

Фаззинг - это такое тестирование, в котором не надо придумывать тесткейсы, потому что умная машина (или настойчивый алгоритм перебора) делает это за вас.
Но есть с ним одна неприятность - непонятно, как тестировать любую достаточно сложную систему. Мы бы хотели генерировать много тестов и быстро прогонять их, а в итоге приходится каждый раз откатывать состояние окружения, потому что программа пишет что-то в БД. Или входные данные настолько сложны, что их так просто не нагенерируешь.
Поэтому попробуем разобраться, как программу можно делить на части. А также определять, какие части нам нужны, а какие не очень.
Объект исследования
В качестве примера кода для поиска багов я взял исходники osm2pgsql. Эта программа загружает карты в формате OpenStreetMap в базу данных PostgreSQL, чтобы потом их анализировать, растеризовать или экспортировать в какой-то другой формат.
Конечно, шансов найти ошибки в обработке входного файла почти нет, ведь *.osm - это всего лишь xml-файл и типы полей в нём не особенно хитрые. Тем не менее, для демонстрации идеи фаззинга сложных программ osm2pgsql вполне сойдёт: входных данных много, работает с базой данных. При этом код не слишком объёмный (это всё же пример, мы не должны умереть от скуки).
Фаззинг - это динамический анализ. То есть, программу придётся запустить. Поэтому сначала скомпилируем её и настроим всё окружение.
Немного про окружение
Я использую здесь Ubuntu 20.04, поэтому для каких-то других сборок строчки скриптов, связанные с установкой пакетов, могут измениться.
Кроме того, надо скачать для osm2pgsql какие-нибудь входные данные. Открываем openstreetmap в произвольном месте и нажимаем кнопку Export. Часть карты в указанном диапазоне координат сохраняется на диск.

Получился небольшой файл map.osm. Если скормить его в osm2pgsql, то карта загрузится в базу данных. Можно указать ключ -O null, чтобы в базу ничего не записывалось, но подключение при этом всё равно устанавливается. Так что без PostgreSQL+PostGIS не обойтись.
Скрипт для установки
sudo apt-get install postgresql postgresql-contrib postgis postgresql-12-postgis-3 postgresql-12-postgis-3-scripts
sudo systemctl restart postgresql
# создаем пользователя
sudo -u postgres createuser gisuser
# создаем БД для хранения карты
sudo -u postgres createdb --encoding=UTF8 --owner=gisuser gis
# включаем PostGIS для созданной БД
sudo -u postgres psql --username=postgres --dbname=gis -c "CREATE EXTENSION postgis;"
sudo -u postgres psql --username=postgres --dbname=gis -c "CREATE EXTENSION postgis_topology;"
# даём права пользователю
sudo -u postgres psql --username=postgres -c "GRANT ALL PRIVILEGES ON DATABASE gis to gisuser;"Теперь, для простоты, разрешим подключение новому пользователю без пароля. Для этого редактируем файл /etc/postgresql/12/main/pg_hba.conf. В нём нужно добавить одну строчку:
local gis gisuser trustОстаётся только перезапустить СУБД.
sudo systemctl restart postgresqlWe're off to see the wizard
Попробуем поверить в волшебство. То есть, в возможность нахождения сбоев для osm2pgsql целиком. Запустим фаззинг всего приложения с тем входным файлом, что у нас есть, в качестве примера.
Для этого нужно:
Инструментировать приложение
Запустить фаззинг
Получить кучу примеров, вызывающих сбои
Скрипт со всей этой магией
# добываем исходники
git clone https://github.com/openstreetmap/osm2pgsql
cd osm2pgsql
mkdir build
cd build
# инструментируем osm2pgsql
cmake -DCMAKE_CXX_COMPILER=afl-g++-fast ..
AFL_USE_ASAN=1 AFL_USE_UBSAN=1 make
# готовим директории
mkdir in
cp ~/Downloads/map.osm in
mkdir out
# да начнётся фаззинг!
afl-fuzz -i in -o out -- ./osm2pgsql -O null -d gis -U gisuser @@Я подождал сутки для приличия, но никаких вредоносных входных данных не нашлось. Более того, за всё это время так и не завершился анализ первого входного файла. Может быть, я тут что-то сделал не так, и шанс всё-таки был. Но я не очень старался, потому что понятно, что с окружением, которое имеет своё состояние, фаззинг делать неудобно. Например, иногда исследуемое приложение дублируется в памяти с помощью fork. Что при этом будет с подключением к БД, неясно.
Поэтому для фаззинга программы обычно разбиваются на отдельные функции или модули. Либо всё окружение заменяется на "фальшивое", например, с помощью функций-заглушек или внешних программ-эмуляторов.
Мы сосредоточимся на первом варианте. Входные данные в этом случае генерировать несколько проще, но за простоту всё равно придётся заплатить своим временем. Ведь сходу не ясно, какие именно функции надо тестировать. Было бы неплохо проследить, куда входные данные добираются в более-менее неизменном виде.
Такие функции можно назвать “поверхностью атаки”. То есть это часть системы, которая лежит на границе с внешним миром. И на которую этот самый внешний мир со всеми его хакерами может повлиять.

