
В этой статье постараюсь затронуть все вещи, которые можно без зазрения совести выкинуть из С++ не потеряв ничего(кроме боли), уменьшить стандарт, нагрузку на создателей компиляторов, студентов изучающих язык и мемосоздавательный потенциал громадности С++
В первую очередь хочется убрать из языка то, что приводит к частым ошибкам и мешает развитию языка, тут идеальным кандидатом можно назвать
1 - union - сумм тип из 70х, в С идея хранения одного типа из нескольких в одном участке памяти выглядит неплохо и сейчас, ведь там все типы это набор байт с заданным размером.
В С++ же использование union это автоматическое undefined behavior, например:
#include <string>
union A { int x; float y;};
union B {
B() {} // требуется написать какой то конструктор и деструктор
// но обратите внимание, что написать деструктор правильно невозможно
// (попробуйте, если не верите)
~B() {}
std::string s;
int x;
};
int main() {
A value;
value.x = 5;
value.y; // undefined behavior, обращение к неактивному члену union
B value2;
value2.s = "hello world";
// undefined behavior, поле s неактивно и используется
// (в операторе= для std::string)
}Как вы видите использовать union без ошибок просто невозможно, при этом вам постоянно придётся вручную вызывать правильный деструктор для объекта и вместо приравнивания делать placement new в нужное поле. Так зачем же так мучаться, если можно сделать нормальный тип с хорошим интерфейсом БЕЗ какого либо оверхеда относительно юниона?
Следующий код полностью заменяет юнион, не имеет никакого оверхеда относительно него и имеет более понятный пользователю интерфейс (emplace / destroy)
Смотреть только если знаете С++
template<typename ... Ts>
struct union_t {
alignas(std::ranges::max({alignof(Ts)...})
std::byte data[std::ranges::max({sizeof(Ts)...});
template<one_of<Ts...> U>
constexpr U& emplace(auto&&... args) {
return std::launder(new(data) U{std::forward<decltype(args)>(args)....});
}
template<one_of<Ts...> U>
constexpr void destroy_as() const {
reintepret_cast<const U*>(reinterpret_cast<void*>(data))->~U();
}
};При этом в стандарте просто колоссальное количество исключений для union, бесполезных правил и ограничений. А можно просто взять и забыть про этот отголосок С, в 2022-то году...
2 - массивы
Это может звучать странно, но мы правда можем убрать из С++ массивы не потеряв ничего (убрав этот чудовищный синтаксис char(&&...arr)[N] (угадайте в комментариях что это значит) )
К тому же массивы почему то не копируемы и не умеют в мув семантику, что делает их самыми неполноценными типами во всём языке
Как же их заменить? Рекусивным(или через множественное наследование) туплом с элементами одного типа(да, это было очевидно)))
Интересный факт:
в тексте стандарта С++ есть исключение аж в цикле for для сишных массивов... Что подтверждает очевидное - массивы безумно плохо соотносятся с остальным языком
Реализация массива без массива
template<typename T, size_t I>
struct array_value { T value; };
template<typename, typename>
struct array_impl;
template<typename T, size_t... Is>
struct array_impl<T, std::index_sequence<Is...>> : array_value<T, Is>...{};
template<typename T, size_t N>
struct array_ : array_impl<T, std::make_index_sequence<N>> {
// тут какой-то интерфейс массива по вашему желанию
T& operator[](size_t n) {
// такая реализация для краткости
return *(reinterpret_cast<T*>(reinterpret_cast<void*>(this)) + n);
}
};3 - тип void
void по большей части служит для того, чтобы делать под него исключения в обобщённом коде, было бы гораздо удобнее иметь тип с единственным ничего не значащим значением... Как же сделать такой тип....
struct [[maybe_unused]] nulltype {};
// Вот и всё... Да и аттрибут [[maybe_unused]] тут разве что для красоты4 - все фундаментальные типы...
Кажется мы идём по нарастающей, на что же автор статьи тут замахнулся? На int?!
Да, не удались в С фундаментальные типы, а С++ их унаследовал. Кто в здравом уме будет использовать int, который может занимать 8 байт, но гарантирует свои значения только до 2 ^ 16??? Это буквально создатель ошибок(особенно у новичков)
Заменить это всё можно одним фундаментальным типом byte и указателями, действительно: с помощью byte и системы типов С++ можно создавать любые типы, в том числе аналогичные int, double, float, bool и т.д. из фундаментального набора
Тут мы убиваем сразу несколько зайцев - нет больше исключений для фундаментальных типов в разрешении перегрузки, нет исключений в шаблонном коде для наследования( от фундаментальных типов нельзя наследоваться) ну и другие более мелкие исключения для подобных типов уходят в прошлое
4.5 - приведения типов из С - это.просто.не.должно.компилироваться. (но оно компилируется) https://godbolt.org/z/fz6eMEeqG
int main() {
(void)(5), (void)5, void(5);
}
5 - runtime variadic arguments - человек, который придумал эту вещь в С должно быть сейчас раскаивается за этот грех, но нам приходится его тянуть.
И даже не смотря на то, что так реализован знаменитый printf(const char* pattern, ... ) <- кто не понял, многоточие это рантайм аргументы! Любые! Это выглядит самый большой костыль в истории программирования, а как этим пользоваться... Ух... макросы __VA_START__ __VA_COPY__ и громадная куча ещё всего связанного с этим будут сниться в кошмарах сишникам десятилетиями, а С++ пожалуй должен просто удалить этого демона из языка и забыть(и добавить за счёт удаления этого новые возможности пакам шаблонных аргументов)
6 - typedef - ну тут всё просто, в С++ есть отличная замена этому слову, просто сравните:
typedef void(*foo)(int); // foo теперь алиас на void(*)(int) (указатель на функцию)
// то же самое, но на С++
using foo = void(*)(int);Смысла оставлять typedef в языке нет...))
7 - функциональные макросы - это те самые макросы из С, которые принимают аргументы. Именно их обычно называют основной причиной сложности понимания кода(плохого кода, ведь в современных плюсах использование подобных макросов это неприемлемо)
Вот, кажется на этом этапе мы вычистили почти весь С из С++ и почти получили чистые ++(плюсы). Пора рассмотреть что стоит удалить тут!
8 - операторы new и delete
Действительно, зачем нужны в языке эти операторы, если всё давно перенесено на уровень абстракций аллокаторов, а память на низком уровне можно продолжать выделять через malloc?! Как вообще можно было догадаться внести систему(системный аллокатор памяти) на уровень языка?
Вы только посмотрите на даже не правила, а просто список перегрузок одного только new
СТРАШНО

Нужно только оставить размещающую версию оператора new для вызова конструктора по нужному адресу, всё остальное, особенно перегрузки new / delete использовать в современном С++ просто запрещено, если вы не хотите чтобы вас засмеяли
9 - ключевое слово class - ну тут я просто оставлю ссылку на мою же статью про бесполезность этого ключевого слова https://habr.com/ru/post/662351/
10 - ключевое слово final (запрет наследоваться от типа) - не имеет ни одного известного мне полезного применения, ломает обобщённый код, вердикт - удалить
11 - виртуальные методы :
Вызывают громадную кучу ошибок
Неэффективны, стимулируют писать архитектурно плохие решения, неэффективно использовать память, не позволяют использовать весь остальной язык, если используется ключевое слово virtual, и САМОЕ ГЛАВНОЕ - могут быть полностью заменены на другие языковые возможности без потери функционала(и с приобретением производительности, удобства, повторяемости кода, проверок на компиляции и т.д....)
Реализация динамического полиморфизма без виртуальных функций и их проблем: https://github.com/kelbon/AnyAny
12 - методы ( указатель на текущий объект внутри реализации типа )
В С++23 появляется(наконец) deducing this, благодаря которому можно будет явно декларировать передачу this в методы типа, при этом такой "метод" будет фактически функцией(с точки зрения языка), а значит в последующем(вместе с удалением виртуальных методов) можно будет избавиться от самого понятия МЕТОД в языке С++(и указателя на эту вещь) (не дай боже вам перед сном увидеть декларацию указателя на метод)
struct A {
void foo(this A& self);
};При этом возможно, что постепенно и ключевое слово this потеряет прежнее значение и останется только такое - декларация явной передачи ссылки/значения типа в функцию
Ну вот и всё, помечтали о великолепном hole C++, можете теперь пойти и опять продолжить писать хрень с виртуальным наследованием, забытым виртуальным деструктором на полиморфном типе и сишными кастами, удачи...
Комментарии (307)

Kotofay
19.06.2022 20:39-1С++ который лишён недостатков уже придумали.
Это Java(+Graalvm).
И да, union был в С не для того что написано в вашем примере, а для работы с аппаратурой, битовыми полями. Особенно нестандартных аппаратных приблуд, в которых половина слова биты значений другая половина -- короткие поля значений. Для того чтобы расписать регистр PSW на чтение/запись. И всё это без геморроя с масками и сдвигами.
Hidden text
На С/С++ с 1989 года, на Java 11/Graalvm - c 2020, и назад на плюсы ни ногой.

Kelbon Автор
19.06.2022 20:41+19java это один большой недостаток, язык завязанный гвоздями на Object и ооп, которое устарело. Громадная куча бойлерплейта с плохой производительностью, не вижу смыла в 2022 году ориентироваться на это

sandersru
19.06.2022 21:21+32В 2022 году не принято делать наброс без цифр, альтернатив и сравнений.
Чем вам помешал Object и чем плох ооп? Какие альтернативы?
Ну и на всякий случай, посчитайте свою зарплату за год, посчитайте сколько за нее можно купить на год железа в облаке и подумайте где на самом деле "тормоза" и стоимость

hobogene
20.06.2022 00:14-3Ну, Object плох тем, что с ним ООП неполноценное :-) "Наследование убивает инкапсуляцию", как учит нас GoF, криво цитируя чужую статью :-)

0xd34df00d
20.06.2022 01:04+5чем плох ооп?
Объекты часто используются в качестве модулей для бедных, и задач, на которые объекты ложатся хорошо, мало.
Какие альтернативы?
ФП и нормальные модульные системы.
Почти все паттерны из какого-нибудь GoF сводятся к достаточно тривиальным конструкциям в типизированном ФП в стиле хаскеля.

vanxant
20.06.2022 01:13+29задач, на которые объекты ложатся хорошо, мало.
Задач, которые хорошо ложатся на ФП, в реальном мире ещё меньше. И, что намного хуже, людей, на мозг которых нормально ложится ФП, вот прям совсем мало. Можете сравнить число резюме на С++/С#/Java/PHP и на вашем хаскеле + F#. А лидируют, внезапно, javascript и python, где большинство кандидатов пишут в старом-добром императивном стиле "пойди туда, возьми то", без всяких извратов с ООП и ФП...
0xd34df00d
20.06.2022 01:43+8Задач, которые хорошо ложатся на ФП, в реальном мире ещё меньше.
Классическое ФП — это просто про композицию функций. Функции композировать заведомо легче, чем объекты.
Современное ФП — это ещё и про контроль эффектов в типах. Типы существенно проще и скейлятся лучше, чем контролировать эффекты в названиях паттернов и соглашениях команд.И, что намного хуже, людей, на мозг которых нормально ложится ФП, вот прям совсем мало.
Вопрос привычек.
Да и очень много людей понимают ООП, что ли?
А лидируют, внезапно, javascript и python, где большинство кандидатов пишут в старом-добром императивном стиле "пойди туда, возьми то", без всяких извратов с ООП и ФП...
Так мы ж обсуждали ООП vs ФП, а не smth vs «нафигачить по-быстрому».

nin-jin
20.06.2022 08:56+5Объекты прекрасно компонуются. Они для того и были придуманы - декомпозиция кода на объекты, чтобы компоновать уже их.
Абстракции для того и нужны, чтобы скрывать несущественные детали, в частности эффекты.
0xd34df00d
20.06.2022 09:04+6Объекты прекрасно компонуются.
Ага, поэтому по тому, как их компоновать, целые книжки пишут, и потом обсуждают, что за SOLID такой, что за билдер, что за визитор.
Они для того и были придуманы — декомпозиция кода на объекты, чтобы компоновать уже их.
Из того, что они для чего-то были придуманы, не следует, что они для этого подходят лучше всего.
Абстракции для того и нужны, чтобы скрывать несущественные детали, в частности эффекты.
Эффекты как раз очень существенны, я не хочу их скрывать. Скрывать я хочу детали реализации, и пусть они как раз остаются внутри функций.
nin-jin
20.06.2022 09:51+8Книжек про монады, моноиды, функторы, эндофункторы и прочие фп паттерны - не меньше.
Было бы странно для компоновки придумывать абстракцию, для этого не годящуюся. Или вы считаете всех вокруг совсем идиотами?
Далеко не все эффекты являются существенными, не врите.
0xd34df00d
20.06.2022 17:29+1Книжек про монады, моноиды, функторы, эндофункторы и прочие фп паттерны — не меньше.
Можно пример книжек про монады, моноиды и эндофункторы примерно того же уровня, что GoF?
Монады и прочие моноиды — это просто интерфейсы с некоторыми правилами о том, что должны делать методы. У вас есть книжки по [гуглю "most common java interfaces"] по
Appendable,Callableи прочим ООП паттернам? Кстати,Appendableвыглядит подозрительно близко ко всяким моноидам. Или тамflatMapкакой-нибудь — о, у вас в жс уже походу монады завезли, когда книжки ждать?Было бы странно для компоновки придумывать абстракцию, для этого не годящуюся. Или вы считаете всех вокруг совсем идиотами?
Нет. Я считаю, что некоторые вещи оказываются удачными, а некоторые — нет, и понятно это становится только через некоторое время.
Далеко не все эффекты являются существенными, не врите.
А потом получается, что для того, чтобы этот метод правильно работал, сначала нужно вызвать те два в правильной последовательности, потому что у них есть общее состояние. Зато фабрики с декораторами присутствуют.
nin-jin
20.06.2022 17:37-4Что такое "уровень GoF"? Вы не поверите, но ООП паттерны - это тоже не более чем интерфейсы с правилами.
Спорить про удачность можно долго, но утверждать о некомпонуемости объектов - это либо дилетантизм, либо троллинг. Ни то, ни другое вас не красит.
Не получается, так как те два метода будут вызваны автоматически.
0xd34df00d
20.06.2022 17:51+3Что такое "уровень GoF"?
Это когда каждый пример разжёвывается на десяток страниц с кучей кода, мотивацией, и так далее.
Вы не поверите, но ООП паттерны — это тоже не более чем интерфейсы с правилами.
Что такое моноид? Моноид — это любой тип
Xи функцииmappend : X → X → Xиmempty : Xтакие, что- Ассоциативность:
mappend a (mappend b c) = mappend (mappend a b) c - Единица слева:
mappend a mempty = a - Единица справа:
mappend mempty a = a
Всё.
Что такое монада? Монада — это любой конструктор типов
Mи пара функций>>= : M a → (a → M b) → M bиpure : a → M a, для которых выполняется-
(m >>= f) >>= g = m >>= (\x -> f x >>= g)— блин, опять ассоциативность. -
pure v >>= f = f x— опять единица. -
m >>= pure = m— и снова единица.
Всё.
Можно аналогичные правила про фабричный метод, обсервер и адаптер?
Спорить про удачность можно долго, но утверждать о некомпонуемости объектов — это либо дилетантизм, либо троллинг. Ни то, ни другое вас не красит.
Я утверждаю, что компоновать объекты существенно сложнее, открыто для интерпретации, и легко приводит к неподдерживаемым системам.
Не получается, так как те два метода будут вызваны автоматически.
И эффекты, которые они выполняют, будут сделаны несколько раз. Письмо клиенту уйдёт несколько раз, деньги будут списаны несколько раз, и так далее.
- Ассоциативность:
0xd34df00d
20.06.2022 20:18Для развития педагогических навыков — какие символы тут непонятны?
И, если не сложно, опишите какой-нибудь ООП-паттерн словесно, без непонятных символов.

DarkEld3r
21.06.2022 10:09+1Для развития педагогических навыков — какие символы тут непонятны?
Мне понятно, но подозреваю, что средний сишник может оказаться не готов к такому способу указания типов.
0xd34df00d
21.06.2022 19:27Я бы ожидал, что средний сишник ходил в школу, а записи вроде
f : ℕ → ℝтам встречаются.
vanxant
21.06.2022 20:47+1Открою страшную тайну, но стрелочки много где встречаются. Даже в математике. Выражение типа
M a → (a → M b) → M bвполне можно прочитать в логике предикатов, например, где они означают импликацию, и которая сишнику, по крайней мере теоретически, значительно ближе. Хотя он, конечно, прочитает какое-то странное "разыменование указателя".
0xd34df00d
21.06.2022 21:04В логике предикатов это тоже можно прочитать, будет вполне нормально — спасибо изоморфизму Карри-Говарда.

