

28 февраля я выступал с докладом на SphinxSearch-meetup, который проходил в нашем офисе. Рассказывал о том, как мы пришли от регулярного перестроения индексов для полнотекстового поиска и отправки обновлений в коде «по месту» к рейлтайм-индексам и автоматической синхронизации состояния индекса и базы данных MariaDB. По ссылке доступна видеозапись моего доклада, а для тех, кто предпочитает чтение просмотру видео, я написал эту статью.
Начну с того, как у нас был устроен поиск, а также зачем мы все это затеяли.
Поиск у нас был организован по вполне стандартной схеме.
С фронтенда приходят пользовательские запросы к серверу приложения, написанному на PHP, а он в свою очередь общается с базой данных (у нас это MariaDB). Если же нам нужно сделать поиск, сервер приложения обращается к балансировщику (у нас это haproxy), который соединяет его с одним из серверов, где запущен searchd, а тот уже выполняет поиск и отдает результат.
Данные из базы в индекс попадают вполне традиционным способом: по расписанию раз в несколько минут перестраиваем индекс с теми документами, которые обновлялись сравнительно недавно, и раз в сутки перестраиваем индекс с так называемыми «архивными» документами (т.е. с теми, с которыми уже достаточно давно ничего не происходило). Есть пара выделенных под индексацию машин, там по расписанию запускается скрипт, который сначала строит индекс, затем переименовывает файлы индекса особым образом, после чего складывает в отдельную папку. А на каждом из серверов с searchd раз в минуту запускается сначала rsync, который из этой папки копирует файлы в папку индексов searchd, а потом, если что-то было скопировано, выполняет запрос RELOAD INDEX.
Однако, для некоторых изменений в резюме и вакансиях требовалось, чтобы они «доезжали» до индекса как можно скорее. Например, если вакансию, которая была размещена в открытом доступе, снимают с публикации, то с точки пользователя резонно ожидать, что она исчезнет из выдачи в течение нескольких секунд, не более. Поэтому такого рода изменения отправляются с помощью UPDATE-запросов напрямую в searchd. А чтобы эти изменения применялись ко всем копиям индексов на всех наших серверах, на каждом searchd заведен распределенный индекс, который рассылает обновления атрибутов по всем инстансам searchd. Сервер приложения по-прежнему соединяется с балансировщиком и посылает один запрос на обновление распределенного индекса; таким образом, ему не нужно заранее знать ни список серверов с searchd, ни на какой именно сервер с searchd он попадет.
Все это работало довольно неплохо, но были и проблемы.
- Средняя задержка между созданием документа (у нас это резюме или вакансии) и его попаданием в индекс была прямо пропорциональна их количеству в нашей базе.
- Поскольку мы использовали распределенный индекс для рассылки обновлений атрибутов, то у нас не было никаких гарантий, что эти обновления были применены ко всем копиям индекса.
- «Срочные» изменения, произошедшие за время перестроения индекса, терялись при выполнении команды
RELOAD INDEX(просто потому, что их еще не было в свежепостроенном индексе), и попадали в индекс только после следующей переиндексации.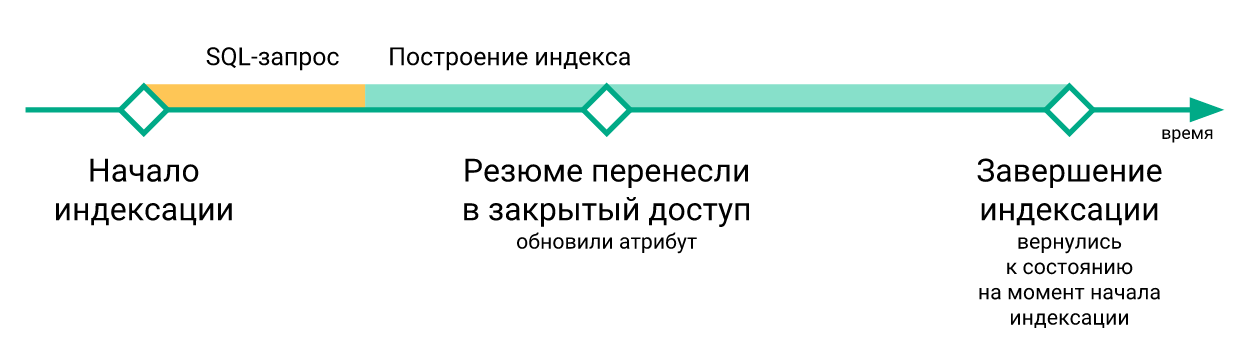
- Скрипты обновления индексов на серверах с searchd выполнялись независимо друг от друга, между ними не было никакой синхронизации. Из-за этого задержка между обновлением индекса на разных серверах могла достигать нескольких минут.
