
Эта статья является переводом материала «Untangling Microservices, or Balancing Complexity in Distributed Systems».
Расцвет микросервисов закончился. Uber преобразовывает тысячи микросервисов в более управляемое решение [1]; Келси Хайтауэр предсказывает, что будущее за монолитами [2]; и даже Сэм Ньюман заявляет, что микросервисы никогда не должны быть выбором по умолчанию, а скорее крайним средством [3].
Что происходит? Почему так много проектов стало невозможно поддерживать, несмотря на обещание микросервисов простоты и гибкости? Или все-таки монолиты лучше?
В этом посте я хочу ответить на эти вопросы. Вы узнаете об общих проблемах проектирования, которые превращают микросервисы в распределенные большие комки грязи (distributed big balls of mud), и, конечно же, о том, как их избежать.
Но сначала давайте проясним, что такое монолит.
Монолит
Микросервисы всегда позиционировались как решение для монолитных кодовых баз. Но обязательно ли монолиты являются проблемой? Согласно определению Википедии [4], монолитное приложение является автономным и независимым от других приложений. Независимость от других приложений? Разве не за этим мы гоняемся, часто безрезультатно, когда разрабатываем микросервисы? Дэвид Хайнемайер Ханссон [5] сразу обратил внимание на ложные обвинения в сторону монолитов. Он предупредил об ответственности и проблемах, присущих распределенным системам, и использовал Basecamp, чтобы доказать, что крупная система, обслуживающая миллионы клиентов, может быть реализована и поддерживаться в монолитной кодовой базе.
Следовательно, микросервисы не «заменяют» монолиты. Реальная проблема, которую должны решать микросервисы, - это неспособность достичь бизнес-целей. Часто командам не удается достичь бизнес-целей из-за экспоненциально растущих или, что еще хуже, непредсказуемых затрат на внесение изменений. Другими словами, система не в состоянии идти в ногу с потребностями бизнеса. Неконтролируемая стоимость изменений - это свойство не монолита, а скорее большого комка грязи [6]:
«Большой ком грязи» - это беспорядочно структурированный, растянутый, неряшливый, словно перемотанный на скорую руку изоляционной лентой и проводами, джунгли спагетти-кода. Эти системы показывают безошибочные признаки нерегулируемого роста и постоянных доделок. Информация делится беспорядочно между отдаленными элементами системы, часто до такой степени, что почти вся важная информация становится глобальной или дублируется.
Сложность изменения и развития большого комка грязи может быть вызвана множеством факторов: координацией работы нескольких команд, конфликтующими нефункциональными требованиями или сложной бизнес-областью. В любом случае, мы часто стремимся решить эту проблему, разбивая такие неуклюжие решения на микросервисы.
Микро что?
Термин «микросервис» подразумевает, что некоторая часть сервиса может быть измерена, и ее стоимость должна быть сведена к минимуму. Но что именно означает микросервис? Давайте рассмотрим несколько распространенных способов использования этого термина.
Микрокоманды?
Первый - это размер команды, которая работает над сервисом. И измерять эту метрику надо в пиццах. Шутки в сторону. Говорят, если команду, работающую над сервисом, можно накормить двумя пиццами, то это микросервис. Я нахожу это эвристическим анекдотом, поскольку я создавал проекты с командами, которых можно было накормить одной пиццей, и я осмеливаюсь называть эти комы грязи микросервисами!
Микроcodebases?
Другим широко распространенным подходом является разработка микросервиса на основе размера его кодовой базы. Некоторые доводят это понятие до крайности и пытаются ограничить размеры сервисов определенным количеством строк кода. Тем не менее, точное количество строк, необходимых для создания микросервиса, еще предстоит найти. Как только этот святой Грааль архитектуры программного обеспечения будет обнаружен, мы перейдем к следующему вопросу — какова рекомендуемая ширина редактора для создания микросервисов?
Если серьезно, то преобладает менее радикальная версия этого подхода. Размер кодовой базы часто используется в качестве эвристики для определения того, является ли это микросервисом или нет.
