
В 2019 году наша площадка для поиска сотрудников и подбора вакансий стала частью экосистемы Сбера. Сразу после этого мы получили доступ к спектру партнерских сервисов, смогли расширить свой технологический стек, штат разработчиков и запустили ряд новых продуктов.
Первое время мы строили решения на собственной «железной» инфраструктуре с LXC-контейнерами. Но мы довольно быстро обнаружили, что она перестала справляться с нагрузкой и только тормозила развитие. Чтобы исправить ситуацию, мы перешли в облако SberCloud.Advanced. Сегодня покажу, как выглядит наша инфраструктура, и как мы ей управляем. Также расскажу об инструменте для сontinuous deployment (CD) в Kubernetes — Helmwave.
Всех заинтересовавшихся приглашаю под кат.

Первый и второй вариант инфраструктуры
Еще до миграции в облако, мы приняли ряд базовых решений. Во-первых, остановили свой выбор на Kubernetes, так как у команды уже были соответствующие наработки. Во-вторых, сделали упор на автоматизацию и такие подходы как Infrastructure-as-Code (IaC) и Don’t repeat yourself (DRY). Первый позволяет управлять инфраструктурой с помощью конфигурационных файлов, а второй — предлагает бороться с дублированием кода и грамотнее задействовать готовые модули.
Также мы понимали, что нам необходимо уделять как можно большее время проектированию собственных продуктов, и не тратить его на администрирование сервисов. Этими мыслями мы поделились с коллегами, которые предложили протестировать SberCloud.Advanced. На этой платформе уже были развернуты все нужные нам решения — PostgreSQL, RabbitMQ, Elasticsearch, Terraform и Kubernetes-as-a Service (CCE).
Однако первый вариант нашей инфраструктуры был далек от идеального, и его пришлось модифицировать. Общая схема выглядела следующим образом:

Мы оставили legacy-платформу на своем железе (baremetal). На ней был развернут мониторинг и системы хранения логов — создавать их с нуля не было смысла. В облаке мы развернули виртуальный ЦОД (VPC) с двумя подсетями: для среды разработки и production. В каждой «крутились» свои сервисы — в частности, Kubernetes, PostgreSQL, RabbitMQ — с раздельными NAT Gateway и белыми IP-адресами. Виртуальные серверы и baremetal связали через VPN.
В теории все выглядело хорошо, но на практике мы столкнулись с проблемами. Каждый VPC в нескольких проектах имел ограничение по количеству NAT — не более десяти штук. В то же время пропускная способность VPN не превышала 300 Мбит/с, что мешало работать с бэкапами. Передача резервных копий занимала всю сеть, и это негативно сказывалось на работоспособности сервисов в ночные часы.
Тогда мы обратились в поддержку SberCloud и коллеги предложили варианты для оптимизации. Они обратили наше внимание на «Проекты». Это подаккаунты, которые можно создавать для отдельных продуктов в облаке. Мы решили воспользоваться этой функцией и сформировали два основных проекта: под систему управления инфраструктурой и под сервисы Rabota.ru. Внутри последнего проекта мы запустили два виртуальных ЦОДа — для production и разработки. Чтобы повысить сетевую доступность, мы подняли третий проект — Main. Там «крутился» еще один VPC, к которому подключались остальные. Так, все наши проекты могли без проблем общаться друг с другом в пределах сетевых политик безопасности.
Cхема выглядит следующим образом:
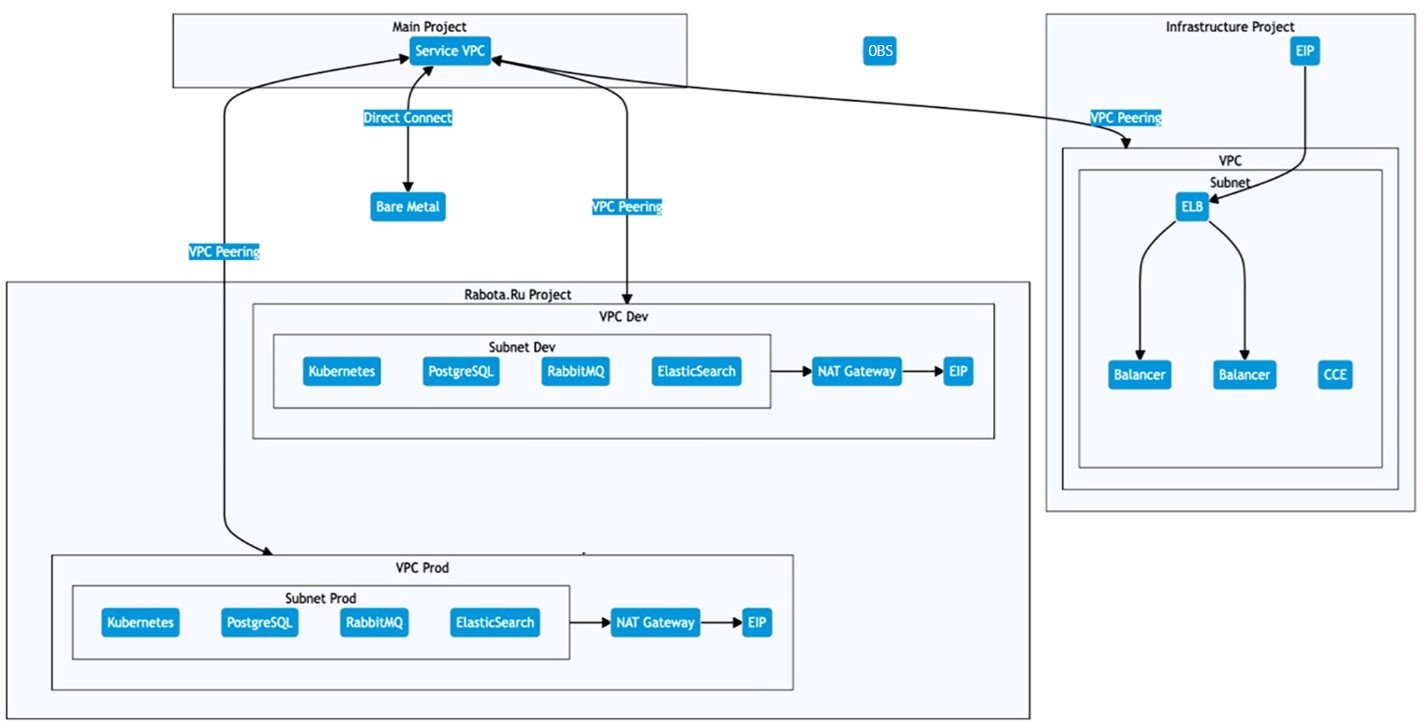
Вместо VPN коллеги из SberCloud протянули оптоволокно от нашей железной инфраструктуры до облака — организовали так называемый Direct Connect. По итогу, вместо 300-мегабитного канала у нас появился 10-гигабитный. Впоследствии для повышения надежности были проложены резервные линки.
Миграция на этот вариант инфраструктуры прошла почти без приключений. Основной проблемой стал перенос stateful-приложений с блочных дисков. Нам пришлось потратить время на копирование их бэкапов. Также процесс работы тормозила необходимость регулярно увеличивать квоты на ресурсы проектов.
Как мы автоматизировали управление
Основу составила методология Infrastructure-as-Code. Реализовать её на практике мы решили с помощью SberCloud Terraform Provider, который позволяет разбить инфраструктуру на модули и управлять ими с помощью файлов конфигурации.
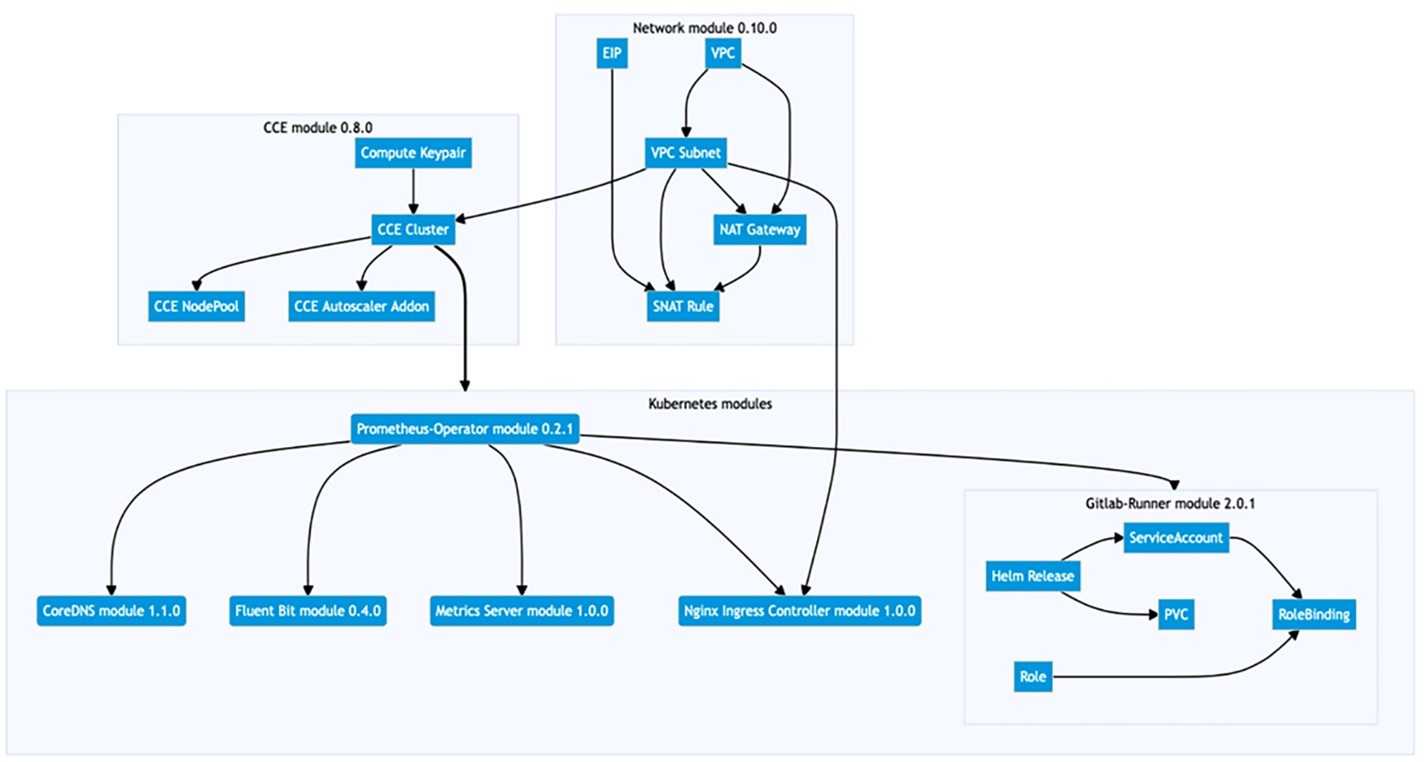
Одним из ключевых компонентов нашей системы стал сетевой модуль (network module). Он отвечает за настройку EIP, VPC и NAT. Также мы выделили CCE-модуль для развертки кластеров K8s и специальные блоки для инициализации мониторинга и других инструментов внутри кластеров. Все компоненты Terraform запускаются в кластере Kubernetes с автоматическим масштабированием — так мы можем оперативно подключать и отключать дополнительные мощности.
Вы могли заметить, на схеме каждый модуль имеет свою версию. Она помогает понять, что происходит с различными компонентами системы, в том числе и в процессе автоматизации. Мы используем методологию semver, или семантическое версионирование. Поэтому версия состоит из трех частей:
Мажорная — увеличивается, когда изменения обратно несовместимы;
Минорная — если добавлена функциональность с обр. совместимостью;
Патч — при внесении небольших обратно совместимых исправлений.
Покажем, как это работает на примере модуля gitlab-runner:
module "gitlab-runner" {
source = "git::https://git.rabota.space/infrastructure/terraform/modules/gitlab-runner.git?ref=0.7.2"
providers = {
kubernetes = kubernetes
helm = helm
}
gitlab-tags = [var.environment-name, var.cluster-name]
gitlab-runner-token = "***"
pvc-storage-class = "csi-nas"
}Здесь указан источник (source), откуда можно скачать модуль. В данном случае им является наш репозиторий на GitLab. В конце пути прописан аргумент ref, обозначающий git-тег.
Первое время при написании модулей мы использовали CI-пайплайн, состоящий из трех шагов:
Проверка синтаксиса (линтинг);
Генерация git-тега согласно правилам semver;
Заполнение журнала изменений проекта.
Непосредственно в GitLab все это выглядело достаточно просто. В интерфейсе было всего три кнопки: сгенерировать патч, минор или мажор.

