
Привет! Меня зовут Кирилл Цветков. Я DevOps, инженер, линуксовый админ – именно через запятую и никак иначе. В этой статье я попробую последовательно рассказать вам что такое DevOps, и примирить два конфликтующих стереотипа, которые это слово окружают.

Я часто слышу о том, что DevOps – это такая гламурная версия системного администратора. Для компетентного администратора слово DevOps в резюме – просто лычка, которая нужна, чтобы получить большую зарплатную вилку. Кубернетесы эти ваши – тьфу, мы такое ещё с FreeBSD jail проходили – модная технология, инструмент. Пришла-ушла, админам не привыкать – выучат и её, если будет надо.
Не менее часто слышу и обратное этому мнение.
DevOps это – не профессия, это половая ориентация методология, философия и порой даже образ жизни. Шерд оунершип, зиро блейм, обервабилити, тулинг и, конечно, континуус эврифин. И вот это всё точно не постигнуть неповоротливым админским умом, которому только и дай, что ядра собирать, сидя в пыльной серверной – индустрии подавай DevOps-трансформацию руками DevOps-евангелистов.
DevOps – начало
Начать нужно, как и полагается, с истоков. История зарождения DevOps берет свое начало с доклада Джона Оллспо и Пола Хэммонда «Десять деплоев в день: кооперация разработки (Dev) и эксплуатации (Ops) во Flickr», прочитанного в 2009 году на конференции Velocity 09. В докладе руководители команд разработки и эксплуатации Flickr рассказывали об извечном разрыве между Dev и Ops, и о том, какие проблемы это приносит бизнесу и подшефным им отделам . В выступлении было сказано о необходимости коммуникации между эксплуатацией и разработкой, о взаимном доверии. О новом подходе, новой методологии, которые возникли в самом Flickr, и об инструментах, нужных для реализации этого подхода.
Под впечатлением от доклада быстро возникла инициатива запустить на эту тему новую конференцию – DevOpsDays – эта конференция и подарила нам слово DevOps. Она была посвящена именно сокращению дистанции между Dev и Ops; алхимическому союзу – словами Пелевина – разработки и эксплуатации ради общего блага продукта.
Постепенно вокруг этой конференции начало формироваться движение энтузиастов, которое и привело к формированию методологии DevOps.
DevOps – методология
Подобно другим IT-методологиям, DevOps – это такой набор советов, паттернов и ценностей, которые нужно ввести в свою организацию, чтобы оптимизировать проблемные процессы.
Более подробно про DevOps, как методологию, можно почитать в книге «Руководство по DevOps». Эта книга часто всплывает в дискуссиях, как аргумент – «Прочитай DevOps Handbook – и вопросов не будет».
Чтобы не прерываться на чтение книги – если вы её не читали – вынесу один из главных тезисов книги. DevOps строится на применении в работе трех принципов:
Принцип системного подхода. Этот принцип нацелен на формирование понимания всеми, кто принимает участие в создании продукта, что система важнее, чем каждый из её компонентов. Что это значит на практике:
Нужно понимание того, как выстроен поток работы между компонентами-отделами. В большинстве случаев, поток данных идет от отдела разработки к отделу эксплуатации. Написали патч – его нужно выкатить.
Этот поток работы всегда нужно пытаться увеличить. Хорошим методом для этого является автоматизация и создание инструментов. Если будут инструменты, сводящие к минимуму рутинные действия, то для продуктивной работы появится больше времени.
Нужно стараться не передавать некачественные изменения ниже по потоку. Если у разработчика новая версия приложения положила ноутбук – не следует в попытках сделать побыстрее передавать эту новую версию эксплуатации, чтобы она уронила теперь уже сервер.
Нельзя допускать, чтобы улучшение работы одного отдела или команды шло в ущерб системе в общем. Да, отдел эксплуатации может выдвинуть требования перекрестного ревью кода перед деплоем и добиться повышения аптайма своих тестовых серверов, но это затормозит процесс разработки.
Нельзя допускать пустого перекидывания задачами от отдела к отделу с формулировками вроде «Это не наша зона ответственности». В идеале DevOps зона ответственности у всех одна – конечный продукт, общая система.
Общая идея этого подхода в том, чтобы все участники разработки и эксплуатации видели систему в целом. Конечный продукт разработки – это не только код или инфраструктура, на которой он крутится. Это система, и понимание этого – очень важно.

Принцип обратной связи. Если первый принцип был про течение задач между разными отделами и подразделениями, то второй – про потоки информации. Тезисно:
Большая часть современного ПО – крайне сложные системы, которые включают в себя множество компонентов, зачастую неочевидно связанных. Иногда сказать почему выросло, например, время ответа в какой-то системе – совсем непростая задача. Вариантов может быть множество. Изменения в коде? Деградация железа? Проблемы со стороны ПО партнёров? Избыток служебного трафика в сети?
Чаще всего высокая сложность таких систем затрудняет анализ проблем, если за него берется всего один участник разработки или эксплуатации. Если разработчик в понедельник выкатил релиз, а в нем время ответа выросло на 20% – разработчик может биться над проблемой несколько дней, катая туда-сюда версии. Потому что корреляция не означает каузацию и выросшее время ответа могло быть вызвано, например, DDoS’ом на балансировщик, о существовании которого он может и не знать.
Чтобы проблемы можно было оперативно решать, по ним нужно давать обратную связь от эксплуатации к разработке и наоборот. Если после релиза серверам стало плохо – скажи об этом разработчикам; если на ровном месте просела производительность – скажи об этом эксплуатации.
Над решением проблем должны работать несколько участников – и от разработки, и от эксплуатации - иначе может оказаться так, что причина проблемы лежит за пределами компетенций решающего.
Знания, полученные при решении проблемы, должны быть разделены с командой, и использованы для предотвращения похожих проблем в будущем.

Принцип непрерывного обучения и экспериментирования. Этот принцип говорит о том, что не нужно бояться ошибок и экспериментов. Вся команда продукта должна, по мере своей возможности, пытаться оптимизировать этот самый процесс. Это может проявляться по-разному:
Самое главное – любой процесс можно оптимизировать. Всегда можно сделать лучше. И попытки оптимизации процессов нужно поощрять, даже если они не выстрелили.
Не нужно бояться тестировать новые технологии или методики. Вполне возможно, что они решают какие-то достаточно болезненные для продукта проблемы, не привнося при этом новых, более страшных.
Хорошим двигателем инициативы для таких экспериментов может быть обратная связь из предыдущего шага. И проблемы, и их решения могут лежать за пределами компетенций столкнувшегося с ними. Коммуникация между отделами и подразделениями, про которую мы уже поговорили, в теории поможет найти неожиданные точки, к которым нужно приложить командные усилия.
Изучение и интеграция новых инструментов приносит пользу всей системе, так как для системы открываются новые – ранее неизвестные способы решения проблем.