В некотором роде такой подход имеет смысл. Чем меньше кодовая база, тем меньше объем бизнес-домена. Таким образом, его проще понять, внедрить и развить. Более того, меньшая кодовая база имеет меньше шансов превратиться в большой ком грязи - и, если это произойдет, ее проще рефакторить.
К сожалению, вышеупомянутая простота - всего лишь иллюзия. Когда мы оцениваем дизайн сервиса на основе самого сервиса, мы упускаем важную часть проектирования системы. Мы забываем о самой системе, о системе, компонентом которой является сервис.
«Есть много полезных и показательных эвристик для определения границ сервиса. Размер - один из наименее полезных». ~ Ник Тьюн
Мы строим системы!
Мы создаем системы, а не набор сервисов. Мы используем архитектуру на основе микросервисов для оптимизации проектирования системы, а не проектирования отдельных сервисов. Что бы ни говорили другие, микросервисы не могут и никогда не будут ни полностью отделены, ни полностью независимы. Вы не можете построить систему из независимых компонентов! Это противоречило бы самому определению термина «система» [7]:
1. Набор связанных вещей или устройств, которые работают вместе
2. Набор компьютерного оборудования и программ, используемых вместе для определенной цели
Сервисы всегда должны взаимодействовать друг с другом, чтобы сформировать систему. Если вы проектируете систему, оптимизируя ее сервисы, но игнорируя взаимодействия между ними, вы можете получить вот что:

Эти «микросервисы» могут быть простыми по отдельности, но сама система - это ад!
Итак, как мы разрабатываем микросервисы, которые справляются со сложностью не только сервисов, но и системы в целом?
Это сложный вопрос, но, к счастью для нас, на него давным-давно был дан ответ.
Общесистемный взгляд на сложность
Сорок лет назад не было облачных вычислений, не было требований глобального масштаба и не было необходимости развертывать систему каждые 11,7 секунды. Но инженерам все еще приходилось уменьшать сложность систем. Несмотря на то, что инструменты в те дни были другими, проблемы – и, что более важно, решения — все они актуальны в наши дни и могут быть применены при проектировании систем на основе микросервисов.
В своей книге «Composite/Structured Design» (ей больше 40 лет) [8] Гленфорд Дж. Майерс обсуждает, как структурировать процедурный код, чтобы уменьшить его сложность. На самой первой странице книги он пишет:
Сложность - это гораздо больше, чем просто попытка минимизировать локальную сложность каждой части программы. Гораздо более важным типом сложности является глобальная сложность: сложность общей структуры программы или системы (то есть степень ассоциации или взаимозависимости между основными частями программы).
В нашем контексте локальная сложность - это сложность каждого отдельного микросервиса, тогда как глобальная сложность - это сложность всей системы. Локальная сложность зависит от реализации сервиса; глобальная сложность определяется взаимодействиями и зависимостями между сервисами.
Итак, какая сложность важнее - локальная или глобальная? Давайте посмотрим, что произойдет, когда будет решена только одна из сложностей.
Удивительно легко свести глобальную сложность к минимуму. Все, что нам нужно сделать, это устранить любые взаимодействия между компонентами системы, т. е. реализовать все функциональные возможности в одном монолитном сервисе. Как мы видели ранее, эта стратегия может работать в определенных сценариях. В других случаях это может привести к страшному большому кому грязи – вероятно, к максимально возможному уровню локальной сложности.
С другой стороны, мы знаем, что происходит, когда вы оптимизируете только локальную сложность, но пренебрегаете глобальной сложностью системы — еще более ужасный распределенный большой ком грязи.