F0iL
21.06.2022 23:49+4Некоторые средние сишники эти записи даже в школе в таком виде не особо понимали, и пользовались "словесными описаниями", которые в школьных учебниках обычно были где-то рядом.
А некоторые средние сишники в школе такое понимали, но в последний раз видели и использовали подобное тоже в школе, или в лучшем случае на первых курсах универа, что могло быть лет так 10-15 назад, и уже давно ничего не помнят.
В результате попытки вникнуть в записи с подобной нотацией вместо словесного описания даже при наличии под рукой шпаргалки приводят к stack overflow в мозгу буквально через полминуты.
Более того, на прошлой работе ради интереса запуливал в чатик разные интересности и задачки, и случайно выяснилось, что для подавляющего большинства разработчиков запись вида

оказывается гораздо менее понятной, чем простое словесное "когда вы складываете последовательные числа, начиная с 1, и количество слагаемых нечётное, то результат равен произведению среднего числа на последнее". Хотя, казалось бы, в школе подобного было более чем достаточно.

Zenitchik
22.06.2022 13:56-1Тут есть ещё другая проблема. Когда я вижу стрелочки и кванторы в математическом тексте - они читаются на вскидку. А когда в коде на незнакомом языке, это вызывает вопрос: "Чёрт возьми, что они в этом языке значат?!!"
Кроме того, символы, не вводимые с клавиатуры, - это триггер "Осторожно! Маргиналы!"

eao197
20.06.2022 20:03+4Это когда каждый пример разжёвывается на десяток страниц с кучей кода, мотивацией, и так далее.
Тут нужно бы делать скидку на уровень аудитории, для которой это все разжевывается.
Много слов нужно не потому, что ООП сложное или паттерны проектирования мудрены. А потому, что большая часть целевой аудитории таких книг, грубо говоря, виртуальный деструктор уяснить для себя не может.
0xd34df00d
20.06.2022 20:21+3Тут нужно бы делать скидку на уровень аудитории, для которой это все разжевывается.
Там вполне себе делаются отсылки к достаточно специфичным вещам, от оконных систем до всяких парсеров-компиляторов.
Много слов нужно не потому, что ООП сложное или паттерны проектирования мудрены. А потому, что большая часть целевой аудитории таких книг, грубо говоря, виртуальный деструктор уяснить для себя не может.
При этом даже изложение в GoF слишком слооожна, поэтому вышли ещё всякие head-first design patterns. И, к слову, группа обсуждения паттернов в одной компании, где я работал (и где были достаточно прошаренные плюсисты, датасайентисты и прочие), избегала GoF (потому что слооожна, да), и вместо этого читала-обсуждала по паттерну из этих head-first раз в две недели.
Виртуальный деструктор большинство из них при этом осилило.
eao197
21.06.2022 08:07отсылки к достаточно специфичным вещам, от оконных систем до всяких парсеров-компиляторов.
Что такого специфического, например, в оконных системах?
Виртуальный деструктор большинство из них при этом осилило.
Судя по тому, что вы пишете, вы только подтверждаете описанное в моем комментарии.
0xd34df00d
21.06.2022 19:46Что такого специфического, например, в оконных системах?
ХЗ, для меня вообще ничего специфичного нет ни в них, ни в парсерах, ни в чём. Но у народа возникают сложности.
Судя по тому, что вы пишете, вы только подтверждаете описанное в моем комментарии.
Я вообще изначально написал, что ООП-паттерны не то чтобы очевидны среднему программисту.
eao197
21.06.2022 19:53Но у народа возникают сложности.
О том и речь. Средней руки программистам даже паттерны разжевывать нужно до состояния мелкой кашицы (хотя в 95% этих самых паттернов, имхо, вообще ничего нет особенного, они переоткрывались многократно многими даже не задумываясь).

rblaze
21.06.2022 18:21Design pattern это библиотека, которую невозможно написать, потому что язык не позволяет (c) не_мой
nin-jin
21.06.2022 14:39Про компоновку объектов можете почитать в этой статье. Там же есть целый параграф с описанием реактивного фабричного метода и других паттернов, которых вы не найдёте в GoF.
0xd34df00d
21.06.2022 19:29+1Вот смотрите, я потратил минут 5-10 своего времени, чтобы написать конкретный комментарий с конкретными примерами правил. Если вы говорите, что паттерны ООП — это тоже интерфейсы с правилами, как моноиды всякие, то не затруднит ли вас потратить ваши 5-10 минут на описание правил для этих паттернов?

ReadOnlySadUser
21.06.2022 15:46-1Можно аналогичные правила про фабричный метод, обсервер и адаптер?
А зачем? :) Мне вот обычному смертному и без этих правил удобно ими пользоваться.
Вот монады, хоть тыщу раз имеют эти правила, я так и не понял зачем нужны. Я уж не говорю о том, что монадой по итогу оказывается куча разных сущностей и их монадическая природа ваще не очевидна на первый взгляд. В то время как фабричный метод я объясню ребенку за 10 минут.
Это когда каждый пример разжёвывается на десяток страниц с кучей кода, мотивацией, и так далее.
Сколько статей про монады было на Хабре, но мир их так и не понял.
0xd34df00d
21.06.2022 19:45Мне вот обычному смертному и без этих правил удобно ими пользоваться.
Как понять, когда у меня адаптер, а когда — бридж?
Как понять, когда фабричный метод применим?
Вот монады, хоть тыщу раз имеют эти правила, я так и не понял зачем нужны.
Для того, чтобы один раз написать кучу разных абстракций.
В то время как фабричный метод я объясню ребенку за 10 минут.
Ну попробуйте :]
Сколько статей про монады было на Хабре, но мир их так и не понял.
Потому что их в основном пишут те, кто недавно открыл для себя теоркат и думает, что понял теоркатовое обоснование.
Но вам же не нужно знать особенности теории рекурсивных функций, чтобы вполне себе писать на обычных императивных языках?
ReadOnlySadUser
21.06.2022 20:05+1Как понять, когда у меня адаптер, а когда — бридж?
А зачем?
Как понять, когда фабричный метод применим?
Как на счёт "когда захочется"? :) С тем же успехом я могу спросить "когда применим нож?". Ответ: во многих ситуациях, в основном когда надо что-то порезать, но вообще можно и гвоздь забить, если сильно прижмёт.
Для того, чтобы один раз написать кучу разных абстракций.
Описание правильной применимости которых точно также займёт по целой книге. Просто никто эти книги не пишет. Не потому, что они не нужны, а просто потому, что ФП как таковое никто не использует.
Потому что их в основном пишут те, кто недавно открыл для себя теоркат и думает, что понял теоркатовое обоснование
Если уж те, кто что-то прочитал в теоркате, и получается что-то знают, не могут объяснить нормально (значит ничего сами не поняли), то я вижу очевидное противоречие, что монады и их применение - это просто.
Но вам же не нужно знать особенности теории рекурсивных функций, чтобы вполне себе писать на обычных императивных языках?
Как и вам не нужно знать паттернов ООП, чтобы успешно писать на ООП языках) Я вот вообще про существование этих паттернов узнал через два года коммерческой разработки. Как оказалось, 80% из них я просто переизобрел, а дизайн некоторых языков просто подталкивал ими пользоваться.
0xd34df00d
21.06.2022 21:24+5А зачем?
Чтобы понять, когда использовать одно, а когда — другое. Это ведь не зря разные паттерны?
И чтобы более эффективно читать код, где один класс называется FooBridge, а другой — BarAdapter.
С тем же успехом я могу спросить "когда применим нож?". Ответ: во многих ситуациях, в основном когда надо что-то порезать, но вообще можно и гвоздь забить, если сильно прижмёт.
А можете с тем же успехом ответить про фабричный метод? Ну, чтобы «Ответ: во многих ситуациях, в основном когда надо что-то…» что?
Описание правильной применимости которых точно также займёт по целой книге.
Откуда там на целую книгу описаний? Почти всё там вообще из типов и названий функций понятно.
Нужно, чтобы одно монадическое выполнялось только тогда, когда другое даст
True? ИспользуетеwhenM. Нужно написать что-то вродеif/then/else, но с монадическим условием? ИспользуетеifM.Забыли, что есть
whenM, но понимаете, что вам вот в данном контексте нужна функция с типомm Bool -> m () -> m ()? Открываете хугл, пишете этот тип, получаете, выбираете междуwhenMиunlessMпо значению слова «when» и «unless», даже документацию читать не нужно.Знаете, что в стандартной библиотеке есть функция
mapMaybeс типом(a -> Maybe b) -> [a] -> [b]и достаточно очевидной семантикой, но вам нужна версия, которая бы поддерживалаMaybe, завёрнутую в монаду? Снова открываете хугл, пишете, находите достаточно ожидаемый результат.Не знаю, о чём тут книги писать.
Не потому, что они не нужны, а просто потому, что ФП как таковое никто не использует.
Хаскелисты не пользуются всеми этими вещами, по-вашему? Все эти пакеты существуют и, более того, добавляются в обратные зависимости для красоты?
Если уж те, кто что-то прочитал в теоркате, и получается что-то знают, не могут объяснить нормально (значит ничего сами не поняли), то я вижу очевидное противоречие, что монады и их применение — это просто.
В теоркате — ну да, не очень просто. Монада — это какой-то там эндофунктор с какими-то там естественными преобразованиями, для которых какие-то там диаграммы должны как-то коммутировать. Чтобы это понимать, нужно знать и, более того, интернализировать понятие категории, понятие функтора, понятие естественного преобразования, и так далее.
Но это всё совершенно не нужно, чтобы эффективно писать на хаскеле и пользоваться хаскелевской интерпретацией монад. Поэтому здесь нет никакого противоречия.
Или с тем же успехом можно взять, скажем, джаву, попытаться объяснять её через объяснение системы типов, состоящей из System Fω c сабтайпингом и ограниченным полиморфизмом, прочитать все N сотен страниц Пирса по теории типов, нихрена не понять и сделать вывод, что в Java без PhD в матлогике и теории типов делать нечего. Разумный ли это вывод? Как по мне — нет.

svr_91
21.06.2022 08:29Можно пример книжек про монады, моноиды и эндофункторы примерно того же уровня, что GoF?
Пусть и не книжка и пусть наверно не настолько глубоко, но вот
https://stepik.org/course/693/promo
целый курс по монадам

nikolas78
20.06.2022 17:05Ага, поэтому по тому, как их компоновать, целые книжки пишут, и потом обсуждают, что за SOLID такой, что за билдер, что за визитор
Да, и это всё из-за того, что сейчас заканчивается первая стадия ООП в духе С++ (слабо-инкапсулированные сильно-связанные объекты).Истинное ООПСледующий этап ООП, который должен был быть — в духе Smalltalk (сильно-инкапсулированные слабо-связанные объекты, а сам Smalltalk просто опередил свое время). Но этот этап пока отложился из-за хайпа ФП. Поэтому я предполагаю, что будет прыжок сразу на третий этап — синтез ООП+ФП, где объекты будут инкапсулировать в себе лишь состояния системы, а все действия будут выполняться в блоках в стиле ФП.0xd34df00d
20.06.2022 17:33+2Зачем объекты для инкапсуляции состояния, когда состояние отлично инкапсулируется в виде глупых и не имеющих собственного поведения структур данных (у которых просто не экспортируются кишки), плюс функций, объявленных в том же модуле?
0xd34df00d
20.06.2022 17:59Чтобы разговор был более предметным — какое именно поведение из той статьи вы имеете в виду? А то там, например, в поведение уходит и «неотрицательность остатка товаров».
nikolas78
20.06.2022 18:28Такое поведение, которое вдруг запрещает действие с данными (по уважительной причине, заранее не ведомой инициатору изменения) и предписывает иные действия. Или же, в зависимости от входных данных, выполняются разные действия (вроде оператора switch case). И это все должно происходить внутри объекта независимо от того, кто его вызвал. Суть в том, что мы пишем поведение один раз и потом уже спокойно обращаемся к объекту, без необходимости проверять все кейсы на корректность — поэтому оно и должно быть внутри объекта…
0xd34df00d
20.06.2022 18:38Это всё вполне выразимо на уровне отдельной функции, не привязанной синтаксически к объекту.
У вас может быть
-- кишки Warehouse не экспортируются, -- никто другой туда залезть не может module Warehouse ( Warehouse , emptyWarehouse , takeGoods , addGoods ) where data Warehouse = WH Nat emptyWarehouse :: Warehouse emptyWarehouse = WH 0 addGoods :: Warehouse -> Nat -> Warehouse addGoods (WH existing) delta = WH (existing + delta) removeGoods :: Warehouse -> Nat -> Maybe Warehouse removeGoods (WH existing) delta = if existing >= delta then Just (WH (existing - delta)) else Nothing
nikolas78
20.06.2022 19:06Тогда я вернусь к вашему предыдущему сообщению
Зачем объекты для инкапсуляции состояния, когда состояние отлично инкапсулируется в виде глупых и не имеющих собственного поведения структур данных (у которых просто не экспортируются кишки), плюс функций, объявленных в том же модуле?
и задам вопрос: что по вашему значит «собственное поведение» в этом контексте?
0xd34df00d
20.06.2022 19:14Любое поведение, которое в ООП-языке вы бы выразили функцией-методом, и которое синтаксически привязано к этой структуре. Начиная от конструктора, инициализирующего структуру, и заканчивая гипотетическим
bool Warehouse::removeGoods(Nat delta).
nikolas78
21.06.2022 23:04Ясно, спасибо. Я тоже на этой стороне, просто не пойму почему «структуры данных (у которых просто не экспортируются кишки), плюс функции, объявленные в том же модуле» нельзя считать объектами (да, не в терминологии современного ООП, но все же)?
0xd34df00d
21.06.2022 23:42Если не в терминологии современного ООП, то тогда вам придётся дать своё определение объекта. А зачем напрягаться, если можно просто рассуждать в терминах каких-то типов и функций на них?
nikolas78
22.06.2022 00:02А зачем напрягаться, если можно просто рассуждать в терминах каких-то типов и функций на них?
Тонко…

Akon32
20.06.2022 18:39состояние отлично инкапсулируется в виде глупых и не имеющих собственного поведения структур данных (у которых просто не экспортируются кишки), плюс функций, объявленных в том же модуле?
Так это и есть объекты. Данные + методы. Разве что без ключевого слова class.
0xd34df00d
20.06.2022 18:44+1Ну да, как я и сказал, инкапсуляция в объекты — это такой кривенький способ реализовать какую-то модульную структуру.
Только свободные методы могут быть связаны сразу с несколькими объектами (и больше никаких вопросов, кому должен принадлежать метод applyDamage — class Weapon, class Person или class GameManager), могут возвращать что-то более точное, чем «объект + изменённый объект», и так далее.

siziyman
20.06.2022 19:54+1Вот только есть один нюанс.
Есть вполне себе ООП-языки, в которых допустимы функции верхнего уровня (т.е. не являющиеся методом объекта). Наличие оных не влияет на "парадигменную ориентированность" (если это так назвать) языка.

Cerberuser
20.06.2022 09:06+13несущественные детали, в частности эффекты
После этих слов в ФПшном поезде начался сущий кошмар.

