
Эта история про то, как искать виновника торможения запросов, если база и бэкенд переводят стрелки друг на друга; почему при обновлении базы не стоит раньше времени завершать нагрузочное тестирование; а также о том, что не всегда во встроенных инструментах оказываются те, что упомянуты в документации.
Ну а начиналось все очень мирно: мы хотели немного подтянуть сайт под обновленные требования Google.

Меня зовут Алексей Сладков, я ведущий разработчик команды поиска SuperJob, где тружусь с 2008 года. За это время успел много с чем поработать у нас внутри и представляю, как устроены различные части нашей системы. На практике больше всего работал с бэкендом, что и привело меня к ковыряниям с базой данных. Но начну я с предыстории.
Google намекнул, что быстрые сайты — это хорошо
Началось все с того, что весной 2021 года Google выкатил обновление алгоритма ранжирования, где много внимания уделено скорости загрузки страниц сайтов. Логично, что быстрые сайты удобнее для пользователя, чем медленные. Поэтому быстрые сайты следует показывать в поисковой выдаче выше, а медленные — ниже.

Факторы, которые, по мнению Google, отражают удобство страницы для пользователя. В зеленой рамке: скорость загрузки основных элементов (LCP), отзывчивость интерфейса при первой загрузке (FID), неожиданные сдвиги макета страницы (CLS)
Таким образом, вопрос о том, насколько быстро работает наш сайт, стал актуальнее.
Как показала Google Analytics, нам действительно стоило беспокоиться по поводу скорости. Document Interactive Time, то есть время с начала загрузки до того момента, как со страницей можно будет взаимодействовать, в среднем составляло около трех секунд.

Это можно сравнить с классическими публикациями на тему того, как пользователи реагируют на задержку системы:
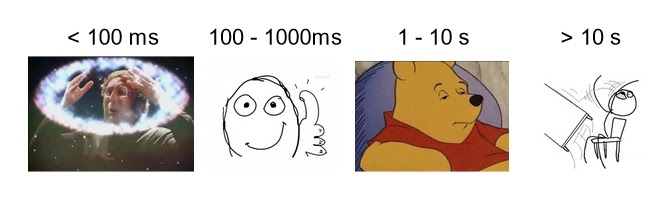
Три секунды — еще не фатально, но уже не очень.
Нужно упомянуть, что за последнее время нашим фронтендом была проделана довольно обширная работа по ускорению сайта. Применили практически полный набор стандартных приемов:
уменьшили количество HTTP-запросов, которые необходимы для отрисовки страницы;
ускорили работу JS-кода;
где это имело смысл, сделали кэширование ответов бэкенда на реверс-прокси;
и другие.
Но как бы мы ни ускоряли фронтенд, если бэкенд работает медленно, толку будет мало. И мне досталась задача разобраться с тем, насколько быстро бэкенд отдает ответ клиенту.
В среднем время выдачи начальной HTML-страницы составляло около секунды или чуть более. Этот результат необходимо было улучшить.
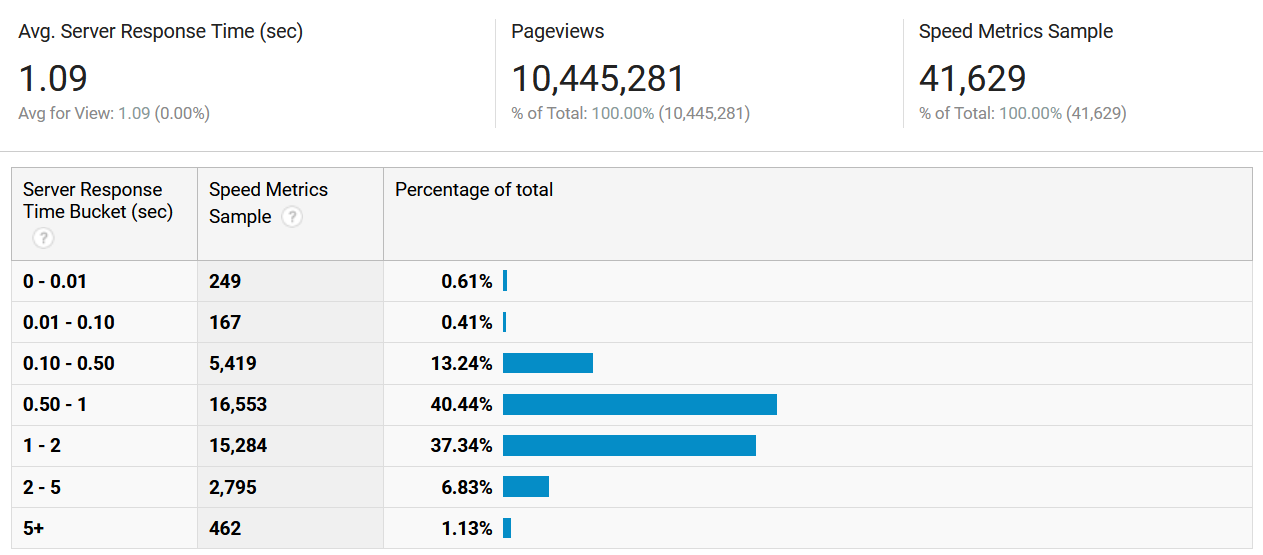
Анализ скорости ответа
В своих изысканиях я сфокусировался на ускорении поиска вакансий. Это одна из важнейших функций нашего сервиса, в минуту на этот эндпоинт приходит порядка 5 тыс. запросов. Кроме того, я работал в команде поиска, поэтому начал со своей «лужайки».