- Если нужно было протестировать что-то, связанное с поиском, требовалось после каждого изменения перестраивать индекс.
Каждая из этих проблем по отдельности не стоила кардинальной переработки инфраструктуры поиска, но вместе взятые они довольно ощутимо портили жизнь.
Бороться с вышеперечисленными проблемами мы решили с помощью realtime-индексов Sphinx. Причем нам было мало одного только перехода на RT-индексы. Чтобы окончательно избавиться от каких-либо data-race'ов, нужно было сделать так, чтобы все обновления от приложения до индекса шли через один и тот же канал. Кроме того, нужно было где-то сохранять изменения, внесенные в базу данных за то время, пока перестраивается индекс (потому что все-таки иногда перестраивать его приходится, а процедура не мгновенная).
Таким каналом передачи данных мы решили сделать соединение по протоколу репликации MySQL, а местом сохранения изменений на время перестроения индекса — binlog MySQL. Такое решение позволило нам избавиться от записи в Sphinx из кода приложения. А так как мы к тому времени уже использовали row-based репликацию с глобальным transaction id, переключение между репликами базы данных можно было сделать довольно просто.
Идея подключения непосредственно к базе данных, чтобы получать оттуда изменения для отправки в индекс, конечно же, не новая: в 2016 году коллеги из Авито выступали с докладом, где подробно рассказывали, как они решали задачу синхронизации данных в Sphinx с основной базой. Мы решили воспользоваться их опытом и сделать у себя похожую систему, с той разницей, что у нас не PostgreSQL, а MariaDB, и старая ветка Sphinx (а именно, версии 2.3.2).
Мы сделали сервис, который подписывается на изменения в MariaDB и обновляет индекс в Sphinx. Обязанности у него следующие:
- соединение с сервером MariaDB по протоколу репликации и получение событий из бинлога;
- слежение за текущей позицией бинлога и номером последней завершенной транзакции;
- фильтрация событий бинлога;
- выяснение, какие документы нужно добавить, удалить или обновить в индексе, а для обновляемых документов — какие именно поля надо обновить;
- запрос недостающих данных из MariaDB;
- формирование и выполнение запросов на обновление индекса;
- перестроение индекса при необходимости.
Подключение по протоколу репликации мы сделали с помощью библиотеки go-mysql. Она отвечает за установление соединения с MariaDB, чтение событий репликации и передачу их в обработчик. Запускается этот обработчик в горутине, которой управляет библиотека, но код обработчика пишем мы сами. В коде обработчика происходит сверка событий со списком таблиц, которые нас интересуют, и отправка на обработку изменений этих таблиц. Также наш обработчик хранит состояние транзакции. Это связано с тем, что в протоколе репликации события идут в порядке: GTID (начало транзакции) -> ROW (изменение данных) -> XID (завершение транзакции), причем сведения о номере транзакции есть только в первом из них. Нам же удобнее передавать номер транзакции вместе с ее завершением, чтобы сохранить информацию о том, до какой позиции в бинлоге применены изменения, а для этого нужно запоминать номер текущей транзакции между ее началом и завершением.