Erriour
20.06.2022 12:27Потому что надо продукт делать, а не размышлять, какие стандарты и паттерны лучше или хуже. На пустых словах деньги бизнес не зарабатывает)

DonVietnam
20.06.2022 14:39+1На лидирующем javascript как раз таки очень любят писать в функциональном стиле.
nin-jin
20.06.2022 15:12+1Ага, эмулируя объекты через грязные хуки.
0xd34df00d
20.06.2022 17:38Мне по ряду причин пришлось понаблюдать за страданиями джаваскриптеров-реактщиков, и я вообще не понял что по-современному функционального в этих ваших реактах, кроме того, что там, ну, функции.

nerlihmax
21.06.2022 10:19+1Потому что "функциональные" компоненты так называются только потому, что являются функциями с точки зрения языка, ФП тут ни причем.
DonVietnam
22.06.2022 12:18-1Не понял о каких хуках речь вообще, разве что вы к разговору о ЯП приплели фронтенд фреймворк.

dmitryvolochaev
19.06.2022 21:31Вам не нравится union - ну так получите вместо него принцип "всё является объектом".
К тому же, я так и не понял, в чем проблема с ООП и виртуальными методами
Kelbon Автор
19.06.2022 21:49-4в том что они не нужны, реализуются на С++ удобно без ключевого слова virtual / override
На гитхабе с реализацией из статьи также описано какие проблемы уходят

Chaos_Optima
20.06.2022 12:45Напишите пожалуйста как удобно без вирутальных методов реализовать нечто подобное
struct GraphicObject { virtual void draw() = 0; }; std::vector<GraphicObject*> graphic_items; .... for (auto item : graphic_items) item->draw();
naviUivan
20.06.2022 14:11Думаю будет выглядеть как-то так
template <typename T> struct GraphicObject { static void do_invoke(const T& self) { self.draw(); } }; struct Circle { ... void draw() {...} }; struct Rectangle { ... void draw() {...} }; std::vector<aa::any_with<GraphicObject>> graphic_items; graphic_items.push_back(Circle{}); graphic_items.push_back(Rectangle{}); for (auto& item : graphic_items) { aa::invoke<GraphicObject>(item); }Но насколько это удобно, от меня пока ускользает. Особенно если нужно иметь более одного метода в интерфейсе. Например, GraphicObject::move.
Chaos_Optima
20.06.2022 14:46Интересно конечно, но на каждый метод создавать класс обёртку это вообще не удобно, также какие проблемы уходят при этом решении, по-моему их становится только больше, получается если код практически полностью полагается на вызовы виртуальных методов везде придётся писать aa::invoke<method class>? К тому же судя по реализации any_with он работает только с movable классами. И давайте ещё немного немного усложним задачу.
struct Widget : GraphicObject { virtual void draw() override { ... } }; struct Label : Widget { virtual void draw() override { Widget::draw(); ... } };draw можно будет поменять на event например, будет более логично.
Kelbon Автор
20.06.2022 14:58в чём усложнение то задачи?
Из кода уходит явный контроль над памятью, наследования, невозможно сделать отсутствие виртуального деструктора и слайсинг, можно переиспользовать код в НЕ полиморфном контексте без каких либо проблем, можно делать дефолтные реализации методов свободными функциями на статическом полиморфизме... И многое другое
Chaos_Optima
20.06.2022 15:09+2в чём усложнение то задачи?
Вызов метода предка.
По остальному, это всё и так есть, достаточно просто не использовать виртуальные методы, вы назовите какие проблемы уходят если убрать виртуальные методы. Потому что без виртуальных методов можно и сейчас писать, но если захочется полиморфизма придётся писать огромную кучу классов обёрток, при этом что делать если нужно лишь частично переписать класс предка, а часть реализаций оставить тех что были, копипастить их? А если требуется вызов метода предка + добавление своей реализации как в усложнённом примере что я кинул? То что вы предлагаете, будет лишь раздувать код в сотни раз, а больше кода больше ошибок, я уж молчу о всяких vasssist ах и решарперах они станут совсем бесполезными в данном случае, а ошибки компиляции будут ммм загляденье, время компиляции тоже наверно скажет спасибо.
Kelbon Автор
20.06.2022 14:53move не нужно будет иметь потому что есть aa::move, то есть это ведёт себя как объект, а не как указатель на объект.
Так что будете писать a = b; а не a=b->copy() и прочая муть.
Методов может хоть 2 хоть 102, просто указываете. По неймингу понятно, что вы не совсем поняли суть, GraphicObject это не интерфейс целиком, а лишь один метод, из множества методов можно собрать интерфейс
Так что назовите его скажем Draw
и потом
using any_drawable = aa::any_with<Draw, aa::move, aa::copy>;(что вам там нужно то и берите)
Ну и в examples там показано, что можно в методы добавлять сразу интерфейс, чтобы писать не aa::invoke<Draw>(v), а v.draw();
Chaos_Optima
20.06.2022 15:33+2move не нужно будет иметь потому что есть aa::move, то есть это ведёт себя как объект, а не как указатель на объект.
Да только там (судя по реализации) на каждый объект происходит по сути placment new и вызывается конструктор копирования\перемещения а если ещё и стандартного размера буфера не хватит то и выделение памяти для каждого any_with.
что вам там нужно то и берите
И на каждый писать класс обёртку? Отлично.
Ну и в examples там показано, что можно в методы добавлять сразу интерфейс, чтобы писать не aa::invoke<Draw>(v), а v.draw();
Да посмотрел, дикое извращение лишь бы не использовать vtable. Да и там по сути есть vtable только своя реализация.
Kelbon Автор
20.06.2022 15:47Вам напомнить, что при использовании виртуальных функций обычно все объекты выделяются на куче? Тут у вас не будет выделения на куче в большинстве случаев, ведь есть оптимизация хранения, то есть аллокаций меньше, а не больше
И на каждый писать класс обёртку? Отлично.
Не на каждый класс, а на каждый полиморфный метод, при этом методы можно переиспользовать при создании других полиморфных интерфейсов
Да посмотрел, дикое извращение лишь бы не использовать vtable
Нигде не было заявлений об отсутствии vtable или о том, что я пытался её не использовать. Суть в отказе от ключевого слова virtual и проблем которые оно приносит
Chaos_Optima
20.06.2022 16:03Вам напомнить, что при использовании виртуальных функций обычно все объекты выделяются на куче? Тут у вас не будет выделения на куче в большинстве случаев, ведь есть оптимизация хранения, то есть аллокаций меньше, а не больше
Вызов конструктора копирования\перемещения никуда при этом не девается. Всё равно оверхед больше чем при копировании указателя.
Не на каждый класс, а на каждый полиморфный метод, при этом методы можно переиспользовать при создании других полиморфных интерфейсов
Я это и имел ввиду, вы же понимаете насколько это неудобно?
Суть в отказе от ключевого слова virtual и проблем которые оно приносит
Честно говоря за 12 лет работы, ни разу не сталкивался с проблемами из-за virtual при том что работаю с графикой
Kelbon Автор
20.06.2022 16:08вы можете сделать методы, которые будут принимать указатель и поставить размер буфера sizeof(void*), таким образом у вас никогда не будет аллокаций и копирование / мув будут происходить для указателя
Плюс в библиотеке ещё не документировано есть polymorphic_ptr<Methods...>, который отделяет полиморфность от типа и практически аналогичен void* для копирования(и принимания в интерфейс соответственно как в случае с виртуальными функциями)
naviUivan
20.06.2022 16:02Под GraphicObject::move имелся ввиду просто метод перемещения графического объекта, с move-семантикой это никак не связано.
А за разъяснение спасибо. Идея в целом понятна, просто городить для каждой функции отдельный класс со статическим методом многословно и не очень удобно.
На мой взгляд тему реализации динамического полиморфизма с семантикой значений хорошо раскрыл Louis Dionne в своей библиотеке https://github.com/ldionne/dyno. Но там тоже, без средств вменяемой кодогенрации, получается жутковато.
Kotofay
20.06.2022 20:21+2Получается вы создали псевдотаблицу виртуальных методов.
Самое интересное в оригинальных виртуальных методах это вызов базовым классом виртуального метода наследника.
Причём класс наследника может быть реализован позже разработки самого базового класса.
class Base { public: virtual void foo() { std::cout << "Base::foo" << std::endl; }; void bar() { std::cout << "Base::bar" << std::endl; } void baz() { foo(); bar(); } }; class AB : public Base { public: void foo() { std::cout << "AB::foo" << std::endl; } void bar() { std::cout << "AB::bar" << std::endl; } }; class DAB : public AB { public: void foo() { std::cout << "DAB::foo" << std::endl; } void bar() { std::cout << "DAB::bar" << std::endl; } }; int main( int argc, char * argv[], char * env ) { DAB tAB; tAB.baz();
Kotofay
19.06.2022 23:03Сейчас мой код обработки матриц на Java работает быстрее чем идентичная по коду реализация на C. Это факт. Не в разы, но на 10-15%. Оптимизатор работает лучше, ему не надо подсказывать или писать ассемблерный код.
А плохая производительность не из за Java, а из за навороченных библиотек не заточенных на производительность, но заточенных на предсказуемость и широчайший функционал.

RNZ
19.06.2022 23:56+3Тут стоит заметить, что Ваши матрицы не единственное мерило. Расскажите как на jvm для linux в одном бинарнике сделать менеджер управляющий своими воркерам(процессы) с тредами, с возможностью оперативно уменьшать/увеличивать кол-во воркеров и с релоадом без разрыва соединений, на манер как это реализовано в nginx например. Отвечу сразу - никак, кроме запуска пачки jvm.
Вообще-же jvm в качестве ОС (а не поверх ОС) - весьма интересное решение.sandersru
20.06.2022 00:26Легко... Это называется GraalVM делаем бинарник, можно вообще в posix напрямую ходить. А можно ещё взять кваркус и vert.x под капотом и добавить реактивщины на все это, с воркерами, эвент лупами и прочим...
JVM в качестве ось - это глупость, а вот хождение прямо в ось(да даже в регистры процессора) уже реальность
RNZ
20.06.2022 00:56+5Неа, не получится. В graalvm:
Directly using process related syscalls like clone, fork, vfork, etc. is not supported.
The exec function family is not supported.
Ну и про глупость - java me squawk, намекают как-бы, ну и есть те кто неплохо на этом зарабатывают: https://microej.com/
sandersru
20.06.2022 01:04+2В graalVM вы можете на прямую ходить в Линукс и делать что хотите. POSIX доступен, ровно как на сях. Просто в доках этого нет ещё граалевских.
Просто повторюсь, я спокойно ддергал mmap и управлял регистрами прямо из java и Грааль.
То о чем вы говорите - это netty+vert.x+quarkus.... Просто никому не интересно 2й nginx писать... Зачем?
RNZ
20.06.2022 01:39+2Вот как в graalvm обойдёте явно указанные ограничения, тогда и поговорим о доступности POSIX "ровно как на сях".
И с чего это никому не интересно писать второй nginx - куда ни посмотри, а на любом популярном языке не меньше десятка реализаций web-сервера или прокси или фреймворка.sandersru
20.06.2022 13:38+1А давайте поговорим...
import org.graalvm.nativeimage.c.function.CFunction; import org.graalvm.nativeimage.c.function.CLibrary; @CLibrary("c") public class Sample { @CFunction(transition = CFunction.Transition.NO_TRANSITION) private static native int fork(); public static void main(String[] args) { int result = fork(); System.out.println("result: " + result); while(true) { try { Thread.sleep(1000); System.out.println("process result = " + result); } catch(Exception e) {} } } }Компиляем, запускаем
javac Sample.java native-image Sample ./sampleи видим:
result: 533 result: 0 process result = 533 process result = 0 process result = 533 process result = 0 process result = 0 process result = 533 process result = 0 process result = 533 process result = 533Заглядываем в top и видим:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 892 484 416 S 0.0 0.0 0:00.13 init 8 root 20 0 892 88 20 S 0.0 0.0 0:00.00 init 9 root 20 0 892 88 20 S 0.0 0.0 0:00.12 init 10 sanders 20 0 10268 5384 3420 S 0.0 0.0 0:00.42 bash 531 sanders 20 0 98932 8860 5492 S 0.0 0.1 0:00.09 sample 533 sanders 20 0 98932 4320 936 S 0.0 0.0 0:00.00 sample 534 root 20 0 892 88 20 S 0.0 0.0 0:00.00 init 535 root 20 0 892 88 20 S 0.0 0.0 0:00.00 init 536 sanders 20 0 10032 5164 3424 S 0.0 0.0 0:00.09 bash 549 sanders 20 0 10868 3664 3152 R 0.0 0.0 0:00.02 topВидимо из java сделать таки можно.
Соответственно ваше утверждение - является ложным
sandersru
20.06.2022 14:35Update: Судя по всему вы в доки по llvm смотрели, а не про native компиляцию, отсюда и не верные выводы.
RNZ
20.06.2022 22:59+1Да я смотрел доки по llvm. И да native-image позволяет сделать форк, оказывается в 2019 году свешилось, алилуя!
Однако:$ time /usr/lib/jvm/java-16-graalvm/bin/javac Sample.java && time /usr/lib/jvm/java-16-graalvm/bin/native-image Sample real 0m1.084s user 0m1.730s sys 0m0.191s [sample:1115840] classlist: 1,441.24 ms, 0.96 GB [sample:1115840] (cap): 840.95 ms, 0.96 GB [sample:1115840] setup: 3,438.19 ms, 0.96 GB [sample:1115840] (clinit): 374.36 ms, 1.74 GB [sample:1115840] (typeflow): 6,396.07 ms, 1.74 GB [sample:1115840] (objects): 5,129.39 ms, 1.74 GB [sample:1115840] (features): 488.59 ms, 1.74 GB [sample:1115840] analysis: 12,691.96 ms, 1.74 GB [sample:1115840] universe: 1,009.62 ms, 1.74 GB [sample:1115840] (parse): 868.96 ms, 1.77 GB [sample:1115840] (inline): 1,460.33 ms, 2.33 GB [sample:1115840] (compile): 13,060.04 ms, 2.38 GB [sample:1115840] compile: 16,215.19 ms, 2.38 GB [sample:1115840] image: 2,244.14 ms, 2.38 GB [sample:1115840] write: 317.16 ms, 2.38 GB [sample:1115840] [total]: 37,670.41 ms, 2.38 GB # Printing build artifacts to: /home/rnz/experiments/graalvm/sample.build_artifacts.txt real 0m38.611s user 3m44.714s sys 0m4.161 s $ du -hs --apparent-size ./sample 11M ./sampleТоже самое на С/С++:
$ cat sample.cpp #include <iostream> #include <chrono> #include <thread> #include <unistd.h> using std::cout; using std::endl; int main() { pid_t rc; rc = fork(); if (rc == 0) { cout << "parent: " << getppid() << endl; cout << "child: " << getpid() << endl; } while (true) { std::this_thread::sleep_for((std::chrono::seconds(2))); if (rc == 0) { cout << "child: " << getpid() << endl; } } return 0; } $ time g++ -o cppsample sample.cpp real 0m0.525s user 0m0.463s sys 0m0.060s $ du -hs --apparent-size cppsample 23K cppsample $ strip cppsample && du -hs --apparent-size cppsample 15K cppsampleНу и потреблянство сравним тоже:
$ pmap -x $(pgrep sample) | egrep 'Address|total' Address Kbytes RSS Dirty Mode Mapping total kB 21488 6712 1320 Address Kbytes RSS Dirty Mode Mapping total kB 21488 4764 1320 $ pmap -x $(pgrep cppsample) | egrep 'Address|total' Address Kbytes RSS Dirty Mode Mapping total kB 5976 3060 192 Address Kbytes RSS Dirty Mode Mapping total kB 5976 1804 200В целом неплохо, на мышах. Но ждать ~4 минуты сборки для минимального приложения, да ещё ~2,4G ОЗУ отъело - так себе удовольствие (на Intel i5-8250U). Ну и судя по доке у native-image тоже хватает ограничений, типа невозможности подгрузить динамические штуки, есть какие-то проблемы с сериализацией, ну и если по коду попадаются какие-то особенные функции и методы, то всё равно надо положить рядом jvm.
sandersru
20.06.2022 23:48Но ждать ~4 минуты сборки для минимального приложения
Ну давайте ближе к реальности. 4 минуты надо собирать в финале. Гонять можно в JVM. А так да, native сборка - это можно Войну и Мир прочитать.
Ну и судя по доке у native-image тоже хватает ограничений, типа невозможности подгрузить динамические штуки
Не не возможности подгрузить, а сделать дополнительное приседание. Которое кстати уже делается самим граалем через agent и генерирует эти приседания.
есть какие-то проблемы с сериализацией
Да нету их. Даже в 22.1 сериализацию лямбд прикрутили. Сейчас вот с ребятами из редхата(который Quarkus) делаем профайлер для реактивных приложений с разворачиванием лямд, эвент-лупов, воркинг пулов и всех методов в них.
ну и если по коду попадаются какие-то особенные функции и методы, то всё равно надо положить рядом jvm
Зачем? Собираете с флагом -static или -staticWithLibC и счастье вам.
Вообще, если костылей не хотите, то Quarkus вам в помощь. Туда уже многое затащили. По зависимостям, если не изменяет склероз - больше 1500 артифактов приходят. Буквально на прошлой неделе Алексей мерял.
Klems
20.06.2022 09:29+5Странно предъявлять языку, в основе которого лежит платформонезависимость - неумение работать напрямую с платформой.
При чем специально вводите доп. ограничения. Потому что сами заранее знаете, что просто с задачей "сделать, чтоб работало так же" язык справится, а ваша цель доказать, что язык фуфло, для чего вводите искусственные ограничения.
sandersru
20.06.2022 14:22Уже снимают это ограничение. Java = Linux в современном мире в подавляющем количестве случаев. Хочешь платформонезависимость - она есть. Хочешь под платформу - тоже есть. Чуть выше можно увидеть пример в моем комментарии в ответ "что якобы нельзя, но можно"
RNZ
21.06.2022 02:02Не "хочешь", а надо или не надо.
Вот "платформонезависимость" - не надо. Своей тонны java кода нет, что-бы пытаться не переписывая получить профит в производительности и эффективности. А начинать писать на java, то что можно эффективнее и оптимальнее реализовать на C/C++ - лишено смысла, кроме как в случае, если вокруг одни java-программисты и ты один со своим cpp.sandersru
21.06.2022 20:24Вот "платформонезависимость" - не надо.
Поясните мысль. В моей картине мира - вся "платформонезависимость" java - это Idea от JetBrains. Больше как на Linux серверах я яву даже близко последние лет 10 не вижу. То есть "платформонезависимость" - не более чем "мем из 90х". "платформонезависимость" есть, явы там нет.
А начинать писать на java, то что можно эффективнее и оптимальнее реализовать на C/C++
Я тут ниже начал тему раскрывать. Главный вопрос - "а что есть эффективность и оптимальность"? Я с огромным уважением отношусь к Джону Кармаку и его годам оптимизаций в ID. Но зачастую этот "эффективность" = "выдать быстрее заказчику" и "оптимальность" = "сделать дешевле". Иначе вы просто пролетите в тендере. Нахрен вы никому не нужны, если готовы за 5 лет круто, а не за год.
Далее - разговоры C++ или Java по моему вообще бессмысленные. Начнем с того, а есть ли у вас вообще java программисты, чтобы на ней писать (для С это тоже верно). Нет, так чего тут разговаривать.
А дальше мы начинаем упираться в задачу... Что лучше, ради "оптимальности" плодить дикие связки C++/JNI/Java или все же сделать на одном языке. Железо ныне сильно дешевле труда программиста, его можно увеличить в 2 раза часто за зарплату одного из них.
Короче говоря - борьба С++ или Ява (как и многое другое) это борьба остроконечников и тупоконечников, как в известной книге. Первична задача. Дальше классический треугольник: быстро-дешево-качественно. Наличие специалистов, риски, цена, сроки, стоимость и сложность багофикса и поддержки. А только потом средства его достижения, как раз где и находится язык.
Kotofay
21.06.2022 22:32+1Больше как на Linux серверах я яву даже близко последние лет 10 не вижу.
Андроид тихо засопел в уголке.
sandersru
21.06.2022 23:18Слота то я и не приметил... Или забыл...
Правда не изучал онное, но если не изменяет склероз, то там по моему с 1.8 ещё не выбрались...
Кстати, разговаривал с соседями, это шишки SW в Samsung/Broadcom/Qualcomm - массово софт на golang с плюсов переводят.... Язык конечно хорошо, но стоимость разработки важнее
RNZ
22.06.2022 02:06Про "плаформонезависимость" - непонял о чём вы, но я имел ввиду, "способность" програм для jvm работать на любой ОС где работает jvm без изменений под конкретнуюю ОС, на практие оно только на десктопах и годится.
Про эффективность, я вам уже привёл пример: ScyllaDB.
Про "есть/нет программисты" - неверно.
Есть бюджет, что-бы:
а) нанять программистов
б) оплатить эффективное решение.
Бюджетом можно распорядиться рационально, а можно разбазарить.
300 разрабов собравшихся вокруг биллинга - разбазаривание бюджета.
40 инстансов субд на java (в облаке-ли, on-premise-ли), там где справятся 3-5 инстансов субд на cpp - разбазаривание бюджета
И вопрос только в том, разберёт "заказчик музыки", что ему впарили "какофонию" или нет. Увы, но часто, выбор эффективного языка, вообще не стоит в начале, пишут не оценивая будущее TCO, в результате имеем кучу легаси с тремя сотнями разрабов плящущими вокруг и доказывающими что "хуяк-хуяк и в продакшин" это time-to-market.
RNZ
21.06.2022 01:07Во-первых, я предъявлял не языку, а jvm. Во-вторых, эта кроссплатформенность вообще не упёрлась.
И предлагая задачу, я намекал на то, что jvm не позволит сделать ряд вещей, хотя как оказалось с 2019 года есть возможность запилить native приложение на java (graalvm), однако выглядит это всё равно как срещивание ужа и ежа, и со значительным оверхедом, хотя в целом неплохо в сравнении c jvm.
В общем я о том, что когда нужна реальная производительность и эффективность, то выбрав java с jvm, можно долго ломать копья и всё равно не достич приемлемых показателей, и на этом фоне кроссплатформенность по типу jvm идёт лесом. Показательными примером является Cassandra vs ScyllaDBsandersru
21.06.2022 07:02Когда речь заходит про "реальную производительнось" не следует забывать про тип задач и количество программистов в нем. Если это какое то небольшое приложение - да, вы совершенно правы. А если это скажем риалтайм биллинг, который пишут 300 человек, то производительнось встаёт на 2й план после стоимости программистов. То есть своей задачи свое решение. Тут и производительность и time to market и главное цена. Одна и та же система, но сделанная "по дзену" но в 100 раз дороже никому на рынке не будет нужна
nin-jin
21.06.2022 11:05+1Та же система "по дзену", а не как обычно "кто во что горазд, а потом скручиваем изолентой" потребовала бы не более 30 человек, в 10 раз меньше времени на разработку и в 10 раз меньше серверов.
sandersru
21.06.2022 11:38-2Назовите мне хоть одну IT компанию, у которой 30 сеньеров сидят ровно на 5й точки и ждут проекта такого объема на кассандре, вместо того чтобы не испытывать недостаток ресурсов, нанимать народ и прочее-прочее прочее. В идеальном придуманном мире - это возможно. В реальном - в крайне редких и исключительных случаях.
Kotofay
20.06.2022 11:20+1Извините, но кто мешает сделать JVM реализацию не для ОС а для железа? Никто не мешает. https://ru.wikipedia.org/wiki/JavaOS
Просто это очень неоптимально с точки зрения разработки -- малейшее изменение платформы и нужно переписывать JVM. С точки зрения программы на Java -- вообще ничего не поменяется, и ваши низкоуровневые задачи управления процессами и другими ресурсами будут отражены в абстракциях пакетов.RNZ
21.06.2022 01:27Да никто не мешает, пусть кому надо тот и делает. Мне не надо.
"малейшее изменение платформы и нужно переписывать JVM" - ну как-бы с ОС именно так. Ведь основная фишка jvm: абстрагировать, вируализировать, эмулировать - ну и логично тогда уже сразу вместо ОС применять jvm.sandersru
21.06.2022 06:53Да нет смысла в этом... Особенно для java + graal. Оно ж заточено куда - в облако. На 10мб alpine работает.
Это всякие извращенцы типа меня делают embedded to cloud. В большинстве случаев это не нужно