На графике — среднее время обработки HTTP-запросов к эндпоинту поиска вакансий. Кривая колеблется в районе 250 мс. Казалось бы, это не фатально.
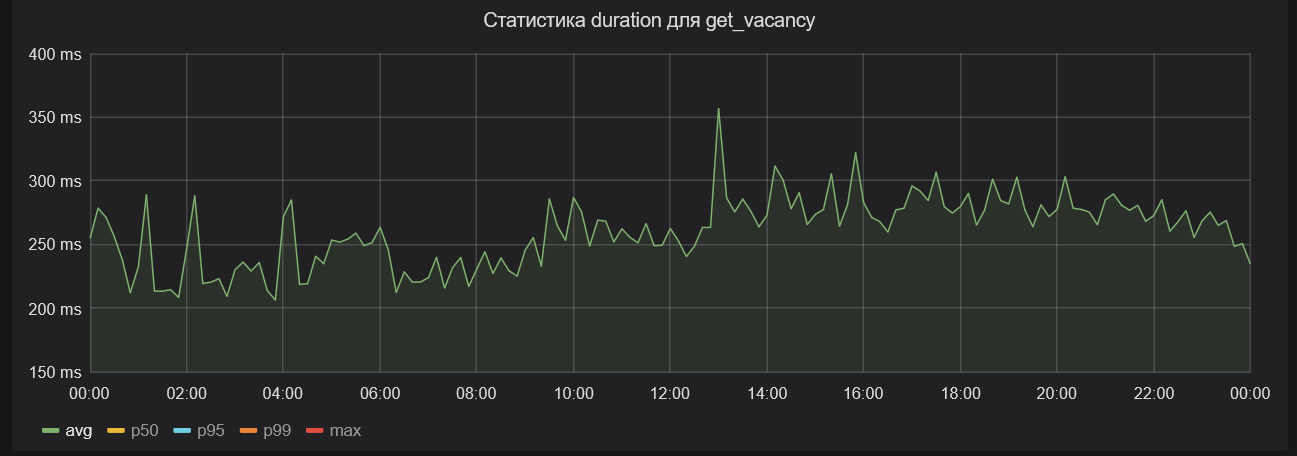
График среднего времени обработки запросов за сутки (каждая точка — порядка 10 мин.)
Но если сюда вывести 95-ый перцентиль, то среднее время обработки для него окажется почти в два раза больше.
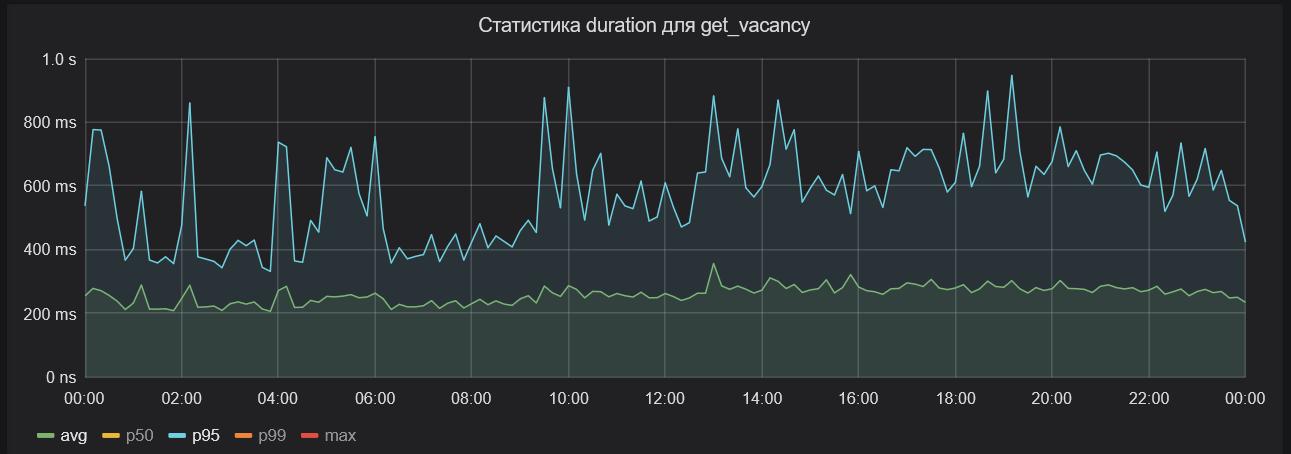
Оранжевая линия на диаграмме ниже — это среднее для 99-го перцентиля. В этом случае время почти в три раза больше — около полутора-двух секунд.
