
В один прекрасный момент вы можете переезжать из одного ДЦ в другой и понять, что не знаете свои системы: их поведение может стать неожиданным. В одной системе вы должны были работать гораздо быстрее, но теперь работаете медленно. В другой — не понимаете, куда приходит запрос, а в третьей столкнетесь с новыми проблемами.
Чтобы проще и быстрее понимать взаимосвязи между системами и легко их оптимизировать, вам прекрасно подойдет distributed tracing. Но как его выбрать, внедрить и не собрать все грабли?
Безкоровайный Денис, директор подразделения DevOps/DevSecOps в Proto Group и Панычев Дмитрий, руководитель разработки в Vprok.ru Перекресток, на конференции DevOps 2021 на примерах показали, как distributed tracing помог им решить бизнес-задачи. Читайте под катом, как они выбирали решение для distributed tracing и обходили грабли.

Кейс №1: долгий отбор товаров на WMS
Представьте себе: складская система WMS (warehouse management system), склад и сборщики заказов. Чтобы сборщики собрали заказ как можно быстрее, логистика по складу и ПО выстроены так, чтобы время сбора заказа было, во-первых, минимально, а во-вторых, предсказуемо. Чтобы у сборщика руки были свободны и ничего не мешало ему собирать заказ, на руке у него закреплен терминал сбора данных, а на пальце — сканер штрих-кодов. А любая его операция в ПО работает быстро (и должна работать быстро).
Но в какой-то момент алертинг сообщает, что процесс сборки затягивается — вместо десятых долей секунды он стал занимать слишком много времени:

График взлетел практически до небес — от десятых долей секунды до десятков секунд.
Проблема воспроизводилась только на одном из складов, и, как ни странно, не самом большом. Посмотрев на трейс от инцидента, стало понятно, что с оборудованием на ТСД и шлюзом проблем нет:

Но зато была замечательная коричневая линия, которая показывала запрос к БД. При этом тот же самый запрос с теми же самыми данными на других сервисах выполнялся быстро:
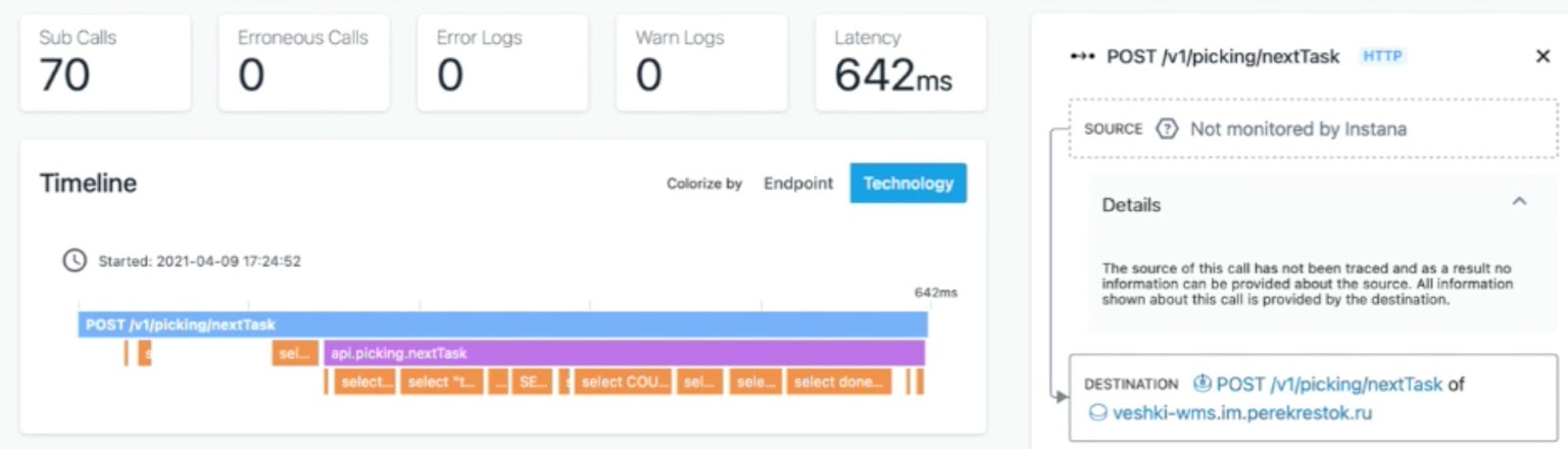
В итоге виновным оказался планировщик базы: для данного конкретного сервиса он немного изменил план выполнения запроса, в результате чего запрос стал ходить мимо индекса:
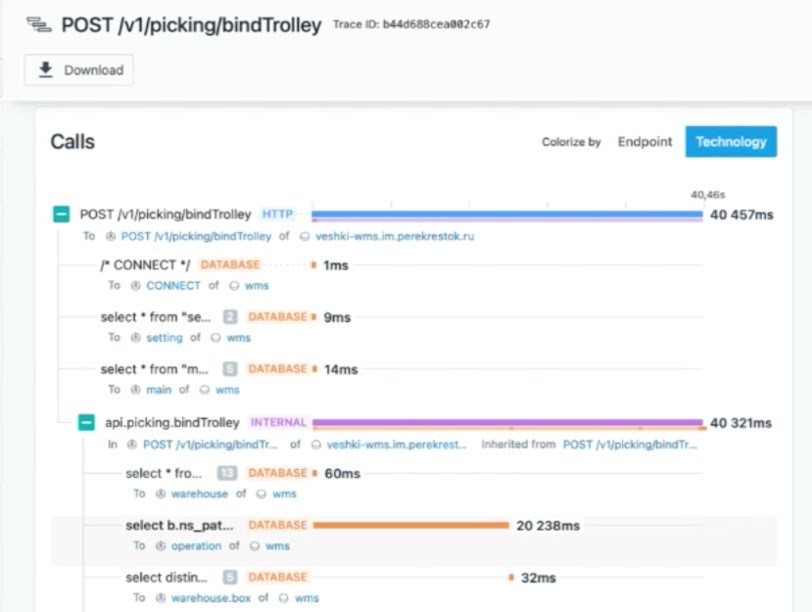
Инженеры создали новый индекс, прибили старый, и всё заработало: запрос стал, как и раньше, выполняться за миллисекунды. Но, исследуя проблему по классическому пути, без distributed tracing, найти корневую причину заняло бы больше времени, то есть сборка на складе стояла бы существенно дольше.
Кейс №2: сетевая связанность с SSO
В один момент стало понятно, что есть проблема: не всегда работает SSO, который лишь часть внешней аутентификации через X5 ID. Он находится во внешнем контуре, а само решение (и сервис аутентификации, в том числе) — в двух различных ЦОДах. Хоть и не везде, но SSO начал падать по таймауту, что означало: клиенты не смогут авторизоваться тем способом аутентификации, который выбрали.
С внедренной системой distributed tracing посмотрели трейс, и действительно: запрос падает по таймауту. Система мониторинга не обманывает:
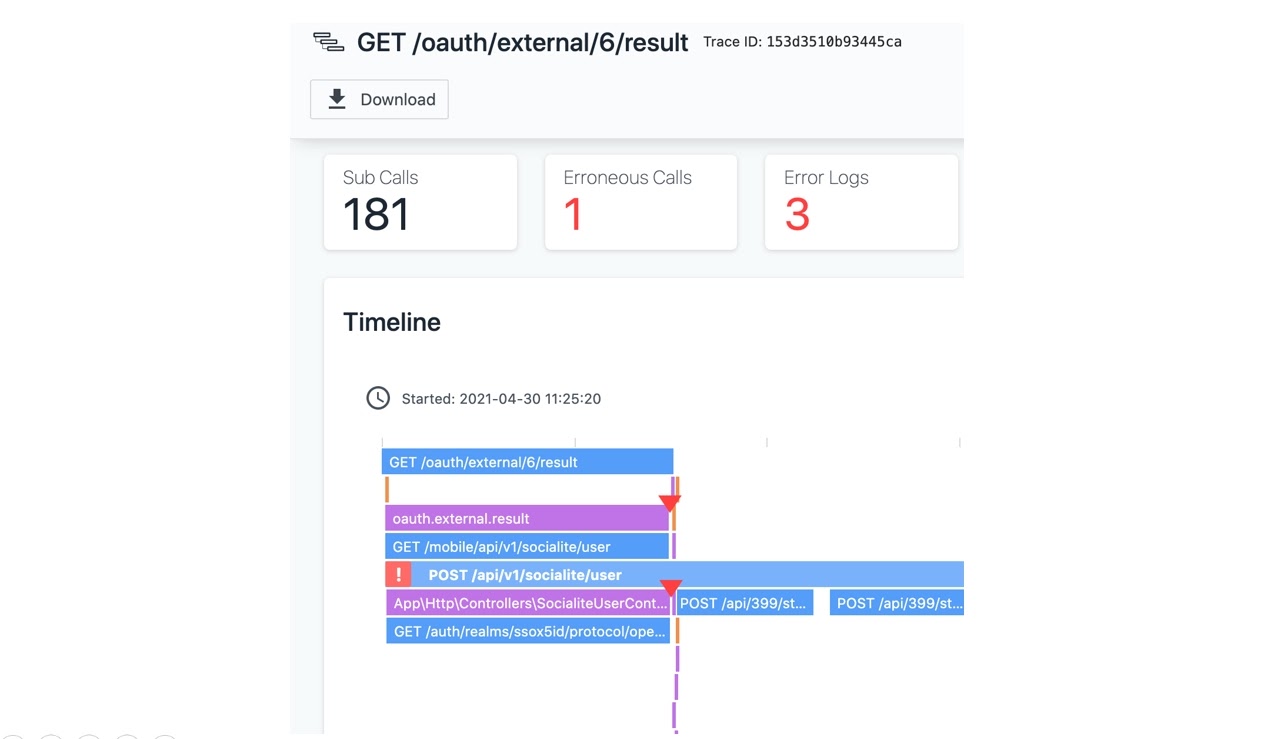
Тем не менее специалист SRE не обнаружил на карте сервисов ошибок при обращении к конкретному сервису. А раз сервис не отдает ошибки, то все запросы к тому самому внешнему SSO завершаются успешно. Но зато в том же самом трейсе был таймаут коннекта к Sentry — в том же самом контуре, где лежал SSO.
Благодаря этому картина стала достаточно ясной. Система, не получая ответ и падая по таймауту от SSO, пыталась записать проблему в Sentry. Но не могла до него достучаться, поэтому соединение с Sentry тоже падало по таймауту. Это происходило на некоторых нодах, и очевидно, эти ноды потеряли сетевую связанность с внешним контуром.
Проблему исправили, переключив балансировку на первый ЦОД, потому что сетевую связанность потерял на самом деле только второй ЦОД. На исследование проблемы хватило меньше одной минуты, вторая была потрачена на переключение. Оставшиеся проблемы были решены в течение некоторого времени, но больше система не пятисотила.
Вы, наверное, уже думаете, что это классная штука, хорошо бы ее себе внедрить. Но давайте немного погрузимся в теорию и посмотрим, как это работает.
Как работает distributed tracing
Итак, допустим, у вас есть несколько сервисов, которые друг с другом взаимодействуют. Чем сложнее становится инфраструктура и чем она более микросервисная, тем сложнее будет это взаимодействие. Сами сервисы при этом могут быть написаны на разных языках: Node, Java, Go, PHP или еще каком-то. Задача в том, чтобы вся цепочка взаимодействий предстала в наглядном, визуально понятном представлении:
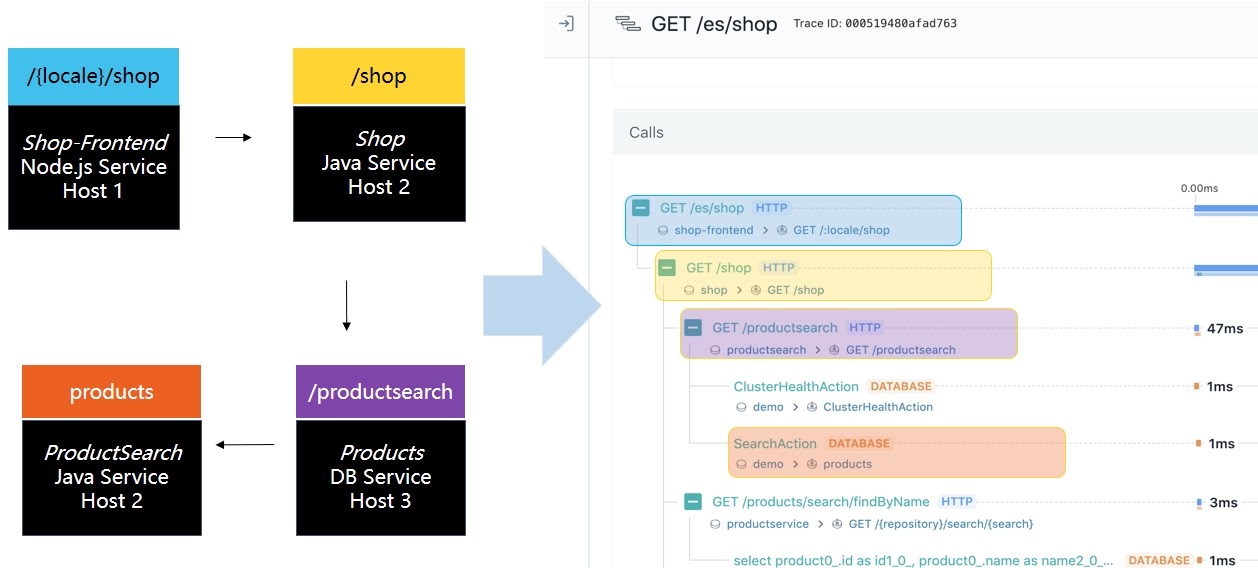
Как правило, в реальной жизни примеры гораздо более сложные
Чтобы получить такую цепочку, нужно еще немного углубиться в теорию, и начнем мы с понятия вызова. В рамках отслеживаемого процесса — обычно это запрос между двумя сервисами — вызов описывает деятельность. Как правило, в микросервисной среде нам важно понять, как один сервис общается с другим, с базой, с очередью, с Elastic или кэш-системой. То, что происходит внутри самого процесса в микросервисной среде — в рассматриваемом контексте менее интересно.
Каждый вызов при этом состоит из одного или нескольких спанов. А трейс состоит из одного или нескольких вызовов, объединяя их в одну цепочку. Эту концепцию и терминологию (трейсы, спаны и т.д.) довольно давно придумал и описал Google: «Dapper, Large-Scale Distributed Systems Tracing Infrastructure». А мы все теперь ее используем, в том числе, в концепции OpenTracing (The OpenTracing Semantic Specification).
Distributed Tracing: сущности
Когда некий сервис обращается ко второму сервису, то этот вызов сначала снимается с вызываемой системы, а потом он же — с вызывающей. В distributed tracing для этого есть понятия SpanId и TraceId — то, что вы как разработчик, сами прописываете, либо это автоматически делает какая-то другая система. В каждом спане есть основной и дочерние вызовы:

Мы понимаем, что вызов — дочерний, если он относится к тому же TraceId, который был в первом вызове, но его SpanId уже другой.
Чтобы понять, что эти несколько спанов относятся к одному вызову, используется TraceContext. Он описывает, какой из трейсов родительский, какой — дочерний, и как они связаны друг с другом. Так, собрав два разных спана и склеив их вместе, мы можем понять, что это один и тот же вызов:

Например, GET /shop есть синий и желтый, но они оба описывают один и тот же вызов.
Зачем это всё нужно?
Distributed tracing — это тайминги и анализ производительности систем. Потому что, когда мы рассматриваем один и тот же вызов с разных сторон, склеивая все спаны в одну систему, то можем понять, сколько времени исполнялся каждый вызов и на что ушло это время:

Например, сколько времени один сервис ожидал вызова другого сервиса. Или мы понимаем, в какое время в сервисе была произведена какая-то работа — и мы знаем, сколько миллисекунд это заняло. Или же это была сетевая задержка. Причем необязательно при межсетевом взаимодействии, это могли быть задержки, связанные с межпроцессным взаимодействием или чем-то еще.
Если описывать коротко, то distributed tracing — это способ понять распределенную систему, что в ней происходит и какие сервисы как обрабатывают запросы:
Через какие сервисы проходят запросы? Например, через какие сервисы проходит один запрос?
Сколько времени обрабатываются запросы в том или ином сервисе?
Если есть какие-то проблемы, то где именно они возникают в распределенной системе?
Также distributed tracing напрямую связан с KPI производительности — таким, как Golden Signals:

По сути, из анализа результатов работы distributed tracing можно получить данные, которые отвечают на вопросы:
Какой процент вызовов завершились ошибкой?
Какая длительность исполнения транзакций по 90-му перцентилю?
Сколько вызовов в секунду обрабатывает сервис X?
В принципе, их можно взять просто как метрики, но по сути, вы можете косвенно, на основе анализа трейсов, эти метрики сразу получить. А это уже часть observability.
Distributed tracing – часть observability
Как мы знаем, observability — это логи, метрики и трейсы. Но не только это, а еще и контекст, в котором все эти данные обрабатываются и интерпретируются. Как правило, в трейсах уже содержится какая-то информация, связанная с ошибками. Практически все реализации distributed tracing собирают ошибки и логи напрямую с приложения, либо их можно туда отправить вручную.
То есть, внедрив distributed tracing, вы уже больше чем на треть приближаетесь к observability, потому что и метрики, и логи также можно получить из трейсов.
Зачем тогда нужно observability? Мониторинг — это некий реактивный процесс: мы отвечаем на вопросы: что и когда сломалось, и, как правило, уже после того, как оно сломалось. В случае observability мы действуем проактивно и, как правило, отвечаем на более сложные вопросы: почему сломалось, как сломалось и как предотвратить, чтобы не ломалось дальше.
В случае кейса про SSO и сетевую связанность observability поможет не только быстро обнаружить виновника и причины проблемы, но и быстро, если не исправить проблему, то начать действовать и свести проблему к минимуму. Потому что distributed tracing — это не только метрики производительности. Есть замечательная метрика time to repair, и distributed tracing позволяет уменьшить время, которое необходимо на восстановление системы в работоспособном состоянии. Поэтому это очень важно для DevOps и SRE.
Distributed Tracing – плюсы использования для Dev и SRE
Понимание всей картины распределенной системы;
Детальный анализ прохождения запросов;
Выявление узких мест;
Возможность просмотреть транзакцию целиком.
Это такой helicopter view на всё. Но при этом вы можете как под микроскопом рассмотреть каждую конкретную транзакцию и понять, как проходит запрос в том или ином сервисе, какие есть узкие места. Ключевое — это понять, как улучшить систему, смотря на нее — с помощью distributed tracing — от общего обзора до мелких деталей.