cepera_ang
20.06.2022 02:17+16Сейчас мой код обработки матриц на Java работает быстрее чем идентичная по коду реализация на C
А чем хорошая реализация на С?
woodhead
20.06.2022 06:38+3А её ещё попробуй напиши.
cepera_ang
20.06.2022 07:10+2Да, всякие *BLAS’ы десятилетиями пилят, а MKL всё равно быстрее :)

tzlom
20.06.2022 08:51но MKL это разновидность BLAS+LAPACK и быстрее он только на Intel
Хотя конечно сам по себе хорош
Kotofay
20.06.2022 11:25-2В том то и дело. Что на С нужно самому извращаться с платформой делая код на переносимом С оптимальным по производительности, тогда как на Java все извращения и оптимизации делает разработчик JVM.
И я не уверен что я это сделаю лучше, т.к. JVM лучше знает как расположить в памяти массивы, оптимизировать обращения с учётом кэширования и ещё 100500 зависимостей.И да, я не фанат Java, и долго писал на С/С++ ассемблере, и считал что это самые быстрые реализации, но Graal меня удивил.
Чистая Java конечно медленнее чем С на 15-20%.
Код вычислительный без выделения памяти и классов.
tzlom
20.06.2022 08:48Я сомневаюсь что ваши версии переплюнут тот же https://bitbucket.org/blaze-lib/blaze/src
Чтобы писать действительно быстрый код без знания платформы пока не обойтись.
Ну и стоимость JVM тоже забывать не надо, не всегда есть возможность или резон держать лишнюю память и прогревать виртуальную машинку.
Trrrrr
20.06.2022 10:05+1Вы явно что-то не то на С написали. Покажите ваш код)
Kotofay
20.06.2022 11:39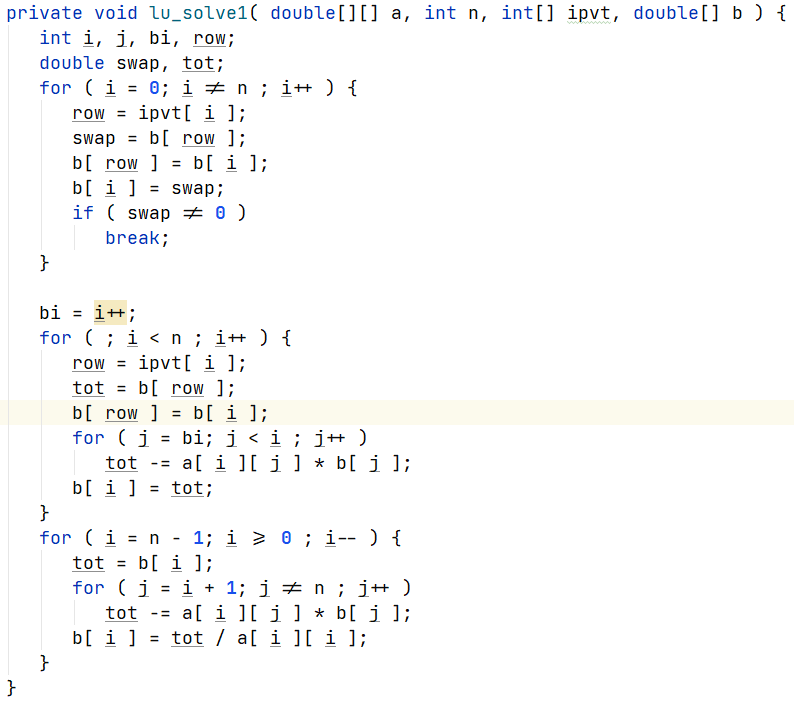
Не знаю как, но Graal оптимизирует такой код лучше чем С.
sandersru
20.06.2022 18:04а давайте ради интереса проверим.
Скиньте полный класс для теста + как его компилять. А я перепишу "в лоб" на яву и компильну в бинарник под graal.
Соответственно обменяемся исходниками и проверим на разных конфигурациях.
Kotofay
20.06.2022 20:49+1https://github.com/Kotofay/JavaVsC
Test time : 1538 Result : -1.0, -2.696002453891236sandersru
20.06.2022 21:03+1Тут все ждали код на сях, а тут java :) завтра под Граалем запущу, интересно цифры будет в jvm vs native увидеть
Kotofay
20.06.2022 21:32Обновил
Test time : 1517 Result : -1.000000 -2.6960020xd34df00d
20.06.2022 22:11+1Потому что надо результат
clock()делить наCLOCKS_PER_SEC, чтобы получить количество секунд. Ну и умножить потом на1e3, чтобы получить количество миллисекунд, которое вам, судя по названию, даётSystem.currentTimeMillis().graal мне ставить лень, но с имеющимися у меня тулзами сишка таки быстрее где-то на четверть или треть:
% java --version openjdk 17.0.2 2022-01-18 OpenJDK Runtime Environment Temurin-17.0.2+8 (build 17.0.2+8) OpenJDK 64-Bit Server VM Temurin-17.0.2+8 (build 17.0.2+8, mixed mode, sharing) % java Main.java Test time : 1130 Result : -1.0, -2.696002453891236 % clang --version clang version 14.0.1 Target: x86_64-pc-linux-gnu Thread model: posix InstalledDir: /usr/bin % clang -O3 -march=native MainC.c -o main && ./main [...] 2 warnings generated. Test time : 885.215000 Result : -1.000000 -2.696002 % clang -ffast-math -O3 -march=native MainC.c -o main && ./main [...] 2 warnings generated. Test time : 753.596000 Result : -1.000000 -2.696002Kotofay
20.06.2022 22:20Майкрософт реализует
clock_tкакlong, 32-разрядное целое число со знаком, а макросCLOCKS_PER_SECопределяется как 1000. Времена 18.2 cps давно прошли ;)printf( "Test time : %lf\n", ( end - start ) / (double)CLOCKS_PER_SEC * 1000. ); Test time : 1535.000000 Result : -1.000000 -2.696002Код на С упрощён, я не стал приводить реальную реализацию. И там присутствуют некоторые неприятные для С вещи.
массивы в Java проверяют выход за границы.
массивы переданные в функцию не имеют заранее известной размерности aka [ 32 ][ 32 ] и компилятор не может вставить константы смещений в код вычисления индекса как это делает компилятор С
подозреваю, что отсутствует выделение памяти как в clone() перед каждым вызовом, а не просто копирование memcpy
Думаю, что введение этих ограничений приведёт к падению производительности.
graal мне ставить лень, но
Чистая Java, как у вас, медленнее graalvm.
0xd34df00d
21.06.2022 00:26Майкрософт
А, майкрософт. А какой кодогенератор у вас там используется? clang-based или что ещё?
И там присутствуют некоторые неприятные для С вещи.
[...] которые jit вполне может вырезать.
Чистая Java, как у вас, медленнее graalvm.
Я, к сожалению, не нашёл graalvm в репах, а ставить в обход пакетного менеджера (или искать оверлей) лень. Но можно посмотреть, как быстро чистая java отрабатывает у вас, и прикинуть по соотношению.
Kotofay
21.06.2022 14:25[...] которые jit вполне может вырезать.
Не может. Это нарушает контракт обращения к массиву по индексу.
Опции JVM: -XX:+UseG1GC
0xd34df00d
21.06.2022 19:49Почему не может? Если он может себе доказать, что индексов больше 31 не бывает (а информации для этого у него достаточно,
nу вас всегда одно и то же и вообщеfinal), то проверку на размер входных массивов он может вынести в начало функции, а не в каждую итерацию, что сильно снизит её стоимость, позволит векторизовать код, и так далее.
Kotofay
21.06.2022 22:43Если он может себе доказать, что индексов больше 31 не бывает
Я уже написал, это не реальный код а кусочек, и n там вполне меняется, как и размеры массивов.
Поэтому никто ничего заранее доказать не может.
Однако со всеми оптимизациями Java справляется с кодом не хуже С++. А если сделать код С++ исключительно надёжным то и превосходит.
0xd34df00d
21.06.2022 23:41Я уже написал, это не реальный код а кусочек, и n там вполне меняется, как и размеры массивов.
Я могу обсуждать только тот код, который вы предоставили и который я запускал, и там
nфиксировано.А если сделать код С++ исключительно надёжным то и превосходит.
Что значит «исключительно надёжным»? Добавить в начало функции проверки на длину и использовать дальше
operator[]вместоat— это исключительная надёжность или уже нет?
Kotofay
21.06.2022 14:30А какой кодогенератор у вас там используется? clang-based или что ещё?
Clang:
Test time : 1237.000000
Result : -1.000000 -2.696002
Kotofay
21.06.2022 16:42-2[...] которые jit вполне может вырезать.
Добавил туда же реализацию на С++: std::vector, с проверкой на выход за границы и отсутствием явного размера:

PS: std::array не подходит, поскольку требует явного указания размера.
Отказываемся от проверки на границы -- падает надёжность и применимость, начинаются попытки оптимизировать внешний код, часто недоступный для ребилда. Вот поэтому я бросил С++.
0xd34df00d
21.06.2022 19:50PS: std::array не подходит, поскольку требует явного указания размера.
Не понял, а здесь у вас что?
static void lu_solve1( double a[ 32 ][ 32 ], int n, int ipvt[46], double b[32])(да, технически это не совсем размер, но неважно)
Kotofay
21.06.2022 22:35Не понял, а здесь у вас что?
Этот код не вызывается, см. main.cpp
UPD: Это С реализация, я же написал про С++
sandersru
21.06.2022 08:41sanders@ubuntu:/mnt/d/work/JavaVsC$ java --version
openjdk 17.0.3 2022-04-19
OpenJDK Runtime Environment GraalVM CE 22.1.0 (build 17.0.3+7-jvmci-22.1-b06)
OpenJDK 64-Bit Server VM GraalVM CE 22.1.0 (build 17.0.3+7-jvmci-22.1-b06, mixed mode, sharing)sanders@ubuntu:/mnt/d/work/JavaVsC$ java Main
Test time : 1427
Result : -1.0, -2.696002453891236sanders@ubuntu:/mnt/d/work/JavaVsC$ native-image Main
sanders@ubuntu:/mnt/d/work/JavaVsC$ ./main
Test time : 1883
Result : -1.0, -2.696002453891236sanders@ubuntu:/mnt/d/work/JavaVsC$ clang --version
clang version 10.0.0-4ubuntu1
Target: x86_64-pc-linux-gnu
Thread model: posix
InstalledDir: /usr/bin
sanders@ubuntu:/mnt/d/work/JavaVsC$ clang -O3 -march=native MainC.c -o main && ./main
MainC.c:6:8: error: unknown type name 'bool'
static bool lu_factor( double a[ 32 ][ 32 ], int n, int ipvt[46] ) {native - оказался медленнее. Почему - надо изучать.
си - не компильнулся :(
Чистая Java, как у вас, медленнее graalvm.
Это спорное утверждение. Например в graalCE - SerialGC только. А вот в EE - уже пожирнее + всякие фишки:
GraalVM Enterprise only:
--pgo: a comma-separated list of files from which to read the data collected for profile-guided optimization of AOT compiled code (reads from default.iprof if nothing is specified).
В "чистой java" еще несколько штук. Тут от задач и тюнинга зависит
nin-jin
20.06.2022 23:03Kotofay
20.06.2022 23:23JS это хорошо, но код надо вызвать 1М раз, при этом нужно массивы копировать. Псевдокод:
a = A
b = B
ipvt = IPVT
call lu_solve( a, n, ipvt, b )nin-jin
20.06.2022 23:49+1Автоматика говорит, что достаточно и пары тысяч вызовов.
А копировать массивы тут не нужно. Вам тоже советую убрать лишнее копирование.
Kotofay
21.06.2022 10:42-1А копировать массивы тут не нужно.
В оригинальном коде требуется брать как бы "чистые" массивы и "портить" их этим вызовом.
Поэтому копирование для точного воспроизведения нагрузки нужно.
Автоматика говорит, что достаточно и пары тысяч вызовов.
Ну это же тестирование производительности. В предоставленных сниппетах должно быть вычисленно 1М вызовов.
Kotofay
21.06.2022 11:30-2Это вы похоже не понимаете для чего был написан этот пример.
Ваш опыт оптимизации примеров оставьте при себе, спасибо.
nin-jin
21.06.2022 13:58Ну так разъясните, какая сакральная цель копировать массив, чтобы передать в функцию, которая его не меняет.
Kotofay
21.06.2022 14:12-1Т.е. смысл вызывать функцию, результаты которой никому не нужны вас не смутил. Ок.
Копирование массивов нужно для приближения теста к реальным условиям вызова данного кода.
Тестируется не код а скорость вычислений, в них входит не только манипуляция с матрицами но и скорость копирования массивных блоков памяти.
nin-jin
21.06.2022 14:53+1Даже не сомневаюсь, что в ваших реалиях массивные блоки копируются по поводу и без.
Либо раскомментируйте `lu_factor`, который меняет остальные массивы, либо уберите их копирование, раз уж мы тут говорим про эффективность и реализм. А тестировать заведомо бестолковый код - не имеет смысла.
Kotofay
21.06.2022 16:06-2в ваших реалиях массивные блоки копируются по поводу и без.
либо уберите их копирование, раз уж мы тут говорим про эффективность и реализм.
Я вам уже предлагал свои огромные скиллы оптимизации тестовых кодов оставить при себе, досвидания.
Akon32
21.06.2022 17:51+1А если прогревать JVM?
Добавил много итераций:
Hidden text
$ java Main iteration : 0 Test time : 1403 Result : -1.0, -2.696002453891236 iteration : 1 Test time : 1273 Result : -1.0, -2.696002453891236 iteration : 2 Test time : 1253 Result : -1.0, -2.696002453891236 iteration : 3 Test time : 1212 Result : -1.0, -2.696002453891236 iteration : 4 Test time : 1323 Result : -1.0, -2.696002453891236Процентов на 10 лучше, и то не всегда. Дисперсии не измерял.
Trrrrr
20.06.2022 19:58+1А покажите ключи оптимизации?
Например без --ffast-math внезапно векторизации флоат операций не произойдет.

ris58h
20.06.2022 11:05с плохой производительностью
Какие языки из индекса-TIOBE (но можете взять и любой другой топ-20 популярных ЯП на свой вкус) обладают хорошей производительностью? Хочу понять на чём имеет смысл писать в 2022 году.
siziyman
20.06.2022 11:16+1"Набор классических ошибочных стереотипов о Java начинающего программиста" из палаты мер и весов прямо-таки.
RomanSt
20.06.2022 12:11Сэр, мне кажется, но вы просто не умеете готовить эти ЯП (C++, Java). Тут у меня два соображения:
1. Ваши примеры "плохого С++" выглядят как примеры "не целевого использования". Вы просто пытаетесь писать простые вещи с использованием сложного функционала. так делать нетсмысла.
2. Обратите внимание какие ЯП используются на топовых соревнованиях по спортивному программированию. Там производительность крайне важна! И организаторы выбрали C++ и Java. Вам не кажется, что люди, которые годами учились писать высокоскоростной код несогласны с тем, что Java имеет плохую производительность? Можете лучше (производительнее)? Покажите на каком-нибудь top coder.
xXxVano
20.06.2022 22:17+4Как человек который участвовал в топовых соревнованиях по спортивному программированию, хочу сказать что Java используется исключительно для реализации задач на длинную арифметику. В каждой команде есть как минимум 1 человек, который даже если и не умеет полноценно в Java, то всё равно может написать короткую функцию, которая условно просуммирует BinInteger в цикле и потом его выведет.
Ну и да, в спортивном программировании не так давно (хотя уже пожалуй давно) паскаль отменили. Общество консервативное достаточно.
А что касается плохой производительности, то она вообще ни разу не в том что арифметические операции делаются дольше, а в реальном бизнесовом коде. Например там где вы поюзаете дженерик с вызовом делегата и нарожаете кучу объектов, С++ всё это будет темплейт с указателем на функцию, который заинлайнится и обойдётся без аллокаций вообще.
Тот же C# сейчас сильно упарывается что бы завезти много фич для повышения комфорта низкоуровневого программирования, но проблема в том что весь язык (как и Java), с ног до головы спроектирован в пользу удобства. И для оптимизации нужно отдельно изощряться, там где в С++ всё происходит само собой.
Kelbon Автор
19.06.2022 20:54А что вы не можете сделать с битами в обычной структуре? Причем тут юнион?

KoCMoHaBT61
19.06.2022 21:03+3union bsshort { unsigned short val; struct { #ifdef LITTLE char l; char h; #else char h; char l; #endif }; char bytes[2]; }Например...
Kelbon Автор
19.06.2022 21:10+4и что мешает вам использовать в этой ситуации типа похожий на span, который даёт вам доступ кроссплатформенно к младшему байту при обращении по индексу [0] ? Неужели легче везде расставлять ифдефы?
F0iL
19.06.2022 21:21+14В C++ проблема в том, что большинство таких type puning трюков с union нарушает active member rule, что согласно стандарту является undefined behaviour. То есть вы создали bsshort, присвоили полю val какое-то значение, полученное от железки... а потом обращаетесь к l или h, и опачки! - у вас код, являющимся некорректным с точки зрения стандарта, и компилятор имеет право сотворить из него все что угодно
Zenitchik
20.06.2022 00:11+6type puning трюков с union нарушает active member rule
А я всю жизнь думал, что тип union придуман ИМЕННО для таких трюков.
F0iL
20.06.2022 00:26+3Изначально union придумали в C. В C такие трюки делать можно.
Когда его переняли в C++, то решили, что так нельзя. Но там union, например, используется, например, в некоторых реализациях variant-типов. А для трюков в C++20 наконец-то завезли std::bit_cast.

mentin
20.06.2022 03:28Давно не лазил в стандарт, но там везде в таких случаях были исключения для POS (plain old struct), так что мне кажется что конкретно этот bsshort по прежнему совершенно легален и определен. Могу быть не прав конечно, но ооочень удивлюсь.
F0iL
20.06.2022 10:19+2Бегло перечитал эту часть стандарта, исключение там есть только дли типов с общей начальной структурой (не уверен, как правильно перевести "common initial sequences"), но type puning это все равно не разрешает, а каких-либо исключений для POS'ов там что-то не видно. Как пишут на SO, некоторые компиляторы в виде исключения разрешают подобные касты как неофициальное расширения стандарта, но тут уж без каких-то гарантий переносимости в целом.
mentin
21.06.2022 01:26Да, согласен, тоже глянул и поразился. Удивительно, но даже в случае С-совместимого кода гарантируется нормальный layout, но толку в этом ноль, компилятор может делать что хочет если идёт доступ не к тем полям что присвоены.
Akon32
20.06.2022 09:49+2В java тоже есть эти устаревшие массивы, местами несовместимые с generic'ами, да ещё и индексируются они только int'ом, а не long'ом. Если нужны структуры с 2^31 элементами и более, их только руками реализовывать.
sandersru
20.06.2022 13:28Долго думал, так и не придумал.... Покажите пожалуйста use cases где нужны массивы с 2^31 в реальной жизни 99,9% программистов.
Akon32
20.06.2022 14:36+2а) воксельные модели NxNxN, где N чуть более 1000.
б) файлы размером чуть более 2ГБ (имеют или не имеют отношения к п. а).
в) 2d изображения немногим больше 500 мегапикселей (не сталкивался).
sandersru
20.06.2022 14:41А теперь попробуйте найти кейс, когда это не потоковое действие, а надо обязательно целиком в память засосать, чтобы начать работу. Получим ровно что я написал про 0,01% случаев, когда это надо.
Но даже тут, можно обойтись другими средствами, а не массивом.
Akon32
20.06.2022 14:59+2Ээ.. Случайный доступ к таким данным?
Конечно, можно обойтись системой кэширования или многомерными ссылочными массивами, но скорость несколько уменьшится. Было бы проще просто работать с обычными массивами, железо-то позволяет. Вон, в .net массивы индексируются long, да и во многих других языках. Особенно обидно, когда файл (массив) не так уж и велик, но слегка в 2^31 не влезает. И довольно неприятно, когда у пользователя (условно) при N=1290 программа ещё работает, а при N=1291 перестаёт. Приходится предусматривать эту возможность, писать странный код.
sandersru
20.06.2022 18:45Такие объемы вы уже вряд ли в памяти будете хранить. Ибо и памяти на пару объектов хватит только и врятли "просто случайный доступ" это бизнес кейс.
У вас уже он где то будет валятся - а дальше что-то типа https://docs.oracle.com/javase/7/docs/api/java/nio/channels/FileChannel.html#map(java.nio.channels.FileChannel.MapMode, long, long)
И вперёд...
Akon32
20.06.2022 20:15Действительно, случайный доступ к огромному массиву не необходим бизнесу, но такая фича делает некоторые вещи проще, а некоторые алгоритмы (выполняемые бизнес-задачи) - возможными. В любом случае, у меня уже есть пример этакой системы кэширования, которая работает уже много лет.
Mmap на jvm, помнится, когда-то приводил к утечкам виртуальной памяти. На таких размерах файлов и все 256ТБ виртуальной памяти съесть недолго. Пока наиболее интересный вариант - MemorySegment, наиболее неприхотливый - кастомные структуры из ссылочных массивов.
sandersru
20.06.2022 14:53Вот просто по памяти:
sun.misc.Unsafe.allocateMemory(long bytes)
jdk.incubator.foreign.MemorySegment (эта часть уже стабильна)
Если говорим про GraalVM:
org.graalvm.nativeimage.UnmanagedMemory.malloc
Ну и в native можно прямо в POSIX:
@CFunction(transition = CFunction.Transition.NO_TRANSITION)
public static native PointerBase mmap(PointerBase addr, long len, int prot, int flags, int fd, long off);Akon32
20.06.2022 15:17+1К сожалению, все эти решения требуют ручного управления памятью и имеют несколько нестандартный синтаксис. Что-то вроде С++ получается.
sandersru
20.06.2022 15:21Именно так... для не стандартных кейсов не стандартные решения...
Akon32
20.06.2022 20:02+2Меня печалит, что кейс "доступ к элементу массива (списка)" норовит стать нестандартным и невозможным (без написания адского кода), когда массив занимает всего 10-20 процентов от доступной памяти. Это искусственное сейчас ограничение. Да, раньше int хватало всем для индексации, но теперь-то long хватает всем.
xXxVano
20.06.2022 22:25Это как раз то что называют:
"Что только люди не делают, что бы не учить C++" ©sandersru
21.06.2022 00:04А давайте перефразирую: Работаешь с 64-х битными массивами - учи С++ :)
В реальности, по моему скромному мнению, массивы только в нише специфичных кейсов остались. 90% народа работает с листами, мапами, сетами и прочими обертками
xXxVano
21.06.2022 00:27+1А листы/мапы/сеты умеют в размер больше чем 2^31?
Я вполне могу представить, что на C++ кто то захочет массив/вектор булов размером больше чем на 500Мб. Но так же не вижу причин оправдываться на вопрос что в Java это нельзя сделать из коробки.А описанные изощрения хоть и позволяют достичь этого, но прям явно сигналят что для данной задачи нужен другой язык. Ну или для данного языка другой подход — не делать так.
Поэтому тезис имхо очень подходит)
sandersru
21.06.2022 07:06-1Ключевое написанное вами - "Я вполне могу представить".
Ровно так же можете представить миллионы(а не несколько) задач где поможет рефлексия или аннотации. И все написанное вами выше сразу теряет смысл.
xXxVano
21.06.2022 14:01Но нет же. Конечно у рефлекшна есть ряд задач, которые он решает более удобно, с этим никто и не спорит. Речь про то что у каждого языка есть свои преимущества и недостатки. Но сделать из Java замену C++ не получится даже близко. Как и из C++ замену Java.
Кстати про рефлекшн и аннотации (да и про GC). Тот же UE4 вполне успешно сделал их реализацию поверх всего этого поверх C++. Причём с предметной спецификой, когда не всё попадает в GC и рефлекшн. Так что это всё тоже можно сделать с определённым извратом.
sandersru
21.06.2022 16:14Ну раз "Но нет же" и "у каждого языка свои преимущества", то это не согласуется с вашей фразой с которой начался этот разговор - "Это как раз то что называют:
"Что только люди не делают, что бы не учить C++" ©"То есть я написал как решить эту задачу на Яве. Всего то показал опции.
xXxVano
21.06.2022 16:35+1Согласуется, мой тезис был в том что если язык не предоставляет удобного способа решения какой то проблемы, в данном контексте — работы с большими массивами, то и не надо использовать его для этих задач. Вместо того что бы придумать костыли как это решить, лучше просто взять подходящий инструмент, например С++.
"Но нет же" — потому что я совсем не согласен с тем что наличие в Java рефлексии хоть каким либо образом обесценивает возможность работы в С++ с большими массивами.
sandersru
21.06.2022 20:06Если мы говорим, про "сферический длинный массив в вакууме", то вы безусловно правы.
Однако я не встречал компании которые пишут исключительно длинные массивы. То есть это какая то из задач. Если у нас компания и так пишет на С++, то нам нечего обсуждать.
А вот если мы говорим про Яву, то давайте попробуем вместе, в этой компании Ява программистов написать массив на сях в решение которое уже пишет куча программистов.
То есть мы найдем сишниеа, возьмём на работу, выгоним нахрен через 3 месяца, если так как он не нужен больше или найдем контактора.
Дальше напишем кучу JNI, который надо будет так же как то поддерживать... Ну то есть "костыль на java"и ваш "просто взять с++" начинают играть совершенно новыми красками...
xXxVano
21.06.2022 22:26По этому я и написал про наиболее подходящий под задачу язык. Если задача например обработка изображений или рендер, то там всё не обойдётся только лишь длинными массивами. Там и множество других проблем всплывёт.
А вот если делать сервер, то Java/C# на порядок более подходящие языки. И даже если появится такая задача с массивами то можно её решить более простым способом, например сделав абстракцию с несколько массивами внутри, а не делать платформозависимый код.
Собственно я пока что не встречал компаний/проектов, где пишут исключительно на одном языке. Из того что я вижу, в рамках одного проекта вполне себе успешно сочетаются C#/C++/Java/Python/Powershell и местами немного Rust/Go.
Akon32
22.06.2022 05:22Но когда требуется написать сервер по обработке изображений или рендеру, приходится "сочетать языки" и вот это всё, порой из-за небольших недостатков. И каждый из этих языков позиционируется как универсальный.

event1
20.06.2022 15:52+4И да, union был в С не для того что написано в вашем примере, а для работы с аппаратурой, битовыми полями
Сомневаюсь, что это так, ибо "C99 6.7.2.1-11:An implementation may allocate
any addressable storage unit large enough to hold a bit- field. If
enough space remains, a bit-field that immediately follows another
bit-field in a structure shall be packed into adjacent bits of the same
unit. If insufficient space remains, whether a bit-field that does not
fit is put into the next unit or overlaps adjacent units is
implementation-defined"Проще говоря, компилятор может раскидать битовые поля, так как посчитает нужным, что не очень подходит для работы с аппаратурой. Драйвера, которые мне приходилось видеть никогда не используют битовые поля в структурах. Они используют маски и смещения.



MFilonen2
19.06.2022 21:25+3C++ это феномен нашего времени – популярный язык, который позволяет писать вот реально «как хочешь», когда все остальные языки пытаются диктовать какую-то одну парадигму и строят все вокруг нее.
Потому я бы в C++ только добавлял – рефлексию там (и статическую и динамическую конечно), аннотации к полям и типам, деривативы, новую версию макросов (не удаляя старой конечно), процедурные макросы и так далее.sandersru
19.06.2022 21:30+33Вам не приходилось, получать код от других программистов, которые пишут "как хотят"? Поделитесь впечатлениями?