Всё это звучит очень круто, но крайне абстрактно. Какие-то стрелочки, кружочки и общие рекомендации. Что со всем этим делать в реальности – не совсем понятно. И поэтому стоит поговорить о более конкретных практиках, которые были сформированы в рамках этой методологии.
DevOps – набор практик
После того, как появились очертания методологии DevOps, развивавшие ее люди, начали конкретизировать довольно общие рекомендации. И выработали несколько практик, применение которых, должно было решить большую часть проблем, подсвеченных докладом-прародителем.
Сразу скажу, что большая часть этих практик – не изобретена в рамках DevOps. Что-то было позаимствовано из других методологий, что-то было раскопано в анналах истории IT, а что-то и вовсе пришло из других профессиональных областей. Давайте поговорим про эти практики, откуда они взялись и что они должны решать. Формулировку я позаимствую у Google – из книги «The Site Reliability Workbook».
1. Никакой обособленности
Традиционно между направлениями разработки и эксплуатации существует разрыв по целому ряду пунктов – у этих двух направлений совершенно разные цели, зоны ответственности, а порой и дистанция до бизнеса.
Цель разработки – внесение изменений. Изменение логики, добавление новых фич, рефакторинг. Все эти задачи нарушают статус-кво, потенциально повышая нестабильность системы в общем. Все ошибаются и рано или поздно (а скорее всего, при выкатке на прод, по заветам Мёрфи) какой-то код что-то сломает. И его надо будет исправить – снова внося изменения.
Условный KPI разработчика выражен в том, как много он смог создать полезных для продукта изменений.
Цель эксплуатация – повышение стабильности. Приведи систему к стабильному, надежному, устойчивому состоянию – и всё замечательно. Для эксплуатационного инженера идеальна ситуация, когда сегодня всё работает идеально, как работало вчера. Ну и чтобы всё оставалось так же завтра – вообще мечта. Есть, конечно, запланированные апгрейды и обслуживание, но они обычно рассматриваются как ситуации близкие к аварийным. Работает – не трогай без нужды.
Условный KPI эксплуатации выражен в том, насколько они смогли минимизировать нестабильность в общей системе.
Уже на этом этапе мы начинаем видеть очертания проблемы: чем больше разработка вносит изменений, тем больше вероятность, что они создадут проблемы для эксплуатации; соответственно, чем меньше эксплуатация хочет вносить изменений, тем медленней разработка сможет реализовывать свои основные задачи.
Зона ответственности разработки – код продукта, который они разрабатывают. При этом команду разработки зачастую не особо интересует инфраструктура, на которой их код будет развернут – они не вникают в детали того, какие аппаратные и программные средства нужны для работы их кода.
Представитель команды разработки вполне может не знать, что внутри стоек у них оптика с пропускной способностью 40 гигабит, а наружу линк всего на 10. И когда локальные тесты – на машинах в одной стойке – спокойно переживают новую фичу, гоняющую 25 гигабит трафика, он уверенно релизит в прод свой микросервис, который польет 25 гигабит наружу, а затем положит ночью продакшен сервер.
Зона ответственности эксплуатации – инфраструктура, которая нужна для продукта. При этом зачастую команда эксплуатации не особо интересуется как устроен этот продукт, его релизными циклами и вообще всем, что касается разработки.
При этом когда новый релиз складывает продакшен-сервер багом, зачастую первой на него реагирует эксплуатация. Именно им прилетают первые алерты, именно они подрывается посреди ночи поднимать упавший сервер, именно их не поставили в курс деталей новой фичи, успешно релизнутой разработчиками. Взаимное незнание двух отделов положило продукту сервер.
Из-за того, что разработка и эксплуатация отвечает за разные компоненты системы и их целевые показатели эффективности различаются, они могут создавать друг другу проблемы. В примере выше разработчик попортил условный KPI отделу эксплуатации, вычеркнув пару девяток из устойчивости продукта, а отдел эксплуатации своим отчетом попортил KPI разработчику, справедливо указав, что хоть прод и лежал – случилось это из-за некачественных изменений в коде.
Остается загадочный пункт «дистанция до бизнеса». Сразу оговорюсь, что это справедливо далеко не всегда и не везде, а во многих компаниях – уже полностью пережиток прошлого. Однако стоит помнить, что движение DevOps создавалось более десяти лет назад и тогда эта ситуация была намного актуальней.
Бизнес и разработка – на короткой ноге. Именно к отделу разработки бизнес приходит, чтобы они реализовывали новые фичи и повышали ценность продукта. Обычно в глазах бизнеса, разработка – главный источник прибыли. Именно улучшение программного продукта приносит бизнесу деньги – программная часть продукта почти всегда перед глазами.
Бизнес и эксплуатация – далеки друг от друга. Зачастую работа команды эксплуатации бизнесу не видна – и в прямом, и в переносном смысле. Традиционно пока всё работает, об эксплуатации никто не вспоминает, и только когда что-то ломается – бизнес слышит новости со словами «датацентр», «аплинк» и «бэкап». И бизнесу, и клиенту не видна инфраструктура, которая нужна для приложения – некоторые о ней даже не задумываются.
Повторюсь – это скорее историческая сноска, сейчас уже почти повсеместно бизнес начал понимать, что без представителей эксплуатации все новые фичи разобьются о неготовность инфраструктуры к ним. Однако слишком часто мне приходилось слышать истории от обиженных и оскорбленных админов, инженеров, операторов, которые пытались объяснить бизнесу что Ops Lives Matter важность инфраструктуры, но были обделены вниманием, бюджетом и свободой действий.
При присутствии хотя бы одного из моментов выше между разработкой и эксплуатацией может быть взаимная неприязнь, конкуренция, а то и вовсе вражда. Когда представители одного из этих направлений видят только свою часть истории, им кажется, что вторая половина уравнения играет против них.
Методология Agile настаивает на необходимости взаимодействии бизнеса и разработки. В рамках DevOps эксплуатации нужно плотно сотрудничать с разработчиками, сокращая свою дистанцию до бизнеса, чтобы все участники слышали друг друга.
У представителей бизнеса, разработки и эксплуатации должны быть точки соприкосновения и пересечения, где у представителей разных направлений есть одинаковая возможность сказать своё слово.
У разработки и эксплуатации есть общая цель, потому что код и инфраструктура, на которой он крутится, – это только части общего продукта.
2. Ошибки – это нормально
Невозможно разработать хоть насколько-то сложный продукт без багов; невозможно застраховаться от ошибок и отказов со стороны инфраструктуры. Когда команды разработки и эксплуатации не работают друг против друга, а имеют общие цели, они могут это друг другу признать. Когда оба направления могут признать друг другу возможность своей ошибки, они могут сообща работать над более устойчивыми системами и процедурами, где учтена возможность ошибки.
Индустрии с высокими рисками – вроде авиаиндустрии и здравоохранения – обнаружили, что поиск виноватого при разборе инцидентов приводит к большим проблемам, чем должен решать. Когда каждый участник системы боится оказаться виноватым и получить санкции, у всех появляется мотивация заметать следы, умалчивать об ошибках и пытаться подставить невиновного. Чтобы решить эту проблему, была создана культуры отсутствия вины, где допускается, что человек мог совершить ошибку и без злого умысла, а решение проблемы важнее поиска виноватого.
Внимательно следим за руками: раз и «культура отсутствия вины» теперь важная часть DevOps практик. Потому что указание пальцем на виновного приводит к попыткам сокрытия правды, затягивает решение проблем, а то и вовсе приводит к перетягиванию одеяла на свой отдел и замиранию продукта.
В рамках этой практики DevOps рекомендуется считать, что если где-то была допущена ошибка, то надо вместе работать над процедурами, которые позволят избежать повторения этой ошибки. Если мы не можем исключить фактор человеческой ошибки, то нужно делать систему и все её компоненты максимально к этим ошибкам устойчивыми
3. Изменения должны быть постепенными
В большинстве случаев конечный продукт крайне сложная вещь. И со стороны кода, и со стороны инфраструктуры. С учетом того, что мы допустили неизбежность ошибок, масштабные изменения в системе почти всегда что-то ломают. И чем больше это изменение, тем трудней установить, что именно стало причиной поломки.
Эта идея не нова, в ней нет ничего революционного. Насколько мне известно, она появилась в рамках всё того же Agile, но вполне вероятно, что идея витала в воздухе и до этого.
Куда проще разобрать что именно сломало работу приложения, если вы постепенно обновляли по одному компоненту, и точно знаете на каком именно всё сломалось. Откатить такое изменение тоже проще. Если система не монолитна, есть вероятность того, что небольшое изменение сломает не все ее компоненты. Это справедливо и для инфраструктуры, и для кода.
Увеличение количества изменений и уменьшение их объема имеет одно неприятное последствие – соответственно растут количества рутинных действий. И эту проблему призвана решить следующая практика.
4. Выбор инструментов и создание культуры их применения
Для решения прикладных задач DevOps предлагает так называемый tooling. Этим словом называют выбор инструментов, которые будут применяться в команде и разработкой, и эксплуатацией.
Мы признали, что ошибки бывают и это норма. Стоит признать и то, что люди, в основном, не очень хорошо справляются с повторением одинаковых действий раз за разом. Человек может ошибиться, отвлечься, опечататься, не выспаться и прочее.
Если разработчик будет по 20 раз на дню собирать новый образ руками, то риск ошибки увеличится. Не сегодня – так завтра. Та же история и у админа, которому нужно поменять конфигурацию на пуле серверов. С другой стороны, машины очень хорошо справляются с выполнением одних и тех же действий раз за разом. В этом, собственно, и есть суть компьютеров.
Поэтому, например, в рамках CI/CD, инструменты и практики которой тоже плотно приросли к DevOps, предлагается все повторяющиеся процессы в интеграции и доставке ПО автоматизировать.
Как и повелось, заимствованная практика развивается чуть дальше. Помимо непрерывной интеграции и доставки, DevOps предлагает использовать общие инструменты во всех возможных областях. Разработчики хранят код в репозитории? Почему бы команде эксплуатации не хранить в соседнем инфраструктурные конфиги. Автоматизировали тестирование и деплой? Отлично, теперь давайте автоматизируем плановое обновление ПО.
Первая часть этой практики о том, что нужно добавлять в команду инструменты, которые будут делать жизнь легче, автоматизируют рутину, снизят вероятность и стоимость ошибок. Если нет готовых инструментов – их нужно создавать. И эта практика возвращает нас к эпохе зарождения Unix, когда роли разработчиков и администраторов серверов были неразделимы. В книге «Время Unix» Брайана Кернигана упоминается забавный эпизод:
Я написал эту программу, но в центральный репозиторий не выложил, так как не хотел, чтобы люди думали, будто я им что-то навязываю.
Когда Дуг Макилрой спросил, разве не здорово было бы, если бы мы могли осуществлять поиск внутри файлов, я ответил, что мне нужно подумать до завтра. А утром принес эту программу, которая оказалась ровно тем, что он хотел.
Это слова Кена Томпсона, а речь идёт об утилите grep, название которой, я думаю, знакомо всем админам unix-подобных систем. Идея о необходимости создания инструментов, облегчающих эксплуатацию систем, руками тех кто их эксплуатирует старше движения DevOps как минимум на три десятилетия.
Вторая часть – про то, как создать культуру использования этих инструментов. Если было принято решение катить изменения кода через пайплайн CI/CD – это должно выполняться всеми членами команды. Никто не должен ходить напрямую на сервер и править текстовые файлы в vim. Какой смысл в подключении, а то и создании, крутых инструментов, если ими никто не будет пользоваться?
5. Метрики – это очень важно
Командам разработки и эксплуатации нужно определить, что реально важно для продукта и начать эти вещи отслеживать. Вновь ничего нового, любой админ знает, что мониторинга много не бывает (в отличие от алертов), а любой разработчик понимает важность внутренних метрик производительности приложения.
В интерпретации методологии DevOps, эта практика про определение реально важных метрик и объектов для мониторинга и предоставление взаимного контекста для них.
Когда админ видит в мониторинге высокую нагрузку на диск и рост ожидания ввода-вывода у процессорных операций, он может не знать, что сейчас происходит. Не будет знать, является ли такая нагрузка следствием ошибки или штатным поведением. У админа без разработчика нет контекста, нужного для понимания во время каких операций со стороны приложения эта нагрузка растет. Возможно это было нагрузочное тестирование на объеме в десять раз больше целевого, возможно это новая норма.

