
С каждой новой версией Veeam ONE круг его пользователей становится все шире, а его новые возможности все более привлекательными. Так, системных интеграторов версия v11a порадовала превью новых эндпойнтов для RESTful API (об этом мы писали здесь). Сегодня посмотрим на старые и новые отчеты, которые, по мнению специалистов Veeam, достойны составить “горячую десятку” для провайдеров облачных услуг (Veeam Cloud Service Providers, VCSP) - а по-моему, и не только для них, но и вообще для IT-администраторов.

Отчеты о состоянии виртуальной инфраструктуры
Вот, например, с чего начать расследование жалобы пользователя на производительность виртуальной машины?
Как вариант - запустить отчет Undersized VMs. Вполне вероятно, он покажет, что для пользовательских задач не хватает выделенных ресурсов - и дальше уже вступит в дело отдел продаж.
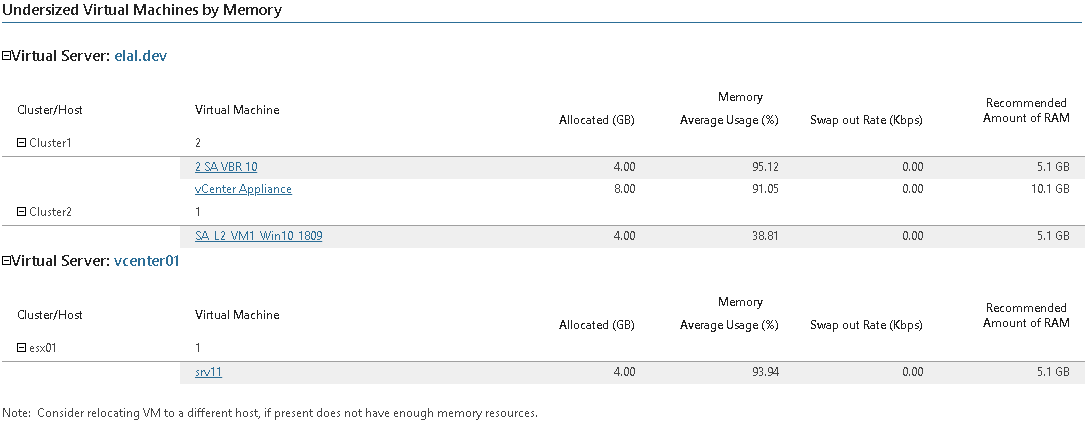
Но может быть и наоборот - то есть виртуалкам выделено слишком много вычислительных мощностей. Такие машины покажет отчет Oversized VMs. А вы согласно его данным сможете оптимизировать использование ресурсов: изменить настройки vSphere, перенести ВМ на менее мощные хосты или спокойно добавить в пул ресурсов еще несколько машин.
Затем стоит посмотреть на отчет Guest Disk Free Space.
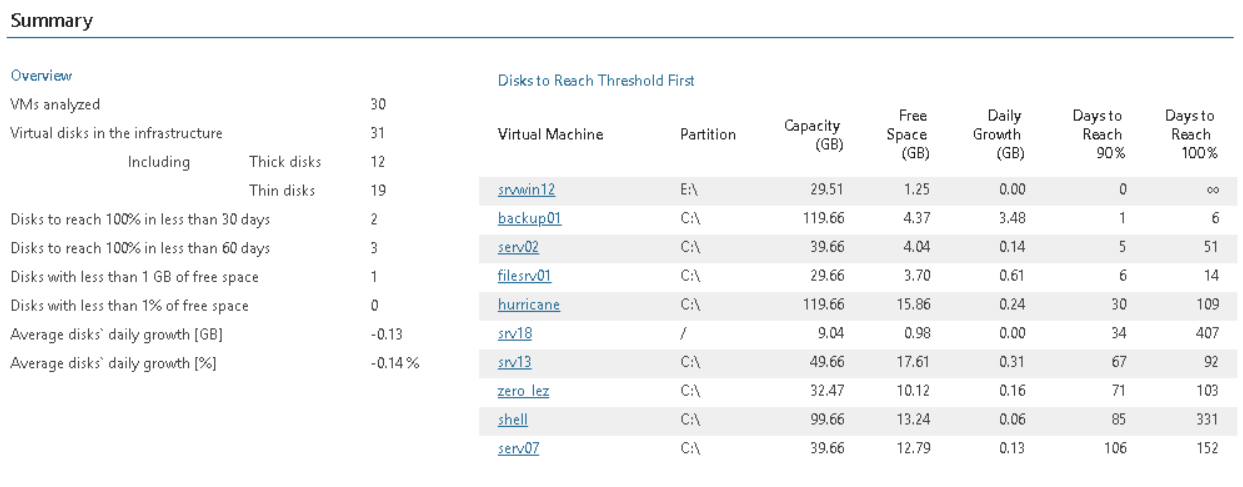
Он покажет, для каких ВМ заканчивается пространство на диске, включая информацию о том, сколько дней осталось до того момента, как будет занято 100% места (ну или не все 100%, а то критичное для вас значение, которое вы выставили в параметрах отчета - на примере ниже это 90%).
