


Наблюдаемость (observability) — это супермножество мониторинга. В дополнение к подробному анализу неявных состояний, приводящих к сбоям, это свойство предполагает высокоуровневый обзор работоспособности системы. Кроме того, наблюдаемая система предоставляет подробную информацию о своей внутренней работе, что позволяет обнаруживать более глубокие системные проблемы.
Развернув сервис в рабочей среде, мы хотим знать, как он справляется с поставленной задачей, анализируя количество запросов в секунду, использования ресурсов и т. д. Кроме того, мы должны быть немедленно предупреждены, если возникает какая-нибудь проблема, например, неисправен инстанс какого-либо сервиса или на диске заканчивается место, в идеале до того, как это скажется на пользователях. В случае возникновения проблемы нам нужно иметь возможность как можно быстрее выявить и устранить неисправности, а затем провести RCA (root cause analysis — анализ первопричин).
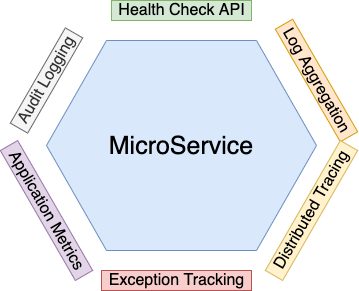
Как разработчики сервисов, мы имеем в своем арсенале несколько паттернов, реализовав которые, мы облегчим управление сервисами и устранение неполадок. Следующие паттерны призваны помочь нам в разработке наблюдаемых сервисов:
API проверки состояния (Health check API) — Вы можете указать специальную конечную точку, которая возвращает работоспособность сервиса.
Агрегация логов (Log aggregation) — Вы можете логировать активность сервиса и хранить эти логи на централизованном лог-сервере, который должен реализовать оповещения и удобный функционал поиска.
Распределенная трассировка (Distributed tracing) — Вы можете присваивать всем внешнем запросам уникальные идентификаторы, чтобы отслеживать весь их путь от сервиса к сервису внутри вашей системы.
Отслеживание исключений (Exception tracking) — О возникающих в вашей системе исключениях следует сообщать в специальную службу отслеживания исключений, которая устраняет дублирующиеся исключения, оповещает разработчиков и отслеживает, как они впоследствии разрешаются.
Метрики приложения (Application metrics) — Сервисы могут содержать внутри себя такие метрики, как, например, счетчики (counters) и датчики (gauges), чтобы сервера метрик могли собирать их показатели.
Ведение журнала аудита (Audit logging) — Для отслеживание действий пользователей.
API проверки состояния
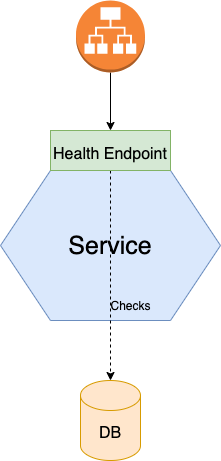
Иногда бывает так, что сервис работает, но не может обрабатывать запросы. Недавно запущенный инстанс сервиса может все еще инициализироваться и выполнять проверки работоспособности, прежде чем он сможет приступить к обработке запросов. Инфраструктуре развертывания нет смысла направлять HTTP-запросы в инстанс сервиса, пока он не будет готов их обработать.
Также может случиться так, что инстанс сервиса выходит из строя без корректного завершения и поэтому, например, все соединения с БД будут заняты, и доступ к базе данных будет невозможен. Инфраструктура развертывания не должна направлять запросы в инстанс сервиса, который дал сбой, но все еще работает; если инстанс сервиса не может восстановиться, то нужно завершить его работу и создать новый инстанс. Инстанс сервиса должен отчитываться перед инфраструктурой развертывания, способен ли он обрабатывать запросы. Для этого вы можете использовать Spring Boot Actuator, который реализует конечную точку состояния (health endpoint), чтобы реализовать собственную конечную точку проверки работоспособности для ваших сервисов.
Агрегация логов
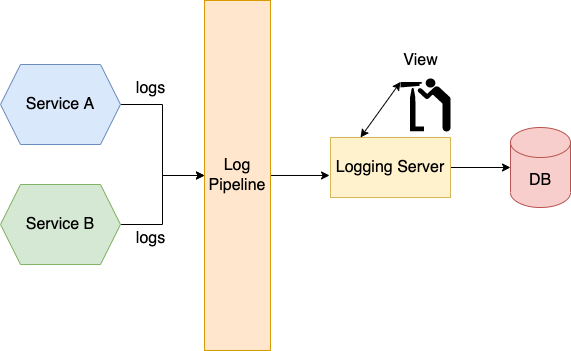
Логи могут оказать неоценимую помощь в устранении проблем. Лог-файлы — отличное место для старта, если вы хотите определить, что не так с вашим приложением. Но логирование в микросервисной архитектуре может быть непростой задачей, поскольку логи разбросаны по файлам в разных сервисах.
Агрегация логов — решение этой проблемы. Конвейеры агрегации логов отправляют логи всех инстансов ваших сервисов на централизованный лог-сервер. Когда логи хранятся на специальном лог-сервере, их можно с удобством просматривать, производить поиск и анализ. Вы также можете создать оповещения, которые будут срабатывать при появлении определенных сообщений в логах.
Отвечает за агрегирование логов, их хранение и обеспечение возможности поиска по ним специальная инфраструктура логирования. Существует целый ряд популярных инструментов, обеспечивающих агрегацию логов: Splunk, Fluentd, стек ELK, Graylog и т.д.
Распределенная трассировка
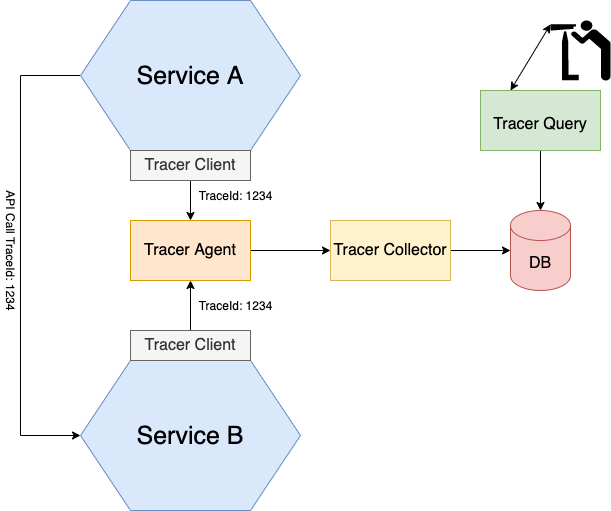
Представьте, что вы занимаетесь поиском проблемы, связанной с медленным ответом API. С этим ответом API может быть связано сразу несколько сервисов. Использование распределенной трассировки может помочь вам получить представление о том, что происходит в вашем приложении. Распределенный трассировщик чем-то похож на профилировщик производительности в монолитном приложении. Он фиксирует информацию о вызовах сервисов, сделанных в рамках обработки запроса. Позже вы можете увидеть, как сервисы взаимодействуют во время обработки внешних запросов, а также сколько времени тратится на работу каждого из сервисов.
Каждому внешнему запросу присваивается уникальный идентификатор, по которому можно отследить его путь от одного сервиса к другому на централизованном сервере, обеспечивающем визуализацию и анализ. Среди самых популярных серверов для распределенной трассировки можно выделить Zipkin, Jaeger, OpenTracing, OpenCensus и New Relic.
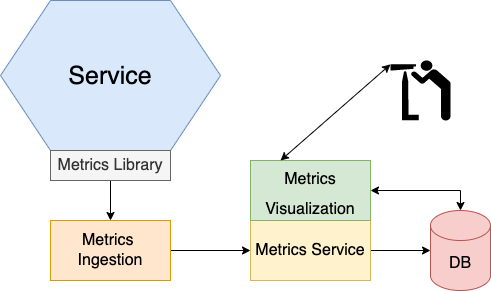
Метрики приложения
Мониторинг и оповещение являются ключевыми компонентами производственной среды. Системы мониторинга собирают метрики, которые предоставляют важную информацию о работоспособности приложения из всех частей его технологического стека. Метрики варьируются от инфраструктурных, таких как использование ЦП, памяти и дискового пространства, до метрик уровня приложения, таких как величина задержки при ответе на запрос и количество обработанных запросов.
Касательно метрик, разработчик сервиса должен позаботиться о двух вещах. Для начала он должен инструментировать свой сервис для сбора метрик о его поведении. Во-вторых, он должен предоставлять эти метрики сервиса, а также метрики из JVM и инфраструктуры приложения серверу метрик. Служба сбора метрик приложения может быть чем-то похожим на AWS CloudWatch или Prometheus, которые опрашивают конечные точки для сбора метрик. Для просмотра метрик, как только они появятся в Prometheus, можно использовать инструмент визуализации данных наподобие Grafana.
Отслеживание исключений
Когда сервис регистрирует исключение, очень важно определить причину его возникновения. Исключения указывают на проблему или программную ошибку. Традиционно для сбора исключений используются логи. Вы даже можете настроить лог-сервер так, чтобы он предупреждал вас, если в лог-файлах регистрируется исключение. Однако у этого есть несколько недостатков:
Лог-файлы состоят из однострочных записей, а исключения состоят из нескольких строк.
В лог-файлах не предусмотрен механизм отслеживания разрешения исключений. Вам нужно будет вручную скопировать/вставить исключение в баг-трекер.
Невозможно автоматически обрабатывать повторяющиеся исключения как одно.
Службы отслеживания исключений — лучший подход. Сервисы сообщают об исключениях в централизованный службу, которая устраняет дублирующиеся исключения, генерирует оповещения и берет на себя управление исключениями. Среди таких служб можно выделить Honeybadger и Sentry.

Ведение журнала аудита
Действия каждого пользователя записываются в журнал аудита. Как правило, журналы аудита используются для поддержки клиентов, обеспечения соблюдения требований и обнаружения подозрительных действий. Запись в журнале аудита фиксирует личность пользователя, выполненное им действие и задействованный бизнес-объект. Журнал аудита обычно хранится в виде таблицы в базе данных.
Ведение журнала аудита можно реализовать несколькими способами:
Добавить код ведения журнала аудита в бизнес-логику — Каждый метод сервиса может создать запись в журнале аудита и сохранить ее в базе данных.
Аспектно-ориентированное программирование (AOP) — Вы можете определить рекомендации, которые перехватывают каждый вызов метода сервиса и сохраняют запись в журнале аудита, используя AOP-фреймворк, такой как Spring AOP.
Использовать event sourcing — Регистрация событий по умолчанию предоставляет журнал аудита под операции создания и обновления.
По определению, паттерны наблюдаемости связаны не сколько с логами, метриками или трейсами, а с грамотным управлением данными во время отладки и использованием фидбека для итерации и улучшения продукта.
Приглашаем всех желающих на открытое занятие «GIT 101: совместная работа, CI, вендоринг». На уроке поговорим про основы git, как и какой git выбрать, как начать работать. Рассмотрим командную работу в git, git flow, pull-реквесты, вендоринг; теги, релизы и сборка кода. Регистрация доступна по ссылке.