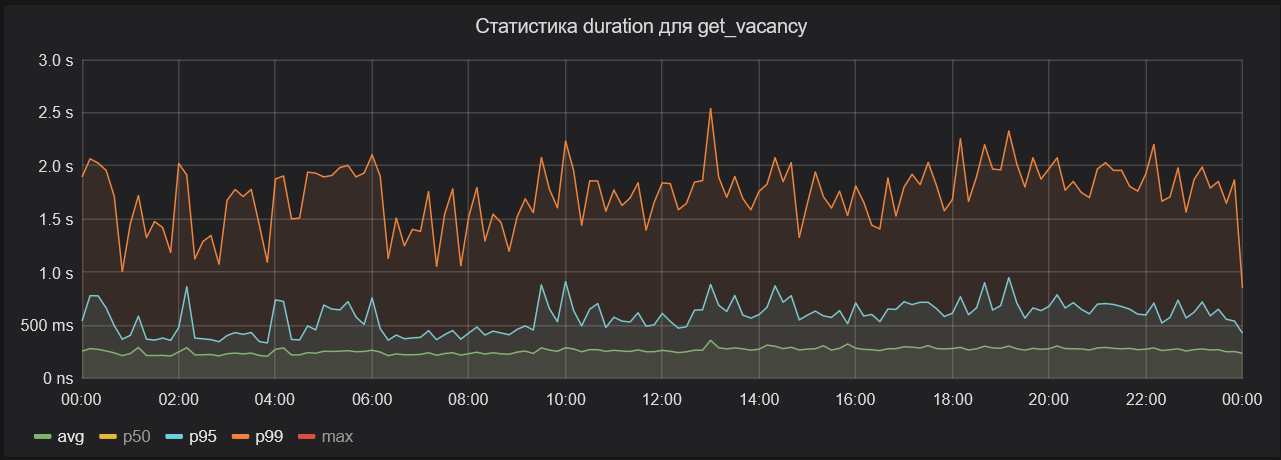
Далее график с максимальным временем обработки запросов. Оно практически не опускается ниже пяти секунд, а иногда доходит до минуты.
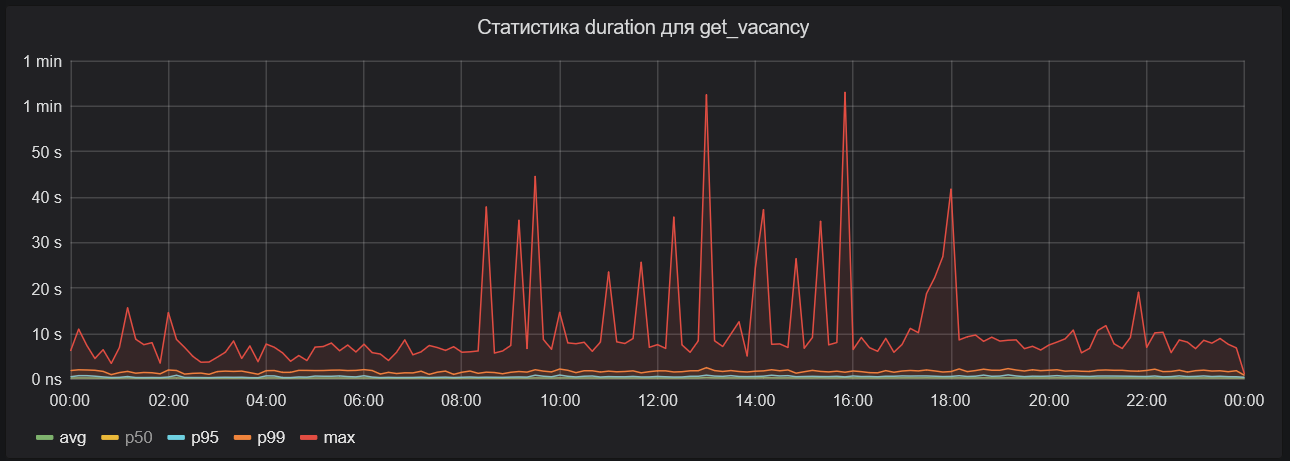
Если подвести итог:
~95% запросов обрабатываются за 250—600 мс;
~4% запросов выполняются за 600 мс — 2 с.;
~1% обрабатывается 2 с. — 60 с.
Каждую минуту на этот эндпоинт приходит порядка 5 тыс. запросов. Это значит, что каждую минуту тормозит примерно 50 поисков. И эту проблему надо как-то решать.
Тут мне помогла методика, про которую некоторое время назад рассказывал мой коллега из команды «Платформа» Александр Малащицкий.

Суть в том, что для каждого запроса сохраняется суммарное время ожидания того или иного ресурса, в том числе базы данных. Собранные метрики позволяют проанализировать ситуацию и понять, где именно у нас «бутылочное горлышко».
Первым делом мы посмотрели, сколько всего времени на этом эндпоинте мы тратим на ожидание ответа от базы данных. В итоге выявили характерную аномалию: среднее время ожидания было порядка 30—50 мс, а 99-й перцентиль стабильно держался на уровне одной секунды.
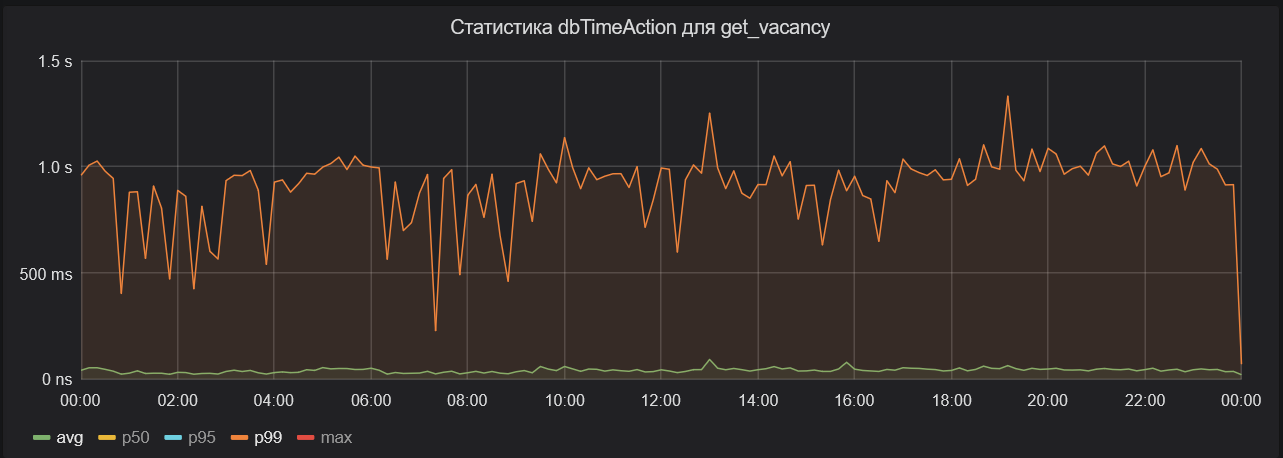
Если на этот график добавить максимальное время ожидания ответа от базы данных (на изображении ниже), то его будет практически не отличить от графика общего времени выполнения HTTP-запроса к эндпоинту поиска вакансий.