В свою очередь разработчик, который видит отчет от программы, не справившейся с важным расчетом вовремя, может не знать, что стало проблемой: неэффективный алгоритм, нехватка ресурсов от полезной нагрузки, троттлинг процессора, умирающий диск и высокий iowait или что-то ещё.
Вырванные из контекста метрики хоть и полезны, но не всегда позволяют понять, принесли ли пользу последние изменения или это чья-то ошибка. Только совместными усилиями можно связать состояние системы с операциями в приложении и решить, насколько это всё для продукта важно.
Помимо мониторинга разрабатываемой системы, метрики можно снимать и с других процессов. Если вы внедрили CI/CD можно замерить насколько увеличилась (или упала) частота релизов, как изменилось количество дошедших до продакшена ошибок. Так можно выявлять проблемные компоненты системы – и сосредотачивать усилия команды на них.
DevOps – трансформация
Отлично! Мы разобрались с практиками. Звучат они местами не менее абстрактно, чем методология, но уже хотя бы понятно, что делать. А зачем вот это всё?
Конечной целью DevOps – как методологии и набора практик – так называемая DevOps-трансформация. Это такое состояние внутренних взаимодействий внутри системы, где разработка и эксплуатация вместе трудятся на благо общего проекта. Где каждый участник понимает, как устроен этот продукт со стороны кода и инфраструктуры, и осознает, что ни одна его часть не является исключительно важной. Где коммуникация важнее бюрократии. Где мы за всё хорошее и против всего плохого.

Однако стоит оторваться от теории и посмотреть на реальность, как начинают возникать вполне справедливые вопросы.
DevOps – специалист
Например, хороший вопрос: почему висит столько вакансий специалистов DevOps и подавляющее их большинство – не про трансформацию?
Как будто конечный результат не нужно достигать внутри организации, постепенно внедряя практики, сближающие существующие отделы разработки и эксплуатации. Можно просто взять специалиста эксплуатации, добавить немного знаний разработки, полить сверху смузи, перемешать – и вот вам моментальный DevOps.
А ведь добавление нового элемента, выполняющего роль прослойки между эксплуатацией и разработкой не способствует выстраиванию коммуникации между командами, а скорее наоборот. Какой смысл разработчику говорить с админом, ведь они друг друга не понимают. Давайте отправим на переговоры нашего DevOps – они явно найдут общий язык.

