

Это третья часть серии статей «Мобильная аналитика на Python», в которой рассказывается, как рассчитать ключевые показатели использования приложений с помощью одного лишь Python.
Фрагменты кода, представленные в каждом разделе, и репозиторий GitHub можно найти здесь.
Задача
Сегодня мы будем проводить анализ воронки и вычислять количество/процент пользователей, которые проходят по ее уровням, визуализируя всю конверсию в виде воронки.
Также мы немного расширим код, чтобы иметь возможность создавать сложенные воронки, в которых пользователи будут сгруппированы по определенным свойствам.
Зачем себя утруждать?
Анализ воронки имеет решающее значение для выявления узких мест на любом этапе пути пользователя. Обычно все сводится к ключевому событию, которое и приносит доход бизнесу. То есть, в наших интересах максимально увеличить число людей, выполняющих это действие.
У пользователей бывает множество значимых точек отсева. Визуализация их пути помогает понять, на какой области следует сосредоточиться, чтобы максимизировать конверсию из одной точки в другую.
.")
Что ясно видно из диаграммы выше, так это то, что недостаточно пользователей покупают товар. Кроме того, можно было бы улучшить процесс регистрации, чтобы на этом этапе отсеивалось меньше людей.
Обратите внимание, что максимизация конверсии на этапе непосредственно перед ключевым событием, приносящим доход, может иметь смысл не для всех компаний. Вы можете увеличить общую активность и вовлеченность пользователей, но в конце концов, если у вас много пользователей, которые изучают приложение, но не приносят вам доход, то вы, возможно, сосредоточились не на той области.
Ориентация на пользователей, которые приносят доход, является более стохастическим подходом, и именно поэтому мы будем строить сложенные воронки, которые позволят нам сравнить конверсии разных сегментов пользователей.
")
После изучения воронки выше, несмотря на большое количество неорганических пользователей (выделено синим), становится ясно, что конверсия органических на последних двух этапах выше, с окончательной конверсией 1% в точке покупки для органических пользователей и 0,2% для неорганических (слишком малый процент, чтобы его можно было увидеть на изображении выше. Позже мы сделаем эти графики интерактивными, и всю статистику можно будет визуализировать, наведением курсора на интересующий этап). Если общее число пользователей можно будет считать репрезентативным для всех пользователей, значит, органические пользователи будут приносить больший доход этому бизнесу.
Требования
Python 3 (у меня 3.7)
Pandas: для работы с данными
Plotly: для визуализации
Примечание для Plotly: Вместо него можно было бы использовать matplotlib, но тогда потребуется гораздо больше строк кода, чтобы диаграммы выглядели красиво, все было подписано и интерактивно. Мы будем создавать диаграммы, в которые легко погрузиться и которыми можно поделиться с другими.
Источники/логика
Если вы погуглите, как сгенерировать данные для воронки, то найдете ответы, подобные этому, где в основном предлагают последовательно использовать несколько LEFT JOIN (на SQL). Чтобы за раз сгенерировать данные для воронки с помощью (postgre)SQL, мы могли бы использовать следующий запрос:
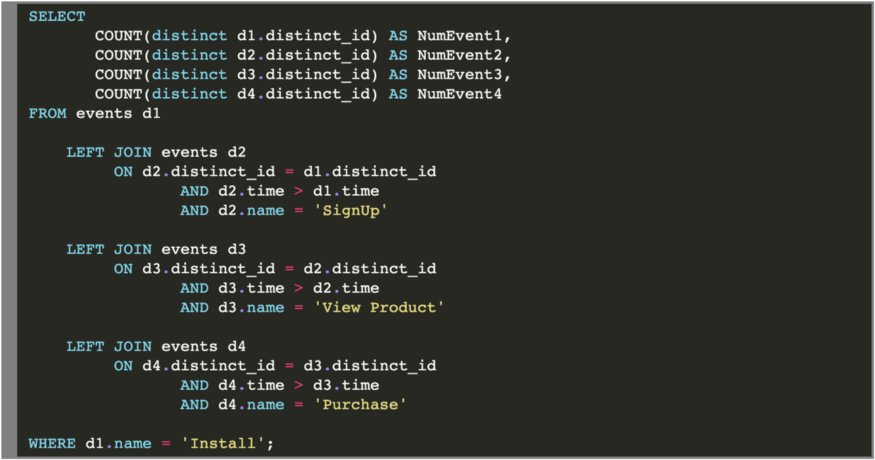
Эту логику мы возьмем за основу при подсчете количества пользователей на каждом уровне воронки, но воспользуемся pandas. Что мы здесь изменим, так это то, что после каждого join мы будем находить минимальное время выполнения события для каждого пользователя и фильтровать для этого DataFrame. Надеюсь, в следующем разделе с наглядной реализацией вы увидите весь смысл.
Код
Код для генерации статистики воронки и диаграммы должен соответствовать следующим требованиям:
Если пользователь учитывается на каком-либо уровне (шаге), то он также должен был пройти все предыдущие;
Для пользователя, который учитывается на любом уровне, время перехода на следующий уровень – это конец предыдущего.
Опционально: Шаг N должен выполняться в течение указанного периода времени после шага N-1.
Опционально: Первый шаг должен выполняться между
from_dateиto_date(фильтрация выполняется только для первого события, подробнее об этом позже).
Сложность анализа воронки заключается в том, что путь пользователя не всегда линейный и однозначный. Что характерно для многих отслеживаемых вами событий, пользователь может выполнить их в любой момент. Например, даже после покупки товара пользователь может вернуться и заполнить или обновить некоторые данные своего профиля.
При анализе воронки мы заинтересованы в том, чтобы выяснить, кто выполнил конкретные шаги, соблюдая при этом порядок/сроки, с которыми они были предприняты.
Методология, которую будем внедрять:
Определите список событий для анализа воронки.
Для первого события найдите минимальное время, за которое пользователь выполняет его.
-
Для любого последующего события:
Сделайте
left joinк DataFrame-ам в столбцеdistinct_id;Для каждого пользователя отфильтруйте только те события, которые произошли после проведения минимального времени на предыдущем шаге;
Для каждого пользователя найдите и отфильтруйте минимальное время прохождения события;
Переходите к следующему событию и повторите все шаги пункта 3.
Определим список всех событий
У нас есть просто список строк, порядок которых коррелирует с порядком событий, отображаемых на диаграмме воронки. Для примера, который мы используем во всем этом разделе, это будет выглядеть так:

2. Для первого события найдем минимальное время, за которое пользователь выполняет его
Для начала нам нужно создать список значений values для определения количества пользователей на каждом уровне.
Затем мы пройдемся по каждому событию в списке steps, и:
Для первого события просто отфильтруйте пользователей, которые прошли этот шаг, и которые сделали это в первый раз.
Для любого последующего события сделайте
left joinи фильтрацию, как описано выше.
Давайте определим список values и структурируем цикл for. Обратите внимание, что мы также определяем словарь dfs для хранения всех отфильтрованных DataFrame-ов каждого шага.
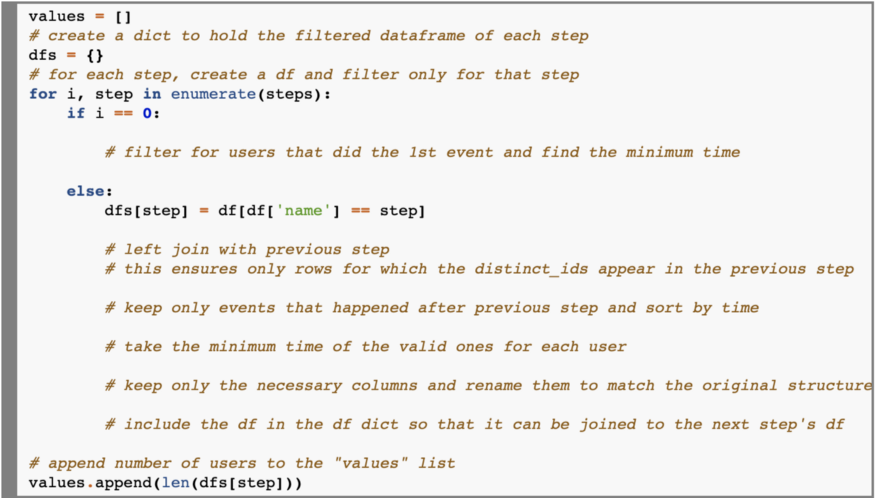
Теперь давайте заполним первую часть цикла, касающуюся первого события:

dfs['Install'] будет выглядеть так:
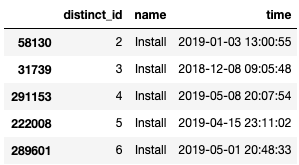
Обратите внимание, что на этом этапе у каждого пользователя будет только одна строка (событие установки), поскольку мы сохранили только первый экземпляр install для каждого пользователя.
3. Left join с каждым последующим событием
Теперь мы можем дописать часть else в цикле для работы с любыми последующими событиями.
Для второго события нам нужно отфильтровать DataFrame этого события и сделать left join с DataFrame-ом из предыдущего шага.

Результат выполнения кода выше будет таким:

По умолчанию суффикс «_x» добавляется к первому DataFrame-у в методе pd.merge(), который соответствует DataFrame-у первого события, а «_y» - второму.
Обратите внимание, что здесь может получаться более одной строки на пользователя, поскольку мы выполнили left join. Количество строк будет соответствовать количеству имеющихся событий SignUp в случае, если у пользователей уже есть событие Install.
Таким образом, теперь нам нужно отфильтровать только те случаи, в которых второй шаг произошел после первого события. Затем можно сохранить только минимальное время для второго события для каждого пользователя из результирующего DataFrame.

Результат выполнения кода выше по-прежнему будет иметь ту же структуру вывода, но теперь каждый пользователь будет встречаться всего один раз (по одной строке на пользователя).
Теперь нам нужно сохранить только столбцы, представляющие текущее событие, и перезаписать dfs[step] полученным DataFrame-ом, чтобы иметь возможность найти отдельных валидных пользователей для следующего шага.

4. Конвертация списка values в DataFrame
Чтобы получить DataFrame воронки, нам просто надо преобразовать список values в DataFrame.
Обратите внимание, что на данный момент нам действительно не нужно создавать DataFrame. Вместо этого мы могли бы передать списки steps и values в функцию отрисовки plotly, но сделаем это здесь для поддержания наглядности.

Итоговый DataFrame выглядит так:

Давайте теперь обернем все в одну функцию:
def create_funnel_df(df, steps, from_date=None, to_date=None, step_interval=0):
"""
Function used to create a dataframe that can be passed to functions for generating funnel plots.
"""
# filter df for only events in the steps list
df = df[['distinct_id', 'name', 'time']]
df = df[df['name'].isin(steps)]
values = []
# for the rest steps, create a df and filter only for that step
for i, step in enumerate(steps):
if i == 0:
dfs = {}
dfs[step] = df[df['name'] == step] \
.sort_values(['distinct_id', 'time'], ascending=True) \
.drop_duplicates(subset=['distinct_id', 'name'], keep='first')
# filter df of 1st step according to dates
if from_date:
dfs[step] = dfs[step][(dfs[step]['time'] >= from_date)]
if to_date:
dfs[step] = dfs[step][(dfs[step]['time'] <= to_date)]
else:
dfs[step] = df[df['name'] == step]
# outer join with previous step
merged = pd.merge(dfs[steps[i - 1]], dfs[step], on='distinct_id', how='outer')
# keep only rows for which the distinct_ids appear in the previous step
valid_ids = dfs[steps[i - 1]]['distinct_id'].unique()
merged = merged[merged['distinct_id'].isin(valid_ids)]
# keep only events that happened after previous step and sort by time
merged = merged[merged['time_y'] >=
(merged['time_x'] + step_interval)].sort_values('time_y', ascending=True)
# take the minimum time of the valid ones for each user
merged = merged.drop_duplicates(subset=['distinct_id', 'name_x', 'name_y'], keep='first')
# keep only the necessary columns and rename them to match the original structure
merged = merged[['distinct_id', 'name_y', 'time_y']].rename({'name_y': 'name',
'time_y': 'time'}, axis=1)
# include the df in the df dictionary so that it can be joined to the next step's df
dfs[step] = merged
# append number of users to the "values" list
values.append(len(dfs[step]))
# create dataframe
funnel_df = pd.DataFrame({'step': steps, 'val': values})
# calculate percentage conversion for each step
funnel_df['pct'] = (100 - 100 * abs(funnel_df['val'].pct_change()).fillna(0)).astype(int)
# shift val by one to plot faded bars of previous step in background
funnel_df['val-1'] = funnel_df['val'].shift(1)