CrashLogger
20.06.2022 10:57+2Из-за такого подхода язык получился безумно раздутым и на его изучение уходит полжизни. При том, что ни в одном реальном проекте все его фичи никогда не используются.

playermet
20.06.2022 11:27+2который позволяет писать вот реально «как хочешь»
В итоге даже Страуструп оценивает свое знание плюсов на 7 из 10, потому что знать этот язык более менее полно нереально. И это создатель языка, который посвятил ему десятилетия своей жизни, причем до тонны новомодных нововведений. Как теперь угадывать, какую часть C++ у которого только список терминов занимает страниц 20 A4 мелким шрифтом нужно учить, чтобы гарантированно понимать код который пишет хотя бы условное большинство - хз.

gotoxy
19.06.2022 21:28+23О, ООП опять хоронят.
10 - ключевое слово final (запрет наследоваться от типа) - не имеет ни одного известного мне полезного применения, ломает обобщённый код, вердикт - удалить
Отличный довод, просто великолепный. И не поспоришь ведь.
Kelbon Автор
19.06.2022 21:33-12покажите пожалуйста полезное применение... Может это?
struct example final { virtual void foo() = 0; };gotoxy
19.06.2022 21:56+3Если мне не изменяет память, то прежде чем кейворд auto поменял своё значение, была просмотрена куча кода на предмет его использования. Немного разнится с личным мнением Васи из интернетов.
Grepshe
19.06.2022 21:59+17final позволяет компилятору делать оптимизации, вызов методов происходит непостредственно, без использования vtable, если переменная типа который final
Kelbon Автор
19.06.2022 22:00-7ну во-первых в статье также предлагается выкинуть virtual, во вторых целое ключевое слово для какой-то возможности оптимизации, когда компилятор итак в состоянии понять, что наследников у типа нет?
Grepshe
19.06.2022 22:04+21Компилятор способен понять в пределах одной единицы трансляции, если же класс уже скомпилирован, то понять будет ли он в будущем унаследован в другой единице трансляции компилятор не может)
Kelbon Автор
19.06.2022 22:21-7Захочет - сможет. Особенно учитывая тот факт, что девиртуализировать нужно по месту применения, то есть компилятор видит что создан конкретный тип и можно не делать вызов через vtalbe
zvszvs
20.06.2022 09:09+4Если функция принимает указатель на базовый класс с виртуальным методом и вызывает его. Чего вы там сможете девиртуализировать?
sandersru
19.06.2022 21:34+2А поделитесь плз ссылками на секту хоронителей ООП. Хочется поднять настроение.
final - пожалуй соглашусь с автором. Ещё с лохматых годов, со времён 90х и delphi, накрывался на финальные классы, которые приводили к дикому количеству копипасты. Реальных же случаев, когда без этого никак, на вскидку не припомню
gotoxy
19.06.2022 22:05+3Часто ООП хоронят в статьях об ФП. Но, всё же, теми, кто это ФП вот-вот попробовал и загорелся мысолью построить новый чудный мир, а всё прежнее отправить на свалку.

sergio_nsk
19.06.2022 21:53+9Убрать
union,typedef, массивы,void,int, макросы. И прощайте все заголовочные файлы C. Будем экспортировать нативные функции, как это делает C#.

Izaron
19.06.2022 22:00+32Некоторые пункты отдают легким троллингом. Я бы еще предложил оставить в функциях не более 1 аргумента, а вызов функций с N аргументами имитировать в виде шаблонной магии.
Реальные проблемы в C++ выглядят не так. Вот так выглядят "классы" проблем, после фикса которых можно получить "C++ мечты":
Вопрос о сломе ABI и всего веера положительных и отрицательных эффектов из-за этого.
Бедность стандартной библиотеки по сравнению с буквально всеми другими языками (тут ABI ни при чем).
Поехавший нейминг и правила, например овер9000 значений слова
staticпри разных обстоятельствах; или что anonymous namespace наделяет все символы внутри себя internal linkage-ом (как до такого додумались?).Медленная компиляция по разным причинам.
Отсутствие общепринятого менеджера пакетов/библиотек (тут могут быть разные мнения, но это тоже "класс" проблем)
Достаточно медленное развитие языка в целом - те же концепты пытались родить с нулевых годов, а также медленная поддержка этого в компиляторах.
Отсутствие встроенных линтеров и чекеров (которых овер9000, но ими пользуются не только лишь все, а только самые продвинутые).
А "фиксы", которые удаляют ООП и т.д. - это не решение всех проблем C++, а описание какого-то нового языка.
Kelbon Автор
19.06.2022 22:08-10Не вопрос стандарта языка, аби хранят реализации, а в стандарте такого понятия нет
Зато есть куча другого кода вне стандарта
Предложенное статье сокращает количество правил. Значительно
Достаточно быстрая компиляция, относительно возможностей языка. У раста в разы медленнее
Cmake
Последние 12 лет очень бурное развитие
Они не должны быть встроенными, потому что IDE и спелчекеры не должны являтся частью языка. Как и система сборки и документирования. Сторонние инструменты есть

tandzan
19.06.2022 22:34+24Cmake это даже не решение, а само по себе проблема с синтаксисом из 70ых и без нормальной документации.

BeardedBeaver
19.06.2022 22:46+8cmake это и не менеджер пакетов, это в первую очередь система сборки

majstar_Zubr
20.06.2022 11:18+1*генератор скриптов для системы сборки make

AnthonyMikh
20.06.2022 13:37+1*генератор скриптов для системы запуска команд оболочки в соответствии с DAG-ом правил и значениями атрибутов mtime у указанных файлов-целей. make — это даже не система сборки, строго говоря.
Izaron
19.06.2022 22:38+11Не вопрос стандарта языка, аби хранят реализации, а в стандарте такого понятия нет
Ситуация из разряда "жопа есть, а слова нету". Почему нельзя удалить из стандарта ставший ненужным с C++11 метод push_back? (А точнее, переписать его код вместо создания нового метода
emplace_back)Потому что ABI сломается. Хотя, казалось бы, про ABI в стандарте ничего не написано.
Я бы, кстати, еще AST (Abstract Syntax Tree) в стандарт "C++ мечты" легализовал, чтобы люди могли писать тулзы для исходного кода без привязки к внутренностям компилятора.
Зато есть куча другого кода вне стандарта
95% людей устроило бы наличие любой (даже не самой быстрой) json-либы (как в питоне). Если бы была нужна какая-то мега-быстрая json-либа (в realtime-приложениях), то там уже могут быть варианты, но свои трейд-оффы есть везде.
Предложенное статье сокращает количество правил. Значительно
Предложенное в статье главным образом создает какой-то совершенно другой язык.
Достаточно быстрая компиляция, относительно возможностей языка.
Я имел в виду "класс" проблем, которые именно вызывают медленную компиляцию. Например, из-за некоторых свойств препроцессора тулза include-what-you-use в 10 раз толще, чем нужно быть, и все равно работает не совсем как следует. Значит, нужно порезать препроцессор. Просто не стал все это расписывать, иначе комментарий получился бы длиннее статьи.
Cmake
Многие считают это худшей системой сборки ever. Если приводить все аргументы, выйдет тоже немаленький текст, но я читал бомбежку на CMake (сам его редко использую) - меня впечатлило.
Они не должны быть встроенными, потому что IDE и спелчекеры не должны являтся частью языка. Как и система сборки и документирования. Сторонние инструменты есть
95% людей были бы согласны на любой нормальный спеллчекер в "C++ мечты". Да и что значит "не должны", "не могут". C#/Java/Python/Rust - у них все есть и они все могут.
BeardedBeaver
19.06.2022 22:49+2ставший ненужным с C++11
Не понял, почему ненужным? Он позволяет создать объект на месте, но есть много случаев когда объект создается, с ним производятся манипуляции, и только потом он добавляется в вектор

NightShad0w
19.06.2022 23:04STL всосалась в стандарт когда JSON еще никому не нужен был, если вообще существовал. А теперь поздно что-то кардинально менять. Но вот оформить пропозал по включению JSON поддержки сейчас, никто не запрещает. Вот только С++ используется там, где текстовый, несамодокументированный формат передачи небольших, непотоковых данных немного редко применим. Так что вряд ли быстро примут в стандарт. Ну и без вменяемой рефлексии, это все будет полу-мерой без решения реальной проблемы, как получить по RPC готовый объект ничего о нем зная, или с динамическими полями.
Kelbon Автор
19.06.2022 23:22-2Убирание push_back сломает не аби совместимость, а интерфейс совместимость))
Да и бывают ситуации когда он нуженНасчёт стандартизации AST - я бы хотел стандартизацию интерфейса модуля. Кстати именно модули решат проблему инклудов...
А CMake обладает плохим синтаксисом, но в целом удобно, желаю всем на него перейти, чтобы подключать либы было удобнее(а синтаксис можно обернуть в программу на питоне по генерации скриптов CMake...)
Ну и что-что, а json либ громадное множество, а мне не хотелось бы ничего включающего в себя даже в названии JAVA SCRIPT в стандарте С++
playermet
20.06.2022 11:52+2а json либ громадное множество
Что является проблемой само по себе. Т.к. в проекте легко может появиться несколько библиотек, каждая их которых тянет разные либы для json. Это из той же серии, как раньше каждый фреймворк пилил свой класс строк, а потом их нужно было по пять раз переводить между собой на ровном месте.
cepera_ang
20.06.2022 17:53А потом всё равно кто-нибудь напишет свой квадратичный парсер и будет 10кб джсон по пять минут грузиться.
0xd34df00d
20.06.2022 18:26Разные либы для парсинга json как раз не особая проблема, покуда они пользуются более-менее совместимыми типами данных.

victor_1212
19.06.2022 22:04+6приятно, что человек думает самостоятельно, но конечно проще и чище делать new from scratch, совет простой - забыть "С++" и описать свой "D"

Revertis
20.06.2022 01:32+10Так Rust уже придуман, работает, и там все эти проблемы решены.
victor_1212
20.06.2022 02:57+1> и там все эти проблемы решены.
кто знает какие у автора могут быть новые идеи, пусть бы попробовал с чистого листа, rust никуда не уйдет, кроме прочего так люди растут

nmrulin
19.06.2022 22:52С помощью union можно сделать например так
typedef struct {union{unsigned int address;unsigned char bytes[4];}} ipv4_address;И как в том же Java так же сделать? Возможно какие-то нормальные обходные пути и есть. Но я в Java максимум быдлокодер, таких не знаю, поэтому приходилось делать громоздкую конструкцию, где я при замене 32 битного значения вручную менял и массив и наоборот. А тут всё быстро и автоматически.
Естественно с первого раза конструкция не взлетела пришлось потом тратить время на вылавливание ошибок.

BugM
19.06.2022 23:04+11Вы написали UB. Если я правильно понимаю как вы это собираетесь использовать.
В Джаве так сделать нельзя и слава богу.
sandersru
19.06.2022 23:06+3А зачем это делать в java или любом другом языке? Разделяем на разные типы и логически всем понятно кто-что-зачем-куда
Kelbon Автор
19.06.2022 23:13+5а ещё это можно сделать без помощи union
(у вас int на другой платформе может быть 2 байта...)
nmrulin
20.06.2022 13:03И как это сделать в Java без помощи юнион?
У нас на порт приходит пакет 10 байтов. На самом деле же это числа по 2 или 4 байта + заголовок и контрольная сумма.
Есть конечно дуболомный вариант. Что если не самый старший байт <0 , то добавляем 256. И потом ещё умножаем на 256 в зависимости от того какой разряд. Но по мне , подход так себе.
----
Про два байта вы правы, такой код не универсальный, для универсальности надо делать костыли.
F0iL
20.06.2022 00:00+9С помощью union можно сделать например так
Если вы храните адрес в виде union чтобы записать значение в поле одного типа, а потом прочесть его из поля другого типа, то я вас расстрою: в C++ согласно стандарту так делать нельзя.
nin-jin
20.06.2022 09:24+1Почему бы не поправить стандарт?
F0iL
20.06.2022 10:23+2В стандарте это сделали не просто потому что так захотелось, а по определенным причинам. Впрочем, можете предложить новую идею, вдруг члены комитета по стандартизации к вам прислушаются.
nin-jin
20.06.2022 10:59Не увидел там ничего про "нельзя", только "в общем случае небезопасно", но этот общий случай проявляется лишь в вариантах (когда мы засовываем в него что попало), а там никому не надо читать не тот тип, что записан. Во всех остальных применениях юниона (структурирование буфера) там всё вполне безопасно.
F0iL
20.06.2022 11:04+2Пункт 11.5 стандарта языка прямо говорит, что для структурирования буфера юниоин использовать нельзя:
At most one of the non-static data members of an object of union type can be active at any time
Авторы стандарта, осознавая опасность манипуляций юнионами со сложными типами в кривых руках, решили просто целиком и полностью запретить такие манипуляции (заодно дав компиляторам простор для применения разных оптимизаций). Если есть веские аргументы почему это правило можно и нужно изменить - ссылка о том, как отправлять предложения в комитет, дана выше
Правда, учитывая, что начиная с C++20 в языке появился std::bit_cast, сомневаюсь, что "мне нужен юнион для того чтобы кастовать буфер к структуре и обратно" будет хорошим аргументом :)
nin-jin
20.06.2022 12:00В вашей цитате нет ничего про "нельзя", да и быть не может, ибо это основная причина существования union вообще. Структурирование буфера - оно не про "сложные типы".
Рано или поздно вам надоест писать одни и те же касты во всех местах работы с полями и вы напишете класс *Union, который это инкапсулирует в себя, и получите те же самые юнионы, только с кучей кода и надеждой, что компилятор всё соптимизирует как надо.F0iL
20.06.2022 12:28В вашей цитате нет ничего про "нельзя"
Я просто ее не до конца скопипастил, там ещё потом идёт "...that is, the value of at most one of the non-static data members can be stored in a union at any time".
Если вы не верите тому, что говорю я, послушайте вот это отличное выступление с CppCon про каламбур типизации в современном C++.
Вы, конечно, можете продолжать спорить с очевидным, вот только корректным в соответствии со стандартом такой C++-код от этого не станет.