Сейчас мы тестируем новый пайплайн, в котором нажимать кнопки нет необходимости. В дополнение к semver мы добавили conventional commits. Сочетание двух подходов позволяет нам автоматически генерировать версии при добавлении коммитов.
Мы также использовали специального бота на основе Renovate, который просматривает актуальные версии модулей, сравнивает их с установленными и предлагает разработчикам обновления. Он даже понимает состояние merge-запроса, и, если тот закрыт, бот перестает его мониторить. Мы пробовали использовать DependaBot, но тогда у него не было поддержки Terraform, поэтому остановились на Renovate.
Вот пример для релиза версии 0.7.2:
Сразу после отправки коммита, бот формирует merge-запрос на обновление в соответствующем terraform-модуле. Он также скомпилирует информацию о версии и приложит к ней список изменений. Так, разработчики даже на разных проектах быстро поймут, что изменилось.

К слову, для работы с Terraform у нас также проработан CI из трех этапов:
Проверка синтаксиса с помощью команд terraform fmt и terraform validate;
Получение плана изменений командой terraform plan;
Применение плана с помощью terraform apply.
В интерфейсе GitLab этот алгоритм выглядит вот так:
Как мы уже говорили, в наших проектах чаще всего развернуты сразу два окружения. Пайплайн учитывает эту особенность, поэтому операции применяются сразу для production и разработки.
В итоге нам удалось построить инфраструктуру, в которой мы можем автоматически создавать и модифицировать сервисы по CI. Мы разбили ее на блоки в виде terraform-модулей и сделали их автоматические версионирование. В основе этих решений лежит методология IaC, которую мы называем «Что в коде, то и на проде». Теперь нам достаточно взглянуть на код, чтобы понять, какие развернуты приложения. В дополнение к этому мы запустили бота, который снимает с DevOps-команды довольно обширный пласт задач — теперь нам не нужно вручную напоминать разработчикам обновить сервисы.
Как мы автоматизировали развертывание
Первая версия CI/CD, автоматизирующего развертку приложений, была проработана не лучшим образом. В основе лежал helm2, при этом мы вручную собирали большое количество образов с программными инструментами, не имеющими отношения к пайплайну. В результате созданные нами CI-шаблоны подходили только для одного, самого крупного, проекта, что не позволяло оперативно вносить новую функциональность. Приходилось писать CI по ночам, чтобы не мешать разработчикам, и работать с отдельными CI-пайплайнами.
Перед миграцией инфраструктуры в облако SberCloud мы поставили себе цель — исправить ситуацию. Мы решили, что проработаем политики безопасности, «переедем» с helm2 на helm3 и ускорим внедрение изменений (желательно, одним коммитом). В ходе обсуждения мы пришли к выводу, что хотим управлять CI-шаблонами из отдельного репозитория, чтобы развести задачи DevOps и задачи разработчиков, а также оперативно масштабировать production-кластеры до нужного объема. Расскажем, как мы реализовали эту идею на практике.
Сформировали репозитории. Первым стал главный репозиторий /SRE. Внутри него хранится целое дерево репозиториев: ci для шаблонов проектов, helmwave для конфигураций инфраструктурного кластера и helm-charts для публичных пакетов helm. Что касается папки terraform, то она хранит все terraform-модули.