MySQL [(none)]> describe sync_state;
+-----------------+--------+
| Field | Type |
+-----------------+--------+
| id | bigint |
| dummy_field | field |
| binlog_position | uint |
| binlog_name | string |
| gtid | string |
| flavor | string |
+-----------------+--------+Номер последней завершенной транзакции мы сохраняем в специальный индекс из одного документа на каждом сервере с searchd. На старте сервиса проверяем, что индексы инициализированы и имеют ожидаемую структуру, а также что сохраненная позиция на всех серверах присутствует и одинакова на всех серверах. Затем, если эти проверки завершились удачно и нам удалось начать чтение бинлога с сохраненной позиции, начинаем процедуру синхронизации. Если же проверки не прошли, либо начать чтение бинлога с сохраненной позиции не удалось, то сбрасываем сохраненную позицию на текущую позицию сервера MariaDB и перестраиваем индекс.
Обработка событий репликации начинается с определения, какие документы затронуты тем или иным изменением в базе данных. Для этого в конфиге нашего сервиса мы сделали что-то вроде роутинга для событий изменения строк в интересующих нас таблицах, то есть набор правил для определения, каким образом изменения в базе данных должны попадать в индекс.
[[ingest]]
table = "vacancy"
id_field = "id"
index = "vacancy"
[ingest.column_map]
user_id = ["user_id"]
edited_at = ["date_edited"]
profession = ["profession"]
latitude = ["latitude_deg", "latitude_rad"]
longitude = ["longitude_deg", "longitude_rad"]
[[ingest]]
table = "vacancy_language"
id_field = "vacancy_id"
index = "vacancy"
[ingest.column_map]
language_id = ["languages"]
level = ["languages"]
[[ingest]]
table = "vacancy_metro_station"
id_field = "vacancy_id"
index = "vacancy"
[ingest.column_map]
metro_station_id = ["metro"]Например, по такому набору правил изменения в таблицах vacancy, vacancy_language и vacancy_metro_station должны попадать в индекс vacancy. Номер документа можно взять в поле id для таблицы vacancy, и в поле vacancy_id для остальных двух таблиц. Поле column_map — это таблица зависимости полей индекса от полей разных таблиц базы данных.
Далее, когда мы получили список затронутых изменениями документов, нужно обновить их в индексе, но делаем мы это не сразу. Сначала мы накапливаем изменения по каждому документу, а отправляем изменения в индекс, как только проходит небольшое время (у нас это 100 миллисекунд) с последнего изменения данного документа.
Мы решили так сделать, чтобы избежать множества лишних обновлений индекса, потому что во многих случаях одно логическое изменение документа происходит с помощью нескольких SQL-запросов, которые затрагивают разные таблицы, а иногда выполняются и вовсе в разных транзакциях.
Приведу простой пример. Допустим, пользователь отредактировал вакансию. Код, отвечающий за сохранение изменений, зачастую для простоты пишут примерно таким образом:
BEGIN;
UPDATE vacancy SET edited_at = NOW() WHERE id = 123;
DELETE FROM vacancy_language WHERE vacancy_id = 123;
INSERT INTO vacancy_language (vacancy_id, language_id, level)
VALUES (123, 1, "fluent"), (123, 2, "technical");
DELETE FROM vacancy_metro_station WHERE vacancy_id = 123;
INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id)
VALUES (123, 55);
...
COMMIT;Другими словами, сначала удаляются все старые записи из связанных таблиц, а затем вставляются новые. При этом записи в бинлоге об этих удалениях и вставках все равно будут, даже если по факту в документе ничего не поменялось.
Чтобы обновлять только то, что нужно, мы сделали следующее: измененные строки сортируем так, чтобы для каждой пары индекс-документ можно было получить все изменения в хронологическом порядке. Тогда потом мы сможем их по очереди применить, чтобы определить, какие поля в каких таблицах в конечном итоге изменились, а какие нет, после чего с помощью таблицы column_map получить список полей и атрибутов индекса, которые нужно обновить для каждого затронутого документа. Более того, события, относящиеся к одному документу, могут поступать не друг за другом, а как бы “вразнобой”, если они выполняются в разных транзакциях. Но, на нашу способность определить, что в каких документах изменилось, это не повлияет.
Заодно такой подход позволил нам обновлять только атрибуты индекса, если не было изменений в текстовых полях, а также объединять отправку изменений в Sphinx.
