

«You Only Live Twice», (1967)
Развитие микроэлектроники, ИТ технологий и широкого спектра программных продуктов открыло новые возможности по контролю всего. Датчики, камеры, цифровые следы… Магнитофон в чемодане уже неактуален.
Разработчики пишут, а компании внедряют различные системы для мониторинга эффективности работы сотрудников. Казалось бы, в зоне опасности банковские операционисты, кассиры, сотрудники колл-центров и т.д, а разработчики на коне.
По факту оказывается, что разработчики могут находиться под куда более жестким контролем.
Как же так???
Рука рынка
Поскольку это хорошо монетизируется, эту тему весьма активно продвигает множество компаний, начиная от ITSM консалтеров и завершая гитлабом. Называется эта тема VSM, расшифровывается как Value Stream Management (есть и чуть другие трактовки, например, M — Metric, но это надо отдельно сопоставлять).
Просто для примера, запрашиваем у поисковика Value Stream Management и получаем сразу широкий спектр:
- Gitlab. View and manage end-to-end processes.
- Производитель ПО Tasktop. Why Value Stream Management for Software Delivery?
- ITSM консалтер Cleverics. Гайд по Value Stream Mapping (VSM): выгоды, процедуры, ценность
Много слов, много картинок, готовность сразу принять кэш. Неизбежность грядет…
Все пропало, все пропало, Матрица наступает.

Контроль почти всегда удручает, но тяжело серьезно поспорить с этим в рамках рабочей деятельности. С точки зрения бизнеса, если программный продукт не выходит согласно роадмэпу, то действительно надо понимать почему и как это исправить. Соблюдение сроков — элементарные обязательства перед заказчиками, внутренними или внешними. Каждый день отставания — как минимум, потеря средств и реноме. Мы же тоже, приобретая заблаговременно билеты на концерт или поезда, ожидаем, что все гарантированно произойдет невзирая на всякие возможные веские причины «у них».
Если нельзя избежать, то можно возглавить и обратить это движение во взаимную пользу. При этом совершенно необязательно за VSM платить бешеные суммы, можно собрать такую штуку на DS стеке, причем функционал будет гораздо мощнее.
Для начала пробежимся тезисно по входным данным. Альфа и Омега.
#1. Разработчики работают во множестве систем. Это и почта и порталы и траблтикет система и репозиторий и много чего другого. Казалось бы, что это является проблемой.
Однако, это совсем не так, скорее, наоборот. При поставленном процессе труд разработчика может быть прецизионно оценен по цифровым следам, поскольку все регламентировано и метки должны быть осмысленными и значимыми.
#2. Метрик может быть много разных, но глобально их можно разделить на два основных класса:
- количественные описания артефактов;
- временные характеристики блоков процесса.
Т.е. кто что делает и как долго с этим возится.
Очевидно, что все решения начинают свое движение от системы ведения задач. Назовем условно «Jira». Из Jira можно достать много всякой информации о задачах, подзадачах, их тегах, статусах, временах и пр… Простая статистика по атомарным атрибутам может дать массу различных срезов, чем и пользуются коммерческие решения. Много графиков и цифр — есть ощущение управляемости.
Вполне понятно, почему ITSM консультанты идут в эту тему.
Естественно, что есть процесс разработки, который каким-то образом, автоматизируется в Jira. Можно вычисляемые метрики дополнительно привязывать к процессу, заниматься ручным выравниванием процессов и т.п.
Немного наукообразия
Однако, это все плоско и скучно.
Отступим на шаг в сторону. Что мы видим? Видим же мы совокупность различных конечных автоматов (state machine), реализованных в различных информационных системах. Во всех системах есть набор записей, осуществляемых под учетной записью разработчика (или робота), содержащего, как минимум, три основных поля:
timestamp, user_id, event_idИдеальная площадка для применения технологии Process Mining. Причем на задачу надо смотреть сразу шире, собирать сразу все. Процессная стыковка данных из различных систем для DS инструментов не является каким-то сложным вопросом. Методологически — да, надо понимать где как матчить события и идентификаторы, как расщеплять или дополнять события, как делать синтетические вставки, как нормализовать справочники по шкале времени и т.д… Но технологически это все решается без проблем.
Реконструкция транзакций дает честные ответы на все вопросы и метрики, про которые рассказывают консультанты. Все эти Lead Time/Cycle Time/Setup Time/… могут быть посчитаны для определенных путей и транзакций, можно построить распределения и увидеть многомодальность, посчитать различные стат. метрики. Картографирование процесса, сверка со стандартом и т.п. осуществляется машиной, а не человеком.
Напомню, как это все выглядит в исходном виде («лапша» или «сортировочная станция») и после применения мат. алгоритмов.
«Сортировочная станция»
«Чистый процесс»
Для демонстрации пример рабочего места такого аналитика, DAG, статистика, фильтры, выборки, трейсы. Все, что полагается...
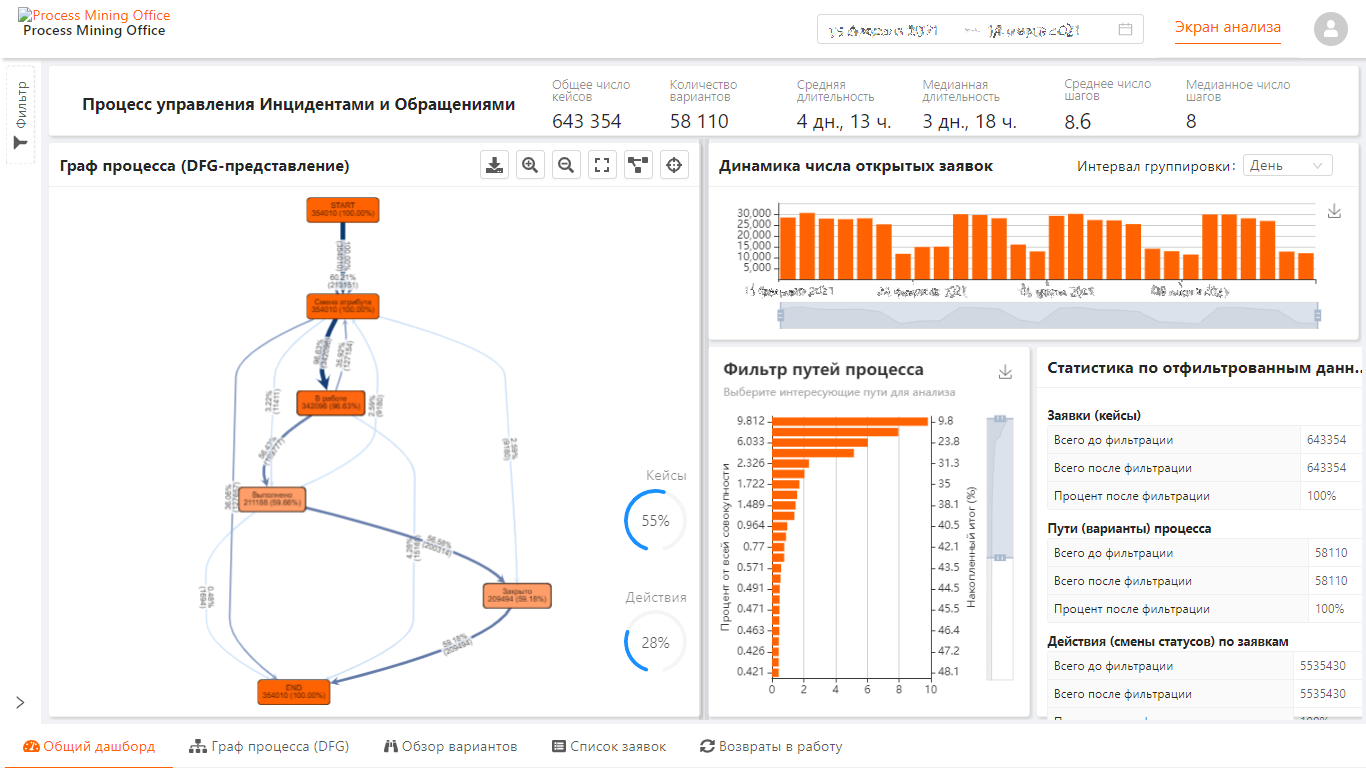
DAG и сводка
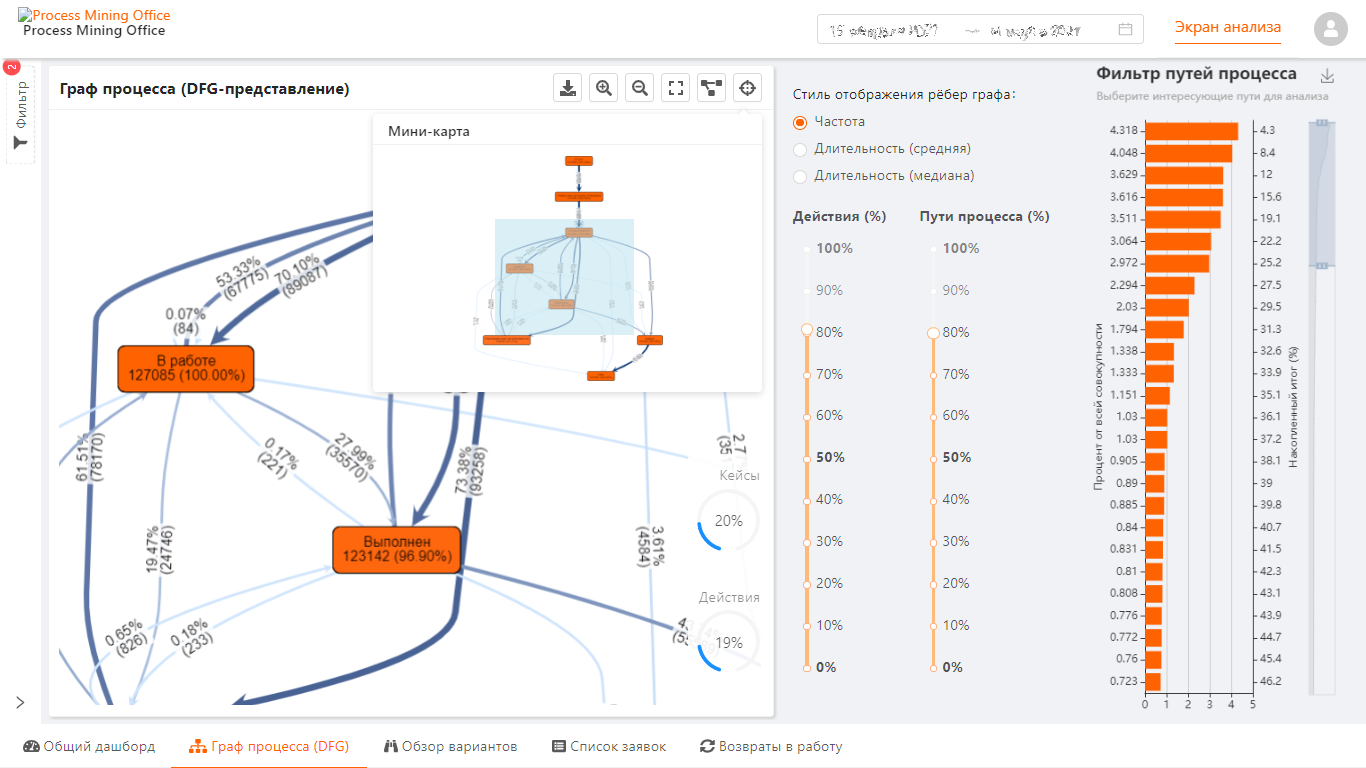
Детализация и «ползунки» настройки
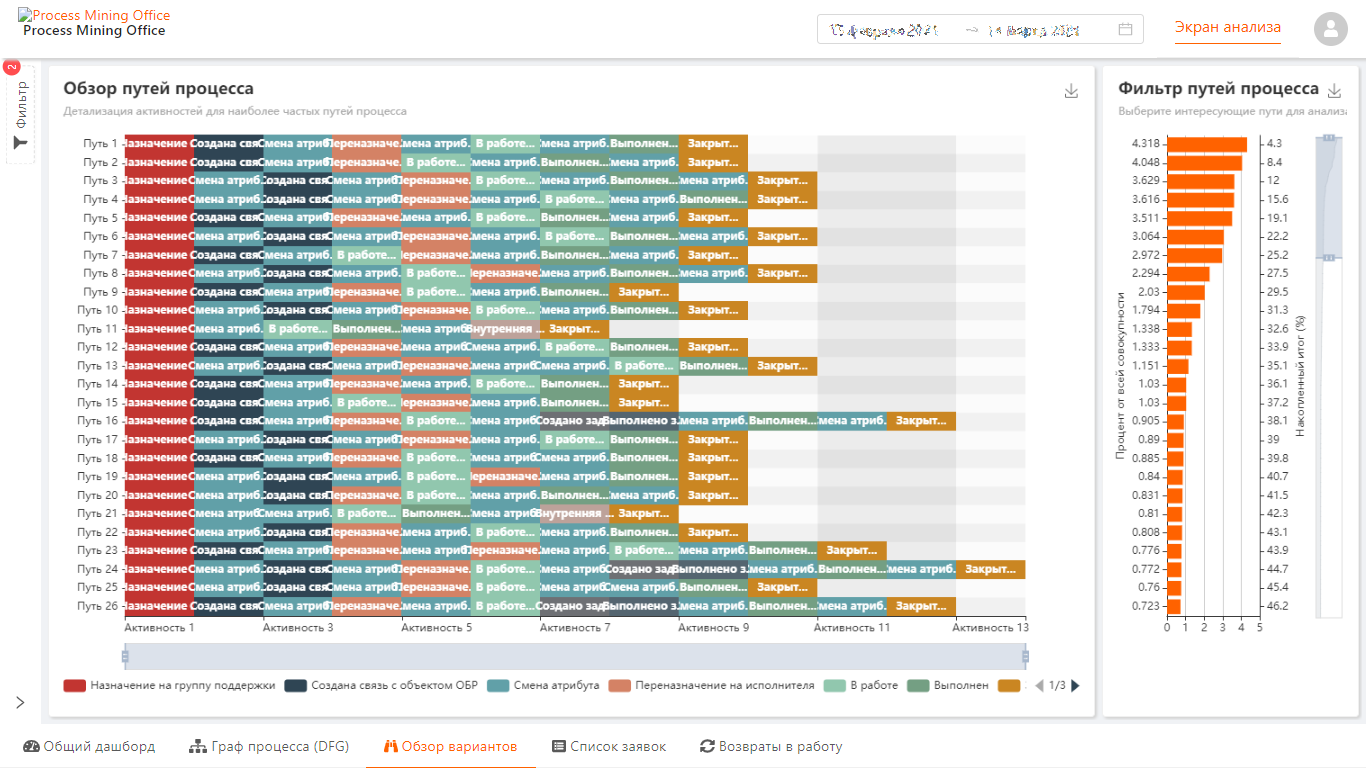
Трейсы
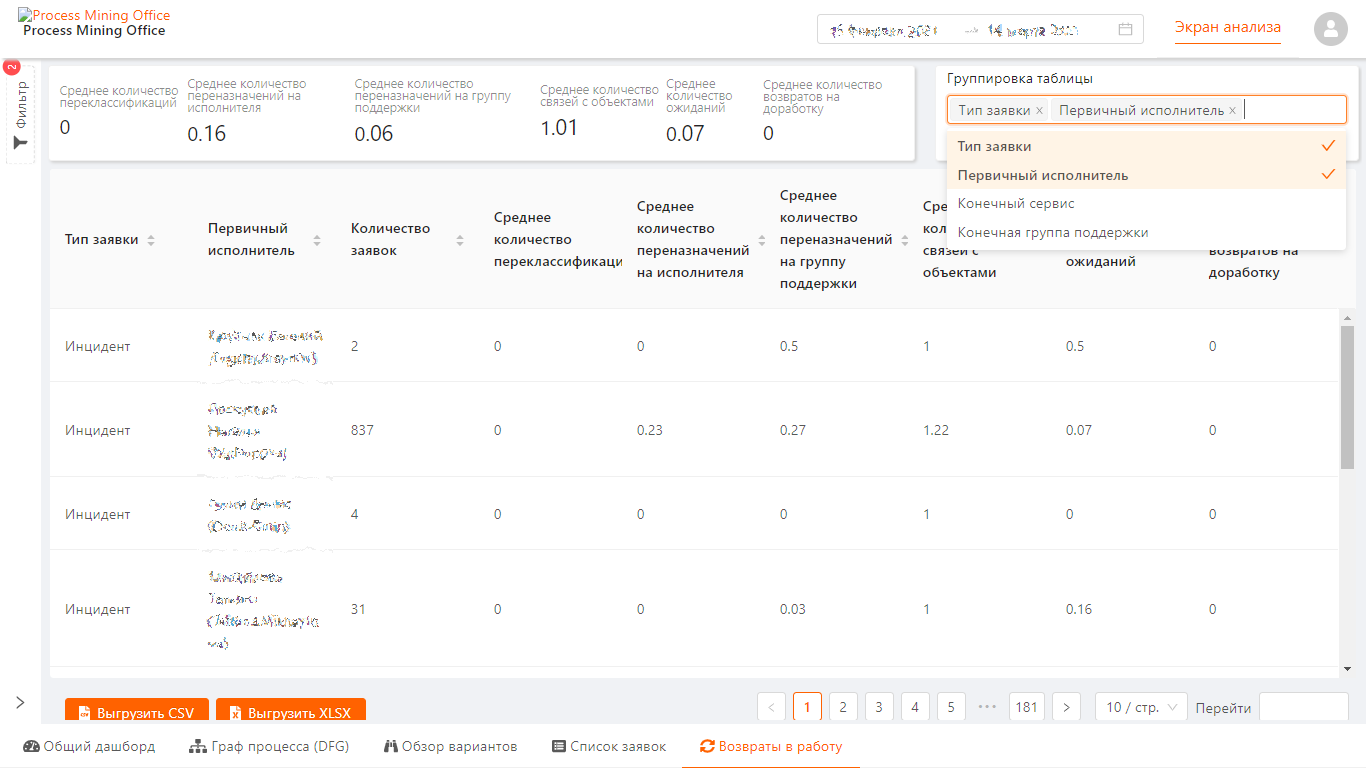
Табличные представления
Шаг в сторону dev
Серьезной интересной связкой является Jira + Git. т.е. когда мы строим процессы по событиям из двух систем сразу. Тут и постановка задач и продвижение по задаче, тут и работа с готовыми артефактами. Репорт в таймтрекер и коммит в гит — совсем разные вещи.
После чуть более глубокого погружения становится очевидным, что к словам консультантов, анализирующих только Jira (а таких в тематике VSM большинство), можно относиться только как говорил Барон Мюнхаузен: «Нет, я говорю сущую правду и берусь ровно через час доставить вам из богдыханского погреба бутылку такого вина, в сравнении с которым ваше вино – жалкая кислятина.»
Именно связка Jira + Git, при должном выстраивании процесса разработки, позволяет построить всю цепочку от «педалить код» до получения реальной ценности в виде фичи, модуля или продукта. В гите остается крайне важный блок, отвечающий за принятие проведенных доработок в конечный продукт.
Маршрут merge-request — merge-to-dev — merge-to-release долог и болезнен.
- Не исключены возвраты на доработку или отказы от проведенных доработок.
- Появляются интересные метрики, связанные с фальшстартом (коммиты по задаче пошли до ее перевода в работу) или же двойным учетом (коммиты шли после формального завершения задачи).
- Временные характеристики могут быть пересчитаны с учетом принятия доработок в релизный код.
- Можно состыковать открытые дефекты с исходной задаче. Быстро не всегда значит качественно!
- Лапша из задачек и подзадачек может быть собрана в единый трейс в рамках процесса.
- При наличии CI/CD можно расширить аналитику и на этап «Deploy», много интересного вскроется.
Для примера — плотность вероятности для времен начала и окончания задач (из тех, что раньше стартовали или позже завершились)… Видна явная бимодальнось — надо детально разбираться с элементами каждого класса отдельно.

Отклонения, связанные с «ранним началом» и «поздним завершением» дочерних задач, имеют существенно более важное значение для процесса по сравнению с Git Commits самой Story
Опыт применения технологии Process Mining позволяет однозначно утверждать — халявщикам и халтурщикам скрыться невозможно. Хороший аналитик (да, как для анализа рентгенограмм, для анализа наблюдаемых картинок надо немного тренироваться) вскроет любую фродовую схему и достанет из любого уголка. Добавление же четвертого измерения (время) позволяет сравнивать разработчика самого с самим и смотреть на его динамику. При негативном тренде самое время подключаться HR специалистам и разбираться с проблемами в коллективе.
Но ведь в создании качественных и конкурентоспособных программных продуктов заинтересованы и сами разработчики. И тут VSM в большую помощь самим же разработчикам. И технология Process Mining для целей VSM.
Заключение
Тему Process Mining немного затрагивал ранее:
- «Как в enterprise приручить при помощи R технологии process mining?»
- «Бизнес-процессы в enterprise компаниях: домыслы и реальность. Проливаем свет с помощью R»
- «process mining: 100 строк кода и генератор логов у нас в руках»
Для более детального погружения в тематику process mining даю отсылку к отправной точке, труду Wil M. P. van der Aalst «Process Mining: Data Science in Action». Лекции, статьи, книги и т.д. можно далее искать самостоятельно, если тема заинтересует.
P.S. Большая просьба, если вам нечего сказать по существу или нет разумного вопроса по теме — пройдите просто мимо. Молча. Тема специфична, кто касался — тот понимает, кого не затрагивало — можно пока фокусироваться на более важных вопросах.
Заглядывайте в группу, задавайте вопросы. Иногда там даже ответы бывают.
Предыдущая публикация — «Дата саентист и циклы-циклы-циклы…».
Комментарии (26)

FanatPHP
12.05.2022 04:52+2Прочитал только что на реддите историю как раз в тему, про оптимизацию рабочих процессов.
Посетитель кафе уронил ложку под стол. К нему тут же подскакивает официант и достает из нагрудного кармана новую. Посетитель очень впечатлен и спрашивает официанта, как ему удалось принести ложку так быстро. На что официант отвечает, что команда экспертов по эффективности персонала собрала и обработала огромный объем данных и пришла к выводу, что ложки роняют 11.4% посетителей, и если официанты всегда будут носить ложку с собой, это позволит сэкономить 7.4 минуты рабочего времени за смену.
Посетитель ещё больше впечатлен, и спрашивает, какие ещё оптимизации были внедрены. Официант показывает белую верёвочку, которая торчит из застегнутой ширинки. Расстегнув ширинку и потянув за верёвочку, он может посетить туалет не трогая ничего руками, и таким образом сэкономить 45 секунд на мытье рук.
Посетитель снова восхищается, но потом задумывается, и смущённо спрашивает официанта, что достать-то он все достал без рук в туалете, но как потом обратно в штаны засунуть не трогая руками? На что официант с широкой улыбкой отвечает, "Ну а ложка-то на что?"
Так что да, оптимизация и дата майнинг - это страшная сила!

i_shutov Автор
12.05.2022 06:44Угу.
Трактат о морально-этических характеристиках белого листа бумаги. Если хотите ездить не по заезженным дорожкам, отступите в сторону. Почитайте книги и статьи по process mining, разберитесь в алгоритмах fuzzy miner, split miner, alpha miner… флёр слетит моментально.
Там действительно интересно. А ложечки и верёвочки пусть в желтой прессе остаются.
amarao
https://www.lesswrong.com/posts/GZSzMqr8hAB2dR8pk/studies-on-slack
Пересказывать статью не хочу, потому что там очень тонко, важно и точно.
Для меня эта статья определила всё. Я не хочу работать там, где нет stress (не понятно что делать). Я не хочу работать там, где нет slack (где точно ясно что делать и максимальная эффективность).
Баланс stress & slack - залог во-первых самореализации и самоактуализации (простите, мне личные ценности важнее корпоративных), во-вторых для компании обеспечивает запас устойчивости в случае смены требований.
i_shutov Автор
Ссылка интересна, но ее связь с текстом явно не просматривается.
amarao
Сделайте шаг на верх.
Статья про value stream и kpi, из которого предполагается оптимизация. Оптимизация - это стресс. Чистый стресс без slack помогает в коротком забеге и мешает в долгом. См ссылку.
i_shutov Автор
В тексте не затрагивается этическая, политическая или экономическая сторона вопроса. Равно как и вопросы оптимизационной функции или предпосылки старта проекта не рассматриваются. И теория игр не затрагивается. Если обобщать, то до Big Bang, как до исходной точки можно добраться.
amarao
Вы хотите фокусироваться только на реализации технологии, а я - на последствиях.
i_shutov Автор
Отличное желание. Пишите свою статью.
Но она вряд ли будет в тематике хабра. Психология, социология, политология, .... но не техника.
FanatPHP
Как у вас там, на Альфе Центавра, погодка? Дожди? :)
i_shutov Автор
i_shutov Автор
А что новенького на Плюке?
FanatPHP
На Плюке уже давно статьи размещают на любую тематику, от интимной жизни викнгов до психологии беспозвоночных.
amarao
Вы имеете в виду, что мне не надо комментировать вашу статью? Вы можете переключить это в настройках статьи - "отключить комментарии у публикации".
https://habr.com/en/admin
i_shutov Автор
Нет, просто комментарии хотелось бы уместные. Я пояснил почему здесь так как есть — ниже можете глянуть.
Ну а желание обсуждать другую тему похвально, но совершенно не радует. Видел уже такое, выглядит неприглядно.
i_shutov Автор
Фокусироваться здесь на последствиях — превратить все в холивар. Вы же это прекрасно понимаете сами.
sshikov
>или экономическая сторона вопроса
А в чем смысл всего вот этого без экономической стороны вопроса? Ну вот реально, вы скажем пишете: «Не исключены возвраты на доработку или отказы от проведенных доработок.», причем выглядит это так, будто это что-то плохое. А по мне — так нормальная часть работы, любой работы, включающей хоть немного R&D, т.е. такой, где результат хоть немного непредсказуем (и в общем-то, именно от такой обычно можно получить неожиданно большой профит, рутина как правило такого не дает). И иногда отказ от проведенных доработок — это самое лучшее, что можно сделать. Выкинуть без жалости, и двигать дальше, с учетом полученных в процессе новых знаний.
i_shutov Автор
Потому что экономическая сторона вопроса -- артефакты конкретного проекта.
И на общественное обсуждение это выносится в редких случаях.
Xsolla, например, была у всех на слуху.
Не путайте инструменты и объективные артефакты со списоком предпринимаемых потом мер. Четкая картинка может помочь принять взвешенное решение. В тумане точно шашкой не так махать будете.
Откуда такое постоянное желание все мешать в кучу. "А вдруг, а что если, иногда бывает, а как быть .... ". Декомпозируйте сложную задачу, а потом синтезируйте.