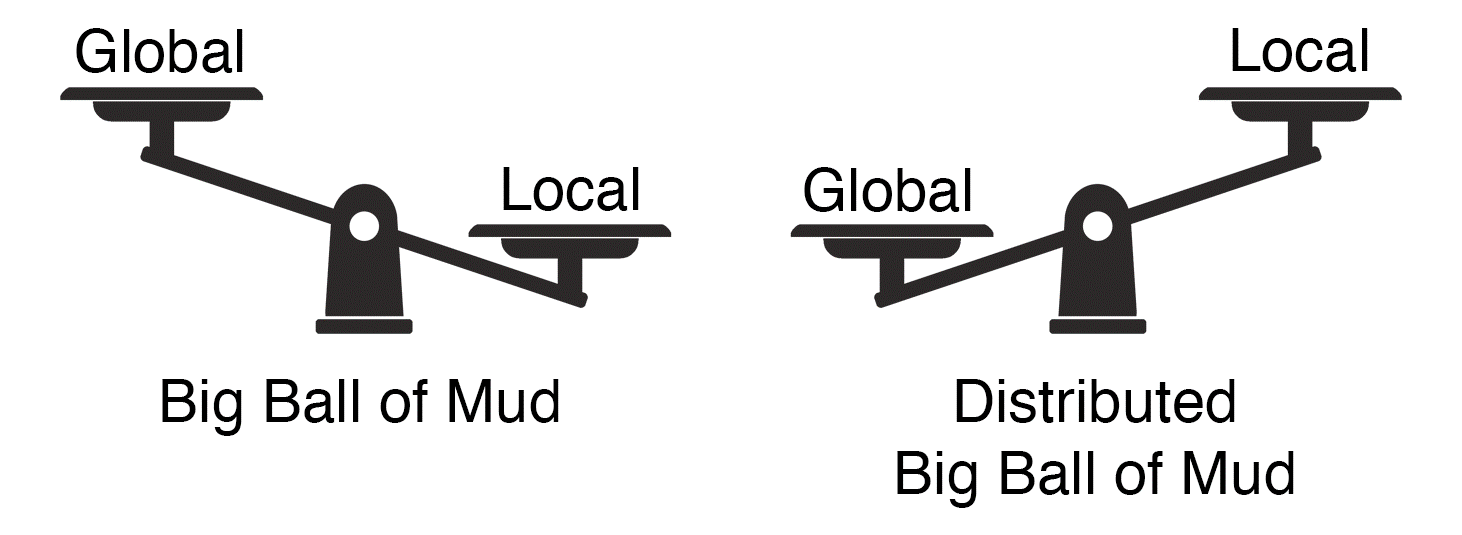
Следовательно, если мы сосредоточимся только на одном типе сложности, не имеет значения, какой из них будет выбран. В довольно сложной распределенной системе противоположная сложность будет стремительно расти. Поэтому мы не можем оптимизировать только одну. Вместо этого мы должны сбалансировать как локальные, так и глобальные сложности.
Интересно, что средства балансировки сложности, описанные в книге «Composite/Structured Design», относятся не только к распределенным системам, но и дают представление о том, как проектировать микросервисы.
Микросервисы
Давайте начнем с определения того, что именно представляют собой те сервисы и микросервисы, о которых мы говорим.
Что такое сервис?
Согласно стандарту OASIS [9], сервис является:
Механизм для обеспечения доступа к одной или нескольким возможностям, где доступ предоставляется с использованием определенного интерфейса.
Интерфейс сервиса определяет функциональность, которую он предоставляет миру. Согласно Рэнди Шупу [10], открытый интерфейс сервиса - это просто любой механизм, который передает данные в сервис или получает из него. Он может быть синхронным, например, обычная модель запроса/ответа, или асинхронным (одна сторона производит, а другая потребляет события). В любом случае, синхронный или асинхронный, открытый интерфейс - это просто средство для передачи данных в сервис или получения из него. Рэнди также описывает общедоступные интерфейсы сервиса как входную дверь.
Сервис определяется своим общедоступным интерфейсом, и этого определения достаточно, чтобы понять, что делает службу микросервисом.
Что такое микросервис?
Если сервис определяется его общедоступным интерфейсом, то микросервис — это сервис с микро-публичным интерфейсом – микро-входной дверью.
Этой простой эвристике следовали во времена процедурного программирования, и она более чем актуальна в области распределенных систем. Чем меньше предоставляемый вами сервис, тем проще его реализация и тем ниже его локальная сложность. С точки зрения глобальной сложности, более мелкие общедоступные интерфейсы создают меньше зависимостей и соединений между сервисами.
