

Данные становятся движущей силой современного мира, поэтому почти каждый уже сталкивался с такими терминами, как data science, «машинное обучение», «искусственный интеллект», «глубокое обучение» и data mining. Но что же обозначают эти понятия? Какие различия и связи между ними существуют?
Все перечисленные выше термины, несмотря на их взаимосвязь, нельзя использовать в качестве синонимов. Эта статья поможет вам не только понять, какие исследования и опыт позволяют извлекать знания из данных, чтобы делать машины умнее, но и как конкретно это происходит.
Вкратце о дисциплинах работы с данными
Data science, data mining, машинное обучение, глубокое обучение и искусственный интеллект — основные термины, вызывающие самый высокий ажиотаж. Поэтому прежде чем приступать к подробным объяснениям, давайте вкратце рассмотрим все дисциплины, для которых важны данные.

Дисциплины data science на примере распознавания снимков МРТ.
Data science — это обширная научная область, занимающаяся осмыслением данных. Например, рассмотрим системы рекомендаций, создающие индивидуальные предложения для покупателей на основе истории их поиска. Допустим, если один покупатель искал удочку и прикорм, а другой наряду с этими продуктами искал и рыболовную леску, то есть высокая вероятность того, что первый покупатель будет заинтересован и в приобретении лески. Data science — это обширная область, включающая в себя все процессы и технологии, помогающие создавать такие системы, и в особенности те, которые мы рассмотрим ниже.
Data mining обычно является частью конвейера data science. Однако в отличие от него, data mining больше связан с техниками и инструментами, используемыми для выявления ранее неизвестных паттернов данных и для преобразования данных, чтобы они были более удобны для анализа. Если вернуться к примеру с рыболовными снастями, то data mining будет заключаться в исследовании данных за последние два года для поиска корреляций между количеством продаж удочек до и во время сезонов рыбалки в магазинах, расположенных в разных регионах.
Машинное обучение предназначено для обучения машин на исторических данных, чтобы они могли обрабатывать новые входящие данные на основании изученных паттернов без программирования, то есть без создаваемых вручную команд для выполнения системой действий. Если бы машинного обучения не существовало, то движки рекомендаций было бы создать невозможно, ведь человеку сложно было бы обработать миллионы поисковых запросов, оценок и обзоров, чтобы определить, какие покупатели покупают удочки с прикормом, а какие покупают дополнительно и леску.
Глубокое обучение — это самая ажиотажная область машинного обучения, использующая сложные алгоритмы глубоких нейронных сетей, примером для создания которых стала работа человеческого мозга. Модели глубокого обучения могут получать точные результаты из больших объёмов входящих данных, без указания того, на какие характеристики данных нужно обращать внимание. Представьте, что вам нужно определить, какие удочки генерируют положительные онлайн-отзывы на вашем веб-сайте, а какие отрицательные. В таком случае глубокие нейронные сети могут извлекать важные характеристики из отзывов и выполнять анализ эмоциональной наполненности.
Искусственный интеллект — это сложная тема. Но для простоты скажем, что каждый продукт, работающий с данными в реальном времени, можно назвать ИИ. Давайте вернёмся к нашему примеру с рыбалкой. Вам нужно купить определённую модель удочки, но у вас есть только её фотография и вы не знаете название производителя. Система ИИ — это программный продукт, способный изучить фотографию и предложить варианты названия продукта и магазинов, в которых его можно купить. Для создания системы ИИ нужно использовать data mining, машинное обучение и иногда глубокое обучение.
Объяснение data science, машинного обучения, искусственного интеллекта и big data за шесть минут.
Итак, подведём итог. Data science — это общий термин. Это область исследований наподобие computer science или прикладной математики. Data mining — более узкий термин, связанный с техниками, применяемыми в процессах data science, однако такие аспекты, как распознавание паттернов, статистический анализ и запись потоков данных, применимы в обеих областях. Data science, а, следовательно, и data mining могут использоваться для создания базы знаний, необходимой для машинного обучения, глубокого обучения, а в дальнейшем и для искусственного интеллекта.
После этого краткого описания мы перейдём к более подробным определениям терминов, а также поговорим об их взаимосвязи.
Что такое data science?
Профессор Школы бизнеса Штерна Васант Дхар предложил следующее определение:
«Data science — это исследование обобщаемого извлечения знаний из данных».
