

Глава 1. Предпосылки
Я думаю, многие слышали про громкий инцидент, произошедший с Tesla в 2018 году, когда группа хакеров через консоль Kubernetes смогла получить доступ к аккаунту. После получения доступа ребята изрядно повеселились, настроив майнер в облачном сервисе Amazon Web Services.
У многих людей сразу же возникнут закономерные вопросы “А как они это сделали?” и “Почему многоуважаемые ИБ данной компании не подумали о потенциальной дыре в безопасности?”. Как правило, при разработке любого продукта могут быть лишь две причины возникновения уязвимостей. Первая причина - человеческий фактор. Ведь кто из нас не забывал что-либо в ходе кропотливой работы над проектом или же не откладывал в бэклог решение “не самых срочных вопросов..?”. Вторая причина - отсутствие необходимых компетенций в той или иной области.

И здесь возникает логичный вопрос: “Кто должен был бороться со злом? Кто же должен следить за секьюрностью приложения? И в этот момент на фоне взрыва и модной музыки приходит на помощь DevSecOps. Тем, кто слышал о нём, но не до конца знает, кто это и зачем он нужен, но уже подумывает просто приписать своему текущему DevOps-инженеру три буквы посередине и не искать нового сотрудника в штат, - скажу сразу: так это не работает.
DevSecOps - это философия, подразумевающая интеграцию принципов безопасности на всех стадиях жизни приложения. От его разработки и сборки, до его эксплуатации непосредственно в инфраструктуре.
И на этом этапе начинается прекрасная повесть “Чем дальше в лес, тем больше дров”. В рамках своего рассказа я не буду стремиться описать сразу все направления этой многогранной философии, а уделю внимание лишь тому, что меня особенно заинтересовало.
Итак, моделируем ситуацию. К вам приходит проект, в рамках которого клиент озвучивает требования о полностью безопасной и стабильной рабочей инфраструктуре k8s. Вы с радостью начинаете искать свои завалявшиеся Terraform-модули для раскатки куба в том или ином облаке, но в какой-то момент становится понятно, что клиент не готов создавать новую инфраструктуру, а хочет оптимизировать текущую.
Нет более страшной работы для DevOps-инженера, чем работать с тем, что создавалось не тобой.
Глава 2. С луком и стрелой на железного зверя
Что такое Kube-Hunter и с чем его едят?
Фактически это утилита, запускающая определенные тесты, которые пытаются проверить на наличие дыр в безопасности инфраструктуры вашего куба. Утилита имеет 2 варианта запуска, как в контейнере docker локально на хосте, так и в виде poda в k8s, а также два режима тестирования: пассивный и активный. Если с пассивным, я уверен, вопросов ни у кого не возникает, то с активным сложнее - во время тестирования он использует найденные уязвимости для поиска других уязвимостей, и потенциально может внести изменения в инфраструктуру. Так что поосторожней с запуском на prod. Хотя на личном опыте могу сказать, что сколько бы ни тестировал этот инструмент, я не смог обнаружить каких-либо изменений в инфраструктуре кластера.
Произведем запуск kube-hunter в кластере:
apiVersion: batch/v1
kind: Job
metadata:
name: kube-hunter
spec:
template:
metadata:
labels:
app: kube-hunter
spec:
containers:
- name: kube-hunter
image: aquasec/kube-hunter:latest
command: ["kube-hunter"]
args: ["--pod", "--enable-cve-hunting", "--statistics"]
restartPolicy: NeverДелаем apply нашей job и через пару минут смотрим в отработанном поде логи. Результат, который я получил, имел примерно следующий вывод:

Первый блок - информация о мастер ноде, где был запущен под.
Второй блок - информация об API ноды.
Третий блок - список уязвимостей, которые он нашёл с кратким описанием.
А также итоговая статистика о всех проверках, которые были произведены и об их результатах:

Первая же найденная уязвимость гласила: “CAP_NET_RAW включен по умолчанию для модулей. Если злоумышленнику удастся скомпрометировать под, он потенциально может воспользоваться этой возможностью для выполнения сетевых атак на другие поды, работающие на том же узле”. Отлично, общая суть понятна. Но, как у любого инженера, у меня сразу возникает ряд вопросов. Как то:
Что такое CAP_NET_RAW?
Зачем он нужен?
Не сломает ли отключение CAP_NET_RAW мой рабочий кластер?
Как злоумышленник может произвести атаку, используя данную capability?
Давайте же разберем самую интересную и наглядную, по моему мнению, уязвимость.
Глава 3. Ответы на вопросы, порождающие ещё больше вопросов
После недолгих поисков я нашел следующую информацию.
CAP_NET_RAW — это разрешающий параметр по умолчанию в Kubernetes, разрешающий трафик ICMP между контейнерами, и предоставляющий приложению возможность создавать необработанные пакеты. В руках злоумышленника CAP_NET_RAW может позволить использовать широкий спектр сетевых эксплойтов внутри кластера.
Чтобы понять, можно ли отключить данный параметр, нужно понимать, как работает сеть куба. Это также позволит понять, как злоумышленник может воспользоваться данной настройкой.
Сетевая архитектура Kubernetes
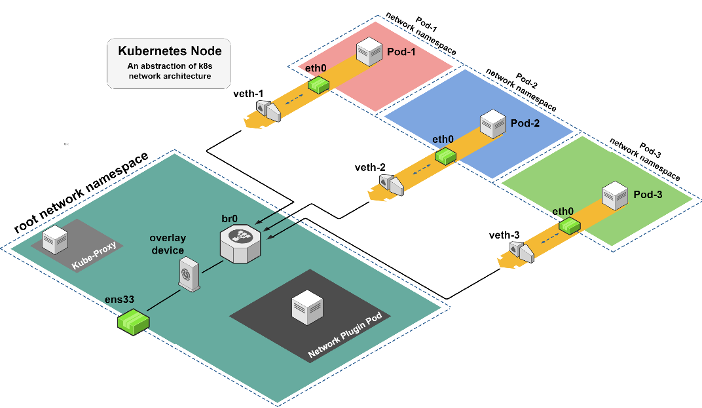
Подключение подов, работающих на одном узле или на разных узлах, не является тривиальной задачей. Для обеспечения этого соединения существует полная инфраструктура, которая, в основном, опирается на сетевые пространства имен, сетевые устройства Linux, таблицы маршрутизации и оверлейные сети.
Рисунок выше описывает абстракцию сетевой структуры на одном узле. Каждый под находится в отдельном сетевом пространстве имен, и существуют сетевые устройства, которые создают связь между различными подами и корневым пространством имен. Это уровень, который управляет трафиком данных внутри и снаружи узла.
Пространство имен корневой сети содержит несколько компонентов. Первый — это под сетевого плагина, который работает (в отличие от большинства других модулей) в корневом сетевом пространстве имен с возможностями NET_ADMIN. Это позволяет реализовать различные конфигурации на узле. Еще одним компонентом, входящим в инфраструктуру Kubernetes, является под kube-proxy, который отвечает за сетевые свойства, такие как правила iptables, при создании службы в кластере.
Помимо этих компонентов есть четыре основных сетевых устройства Linux. Компоненты veth (виртуальный ethernet), о котором я расскажу подробнее позже, и компоненты моста, которые отвечают за подключение подов к сетевому пространству узла, чтобы пакеты могли проходить между подами на одном узле или передаваться другим устройствам, - например выйти из узла. Первым устройством на выходе из пода будет оверлейное устройство, которое оборачивает проходящий через него трафик в существующую оверлейную сетевую инфраструктуру между подами в кластере. И, наконец, последнее устройство — ens33, которое является основным интерфейсом пода и обеспечивает доступ к внешним компонентам.
Хорошо, но как пакеты ходят между разными namespace?
В данном случае ключевую роль играет устройство veth, которое необходимо для создания виртуальных подключений между различными сетевыми пространствами имён. Оно обеспечивает связь таким образом?
Еще одно ключевое устройство, присутствующее в сетевых подключаемых плагинах уровня 2, — это мостовое устройство br0. Его основная обязанность — позволить подам внутри одного узла общаться друг с другом. Устройство моста заполняет свою собственную таблицу ARP всеми данными пода, чтобы знать, куда должен двигаться каждый пакет.
Чтобы не уходить в дебри всего этого сетевого леса, можно подойти к сути и уже сказать про Kubernetes DNS, который занимается направлением трафика и резолвом DNS-имён в кластере. Получается если недоброжелатель получает доступ в под приложения, в котором есть возможность CAP_NET_RAW, то он получает доступ ко всей сети ноды кластера k8s. Так и хочется попробовать!
Глава 4. А правда ли всё, что пишут?
Попробуем реализовать ARP-spoofing через один из эксплойтов, найденных на просторах github, и проверить теорию, описанную выше. Забегая вперёд скажу, что ARP - это протокол определения адреса, и работает он по следующему принципу. Имеются две машины, находящиеся в одной сети compute-1 и compute-2. С ВМ compute-1 необходимо отправить пакет на compute-2. Для этого ему нужно узнать физический адрес compute-2. Поэтому compute-1 всем компьютерам в одном с ним broadcast domain отправляет запрос следующего содержания “ВМ с виртуальным IP ... сообщите свой MAC-адрес на ВМ c IP 02:00:c0:a8:fb:02 (compute-1)”. После чего он получает необходимые данные для отправки пакетов.
Выкачиваем репозиторий и применяем манифесты с подами. Затем смело заходим в каждый из подов, запускаем exploit и смотрим, что у нас получается.