tsvetkovpa
20.06.2022 09:07+1Ближайшее, что есть для подробного в Java, это ByteBuffer.
Но позволяет читать один и тот же массив данных и как int и как byte
nmrulin
20.06.2022 13:34Спасибо , может мне пригодится. Интересно, как он внутри работает. В коде ByteBuffer.java описываются getFloat() и putFloat(float f) но самого кода , как это работает нет.
Единственное ,нашёл в модуле bits что-то вроде такого
static private int makeInt(byte b3, byte b2, byte b1, byte b0) { return (((b3 ) << 24) | ((b2 & 0xff) << 16) | ((b1 & 0xff) << 8) | ((b0 & 0xff) ));}
Kotofay
20.06.2022 21:06Примерно это работает вот так:
SocketChannel channel = ... int bytes = ( volts.length + currents.length + resistances.length + 1 ) * Double.BYTES; bytes += Integer.BYTES * 7; ByteBuffer bbw = ByteBuffer.allocateDirect( bytes ); bbw.order( ByteOrder.nativeOrder() ); bbw.putDouble( t ); bbw.putInt( callIndex ); // 0 - startIteration, 1 - doStep bbw.putInt( inCount ); bbw.putInt( outCount ); bbw.putInt( volts.length ); bbw.putInt( currents.length ); bbw.putInt( resistances.length ); bbw.putInt( flags ); bbw.asDoubleBuffer() .put( volts ) .put( currents ) .put( resistances ); bbw.rewind(); try { int sended = 0; while ( bbw.hasRemaining() ) { sended += channel.write( bbw ); } } catch ( Exception x ) { disconnect(); return; }sandersru
20.06.2022 21:37Самое зло с union - Это вызов его из Java. :) Год назад неделю промучался, чтобы вот это:
#define I2C_SMBUS_BLOCK_MAX 32 /* As specified in SMBus standard */ #define I2C_SMBUS_I2C_BLOCK_MAX 32 /* Not specified but we use same structure */ typedef union i2c_smbus_data { uint8_t byte ; uint16_t word ; uint8_t block [I2C_SMBUS_BLOCK_MAX + 2] ; // block [0] is used for length + one more for PEC } i2c_smbus_data; typedef struct i2c_smbus_ioctl_data { char read_write ; uint8_t command ; int size ; union i2c_smbus_data *data ; } i2c_smbus_ioctl_data;в ioctl передать из java... Неделя в GDB и профайлера и вот счастье... Которое закончилось ровно 2 дня назад. Тот же самый код - уже не работает :)
Ждет нас опять чудное сравнение байтов в памяти...
Kotofay
20.06.2022 22:05+1Тоже игрался долго.
Без "
ByteOrder.nativeOrder()"ничего не работало.Код выше обменивался с программой на С по сети.
#pragma pack(1) struct PICHeader { double time; uint32_t callIndex; // 0 - startIteration, 1 - doStep uint32_t inCount; uint32_t outCount; uint32_t volts; uint32_t currents; uint32_t resistances; uint32_t VccClk; };sandersru
21.06.2022 07:14Попробую, спасибо.
Вопрос: как человек более близкий к ось и сям - не подскажите, есть ли лёгкий способ трэйсить что в ioctl пришло (на примере этих структур хотя бы)
Kotofay
21.06.2022 11:20На реальных данных наверно долго будете искать ошибку.
Нужно написать тестовый пример, и заполнить известными данными. Потом вывести в лог побайтно и смотреть где компилятор вставил дырки для выравнивания.
Если используете MSVC то упаковка структуры с выравниванием до байта делается #pragma pack(1).
Если вы используете GCC/Clang то:
Использование
__attribute__((aligned(1)))сообщает компилятору, чтобы начать каждый элемент структуры на следующей границе байта, но не говорит, сколько места он может положить в конце. Это означает, что компилятору разрешено округлятьstructдо кратного размера машинного слова для лучшего использования в массивах и тому подобное.__attribute__((packed))сообщает компилятору, что он вообще не использует никаких дополнений, даже в концеstruct.struct foo {uint8_t bar;uint8_t baz;} __attribute__((packed));
event1
20.06.2022 15:58+2А потом можно перекомпилировать этот код на машине с другим порядком байт в слове и "happy debugging, suckers"
NightShad0w
19.06.2022 22:56+12Хорошая статья. И провокационная, и по делу. Спасибо.
Про 1-8 пункты помечтать не вредно. Вот как Комитет разрешит ломать обратную совместимость, так можно и предложения официально оформлять.
На текущий момент, мне вот крайне зашел Rust как язык, отринувший старье без душевных терзаний за это. Сразу оговорюсь, в Rust, на мой взгляд, крайне сырые и неудобные правила именования стандартных сущностей, репозиторий пакетов как огромная свалка сломанных и заброшенных библиотек, захвативших очевидные названия. Однако, логика языка, поддержка разных парадигм и встроенный инструментарий, готовность быть языком общего назначения — мне понравилась.
Пункт 9. С++ он все таки объектный язык. Из-за нам тут машет Smalltalk, который ввёл моду на ООП, но шила в мешке не утаишь, и перегруженную грамматику языка все-таки как-то надо реализовывать, ключевое слово class для объявления объекта в целом оправдано. struct и class вдвоем избыточны да. Haskell вот вводит data, type и, внезапно, newtype слова. Ну что вообще не лучше class/struct и using/typedef. А Хаскелл трудно упрекнуть в неточности.
Пункт 10. С++ — язык общего назначения, в том числе и для хардкорных, узко-специфичных библиотек и фреймворков. И, теоретически, фреймворк может заставить пользователя не расширять какие-то иерархии. ADL опять же. Пересечение со статической типизацией и мета-программированием конечно возможно, но теоретическая необходимость в Стандарте С++ во многих местах прослеживается. Правило 3(5 с недавнего времени) тоже не в каждой базе кода встретишь, но мы же не удаляем из языка методы-операторы присвоения и равенства.
Пункт 11. Виртуальные методы — центр всей объектной модели объектно-ориентированного языка общего назначения. Rust предлагает динамические трейты, Java — вообще вся насквозь по умолчанию виртуальные методы использует. Я не углубился в реализацию предложенной библиотеки, и могу ошибиться в суждении, но только виртуальные методы на уровне языка умеют пересекать границы бинарника без рекомпиляции. Все шаблонные башни и чернокнижные преобразования, сломаются, если потребуется передать новые типы, неизвестные в момент создания библиотеки. (Этот факт, кстати, вызывает у меня несказанное удивление до сих пор. Не имея стандартного ABI С++ позволяет передавать указатели на интерфейсы через границы бинарников и это чаще работает, чем не работает. Хотя в принципе не должно работать вообще, по аналогии с проблемой манглинга имен и передачи STL сущностей через границу бинарника.)
Пункт 12. С++ — объектно-ориентированный. Опять. Метод, это не столько еще один блок кода, который вызывается вокруг некоторого инстанса. (Тут нам передает привет Go, где указатель на метод и на функции — одно и то же, а получатель вызова по указателю и по значению — тема для продвинутых и особо не афишируется). В С++ метод — это не столько операция над аргументами, сколько операция над объектом в первую очередь. В идеальном ООП мире не существует c = a.add(b), однако, шаблоны Visitor или Builder полагаются на то, что методы выполняют не только работу над аргументами, но и над внутренним устройством типа. Ну и RAII без методов было бы ущербным. Нам опять передает привет Go, где потоко-безопасный множественный доступ в коллекцию из разных функцию — антипаттерн в пользу каналов или унылого бойлерплейта с мутексом и кастомным типом вокруг каждой коллекции. То, что метод в С++ неотъемлемая часть типа, это и ограничение и преимущество. И просто так избавляться от в целом невредного инструмента ну как-то импульсивно. ADL вот только для функций используется, и это прекрасно. Хочешь применить алгоритм к аргументам — используешь свободные функции, хочешь запускать сложную машинерию скрыто от глаз вызывающего кода(и для хитрого продакшен кода, и для тестов, почему нет) — методы наше все.
Kelbon Автор
19.06.2022 23:07Так методы фактически остаются, но понятие метод и указатель на метод исчезает, deducing this показывает что это вполне реальность
Насчёт пункта 11 - не то чтобы это должно было волновать С++ программистов, ведь длл вообще не существуют для С++. Но библиотека их(надеюсь) поддерживает, правда с дефайном (#define AA_DLL_COMPATIBLE ), можете посмотреть как оно реализовано(в стандартной библиотеке +- также работает междллное взаимодействие, насколько я знаю)
AnthonyMikh
20.06.2022 13:43+1в Rust, на мой взгляд, крайне сырые и неудобные правила именования стандартных сущностей <...>
Можете пояснить, что вы имеете в виду?
NightShad0w
21.06.2022 19:05+1C++ STL использует snake_case и преимущественно полные или достаточно длинные идентификаторы: std::shared_ptr; std::swap; std::in_place_index_t; std::format_to_n; std::unordered_multiset; std::condition_variable.
Комбинация типов через метапрограммирование хоть и монструозна, но псевдонимится через using, оставляя основное определение многословным, но однозначным. std::shared_ptr<std::variant<std::vector<std::string>, std::map<std::byte, std::string>>> не оставляет разночтений и места для предположений.Теперь смотрим в Rust, где хоть и есть стандарт по именованию, но он не помогает читать чужой код.
Типы именуем CamelCase, функции и модули — snake_case.
Комбинированное внесение в область видимости заставляет спотыкаться:
use datafusion::logical_plan::{DFField, DFSChema, lit_timestamp_nano};use std::path::{Path} дублирование разным регистром выглядит подозрительно избыточно, хоть и теоретически обоснованно, потому что модули и тип это разные сущности.
use std::sync::Arc — причем здесь потокобезопасная дуга? Нет, Atomically Reference Counted. Теперь мы подготовлены к std::sync::Condvar, std::path::PathBuf;
std::sync::mpsc::channel — Multi-producer, single-consumer FIFO queue communication primitive.
std::rc::Rc мы уже понимаем как Reference Counter; но std::rc::Weak вообще прилагательное. И мы додумываем, что это про слабый счетчик ссылок.To/From, Into_ типы, трейты и вспомогательные функции тоже не самодостаточно именнованы, чтобы понимать о чем речь. Какое правило по превращение одного в другое: B = A.into() или B = B.from(A), и прочие противоречивости.
От аббревиатур в CamelCase к Rust сущностям.
std::boxed::Box, что по сути является указателем на динамически выделенную в куче память. И ничего общего с боксингом/анбоксингом значений в Java, или двумерной фигурой с 4 углами.И std::borrow::Cow, который не про одолжить корову у соседа, и даже не про одолжение Copy-On-Write.
The type Cow is a smart pointer providing clone-on-write functionality: it can enclose and provide immutable access to borrowed data, and clone the data lazily when mutation or ownership is required.std::cell::{RefCell, RefMut, Cell}; без подглядывания в референс мануал напрашиваются какие-то клетки или ячейки, а ведь это A mutable memory location. И это совсем не про memory buffer.
DarkEld3r
21.06.2022 21:54+2Может у меня глаз замылился, всё-таки пишу уже несколько лет на расте, но честно говоря не припоминаю, чтобы даже на заре знакомства с языком эти "неочевидности" вызывали вопрос. Хотя первое время "ломка" и была из-за того, что многое хотелось писать как привык в С++. Но да, люди разные, так что аргументировать личным опытом — такое себе. Теперь мне даже интересно у многих ли людей такие же вопросы возникают...
Комбинированное внесение в область видимости заставляет спотыкаться:
А мне наоборот нравится, что сразу видно где тип, где функция, где переменная, а где константа.
To/From, Into_ типы, трейты и вспомогательные функции тоже не самодостаточно именнованы, чтобы понимать о чем речь. Какое правило по превращение одного в другое: B = A.into() или B = B.from(A), и прочие противоречивости.
Вот это не очень понял. Почему
FromиIntoименованы не самодостаточно, если всё что они делают — это просто преобразуют из одного типа в другой. Как-то даже затрудняюсь придумать как название можно расширить чтобы сделать "более очевидным".Зачем два? Потому что много где не надо явно указывать целевой тип — он будет известен из контекста и достаточно просто
а.into(), а там где нужно указать тип — там удобнееX::from. В доке, вроде как, вполне внятно это описывается, а так же какой из трейтов надо реализовывать чтобы автоматически получить реализацию второго.

zakker
19.06.2022 23:43+2Про virtual не понял. Вы хотите как в java, где все, что не помечено как final или private, по факту virtual? Или вообще vtable выпилить из языка? Если vtable убирать, то я против. Это очень мощная фича языка и я даже не представляю, как писать эффективный код без этого.
Kelbon Автор
19.06.2022 23:53-1Посмотрите на примеры с гитхаба в том же пункте. Нет, мне не нужны везде virutal, наоборот, отделение типа и его полиморфизма
template<typename T> struct Say { static void do_invoke(const T& self, std::ostream& out) { self.say(out); } }; using any_animal = aa::any_with<Say>; struct Cat { int field; void say(std::ostream& out) const { out << "Meow\n"; } }; struct Dog { std::string field; void say(std::ostream& out) const { out << "Woof!\n"; } }; int main() { any_animal Pet = Cat{}; }Как вы можете видеть здесь any_animal - тип созданный библиотекой, он может хранить любой другой тип с требуемыми методами( в данном случае Say)

Ritan
20.06.2022 01:57+6Вот только эта либа желает динамическую аллокацию памяти на КАЖДЫЙ чих. И да, таблицы виртуальных функций там всё ещё есть, только теперь девиртуализация с эти и чудом невозможна, любые оптимизации с вызовом final невозможны. Если для вас всё это ок, то может вам и плюсы не нужны? Ну пишите вы на питоне, зачем мучаться
Kelbon Автор
20.06.2022 08:29+1Что вы несёте? Где там нужна аллокация на каждый чих? Может вы посмотрите как используют СЕЙЧАС виртуалньые функции, когда каждый объект выделен в куче?
А в библиотеке как раз этот недостаток убирается и можно как изменить аллокатор так и просто ничего не делая получать бонусы от small object optimization
Пожалуйста, если вы не разбираетесь в вопросе - не делайте таких уверенных утверждений
P.S. оптимизации очевидно всё ещё возможны, потому что это всё ещё код, который можно оптимизировать. Даже больше - языковой vtable оптимизируется менее охотно, ведь он языковой и гарантируется чем-то, плюс там часто куча лишней информации,раздувающей бинарник, в либе этого уже нет, только нужное
zakker
20.06.2022 10:28+2Правильно ли я понял, что автор библиотеки реализовал виртуальные методы на шаблонах, со своей собственной vtable? И что в итоге получили? Усложнение синтаксиса. Ну да ладно, привыкнуть можно. К генерации столь-же оптимального кода, как сейчас на встроенном vtable тоже есть вопросы. Я бы не стал тут полагаться на магию оптимизатора. А вот умеет ли библиотека (не сильно ковырялся в ней) делать множественное виртуальное наследование? Да, это спорная фича и вызывает у многих вопросы, но в моей практике множественное виртуальное наследование довольно часто оказывается самым удобным, быстрым и красивым решением задачи.
Так что все равно нет.

Helltraitor
19.06.2022 23:53+6Однажды автор познакомится с Rust и будет ему счастье. Ну серьезно, для меня C++ это прежде всего ООП язык с упором на скорость и удобство разработки (в последних стандартах), мне нравится на нем программировать, но я делаю это без использования каких-либо сложных концепций (ламер на C++, использующий только умные указатели вне функций)

PkXwmpgN
20.06.2022 01:50+5Следующий код полностью заменяет юнион, не имеет никакого оверхеда относительно него и имеет более понятный пользователю интерфейс (emplace / destroy)
Как вы лихо запихали
placement newиreinterpret_castв constexpr-контекcт. Можете продемонстрировать как вы замените вот такой код с помощью вашегоunion_t?struct T { union { int n; float f; }; constexpr T(int a) : n(a) {} constexpr T(float b) : f(b) {} }; int main() { constepxr T a = 1; constexpr T b = 0.5f; static_assert(a.n == 1); static_assert(b.f == 0.5f); }И реальный кейс: как вы планируете реализовать стандартный
std::optionalбез union илиstd::variant?Как же их заменить? Рекусивным(или через множественное наследование) туплом с элементами одного типа(да, это было очевидно)))
Вы же это несерьезно, правда?
https://cppinsights.io/s/62550a23 и вот это у вас будет в каждом юните трансляции?Kelbon Автор
20.06.2022 08:35-5И реальный кейс: как вы планируете реализовать стандартный
std::optionalбез union илиstd::variant?Как массив байт с правильным алигментом, прямо в статье код делающий всё что вам нужно. Если вы не знаете способа - не значит что его нет
PkXwmpgN
20.06.2022 09:13+1Хорошо. Можете, пожалуйста, на https://godbolt.org привести код инициализации и использования вашего union_t в constexpr-контексте. Не важно каким компилятором и стандартом вы это сделаете?
Как массив байт с правильным алигментом, прямо в статье код делающий всё что вам нужно
И было бы здорово посмотреть, думаю не только мне, как вы с помощью массива байт реализуется ваш
fucking::optional<T>какliteral type, что требует стандарт.Kelbon Автор
20.06.2022 09:44Для optional и variant вообще то исключения в стандарте на использование в constexpr контексте. Никаким языковым способом не реализуемо на данный момент сделать их constexpr. Только внутренняя реализация компилятора может это позволить
Если бы это было возможно, то был бы разрешён reinterpret_cast и bit_cast указателей в constexpr контексте, но это запрещено
PkXwmpgN
20.06.2022 10:04+1Никаким языковым способом не реализуемо на данный момент сделать их constexpr.
Это реализуется за счет union.
Заменить это всё можно одним фундаментальным типом byte и указателями, действительно: с помощью byte и системы типов С++ можно создавать любые типы, в том числе аналогичные int, double, float, bool и т.д. из фундаментального набора. Тут мы убиваем сразу несколько зайцев - нет больше исключений для фундаментальных типов в разрешении перегрузки, нет исключений в шаблонном коде для наследования( от фундаментальных типов нельзя наследоваться) ну и другие более мелкие исключения для подобных типов уходят в прошлое
И одним из этих убитых "зайцев" будет видимо constexpr.
Kelbon Автор
20.06.2022 10:46нет не реализуемо, просто создать переменную в юнионе - бесполезно. Пользоваться юнионом на компиляции вы не сможете (так как на компиляции undefined behavior это ill formed программа)
PkXwmpgN
20.06.2022 11:03https://eel.is/c++draft/expr.const#5
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p1330r0.pdfKelbon Автор
20.06.2022 11:22Это равносильно созданию одной переменной, о чём я и написал. При реализации variant вы не сможете обойтись без placement new и reinterpret_cast в том или ином виде.
Kelbon Автор
20.06.2022 08:38-2Вы всерьёз смотрите на то, что выплёвывает cppinsights? Это не то что реально происходит, а лишь какая то демонстрация непонятная
https://godbolt.org/z/oW4zEc7hK
И во вторых, если в ЯЗЫКЕ нет массива, это не значит что РЕАЛИЗАЦИЯ(например от msvc) не сможет его сделать на built-in'ах, при этом ничего не потеряв вы убрали лишнюю вещь из языка. Перечитайте и подумайте над этим
Cerberuser
20.06.2022 08:57+2если в ЯЗЫКЕ нет массива, это не значит что РЕАЛИЗАЦИЯ(например от msvc) не сможет его сделать на built-in'ах
То есть Вы предлагаете рассчитывать на нестандартные вендорские расширения (в ещё большей степени, чем это происходит сейчас)?
Kelbon Автор
20.06.2022 09:02Вот вам очень похожий случай:
template <class _Ty, _Ty _Size> using make_integer_sequence = __make_integer_seq<integer_sequence, _Ty, _Size>;Никаких расширений. Вы не знаете как это реализовано. На уровне языка нет понятия index_sequence. Реализуется только через рекурсию внутри языка. Но как вы видите компилятор делает реализацию не через рекурсию, а через встроенный в компилятор механизм.
И в языке нет лишних сущностей и вы ничего не потеряли как пользователь
Cerberuser
20.06.2022 09:05+2Если этого нет на уровне языка, то, вообще говоря, потерял - возможность перенести этот код на другой компилятор и знать, что он скомпилируется и отработает как ожидается.
Kelbon Автор
20.06.2022 09:52Если другой компилятор не даёт вам этого, значит он не поддерживает стандарт языка, значит он не компилятор С++, значит вам не нужно переносить на него код
Cerberuser
20.06.2022 09:55+2Так если это требуется стандартом - значит, это всё-таки есть на уровне языка?
0xd34df00d
20.06.2022 18:30+1Нет, потому что это библиотечная функция, поэтому она может пользоваться интринсиками компилятора. Ожидать от другого компилятора поддержки тех же интринсиков как-то глупо.
Условно, я могу
is_sameреализовать через специализацию шаблонов, а могу — через интринсик в моём компиляторе. Непереносимость второго варианта кода на любой другой компилятор не делает любой другой компилятор несовместимым с плюсами — она делает мою реализацию несовместимой со стандартным C++.Да, в стандарте есть некоторые вещи, которые нельзя сделать иначе как интринсиками, но
make_integer_sequenceне из них.Kelbon Автор
20.06.2022 18:34так вы используйте не интринсики, а интерфейс стандартной библиотеки. Я указал, что это реализуемо рекурсией, но никто так не делает
PkXwmpgN
21.06.2022 09:06+1Это не то что реально происходит, а лишь какая то демонстрация непонятная
Хорошо, не нравиться cppinsight, давайте посмотрим на AST или трансляция кода это тоже не то, что реально происходит?
Вот для вашего примера
https://godbolt.org/z/3f1rMWG4eА вот для обычного массива
https://godbolt.org/z/4T6hGoKnWИ во вторых, если в ЯЗЫКЕ нет массива, это не значит что РЕАЛИЗАЦИЯ(например от msvc) не сможет его сделать на built-in'ах, при этом ничего не потеряв вы убрали лишнюю вещь из языка.
Это также не значит что реализация СМОЖЕТ это сделать.
Но если предположить что смогла. Вот я могу взять clang и использовать стандартную библиотеку gcc или наоборот. По libc++, например, https://libcxx.llvm.org/#platform-and-compiler-support. Как это должно работать? Вы предлагает стандартизировать built-in'ы?