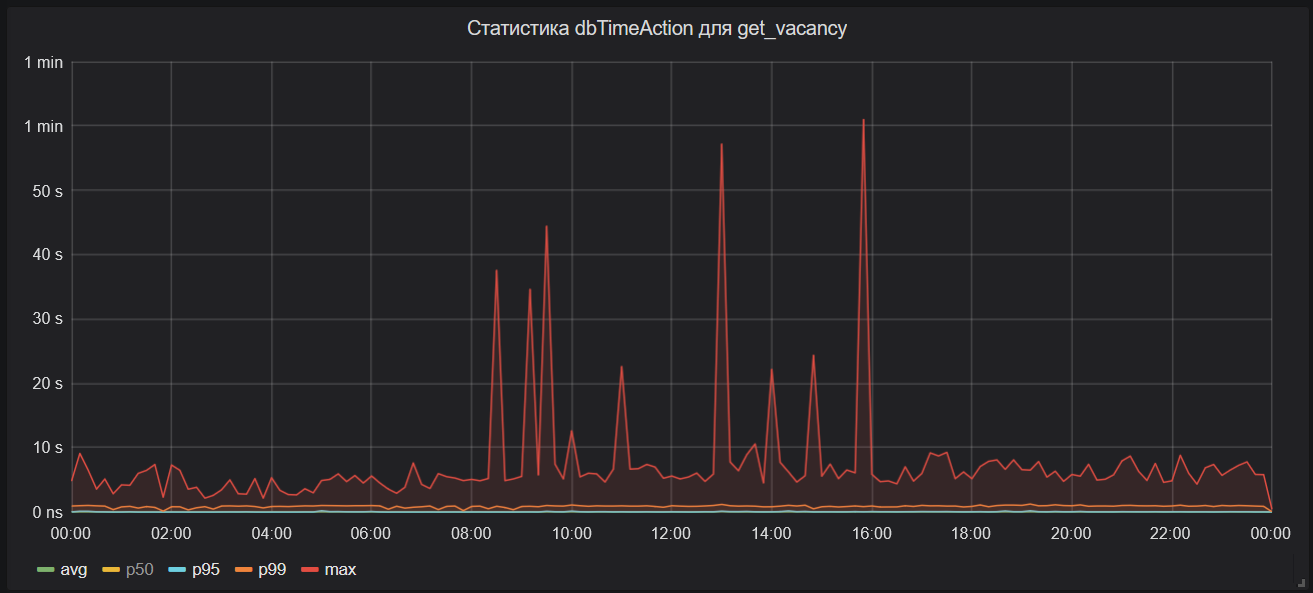
Стало ясно, что значительная часть тормозов происходит на уровне БД.
MariaDB под подозрением
В обычной ситуации я бы пошел к специальному человеку, хорошо знакомому с нашей базой данных, и попросил бы помочь решить этот вопрос. Но так вышло, что человек, который мог бы взять на себя эту задачу целиком, в тот момент оказался недоступен. Пришлось разбираться самому.
Коллеги, к которым я обратился за консультацией, посоветовали сразу несколько способов выявления тормозящих запросов и установления причин задержек:
MariaDB performance schema — это набор системных таблиц, где сохраняются данные о времени выполнения запросов. С их помощью можно посмотреть по шагам, сколько времени выполнялся каждый запрос.
Slow query log — лог-файл на сервере, в который записываются запросы, выполняющиеся дольше определенного порога (а при желании вообще все), с деталями исполнения.
Инструмент из комплекта Percona Tools — pt-query-digest, который может анализировать Slow query log, список процессов, tcpdump, и на основе этих данных строить отчеты по тормозящим запросам.
Percona Monitoring and Management — готовое решение с красивыми графиками. Мы используем его при поиске и оптимизации тяжелых запросов.
Поскольку процент медленных запросов был небольшой, хранить и работать только с агрегированными метриками не имело особого смысла. Нам нужны были все данные целиком. Поэтому мы выбрали MariaDB performance schema и работали с этими данными напрямую.
План был понятен: берем данные из этих таблиц, сохраняем и анализируем в надежде найти узкое место.

Для этого в конце обработки HTTP-запроса, который выполняется достаточно долго, из специальной таблицы получаем ID системного треда, отвечающего за текущее соединение:
SELECT * FROM performance_schema.threads WHERE PROCESSLIST_ID = CONNECTION_ID()А затем из таблицы events_statements_history получаем данные о том, сколько времени выполнялся каждый запрос.
SELECT * FROM performance_schema.events_statements_history WHERE THREAD_ID = ?На выходе мы имеем довольно много информации, в частности о том, сколько строк было просканировано, сколько было возвращено. Все это мы сохраняем в Clickhouse для дальнейшего анализа, не забыв подвязать ID HTTP-запроса, чтобы можно было сопоставить эти данные с данными бэкенда.