Текущий exploit, запущенный из пода, перехватывает и видит весь трафик ноды в k8s.
Протестируем какой ответ будет у нас получаться до ARP-спуфинга:

А теперь посмотрим ip-адрес нашего пода hacker и отредактируем в нём файл hosts для exploit следующим образом:
google.com. 172.17.0.13где 172.17.0.13 - ip адрес пода.
Теперь вновь повторим действия “злоумышленника”. Запускаем netcat в поде для отправки нашего ответа на 80-ом порту, запускаем exploit и тестируем всё тот же запрос.

Что произошло?
Наш exploit запустился в подe с приложением, и в нём присутствует возможность NET_RAW. Проверить, что в контейнере работает NET_RAW, можно следующей командой:
apt-get install libcap-ng-utils; pscap -a Ожидаемый вывод будет примерно такой:

Утилита обнаруживает все виртуальные и физические ip-адреса по принципу ARP, описанному выше.
Запускает подделку ARP на мосту br0.
Читает пользовательский файл hosts, в котором ранее мы прописывали домен и ip пода.
Проксирует весь трафик через себя на под с kube-dns, выполняя атаку по принципу человек посередине.
Получается, что сейчас вся сеть ноды k8s доступна из одного пода, и если недоброжелатель решит воспользоваться этой возможностью, он может произвести кражу данных пользователей.
Как с этим бороться?
Настройки SecurityContext;
Отключение пользовательский оболочек Bash, sh;
Отключение CAP_NET_RAW путём создания ClusterPolicy.
Главное, в этом моменте не перестараться и не нарушить работоспособность своего приложения.