Аналогичная структура была сформирована для каждого продукта, только в неё были добавлены сервисы api и frontend.

Оформили дерево зависимостей CI/CD. Для этой задачи мы выбрали трехслойную модель. Основной репозиторий ссылается на блок iac/ci, который, в свою очередь, обращается к папкам со всеми шаблонами (написаны на YAML) из нашего «магазина шаблонов», в котором хранятся пресеты для бота, terraform-магазин и магазин CI-шаблонов.
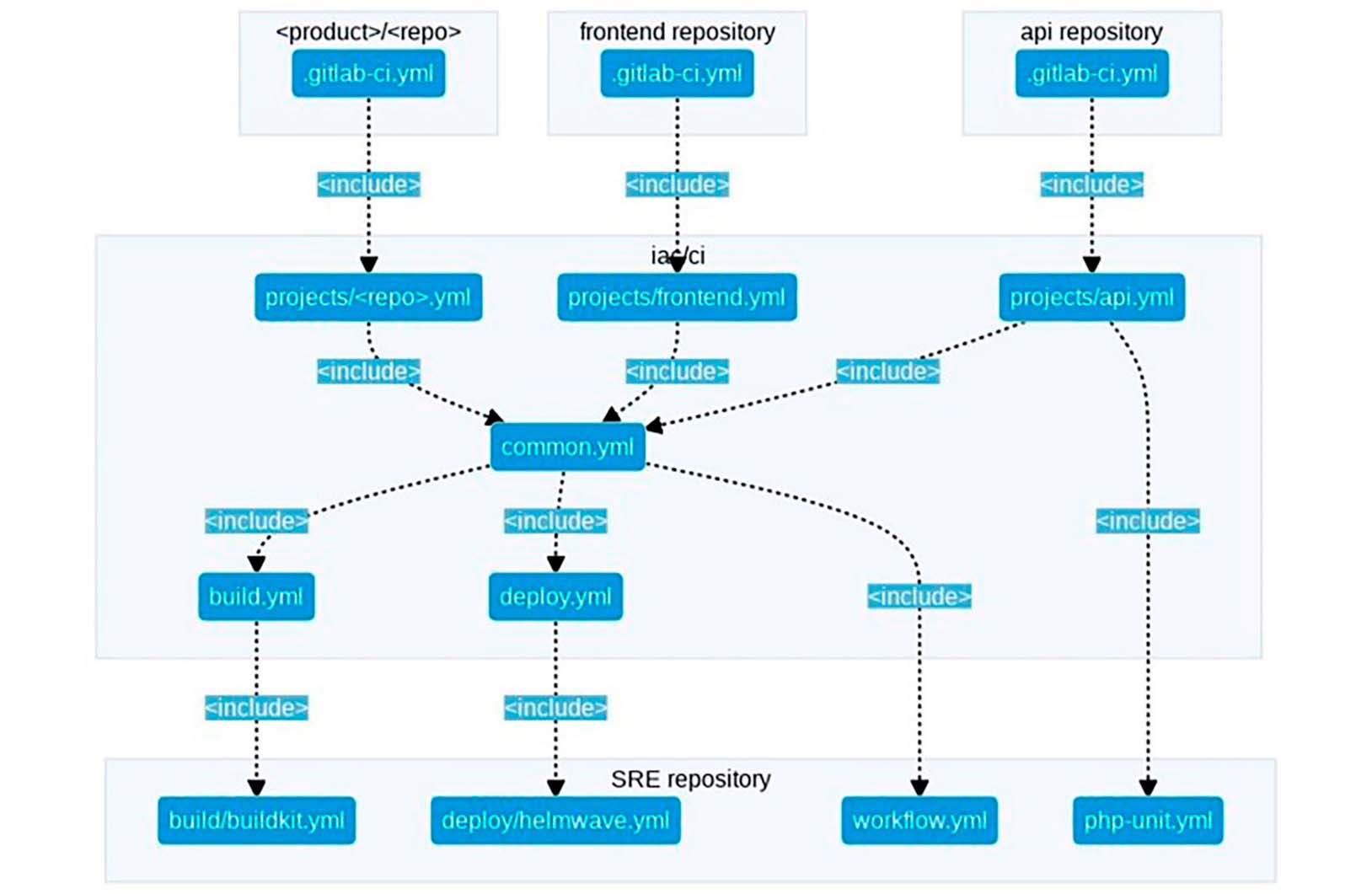
Теперь мы можем перейти в наш api-сервис, создать для всех сервисов одинаковый шаблон .gitlab-ci.yml и управлять пайплайном одного репозитория из другого репозитория. Так, мы не мешаем разработчикам и спокойно обновляем сервисы. Шаблон состоит всего и трех строк:
include:
- project: $CI_PROJECT_ROOT_NAMESPACE/iac/ci
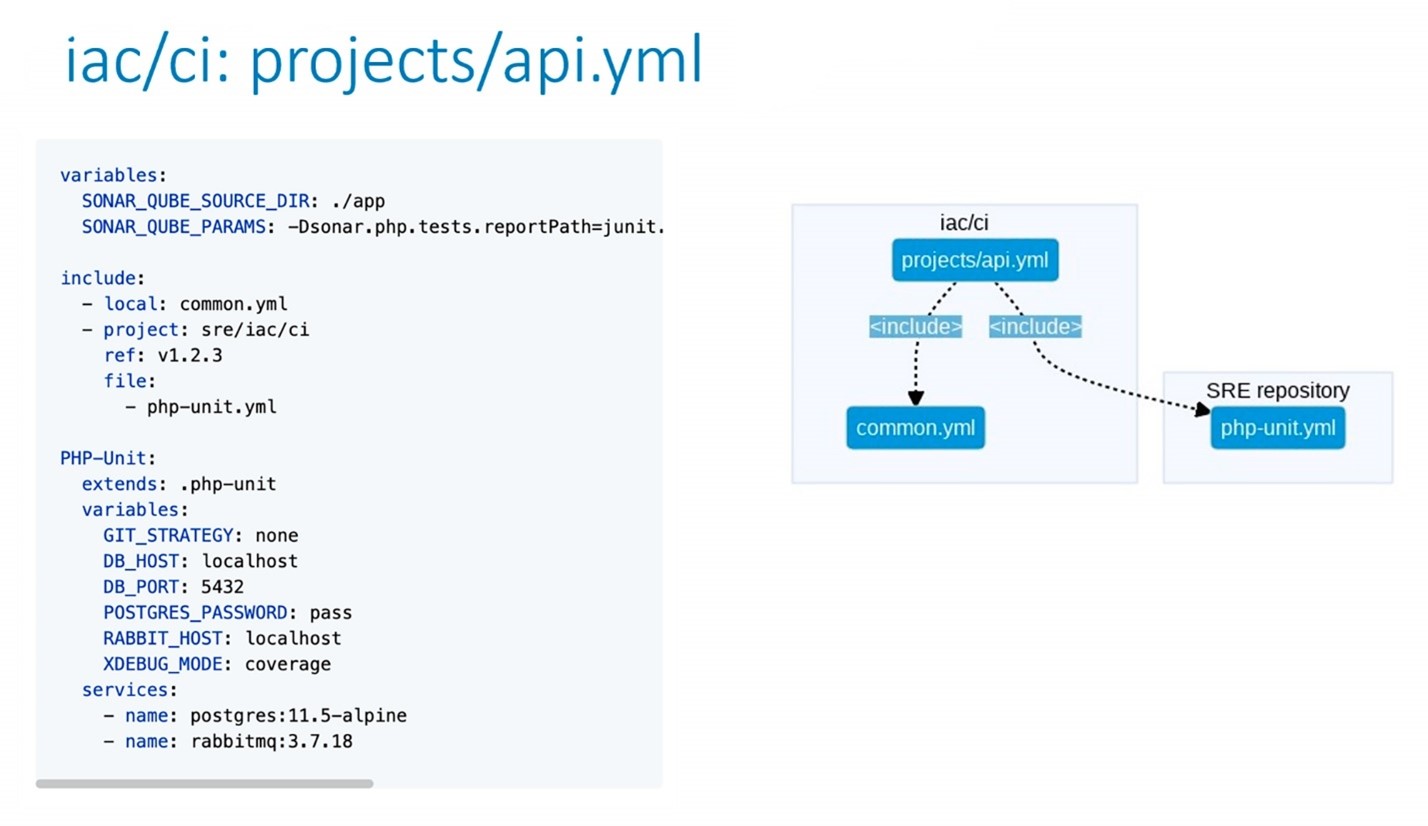
