

Введение
В этой статье я собираюсь объяснить, как работает кеш первого уровня JPA и Hibernate и как он может улучшить производительность вашего уровня доступа к данным.
В терминологии JPA кэш первого уровня называется Persistence Context, и он представлен интерфейсом EntityManager. В Hibernate кэш первого уровня представлен интерфейсом Session, который является расширением к JPA EntityManager.
Состояния сущностей JPA и связанные с ними методы перехода
Сущность JPA может находиться в одном из следующих состояний:
Новая (Transient)
Управляемая ( Associated)
Отсоединенная (Dissociated)
Удалена (Deleted)
Чтобы изменить состояние сущности, вы можете использовать методы persist, merge или remove JPA EntityManager, как показано на следующей диаграмме:

Когда вы вызываете метод persist, состояние сущности меняется с New (Новая) на Managed (Управляемая).
И при вызове метода find состояние сущности также становится Managed (Управляемая).
После закрытия EntityManager или вызова метода evict состояние сущности становится Detached (Отсоединенная).
Когда сущность передается в метод remove JPA EntityManager, состояние сущности становится Removed (Удаленная).
Имплементация кэша первого уровня в Hibernate
Внутри Hibernate сохраняет сущности в следующей карте:
Map<EntityUniqueKey, Object> entitiesByUniqueKey = new HashMap<>(INIT_COLL_SIZE);А EntityUniqueKey определяется следующим образом:
public class EntityUniqueKey implements Serializable {
private final String entityName;
private final String uniqueKeyName;
private final Object key;
private final Type keyType;
...
@Override
public boolean equals(Object other) {
EntityUniqueKey that = (EntityUniqueKey) other;
return that != null &&
that.entityName.equals(entityName) &&
that.uniqueKeyName.equals(uniqueKeyName) &&
keyType.isEqual(that.key, key);
}
...
}Когда состояние сущности становится Managed, это означает, что оно хранится в этой Java Map entitiesByUniqueKey.
Итак, в JPA и Hibernate кэш первого уровня - это Java Map, в котором ключ Map представлен объектом, инкапсулирующим имя сущности и ее идентификатор, а значение Map - это сам объект сущности.
Поэтому в JPA EntityManager или Hibernate Session может быть только одна сущность, хранящаяся с использованием одного и того же идентификатора и типа класса сущности.
Причина, по которой мы можем иметь не более одного представления сущности, хранящегося в кэше первого уровня, заключается в том, что в противном случае мы можем получить различные отображения одной и той же строки базы данных, не зная, какая из них является правильной версией, синхронизируемой с соответствующей записью базы данных.
Транзакционная отложенная запись
Чтобы понять преимущества использования кэша первого уровня, следует разобраться, как работает стратегия транзакционной отложенной записи.
Как уже объяснялось, методы persist, merge и remove JPA EntityManager изменяют состояние данной сущности. Однако состояние сущности не синхронизируется каждый раз, когда вызывается метод EntityManager. На самом деле, изменения состояния синхронизируются только при выполнении метода flush EntityManager.
Эта стратегия синхронизации кэша называется write-behind (отложенная запись) и выглядит следующим образом:
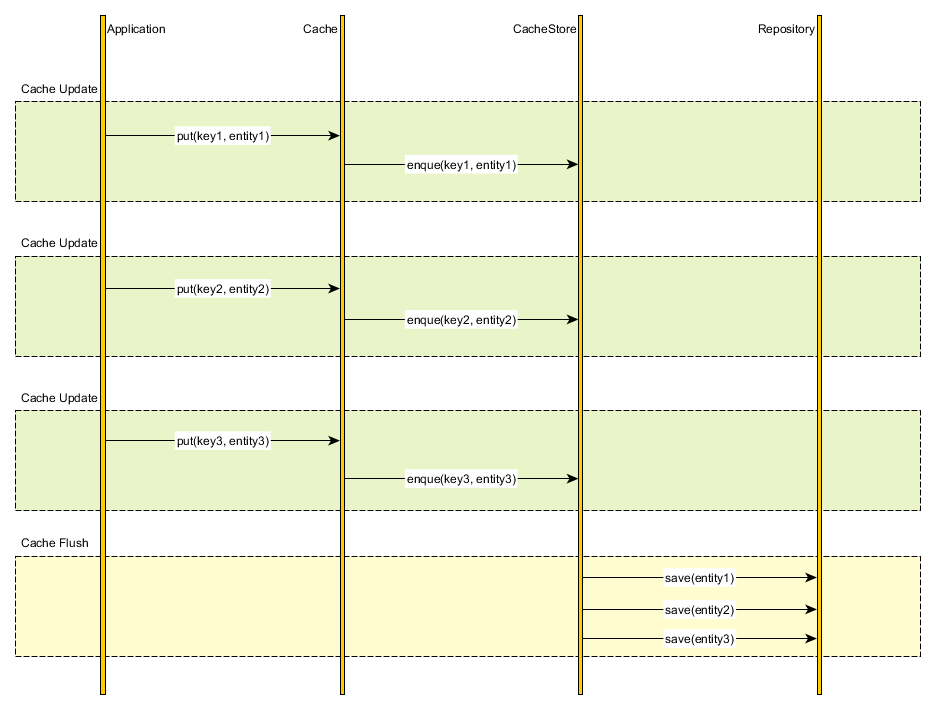
Преимущество использования стратегии write-behind заключается в том, что мы можем пакетно обрабатывать несколько объектов при очистке кэша первого уровня.
Стратегия write-behind на самом деле очень распространена. Процессор также имеет кэши первого, второго и третьего уровней. И при изменении реестра его состояние не синхронизируется с основной памятью, пока не будет выполнен сброс (flush).
Кроме того, как объясняется в этой статье, реляционная система баз данных маппирует страницы ОС на страницы буферного пула в памяти, и, по соображениям производительности, буферный пул синхронизируется периодически во время контрольной точки, а не при каждой фиксации транзакции.
Повторяющиеся чтения на уровне приложения
Когда вы получаете сущность JPA, либо напрямую:
Post post = entityManager.find(Post.class, 1L);Или через запрос:
Post post = entityManager.createQuery("""
select p
from Post p
where p.id = :id
""", Post.class)
.setParameter("id", 1L)
.getSingleResult();Будет вызвано событие Hibernate LoadEntityEvent. Событие LoadEntityEvent обрабатывается DefaultLoadEventListener, который загрузит сущность следующим образом:

Сначала Hibernate проверяет, хранится ли сущность в кэше первого уровня, и если да, то возвращается текущая управляемая ссылка на нее.
В случае, когда сущность JPA не найдена в кэше первого уровня, Hibernate проверяет кэш второго уровня, если этот кэш включен.
Если сущность не найдена в кэше первого или второго уровня, то Hibernate загрузит ее из базы данных с помощью SQL-запроса.
Кэш первого уровня гарантирует повторяемость чтения сущностей на уровне приложения, поскольку независимо от того, сколько раз сущность загружается из Persistence Context, вызывающей стороне будет возвращена одна и та же управляемая ссылка на сущность.
Когда сущность загружается из базы данных, Hibernate берет JDBC ResultSet и преобразует его в Java Object[], который известен как состояние загруженной сущности. Загруженное состояние хранится в кэше первого уровня вместе с управляемой сущностью, как показано на следующей диаграмме:

Как видно из приведенной выше диаграммы, кэш второго уровня хранит загруженное состояние, поэтому при загрузке сущности, которая ранее хранилась в кэше второго уровня, мы можем получить загруженное состояние без необходимости выполнять соответствующий SQL-запрос.
По этой причине загрузка сущности занимает больше памяти, чем сам объект Java-сущности, так как необходимо хранить еще и загруженное состояние. При сбросе (flush) JPA Persistence Context загруженное состояние будет использовано механизмом "грязной" проверки (dirty checking), чтобы определить, изменилась ли сущность с момента ее первой загрузки. Если она изменилась, будет сгенерирована команда SQL UPDATE.
Поэтому, если вы не планируете изменять сущность, то эффективнее загружать ее в режиме только для чтения, поскольку загруженное состояние будет отброшено после инстанцирования объекта сущности.
Заключение
Кэш первого уровня является обязательной конструкцией в JPA и Hibernate. Поскольку он привязан к текущему выполняющемуся потоку, то не может быть общим для нескольких пользователей. По этой причине в JPA и Hibernate кэш первого уровня не является потокобезопасным.
Помимо обеспечения повторяющихся операций чтения на уровне приложения, кэш первого уровня может пакетно обрабатывать несколько SQL-операторов в момент сброса, тем самым улучшая время отклика транзакции "чтение-запись".
Однако, хотя он предотвращает получение одной и той же сущности из базы данных несколькими вызовами find, но при этом не может предотвратить загрузку JPQL или SQL последнего снапшота сущности из базы данных, только для того, чтобы отбросить его при сборке набора результатов запроса.
Материал подготовлен в рамках курса «Java Developer. Professional».
Всех желающих приглашаем на бесплатное demo-занятие «Применение kafka для связи микросервисов на Java Spring Boot». Продолжаем разрабатывать систему получения курса валюты. Познакомимся с kafka и организуем с ее помощью взаимосвязь пары микросервисов.
>> РЕГИСТРАЦИЯ
Комментарии (3)

jobber_man
19.12.2021 23:02+2Сущность JPA может находиться в одном из следующих состояний:
Новая (Transient)
Управляемая ( Associated)
Отсоединенная (Dissociated)
Удалена (Deleted)
Не может, нет у сущности JPA таких состояний. Четыре возможных состояния сущности JPA называются new, persistent, detached и removed.
Вы смешали в кучу JPA как стандарт (спецификацию) и библиотеку Hibernate как одну из ее реализаций. Притом, даже не самую соответствующую спецификации, референсной реализацией JPA является библиотека EclipseLink.
Кэш первого уровня является обязательной конструкцией в JPA и Hibernate.
Опять не так. Откройте уже JSR 338 и почитайте. Слово кэш там употребляется исключительно по отношению к кэшу второго уровня, то, что вы называете кэшем первого уровня в JPA называется persistence context. Hibernate, конечно, может его реализовывать и в виде кэша.
Материал подготовлен в рамках курса «Java Developer. Professional».
Без комментариев.
Hett
Плохой перевод.