Глава 5. Доверяй, но проверяй!
Но что скажет на это всё другая технология - Kube-bench?
Она по своей сути тоже призвана искать уязвимости в инфраструктуре k8s, но немного иным способом, а именно - через анализ конфигураций кластера.
Запустим аналогичную проверку посредством этого ПО:
apiVersion: batch/v1
kind: Job
metadata:
name: kube-bench
spec:
template:
metadata:
labels:
app: kube-bench
spec:
hostPID: true
containers:
- name: kube-bench
image: docker.io/aquasec/kube-bench:latest
command: ["kube-bench"]
volumeMounts:
- name: var-lib-etcd
mountPath: /var/lib/etcd
readOnly: true
- name: var-lib-kubelet
mountPath: /var/lib/kubelet
readOnly: true
- name: var-lib-kube-scheduler
mountPath: /var/lib/kube-scheduler
readOnly: true
- name: var-lib-kube-controller-manager
mountPath: /var/lib/kube-controller-manager
readOnly: true
- name: etc-systemd
mountPath: /etc/systemd
readOnly: true
- name: lib-systemd
mountPath: /lib/systemd/
readOnly: true
- name: srv-kubernetes
mountPath: /srv/kubernetes/
readOnly: true
- name: etc-kubernetes
mountPath: /etc/kubernetes
readOnly: true
- name: usr-bin
mountPath: /usr/local/mount-from-host/bin
readOnly: true
- name: etc-cni-netd
mountPath: /etc/cni/net.d/
readOnly: true
- name: opt-cni-bin
mountPath: /opt/cni/bin/
readOnly: true
restartPolicy: Never
volumes:
- name: var-lib-etcd
hostPath:
path: "/var/lib/etcd"
- name: var-lib-kubelet
hostPath:
path: "/var/lib/kubelet"
- name: var-lib-kube-scheduler
hostPath:
path: "/var/lib/kube-scheduler"
- name: var-lib-kube-controller-manager
hostPath:
path: "/var/lib/kube-controller-manager"
- name: etc-systemd
hostPath:
path: "/etc/systemd"
- name: lib-systemd
hostPath:
path: "/lib/systemd"
- name: srv-kubernetes
hostPath:
path: "/srv/kubernetes"
- name: etc-kubernetes
hostPath:
path: "/etc/kubernetes"
- name: usr-bin
hostPath:
path: "/usr/bin"
- name: etc-cni-netd
hostPath:
path: "/etc/cni/net.d/"
- name: opt-cni-bin
hostPath:
path: "/opt/cni/bin/"В рамках анализа присутствует 5 разделов:
Master Node Security Configuration;
Etcd Node Configuration;
Control Plane Configuration;
Worker Node Security Configuration;
Kubernetes Policies.
Мы останавливаемся сразу на последнем, где получаем кучу предупреждений о проблемах в текущих политиках кластера, а также о кратких рекомендациях по их устранению.
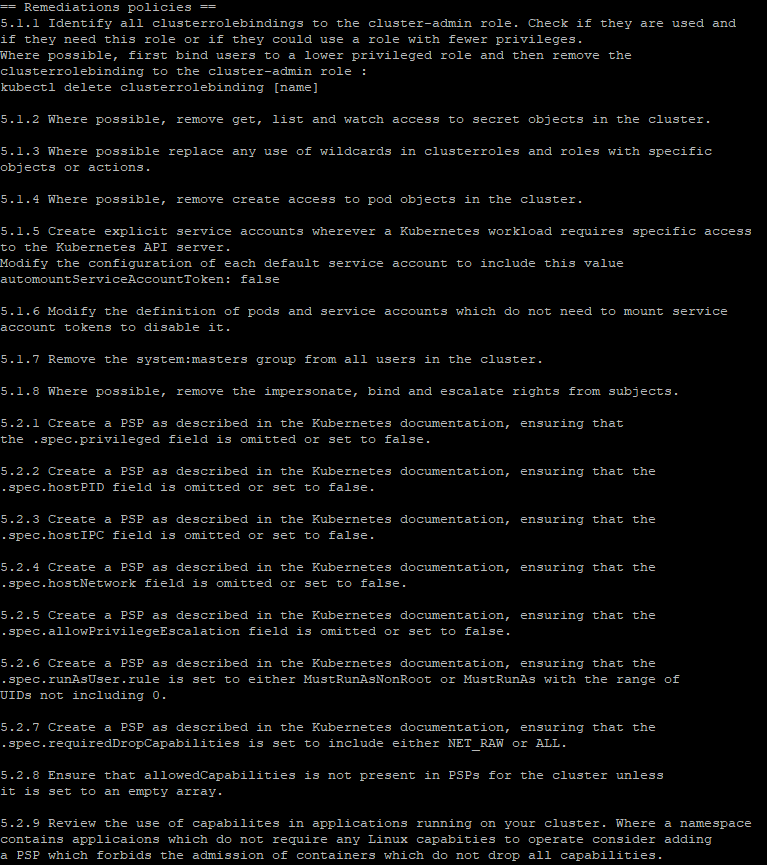
Здесь мы явно видим те же рекомендации, которые уже описаны выше, и хочется с акцентировать внимание на важном пункте 5.2.7 - рекомендации по отключению NET_RAW.
Получается, что какими средствами ни тестируй кластер, а проблема в наличии уязвимости по-прежнему присутствует. Попробуем произвести устранение данной проблемы путём написания PodSecurityPolicy, затем проведём тесты инфраструктуры.
Для создания отключения NET_RAW добавили в поде следующие строчки:
securityContext:
capabilities:
drop: ["NET_RAW"]После внесения корректировок в yaml-манифест этой возможности в запущенном контейнере уже не было:

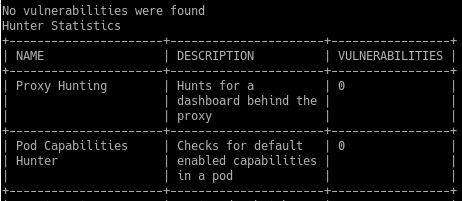
Результаты тестирования:
Kube-hunter
Kube-bench
Результат остался не изменен и статус “Warning” никуда не делся. А теперь интрига - данный инструмент в результате вывода проверки предоставляет лишь текстовую рекомендательную часть (Manual) по устранению возможной проблемы в кластере, но не несёт в себе какую-либо проверку в рамках данного раздела. Вывод - результаты с тестированием Kubernetes Policies всегда будут неизменны, и никак не проверяют ваш кластер.

Заключение
Итак, к чему же было так много слов, и для чего стоит это всё применять? Изначально, когда мы моделировали ситуацию, в которой нам необходимо было улучшить безопасность нашего кластера, не было понятно, какими средствами хотелось бы пользоваться в рамках решения проблемы. Тестируя технологии kube-hunter и kube-bench, можно сказать, что они выполняют свой основной функционал по анализу проблем, но не несут в себе конкретные и правильные рекомендации по их устранению или же выполняют не все необходимые тесты для проверки CIS. Из чего следует, что нельзя доверять всецело их советам и необходимо проводить свой анализ для каждого отдельного случая, чтобы в дальнейшем принять единственно верное решение.
Также хочется отметить, что при анализе одной проблемы, мы лишь слегка углубились в бескрайнее болото безопасности инфраструктуры, и что в дальнейшем можно бесконечно долго докапываться до первопричин возникновения угрозы. Для выполнения тех же аудитов безопасности также могут быть использованы krane, statboard, falco и другие технологии, подробное изучение которых можно ещё расписать на отдельную статью или даже книгу.
P.S.: еще больше новостей и статей по теме DevOps - в нашем telegram-канале DevOps FM, присоединяйтесь, чтобы быть в курсе.
Рекомендации для чтения:
kksudo
Спасибо, интересно. Как часто вы у себя в компании применяете подобные практики ?
У вас есть некоторые требования к безопасности или начинали использовать подобные подходы после какого-нибудь инцидента ?
Gacblk Автор
По стандарту мы настраиваем минимальные настройки безопасности необходимые для работы инфраструктуры (firewall, security groups, централизованная авторизация и т.д.).
Если стоит задача, что нужно произвести более детальную настройку, то в ход идут инструменты описанные выше. Данные подходы используем, чтобы предотвратить возникновение проблемы на корню, а не ждать когда случить апокалипсис)