
Всем привет! Сегодня мы поговорим об интеграционном тестировании платежного шлюза, но перед этим расскажу немного про нашу команду и наш проект. Мы (ContactPay) — самостоятельный финтех-стартап внутри QIWI, строим высокопроизводительный отказоустойчивый платежный шлюз и соответствуем стандартам безопасности PCI DSS.
Как платежный шлюз мы интегрированы со множеством внешних API, это могут быть и платежные системы, и сторонние сервисы мониторинга, антифрода, KYC (know your customer) и так далее.

Как финтех — работаем с большим количеством финансовых данных, и нам важны и сохранность, и консистентность и безопасность данных. Исходя из требований к нашему продукту у нас есть высокие требования к нашему коду, поэтому мы определили критичные для нашего проекта метрики кода и стараемся поддерживать их на высоком уровне.
Мы стараемся писать корректный код с наименьшим количеством багов. Код должен быть читаемым, самодокументируемым и поддерживаемым. Кроме того, он должен быть безопасным, так как мы финтех и у нас PCI DSS, это накладывает определенные требования к безопасности. А ещё код должен быть тестируемым.
Сегодня мы поговорим о двух метриках — корректность и тестируемость. Одна метрика напрямую влияет на другую, через тестируемость мы добиваемся корректности в том числе, мы проверяем, насколько код ожидаемо работает.
Перед тем как говорить об интеграционном тестировании, нужно понять, какой процесс мы будем тестировать. Рассмотрим сценарий интеграционного тестирования из жизни. Это сценарий выставления счета, на самом деле процесс проходит в несколько этапов, но мы рассмотрим в посте первые две стадии этого сценария.
Как работает выставление счёта
Любой платеж с карты или с кошелька, который вы делаете в интернете, начинается с создания счета на оплату.
Если говорить про самый первый шаг выставления счета, то здесь есть несколько лиц, участвующих в процессе:
плательщик;
магазин;
ContactPay, то есть мы, платежный шлюз;
некая платежная система, в данном случае это QIWI API.

Сценарий, на самом деле, всем нам знаком, мы все его проходили, если кто-то хоть раз оплачивал в интернете покупку.
Плательщик, покупая товар в магазине, делает заказ. На этот заказ магазин выставляет счет, то есть обращается к нашему API. Наш API делает некоторую магию с данными, которые пришли от магазина, осуществляет какие-то запросы во внешние сервисы, возможно, это сервис антифрода, мониторинга, KYC, и таких сервисов может быть множество.
Также между своими микросервисами мы можем делать множество запросов. Далее мы уже сформированный запрос отправляем в платежную систему, на что получаем ответ и отправляем его в магазин. Магазин, соответственно, отправляет ссылку плательщику на оплату, будь то форма, куда нужно ввести данные карты, либо это будет форма, где можно оплатить с QIWI-кошелька. То есть там уже плательщик сам решает, когда ему оплатить этот счет — он может его оплатить через 5 минут, через час, пока действительно время жизни счета, или может вовсе не оплатить, это тоже один из сценариев в рамках этого процесса.
Мы должны каким-то образом узнать, что счет был оплачен или просрочен, его lifetime истек, и предпринять соответствующие меры — провести до конечного статуса у себя, чтобы отдать магазину информацию о том, что счет перешел в конечный статус (будь то success или reject), и завершить процесс оплаты.
При выставлении счета мы видим синхронный процесс, в рамках этого запроса сразу отдается ответ магазину о результате создания счета на оплату. Но вот о том, оплатил плательщик счет или не оплатил, мы узнаем позже асинхронно, это как раз вторая часть процесса оплаты — уведомление об оплате, в простонародии — callback.
Callback приходит от платежной системы, в нашем случае это QIWI API. Он присылает на наш Webhook информацию о том, что счет принял какой-то статус. Во время обработки callback’a от платежной системы мы можем сходить между своими сервисами, для сохранения и обработки данных платежа, либо сходить в какой-то третий сервис. Обработка callback’a может быть для нас тоже многовариантной ситуацией.
После обработки callback’a от платежной системы мы отправляем свой собственный callback на Webhook магазина. При этом надо учесть, что мы можем сразу не доставить callback, так как может возникнуть сетевая ошибка или магазин не сможет принять наш callback в текущий момент. Мы должны постараться доставить callback до магазина при возникновении проблем, чтобы магазин мог отпустить товар или услугу плательщику.
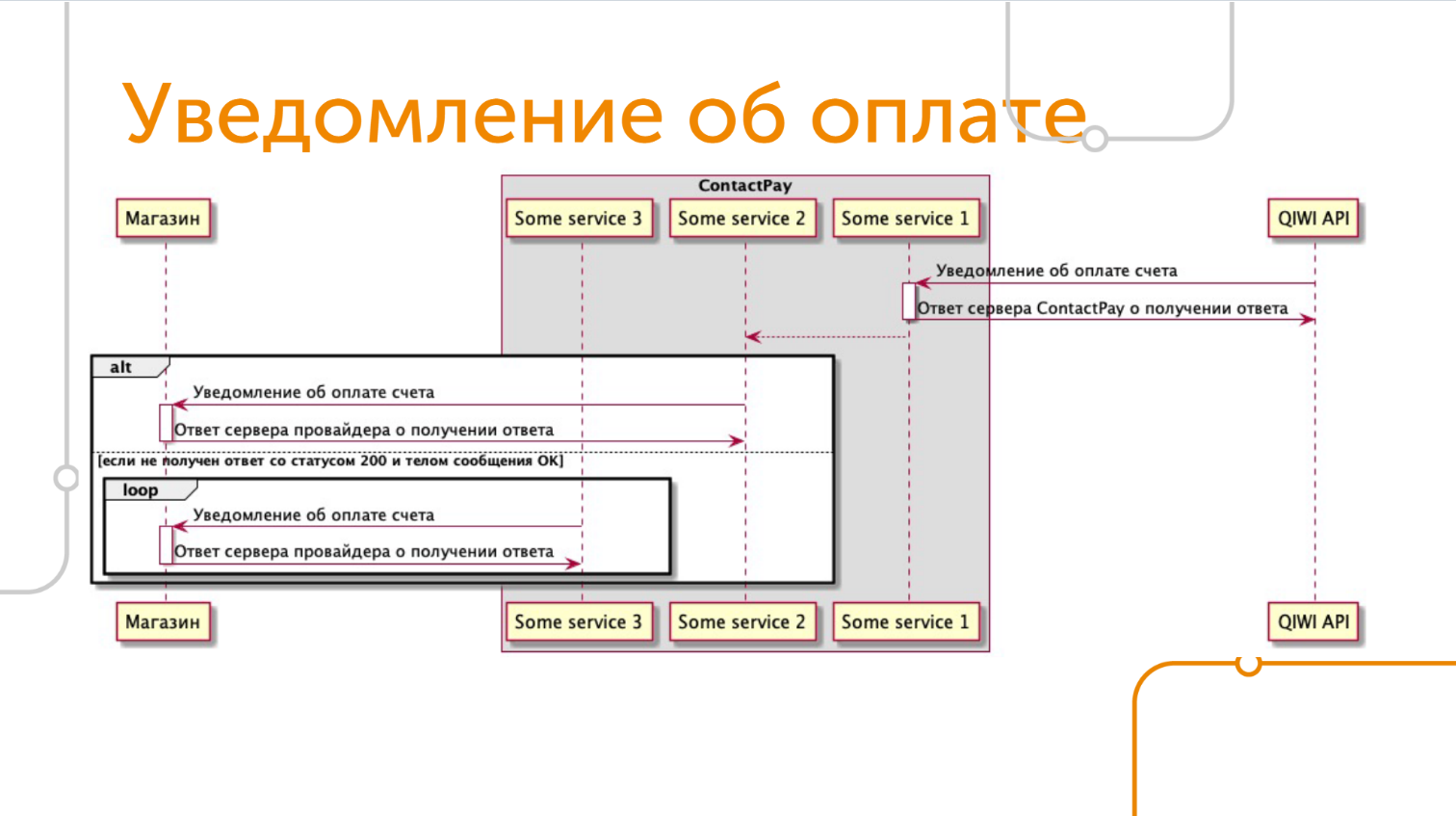
Согласен, схемы могут показаться сложными, поэтому я подготовил более простой вариант описания процесса. Выделил трех наших участников, это магазин, ContactPay и сторонние API.

На самом деле, если в глобальном смысле посмотреть на весь процесс, то это двусторонний обмен, не всегда синхронный, с возможными асинхронными запросами между сервисам.
Нам нужно добиться того, чтобы мы могли тестировать любой сценарий с подобным обменом данными, в том числе и к сторонним API. Если мы тестируем свои внутренние сервисы, то все вроде бы понятно, мы контролируем их, но в случае со сторонними сервисами мы не можем быть полностью уверены в их поведении и доступности при тестировании.
Что делать со сторонними API?
Мы задали себе вопрос: чего мы хотим от тестирования при описанном сценарии?
Первое — максимально реалистично проводить тестирование, то есть мы хотим делать реальные HTTP-запросы к сторонним сервисам.
Второе — тестировать corner case’ы, такие как ConnectionError, TimeoutError, то есть мы хотим убедиться, что при наступлении такого сценария с каким-то пограничным кейсом наши системы не разваливаются, сохраняют консистентность данных, могут провести транзакцию до какого-то ожидаемого состояния. Мы работаем в этом сценарии ожидаемо, даже если платежная система timeout’нула, либо запрос в какую-то третью систему отвалился, мы при этом адекватно себя ведем.
Третье — проверять callback’и, причём не только проверять отправку callback’а, но и знать, какой callback получил магазин, чтобы проверить его содержимое, что оно нигде не изменилось, и его можно распарсить правильно, и так далее.
При этом callback'и бывают от платежных систем, мы хотим управлять их состоянием и поведением.
Например, мы хотим убедиться, что если к нам не пришел callback из платежной системы, то счет, который из-за этого остался в неконечном состоянии на нашей стороне будет обработан соответствующими механизмами на этот случай, и будет доведен до конечного состояния.
Хорошо, цели определили, остаётся ещё один вопрос.
Как это тестировать?
Мы начали рассуждать и столкнулись со следующими сложностями: у нас есть ограничения, которые нас сильно блокируют в проведении таких тестов. Первое — у сторонних сервисов банально может не быть песочницы, в которой можно проводить наши интеграционные тесты.
Это большая проблема при таких тестированиях, для нас чужой сервис – черный ящик, при этом песочница может вообще отсутствовать или не работать в момент проведения тестирования. Представьте, вы хотите провести интеграционное тестирование перед тем, как катнуть что-то в прод, а у сервиса не работает песочница. Вот не работает — и всё тут.
Что делать? Не совсем понятно.
Хорошо, даже если песочница есть, то она может иметь ограничения. Они могут быть по количеству операций, которые мы совершаем в песочнице, по сумме, например, транзакций, если это песочница платежной системы. Получается, что ни о каких нагрузочных тестах, на основе наших интеграционных тестов, уже речи не идет. Плюс к этому мы уже начинаем тестировать не себя, а чужую песочницу. Ещё бывает, что песочница доступна, но в момент проведения тестирования она может не работать. Ведь не всегда гарантируется 100% работоспособность песочницы. На то она и песочница.
С одной стороны на это можно посмотреть как на corner case, когда третья система недоступна. Но мы хотели бы это контролировать. То есть сами определять, когда третья система не доступна или отбивает запросы по таймауту. И здесь мы переходим к следующей сложности: мы не можем контролировать все edge cases при использовании чужих песочниц.
Что еще важно, мы не можем тестировать все нужные нам сценарии с callback’ами.
Нужен инструмент, который мог бы получить вместо магазина callback с целью прочитать тело запроса, проверить его содержимое или совершить какую-то работу. Есть желание контролировать, когда нам будет доставлен callback от платежной системы и будет ли доставлен вообще.
Например, мы хотели бы протестировать такой сценарий: что если callback будет отправлен раньше, чем мы закрыли соединение с платежной системой? Будет ли там race condition?
Когда мы задали себе эти вопросы и поняли, что есть ряд ограничений, то подумали: “А кто может с этим справиться? Какой инструмент нам в этом поможет?”.
Мы поняли, что это инспектор Гаджет, на самом деле. У него всегда много разных фич, которые могут в разных условиях помочь.

Значит, нам нужен собственный такой инспектор Гаджет и написали свой Mock-service. Но мы писали его не просто как сервис в нашей инфраструктуре, а сделали из него фреймворк, Mock-фреймворк, на основе которого уже развит наш Mock-service и созданы различные обработчики, о которых мы поговорим. Заодно покажем наш подход к архитектуре и к фичам, которые мы реализовали. Возможно, это вас вдохновит.
Первое, чему научился наш инспектор Гаджет, это отправлять произвольные ответы на запросы с параметризацией.

Есть обработчик, принимающий определенный набор query-параметров, на основе которых он формирует ответ. В данном примере можно увидеть, как я делаю запрос с несколькими get-параметрами. Я указал 3 параметра, это status code, content-type и content, то есть при запросе на этот URL я получу ответ с content-type, с содержимым и кодом ответа, которые передал в запросе.
Для чего этот обработчик может быть нужен? Он очень хорошо эмулирует поведение магазина, который получит от нас callback. Имея такой не сложный обработчик, мы можем протестировать различные сценарии, отправив callback на этот URL, например:
магазин принял сразу callback от нас,
не принял callback, упал с ошибкой или произошел timeout соединения.
В этих сценариях мы тестируем поведение нашей системы при обработке различных сценариев доставки callback’ов.
Хорошо, эту проблему закрыли, хотим тестировать ответы.
Я говорю про то, что мы хотим тестировать еще и содержимое того, что мы отправляем. Не вопрос, у нас есть API нашего Mock-service, который позволяет как через WebUI, так и через API получить информацию по любому запросу, который был сделан к Mock-service’у, а именно, что он получил в запросе, и то, что он отдал в ответе.
Таким образом мы в своих тестах можем анализировать эту информацию и описывать различные тест кейсы. Но мы делали Mock-service не только для себя, делали его и для тестировщиков, и понимали, что тестировщикам может быть удобнее некоторые сценарии описывать, например, не в коде, а через UI, и мы сделали WebUI для удобства и скорости формирования ответов. WebUI у нас получился очень крутой с точки зрения того, что он умеет еще и в скриптинг.

На этом скриншоте пример того, как можно создать webhook, который будет принимать запросы по URL, который он сгенерировал, и отдавать ответ. При этом ответ может быть динамическим, я могу написать его на Python. Можно написать скрипт, который будет генерировать ответ для этого handler’а, при этом я могу сгенерировать еще и ответ, учитывая тело запроса, которое пришло, и заголовки запроса, то есть мне при написании скрипта для формирования ответа доступен весь запрос. Это очень удобно, так как я могу на основе пришедших данных сформировать ответ для тестирования различных тест кейсов.
Вдобавок я могу настроить delay – задержку ответа, код ответа. Если я сделаю http-запрос к этому обработчику, то я увижу такой ответ, то есть у меня создадутся рандомные значения с помощью библиотеки Faker и выведутся в браузере, в данном случае в виде JSON.
А что, если я хочу не просто webhook, а сделать заведомо известный URL-адрес, который подставлю в своем приложении, и это URL будет имитировать поведение какой-то третьей системы?
Не вопрос, есть и такая возможность. Я могу указать regex для path, который будет принимать этот запрос на Mock-service, и написать скрипт для генерации ответа. Здесь абсолютно такая же идея с доступными возможностями этого скриптинга, поэтому, если я сделаю запрос к этому адресу, то получу заскриптованный ответ.
Если я сделаю запрос к новому URL, то в JSON’е будет видно, как я в ID получил qwerty123 – это именно то, что было указано в URL. Иными словами, я в скриптинге смог прочитать содержимое запроса и получить часть этого содержимого, также там видно, что сгенерировались рандомные данные.

Ниже видно, как в веб-интерфейсе можно посмотреть историю запросов — тестировщику не нужно владеть информацией о том, что есть какое-то внутренний API Mock-service, он прямо в веб-интерфейсе может посмотреть историю запросов по каждому обработчику, по каждому webhook. Это очень удобно и ощутимо помогает в тестировании и при отладке.
API Mock-service напрямую тестировщики также используют в автотестах и проверяют, что реквесты к платежным системам (то есть к нашему моку) соответствуют ожидаемым.
Я называю это веб-фреймворком, поэтому можно легко добавлять новые обработчики as code. Вот как архитектурно это выглядит — обработчик, который умеет принимать get-параметры и отдавать ответ с валидацией запроса.
Валидация у нас реализована с помощью pydantic, библиотека может быть знакома тем, кто пишет на Python. Она прекрасно умеет валидировать то, что приходит в запросах. Скажем, есть параметр same_key и он должен быть обязательно integer. Дальше указываю в атрибуте моего обработчика наш валидатор, который создал ранее. И теперь, при запросе к этому обработчику, будет вызван наш валидатор.
Если теперь я сделаю запрос с некорректными данными, например, передам строковое значение ключа same_key, то я увижу 400 код ошибки и человеческое описание того, что произошло. При этом наш фреймворк позволяет кастомизировать варианты ответов, которые будут приходить в случае ошибки валидации. Это удобно, если мы хотим также покрывать сценарии тестирования, при которых со стороннего сервиса будет падать запрос из-за ошибки валидации. При успешной валидации все прекрасно, вернулся 200-й ответ, мы видим, что значение с типом integer прошло успешно.
Corner-кейсы
Corner-кейсы – это важная составляющая работы нашего Mock-service, потому что позволяет нам контролировать поведение третьих систем в нашем Mock-service и тестировать реакцию наших сервисов.

Здесь можно посмотреть, что у нас есть обработчики, которые умеют и timeout’ить, и выдавать 500-ю ошибку.
Из интересного функционала тут стоит выделить callback’и. В данном случае можно также запрограммировать callback в веб-интерфейсе, но можно еще написать с помощью кода к конкретному обработчику, то есть callback — это такой же class, который имеет атрибуты: delay, URL, на который будет отправлен callback.
Мы указываем этот class callback’а в обработчике, после которого этот callback должен быть отправлен. В данном случае будет вызван HTTP-запрос через 5 секунд после запроса CommonHandler, так мы тоже можем управлять поведением отправки callback’ов или не отправлять, убрать отправку callback’ов.
Что мы получили благодаря этому
На самом деле, мы получили даже больше, чем хотели.
Во-первых, у нас появились автотесты, которые мы теперь регулярно запускаем и максимально независим от того, доступен сторонний сервис или нет, мы завязаны только на себя.
Теперь перед тем, как что-то выкатить в продакшн, мы можем смело запустить автотесты и убедиться, что все хорошо, регрессии никакой нет, новый функционал работает, все прекрасно, интеграции работают.
Мы можем проводить нагрузочное тестирование. Это тоже связано с тем, что мы не имеем никаких ограничений: мы можем заскейлить наш Mock-service настолько, насколько захотим, и в итоге мы теперь тестируем не чужую песочницу, а именно наши интеграции, наши сервисы. Это тоже нам помогает, мы можем проводить это регулярно.
Еще один приятный side-эффект – у нас появился собственный sandbox, который мы даем нашим клиентам при интеграции с нашим платежным шлюзом. За счёт этого уменьшилось время интеграции с нашим API, а качество интеграции увеличилось. Time-to-market наших клиентов стал быстрее. Это позитивно сказывается на нашем шлюзе как на продукте.
Хочу отметить главное — не стоит бояться писать собственные инструменты. Нам нужен был инструмент под конкретные нужды, мы активно исследовали рынок, но не нашли ничего подходящего, поэтому решили написать свой.
Иногда такой подход даёт даже больше, чем вы могли представить, могут быть приятные side-эффекты. Важная штука, которая помогла нам прийти к таким результатам — мы задавали правильные вопросы.
Мы задали вопрос: “Чего мы хотим от тестирования?” и родился правильный инструмент, решающий поставленные цели перед собой и даже больше.
Подробная презентация на github.
А вот тут видео доклада для тех, кому проще воспринимать информацию так.