Понятие микроинтерфейсов также объясняет широко распространенную практику, когда микросервисы не раскрывают свои БД. Никакой микросервис не может получить доступ к БД другого микросервиса, только через его общедоступный интерфейс. Почему? Ну, БД была бы огромным публичным интерфейсом! Просто подумайте, сколько различных операций вы можете выполнить с реляционной БД.
Следовательно, повторюсь, в распределенных системах мы балансируем локальные и глобальные сложности, сводя к минимуму общедоступные интерфейсы сервисов и, таким образом, превращая их в микросервисы.
ПРЕДУПРЕЖДЕНИЕ
Эта эвристика может показаться обманчиво простой. Если микросервис - это просто сервис с микроинтерфейсом, то мы можем просто ограничить публичные интерфейсы только одним методом. Поскольку входная дверь не может быть меньше этой, это должны быть идеальные микросервисы, верно? Не совсем. Чтобы продемонстрировать, почему нет, я приведу пример из моего другого поста [11] на эту тему:
Допустим, у нас есть следующий сервис управления backlog-ом:
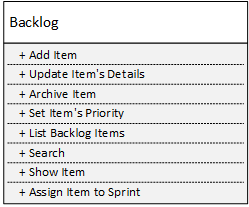
После того, как мы разложим его на 8 сервисов, каждый из которых имеет один публичный метод, мы получим сервисы с идеальной локальной сложностью:

Но можем ли мы подключить их к системе, которая фактически управляет backlog-ом? Не совсем. Чтобы сформировать систему, сервисы должны взаимодействовать друг с другом и обмениваться информацией об изменениях в состоянии каждого сервиса. Но они не могут. Публичные интерфейсы сервисов этого не поддерживают.
Следовательно, мы должны расширить входные двери с помощью публичных методов, которые обеспечивают интеграцию между сервисами:

Бум. Если мы оптимизируем сложность каждого сервиса в отдельности, наивная декомпозиция отлично работает. Однако, когда мы пытаемся подключить сервисы в систему, возникает глобальная сложность. В результате система становится запутанной. Мы также должны расширить публичные интерфейсы за пределы нашей первоначальной цели — ради интеграции. Перефразируя Рэнди Шоупа, в дополнение к крошечной входной двери мы создали огромный вход «только для персонала»! Что подводит нас к важному моменту: Сервис, имеющий больше методов, связанных с интеграцией, чем с бизнесом, является сильной эвристикой для растущего распределенного большого кома грязи!
Следовательно, порог, при котором публичный интерфейс сервиса может быть сведен к минимуму, зависит не только от самого сервиса, но и от системы, частью которой он является. Правильная декомпозиция на микросервисы должна сбалансировать глобальную сложность системы и локальные сложности ее сервисов.
Проектирование границ сервисов
«Найти границы сервиса действительно чертовски сложно… Нет никакой блок-схемы!» - Уди Дахан
Приведенное выше утверждение Уди Дахана особенно верно для систем на основе микросервисов. Определить границы микросервисов сложно, и, вероятно, невозможно понять их с первого раза. Это делает разработку довольно сложной системы на основе микросервисов итеративным процессом.
Следовательно, безопаснее начинать с более широких границ - возможно, границ соответствующих ограниченных контекстов [12] - и разбивать их на микросервисы позже, когда будет получено больше знаний о системе и ее бизнес-области. Это особенно актуально для сервисов, охватывающих основные области бизнеса [13].
Микросервисы вне распределенных систем
Несмотря на то, что микросервисы были «изобретены» совсем недавно, вы можете найти множество реализаций тех же принципов проектирования в других отраслях.
Кросс-Функциональные команды. Все мы знаем, что кросс-функциональные команды – самые эффективные. Такая команда представляет собой разноплановую группу профессионалов, работающих над одной задачей. Эффективная кросс-функциональная команда максимизирует общение внутри команды и сводит к минимуму общение за ее пределами.