Что выбрать для distributed tracing
Чтобы понять, что лучше — купить инструментарий, сделать его самим или поискать OpenSource — определитесь с критериями. Например, инженерам Впрока нужно было внедрить distributed tracing быстро, но при этом покрыть весь имеющийся у них разнородный стек технологий. Для идеальной реализации вся система также должна была быть стабильной и поддерживаться вендором, а команда — обладать достаточным опытом работы с ней.
Если говорить про ручную инструментацию, даже на базе готовых инструментов — то это достаточно долго и дорого относительно тех ресурсов, которые необходимо потратить. И наконец, у компаний, которые пошли по этому пути, обычно есть проблема: когда запрос проходит через множество разных сервисов, часть которых еще не покрыта, то ценность distributed tracing сильно падает. То есть это нетривиальная задача: написать самим всё и сразу, особенно когда реализовать нужно достаточно быстро — как это было во Впроке. Поэтому они выбрали коммерческое решение.
В принципе, на рынке есть несколько подходов к distributed tracing, чтобы всю инструментацию за вас делали агенты:

Возможно, теперь вы думаете, что реализация distributed tracing должна пройти без проблем, но на самом деле в таких проектах есть большое количество подводных камней, сложностей и граблей.
Проблемы и сложности при внедрении distributed tracing
Вот краткий список граблей, с которыми столкнулись инженеры Впрока.
Сложности
Если говорить про инструментацию всего, то это огромные объемы данных, которые генерит система distributed tracing. Кто-то для снижения нагрузки решает эту проблему сэмплированием трейсов. Но это не дает гарантии того, что когда вам нужно найти проблему, вы найдете именно ту транзакцию, тот трейс, который вам нужен.
Другая проблема связана с детализацией трейсов. Если у вас неполное покрытие, то вы не видите какую-то критичную часть, через которую проходит ваш запрос, и по сути, ценности очень сильно теряются.
Естественно, когда вы сами внедряете систему, нужно постоянно думать про TraceContext, не забывая его делать. Это решается частично шаблонами ваших микросервисов, но все равно это время разработчика, которое нужно затратить на инструментацию этих вещей.
Если говорить про стандарты, то не всегда они стыкуются с их конкретными реализациями, потому что одни и те же вещи можно назвать по-разному. Разные команды разработки могут использовать разные нотации. Хотя по сути данные одни и те же, но у них, например, разные названия тегов, и поэтому всё вместе сложно склеить, как и анализировать. Даже используя одни и те же, казалось бы, стандартизированные вещи, все равно можно столкнуться с разным подходом к реализации.
И, конечно, существуют риски, как в любом проекте: сроки, ресурсы и влияние на стабильность приложения. Посмотрим на примерах Впрока.
Нагрузка на CPU на проде
Что случилось? В один прекрасный момент на app-нодах (PHP) начало расти потребление CPU со временем, причем пропорционально нагрузке и достаточно непонятно. При отключении агента всё возвращалось в норму
Кто виноват? От глубокого и долгого исследования инженеров спасло, во-первых, понимание, что агент — это JVM. Они знали об особенностях работы ее с процессором в некоторых случаях. А во-вторых — то, что сами по себе агенты были раскатаны на 20% нод. Всё это помогло достаточно быстро выявить прямую корреляцию агента с потреблением CPU.
Что сделали? Во-первых, поставили reboot, чтобы после него JVM некоторое время она не перегружал процессор. На некоторых нодах reboot поставили раз в 3 часа. После чего стали разбираться с вендором и выяснили, что архитектура самого агента под этот кейс не совсем подходит. Потому что именно в этих условиях он архитектурно будет себя вести себя именно так.
У агента отключили ряд функций, после чего вендор достаточно долго дорабатывал и пересматривал его архитектуру. И после того как выкатили обновленную версию агента с новой архитектурой, больше таких проблем не воспроизводится. Это ясная и понятная проблема, с которой может столкнуться каждый, кто внедряет в свои продовые процессы стороннее решение.