Итак, теперь мы можем выяснить, какие документы нужно обновить в индексе.
Во многих случаях данных из бинлога недостаточно, чтобы построить запрос на обновление индекса, поэтому недостающие данные мы получаем с того же сервера, откуда читаем бинлог. Для этого в конфиге нашего сервиса есть шаблон запроса на получение данных.
[data_source.vacancy]
# индекс может быть разбит на несколько примерно равных частей для ускорения поиска и индексации
# у нас - просто по остатку от деления id документа на число частей
parts = 4
query = """
SELECT
vacancy.id AS `:id`,
vacancy.profession AS `profession_text:field`,
GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`,
GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi`
FROM vacancy
LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id
LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id
GROUP BY vacancy.id
"""В этом шаблоне все поля помечены алиасами специального вида: [имя_поля_в_индексе]:тип_поля_в_индексе.
Он используется как при формировании запроса на получение недостающих данных, так и при построении индекса (об этом немного позже).
Формируем запрос такого вида:
SELECT
vacancy.id AS `id`,
vacancy.profession AS `profession_text`,
GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`,
GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro`
FROM vacancy
LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id
LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id
WHERE vacancy.id IN (<список id документов, попавших на обработку>)
GROUP BY vacancy.idЗатем для каждого документа проверяем, есть ли он в результате этого запроса. Если нет, то это означает, что он был удален из основной таблицы, и значит его можно также удалить и из индекса (выполняем для этого документа запрос DELETE). Если же он есть, то смотрим, нужно ли обновлять текстовые поля для этого документа. Если текстовые поля обновлять не нужно, то делаем для этого документа запрос UPDATE, иначе — REPLACE.
Здесь стоит отметить, что логику сохранения позиции, с которой можно начинать чтение бинлога в случае сбоев, пришлось усложнить, потому что теперь возможна ситуация, когда мы применяем не все изменения, прочитанные из бинлога.
Чтобы возобновление чтения бинлога работало корректно, мы сделали следующее: для каждого события изменения строк в базе данных запоминаем id последней завершенной транзакции на тот момент, когда это событие произошло. После отправки изменений в Sphinx обновляем номер транзакции, с которого можно безопасно начинать чтение, следующим образом. Если мы обработали не все накопленные изменения (потому что некоторые документы не «отлежались» в очереди), то берем номер самой ранней транзакции из тех, что относятся к изменениям, которые мы еще не успели применить. А если случилось так, что мы применили все накопленные изменения, то берем просто номер последней завершенной транзакции.
То, что получилось в результате, нас устраивало, но оставался еще один довольно важный момент: чтобы производительность realtime-индекса со временем оставалась на приемлемом уровне, необходимо, чтобы размер и количество «чанков» этого индекса оставалось небольшим. Для этого в Sphinx есть запрос FLUSH RAMCHUNK, который делает новый дисковый чанк, и запрос OPTIMIZE INDEX, который сливает все дисковые чанки в один. Изначально мы думали, что просто будем периодически его выполнять и все. Но, к сожалению, выяснилось, что в версии 2.3.2 OPTIMIZE INDEX не работает (а именно с достаточно большой вероятностью приводит к падению searchd). Поэтому мы решили просто раз в сутки полностью перестраивать индекс, тем более что время от времени все равно придется это делать (например, если меняется схема индекса или настройки токенайзера).
Процедура перестроения индекса проходит в несколько этапов.
Генерируем конфиг для indexer
Как и было сказано выше, в конфиге сервиса есть шаблон SQL-запроса. Он же используется и для формирования конфига индексатора.
Также в конфиге есть и другие настройки, необходимые для построения индекса (настройки токенайзера, словари, различные ограничения на потребление ресурсов).
Сохраняем текущую позицию MariaDB
С этой позиции мы начнем чтение бинлога, после того, как новый индекс будет доступен на всех серверах с searchd.
Запускаем indexer
Выполняем команды вида
indexer --config tmp.vacancy.indexer.0.conf --allи ждем их завершения. При этом если индекс разбит на части, то запускаем построение всех частей параллельно.
Загружаем файлы индекса по серверам
Загрузка на каждый сервер также происходит параллельно, но мы, естественно, дожидаемся, пока на все сервера будут загружены все файлы. Для загрузки файлов в конфиге сервиса есть секция с шаблоном команды для загрузки файлов.
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]
Для каждого сервера мы просто подставляем его имя в переменную Host и выполняем получившуюся команду. Мы для загрузки используем rsync, но в принципе подойдет любая программа или скрипт, который принимает список файлов в stdin и закачивает эти файлы в папку, где searchd ожидает увидеть файлы индекса.
Останавливаем синхронизацию
Прекращаем чтение бинлога, останавливаем горутину, отвечающую за накопление изменений.
Заменяем старый индекс на новый
Для каждого сервера с searchd делаем последовательно запросы
RELOAD INDEX vacancy_plain,TRUNCATE INDEX vacancy_plain,ATTACH INDEX vacancy_plain TO vacancy. Если индекс разбит на части, то выполняем эти запросы для каждой части последовательно. При этом, если мы находимся в production-окружении, то перед тем, как выполнять эти запросы на каком-либо сервере, снимаем с него нагрузку через балансировщик (чтобы никто не делал SELECT-запросов к индексам междуTRUNCATEиATTACH), а как только последнийATTACH-запрос выполнен, возвращаем нагрузку на этот сервер.
Возобновляем синхронизацию с сохраненной позиции
Как только мы заменили все realtime-индексы на свежепостроенные, мы возобновляем чтение из бинлога и синхронизацию по событиям из бинлога, начиная с той позиции, которую мы сохранили перед началом индексации.
Вот пример графика отставания индекса от сервера MariaDB.

Здесь можно видеть, что хотя состояние индекса после перестроения и возвращается назад во времени, это происходит совсем ненадолго.
Теперь, когда все более-менее готово, пришло время релиза. Делали мы это постепенно. Сначала мы вылили realtime-индекс на пару серверов, а остальные в это время работали по-старому. При этом структура индексов на «новых» серверах не отличалась от старых, поэтому наш PHP-приложение могло по-прежнему соединяться с балансировщиком, не заботясь о том, будет ли запрос обработан на realtime-индексе или на plain-индексе.
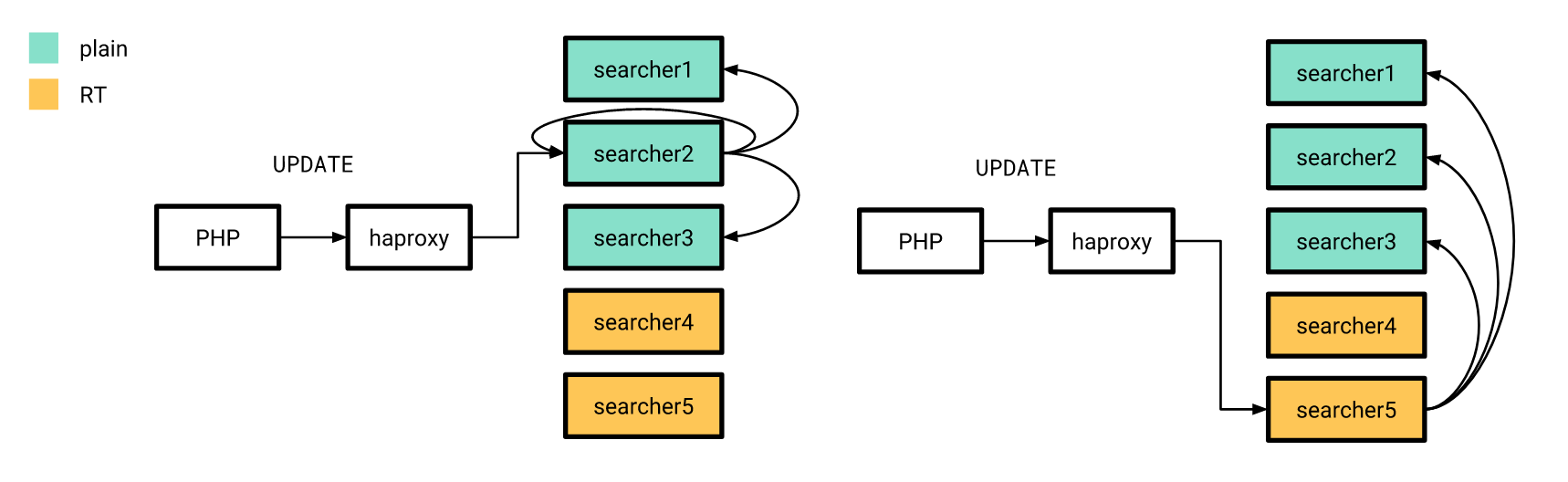
Обновления атрибутов, про которые я рассказывал ранее, тоже рассылались по старой схеме, с той разницей, что распределенный индекс на всех серверах был настроен так, чтобы рассылать UPDATE-запросы только по серверам с plain-индексами. Причем, если UPDATE-запрос от приложения попадает на сервер с realtime-индексами, то он у себя этот запрос не выполняет, но рассылает по серверам, настроенным по-старому.
После релиза, как мы и надеялись, получилось существенно сократить задержку между тем, как резюме или вакансия меняется в базе данных и тем, как соответствующие изменения попадают в индекс.
После перехода на realtime-индекс отпала необходимость перестраивать индекс после каждого изменения на тестовых серверах. А стало быть появилась возможность относительно недорого писать end-to-end автотесты с участием поиска. Однако, поскольку изменения из бинлога мы обрабатываем в асинхронном режиме (с точки зрения клиентов, которые делают запись в базу данных), то нужно было сделать возможность дождаться, пока изменения, касающиеся документа, участвующего в автотесте, будут обработаны нашим сервисом и отправлены в searchd.
Для этого мы сделали endpoint в нашем сервисе, который именно это и делает, то есть дождается, пока будут применены все изменения до указанного номера транзакции. Для этого сразу после того, как мы сделали нужные изменения в базе данных, запрашиваем у MariaDB @@gtid_current_pos и передаем его в endpoint нашего сервиса. Если мы уже к этому времени применили все транзакции до этой позиции, сервис сразу отвечает, что можно продолжать. Если нет, то в горутине, которая отвечает за применение изменений, создаем подписку на этот GTID, и как только он (или любой следующий за ним) будет применен, также разрешаем клиенту продолжать выполнение автотеста.
В PHP-коде это выглядит примерно следующим образом:
<?php
declare(strict_types=1);
use GuzzleHttp\ClientInterface;
use GuzzleHttp\RequestOptions;
use PDO;
class RiverClient
{
private const REQUEST_METHOD = 'post';
/**
* @var ClientInterface
*/
private $httpClient;
public function __construct(ClientInterface $httpClient)
{
$this->httpClient = $httpClient;
}
public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void
{
$masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn();
$this->httpClient->request(
self::REQUEST_METHOD,
"http://{$riverAddr}/wait",
[RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]]
);
}
}Результаты
В итоге нам удалось значительно сократить задержку между обновлением MariaDB и Sphinx.


Также мы стали намного более уверены в том, что все обновления доходят до всех наших Sphinx-серверов вовремя.
Кроме того, тестирование поиска (как ручное, так и автоматическое) стало значительно более приятным.
К сожалению, это нам далось не бесплатно: производительность realtime-индекса по сравнению с plain-индексом оказалась немного хуже.
Ниже изображено распределение времени обработки поисковых запросов в зависимости от времени для plain-индекса.

А вот такой же график для realtime-индекса.

Можно видеть, что доля «быстрых» запросов немного сократилась, а доля «медленных» — возросла.
Вместо заключения
Осталось сказать, что код сервиса, описанного в этой статье, мы выложили в открытом доступе. К сожалению, подробной документации пока нет, но при желании можно запустить пример использования этого сервиса через docker-compose.
RinNas
Матвею Травкину превед! )