
Если система работает длительное время, объём свободной памяти может уменьшаться, что может приводить к отказу некоторых сервисов. Это типичная проблема утечки памяти, которую обычно сложно спрогнозировать и выявить. Удобными инструментами для решения подобных проблем являются профайлеры кучи. Они отслеживают распределение памяти и помогают разобраться, что находится в куче программы, а также найти утечки памяти.
В этой статье мы расскажем об использовании профайлеров кучи, а также объясним, как спроектированы и реализованы популярные профайлеры кучи, например, профайлер кучи Go, gperftools, jemalloc и Bytehound.
Прежде чем углубляться в подробности каждого профайлера, я покажу в табличном виде их производительность и точность метрик, чтобы вы могли понять, стоит ли читать статью целиком.
| Профайлеры | Снижение производительности | Качество метрик |
| Go | Слабое | Среднее |
| TCMalloc (gperftools) | Слабое | Среднее |
| jemalloc | Слабое | Среднее |
| Bytehound | Сильное | Высокое |
Что такое профилирование кучи?
Профилирование кучи — это сбор или сэмплирование распределения кучи приложения, чтобы помочь пользователям понять, что находится в куче программы. Его можно использовать для нахождения утечек памяти, анализа паттернов распределения памяти или обнаружения мест, распределяющих много памяти.
Как работает профилирование кучи
Прежде чем мы углубимся в профилирование кучи, давайте узнаем, как работает профилирование центрального процессора, это проще и поможет нам понять, как работает профилирование кучи.
При профилировании использования ЦП нужно выбрать определённое временное окно. В этом окне профайлер ЦП регистрирует обработчик (hook), который исполняется целевой программой с регулярными интервалами. Существует много способов его реализации, например, сигнал SIGPROF. Этот обработчик получает трассировку стека рабочего потока в реальном времени.
Затем мы указываем, как часто должен исполняться обработчик. Например, если мы зададим частоту 100 Гц, то сэмпл стека вызовов приложения будет сохраняться каждые 10 мс. После завершения временного окна мы агрегируем собранные сэмплы и получаем число раз сбора каждой функции. Далее сравниваем эти числа с общим количеством сэмплов, чтобы определить относительную пропорцию использования ЦП каждой функцией.
Эту модель можно использовать для нахождения функций с высоким использованием ЦП и выявления «горячих» с точки зрения ЦП точек программы.
Профилирование ЦП и кучи имеют схожие структуры данных. Оба используют трассировку стека + статистическую модель. Если воспользоваться предоставляемым Go pprof, можно увидеть, что их форматы отображения практически одинаковы:


Однако в отличие от профилирования ЦП профилирование кучи делает чуть больше, чем сбор данных по таймеру. Оно вставляет в распределитель памяти статистический код. В общем случае — профайлер кучи напрямую интегрирован в распределитель памяти. Когда приложение распределяет память, он получает текущую трассировку стека, а в конце агрегирует сэмплы. Так мы можем узнать прямое и косвенное распределение памяти каждой функции.
Модель трассировки стека + статистических данных профилирования кучи согласуется с моделью профилирования ЦП.
Далее мы расскажем о том, как реализованы и используются различные профайлеры кучи. Для полноты описания я объясню работу каждого профайлера кучи. Если вы уже знаете эту информацию, то можете её пропустить.
Профайлер кучи Go
Инженеры нашей компании в качестве основного языка программирования используют Golang, поэтому в этой статье я подробно расскажу о профайлере кучи Go, его архитектуре и реализации. Также мы рассмотрим другие профайлеры кучи. Но поскольку большинство профайлеров кучи имеет одинаковую архитектуру, подробно мы их рассматривать не будем.
Использование профайлера кучи Go
Среда исполнения Go имеет встроенный профайлер, и куча является одним из её типов. Порт отладки можно открыть следующим образом:
import _ "net/http/pprof"
go func() {
log.Print(http.ListenAndServe("0.0.0.0:9999", nil))
}()В процессе исполнения программы можно использовать следующую командную строку для получения снэпшота текущего профилирования кучи:
$ go tool pprof http://127.0.0.1:9999/debug/pprof/heapТакже можно напрямую получить снэпшот профилирования кучи в конкретном месте кода приложения:
package main
import (
"log"
"net/http"
_ "net/http/pprof"
"time"
)
func main() {
go func() {
log.Fatal(http.ListenAndServe(":9999", nil))
}()
var data [][]byte
for {
data = func1(data)
time.Sleep(1 * time.Second)
}
}
func func1(data [][]byte) [][]byte {
data = func2(data)
return append(data, make([]byte, 1024*1024)) // распределение 1 МБ
}
func func2(data [][]byte) [][]byte {
return append(data, make([]byte, 1024*1024)) // распределение 1 МБКод непрерывно распределяет память в
func1 и func2. Он распределяет 2 МБ памяти кучи в секунду.После того как программа поработает в течение какого-то интервала времени, мы можем исполнить следующую команду для получения снэпшота профилирования и запустить веб-сервис для просмотра:
$ go tool pprof -http=":9998" localhost:9999/debug/pprof/heap
Этот граф сообщает нам о двух важных аспектах. Чем больше поле, тем больше распределение памяти. Также мы видим связи между вызовами функций. В этом примере очевидно, что
func1 и func2 имеют наибольшее распределение памяти, и func1 вызывает func2.Обратите внимание, что поскольку профилирование кучи тоже сэмплируется (по умолчанию стек вызовов сэмплируется каждый раз, когда распределитель памяти распределяет 512 КБ памяти), показанный здесь размер памяти меньше, чем распределённый размер памяти. Как и в профилировании ЦП, это значение лишь вычисляет относительные пропорции, а затем находит «горячие» точки распределения памяти.
Примечание: хотя у среды исполнения Go есть логика для оценки исходного размера сэмплированных результатов, эти вычисления необязательно точны.
В этом графе «48.88% of 90.24%» в поле
func1 означают процентную долю от суммарной процентной доли.Давайте изменим способ отображения, выбрав Top в меню в левом верхнем углу. Мы увидим следующее:

Что означают поля:
| Столбец | Определение |
| Flat | Память, распределённая для функции |
| Flat% | Отношение Flat к общему размеру распределения |
| Sum% | Суммирование Flat% сверху вниз; можно узнать, сколько памяти распределено из этой строки относительно вершины |
| Cum | Память, распределённая для функции и для вызываемых ею подфункций |
| Cum% | Отношение Cum к общему размеру распределения |
| Name | Идентифицирует функцию |

В профилировании ЦП мы часто находим широкую верхушку во flame-графике для быстрого поиска «горячей» функции. Разумеется, благодаря однородности модели данных можно использовать flame-график и для отображения данных профилирования кучи. В левом верхнем углу нажмите на VIEW и выберите в меню Flame Graph:

Благодаря показанным выше способам, мы можем увидеть, что
func1 и func2 имеют наибольшее распределение памяти. Однако в реальных ситуациях первопричину найти не так просто. Поскольку мы получаем снэпшот конкретного момента, этого недостаточно для выявления проблемы утечки памяти. Чтобы судить о том, какая функция постоянно увеличивает память, нам нужны инкрементные данные. Следовательно, мы можем получать профиль кучи повторно спустя какое-то время и наблюдать различия между двумя результатами.Реализация профайлера кучи Go
Ранее я говорил о том, что в общем случае профайлер кучи интегрирован в распределитель памяти. Когда приложение распределяет память, профайлер кучи получает текущую трассировку стека. Так поступает и Go.
Элементом распределения памяти в Go является функция
mallocgc() в src/runtime/malloc.go. Функция mallocgc() распределяет область памяти. Вот важная часть её кода:func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// ...
if rate := MemProfileRate; rate > 0 {
// Стоит заметить, что кэш c валиден только когда получено m
if rate != 1 && size < c.nextSample {
c.nextSample -= size
} else {
profilealloc(mp, x, size)
}
}
// ...
}
func profilealloc(mp *m, x unsafe.Pointer, size uintptr) {
c := getMCache()
if c == nil {
throw("profilealloc called without a P or outside bootstrapping")
}
c.nextSample = nextSample()
mProf_Malloc(x, size)
}Из кода видно, что каждый раз, когда
mallocgc() распределяет 512 КБ памяти кучи, она вызывает profilealloc() для записи трассировки стека.Полезно было бы получать точное распределение памяти всех функций, но это сильно влияет на производительность. Так как
malloc() является функцией библиотеки пользовательского режима, приложения вызывают её часто. Если каждый вызов malloc() вызывает обратную трассировку стека, то падение производительности практически неприемлемо, особенно в ситуациях, когда профилирование на стороне сервера выполняется долгое время. Сэмплирование выбирают не потому, что оно обеспечивает более точные результаты, а лишь в качестве компромисса.Разумеется, мы также можем изменить переменную
MemProfileRate. Если мы присвоим ей значение 1, то при каждом вызове mallocgc() она будет записывать трассировку стека; если присвоить ей значение 0, профилирование кучи будет отключено. Вы можете искать баланс между производительностью и точностью в каждой конкретной ситуации.Стоит заметить, что когда мы присваиваем
MemProfileRate обычную величину разбиения сэмплирования, это значение не будет совершенно точным. Оно случайно выбирается из экспоненциального распределения, где MemProfileRate является средним значением.// nextSample возвращает следующую точку сэмплирования для профилирования кучи. Цель заключается в том,
// чтобы сэмплировать распределения в среднем каждые MemProfileRate байт,
// но с совершенно случайным распределением по шкале времени распределения;
// это соответствует процессу Пуассона с параметром MemProfileRate. В процессах
// Пуассона расстояние между двумя сэмплами соответствует экспоненциальному
// распределению (exp(MemProfileRate)), поэтому наилучшее случайное значение - это случайное
// число, взятое из экспоненциального распределения со средним значением MemProfileRate.
func nextSample() uintptrВо многих случаях распределение памяти равномерно. Если сэмплирование выполняется с фиксированной величиной разбиения, итоговый результат может иметь крупную погрешность. Может оказаться так, что определённый тип распределения памяти присутствует в каждом сэмпле. Именно поэтому здесь выбирается случайность.
Погрешности имеет не только профилирование кучи, но и различные профайлеры, использующие сэмплирование (например, SafePoint Bias). При проверке результатов профилирования, использующего сэмплирование, мы должны учитывать возможность погрешностей.
За сэмплирование отвечает функция
mProf_Malloc() в src/runtime/mprof.go:// Вызывается malloc для записи профилируемого блока.
func mProf_Malloc(p unsafe.Pointer, size uintptr) {
var stk [maxStack]uintptr
nstk := callers(4, stk[:])
lock(&proflock)
b := stkbucket(memProfile, size, stk[:nstk], true)
c := mProf.cycle
mp := b.mp()
mpc := &mp.future[(c+2)%uint32(len(mp.future))]
mpc.allocs++
mpc.alloc_bytes += size
unlock(&proflock)
// Setprofilebucket блокирует группу других мьютексов, чтобы мы могли вызывать их за пределами proflock.
// Это снижает потенциальную возможность конфликтов и вероятность deadlock.
// Так как при вызове mProf_Malloc объект должен быть живым,
// вполне можно выполнять это неатомарно.
systemstack(func() {
setprofilebucket(p, b)
})
}
func callers(skip int, pcbuf []uintptr) int {
sp := getcallersp()
pc := getcallerpc()
gp := getg()
var n int
systemstack(func() {
n = gentraceback(pc, sp, 0, gp, skip, &pcbuf[0], len(pcbuf), nil, nil, 0)
})
return n
}Обратная трассировка стека — это процесс вызова профайлером
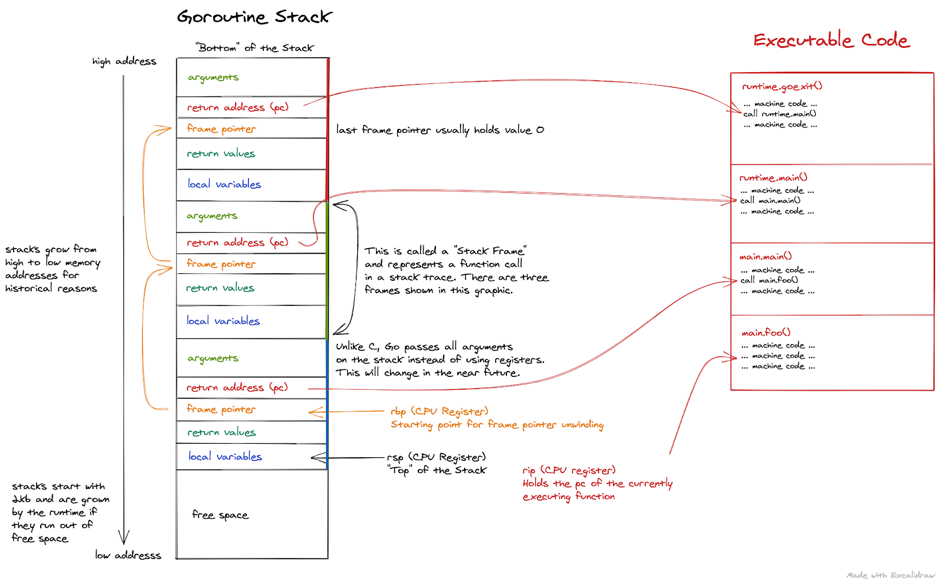
callers() и gentraceback(), получения текущего стека вызовов и сохранения его в массив stk. В этом массиве хранятся адреса программных счётчиков. Эта технология используется во многих ситуациях. Например, когда в программе возникает паника, стек расширяется.Переменные из показанного выше блока кода:
| Переменная | Предназначение | Регистр x86-64 |
pc |
Программный счётчик | RIP |
fp |
Указатель кадра | RBP |
sp |
Указатель стека | RSP |
Примечание: на этом рисунке все параметры Go передаются через стек. Эта ситуация устарела. Начиная с версии 1.17, Go поддерживает передачу через регистры.
Так как x86-64 классифицирует RBP как регистр общего назначения, такие компиляторы, как GNU Compiler Collection (GCC), по умолчанию больше не используют RBP для сохранения базового адреса стека, если только не включить такое поведение опцией. Однако компилятор Go сохраняет эту функцию, поэтому можно использовать RBP для обратной трассировки стека в Go.
Go не использует это простое решение, поскольку в некоторых ситуациях оно может вызывать проблемы. Например, если функция встроенная, то получаемый через обратную трассировку RBP стек вызовов будет отсутствовать. Также это решение должно вставлять дополнительные команды между обычными вызовами стека, и для этого оно занимает дополнительный регистр общего назначения. Даже если нам не нужна обратная трассировка стека, это снижает производительность.
Каждый двоичный файл Go содержит область
gopclntab, название которой является аббревиатурой от Go program counter line table. Файл хранит следующую информацию:- Отображение
pcнаspи его адрес возврата. Благодаря этому, нам не нужно полагаться наfpи можно напрямую завершать последовательности связанных списковpc, выполняя их поиск в таблице. -
Информацию о том, оптимизированы ли встраиванием
pcи его функция. Следовательно, мы не потеряем кадр встроенной функции во время обратной трассировки стека. - Таблица символов хранит информацию о коде (например, имена функций и номера строк) в соответствии с
pc. Таким образом, мы наконец можем увидеть человекочитаемые результаты паники или результаты профилирования вместо огромного набора информации об адресах.

В отличие от
gopclntab языка Go, DWARF является стандартизованным форматом отладки. Компилятор Go тоже добавляет информацию DWARF (v4) в свой сгенерированный двоичный файл, поэтому внешние инструменты, не относящиеся к экосистеме Go, могут использовать её для отладки программ на Go. Содержащаяся в DWARF информация является надмножеством gopclntab.Когда мы получаем массив
pc при помощи технологии обратной трассировки стека (функция gentraceback() в предыдущем блоке кода), нам необязательно превращать его в символы. Затраты на символизацию высоки. Сначала мы можем агрегировать массив pc при помощи стека адресов указателей. Под «агрегацией» подразумевается суммирование сэмплов с тем же содержимым массива в hashmap.Функция
stkbucket() получает соответствующий участок памяти (bucket), используя в качестве ключа stk, а затем суммирует поля для статистики в нём.Стоит заметить, что в
memRecord есть несколько групп данных memRecordCycle для статистики:type memRecord struct {
active memRecordCycle
future [3]memRecordCycle
}При суммировании данных в качестве подскрипта выполняется доступ к группе
memRecordCycle с глобальной переменной mProf.cycle. Инкремент mProf.cycle осуществляется после каждого раунда сбора данных (GC). Далее записывается распределение памяти между тремя раундами GC. После завершения первого раунда GC распределение памяти и освобождение между предыдущим раундом GC и текущим раундом GC внедряется в финальную отображаемую статистику. Такая структура позволяет нам не получать профиль кучи до выполнения GC. Следовательно, мы не увидим множества бесполезных временных операций распределения памяти. Также на разных этапах цикла GC мы можем увидеть нестабильные состояния памяти кучи.Далее
setprofilebucket() вызывается для записи bucket по mspan присвоенного адреса, и вызывается mProf_Free() для записи соответствующего освобождения памяти в будущем GC.Таким образом, эта коллекция bucket сохраняется в среде исполнения Go. Например, при выполнении профилирования памяти, когда мы вызываем
pprof.WriteHeapProfile(), выполняется доступ к коллекции bucket, которая преобразуется в формат, необходимый для вывода pprof.Также в этом заключается различие между профилированием кучи и профилированием ЦП:
- Профилирование ЦП снижает производительность приложения из-за сэмплирования только во временном окне профилирования.
- Сэмплирование для профилирования кучи происходит постоянно. На данный момент профилирование заключается лишь в дампинге снэпшотов данных.
А теперь мы перейдём в мир C/C++/Rust. К счастью, поскольку у большинства профайлеров кучи принципы реализации схожи, мы можем воспользоваться многим из того, что уже узнали. Профилирование кучи Go портировано из Google TCMalloc и они имеют схожие реализации.
Профайлер кучи Gperftools
Gperftools (ранее Google Performance Tools) — это тулкит, включающий в себя профайлер кучи, код проверки кучи, профайлер ЦП и другие инструменты.
Он имеет глубокую взаимосвязь с Go, поэтому я расскажу о нём непосредственно после Go.
Google TCMalloc, портированный средой исполнения Go, имеет две community-версии:
- TCMalloc — чистая реализация malloc без дополнительных функций.
- gperftools — реализация malloc с функциями профилирования кучи и другими поддерживающими наборами инструментов, в том числе pprof. Основным автором gperftools является Санджай Гемават, программировавший в паре с Джеффом Дином.
▍ Использование профайлера кучи Gperftools
Google использует профайлер кучи gperftools для анализа распределения памяти кучи программ на C++. Он обладает следующими возможностями:
- Определяет, что в текущий момент находится в памяти кучи.
- Находит утечки памяти.
- Ищет места в коде, выполняющие много распределений.
Go напрямую прописывает код получения в среде исполнения в функцию распределения памяти Аналогичным образом gperftools внедряет код получения в реализацию malloc libtcmalloc. Для замены стандартной реализации libc из malloc нам нужно исполнить
-ltcmalloc для компоновки библиотеки на этапе компоновки компиляции проекта.Мы можем использовать механизм динамической компоновки Linux для замены стандартной реализации libc из malloc в среде исполнения:
$ env LD_PRELOAD="/usr/lib/libtcmalloc.so" <binary>Когда
LD_PRELOAD задаёт libtcmalloc.so, то malloc(), по умолчанию скомпонованный в нашей программе, перезаписывается. Динамический компоновщик Linux гарантирует, что первой будет исполняться версия, заданная LD_PRELOAD.Если перед запуском скомпонованного с libtcmalloc исполняемого файла мы присвоим переменной окружения
HEAPPROFILE имя файла, то при исполнении программы данные профайлера кучи будут записываться в файл.По умолчанию, каждый раз, когда программа распределяет 1 ГБ памяти или объём используемой ею памяти увеличивается на 100 МБ, выполняется дамп профиля кучи. Изменять эти параметры можно при помощи переменных окружения.
Для анализа сдампленных файлов профиля можно использовать скрипт pprof, поставляемый в комплекте с gperftools. Он используется практически так же, как и в Go.
$ pprof --gv gfs_master /tmp/profile.0100.heap
$ pprof --text gfs_master /tmp/profile.0100.heap
255.6 24.7% 24.7% 255.6 24.7% GFS_MasterChunk::AddServer
184.6 17.8% 42.5% 298.8 28.8% GFS_MasterChunkTable::Create
176.2 17.0% 59.5% 729.9 70.5% GFS_MasterChunkTable::UpdateState
169.8 16.4% 75.9% 169.8 16.4% PendingClone::PendingClone
76.3 7.4% 83.3% 76.3 7.4% __default_alloc_template::_S_chunk_alloc
49.5 4.8% 88.0% 49.5 4.8% hashtable::resize
...В показанном выше блоке кода слева направо: Flat (МБ), Flat (%), Sum (%), Cum (МБ), Cum (%) и Name.
▍ Реализация профайлера кучи Gperftools
TCMalloc добавляет логику сэмплирования функции
malloc() и оператору new. Когда на основании условий срабатывает обработчик сэмплирования, исполняется следующая функция RecordAlloc:// Запись распределения в профиль.
static void RecordAlloc(const void* ptr, size_t bytes, int skip_count) {
// Берём трассировку стека снаружи критического раздела.
void* stack[HeapProfileTable::kMaxStackDepth];
int depth = HeapProfileTable::GetCallerStackTrace(skip_count + 1, stack);
SpinLockHolder l(&heap_lock);
if (is_on) {
heap_profile->RecordAlloc(ptr, bytes, depth, stack);
MaybeDumpProfileLocked();
}
}
void HeapProfileTable::RecordAlloc(
const void* ptr, size_t bytes, int stack_depth,
const void* const call_stack[]) {
Bucket* b = GetBucket(stack_depth, call_stack);
b->allocs++;
b->alloc_size += bytes;
total_.allocs++;
total_.alloc_size += bytes;
AllocValue v;
v.set_bucket(b); // также задали set_live(false); set_ignore(false)
v.bytes = bytes;
address_map_->Insert(ptr, v);
}Процесс исполнения происходит следующим образом:
- Для получения стека вызовов вызывается
GetCallerStackTrace(). - Для получения соответствующего bucket, вызывается
GetBucket()со стеком вызовов в качестве ключа hashmap. - Накапливается статистика bucket.
Так как GC отсутствует, этот процесс сэмплирования гораздо проще, чем в Go. Из наименования переменных мы понимаем, что код профилирования в среде исполнения Go перенесён отсюда.
sampler.h подробно описывает правила сэмплирования gperftools. gperftools имеет средний шаг сэмплирования в 512 КБ, как и профайлер кучи Go.Для записи освобождения памяти нам также нужно добавлять логику в оператор
free() или delete. Это гораздо проще, чем в профайлере кучи Go с GC:// Запись освобождения в профиль.
static void RecordFree(const void* ptr) {
SpinLockHolder l(&heap_lock);
if (is_on) {
heap_profile->RecordFree(ptr);
MaybeDumpProfileLocked();
}
}
void HeapProfileTable::RecordFree(const void* ptr) {
AllocValue v;
if (address_map_->FindAndRemove(ptr, &v)) {
Bucket* b = v.bucket();
b->frees++;
b->free_size += v.bytes;
total_.frees++;
total_.free_size += v.bytes;
}
}Далее нам нужно найти соответствующий bucket и суммировать поля, относящиеся к
free.В современных программах на C, C++ и Rust для получения стека вызовов обычно используется библиотека libunwind. Аналогично принципу обратной трассировки стека в Go, libunwind не выбирает режим обратной трассировки указателя кадра, а применяет таблицу раскрывания, записанную в определённой области программы. Разница заключается в том, что в Go используется конкретная функция
gopclntab, создающая собственную экосистему, а в программах на C, C++ и Rust применяется область .debug_frame или область .eh_frame..debug_frame определяется стандартом DWARF. Компилятор Go также содержит эту информацию, однако она не используется самостоятельно, а зарезервирована только для сторонних инструментов. GNU Compiler Collection (GCC) записывает отладочную информацию в .debug_frame только при включённом параметре -g..eh_frame более современен, он определён в Linux Standard Base. Он позволяет компилятору вставлять псевдокоманды, в том числе и директивы CFI, а также информацию кадра вызова в соответствующей позиции ассемблерного кода. Эти команды помогают ассемблеру генерировать окончательную область .eh_frame, содержащую таблицу раскрывания.Возьмём для примера следующий код:
// demo.c
int add(int a, int b) {
return a + b;
}Мы используем
cc -S demo.c для генерации ассемблерного кода; можно использовать компиляторы GCC или Clang. Обратите внимание, что параметр -g здесь не используется..section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _add ## -- Begin function add
.p2align 4, 0x90
_add: ## @add
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
addl -8(%rbp), %eax
popq %rbp
retq
.cfi_endproc
## -- End function
.subsections_via_symbolsСгенерированный ассемблерный код содержит множество псевдокоманд с префиксом
.cfi_, которые являются директивами CFI.Профайлер кучи Jemalloc
По умолчанию TiKV использует в качестве распределителя памяти jemalloc.
▍ Использование профайлера кучи Jemalloc
У Jemalloc есть функция профилирования кучи, но по умолчанию она отключена. При компилировании кода необходимо задать параметр
--enable-prof../autogen.sh
./configure --prefix=/usr/local/jemalloc-5.1.0 --enable-prof
make
make installКак это было и с TCMalloc, мы можем скомпоновать jemalloc с программой при помощи
-ljemalloc, или перезаписав malloc() библиотеки libc на jemalloc при помощи LD_PRELOAD.Давайте для примера рассмотрим программу на Rust и покажем, как выполнять профилирование кучи при помощи jemalloc:
fn main() {
let mut data = vec![];
loop {
func1(&mut data);
std::thread::sleep(std::time::Duration::from_secs(1));
}
}
fn func1(data: &mut Vec<Box<[u8; 1024*1024]>>) {
data.push(Box::new([0u8; 1024*1024])); // распределяем 1 МБ
func2(data);
}
fn func2(data: &mut Vec<Box<[u8; 1024*1024]>>) {
data.push(Box::new([0u8; 1024*1024])); // распределяем 1 МБ
}Мы распределяем на Rust 2 МБ памяти кучи в секунду: по 1 МБ в
func1 и func2. func1 вызывает func2.Используем
rustc для компиляции файла без параметров. Для запуска программы исполним следующую команду:$ export MALLOC_CONF="prof:true,lg_prof_interval:25"
$ export LD_PRELOAD=/usr/lib/libjemalloc.so
$ ./demoMALLOC_CONF задаёт параметры, связанные с jemalloc. prof:true включает профайлер, log_prof_interval:25 дампит файл профиля каждый раз, когда распределяется 2^25 байт (32 МБ) памяти кучи.Подробнее об опциях
MALLOC_CONF можно прочитать в этом документе.Спустя какое-то время мы увидим, что были сгенерированы файлы профилей.

jemalloc предоставляет jeprof — инструмент, схожий с pprof из TCMalloc. Фактически он форкнут из Perl-скрипта pprof. Можно использовать jeprof для просмотра файла профиля.
$ jeprof ./demo jeprof.7262.0.i0.heap
jeprof может сгенерировать такой же граф, как Go и gperftools:
$ jeprof --gv ./demo jeprof.7262.0.i0.heap
▍ Реализация использования профайлера кучи Jemalloc
Аналогично TCMalloc, jemalloc добавляет логику сэмплирования в
malloc():JEMALLOC_ALWAYS_INLINE int
imalloc_body(static_opts_t *sopts, dynamic_opts_t *dopts, tsd_t *tsd) {
// ...
// Если профилирование включено, получаем контекст профилирования.
if (config_prof && opt_prof) {
bool prof_active = prof_active_get_unlocked();
bool sample_event = te_prof_sample_event_lookahead(tsd, usize);
prof_tctx_t *tctx = prof_alloc_prep(tsd, prof_active,
sample_event);
emap_alloc_ctx_t alloc_ctx;
if (likely((uintptr_t)tctx == (uintptr_t)1U)) {
alloc_ctx.slab = (usize <= SC_SMALL_MAXCLASS);
allocation = imalloc_no_sample(
sopts, dopts, tsd, usize, usize, ind);
} else if ((uintptr_t)tctx > (uintptr_t)1U) {
allocation = imalloc_sample(
sopts, dopts, tsd, usize, ind);
alloc_ctx.slab = false;
} else {
allocation = NULL;
}
if (unlikely(allocation == NULL)) {
prof_alloc_rollback(tsd, tctx);
goto label_oom;
}
prof_malloc(tsd, allocation, size, usize, &alloc_ctx, tctx);
} else {
assert(!opt_prof);
allocation = imalloc_no_sample(sopts, dopts, tsd, size, usize,
ind);
if (unlikely(allocation == NULL)) {
goto label_oom;
}
}
// ...
}Вызываем
prof_malloc_sample_object() в prof_malloc(), чтобы накапливать соответствующие записи стека вызовов в hashmap:void
prof_malloc_sample_object(tsd_t *tsd, const void *ptr, size_t size,
size_t usize, prof_tctx_t *tctx) {
// ...
malloc_mutex_lock(tsd_tsdn(tsd), tctx->tdata->lock);
size_t shifted_unbiased_cnt = prof_shifted_unbiased_cnt[szind];
size_t unbiased_bytes = prof_unbiased_sz[szind];
tctx->cnts.curobjs++;
tctx->cnts.curobjs_shifted_unbiased += shifted_unbiased_cnt;
tctx->cnts.curbytes += usize;
tctx->cnts.curbytes_unbiased += unbiased_bytes;
// ...