Конечно, у нас есть и встроенное оповещение мониторинга Guest disk space, которое сообщит о том, что место на диске гостевой ОС заканчивается. Но оптимально все же настроить периодическую генерацию этого отчета, чтобы быть в курсе трендов и заранее выявлять проблемные места, не дожидаясь шквала претензий от недовольных клиентов.
Отчеты про снэпшоты
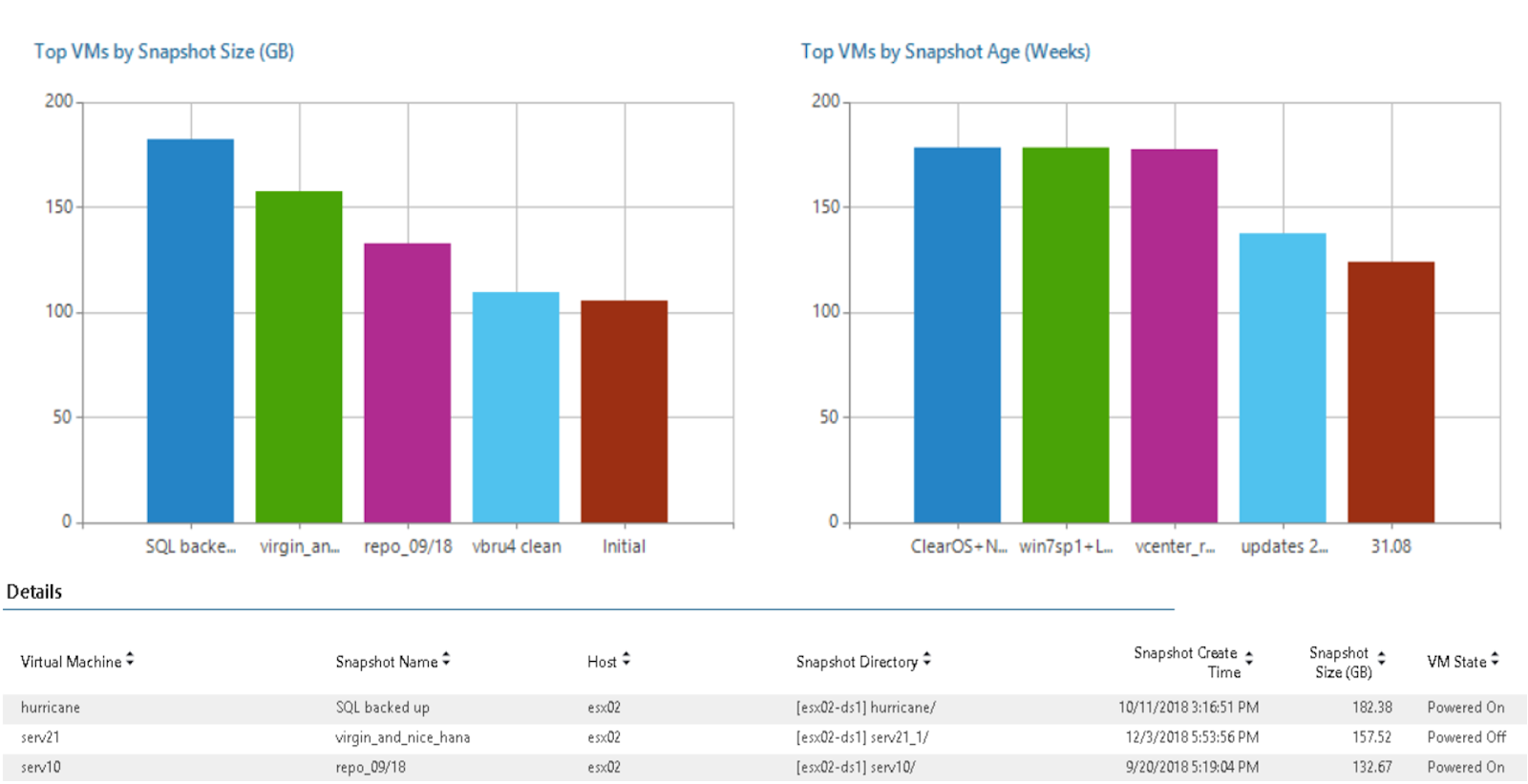
Как известно, головная боль, вызываемая снэпшотами, связана с тем, что их не удаляют после использования. В Veeam Backup & Replication уже давно обзавелись “охотником за снэпшотами” (подробно мы писали о нем здесь) - но так поступили не все, и есть смысл время от времени запускать отчет Orphaned VM Snapshot. Он покажет все снэпшоты, которые не видны в Snapshot Manager, включая и те, которые оставил за собой какой-либо программный продукт. По итогам можно будет оптимизировать пространство на диске.
А для оценки инфраструктуры клиента очень подойдет отчет Active Snapshots - он позволит оценить размеры имеющихся снэпшотов и выявить самые старые и, возможно, уже ненужные пользователям:
Анализ потребления и планирование ресурсов для виртуальных машин
Для этой цели может пригодиться отчет VM Change Rate Estimation. Он позволяет проанализировать изменения объема данных на виртуальном диске и выяснить, например, в какой момент началась атака вируса-шифровальщика (да минует сия напасть вашу инфраструктуру)
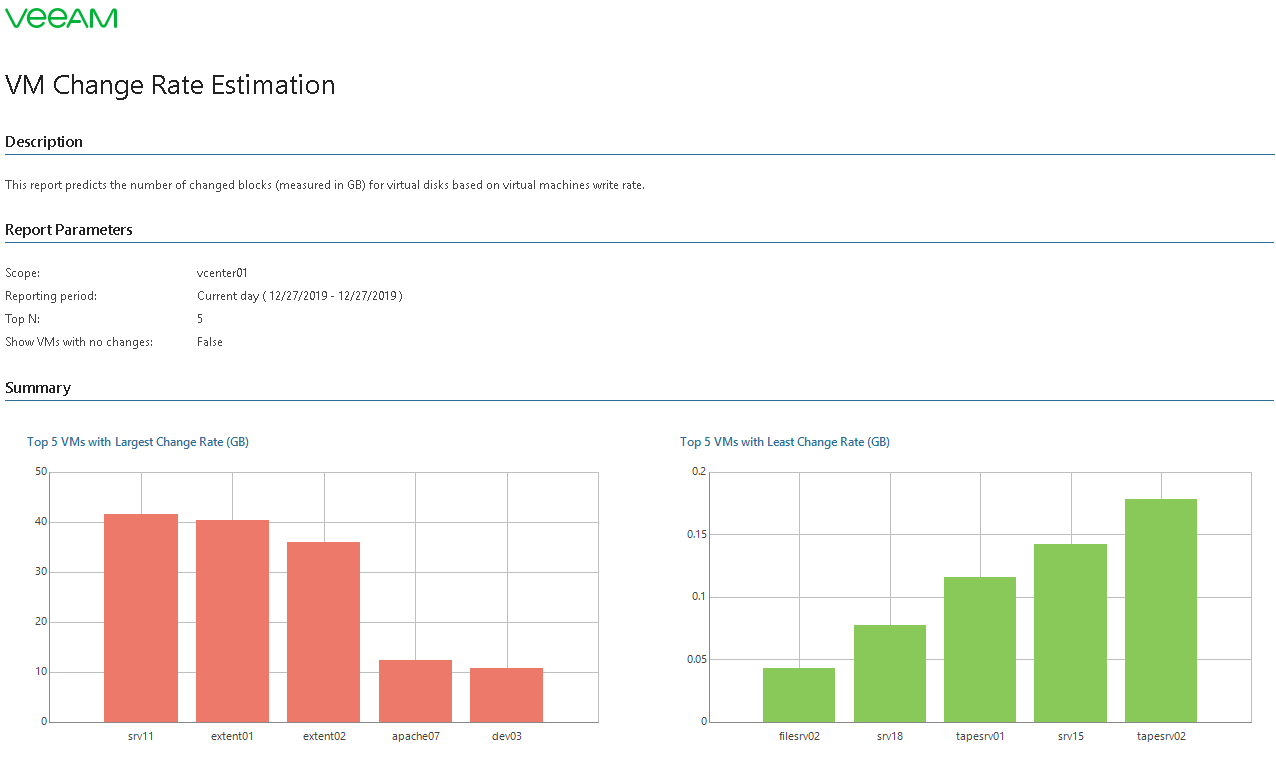
Если кликнуть на диаграмму или на ВМ в списке, то можно узнать, сколько данных пишется на виртуальный диск выбранной машины за указанное время, и таким образом прикинуть объем изменений на грядущий период.
Еще больше приблизить прикидки к реальности поможет отчет Data Change Rate History. Он умеет рассчитывать change rate для виртуальных и физических машин, защищаемых Veeam Backup & Replication. Причем возможно делать расчеты двумя способами - вы можете задать требуемый с помощью параметра отчета Calculate change rate based on:
Считать change rate, опираясь на количество измененных данных с момента предыдущего бэкапа (прочитанные данные) - Data read
Считать, опираясь на количество данных, которые были непосредственно перевезены Veeam Backup & Replication на целевой репозиторий (переданные данные) - Data transferred
В этом случае умный отчет учитывает, что Veeam Backup & Replication уже после чтения данных сокращает их объем благодаря сжатию и дедупликации. Это позволяет ощутимо уменьшить объем места, занимаемого на целевом репозитории, например, теми машинами, у которых одни и те же блоки регулярно меняются в промежутках между запусками заданий бэкапа. Выбрав такой вариант, вы сможете наиболее точно рассчитать количество места для хранения резервных копий машин.
Полезно: А еще для планирования ресурсов у нас есть вот такой онлайн-калькулятор.
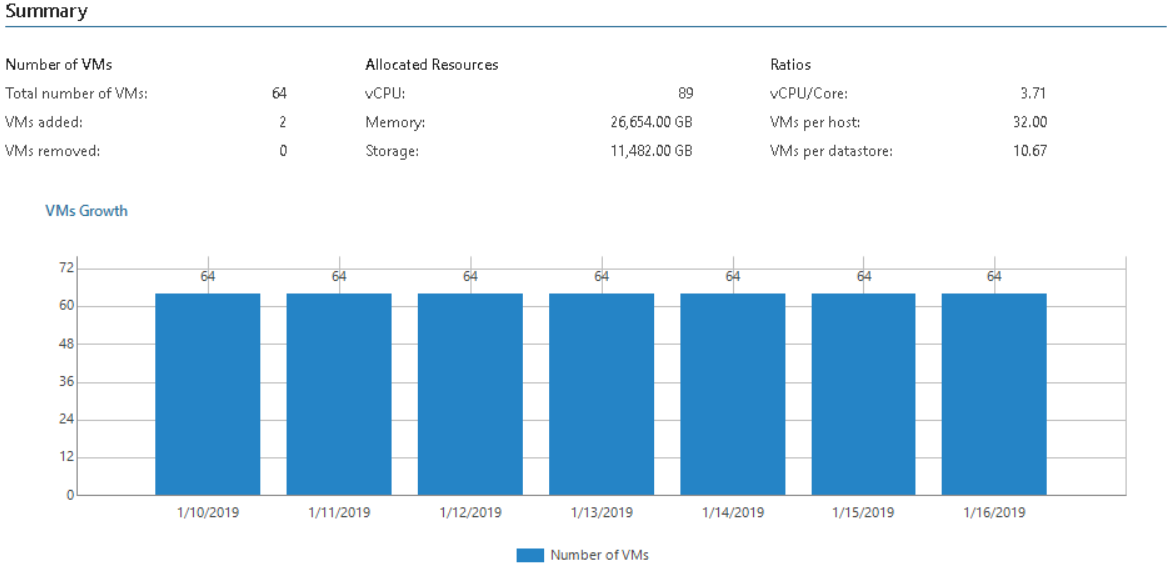
Если вы постоянно развертываете новые ВМ - а без этого работу сервис-провайдера невозможно себе представить - то неплохо бы иметь удобный отчет, чтобы отслеживать рост инфраструктуры и не допускать ее бесконтрольного расширения (да-да, того самого VM sprawl). Для этого у нас есть VMs Growth, который рапортует об изменении количества числа ВМ за указанный период, о выделенных им vCPU и памяти.
Бэкап в фокусе
С виртуальной инфраструктурой разобрались, теперь посмотрим, как обстоят дела с инфраструктурой резервного копирования - все ли ВМ защищены, соблюдаются ли установленные показатели RPO, и так далее.
Примечание: RPO - это максимальный объем данных, которые вы можете позволить себе потерять, соотнесенный со временем. Иными словами, RPO определяет “возраст” последнего бэкапа или реплики, из которого в случае сбоя будет выполняться восстановление до нормального рабочего состояния.
Начнем с отчета Protected VMs.
В нашей терминологии машина считается защищенной (Protected), если у нее есть как минимум одна точка восстановления (бэкап или реплика), которая отвечает заданному показателю RPO.
Если точка восстановления с заданным RPO отсутствует или не соответствует его значению (например, есть лишь старая реплика), то такая машина считается незащищенной (Unprotected).
Отчет Protected VMs сообщает нам для каждой виртуальной машины ее название, размер, число точек восстановления и дату создания новейшей точки, а также рапортует о том, с каким статусом (успех или неуспех) завершились задания бэкапа и репликации. Значение RPO вы указываете в параметрах отчета, а затем на диаграмме VM Last Backup Age сможете увидеть, например, сколько ВМ не попали в требуемый промежуток со своими точками восстановления (Outside RPO):

Если обнаружились незащищенные машины, можно открыть отчет Workload Protection History и посмотреть, что с такой машиной происходит. Отчет показывает, как отрабатывают задания бэкапа, имеющие такие-то параметры (эти параметры можно задать в настройках отчета, в поле Columns). Это единственный исторический детальный отчет по всем защищаемым объектам (per-workload), который поддерживает такого рода кастомизацию. Этот же отчет послужит и для аудита, когда нужно подтвердить, что бэкап определенного объекта сделан вовремя.
Есть еще отдельный подвид заданий бэкапа - это бэкап логов баз данных SQL и Oracle. Как известно, эти задания работают непрерывно (мы подробно разбирали, что и как при этом происходит в статье на Хабре). Поэтому если с ними что-то идет не так, это тут же покажет отчет Database Protection History - а конкретно его диаграмма SLA: на ней видно, сколько (в %) интервалов для бэкапа логов (те самые log backup intervals, по умолчанию это 15 минут) завершились успешным бэкапом этих самых логов за установленный период RPO.