Если это противоречит самой идее всей методологии, почему появился спрос на DevOps-специалистов?
Потому что любая красивая теория при попытке её применения сталкивается с самыми разными аспектами реальности, где всё не сферическое, а вакуумом даже и не пахнет.
Где-то эксплуатация и инфраструктура отданы на аутсорс – тяжеловато интегрировать в команду стороннего специалиста, для которого ваш продукт не существует за пределами очередного тикета в списке задач.
Где-то взаимодействия отделов погрязли во внедряемой сверху бюрократии, и попытки её избежать грозят взаимными санкциями от начальства.
Где-то админы при словах Agile и DevOps начинают кривить лицо так, будто им предложили что-то непристойное.
Где-то разработчики при словах «Мы не можем просто закидать проблему ресурсами» кривят лицо не хуже админов из прошлого пункта, и требуют заменить сервер вместе с админом.

В реальности всегда существуют подводные камни, грабли, а то и вовсе глубоководные мины, и далеко не всегда красивые методологии из книг позволяют их все обойти.
Однако движение это возникло не на пустом месте. Все озвученные в рамках методологии проблемы имеют место, и их решение безусловно идет на пользу разрабатываемому продукту. Поэтому вместо порой недостижимой трансформации ищут трансформера.
Но что этот трансформер должен знать и уметь?
DevOps – технологии
Есть довольно длинный список технологий, инструментов и даже целых направлений в IT, который желательно знать специалисту DevOps. Важно понимать, что эти знания не являются чем-то исключительным для DevOps, однако именно наличие компетенций в этих областях чаще всего требуют от DevOps-специалиста. Я не стал придумывать список требуемых навыков и технологий, а взял его из популярной дорожной карты DevOps.
Язык программирования.

Представители: Go, Python.
Что дает: возможность автоматизации задач, возможность создавать инструменты, понимание процесса разработки ПО.
Зачем: по поводу необходимости мне особо нечего сказать. Умение программировать в IT нужно всем. Возможно и не только в IT.
Комментарий: роадмап советует выбрать Go, а не Python, и почему-то ставит в один ряд с ними C++, Ruby и C. Не уверен, что автоматизировать мелкие задачки с помощью C++ – хорошая идея, но это вопрос вкуса.
Навыки эксплуатации

Представители: знание ОС, знание сетей, знание ПО.
Что дает: представление о том, как работают базовые компоненты инфраструктуры.
Зачем: не уверен может ли DevOps существовать без этих знаний. Это основы знаний для любого представителя эксплуатации. Как можно эксплуатировать системы и не понимать их устройства – вопрос открытый.
Комментарий: без комментариев.
-
Базовые концепции устройства ОС
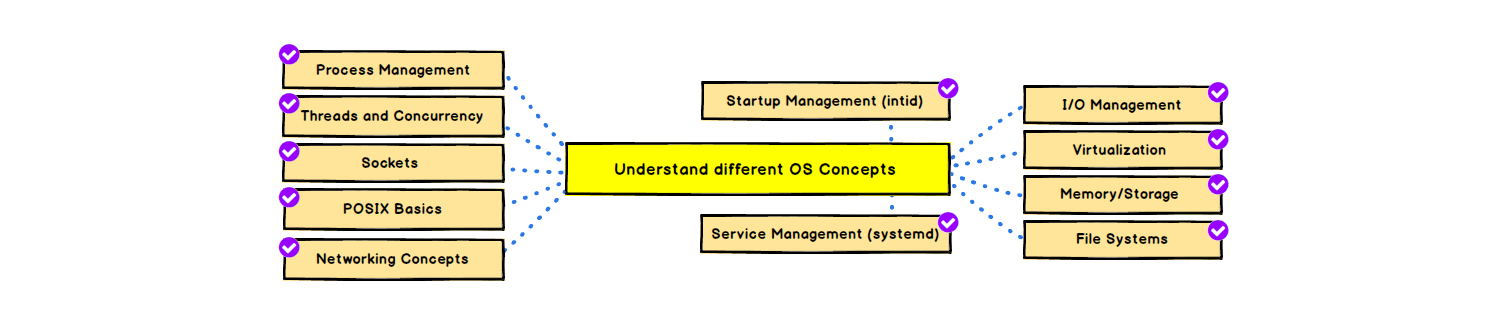
Представители: виртуализация, файловые системы, POSIX, сокеты и основы сетей. Управление процессами, загрузкой и сервисами. Работа с аппаратными ресурсами.
Что даёт: понимание того что происходит под капотом системы и как всё это устроено.
Зачем: рано или поздно, у вас что-то Сломается с большой буквы С. И тогда высокоуровневые знания инструментов и методологии вам не особо помогут. Вам придется читать RFC или лезть в разделы man, посвященные сигналам и соглашениям.
Комментарий: насколько глубоко нужно закапываться в каждый компонент – сложный вопрос. Есть книга о принципах управления памятью в Linux Understanding the Linux Virtual Memory Manager Мэла Гормана. В ней буквально построчно разбирается исходный код ядра Linux, отвечающий за управление памятью. Когда вы дошли до этой книги – или её аналога о другом компоненте ОС – вы, скорее всего, зашли слишком далеко.
-
Администрирование ОС

Представители: Linux, Windows, BSD.
Что дает: возможность управлять системами, на которых работают все нижележащие технологии.
Зачем: еще один базовый навык, который пригодится каждому. Ничто не крутится в вакууме – все проекты и технологии рассчитаны на запуск на какой-то операционной системе. Если у вас что-то сломается на низком уровне, будьте добры иметь навыки администрирования. Сюда же я запишу навыки работы в терминале во всём своем многообразии.
Комментарий: касательно выбора семейства ОС – я бы однозначно советовал Linux. Знания BSD/Windows лишними не будут, но значительная часть современных технологий крутится именно под управлением пингвина. Я с Линуксом вместе уже лет 15, и ни разу не пожалел, кроме того случая с Bumblebee, кривых драйверов от Atheros, и...
-
Сети и протоколы

Представители: базовое устройство сетей, DNS, маршрутизация, фаерволл. Протоколы: HTTP, HTTPS, SSL/TLS, SSH.
Что дает: понимание того, как один компьютер говорит с другим.
Зачем: скорее всего ваш проект и его инфраструктура не будут представлены одиноким сервером, лежащим посреди пустыни Гоби, а значит будет сетевая активность. А где есть сетевая активность, ее нужно понимать, настраивать и контролировать.
Комментарий: роадмап советует получить хотя бы поверхностное понимание, но устройство сетей и сетевых технологий – очень глубокая и сложная тема. Опять же, если вы дошли до «Компьютерных сетей» Таненбаума – бегите, если вам дороги ваша жизнь и рассудок.
-
Web-серверы и стандартный набор ПО

Представители: Nginx, IIS, Apache.
Что дает: понимание того, как публикуются Web-приложения.
Зачем: скорее всего, у вашего проекта будет хоть один веб-интерфейс. Возможно, их будет много. Скорее всего большая часть этих интерфейсов будет выставлена в мир с использованием специализированного веб-сервера. Сюда же добавлю пункт про понимание того, как устроены прямые и реверс-прокси, кэширующие сервера и балансировщики.
Комментарий: опять же, даже если ваш проект – не веб-приложение, у окружающей его инфраструктуры будут веб-интерфейсы – от репозиториев проекта до мониторинга. И рано или поздно их придется настраивать.
Инфраструктура как код