На следующем шаге можно было бы начать сохранять данные не только по самим запросам, но и по этапам их выполнения.
До этого шага мы не дошли, потому что ответ на вопрос, какие запросы тормозят с точки зрения MariaDB, был довольно неожиданным: никакие.
Ниже приведен график распределения суммарного времени ожидания ответа от базы данных при обработке HTTP-запросов к эндпоинту поиска вакансий примерно за 15 минут.
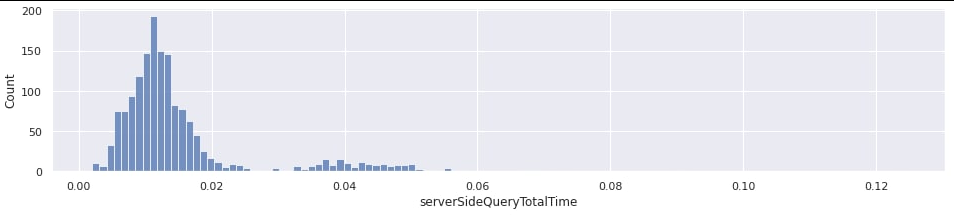
Видно, что за это время практически не было запросов, на которые в сумме ушло больше 50 мс. Стоит заметить, что этот график был построен только по тем запросам, для которых общее время ожидания ответа от базы, измеренное со стороны бэкенда, было не меньше секунды. Иными словами, с точки зрения MariaDB сервер был ни при чем.
При этом график времени, измеренного со стороны бэкенда, выглядел совсем иначе:
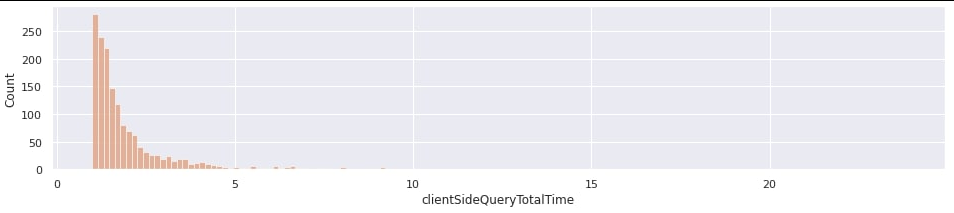
Я долго думал, что же может быть причиной такого поведения. Единственная версия, что на время ожидания ответа от БД как-то влияют сетевые задержки. Я приготовился запустить tcpdump и анализировать его вывод с помощью pt-query-digest. Но мне пришлось отвлечься на другую задачу, на первый взгляд не особо связанную с первой.
Проблемы оказались серьезнее
Начались почти ежедневные перебои в работе базы данных. Сайт иногда подтупливал и в целом проявлял все симптомы перегруженного сервиса.
Насторожило, что у базы данных было очень много соединений, которые находились в спящем состоянии (sleep — согласно документации — waiting for the client to send a new statement), т.е. клиент подключился, выполнил какие-то запросы, но потом занялся чем-то другим, и соединение не используется.
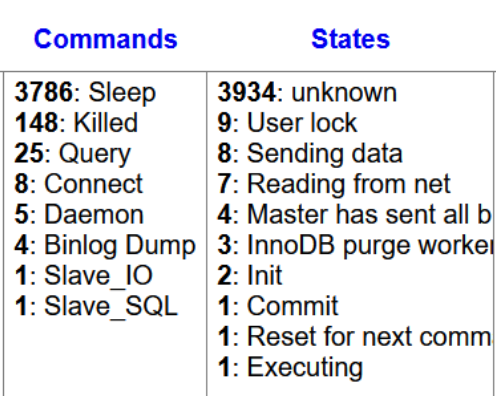
При этом у бэкенда было свое мнение на этот счет. С момента начала инцидента среднее время выполнения запроса подскакивало в десять и более раз.
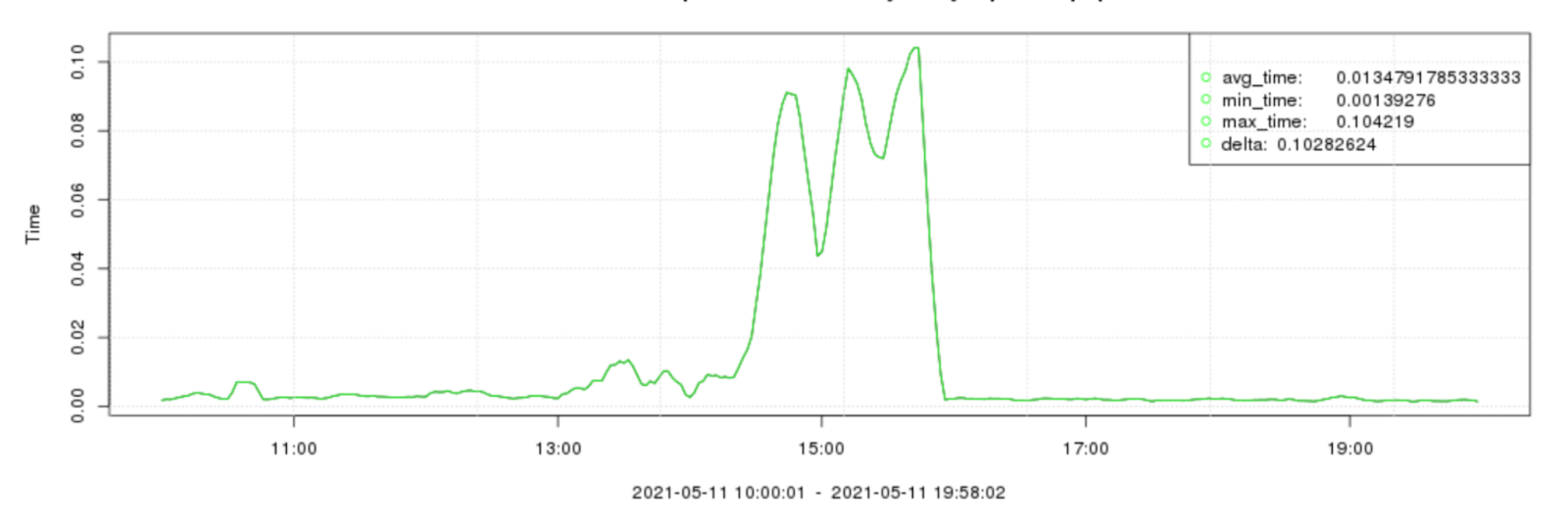
На этом графике инцидент длился примерно с 14:00 до 16:00.