file: projects/$CI_PROJECT_NAME.ymlОписали структуру отдельных шаблонов. В шаблоне api.yml мы подключаем функцию php-unit, реализующую unit-тестирование для php. С её помощью мы расширяем и переопределяем под наши сервисы с помощью директивы extend. Также в коде можно увидеть упоминание common.yml — он будет участвовать во всех проектах.
В самом common.yml мы подключаем workflow.yml, который отвечает за workflow-разработки, включение и отключение merge-квестов, включение и отключение пайплайнов на merge-квестов, и можем подключить дополнительные функции — нотификации в Rocket.Chat, SonarQube, линтер для докер-файлов hadolint или gitleaks для сканирования репозиториев (но сейчас они закомментированы). В этом же репозитории лежат два локальных файла: docker-build.yml и helmwave.yml — их содержимое вынесено в отдельные документы, чтобы не нагромождать common.yml.
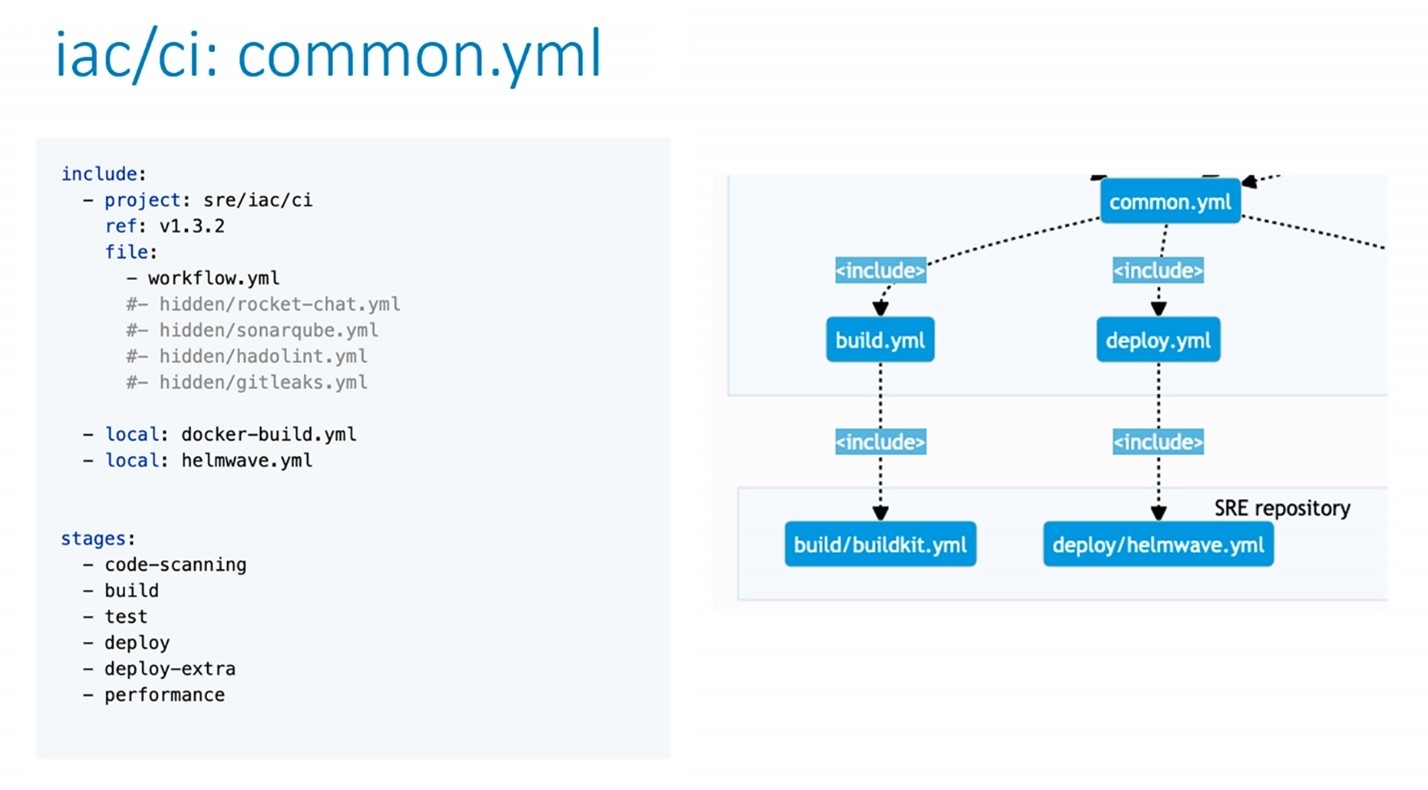
Docker-build.yml просто сообщает системе, что нам нужен runner для сборки docker-образов.