Представители: управление облачной инфраструктурой, mesh-сети, управление конфигурацией, контейнеризация, оркестрация контейнеров, CI/CD.
Что дает: возможность хранить информацию об инфраструктуре, как код.
Зачем: сохранение информации об инфраструктуре в виде кода дает огромное преимущество. Если кто-то что-то захочет изменить – изменение будет публично видно; это изменение можно будет проверить и, если нужно, откатить. Первичность кода над инфраструктурой также гарантирует, что у вас не будет запаздывать документация – вы описываете системы кодом, а потом он уже превращается в машины, пайплайны и конфиги.
Комментарий: тут речь идёт об общем подходе хранения инфраструктурной конфигурации, как кода. Дальше речь пойдет о более конкретных применениях.
-
Облачная инфраструктура как код

Представители: Terraform, Cloudformation.
Что дает: возможность декларативно описывать выделяемые под проект ресурсы – серверы, сети, DNS-записи.
Зачем: В составе инфраструктуры больше не остается белых пятен, если все серверы описаны как код. С IaC вы можете поднимать системы, аналогичные вашей текущей на другом облачном провайдере – если проект ожидает переезд.
Комментарий: К сожалению, эта история – про облачную инфраструктуру. Если ваш проект не в облаке – вполне вероятно, что заказывать инфраструктуру средствами кода выйдет. Существует возможность разработки собственного terraform provider’а для API платформы, где вы заказываете ресурсов, но это возможно не всегда.
-
Service mesh

Представители: Istio, Consul.
Что дает: возможность контролировать сетевую активность компонентов микросервисного приложения.
Зачем: если ваш проект состоит из стаи микросервисов, вы наверняка знаете, насколько сложной и запутанной может быть карта их взаимодействий. Service mesh позволяет добавить ещё один уровень абстракции, который позволяет управлять этими взаимодействиями с помощью кода. Вы можете явно прописать, где и как должна работать балансировка нагрузки, снимать информацию о проходящем через сервис трафике и многое другое.
Комментарий: как прошлая история была про облачную инфраструктуру, так эта – про микросервисную архитектуру. Если ваш проект монолитное приложение – вам не особо пригодится service mesh.
-
Конфигурация как код

Представители: Ansible, Chef, Puppet.
Что дает: возможность описывать изменения вносимые в конфигурацию ОС и приложений как код
Зачем: управление большим количеством серверов вручную – боль. Установка и обновление пакетов, изменение политик фаерволла, изменение расписаний в планировщике – это тривиальные задачи, если вам нужно сделать их на одной машине, и настоящий кошмар наяву, если вам нужно сделать их на нескольких десятках машин. Управление конфигурацией как кодом решает эти проблемы. Вы описываете конечное состояние, к которому хотите привести машину – и автоматика выполняет все действия за вас. Плюс такой подход решает проблему с “Я настроил сервер для определенных задач, но уже не помню как, а теперь этот сервер умер и мне нужно поднять новый”.
Комментарий: тяжело описать словами, насколько сильно конфигурация как код упрощает работу. От простых задач вроде “добавить везде нового пользователя” до сложных сценариев, где с нуля устанавливаете и конфигурируете всё серверное ПО – всё это можно сохранить в виде кода и переиспользовать по мере необходимости.
-
Контейнеризация

Представители: Docker.
Что дает: возможность замораживать рабочее окружение приложения, чтобы потом запускать его где угодно.
Зачем: для запуска приложений требуется определенный набор ПО, зачастую вполне конкретных версий. Контейнеризация приложения позволяет декларативно – в виде кода – описать нужный набор ПО, выполнить все необходимые для запуска шаги и, что самое главное, запускать этот контейнер на самых разных системах. Ваш разработчик сидит на Windows, а приложение работает под Linux? Дайте разработчику Dockerfile, и он сможет локально у себя поднять контейнер с приложением, в котором он может экспериментировать как угодно. Вы обновили версию ОС на серверах? Приложение внутри контейнера этого даже не заметит.
Комментарий: контейнеризация приложений встречается повсеместно. Количество плюсов, которые этот подход даёт, значительно перевешивает количество минусов. Однако, опять же, это возможно не всегда и не везде.
-
Оркестрация контейнеров

Представители: Kubernetes, Nomad, Docker Swarm.
Что дает: возможность управления сложными комбинациями контейнеров
Зачем: перефразируя поэта, ни одно приложение не является островом. Почти всегда у приложения есть несколько компонентов, от которых оно зависит. А ещё возможно приложение нужно масштабировать горизонтально. Все эти задачи (и многие другие) решает оркестрация контейнеров. Вы можете описать, что с приложением вместе нужно раскатывать его зависимости, можете описать как распределять по разным машинам отдельные инстансы приложений, и всё это, опять же, хранить как код в репозитории, чтобы это не было тайным знанием.
Комментарий: А ещё вы можете очень смешно выстрелить себе в ногу. Попытки запихать всё, что только можно, в оркестрируемые контейнеры может печально закончится, если приложение не писалось для работы в такой среде. Оркестрация, как и все остальные технологии, это не панацея для всех проблем, а просто инструмент. Инструмент мощный, довольно многофункциональный, но абсолютно не универсальный.
-
CI/CD

Представители: Gitlab CI, Github Actions, Jenkins.
Что дает: автоматизацию рутинных процессов – сборку, тестирование, деплой.
Зачем: мы уже говорили про то, что люди склонные ошибаться на рутинной работе. И мы опять перекладываем эту работу на неутомимые плечи автоматики. Возможность автоматически собирать, тестировать и деплоить ПО значительно сокращает накладки на ручной труд. А ещё эта автоматизация тоже хранится код. А значить её можно переиспользовать, ей можно делиться, она не является секретом.
Комментарий: мы выше описали целую-кучу-вещей-как-код. От управления инфраструктурой до добавления пользователей. И знаете что? Если всё это – код, значит выполнение этого кода тоже можно автоматизировать с помощью CI/CD. Внесли изменение в код, описывающий вашу инфраструктуру – автоматика пойдет и сама создаст эту машину. Решили изменить версию ПО в конфигурации для ряда машин? Поправили код – отработал пайплайн – автоматика сама пошла обновлять машины, и её отчет будет виден всем, а не только на вашем ноутбуке.
Трансформация инфраструктурных решений в код – это шаг к повышению надежности, прозрачности и масштабируемости этой самой инфраструктуры.
Мониторинг