# calculate percentage conversion between each step and the first step in the funnel
funnel_df['pct_from_first'] = (funnel_df['val'] / funnel_df['val'].loc[0] * 100).fillna(0).astype(int)
return funnel_dfМоменты, которые мы добавили в итоговую функцию:
from_dateиto_date: Могут использоваться для фильтрации первого события в случаях, когда оно произошло между этими двумя датами. Мы отфильтровываем только первое события, чтобы правильно посчитать время выполнения пользователями последующих действий. Механика очень полезна при объединении диаграмм воронок с анализом когорт, поскольку пользователям, которые выполнили первое событие ближе к концу данной когорты, должно быть разрешено выполнять следующие действия в следующей когорте, чтобы не выдавать неверные данные.step_interval: Полезная вещь, если мы хотим ограничивать интервал времени между последующими событиями, то есть, например, показывать только тех людей, которые завершилиevent_2в течение 2 часов после завершенияevent_1. Этот интервал должен быть валиднымpd.Timedeltaобъектом.
Визуализация
Поскольку plotly классный, мы воспользуемся им для создания диаграммы воронки. Для создания обычной (не сложенной) диаграммы все что нам понадобится, это:
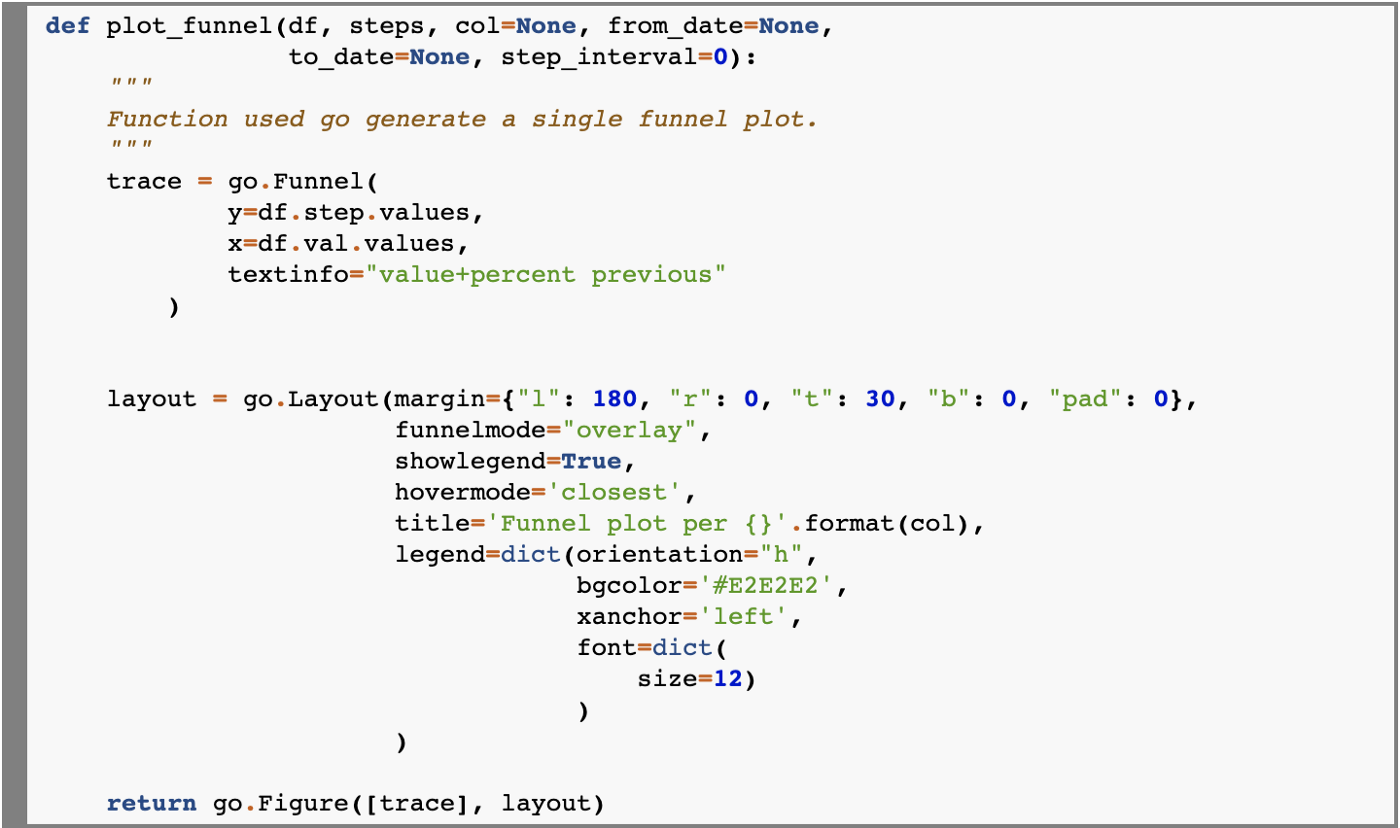
Перед тем, как сделать итоговую функцию построения воронки, давайте сделаем небольшую функцию, которая позволит нам делать сложенные воронки. Хороший способ – вызвать create_funnel_df в цикле for и заполнить словарь DataFrame-ов воронки. В функции построения диаграммы мы пройдемся по этому словарю и сгенерируем по одной трассировке для каждого DataFrame-а.
def group_funnel_dfs(events, steps, col):
"""
Function used to create a dict of funnel dataframes used to generate a stacked funnel plot.
"""
dict_ = {}
# get the distinct_ids for each property that we are grouping by
ids = dict(events.groupby([col])['distinct_id'].apply(set))
for entry in events[col].dropna().unique():
ids_list = ids[entry]
df = events[events['distinct_id'].isin(ids_list)].copy()
if len(df[df['name'] == steps[0]]) > 0:
dict_[entry] = create_funnel_df(df, steps)