Ищем поверхность атаки
В одной из статей на хабре предлагается искать поверхность атаки вручную.
Для составления поверхности атаки необходимо ПО для аудита кода. Например, это может быть sourcetrail, understand, или подойдёт какая-нибудь популярная IDE. Лучше, чтобы ПО для инспекции кода имело возможность автоматического "рисования" блок-схем. Если у разработчиков уже есть готовые блок-схемы для программ из их проекта, то это значительно облегчит процесс. Если же нет, то искренне соболезнуем. Далее из составленной блок-схемы необходимо извлечь те куски, где тем или иным способом могут попасть на вход данные из недоверенных источников. Так и определяется поверхность атаки. На практике весьма удобно оформлять поверхность атаки в виде майндмап. Поверхность атаки служит не только для составления метрик "безопасности" (code coverage), а также, можно сказать, выступает чеклистом для написания фаззеров.
Так это делать не очень интересно, поэтому в качестве первого приближения того, как входные данные влияют на работу программы, построим её покрытие нашим тестом. Это будет список функций (и выполнившихся строк) с частотой их вызова.
Идея здесь такая:
Если функция часто вызывалась, то, вероятно, у неё на входе много разных данных.
Коробка квадратная, значит внутри что-то круглое.Если данные разные, то внутри кода может быть сложная логика для их обработки.А где сложная логика, там и много ошибок.
Придётся пересобрать osm2pgsql, но уже с инструментированием для сбора покрытия кода. Такое инструментирование современные компиляторы умеют делать сами.
Компилируем, запускаем, генерируем отчёт
# идём туда, где собирали osm2pgsql
...
# меняем переменную окружения при сборке
CXXFLAGS=--coverage cmake ..
make
# запускаем программу
./osm2pgsql -O null -d gis -U gisuser ~/Downloads/map.osm
# генерируем html-файлы с отчётом
lcov -o coverage.info -c -d .
genhtml ./coverage.infoУтилита genhtml разложит кучу html-файлов по всему дереву сборки, но в них легко проникнуть через index.html в текущем каталоге. В этих файлах множество раскрашенных таблиц и картинок. Одни показывают процент покрытия кода, дргугие количество вызовов функций, третьи - какие строчки исходного кода выполнялись, а какие нет.

Начнём смотреть самые часто вызывающиеся функции. Логично, что в нашем примере наиболее "популярные" функции занимаются разбором входного файла. Если точнее, они находятся в исходном файле xml_input_format.hpp.

Тестировать работу разборщика XML не очень хочется, слишком сложные будут обёртки, ведь большинство функций зависит от текущего состояния парсера (открытые теги, уровень вложенности). Поэтому поищем модуль попроще.

И это будет реализация расширяемого буфера. Функция reserve_space много раз вызывается, но код её покрыт не полностью, как видно из картинки ниже. Попробуем написать для неё тест.

Создадим в тесте объект-буфер и будем в цикле несколько раз расширять его. Количество байт, которые нужно добавить, читаются из входного потока.
Текст тестовой программы
#include <iostream>
#include <algorithm>
#include <osmium/memory/buffer.hpp>
int main()
{
unsigned char c = std::cin.get();
osmium::memory::Buffer buf(c);
while (!std::cin.eof()) {
c = std::cin.get();
unsigned char *p = buf.reserve_space(c);
std::fill_n(p, c, c);
std::cout << (void*)p << "\n";
}
}Нужный заголовочный файл подключает ещё несколько других, поэтому просто скопируем каталог osmium, где они все лежат. Компилируется тест с помощью следующей командной строки:
AFL_USE_ASAN=1 AFL_USE_UBSAN=1 afl-g++-fast -I. ./test.cpp Переменные окружения включают нужные санитайзеры, а опция -I даёт возможность использовать #include с угловыми скобочками. Санитайзеры нужны, чтобы обрушивать приложение при некорректной работе с памятью или при обнаружении неопределённого поведения (в терминах стандарта C++), например, переполнения знаковых целых.
Запускаем фаззер примерно так же, как и раньше:
afl-fuzz -i in -o out -- ./a.outНесколько часов работы никакого результата не дали. Может здесь и нет никаких багов, пойдём искать дальше.
Следующая (нетривиальная) часто используемая функция находится в модуле location.hpp:


В ней гораздо больше ветвлений, чем в прошлой, и они имеют неполное покрытие. А входные данные не очень сложные для того, чтобы написать обёртку. Отличный кандидат для тестирования.
Настоящий спойлер, а не просто всякие командные строки
На самом деле, баг в этой функции я увидел глазами. Поэтому, когда не смог его найти с помощью теста, я понял, что делаю что-то не так, и переконфигурировал фаззер.
Функция выбрасывает исключение, если обнаруживает, что входные данные некорректны. Эти случаи нас не слишком волнуют (ведь они уже обработаны). Гораздо интереснее те данные, для которых получается неопределённое поведение. Поэтому генерируемые оператором throw исключения будем игнорировать.
Исходный код тестовой программы
#include <string>
#include <limits>
#include <iostream>
#include "location.hpp"
int main()
{
std::string s;
std::cin >> s;
const char *buf[2] = { s.c_str(), 0 };
try {
std::cout << osmium::detail::string_to_location_coordinate(buf) << "\n";
} catch (const osmium::invalid_location &) {
std::cout << "invalid_location\n";
}
}
Теперь нужно всё это скомпилировать и отдать фаззеру.
Скрипт для инструментирования и запуска
mkdir in
mkdir out
echo 1 > in/1
AFL_USE_ASAN=1 AFL_USE_UBSAN=1 afl-g++-fast -O0 -g ./src.cpp
afl-fuzz -i in -o out -- ./a.outЗа какие-то несколько секунд AFL++ нашёл входные данные, при которых программа аварийно завершается.
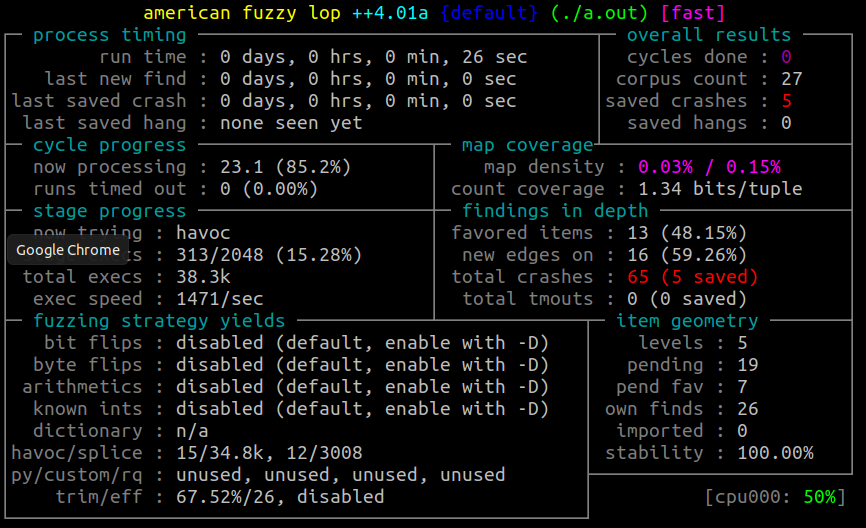
Включённые санитайзеры должны были отреагировать на некорректные обращения к памяти или неопределённое поведение. Заглянем в каталог out/default/crashes:
id:000000,sig:04,src:000003,time:22521,execs:33062,op:havoc,rep:16
id:000001,sig:04,src:000011+000007,time:22831,execs:33526,op:splice,rep:4
id:000002,sig:04,src:000010+000005,time:23704,execs:34783,op:splice,rep:4
id:000003,sig:04,src:000023,time:25888,execs:38012,op:havoc,rep:2
id:000004,sig:04,src:000023,time:25933,execs:38074,op:havoc,rep:4Это файлы с входными данными, вызывающими сбой. К примеру, в первом из них записана строка 4444444444E4. Если запустить нашу программу в отладчике и ввести эту строку, то мы узнаем, где падает программа:

Оказывается, дело в переполнении знаковой переменной result. Вот мы и нашли "дыру".

Получается, в файле можно написать какое-то огромное число типа 8E88, а получится координата, равная 0. Или компилятор почует неладное и удалит весь код. И никакое исключение не сработает.
Ещё более лучшая поверхность атаки
То, что код выполнился, ещё не означает, что он в качестве входа получал хоть что-то напрямую из нашего файла. Вызовы тех же самых malloc/new довольно сложным образом зависят от входных данных. Лучше всего было бы отследить, как байты из файла попадают в функции программы. Прямо как с тем осьминогом из карманной игры. Можно увидеть все щупальца сразу, но лучше знать только про те, которые тянутся непосредственно ко входным данным:


Попробуем проанализировать поток данных с помощью отслеживания пометок. Часто методы анализа помеченных данных используются, чтобы проследить, что пользовательский ввод не попадает куда не надо. Например, не перезаписывает регистр-указатель инструкции EIP. Мы же просто попробуем узнать, куда именно доходят данные.
С инструментами отслеживания помеченных данных (для программ на C++) дела обстоят не очень хорошо. Из инструментов уровня приложений есть libfdt64, использующий фреймворк Pin. Он только позволяет явно проверять, достигли ли помеченные данные нужной точки. Это может пригодиться на защиты каких-нибудь SQL-запросов, но для наших целей подходит не особенно хорошо. Мы ведь не можем легко и удобно проинструментировать все обращения к памяти.
Можно засунуть нашу программу в виртуальную машину и применить полносистемный эмулятор. Потому что для полносистемного анализа есть широко известный в узких кругах инструмент Panda. С ним можно получить список инструкций, которые обращались к помеченным данным. Получается объёмный отчёт, из которого ещё как-то надо выделить нужные нам функции. Возиться с этим пока не хочется, оставим на следующий раз.
Другой вариант, известный в ещё более узких кругах - инструмент Natch от ИСП РАН. Он тоже на основе QEMU, как и Panda, поэтому подготовленный образ виртуальной машины не пропал даром.
План такой:
Настраиваем виртуальную машину
Записываем сценарий работы виртуальной машины
Воспроизводим сценарий и отслеживаем потоки данных
Выводим поверхность атаки
Фаззим полученные функции
Подготовить образ легко. Я брал дистрибутив Ubuntu 20 и ставил внутри него всё то, что нужно для компиляции и работы osm2pgsql, как это уже делалось выше.
Командные строки для запуска эмулятора
# создаем пустой образ диска
qemu-img create -f qcow2 ubuntu20.qcow2 100G
# запускаем эмулятора для установки ОС
qemu-system-x86_64 -m 4G -hda ubuntu20.qcow2 \
-cdrom ubuntu-20.04.3-live-server-amd64.iso
# перезапускаем эмулятор для нормальной работы
qemu-system-x86_64 -m 4G -hda ubuntu20.qcow2Чтобы анализировать работу приложения, лучше всего записать нужный сценарий средствами QEMU. Тогда его потом можно будет воспроизводить многократно для анализа. Это очень удобно, если понадобится поменять что-то в настройках анализатора, ведь не придётся делать все действия внутри виртуальной машины заново.
Но перед этим выгрузим собранный внутри виртуалки бинарный файл osm2pgsql и загрузим туда же файл с картой. Для этого можно смонтировать образ диска в хостовую систему, а потом переместить файлы.
После чего запустим в эмуляторе исследуемую программу.
Командные строки для записи и воспроизведения
# создаем overlay для диска, чтобы сохранять состояния виртуальной машины
qemu-img create -f qcow2 -b ubuntu20.qcow2 -F qcow2 ubuntu20.diff
# записываем работу ВМ
qemu-system-x86_64 -m 4G \
-monitor stdio -net none \
-icount shift=auto,rr=record,rrfile=record.bin,rrsnapshot=init \