Представители: мониторинг инфраструктуры, мониторинг приложений, управление логами.
Что дает: возможность увидеть здоровье системы.
Зачем: без мониторинга вы оперируете вслепую. Если вам неизвестно в каком состоянии инфраструктура, размещенное на ней приложение, и что в этом приложении происходит – говорить об эксплуатации этого всего невозможно.
Комментарий: мониторинга много не бывает, а вот алертов по нему – легко. Когда настраиваете свой мониторинг, постарайтесь, чтобы алерты приходили только по реально важным вещам. Для этого маловажные алерты нужно завернуть в какой-то отдельный поток, и обращаться к ним только в случае инцидентов. Ни один нормальный живой человек не сможет за рабочий день среагировать на 400 алертов, и рано или поздно этот человек начнет их игнорировать, просто от неизбежности.
-
Мониторинг инфраструктуры
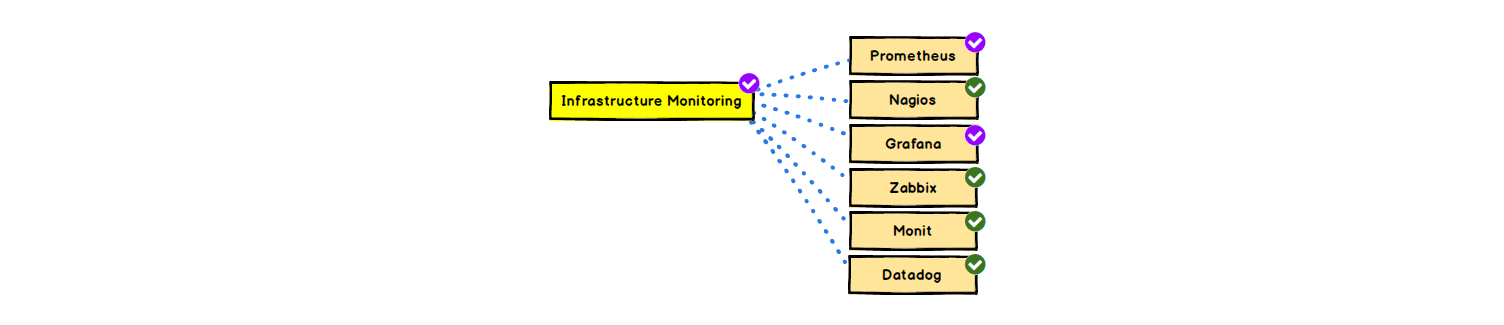
Представители: Prometheus, Zabbix, Nagios.
Что дает: возможность увидеть здоровье инфраструктуры.
Зачем: если вы не понимаете зачем мониторить состояние инфраструктуры, вам следует подучить материалы из второго пункта этого роадмапа. Никакие системы не крутятся в вакууме – облака, кластера контейнеров, mesh-сети развернуты рано или поздно упираются в виртуальные машины, железо и вполне физические сети. Деградация чего-то на низком уровне повлияет на все вышележащие абстракции, и если вы этого не увидите – хуже вам.
Комментарий: не уверен, что тут нужны какие-то комментарии.
-
Мониторинг приложений

Представители: OpenTracing, Jaeger, Sentry.
Что дает: возможность увидеть, что происходит внутри приложений.
Зачем: мы уже говорили о том, что важно понимание состояние продукта в целом. Как без понимания состояния инфраструктуры, так и без понимания состояния приложений, картина получается неполной. Если будет видно, что и сколько в приложении отрабатывает, можно будет определить бутылочные горлышки в системе, которые могут быть не видны на инфраструктурном мониторинге.
Комментарий: встраивание трассировки и мониторинга в приложения требует либо определенных навыков программирования, либо, как и завещала методология DevOps, кооперации с командой разработки.
-
Сбор логов

Представители: ELK, Splunk, Graylog.
Что дает: возможность получать журналы событий от множества машин и приложений.
Зачем: агрегация логов от множества компонентов системы дает возможность к анализу комплексных инцидентов. Не все вещи можно отловить мониторингом, и иногда исторический срез журналов позволяет получить информацию о том, что фиксировала система, и что фиксировало приложение.
Комментарий: в рамках все той же кооперации вы можете попросить команду разработки добавить в логи приложения отслеживание каких-то нужных вам метрик. Не хватает статистики времени выполнения операций – договоритесь и она появится. Вы, в свою очередь, можете предоставить команде разработки единый интерфейс, где они могут смотреть логи своих приложений и, если им это надо, связанных с ними систем.
Облачные технологии

Представители: Облачные провайдеры, архитектура приложений в облаке.
Что дает: знания и навыки для работы с облаками.
Зачем: значительная часть современных проектов разрабатывается для облаков, живет в облаках и будет плохо себя чувствовать без них. Многие инструменты из списка выше затачивались под облака. Незнание того, как работать с облаками, может ограничить доступные для вас проекты.
Комментарий: в мире достаточно проектов и без облачной инфраструктуры – на ней свет клином не сошелся. Но в последние годы процент облачных проектов только растет, и рост этот пока не спешит замедляться.
-
Облачные провайдеры
Представители: AWS, Azure Cloud, DigitalOcean.
Что дает: понимание того, как развернуть инфраструктуру проекта в облаке.
Зачем: работа с тем же AWS настолько отличается от работы с классической – не облачной – инфраструктурой, что приходится многому переучиваться. Работа с такими облаками – отдельный технический навык, и тоже требует изучения документации.
Комментарий: Даже если ваш текущий проект не работает с облаками – научиться будет не лишним. Вполне возможно, что следующий проект уже будет в облаке.
-
Отказоустойчивая архитектура в облаке

Представители: масштабируемость, доступность.
Что дает: возможность эксплуатации облаков на полную.
Зачем: облака предоставляют большие возможности в масштабировании ресурсов (как горизонтальном, так и вертикальном). Не меньшие в повышении доступности, путем географического распределения сервисов.
Комментарий: я, честно говоря, не очень хорош в облачной архитектуре – еще изучаю этот вопрос. Комментарии лучше получать от практикующих экспертов, поэтому я от комментариев воздержусь.
Вот мы и прошлись по этой большой страшной карте технологий DevOps. Она, честно говоря, покрывает далеко не все технологии и инструменты, которые могут оказаться нужны, как на низком, так и на высоком уровне. Требования под каждый проект индивидуальны: где-то вам не понадобится оркестрация контейнеров, где-то потребуются знания принципов аутентификации.
Однако у некоторых представителей Ops-направления может возникнуть справедливый вопрос: “Стоп! Я большую часть вот этих вот штук знаю, умею, практикую. Это получается я DevOps?”