Есть и гибкий отчет Data Change Rate History (работает как для виртуальных, так и для физических машин, которые бэкапит Veeam Agent) - с его помощью можно определить, какие бэкапы и реплики растут слишком быстро и грозят заполонить собою все пространство репозитория. Этот отчет можно также применять для планирования объемов СХД.

А какова средняя продолжительность задания бэкапа? С какой скоростью передаются данные, и не возникают ли где узкие места?
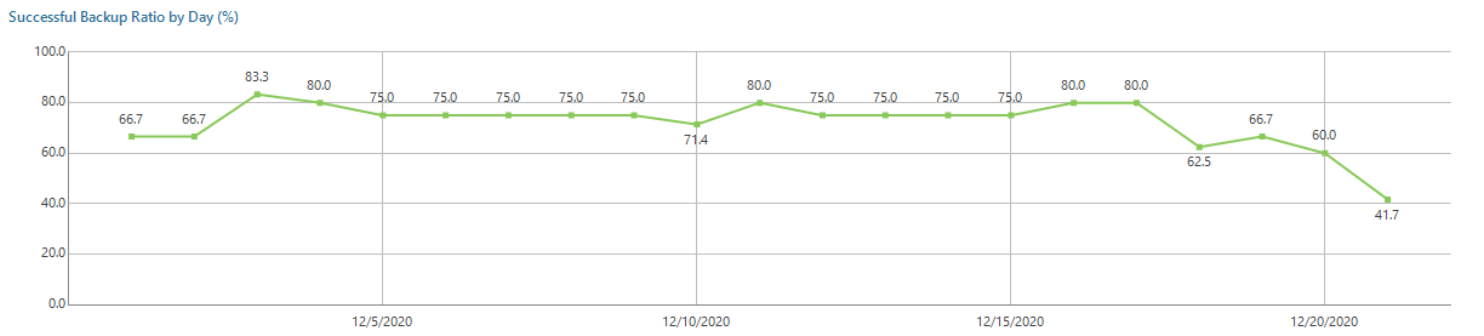
На эти вопросы вам с заданной регулярностью будет отвечать отчет Job History и входящие в него диаграммы Top Jobs by Average Duration and Transferred Data, Successful Backup Ratio by Day (доля успешных бэкапов за день):
Небольшой лайфхак для документирования инфраструктуры
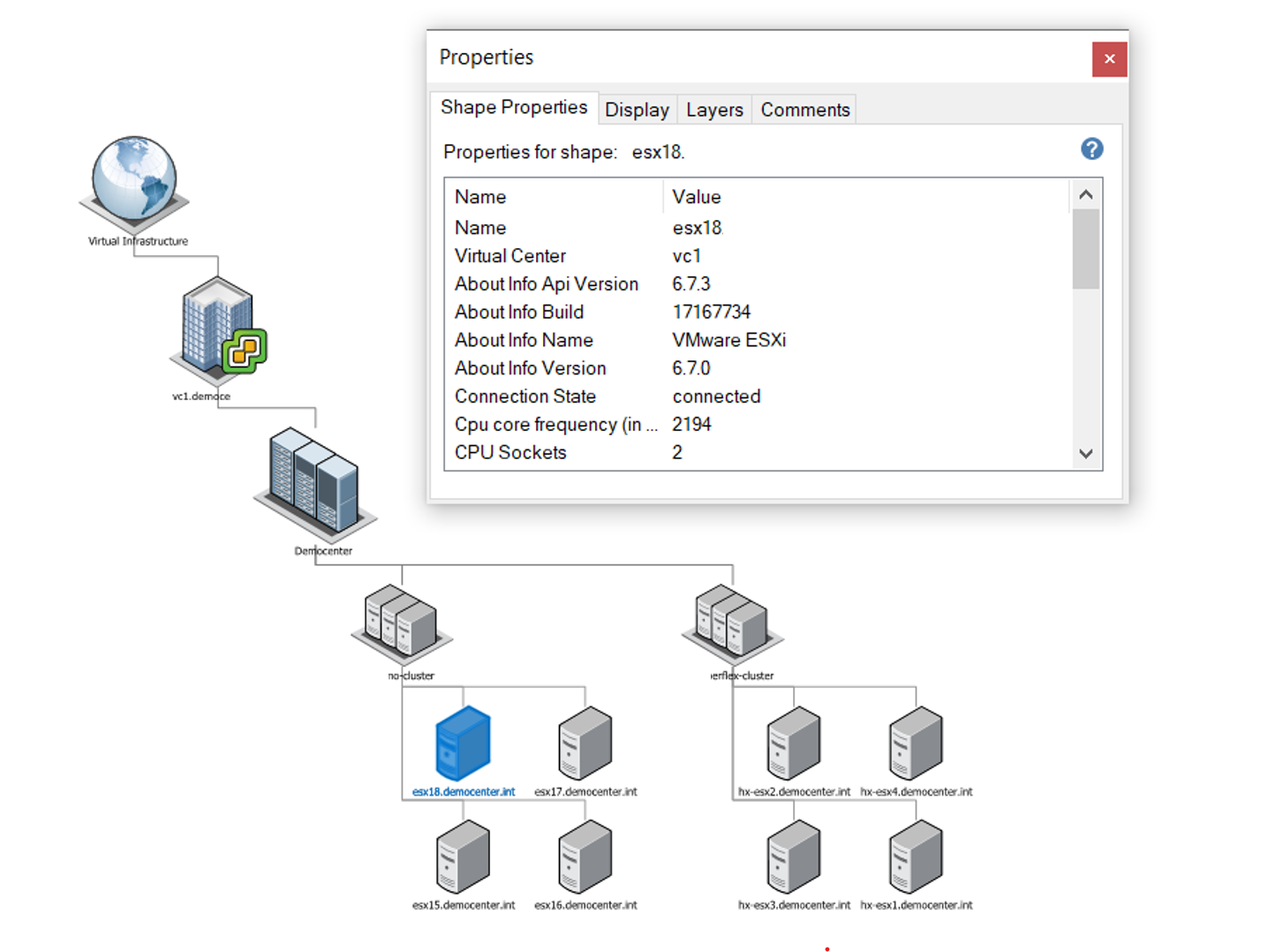
Если вам предстоит задокументировать топологию вашей IaaS-среды или предоставить клиенту наглядную схему его инфраструктуры, то пригодится умение Veeam ONE автоматически генерировать отчеты в формате диаграмм Visio. На выходе вы получите схемы-иллюстрации, описывающие виртуальную инфраструктуру на базе vSphere или Hyper-V, а именно:
Настройки конфигурации
Настройки СХД
Параметры сети (только для VMware vSphere)
Использование ресурсов СХД (только VMware vSphere)