К сожалению, это не приблизило меня к пониманию того, что происходит. Для этой истории, как и для первой проблемы, было характерно несоответствие показаний.
По мнению MariaDB, проблема была не в ней, а согласно показаниям бэкенда, написанного на PHP, тормоза были именно в базе данных.
Я рассказал о своих исследованиях руководителю команды «Платформа» Антону Золотилину (кстати, у него вышел интересный пост про версионирование API), и он высказал предположение, что запросы подвисают в очереди ThreadPool, которая не справляется с нагрузкой. При этом время ожидания в этой очереди не учитывается ни в каких метриках, предоставляемых базой данных.
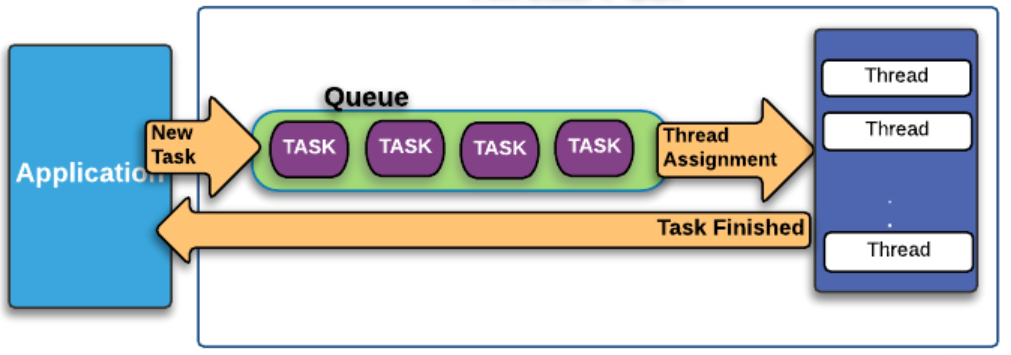
Осталось придумать, как проверить эту гипотезу — измерить время, которое запросы проводят в очереди. И как сделать так, чтобы людей не вводили в заблуждение обычные инструменты вроде того же самого списка процессов, которые по факту показывают неправильный статус.
Я сейчас не буду останавливаться на деталях и лишь скажу, что мне удалось воспроизвести проблемную ситуацию и убедиться, что все обстоит именно так:
клиент посылает запрос к базе данных;
запрос приходит на сервер;
ставится в очередь на выполнение;
если нет свободных тредов, в списке процессов он будет находиться в состоянии Sleep;
при появлении свободного треда запрос начинает выполняться.
Итак, «больное» место найдено.
Мониторинг ThreadPool
Прежде чем пробовать разные подходы к решению проблемы, нужно убедиться, что профит будет результатом именно наших изменений, а не каких-то других процессов. Поэтому нужно построить мониторинг.
Оказывается, в MariaDB есть системные таблицы, в которых вся эта информация вроде бы есть:
в таблице thread_pool_queues перечислены соединения, которые ждут своей очереди, с указанием времени, которое они в этой очереди провели;
в таблице thread_pool_groups указано количество активных и неактивных тредов в текущий момент, а также суммарное количество соединений в очереди для этой группы.
Однако в версии MariaDB 10.3, которую мы тогда использовали, этих таблиц еще не было.
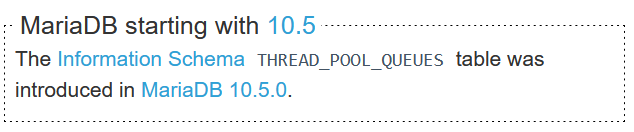
Использовать на боевой базе отладчик GDB и трассировщик strace, которые я применял для поиска проблемы, — так себе идея, поэтому мы решили обновиться до новой версии базы данных.

Конечно же, обновление базы данных у нас прошло не очень гладко. Я сделал три ошибки:
слишком рано завершил нагрузочное тестирование. Его следует проводить хотя бы неделю, чтобы собрать характерный профиль нагрузок, которые бывают на сервисе;
ошибся с интерпретацией результатов нагрузочного тестирования. У меня в отчете было порядка 4200 разных запросов. Из них около десяти на новой версии выполнялись на 10—80% медленнее. Проблема была в том, что среди этих десятков запросов были те, которые иногда начинают выполняться в цикле в очень большом количестве. И этой добавочной нагрузки хватало, чтобы создать перегрузку;
и я не оставил быстрого способа вернуться на старую версию базы. В документации написано, что репликация со старой версии на новую работает. А с новой версии на старую может работать, а может и не работать. По факту между версиями 10.3 и 10.5 она работает в обе стороны. Но я это, к сожалению, не проверил. И поэтому все реплики обновил в один день, не оставив ни одной на старой версии.