DevOps – админ
Если посмотреть на инструменты и задачи, которые они решают, то практикующий специалист DevOps это такой системный администратор, присыпанный сверху современными технологиями. Зачем тогда эта приставка Dev?
Давайте начнем с того, что под профессией “системный администратор” в русском языке подразумевается целый спектр специальностей. Традиционно этим словом описывают почти всех, кто занимается инфраструктурной частью IT. Это пошло с самого зарождения IT, когда все непрограммисты были сисадминами.
Мифологизированный башоргом образ админа в коллективном бессознательном – это такой человек-швейцарский нож: он протянет сеть, настроит сервер с сайтом компании, настроит политики безопасности, починит сломавшийся принтер, постучит в бубен, погладит кота и уйдет пить пиво, обнимаясь с не менее мифическим шредером. Открываешь список вакансий по специальности “Системный администратор” и видишь широкий разброс требований к знаниям, технологиям и рабочим задачам.
Конечно, существуют названия профессий, которые более точно описывают конкретную эксплуатационную специализацию. Теперь часто можно увидеть уточнение – хелпдеск, эникей, облачный инженер, инженер инфраструктуры, сетевой инженер и множество других, включая DevOps.
Произошло это из-за того, что с ростом сложности процессов и технологий в информационных технологиях, оказалось, что универсальные специалисты – это дорого, сложно и не всегда возможно. Появилась нужда в специализациях и специалистах.
Этой самой специализацией и является DevOps. Это не админ 2.0, который призван заменить устаревшего админа 1.0 вместе с бубном и шредером, – это просто ещё одна область, в которой может развиваться специалист эксплуатации.
Отличие от обычного инфраструктурного инженера заключается не только в умении настроить kubernetes, но в более высокой степени интеграции в команду разработки и понимании идей, которые лежат в основе движения DevOps. Методология и практики хоть и имели порой труднодостижимую цель, в общем и целом были правы – совместное сотрудничество Dev и Ops приводит к более здоровому продукту, который зачастую добирается до рынка быстрей и остается на нем дольше.
DevOps – инженер или евангелист
В таком контексте мне особенно странно слышать, что не бывает такого понятия “DevOps-инженер", а бывает лишь "DevOps-евангелист". Мы уже адресовали то, почему вместо попыток организационной трансформации в существующие системы встраивают конкретных специалистов, но ведь ничто не мешает реализовывать практики и применять методологию руками DevOps инженера.
В изначальном видении людей, создававших методологию и мечтавших о трансформации процессов, реализация задач методологии была уже в руках инженеров – представителей Dev и Ops. В том случае, когда трансформация их руками невозможна или сложна – её берут в свои руки DevOps. Именно они занимаются созданием новых инструментов, выстраиванием коммуникаций, применением практик.
Ну а тех, кто говорит, что админы (специализируются ли они в DevOps, или нет) не могут быть инженерами я понять не смогу никогда. Поиск решений в сложных информационных системах требует глубокого понимания того, как эти системы устроены.
У моего коллеги есть невероятно крутая способность. Ему можно описать какую угодно схему – будь она частью проблемы или решения – он посидит, подумает и скажет, как сделать лучше, укажет на проблемные места. Умение моделировать в голове поведение сложных системы требует опыта их эксплуатации, понимание устройства как этих систем, так и лежащих ниже их.
Мне совсем понятно, как можно можно быть DevOps-евангелистом, не являясь при этом инженером. Как можно пытаться улучшить процессы, завязанные на системы, которые тебе непонятны?
DevOps – что же это такое?
Простого ответа нет. Единственно верного – тоже. Под этим словом подразумевают много всего: методологию, практики, трансформацию процессов в организации, конкретного специалиста, стек технологий и компетенций, интегрированных в команду разработки инженеров, которые могут быть евангелистами методологии, а могут и не быть. Спросите десять человек – вряд ли получите десять одинаковых ответов. И попытка исключить одну или несколько трактовок всегда дает неполную картину.
Теория, лежащая за этим понятием, и ее применение на практике имеют общую цель – улучшить процесс разработки продукта и получить на выходе лучший конечный результат. Там, где теоретические попытки трансформировать устоявшиеся взаимодействия между отделами не получились, бизнес ищет готовых специалистов, имеющих как минимум технические навыки, которые нужны для эксплуатации разрабатываемого продукта, а ещё лучше – понимание того, какую пользу одноименная методология приносит продукту, и желание её реализовывать.
В таком раскладе может показаться, что из двух половинок Dev и Ops именно эксплуатация вытянула короткую соломинку. Праздник проходит мимо них, всем подавай DevOps. Но это только если считать, что DevOps – не Ops. На практике появилась ещё одно направление, в котором Ops-специалист может развиваться. Многие админы, сами того не осознавая, на самом деле уже давно стали частью этого самого DevOps, даже если они по-прежнему называют себя админами.
В целом отношение к эксплуатации в IT сдвинулась в правильном направлении – сейчас понимание важности и ценности инфраструктуры выросло, как и уровень интегрированности команд разработки и эксплуатации. Я думаю, что хотя бы частично этот сдвиг – результат движения DevOps, и всего что из него произошло.
Не меньше от этого процесса выигрывает и разработка. Технологии и инструменты эксплуатации сильно выросли за последние 15 лет как количественно, так и качественно. Развернуть приложение в kubernetes несравнимо сложней, чем развернуть сайт на LAMP. А потому разрабатываемым проектам нужны эксплуатационные специалисты, у которых будет знание как последних технологий, так и базовых инструментов и принципов, на которых они построены. Артур Кларк писал, что любая продвинутая технология неотличима от магии. Компетентный админ знает, что никакой магии нет. Достаточно заглянуть под ширму красивого блестящего CI/CD-пайплайна – и там будут сотни строк на bash, python, а то и вовсе perl. Без того, кто может и хочет это настроить, конечный продукт будет ограничен в выборе доступных технологий и решений.
Да, нет единственного правильного ответа, на вопрос о том, что такое DevOps. Я рассказал вам о том, какие могут быть ответы, ссылаясь на мнения самых разных источников – книги, доклады, методологии, дорожные карты, вакансии на рынке труда. Везде, где не забыл, я оставил ссылки – и если вы захотите, вы можете изучить те же материалы. Возможно вы придете к выводу, который отличается от моего.
Мне кажется, что DevOps – это что-то на пересечении всего описанного выше. Это методология с англицизмами в качестве названий для простых и логичных практик. Это трансформация устаревших процессов, когда разработка и эксплуатация отказывалась вести между собой диалог. Это набор технологий, который плотно ассоциируется с понятием. Это инженер, который умеет не только планировать и поднимать кластеры чего угодно, но и обсуждать с командой разработки как и зачем им эти кластеры нужны. Это админ, который освоил теорию, имеет практический опыт, и не может избавиться от жгучего желания что-то улучшить. Это все эти вещи – именно через запятую и никак иначе.
Комментарии (14)

ky0
18.02.2022 18:21+1Развернуть приложение в kubernetes несравнимо сложней, чем развернуть сайт на LAMP. А потому разрабатываемым проектам нужны эксплуатационные специалисты, у которых будет знание как последних технологий, так и базовых инструментов и принципов, на которых они построены.
И откуда же, по-вашему, начинающие девопсы получат опыт работы с, как вы это называете, «базовыми инструментами», если всем работодателям подавай высокоуровневые абстракции?
Получается, хорошим девопсом можно стать, только набрав опыт на инфраструктуре без использования «модных» технологий, а затем захотев объять и их? Много вы таких знаете, выросших из админов, а не пришедших сразу в облака и Ансибл с Терраформом?
bananaseverywhere Автор
18.02.2022 18:30+3И откуда же, по-вашему, начинающие девопсы получат опыт работы с, как вы это называете, «базовыми инструментами», если всем работодателям подавай высокоуровневые абстракции?
Получается, хорошим девопсом можно стать, только набрав опыт на инфраструктуре без использования «модных» технологий, а затем захотев объять и их?
Именно так. Без базовых навыков администрирования, все высокие технологии рано или поздно наткнутся на низкоуровневую ошибку, которую не победить, не понимая что находится под ними.
Много вы таких знаете, выросших из админов, а не пришедших сразу в облака и Ансибл с Терраформом?
Честно говоря, большинство. Я не уверен, что смогу назвать девопсов, которые стартанули "с места в карьер", без какого-то опыта администрирования.