Что касается helmwave.yml, то в нем мы инициализируем runner с правами на развертку приложений, создаем задачу на его остановку и устанавливаем время жизни окружения на семь дней (auto_stop_in). Самое важное, что мы определяем в этом файле — это образ для развертки CI_Project_Root_Namespace/helmwave.

Протестировали CI. У нас сформировалось большое количество шаблонов. Для их тестирования мы проводили линтинг CI с помощью CI. Для этих целей мы разработали специализированные шаблоны. В тестировании нам также помогает методика semver и Renovate-бот.
Настроили gitlab-runner. Мы управляем кластером с помощью kubernetes executor. Через сервис-аккаунт он умеет обращаться в kubeapi, что позволяет нам модифицировать настройки кластера через gitlab-runner — нет необходимости делать это вручную. Gitlab-runner прикреплён к группе GitLab, для которой присваиваем теги docker, k8s и название продукта. Дополнительно разворачиваем PVC для кеша.

Несмотря на всю автоматизацию, мы все же сталкиваемся с некоторыми недостатками gitlab-ci. Первый из них — нам не хватает шаблонизатора для пайплайна. Мы пробовали работать с JSON, но тогда размер шаблона превышал размер итогового файла. Также GitLab не имеет пула готовых контейнеров для исполнения. Часто возникают ситуации, что новые директивы gitlab-ci идут вразрез со старыми, что приводит к необходимости переделывать некоторые шаблоны вручную. Также стоит отметить проблемы интеграции с helm и сложности передачи переменных между выполняющимися задачами.
Что такое Helmwave и что он умеет
Helmwave — это наш инструмент для сontinuous deployment в Kubernetes, который по своей функциональности напоминает утилиту Docker Compose для совместной работы с многоконтейнерными приложениями. Еще его можно описать как YAML с настройками релизов. На основе специальных шаблонов он настраивает helm-репозитории, а затем устанавливает в них релизы. К списку преимуществ Helmwave можно отнести высокую скорость работы, возможность параллельной установки релизов и их тегирование, а также поддержку kubedog и templating values. Документацию к проекту вы можете прочесть на GitHub.
Структура репозитория. Helmwave задумывался как максимально гибкий инструмент, поэтому мы разработали для него такую структуру репозитория, чтобы он охватывал как можно больше сценариев работы. Эта структура выглядит следующим образом:

Вы можете видеть, что мы делим все helm-релизы на две крупные категории — инфраструктурные и продуктовые. В верхней части структуры мы инициализируем helwave.yml.tpl — это главный файл Helmwave с репозиториями, необходимыми для установки того или иного релиза. Внутри файла мы обозначаем имя проекта и версию Helmwave:
# vim: set filetype-yaml:
{{- $env := env "CI_ENVIRONMENT" | default "_" }}
{{- $ns := requiredEnv "HELM_NS" }}
project: {{ env "CI_PROJECT_ROOT_NAMESPACE" }}
version: 0.9.6
repositories:
- name: bitnami
url: https://charts.bitnami.xom/bitnami
- name: cetic
url: https://cetic.bitnami.xom/helm-chartsУстановка инфраструктурных релизов. О том, что идет установка именно инфраструктурных релизов, в helwave.yml.tpl сигнализирует блок tags. Блок values определяет, какие части инфраструктуры будут обновлены. Строку values/infrastructure/{{ $v | get "name" }}/_.yml с нижним подчеркиванием используем для всего релиза, а строку values/infrastructure/{{ $v | get "name" }}/{{ $env }}.yml — для конкретного окружения.

Значения полей name, repo, version мы читаем (с помощью readFile) из документа в директории vars/infrastructure.yaml. Он оформляется в свободном ключе, главное учесть форматирование при считывании значений. У нас он выполнен в таком виде:
releases:
- name: postgresql
repo: bitnami
version: 10.3.13
- name: adminer
repo: cetic
version: 0.1.5
- name: rabbitmq
repo: bitnami
version: 7.6.6
- name: ns-ready
repo: charts
version: 0.1.1К слову, наш бот умеет читать этот файл и обновлять версии релизов.
Установка продуктовых релизов. В этом случае тег меняется на product, а значений в поле values становится больше.

Соответствующий документ vars/products.yaml оформлен по аналогии с документом для инфраструктурных релизов. Только в поле path мы указываем gitlab-ci.project.path.
releases:
- name: frontend
path: <product>/frontend
- name: api
path: <product>/apiБольшое количество значений values позволяет нам гибко определять релизы как для всей среды, так и для отдельных приложений. Давайте представим, что мы хотим развернуть api-приложение в среде разработки. Релиз первым делом попадет в стандартную группу values, а затем перейдёт в _/_.yml — это values который работает на все приложения и на все окружения. Затем он проследует в _/dev.yml, который предназначен только для dev-окружения и уже оттуда попадет в необходимый dev/api.yml. Цепочку зависимостей можно представить следующим образом:

Также в нашем репозитории есть необязательные папки /scripts и /charts. В первой лежат вспомогательные скрипты, которые вызываются внутри шаблонов и нужны при проведении CI или тестов. Вторая содержит локальные пакеты helm, необходимые для каждого проекта Helmwave.
Docker-файл. В конечном счете мы написали небольшой Docker-файл для быстрой развертки приложений. К Docker Hub мы подключаемся с помощью прокси-кеша через Harbor. В публичный образ Helmwave помещаем все исходники и устанавливаем дополнительные пакеты — в примере ниже мы загружаем jq.
FROM harbor.tabota.space/dockerhub/diamon/helmwave:0.11.0
RUN apk –no-cache add jq \
&& mkdir -p /root/.config/helm/ \
&& touch /root.config/helm/repositories.yaml
WORKDIR /opt/helmwave
COPY . ..helmwave-depoly:
stage: deploy
image:
name: $CI_REGISTRY/$CI_REGISTRY_ROOT_NAMESPACE/helmwave
entrypoint: [""]
before_script:
- mkdir -p /root/.config/helm/ && touch /root/.config/helm/repositories.yaml
script:
- cd /opt/helmwave
- helmwave deployПлощадка GitLab не поддерживает работу с циклами, поэтому у нас возникли сложности с запуском большого количества приложений в четырех окружениях — production, stage, release, dev. Мы решили проблему с помощью тегов Helmwave. Например, когда мы хотим установить приложение .api, то можем указать сразу четыре релиза — ns-ready, api, rabbitmq и postgresql (это видно в строчке HELMWAVE_TAGS). Если нужно развернуть приложения в другом окружении, то мы просто создаем задачу и с помощью параметра extends добавляем необходимые среды (api to dev).

Такой подход позволяет разработчикам быстро запустить нужный сервис в своей ветке и провести тесты.
«Режим доверия». Когда наши разработчики освоились с новым CI-пайплайном, то попросили дать им возможность самостоятельно настраивать helm-пакеты для отдельных репозиториев. Тогда мы добавили в файл vars/products.yml параметр repoHasChart. С помощью переменной CI_PROJECT_PATH определяем проект и проверяем, может ли разработчик получить доступ к helm-пакету. Если все в порядке, то мы просто подменяем стандартный путь к нему (в docker-образе) на тот, что лежит в репозитории разработчика.