}Инъецированная jemalloc в
free() логика схожа с TCMalloc. jemalloc также использует libunwind для обратной трассировки стека.Профайлер кучи Bytehound
Написанный на Rust Bytehound — это профайлер памяти для платформы Linux. Из-за его сильного влияния на производительность мы не можем использовать его в TiKV. Однако мы вкратце расскажем о его использовании. Нас интересует, как он реализован.
▍ Использование профайлера кучи Bytehound
Скачать двоичную динамическую библиотеку Bytehound можно на его странице Releases, которая поддерживается только платформой Linux.
Как и TCMalloc или jemalloc, Bytehound монтирует свою реализацию через
LD_PRELOAD. Здесь мы предполагаем, что выполняем ту же программу на Rust с утечками памяти в области профайлера кучи Bytehound:$ LD_PRELOAD=./libbytehound.so ./demoДалее в рабочей папке программы генерируется файл
memory-profiling_*.dat. Это результат профилирования кучи Bytehound. В отличие от ситуации с другими профайлерами кучи, этот файл постоянно дополняется, а не генерируются новые файлы.Далее мы исполним следующую команду, чтобы открыть веб-порт для анализа описанных выше файлов в реальном времени:
$ ./bytehound server memory-profiling_*.dat
Можно нажать на Flamegraph в правом верхнем углу, чтобы посмотреть flame-график:

Из flame-графика мы видим, что
demo::func1 и demo::func2 являются горячими точками использования памяти.Подробнее о Bytehound можно из его документации.
▍ Реализация профайлера кучи Bytehound
Bytehound заменяет стандартную реализацию malloc пользователя. Однако он не реализует распределитель памяти; он был упакован на основании jemalloc.
// Вход
#[cfg_attr(not(test), no_mangle)]
pub unsafe extern "C" fn malloc( size: size_t ) -> *mut c_void {
allocate( size, AllocationKind::Malloc )
}
#[inline(always)]
unsafe fn allocate( requested_size: usize, kind: AllocationKind ) -> *mut c_void {
// ...
// Вызываем jemalloc для распределения памяти
let pointer = match kind {
AllocationKind::Malloc => {
if opt::get().zero_memory {
calloc_real( effective_size as size_t, 1 )
} else {
malloc_real( effective_size as size_t )
}
},
// ...
};
// ...
// Обратная трассировка стека
let backtrace = unwind::grab( &mut thread );
// ...
// Запись сэмплов
on_allocation( id, allocation, backtrace, thread );
pointer
}
// xxx_real компонуется с реализацией jemalloc
#[cfg(feature = "jemalloc")]
extern "C" {
#[link_name = "_rjem_mp_malloc"]
fn malloc_real( size: size_t ) -> *mut c_void;
// ...
}При каждом распределении памяти Bytehound выполняет обратную трассировку стека и запись. Логика сэмплирования отсутствует. Обработчик
on_allocation отправляет запись распределения в канал. Обобщённый поток процессора потребляет запись в канале и асинхронно обрабатывает запись.pub fn on_allocation(
id: InternalAllocationId,
allocation: InternalAllocation,
backtrace: Backtrace,
thread: StrongThreadHandle
) {
// ...
crate::event::send_event_throttled( move || {
InternalEvent::Alloc {
id,
timestamp,
allocation,
backtrace,
}
});
}
#[inline(always)]
pub(crate) fn send_event_throttled< F: FnOnce() -> InternalEvent >( callback: F ) {
EVENT_CHANNEL.chunked_send_with( 64, callback );
}Реализация
EVENT_CHANNEL является Mutex<Vec>:pub struct Channel< T > {
queue: Mutex< Vec< T > >,
condvar: Condvar
}Тестируем излишнюю нагрузку профайлеров кучи
В этом разделе мы измерим дополнительную нагрузку на производительность, накладываемую описанными выше профайлерами. Способы измерения основаны на сценариях использования.