Автообновление агента на проде
Что случилось? Начал пятисотить сервис аутентификации, причем только он, иногда, и в Kubernetes. Но примерно 1 из 200 пользователей мог аутентифицироваться только со второго раза.
Кто виноват? Ситуация не была такой уж очевидной — в APM, Sentry и логах ничего криминального не было. Разбирались достаточно долго, пока один из SRE-инженеров не попал на конкретный трейс процессов в момент исполнения, где неожиданно обнаружил следы агента. Когда отключили APM и distributed tracing, то внезапно пятисотки прекратились. Но у нас же везде то же самое, у нас же везде стоит — в чем проблема?
Все оказалось достаточно просто: агент конкретного решения автоматически обновляется в кластере k8s в случае, если не указано иное, если не зафиксирована версия. А новая версия агента приводила в некоторых случаях к крашу приложения. Да, ребята забыли, что версию нужно зафиксировать. Они фиксировали их на предыдущих сервисах, этот сервис был инструментирован позже. К тому же они не думали, что кому-то в здравом уме придет в голову что-то автоматически обновлять на чужом проде.
Что сделали? Зафиксировали версию агента, и проблема была решена. Коллег из этого конкретного решения попросили отключить обновление для всех.
Остаться без мониторинга?
APM — это круто и здорово, но альтернативные системы также нужны. Любое решение, которое полностью поставляет всю информацию о ваших сервисах и системах (особенно на достаточно небольших и достаточно простых инфраструктурно проектах), иногда может приводить к вопросам: а зачем нам другой мониторинг, зачем нам его вообще поддерживать?
Но если падает APM, то есть вариант остаться вообще без мониторинга. Во Впроке был случай, когда на 20-30 минут инженеры остались без мониторинга, потому что одновременно с ним упал и APM. Такая ситуация возможна, и от нее нужно страховаться по максимуму.
Нужно больше места!
Абсолютно каждый запрос записывает всё, что он делает. И для хранения этого объема, как его ни архивируй, как ни складывай, необходимо очень много места. В Перекрестке уже не так, но когда-то было прямо совсем тяжело.
Сейчас это порядка 30 Тб, но не с очень большим горизонтом хранения полностью детализированной информации для быстрого анализа — порядка 6-7 дней. Агрегированная информация хранится до 3-4 месяцев. При этом эти 30 Тб — это быстрые диски, поэтому это не всегда дешево.
Подведение итогов
На скриншоте слева обратите внимание на время — это 5:00 утра. Для экстренных собраний Впрок использует Discord, и некоторое время назад, когда еще не все сервисы были инструментированы, в пять утра можно было наблюдать две группы людей в двух переговорных. Сейчас инженеры стали спать лучше и больше:
В заключение хотелось бы сказать, что distributed tracing — очень эффективный инструмент для:
Ответа на вечный вопрос «Кто виноват?» Distributed tracing помогает это понять до конкретного сервиса, эндпойнта и даже транзакции. А если есть интеграция с системой релизов, то и до конкретного человека.
Понимания работы системы во всех её взаимосвязях. Чем более сложна ваша система, тем больше выгоды компания получает от внедрения distributed tracing в том или ином виде.
Поиска узких мест. От общего вида (helicopter view) можно углубиться и под микроскопом посмотреть каждую транзакцию, каждое узкое место. Понять, почему оно узкое, сколько запросов обрабатывается, где конкретно проблема, избавиться от этих узких мест — и лучше и больше спать.
Видео выступления Дениса и Дмитрия на конференции DevOps Conf 2021:
Профессиональная конференция по интеграции процессов разработки, тестирования и эксплуатации — DevOpsConf 2022 — пройдет 9 и 10 июня в Москве, в Крокус-Экспо, совместно с TechLead Conf.
Обсудим инженерные процессы в IT от XP до DevOps & Beyond, must have инструменты и практики изменений в командах для быстрых и качественных релизов. Программный комитет сейчас в процессе формирования расписания. А пока вы можете посмотреть отобранные доклады и купить билеты.