Наша отрасль только недавно открыла для себя кросс-функциональные команды, но целевые группы существуют всегда. Основополагающие принципы для них те же, что и для системы на основе микросервисов: высокая сплоченность (cohesion) внутри команды и низкая взаимосвязь (coupling) между командами. «Публичный интерфейс» команды сводится к минимуму за счет включения в команду навыков, необходимых для выполнения задачи (то есть деталей реализации).
Микропроцессоры. Наткнулся на этот пример в замечательном блоге Вона Вернона на ту же тему. В своем посте Вон проводит интересную параллель между микросервисами и микропроцессорами. В частности, он обсуждает разницу между процессорами и микропроцессорами:
Мне кажется интересным, что существует классификация размеров, которая помогает определить, считается ли центральный процессор (CPU) микропроцессором: размер его шины данных [21]
Шина данных микропроцессора – это его публичный интерфейс. Он определяет объем данных, которые могут передаваться между микропроцессором и другими компонентами. Существует строгая классификация размеров для публичного интерфейса, которая определяет, считается ли центральный процессор (ЦП) микропроцессором.
Unix Philosophy. Философия Unix, или путь Unix, - это набор культурных норм и философских подходов к минималистичной модульной разработке программного обеспечения [22].
Кто-то может возразить, что философия Unix противоречит моему мнению о том, что вы не можете построить систему из полностью независимых компонентов: разве программы unix не являются полностью независимыми и все же формируют рабочую систему? Верно и обратное. Путь Unix почти буквально определяет, что программы должны предоставлять микроинтерфейсы. Давайте посмотрим, как принципы философии Unix соотносятся с понятием микросервисов:
Первый принцип требует, чтобы публичные интерфейсы программ предоставляли одну согласованную функцию, вместо того, чтобы загромождать программы функциональностью, не связанной с их первоначальной целью:
Сделайте так, чтобы каждая программа хорошо выполняла одну задачу. Чтобы выполнить новую, создавайте заново, а не усложняйте старые программы, добавляя новые «функции».
Несмотря на то, что команды Unix считаются полностью независимыми друг от друга, это не так. Им по-прежнему нужно общаться с другими, и второй принцип определяет, как должны быть спроектированы интерфейсы для коммуникации:
Ожидайте, что выходные данные каждой программы станут входными данными для другой, пока еще неизвестной программы. Не загромождайте вывод посторонней информацией. Избегайте строго столбчатых или двоичных форматов ввода. Не настаивайте на интерактивном вводе.
Не только интерфейс связи строго ограничен (стандартный ввод, стандартный вывод и стандартная ошибка), но в соответствии с этим принципом данные, передаваемые между командами, также должны быть строго ограничены. То есть команды Unix должны предоставлять микроинтерфейсы и никогда не зависеть от деталей реализации друг друга.
А что на счет наносервисов?
Термин «наносервис» часто используется для описания слишком маленького сервиса. Можно сказать, что эти наивные сервисы с одним методом в предыдущем примере - это наносервисы. Однако я не согласен с этой классификацией.
Наносервисы используются для описания отдельных сервисов при игнорировании общей системы. В приведенном выше примере, как только мы включили систему в уравнение, интерфейсы сервисов должны были вырасти. Фактически, если мы сравним исходную реализацию одного сервиса с наивной декомпозицией, мы увидим, что как только мы подключаем сервисы к системе, система переходит с 8 общедоступных методов до 38. Более того, среднее количество общедоступных методов на сервис подскакивает с желаемой 1 до 4,75.
Следовательно, если вместо кодовой базы мы оптимизируем сервисы (публичные интерфейсы), термин «наносервис» перестанет быть актуальным, поскольку сервис будет вынужден снова расти, чтобы поддерживать варианты использования системы.
И это все, что нужно сделать?
Нет. Хотя минимизация публичных интерфейсов сервисов является хорошим принципом для проектирования микросервисов, это все еще просто эвристика и не заменяет здравый смысл. На самом деле, микроинтерфейс - это всего лишь своего рода абстракция по сравнению с более фундаментальными, но гораздо более сложными принципами проектирования связи (coupling) и сцепления (cohesion).
Например, если два сервиса имеют публичные интерфейсы, но их необходимо координировать в распределенной транзакции, они по-прежнему тесно связаны друг с другом.