Тесты выполнялись по отдельности, но в одном тестовом окружении:
| Ключевые компоненты | Спецификация |
| Хост | Intel NUC11PAHi7 |
| ЦП | Intel Core i7-1165G7 2,8 ГГц~4,7 ГГц, 4 ядра, 8 потоков |
| ОЗУ | Kingston 64G DDR4 3200 МГц |
| Жёсткий диск | Samsung 980PRO 1T SSD PCIe4. |
| ОС | Arch Linux Kernel-5.14.1 |
▍ Go
В Go мы использовали TiDB (опенсорсную распределённую базу данных SQL) + unistore для развёртывания одного узла, настраивали параметр
runtime.MemProfileRate и применяли sysbench для замера производительности.Соответствующие версии ПО и параметры стресс-тестов:
| ПО | Версия |
| Go | 1.17.1 |
| TiDB | v5.3.0-alpha-1156-g7f36a07de |
| Хэш коммита | 7f36a07de9682b37d46240b16a2107f5c84941ba |
| Параметры Sysbench | Спецификация |
| Version | 1.0.20 |
| Tables | 8 |
| TableSize | 100,000 |
| Threads | 128 |
| Operation | oltp_read_only |
| MemProfileRate | Результат |
| 0: не записывается | Транзакций: 1 505 224 (2508,52 в секунду), запросов: 24 083 584 (40 136,30 в секунду), задержка (средняя): 51,02 мс, задержка (P95): 73,13 мс |
| 512 КБ: запись сэмплов | Транзакций: 1 498 855 (2 497,89 в секунду), запросов: 23 981 680 (39 966,27 в секунду), задержка (средняя): 51,24 мс, задержка (P95): 74,46 мс |
| 1: полная запись | Транзакций: 75 178 (125,18 в секунду), запросов: 1 202 848 (2 002,82 в секунду), задержка (средняя): 1 022,04 мс, задержка (P95): 2 405,65 мс |
Мы ожидали, что влияние на производительность, вызванное полной записью, будет очень высоким; однако оно оказалось неожиданно высоким: TPS и QPS уменьшились в двадцать раз, а задержка P95 увеличилась в тридцать раз.
Поскольку профилирование кучи — это общая функция, мы не можем точно замерить общее влияние на производительность при всех сценариях использования, поэтому ценными оказываются выводы из измерений в отдельных проектах. TiDB — это вычислительно затратное приложение. Однако оно может и не распределять память так часто, как некоторые приложения, активно использующие память. Следовательно, все сделанные в этой статье выводы можно использовать только для справки; вы сами можете замерить влияние на производительность в ваших конкретных сценариях использования приложений.
▍ Результаты тестирования TCMalloc и jemalloc
Мы замеряли TCMalloc и jemalloc на примере TiKV — распределённого движка хранения ключей и значений для TiDB. Был развёрнут процесс Placement Driver (PD) (компонент кластера TiDB, управляющий метаданными) и процесс TiKV на машине, после чего использовали go-ycsb для стресс-тестирования. Важные параметры:
threadcount=200
recordcount=100000
operationcount=1000000
fieldcount=20Прежде чем запускать TiKV, мы использовали
LD_PRELOAD для инъецирования различных обработчиков malloc. В TCMalloc использовалась конфигурация по умолчанию, то есть сэмплирование 512 КБ, как в Go; в jemalloc использовалась схожая стратегия сэмплирования, а файл профиля дампился каждый раз, когда распределялся 1 ГБ памяти кучи.Мы получили следующие результаты, измеряемые в операциях в секунду (OPS).
| Распределитель | Результат тестов |
| Стандартный распределитель памяти | OPS: 119 037,2, среднее (мкс): 4 186, P99 (мкс): 14 000 |
| TCMalloc | OPS: 113 708,8, среднее (мкс): 4 382, P99 (мкс): 16 000 |
| jemalloc | OPS: 114 639,9, среднее (мкс): 4 346, P99 (мкс): 15 000 |
Ранее мы выяснили, что реализация TCMalloc почти такая же, как pprof кучи Go, но замеренные данные не совсем совпадают. Возможно, это вызвано различиями в распределении памяти TiKV и TiDB. Мы не можем точно замерить общее влияние на производительность во всех сценариях использования. Наши выводы применимы только к конкретному проекту.
▍ Результаты тестов Bytehound
Я не стал помещать Bytehound, TCMalloc и jemalloc в один раздел, потому что при использовании Bytehound с TiKV в процессе запуска возникает проблема блокировки (deadlock).
Мне кажется, причина заключается в том, что Bytehound очень сильно влияет на производительность, теоретически его нельзя примерять в окружении продакшена TiKV. Нам нужно только проверить, верна ли моя гипотеза.
Она основана на том факте, что Bytehound не содержит логики сэмплирования. Данные, собираемые каждый раз, отправляются через канал в фоновый поток для обработки, а канал просто инкапсулирован при помощи Mutex+Vec.
Для измерения влияния Bytehound на производительность мы используем простой проект mini-redis. Так как наша цель заключается только в том, чтобы подтвердить возможность удовлетворения им требований окружения продакшена TiKV, а не в том, чтобы точно измерить данные, мы будем учитывать и сравнивать только TPS. Фрагмент кода драйвера выглядит следующим образом:
var count int32
for n := 0; n < 128; n++ {
go func() {
for {
key := uuid.New()
err := client.Set(key, key, 0).Err()
if err != nil {
panic(err)
}
err = client.Get(key).Err()
if err != nil {
panic(err)
}
atomic.AddInt32(&count, 1)
}
}()
}Мы включили 128 горутин для считывания и записи на сервер. Считывание или запись считаются полной операцией. Учитывается только количество раз, а такие метрики, как задержка, не измеряются. Мы разделим общее количество раз на время исполнения и получим разные TPS до и после включения Bytehound.
Результаты оказались такими:
| Конфигурация | Результат тестов |
| Стандартная конфигурация | Количество: 11 784 571, время: 60 с, TPS: 196 409 |
| Со включённым Bytehound | Количество: 5 660 952, время: 60 с, TPS: 94 349 |