Комбинация этих промахов привела к необходимости ручной оптимизации по традиционному сценарию, который надо было реализовывать в любом случае:
ищем «тяжелые» запросы, дающие большую нагрузку на БД;
оптимизируем;
если не получается, переносим на реплику;
если это не запрос на чтение, переносим в другую БД;
повторяем процедуру, пока не полегчает.
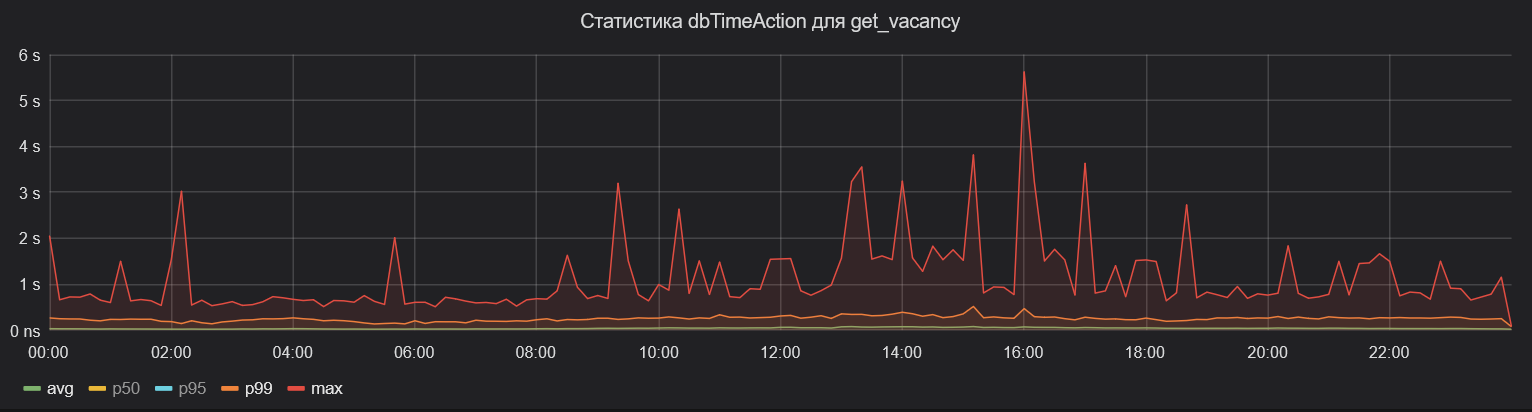
Результат появился достаточно быстро. Ниже — тот же график общего времени ожидания ответа от базы данных в рамках эндпоинта поиска вакансий. Видно, что среднее время для 99-го перцентиля сократилось почти в три раза.
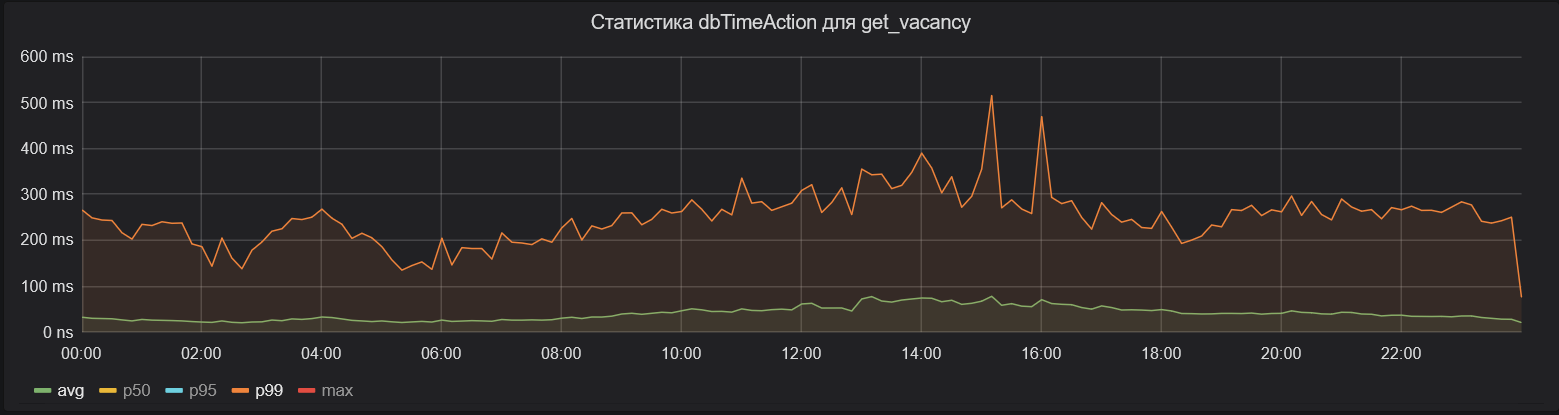
Максимальное время стало значительно меньше: минутные ожидания мы наблюдаем достаточно редко.
Как только мы обновились до версии 10.5, пришла пора воспользоваться таблицами, ради которых все затевалось. Напомню, они должны были помочь нам разобраться со sleep-соединениями.