vMotion (только для VMware vSphere)
Вот пример схемы-иллюстрации настроек конфигурации:
Подробнее о диаграммах Visio можно почитать тут (на англ.языке).
Как видим, Veeam ONE предоставляет не просто отчеты и оповещения, а подробную и полезную информацию, на основе которой сервис-провайдеру можно взаимодействовать с клиентами, повышая качество сервиса, предотвращая возникновение проблем и узких мест, а если уж они появились - позволяя оперативнее и успешнее их решать.
Что еще почитать и посмотреть
Скачать бесплатную редакцию Veeam ONE Community Edition можно здесь.
Пробная версия коммерческой редакции Veeam ONE доступна для скачивания здесь.
krids
Спасибо за статью. А то, что на 11a репорт "Protected VM's" для всех машин со включенным Fault Tolerance говорит, что "Unprotected Time: No Backup", а бекапы свежие вполне себе лежат на репе это бага или фича ?
polarowl Автор
Чтобы разобраться с проблемой в работе продукта конкретно в вашей инфраструктуре, лучше всего обратиться в поддержку. Конечно, можно написать и на форум, но, скорее всего, и там попросят завести тикет.
(Некоторые известные проблемы описаны в Release Notes (раздел Known Issues) или попали в Top Issues Tracker для 11а: https://forums.veeam.com/veeam-one-f28/top-issues-tracker-t77613.html - но это, кажется, не ваш случай.)