Тем не менее, стремление к микроинтерфейсу по-прежнему остается сильной эвристикой, которая обращается к различным типам связи, например, таким как функциональная и семантическая. Но это тема для другого блога.
От теории к практике
К сожалению, у нас пока нет объективного способа количественно оценить локальную и глобальную сложности. С другой стороны, у нас есть некоторые эвристики проектирования, которые могут улучшить дизайн распределенных систем.
Основной посыл этого поста заключается в том, что вы должны постоянно оценивать публичные интерфейсы ваших сервисов, задавая следующие вопросы:
Каково соотношение эндпоинтов, ориентированных на бизнес и интеграцию, в данном сервисе?
Существуют ли в сервисе с точки зрения бизнеса несвязанные эндпоинты? Можете ли вы разделить их на два или более сервисов, не вводя эндпоинты, ориентированные на интеграцию?
Приведет ли слияние двух сервисов к устранению эндпоинтов, которые были добавлены для интеграции исходных сервисов?
Используйте эту эвристику для определения границ и интерфейсов ваших сервисов.
Резюме
Я хочу резюмировать все это наблюдением Элияху Голдратта. В своих книгах он часто повторял такие слова:
«Скажите мне, как вы меня оцениваете, и я скажу вам, как я буду себя вести» ~ Элиягу Голдратт
При разработке систем на основе микросервисов очень важно правильно измерить и оптимизировать метрику. Микросервисы предназначены для проектирования систем, а не отдельных сервисов.
И это возвращает нас к названию статьи - «Распутывание микросервисов или балансировка сложности в распределенных системах». Единственный способ распутать микросервисы - это сбалансировать локальную сложность каждого сервиса и глобальную сложность всей системы.
Библиография
Комментарии (8)

zuborg
21.11.2021 12:04+4Простота (как антоним к сложности) системы - это своего рода ресурс, им надо управлять, в частности - экономить (при проектировании), или восполнять (рефакторингом) - потраченные на это время и деньги окупаются при разумном планировании. Недостаток простоты увеличивает цену разработки и поддержки - при критически низком значении это может сыграть фатальную роль.

nApoBo3
21.11.2021 13:32Отдельно управление сложность зависимостей в микросервисах говорит о том, тадам, у вас не микросервисы а распределенный монолит. Можно написать, а где вы эти самые настоящие микросервисы видели то. Да, их в дикой природе практически нет. Просто не надо к распределенным монолитам, которые тоже решают некоторые проблемы, применять теорию "микросервисов", а при переносе практик понимать ограниченность применения. В частности очень четко разделять роли, даже если это один человек, заказчика и поставщика изменений.
И да, если вы сделали большой комок грязи в виде монолита, то вероятно рефакторя их в микросервисы вы получите еще более жуткий комок грязи, просто в силу того, что микросервисы это сложнее монолита, а ваше окружение( ресурсы в самом широком смысле ) и квалификация монолит не осилила.

codefun
21.11.2021 13:51+1ну Uber тоже поморочился чтобы управлять сложностью микросервисов. Не понял суть вашего месседжа. Вы говорите что "это не настоящие микросервисы", но сами признаете что настоящих нигде нет. Тогда выходит что и у Убера вышла какая-то фигня раз они стали заморачиваться как управлять зоопарком?


OhSirius
21.11.2021 22:01Здесь есть проблема с определением стабильных границ между микросервисами - без них сложно получить профит с независимым деплоем частей и не свалиться в распределённый монолит. Если следовать Сэму Ньюману, то нужно начинать с монолитов и по мере стабилизации домена решить, какая конкретно часть в нем применения архитектуры микросервисов. Например увелечение производительности определенного слля или ускорение введения изменений в определенную часть.

kspshnik
22.11.2021 11:17А нет ли в этом уравнении третьей силы - управления сложностью разработки?
Не надо ли это также учитывать?

korsetlr473
а где можно найти интерактивную картинку из поста с сеткой мс ? для создании видео , мб подобные сервисы ктото видел