-drive file=ubuntu20.diff,if=none,id=disk \
-drive driver=blkreplay,if=none,image=disk,id=disk-rr \
-device ide-hd,drive=disk-rr
# перед тем, как запустить исследуемое приложение, сделаем снимок ВМ
# с помощью команды монитора savevm start
# запускаем приложение внутри ВМ
...
# закрываем эмулятор
# воспроизводим работу ВМ с сохранённого состояния start
qemu-system-x86_64 -m 4G \
-monitor stdio -net none \
-icount shift=auto,rr=replay,rrfile=record.bin,rrsnapshot=start \
-drive file=ubuntu20.diff,if=none,id=disk \
-drive driver=blkreplay,if=none,image=disk,id=disk-rr \
-device ide-hd,drive=disk-rrВнутри виртуальной машины мы, понятное дело, запускали osm2pgsql, как и раньше. Только теперь этот сценарий был записан на втором шаге скрипта. Можно запускать воспроизведение и любоваться, как всё работает само. А можно анализировать этот сценарий с помощью Natch. Для этого придётся создать пару конфигурационных файлов и дополнить командную строку.
Первый конфигурационный файл, natch.cfg, отвечает за общие настройки. В нём также есть пара ссылок на вспомогательные файлы.
natch.cfg
# threshold value for tainting. should be in decimal number system [0..255]
[Taint]
threshold=250
on=true
# section for loading map files and binaries
[Modules]
config=api.cfg
[Tasks]
config=task_struct_offsets.iniОдна из ссылок - файл api.cfg. В него нужно вписать те исполняемые файлы, из которых будет подгружаться символьная информация. Иначе мы получим на выходе после анализа лишь набор адресов. Поэтому впишем в этот конфиг исполняемый файл osm2pgsql, добытый из виртуальной машины.
api.cfg
[Image1]
path=osm2pgsqlПоследний файл - task_struct_offset.ini - генерируется автоматически при первом запуске Natch. В нём хранятся параметры, специфичные для используемого ядра Linux. Чтобы получить этот файл, просто запустим Natch с любым достаточно долго работающим процессом (загрузка ОС подойдёт). Возьмём командную строку для воспроизведения работы ВМ и добавим к ней Natch:
Запуск воспроизведения с начального состояния ВМ, чтобы она подольше поработала
qemu-system-x86_64 -m 4G \
-monitor stdio -net none \
-icount shift=auto,rr=replay,rrfile=record.bin,rrsnapshot=init \
-drive file=ubuntu20.diff,if=none,id=disk \
-drive driver=blkreplay,if=none,image=disk,id=disk-rr \
-device ide-hd,drive=disk-rr \
-os-version Linux -plugin natch,config=natch.cfgТеперь всё готово для анализа. Следующий скрипт уже загружает тот снимок виртуальной машины, start, который мы создали для ускорения анализа.
Запускаем Natch
qemu-system-x86_64 -m 4G \
-monitor stdio -net none \
-icount shift=auto,rr=replay,rrfile=record.bin,rrsnapshot=start \
-drive file=ubuntu20.diff,if=none,id=disk \
-drive driver=blkreplay,if=none,image=disk,id=disk-rr \
-device ide-hd,drive=disk-rr \
-os-version Linux -plugin natch,config=natch.cfgПосле того, как скрипт отработает, появятся файлы surface_functions.txt и surface_modules.txt. Нам понадобится первый, в нём записано, какие функции обращались к помеченным данным и сколько раз они это делали. Для модуля osm2pgsql мы получили такой набор функций.
_ZN6osmium6detail29string_to_location_coordinateEPPKc |
604483 |
_ZN6osmium6detail15parse_timestampEPKc |
472531 |
_ZN6osmium19string_to_object_idEPKc |
136790 |
_ZN6osmium6detail15string_to_ulongEPKcS2_ |
120138 |
_ZN6osmium7builder25RelationMemberListBuilder10add_memberENS_9item_typeElPKcPKNS_9OSMObjectE |
11043 |
_ZN6osmium2io6detail9XMLParser13start_elementEPKcPS4_ |
11043 |
_ZZN6osmium2io6detail9XMLParser13start_elementEPKcPS4_ENKUlS4_S4_E0_clES4_S4_ |
11043 |
_ZN6osmium7builder25RelationMemberListBuilder10add_memberENS_9item_typeElPKcmPKNS_9OSMObjectE |