return dict_Теперь мы можем создать диаграмму воронки для каждой записи в указанном столбце. Здесь мы будем использовать столбец user_source, чтобы разбить воронки в зависимости от того, является ли пользователь органическим или неорганическим.
Итоговая функция построения диаграммы будет выглядеть так:
def plot_stacked_funnel(events, steps, col=None, from_date=None, to_date=None, step_interval=0):
"""
Function used for producing a (stacked) funnel plot.
"""
# create list to append each trace to
# this will be passed to "go.Figure" at the end
data = []
# if col is provided, create a funnel_df for each entry in the "col"
if col:
# generate dict of funnel dataframes
dict_ = group_funnel_dfs(events, steps, col)
title = 'Funnel plot per {}'.format(col)
else:
funnel_df = create_funnel_df(events, steps, from_date=from_date, to_date=to_date, step_interval=step_interval)
dict_ = {'Total': funnel_df}
title = 'Funnel plot'
for t in dict_.keys():
trace = go.Funnel(
name=t,
y=dict_[t].step.values,
x=dict_[t].val.values,
textinfo="value+percent previous"
)
data.append(trace)
layout = go.Layout(margin={"l": 180, "r": 0, "t": 30, "b": 0, "pad": 0},
funnelmode="stack",
showlegend=True,
hovermode='closest',
title='Funnel plot per {}'.format(col),
legend=dict(orientation="v",
bgcolor='#E2E2E2',
xanchor='left',
font=dict(
size=12)
)
)
return go.Figure(data, layout)А результат получится такой:
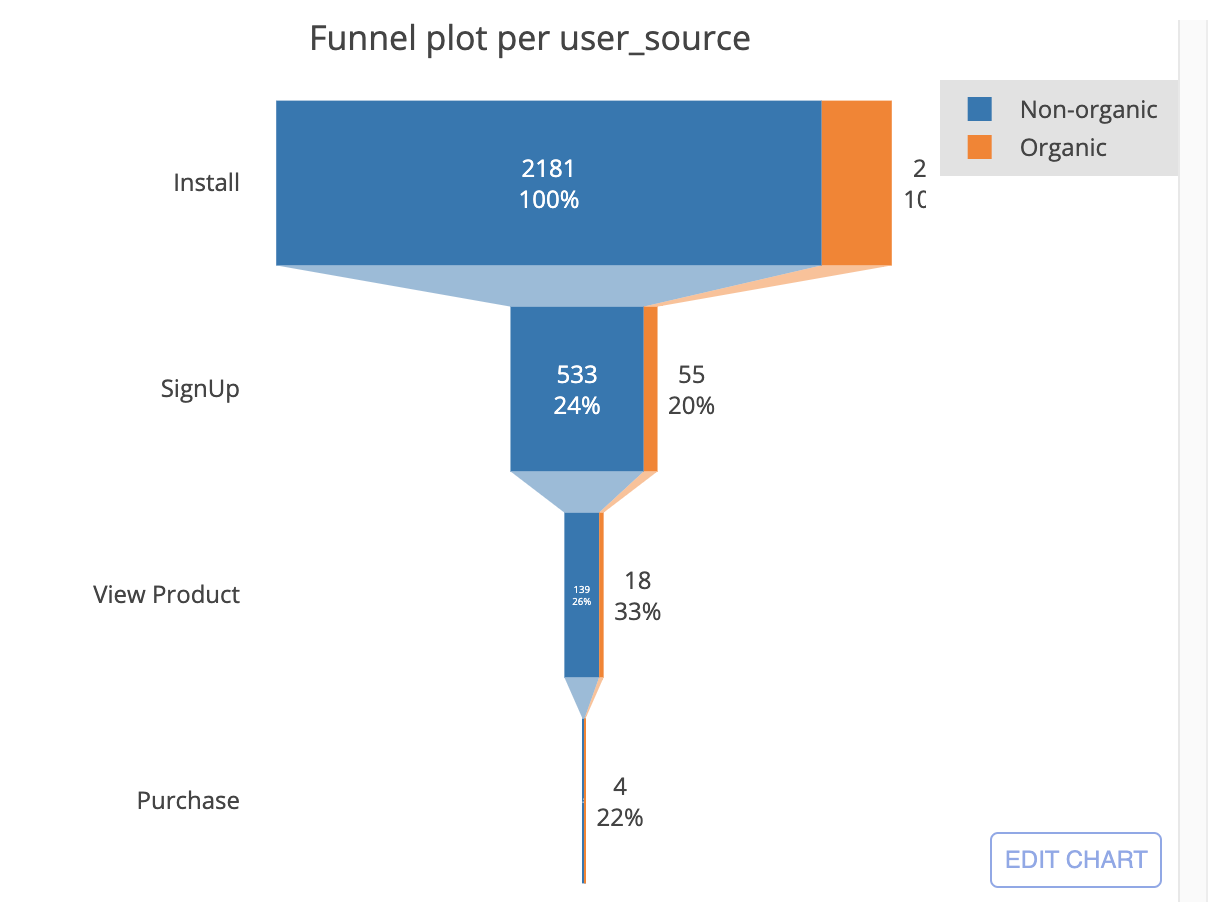
Мы сгенерировали его с помощью:

Здесь мы сохраняем диаграмму только в студии диаграмм plotly, так я ее сюда и встроил.
Репозиторий Github: https://github.com/atsangarides/mobile-analytics
Материал подготовлен в рамках курса «Python для аналитики».
Комментарии (2)

mattroskin
29.11.2021 15:46Насколько ваш алгоритм построения воронки будет эффективен для большого числа событий? Ну, скажем, у нас 1млн новых клиентов в день, глубина воронки - 10 событий, и типичное время от инстала до конверсии - несколько дней.
todoman
Скажите, пожалуйста: у вас в примерах визуализации цифры из жизни или совсем "от ума"? Без подкола спрашиваю. 8 человек из 2 с половиной тысяч инстоллеров совершили покупку? Всего 0,3%? Это нормальная цифра для контента? Я удивлен.