gecube
18.02.2022 19:30+2что интересно - я знаю достаточное (но не многое!) количество "devops", выросших из разработки, которым интересно было - как же их система работает. Поэтому, во-первых, не нужно говорить, что девопсы получаются из опсов. Во-вторых, как выше правильно было замечено - нет такого, как девопс инженер. Я уже приводил аналогию. Если девопс - это философия и методология, то давайте разработчиков уж называть "канбан-разработчик", "agile-разработчик"... и прочее
bananaseverywhere Автор
18.02.2022 19:46+1что интересно - я знаю достаточное (но не многое!) количество "devops", выросших из разработки, которым интересно было - как же их система работает. Поэтому, во-первых, не нужно говорить, что девопсы получаются из опсов.
Я тоже знаю пару девопсов, которые выросли из разработки. Так что вы правы, может и не из опсов, что не отменяет необходимости учить "базу".
Во-вторых, как выше правильно было замечено - нет такого, как девопс инженер. Я уже приводил аналогию. Если девопс - это философия и методология, то давайте разработчиков уж называть "канбан-разработчик", "agile-разработчик"... и прочее
Тут проблема в том, что понятие DevOps "пошло в народ". Если посмотреть вакансии по ключевому слову DevOps, большая часть будет не про методологию и трансформацию процессов взаимодействия, а про опсов с конкретным набором технологий.
Я потому и взялся за эту статью - под словом DevOps разные люди подразумевают слишком разные вещи, и мне захотелось посмотреть на путь понятия. Откуда взялось, чем стало в коллективном бессознательном :)
gecube
18.02.2022 20:41Тут проблема в том, что понятие DevOps "пошло в народ". Если посмотреть вакансии по ключевому слову DevOps, большая часть будет не про методологию и трансформацию процессов взаимодействия, а про опсов с конкретным набором технологий.
варианты:
инженер по клаудам
инженер мониторинга
релиз инженер
инженер поддержки (в целом)
сантехник (оке, build engineer или прочищальщик пайплайнов)
...
легион их
Я уж не говорю о том, что часто под вывеской "DevOps engineer" идет вакансия типикал админа, просто с новой лычкой, чтобы не отставать от трендов (и, да, платят конкурентно, но точно так же придется ковыряться в паппете, искать узкие места в базульках и линуксах)

Oll123
19.02.2022 02:11-1Как сказал один мой хороший высокооплачиваемый друг девопс (больше 120к после налогов) - джуниор девопсов не бывает. Прийти ты можешь откуда угодно, если из сетей - то учи программирование, если из разработки, то сеть. Но это все ямл писатель пайплайнов если ты не овнеришь/участвуешь в процессах улучшения процессов в компании.
Куча бывших админов из ops просто не могут больше. Их и нанимают на «девопс, надо что бы сервера и сеть»

Jammarra
20.02.2022 07:15120к это же в долларах в год?
если в рублях в месяц то это даже на Джуна тянет с трудом. А высокооплачиваемые начинаются от 400-500к.
ну и да это фигня все. Девопсы по большей части все же разработчики. Про сеть например фигня, в крупной компании тебя никто к сети не подпустит. Да тебе даже тот же Кубер будет нужен только на самом верхнем уровне. Потому что админить его будут совсем другие инженеры. А у тебя прав не будет.
Твоя задача только помогать разрабам писать манифесты(и то не факт) и обмазывать автоматизацией тесты, сборку выкату в прод и т.д.
Просто классические админы умирают. Те кто успевают учатся кодить и уходят в разрабы. Только разрабы всегда и получали нормально) Это для админов зп в 300-400к огромные деньги. Но какой то хороший разраб на Java их и так давным давно получал.
лет 5 назад у меня другое мнение было. Но я в то время как раз и считал что «100к рублей это большая зп» как только перестал страдать фигней и начал серьезно учить программирование то жизнь резко изменилась.
есть ещё SRE правда. Немного другая тема. Но один черт в первую очередь про разработку и автоматизацию.

elve
21.02.2022 09:50ну и да это фигня все. Девопсы по большей части все же разработчики. Про
сеть например фигня, в крупной компании тебя никто к сети не подпустит.
Да тебе даже тот же Кубер будет нужен только на самом верхнем уровне.
Потому что админить его будут совсем другие инженеры. А у тебя прав не
будет.Т.е. по вашему разработчик не должен понимать технологии с которыми работает? Полагаю, что примерно с такими мыслями, разработчики uTorrent изобретали свой мега-протокол, который до внесения исправлений укладывал провайдерские сети.
Jammarra
21.02.2022 10:03Далеко не каждый разработчик работает с сетями. А что бы делать условные запросы в кафку знание например BGP совсем не обязательно да. А то так можно дойти до того что что бы пользоваться компьютером нужно схемотехнику учить.
Скажу больше я отработав 10 лет админом. Про тот же BGP знаю только то что он существует. Но никогда бы не полез на джунипер или циску его настраивать. На все это в нормальных компаниях есть сетевик который каждый день с сетями работает и которого шансы что он будет менять и что то уронит в разы меньше, чем если бы полез я.
В целом всегда когда мне задают такие вопросы на собеседовании я задаю вопрос в ответ. А у вас настройка сетей входит в должностные обязанности DevOps/linux админа? Если нет то зачем вы спрашивайте?
К слову по вашему если человек пишет приложения для мобильников, ему нужно знать как работают 4g, 3g и т.д.?Нет оно конечно ваше право искать такого разраба который знает все. И Таненбаума может пересказать. И Кнута за обедом цитирует. И литкод по вечерам на максимальной сложности решает.
Это ваше право как компании. Только не удивляйтесь если он ЗП в миллионов 5-10 в месяц попросит. Я даже уверен что где то у FAANG такие разрабы есть в запасниках. И это нормально
Искреннее удивление вызывает когда таких ищут в ООО "Рога и Копыта".Это как Тиньков и Яндекс. Они иногда предлагают пройти собеседования и скидывают список что нужно сдать. Всегда когда смотрю этот список задаюсь вопросом, "если я это буду знать и заучу, то зачем мне сдались эти компании с ним можно и в Гугл пособеседоваться". Если только как разминку их использовать и пробник перед собеседованием в нормальную компанию.
Зачем это все учить ради работы в том же яндексе на 300-400к решительно не понятно. Потому что на 300к на руки в обычную компанию без пафоса собеседование выглядело последний раз так "-О прикольное резюме. Helm, gitlab и werf знаешь? У нас они используются" "-Да" "-Отлично ну подумай хочешь или нет к нам и напиши когда можешь выходить"
elve
21.02.2022 10:58Давайте не будем сразу в крайности бросаться =). Я вижу что у вас своя личная война с сетями, но постарайтесь быть объективнее.
В общем виде, знание сетей (и других смежных областей) разработчику или DevOps-у нужно хотя бы на уровне - продиагностировать проблему и выдать корректную задачу узкому специалисту. Как максимум самому влезть и починить, т.к. обычные проблемы с сетью на стенде это уровень ccna.Что касается разработчика мобильных приложений. Если эти приложения работают с сетью, то разработчику придется погрузиться в эту предметную область и знать как работают используемые им протоколы и также учитывать особенности используемых каналов связи. Иначе может получиться как с uTorrent, когда они переизобретали tcp поверх udp.
То же касается и других смежных предметных областей.

mc2
19.02.2022 07:25+4Почему то большей частью сталкиваюсь с девопсами, которые задают вопросы типа: у нас не работает скрипт из джобы, падает с ошибками "python3 error while loading shared libraries: libpython... cannot open shared object file. No such file or directory" или немогу в контейнере посмотреть логи, там пишет "cd /logs Permission denied". Зато знают как настроить новую джобу в jenkins (не экзотика, просто запросить новую сборку из git).
amarao
Зачем ещё раз пережёвывать одно и тоже вручную? Уже давно есть GPT-3, и она про "это методология" может писать гигабайтами и не напрягаться.
bananaseverywhere Автор
Так это не только методология, про что я и писал :)
В слово вкладывают много понятий, одно из которых - методология, с её абстрактными советами и глобальными целями.