11043 |
_ZZN6osmium2io6detail9XMLParser7get_tagERNS_7builder7BuilderEPPKcENKUlS7_S7_E_clES7_S7_ |
1267 |
_ZN6osmium14RelationMemberC1ElNS_9item_typeEb |
1 |
Список довольно компактный, поэтому разберём их все. Функцию string_to_location_coordinate мы уже анализировали в предыдущем разделе, и там нашёлся баг.
Функция parse_timestamp переводит строку в unixtime, используя функцию timegm. При этом некорректно проверяется число дней февраля в зависимости от года. Правда фаззинг тут бессилен, так как никакого переполнения, как в прошлый раз, не происходит. Просто на выходе будет ерунда, если задать что-то вроде 29 февраля 1999 года.
Следующие функции string_to_object_id, string_to_ulong просто обёртки для strtoul с небольшими наворотами. Вроде бы нечего тестировать.
RelationMemberListBuilder::add_member берёт на входе число и строку, а вызывает несколько функций, пополняющих список. Выглядит так, что её можно протестировать с помощью фаззинга следующего кода:
Тест для фаззинга add_member
#include <iostream>
#include <algorithm>
#include <osmium/memory/buffer.hpp>
#include <osmium/builder/osm_object_builder.hpp>
int main()
{
osmium::memory::Buffer buf(0);
osmium::builder::RelationMemberListBuilder builder(buf);
while (!std::cin.eof()) {
int ref = std::cin.get();
std::string role;
std::cin >> role;
try {
builder.add_member(osmium::item_type::node, ref, role.c_str(), role.length());
} catch (const std::length_error &) {
}
std::cout << builder.size() << "\n";
}
}
Для теста пришлось сделать функцию builder.size() публичной, чтобы у кода был хоть какой-то побочный эффект (защита от оптимизаций кода компилятором не помешает). Обработчик же исключения появился здесь после того, как фаззер нашёл входные данные, где это исключение выбрасывается. Больше ничего хорошего не нашлось.
В итоге не проверенными остаются только функции из парсера XML и конструктор RelationMember, который почитал какой-то один помеченный байт.
Итоги
Исследуемое приложение оказалось проще, чем я ожидал. Изначально я рассчитывал, что приложение работает со сложным бинарным форматом pbf, а оказалось, что в нём только xml, пожатый с помощью одной из типовых библиотек. Альтернативным форматом оказался уже распакованный вариант, osm, обработка которого не предусматривает особых ветвлений и циклов. Так что вполне логично, что нашлась всего пара багов. В следующий раз выберу что-нибудь поизощрённее.
"Когда верстался этот номер" появилась новость об уязвимостях в библиотеке libexpat, предназначенной для парсинга xml. А osm2pgsql как раз эту библиотеку использует (по найденной поверхности атаки это прекрасно видно) и можно было бы попробовать потестировать разбор формата xml. С другой стороны, такие тесты уже есть в репозитории с самой библиотекой. Всё-таки фаззинг не так прост.
emaxx
Целочисленное переполнение без понятного вектора атаки - как-то слабовато. Как правило, большинство переполнений безобидны (приведут к некорректной работе, но не взлому); исключения бывают, но редки.
На мой взгляд, при целенаправленном поиске уязвимостей надо включать только ASan, но не UBSan. Отчёты последнего разгребать тоже можно, но скорее только когда слишком много свободного времени...
Dovgaluk Автор
Всё так.
Так тут и UB не особо ловились. Либо программа хорошая, либо я плохо ловил. Либо оба.
Может есть предложения, какую ещё программу поковырять?
emaxx
Chrome? :) Там можно и подзаработать: https://bughunters.google.com/about/rules/5745167867576320 .
Ну либо драйверы всякие. Там обычно много чего находится (правда, многое на практике маловероятно при условии корректно работающего железа).