Дополнительные «плюшки». Мы разработали специальный helm-пакет NS-Ready для подготовки NAMESPACE в среде Kubernetes. Он устанавливается самый первый и отвечает за первичную настройку лимитов, квот, секретов, а также политик RBAC и сервис-аккаунтов. В первую очередь RBAC удобен для разработчиков – они смогут получить токен, и с его помощью подключиться к своему приложению через telepresence.
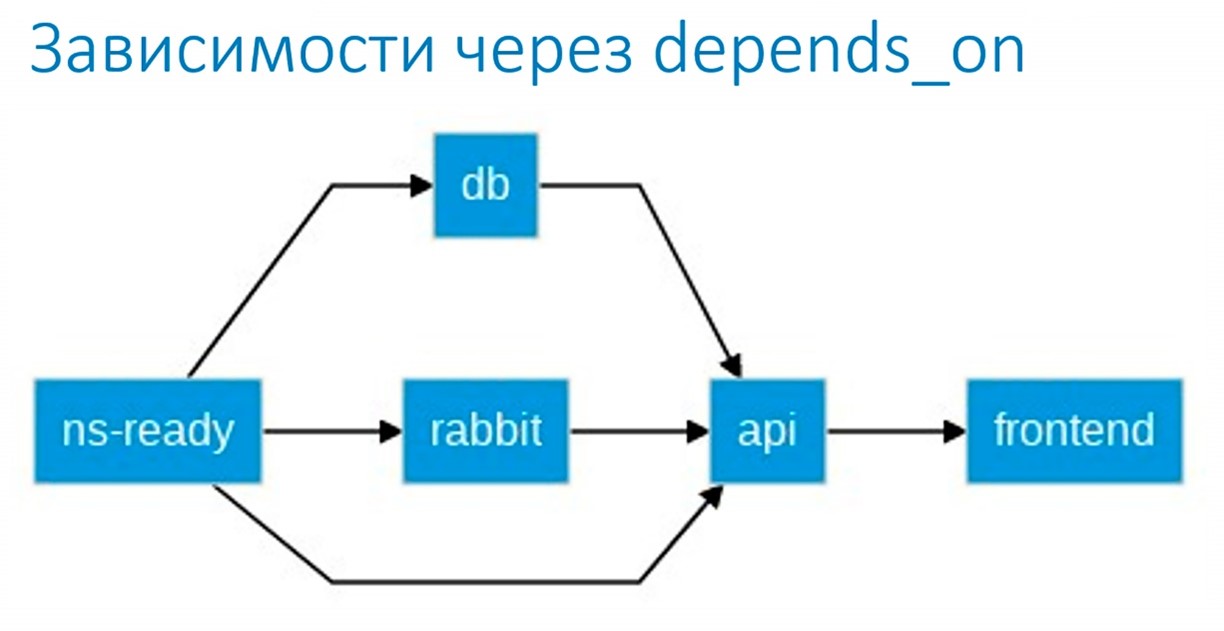
По умолчанию helm не умеет работать с зависимостями depends_on. Мы реализовали его в Helmwave, так как у нас часто возникала ситуация, когда нужно последовательно развернуть среды и приложения (сперва RabbitMQ, затем api, а уже после — frontend).
Также мы работаем с Kubedog. Это написанная на Go библиотека для мониторинга ресурсов Kubernetes и сбора логов. Инструмент полезен при развертывании, так как мы можем в прямом эфире просматривать логи и отлавливать ошибки — например, при развертке четырех приложений окно Kubedog будет выглядеть вот так:

Что в итоге
Финальный CI/CD-пайплайн включает в себя серию линтингов и сканирование кода на безопасность. Затем идут юнит-тесты, сборка Docker-образа и развертка. Разумеется, проводятся и интеграционные тесты. Об этом подробнее можно почитать в моей статье на Хабре про идеальный пайплайн в вакууме.
Когда мы перешли на новый пайплайн, первое время разработчики привыкали к нему. Но потом семантическое версионирование (semver) упростило процесс обновления сервисов. Сейчас все процессы занимают гораздо меньшее время.
Облачные сервисы SberCloud помогли нам успешно реализовать проект. Мы развернули порядка пятнадцати кластеров Kubernetes с автомасштабированием. Также мы активно используем балансировщики нагрузки, которые управляют трафиком сервисов внутри кластеров, и облачные NAS. С помощью последних переносили блочные устройства во время миграции на новую инфраструктуру.
Кроме того, техподдержка провайдера помогает нам быстро справляться с нестандартными ситуациями — например, в какой-то момент мы по ошибке запустили несколько тысяч подов Kubernetes, с которыми не справился мастер-сервер. Мы передали всю информацию техническим специалистам SberCloud, и они помогли нам вернуть кластеры в работу — ошибку исправили с помощью NS_READY, настроив квоты и лимиты. Подобного рода вещи снимают с нас вопросы администрирования вычислительных ресурсов, и мы можем сконцентрироваться на разработке собственных продуктов.
Больше о работе в облаке: