
Всем привет, читатели Habr! В этой статье я расскажу как я познакомился с GraphQL, что это такое и как мне удалось совместить его с JsonSerializable.
Шел 7 месяц работы в моей первой компании. В целом, работой я был доволен, однако платили мало. Повышение должно было быть только через 2 месяца, поэтому я решил перестраховаться и получить офер, на тот случай, если меня не устроит новая ЗП. Начал отправлять резюме и одна из компаний попросила сделать тестовое, где нужно было получить информацию о миссиях SpaceX с использованием GraphQL. С этим аналогом REST API я был не знаком и моим первым шагом стало ознакомление с технологией, а потом уже выбор пакета и реализация задания.
Что же такое GraphQL?
Как я написал выше, это аналог REST API. GraphQL был разработан в Facebook (теперь уже Meta). Он чем-то напоминает SQL, а именно тем, что у него есть свой синтаксис для составления запросов. Используется в основном для загрузки данных с сервера.
Из его основных характеристик можно выделить следующие:
Позволяет клиенту точно указать, какие данные ему нужны.
Облегчает агрегацию данных из нескольких источников.
Использует систему типов для описания данных.
Meta создала GraphQL в следующих целях: вместо того, чтобы иметь множество "глупых" endpoint, лучше иметь один "умный" endpoint, который будет способен работать со сложными запросами и придавать данным такую форму, какую запрашивает клиент. Если некоторые данные хранятся, допустим, в MySQL, а другие PostgreSQL, то данная технология призвана облегчить получение данных с разных источников. То есть при работе с REST API вы выполняете “синхронно” запросы, чтобы получить агрегированные данные (для этого вам нужно несколько endpoint), то с GraphQL вы можете делать это “параллельно” (написав один умный endpoint). И этот умный endpoint называется запросом.
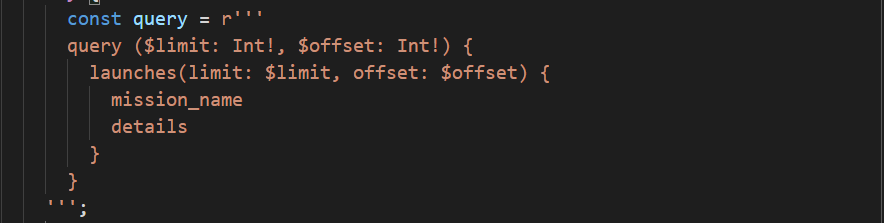
На картинке выше вы можете увидеть пример такого запроса. Я думаю прочитав его можно понять, что мы запрашиваем список из всех миссий. Каждая миссия включает в себя имя и детали. Также тут есть параметры: limit и offset. Первый из них указывает, сколько миссий мы должны получить после выполнения запроса, а второй - с какого индекса в массиве мы будем получать данные.
GraphQL позволяет не только получать данные, а и создавать. Это называется операцией мутации (аналог POST). Если вы хотите более подробно ознакомиться с GraphQL, то настоятельно рекомендую к прочтению эту статью.
Время делать тестовое
После прочтения статьи на Habr у меня появилось базовое понимание, что представляет собой данная технология и я перешел к выбору пакета, чтобы начать делать тестовое. Спустя час ресерча я остановился на graphql. Документация мне показалась понятной, почему бы и нет.
Первым шагом нам нужно создать клиент, куда необходимо передать ссылку на источник и создать CacheManager. Если с первым все понятно, то вот со вторым у меня самого еще остались вопросы.

После того как мы создали клиент, мы уже можем писать и выполнять запросы. Посмотрев, как выглядит сериализация\десериализация данных в документации, я понял, что что-то здесь не то… (можно сказать, что ее вообще нет)

И в этот момент я понял, что это является проблемой и ее нужно как-то решить.
Думаю большинство из нас знакомы с замечательным пакетом для сериализации\десериализации json объектов - JsonSerializable. С помощью аннотации мы можем пометить любую модель, которая должна уметь конвертироваться в json и из json. Дальше, на основе кодогенерации, пакет генерирует два метода: toJson() и fromJson(Map<String, dynamic> json). И у меня появилось сильное желание совместить как-то эти 2 пакета.
В начале я полез в Google, однако либо я плохо искал, либо инфы не было, в итоге я ничего не нашел, поэтому начал придумывать решение самостоятельно.
Кроме GraphQL, я конечно же использовал REST API. Сперва мой выбор пал на chopper, потом я перешел на retrofit + dio. И вот первый пакет, в отличие от второго, не умеет работать с JsonSerializable из коробки. Для этого нужно написать свой класс парсер, после чего передать его в клиент. Выглядит он так.

Как мы можем понять, этот класс умеет декодировать либо одну модель, либо список моделей. А большего вроде и не нужно. Для этого нам нужно в словаре factories указать все модели, которые способен обрабатывать парсер. Ключом у нас является тип модели, а ее значением - метод fromJsonFactory, который нужно прописать в модели после кодогенерации JsonSerializable. Необходимо сделать его статическим.

После всех этих манипуляций я перешел к следующему этапу. Надеюсь большинство из вас знакомо с паттерном Repository, который отвечает за получение данных. Ко мне в голову пришла идея создать класс BaseRepository, который будет содержать в себе класс парсер, что позволит нам параметризовать все наши запросы.

Этот класс позволяет нам получать одну модель и список всех моделей. Далее мы можем унаследовать от него любой наш репозиторий для вызова методов. Вот, например, мой репозиторий, который отвечает за миссии SpaceX.

Таким образом я решил одну из главных, лично для меня, проблем. После того как я реализовал еще поиск, отправил задание на проверку и спустя день получил офер на 1500$ (однако остался все-таки в своей компании, хотя через 4 месяца все равно ушел :) ).
На этом у меня все. Спасибо тем, кто дочитал до конца! Вот ссылка на этот репозиторий.