suns
20.06.2022 08:17+4У компиляторов есть ограничение на шаблонные рекурсии, так что ваш аналог std::array работает только на крошечных примерах (для clang, если память не изменяет, до 512 ограничение)
На счет слова final - оно позволяет оптимизировать прямые вызовы функций final-типа, т.е. теряется оверхед на поход в vtable
Kelbon Автор
20.06.2022 08:33-3если в ЯЗЫКЕ нет массива, это не значит что РЕАЛИЗАЦИЯ(например от msvc) не сможет его сделать на built-in'ах, при этом ничего не потеряв вы убрали лишнюю вещь из языка. Перечитайте и подумайте над этим
Практика показывает, что ничего не оптимизируется. Или оптимизируется абсолютно также как без final
Добавлять ключевое слово исключительно для оптимизации, ломая при этом шаблонный код - безумие

Vitaly83vvp
20.06.2022 08:27+2Сложилось впечатление, что автору статьи С/С++ не подходит. Лучше ему поискать другой язык.

lastmac
20.06.2022 08:48+2Нет же. Автор исходит из мысли «мне это не нравится (я это не использую), значит всем остальным не надо».

lncubus
20.06.2022 08:32-1Уважаемый автор предлагает нечто очень странное, на мой взгляд.
То есть вот до отказа от таблицы вирт. функций еще можно было себе представить реализацию этого, но тут соломинка все же сломала верблюду хребет.
Kelbon Автор
20.06.2022 08:32Идите по ссылке и посмотрите как это реализовано. И не было никакого отказа от таблиц виртуальных функций, был отказ от ключевого слова virtual
eao197
20.06.2022 08:47+1Если мне не изменяет склероз, то вот тут:
template<one_of<Ts...> U> constexpr U& emplace(auto&&... args) { return std::launder(new(data) U{std::forward<decltype(args)>(args)....}); }std::launderне нужен, т.к. у нас есть результат placement new, который "отмывать" уже не нужно.std::launderпотребовался бы вот в таком случае:template<one_of<Ts...> U> constexpr U& emplace(auto&&... args) { new(data) U{std::forward<decltype(args)>(args)....}; ... return std::launder(reinterpret_cast<U*>(data)); }PS. Статью целиком не осилил.

DX168B
20.06.2022 08:54-1Короче, выбросить всё, что активно используется в embedded. Не, так не пойдет.

NeoCode
20.06.2022 10:02+7Я категорически против большинства ваших предложений:)
Вы предлагаете выбросить все простое и заменить это какими-то мозгодробительными решенями на шаблонах.
А я бы наоборот выкинул метапрограммирование на шаблонах, ограничил бы шаблоны их изначальным применением (параметризированные алгоритмы и структуры данных), а для метапрограммирования ввел бы нормальные императивные синтаксические макросы.
Ваши примеры при беглом взгляде совершенно непонятны. Наверное, если помедитировать над ними, то станет понятнее, но зачем? union, массивы, базовые типы - это основы, они просты и понятны. А вы предлагаете и дальше продолжить переносить кишки компилятора наружу, в шаблоны. И в результате С++ превратится в интерпретатор некоего функционального языка с уродским синтаксисом, на котором будет написан некий объектно-ориентинованный язык (с не менее уродским синтаксисом), и вот на смеси этих двух языков и предлагается писать программы обычным программистам.
Отчасти соглашусь с отказом от сишного приведения типа - оно неудобно для поиска в коде, т.к. нет ключевого слова. Также соглашусь с тем что typedef и using пересекаются, можно оставить что-то одно.

staticmain
20.06.2022 12:41Автор предлагает убрать массивы, но сделать *(a + n)
return *(reinterpret_cast<T*>(reinterpret_cast<void*>(this)) + n);Кажется человек не очень понимает, что есть [ ] на самом деле.
Kelbon Автор
20.06.2022 12:57??? В чём проблема?) Я специально использовал здесь не [], чтобы самые умные читатели не начали причитать, что я тут синтаксис массива использую в реализации массива.
К оператору [] претензий нет, а вот к массиву в языке - есть. Как показано в статье, массив как языковая абстракция не нужен
playermet
20.06.2022 13:23К оператору [] претензий нет, а вот к массиву в языке - есть
А надо бы наоборот. Потому что сейчас это может работать так:
foo = 5[bar];

HEXFFFFFFFF
20.06.2022 10:02-1Про union вообще не понял. Очень частая задача в с++ (я пишу под микроконтроллеры) это представить какую либо структуру как массив байт( например что бы сохранить на флеш, или отппавить кудато) Бывает так же , например, ситуация когда dword хочется представить как два int ну итд. Без подобных преобразований просто не обойтись. Как автор предлагает действовать без union?
F0iL
20.06.2022 10:45+3Вариантов реализации type-puning'а на C++ чуть ли не десяток. Проблема в том, что практически все из них (в том числе и ваш любимый вариант с union) являются некорректными (а следовательно, опасными) с точки зрения стандарта языка.
Поэтому среди них единственными правильными и переносимыми являются std::bit_cast (начиная с С++20) иstd::memcpy(&destination, &x, sizeof(x). Современные компиляторы трюк с memcpy легко узнают и оптимизируют как надо, поэтому по факту в плане производительности разницы с union никакой.

Gumanoid
20.06.2022 11:05+1Подобное преобразование нелегально в C++, но т.к. многие его используют по привычке из C, то компиляторы предпочитают не ломать такой код: https://stackoverflow.com/questions/11373203/accessing-inactive-union-member-and-undefined-behavior

Static_electro
20.06.2022 10:21у меня один вопрос, вот здесь:
template<one_of<Ts...> U>
constexpr void destroy_as() const {
reintepret_cast<const U*>(reinterpret_cast<void*>(data))->~U();
}мне предлагается руками писать тип, который я хочу дестроить? Или я просто чего-то не понял?
Kelbon Автор
20.06.2022 11:04+2В обычном union вам никто даже не предлагает этого, просто если вы не сделаете - ваша программа не является программой на С++

FloorZ
20.06.2022 10:35Если union не нужен, то почему почти в каждом игровом движке, даже на C++17, они пишут самодельную реализацию Variant типа, под капотом которого union, а не шаблон c new? Или интерпретаторы с универсальными типами?
Kelbon Автор
20.06.2022 11:06+2Как человек, который реализовывал variant и многие другие вещи могу точно сказать, что реализовать variant через union СЛОЖНЕЕ, чем просто через массив байт. ОСООБЕННО таким образом, чтобы соблюсти гарантии языка
F0iL
20.06.2022 12:51boost::variant2 использует union'ы. Правда, весьма своеобразно :) Оригинальная же реализация, как вы и сказали, работает через массив байт.
AnthonyMikh
20.06.2022 13:55+2Реализация массива без массива:
Арифметика указателей не работает на
void*. Я бы понял, если бы каст был кchar*илиbyte*, но так, как сейчас, это на конформном компиляторе не работает.6 — typedef
typedefможно положить в заголовочный файл, разделяемый между C и C++,using— нет.

truthfinder
20.06.2022 16:37Что-то автор не сильно углубился в тему: всё равно всё превращается в биты, давайте писать сразу ими.

Soukhinov
20.06.2022 20:03Да. Из типов данных оставить только некий
bit. Оптимизирующий компилятор должен «узнавать» реализации популярных операций над группами битов, и использовать имеющиеся функции процессора.
Soukhinov
20.06.2022 19:51Автор, пожалуйста, сделайте что-нибудь с инициализацией! Сейчас инициализировать можно знаком
=, круглыми скобками, фигурными скобками…
И с преобразованиями типов тоже что-нибудь сделайте. Сейчас можно писатьint(a),(int)a,static_cast<int>(a).

maeris
20.06.2022 20:11правда можем убрать из С++ массивы не потеряв ничего
И буквально абзацем выше через них юнионы заимплеменчены. Что ж вы сразу не попробовали хотя бы примеры без всех ненужных фич написать? Может, потому что так получается ещё непонятнее?
Как дела с арифметикой указателей у массивов-через-иерархию наследования? Даёт ли стандарт гарантии относительно раскладки в памяти полей классов, которые не POD? В целом эти вот массивы через
reinterpret_castвыглядят как прямая дорога в UB.maeris
20.06.2022 20:19Предлагаю расширить идею автора: берём ассемблер с одной инструкцией
db 0xHH, подкладываем его под Forth, и в библиотеке имплементим все эти вот ваши новомодные структуры, юнионы и шаблоны, пока не получим С++. Всё по стандарту (Forth'а), в языке никаких ненужных фичей нет, всё вообще эксельсиор и дистинктивно.
Kelbon Автор
21.06.2022 07:24То есть std::array<std::byte, N> это вам непонятно? Как реализовать этот массив я показал

nickolaym
21.06.2022 23:261) Как только вы в своём велосипедном union задействовали placement new, - вы автоматически выбросили constexpr. В отличие от оригинального, встроенного в язык.
2) У любого компилятора есть ограничения на размер набора параметров шаблона и на глубину рекурсии времени компиляции. Сделайте массив на 100000 элементов.
3) std::monostate.
4) Докопались до столба. Если вы реально занимаетесь поддержкой зоопарка платформ, то разрядность int вас будет волновать лишь наряду с другими вещами. А если не занимаетесь, и не прижимаетесь к границам максимальных значений на вашей платформе, то повсеместно уточнять int8_t, int16_t, int32_t, int64_t для каждой переменной - только голову себе морочить.
4.5) Да. Коропоративные стили кода и агрессивные линтеры вам в помощь.
5) Большей частью - да. Но компиляторы умеют ловить ошибки в сишных вариадиках. А по части производительности - printf, например, жэстачайше уделывает std::iostream. И где нужна скорость, нужно оставить возможность.
6) Да. Только для хедеров, совместимых с обоими языками, придётся сохранить. Потому что сишный ABI рулит как наибольший общий знаменатель.
7) Макросы нужны. Не нравятся такие - предложите другие. m4? Гигиенические макросы из лиспа или немерле?
8) Действительно, зачем нам эти операторы, если сами же в первом же пункте на них что-то наколбасили?
9) Много не потеряем, можно всё лепить на struct - и прописывать доступы.
10) final - чтобы рукожопые студенты не наследовались от std::vector. Типы с семантикой значения должны быть final, попробуйте понять, почему.
11) Полиморфизм без таблиц - это или оверхед в экземпляре класса, или всё равно таблицы, только без ключевого слова virtual. А вообще, стирание типов давно уже есть в boost::any. Да и даже в std::shared_ptr.
12) Гвидо ван Россум, отстаньте уже, пожалуйста. Над питоном в младенчестве надругались, это не значит, что надо над всеми остальными языками то же самое делать.
AnthonyMikh
22.06.2022 01:55+15) Большей частью — да. Но компиляторы умеют ловить ошибки в сишных вариадиках. А по части производительности — printf, например, жэстачайше уделывает std::iostream.
А fmtlib уделывает printf.
Но компиляторы умеют ловить ошибки в сишных вариадиках.
А можете продемонстрировать пример? И желательно не на стандартной функции, для которой поддержку в компиляторе можно и захардкодить.
Kelbon Автор
22.06.2022 13:45Вы не знаете С++, constexpr создание элемента где-то возможно только с С++20 std::construct_at, для которого сделано исключение на конструирование на компиляции
В реализации массива в статье нет рекурсии, вы не знаете С++ и не понимаете этого
Нет, это ничего не имеет общего с std::monostate. это называется тег тип и таких типов в стандартной библиотеке великое множество, std::piesewise_construct, std::nothrow, std::monostate, std::forward_iterator_tag и все остальные теги и так далее
Если вы не уточняете какое максимальное число вам нужно хранить в инте, то вы либо используете гарантированные стандартом 2^16, либо ваш код потенциально содержит undefiend behavior
-
printf ужасно медленный, он уделывает iostream потому что iostream сделан плохо. В древние времена туда добавили виртуальные функции, виртуальное наследование, возможность ребиндить стрим на другой, кривое форматирование и громадное количество флажков ошибок/исключений/форматирования
В современном С++ это всё может быть заменено куда более хорошими вещами, например std::print , std::format и так далее. Они быстрее printf, потому что в них нет рантайм определения типа аргумента, это просто факт
Компиляторы делают костыли, чтобы проверять форматные строки printf на компиляции, стандарт С++ ничего об этом не говорит
extern "C"
Функциональные макросы не нужны, они ужасны
В этом же пункте я ЯВНО указал, что нужен ТОЛЬКО оператор РАЗМЕЩАЮЩЕГО new, который и использован в 1 примере. Размещающий(Placement), тот который НЕ выделяет память и НЕ связан с системным аллокатором
Да, именно поэтому class лишнее в языке
std::vector не объявлен final, потому что разработчики стандарта понимают, что final даже в случае std::vector неприменим
В статье нет ничего про убирание таблиц, есть про убирание ключевого слова virtual и связанных с ним нагромождений в стандарте. boost::any и std::any ужасны и неприменимы на практике, а в библиотеке по ссылке https://github.com/kelbon/AnyAny концепции стирания типов обобщены и легко кастомизируемы, по сути этот репозиторий - доказательство, что virutal лишнее в языке
Скажите это коммитету по стандартизации ,который принял deducing this в С++23 и это теперь реальность плюсов
panteleymonov
C++ он и есть от того С++, что к языку С добавили эти самые ++. А если хотите чистые ++, то тогда тут нужен другой язык.
Вот вам другое мнение для размышления: почему язык C++ развивается не согласованно со стандартами языка С? Как это подразумевалось при его создании чтобы расширить возможности С. А рождает вместо этого противоречивые костыли.
Kelbon Автор
С развивается?..
Artem_Mironov
Вполне себе развивается, можете будущий C23 стандарт глянуть
Kelbon Автор
там практически ничего не добавляется, а компилируется С++ код с С99 или чем нибудь таким
Artem_Mironov
Не до конца понял что с чем компилируется. Если вы имели ввиду компилить C++ код под стандарт C99, то далеко не всякий C++ код будет компилиться таким образом.
Никто и не ожидает от небольшого низкоуровневого языка кардинальных изменений.
MarkusD
До стандарта C++17 совместимым с C++ стандартом был C98. Не C99.
Начиная со стандарта C++17 совместимым с C++ стандартом стал C11.
Стандарт C, при этом, и обновляется, и улучшается. Многие спорные практики из ранних стандартов C сейчас или утратили силу, или получили титул опциональных.
Зачем чинить инструмент, который не сломан? Как исправлять инструмент, который достаточно эффективно покрывает задачи своего применения?