Гипотеза, что во всем был виноват ThreadPool, подтвердилась. Если в момент перегрузки сделать запрос к таблице thread_pool_groups, то можно увидеть сотни соединений, висящих в очереди:
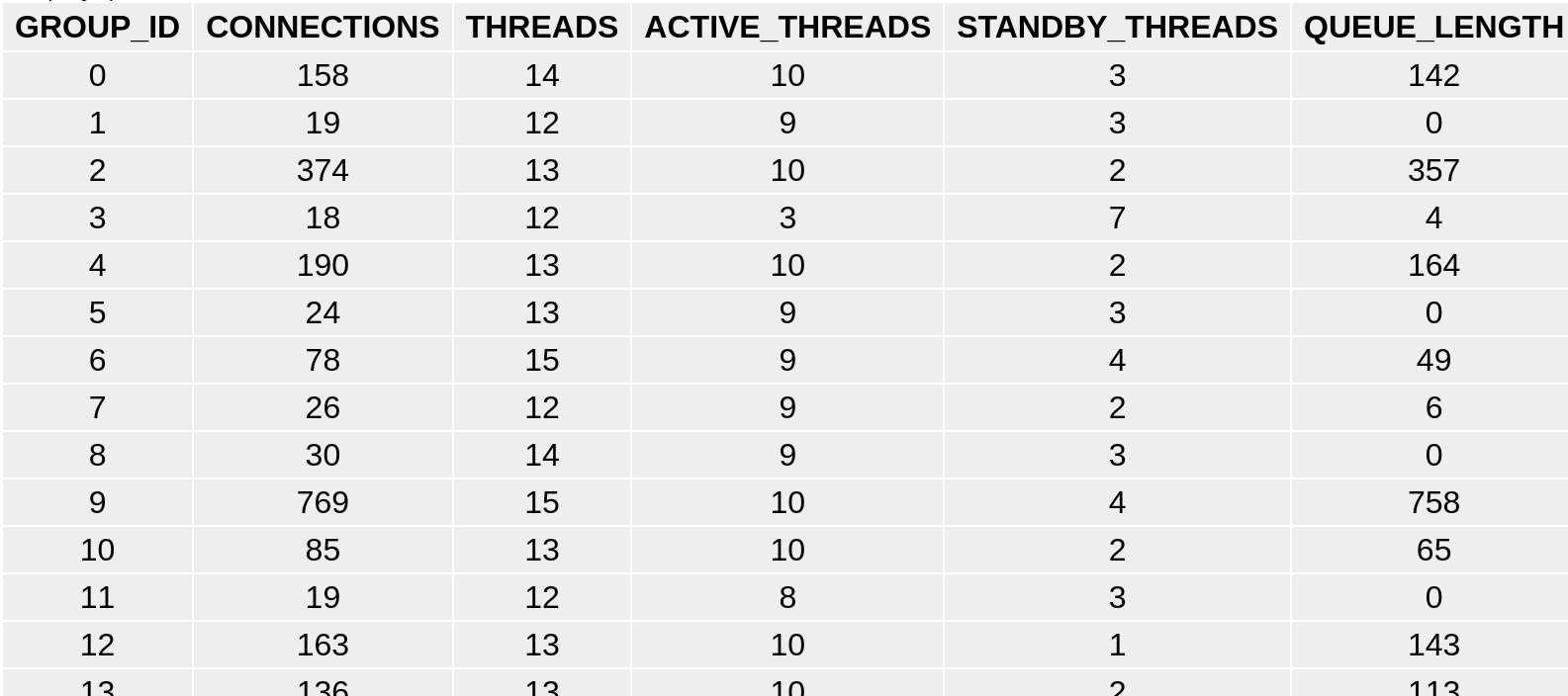
Но в истории с небольшим процентом медленно выполняющихся запросов нас ожидал неожиданный поворот.
Задумка была в том, чтобы в средствах мониторинга вместо обычного списка процессов использовать его модифицированный вариант, который учитывает, находится ли процесс в состоянии ожидания свободного треда. Чтобы получить корректное состояние каждого процесса, нужно сделать JOIN с таблицей thread_poll_queues.
Другими словами вместо обычного запроса
SHOW FULL PROCESSLISTиспользовать, например, такой
SELECT
P.*,
IF(Q.CONNECTION_ID IS NULL, COMMAND, 'Queued') AS REAL_COMMAND
FROM INFORMATION_SCHEMA.PROCESSLIST AS P
LEFT JOIN INFORMATION_SCHEMA.THREAD_POOL_QUEUES AS Q
ON P.ID = Q.CONNECTION_IDТак можно понять, настоящий sleep у соединения или нет.
К сожалению, на той версии базы, до которой мы обновились (10.5.10), мы не увидели ни одной строки, где connection_id был бы не null. А без этих данных мы не можем определить, какие именно процессы «спят».

После небольшого исследования оказалось, что это ошибка в коде MariaDB.
Итоги
мы зарепортили разработчикам баг в коде MariaDB, и в версиях 10.5.13 и 10.6.5, которые вышли 8 ноября, она уже исправлена. Соответственно, в таблице thread_pool_queues теперь должны отображаться нужные данные;
среднее время ожидания ответа от базы данных для 99-го перцентиля сократилось почти в три раза, также значительно уменьшилось максимальное время ожидания.
Выводы
Вместо заключения хочу привести несколько выводов, которые я сделал для себя из этой истории:
ThreadPool при некоторых обстоятельствах маскирует проблемы с производительностью базы данных;
нагрузочное тестирование нужно проводить тщательнее;
в любом сколько-нибудь большом проекте нельзя пускать на произвол судьбы работу с базой данных — следует регулярно следить за производительностью отдельных запросов.
flashyua
Сколько времени заняло изучение этой проблемы? И работа производилась параллельно с другими задачами, или сфокусировались только на этой?