Очевидно же.
sshikov
Нет, не очевидно. И при чем тут общественное обсуждение — тоже не ясно.
Вот у нас тоже есть целый отдел, который пытается подобными же вещами заниматься. Например, измерять и прогнозировать (на базе Jira и Git) скажем Lead Time по задачам. Получается у них откровенная хрень, прямо скажем. Ну вот яркий пример — если я занимался задачей скажем два дня, 1 января и 30 июня, то они считают, что делал я ее полгода. То есть, статусы «отложено» не учитываются.
У них есть в голове некая модель, пригодная для процесса, где R&D не пахнет, где каждый день тупая одинаковая рутина, и взяв задачу в работу, надо ее непременно закончить сразу — а тянуть полгода нехорошо.
Тогда как в реальной жизни задача имеет самый низкий приоритет, и польза от нее минимальна. И смысла Lead Time по ней считать — никакого. И вот это все откуда проистекает? А из простой вещи — ни в Jira, ни в Git нет информации о полезности задач (ну и коммитов). Уж как ни посмотрите — хоть экономической, хоть какой. И если у вас все задачи одинаково (бес)полезны — на выходе из подобных расчетов чаще всего выходит нечто бессмысленное, на основе чего принимать какие-либо решения просто нельзя.
Заметьте, я не хочу сказать ничего плохого про саму идею. Всю жизнь старался подобные метрики снимать, и выводы из них делать, и жиру с гитом связывать. Я скорее о другом — что метрики, особенно лежащие на поверхности, обычно годятся только для проекта, состоящего из тупой рутины. А в проекте другого типа могут оказаться вредными.
i_shutov Автор
Если серьезно и без клоунского колпака.
Вы все верно говорите. Об этом и статья. Считать нужно очень аккуаратно и поднимать все трейсы и переходы. Классические консалтеры не очень хорошо понимают нюансы DevOps и морозят нелепицы.
Инструмент Process Mining позволяет построить реальную картину, это как туннельный микроскоп. Туда люди с экселем или табло не заберутся никогда.
Вынесение суждений и заключений -- отдельный сложный процесс. Человеку, который никогда не занимался серьезной разработкой будет крайне тяжело объективно оценить даже фактические метрики. Равно как и обсуждение нюансов того или иного проекта никак невозможно в коментах хабра по многим причинам. Здесь только вершина айсберга, даже не 1/10.
Если же наверху будет принято внедрять VSM, то самое лучшее, что можно сделать разработчикам -- самим курировать этот процесс с пониманием технологий, приводящих к объективным показателям.
Стиль хабра редко предполагает серьезные дискуссии. Все обычно сваливается в потенциальную яму. Невысокий заборчик помогает крайне редко.
sshikov
Ну, я возможно чуть упрощенно понял текст, не исключаю. В любом случае, я и не пытался критиковать, а скорее уточнял некоторые вещи.
i_shutov Автор
Жанр вынуждает делать микс между комиксами и притчами. Чтобы все было просто для беглого взгляда.
ZhilkinSerg
Так, а зачем на эксель-то гнать? Не умеете им пользоваться?
i_shutov Автор
Возвращайтесь в свой уютный клуб экселеводов. В открытом мире Вам будет зябко и дискомфортно.
ZhilkinSerg
Вы не умеете пользоваться экселем.
i_shutov Автор
Вам нравится нудеть?
Какие-то утверждения, высосанные из пальца. Жаль, банить нельзя.
PowerPivot используете?
i_shutov Автор
Вот как это все выглядит. Вы пришли, стали навязывать свою точку зрения в комментариях. Попытка аккуратно выправить ситуацию не очень помогла (на верх, кстати, пишется слитно). Несогласие с Вашими замечаниями вызвала обиду и опускание пальцем где дотянулись. С учетом Ваших 207 публикаций и уже накопленного опыта это выглядит очень странно.
Правда ведь?
Зачем так поступать?
Какова цель?