. Здесь отсекаются нежизнеспособные версии, которые могут привести к сбою в работе процесса.
Опционально можно проверять отсутствие опечаток в номинальных параметрах.
Когда с проверками покончено, json превращается в набор insert скриптов и отправляется в базу.
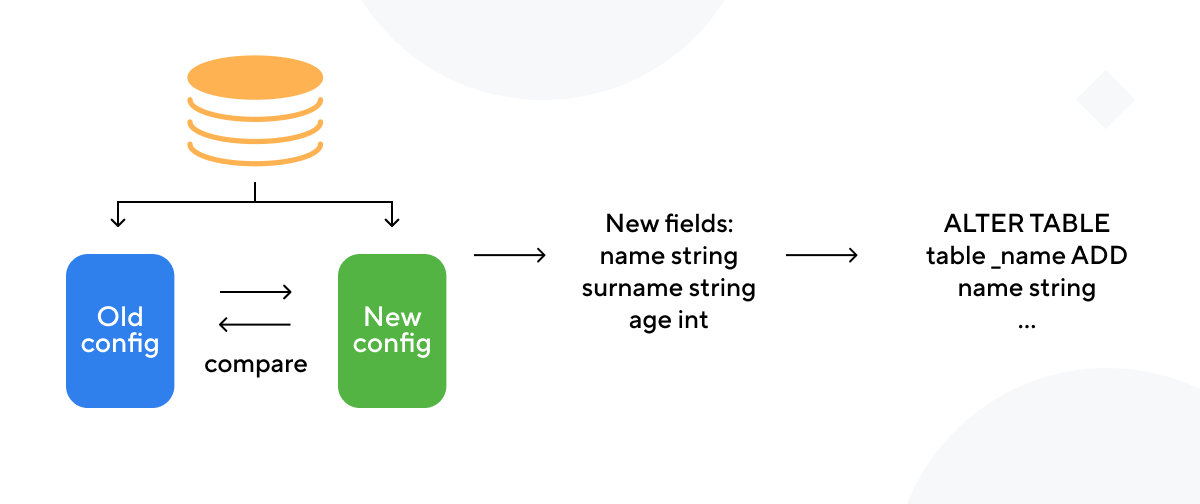
После того, как новая конфигурация расположилась в реляционной модели и готова к использования, наступает время второго приложения — config migrator.
Логика миграции таблиц основана на сравнении разных версий конфигурации в базе данных. Приложение вытягивает последнюю и предпоследнюю версию конфигурации для объекта из базы и на их различии строит миграционный сценарий.
В текущей версии, как я уже упомянул выше, мы не рассматриваем возможность удаления полей из объекта, так как это потребовало бы обратной миграции всех исторических данных, что достаточно затратно.
Рассмотрим работу этого приложения по шагам. Первым делом приложение, сравнивая версии конфигурации, получает список изменений. Затем, формируются sql-скрипты изменений формата «ALTER TABLE ADD COLUMN» для целевых таблиц как в data lake, так и в data mart. Когда для всех таблиц получены скрипты миграций, приложение поочередно запускает их исполнение.
Здесь основную трудность составляет работа с особенностями процесса изменений в отдельных базах данных. Например, в Apache Hive отсутствует операция DROP COLUMN. Вместо этого нам необходимо использовать REPLACE COLUMNS со старой схемой, чтобы откатиться к предыдущей версии.
Последовательное исполнение миграционных скриптов позволяет нам контролировать состояние целевых таблиц и оперативно отлавливать некорректное поведение при миграции.
Имплементация
Имплементировать принятое решение мы стали поэтапно. Первым этапом были переписаны конфигурации объектов под новый формат и поддержана работа с конфигурациями из базы данных на уровне ETL. Вторым этапом мы автоматизировали процесс раскатки конфигурации в базе данных, создав config applier. Заключительным этапом стало создание миграционного приложения.
Разделение процесс имплементации на этапы позволило нам сразу получать пользу от новой архитектуры. К тому же успехи начальных этапов позволили получить ресурсы на дальнейшее развитие.
Планы на будущее
Первый пункт улучшений заключается в инкапсуляции всей логики работы с конфигурацией в отдельную библиотеку, чтобы облегчить процесс портирования в другие проекты.
Второй пункт связан с вынесением процесса миграции таблиц из внешнего процесса внутрь ETL, так чтобы подготовительный этап каждого запуска пайплайна заключался в проверке изменений и запуска миграций. Такой способ не будет требовать остановки запланированных пайплайнов для миграции с блокировкой из внешнего процесса. Однако в данный момент процесс нестабилен из-за специфики используемых нами баз данных.
Итоги
От десятков часов мануальной работы, отнимающих время у более интересных задач, мы перешли к паре часов в спринт на написание нескольких строк в json-скрипты.
Процесс верификации стал прозрачнее, так как все компоненты автоматизации могут быть протестированы независимо от самих конфигураций объектов. А сами конфигурации валидируются внутренней проверкой config applier.
Комментарии (4)

OkunevPY
22.11.2021 11:44В нашем продукте эта задача решается схожим образом, но конфигурации задаются пользователем через UI, метаданные версионируються, данные тоже, в любой момент времени единицу объекта можно поднять по истории вверх или окатить вниз.
Источниками данных служит абстракция коннекторов которые могут как получать так и отдавать данные, не только в наше хранилище, но и в любое допустимое из списка коннекторов.
В итоге мы можем проинтегрирорвать всё со всем, буквально в пару кликов. Главное можем передать это пользователю, простая трансформация без инъекций кода накидываеться пользователем самостоятельно

semaputnik Автор
22.11.2021 11:46Отдать настройку пользователям - отличный вариант. Очень надеюсь, что и мы скоро перейдем к подобной системе
TimonKK
Спасибо за статью. Про "удаления полей из объекта" не понял, все таки если поле уже не нужно или в источнике его теперь уже нет - это изменение доходит до data lake/data mart?
semaputnik Автор
Если поле ранее загружалось и необходимость в нем отпала или оно пропало в источнике, мы отключаем его загрузку через конфигурацию. И когда пайплайн начнет в следующий раз загрузку, это отключенное поле будет пропущенно из запроса, а в целевую таблицу зальется значение NULL что в Data lake, что в Data Mart. Конечно, с извещением пользователей.
Т.е. мы не удаляем отключенное поле из схем целевых таблиц, чтобы избежать обязательной в таких случаях миграции исторических данных.