Хотя это одно из самых популярных определений data science, оно требует более подробного объяснения.
Data science — это непрерывно эволюционирующая научная дисциплина, нацеленная на понимание данных (структурированных и неструктурированных) и на поиск выводов из них. Data science использует big data и обширное множество различных исследований, методов, технологий и инструментов, в том числе машинное обучение, ИИ, глубокое обучение и data mining. Эта научная сфера сильно зависит от анализа данных, статистики, математики и программирования, а также от визуализации и интерпретирования данных. Всё это помогает дата-саентистам принимать обоснованные решения на основании данных и определять, как извлекать из них ценность и полезные для бизнеса выводы.
Процесс и примеры применения data science
Дата-саентисты работают с огромными объёмами данных, пытаясь добиться их понимания. Благодаря использованию нужных инструментов анализа данных дата-саентисты могут собирать, обрабатывать и анализировать данные для того, чтобы делать суждения и прогнозы на основе полученных выводов.
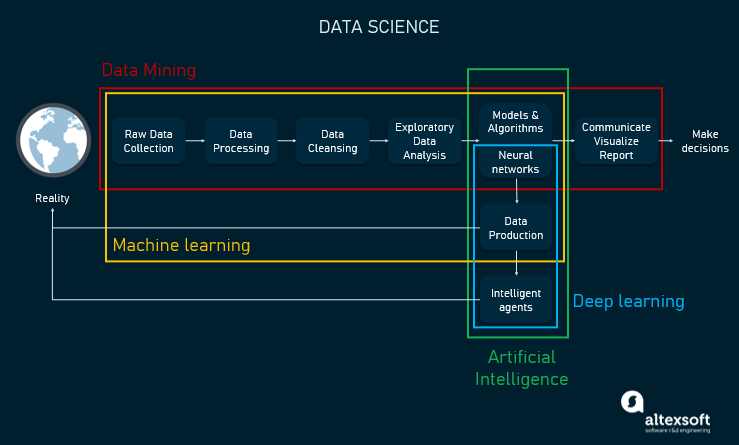
Иллюстрация взаимосвязей между data science, машинным обучением, искусственным интеллектом, глубоким обучением и data mining.
Уже многие годы data science эффективно используется в различных отраслях для внедрения инноваций, оптимизации стратегического планирования и совершенствования производственных процессов. И огромные корпорации, и мелкие стартапы собирают, а затем анализируют данные для развития своих бизнесов и повышения прибылей. Логика проста ‒ чем больше данных вы можете собрать и обработать, тем больше вероятность того, что вы сделаете из этих данных важные выводы. При помощи предсказательной аналитики бизнесы могут выявлять паттерны данных, о которых они и не догадывались. Одним из примеров таких областей применения является предсказательная оценка лидов.
Например, финансовая компания может выяснить, что клиенты, правильно расставляющие в тексте заглавные буквы, более надёжны, когда дело касается выплаты кредитов онлайн.
Ещё одним популярным примером использования data science является прогнозирование спроса и предложения. Рассмотрим компанию, занимающуюся производством графических карт. Предположим, что компания знает о выпуске новых популярных видеоигр. Она знает приблизительные даты, а также то, каким из игр требуются мощные GPU. В наилучшем для компании случае она сможет выполнить точное предсказание спроса, чтобы спрогнозировать будущие продажи и оптимизировать прибыль. Дата-саентисты сначала собирают исторические данные, сравнивают схожие ситуации с ожидаемыми, производят вычисления, а затем планируют предложение, чтобы покрыть спрос.
Что такое data mining?
Data mining — это набор техник и инструментов, широко используемых учёными и исследователями для извлечения новой и потенциально полезной информации из больших массивов ранее неизвестных данных, а также преобразования их в легко воспринимаемые структуры для дальнейшего применения. В основе современных технологий data mining лежит концепция поиска сокрытых паттернов и аномалий, отражающих многогранные соотношения между сырыми данными.
Процесс data mining и примеры его использования
Процесс data mining состоит из двух частей, называемых предварительной обработкой данных (data pre-processing) и самим data mining. Первая включает в себя такие этапы, как очистка данных, интеграция данных и преобразование данных, в то время как data mining занимается выявлением паттернов и представлением данных в понятном для понимания виде. Data mining часто рассматривается как часть более обширной области под названием Knowledge Discovery in Databases (KDD).
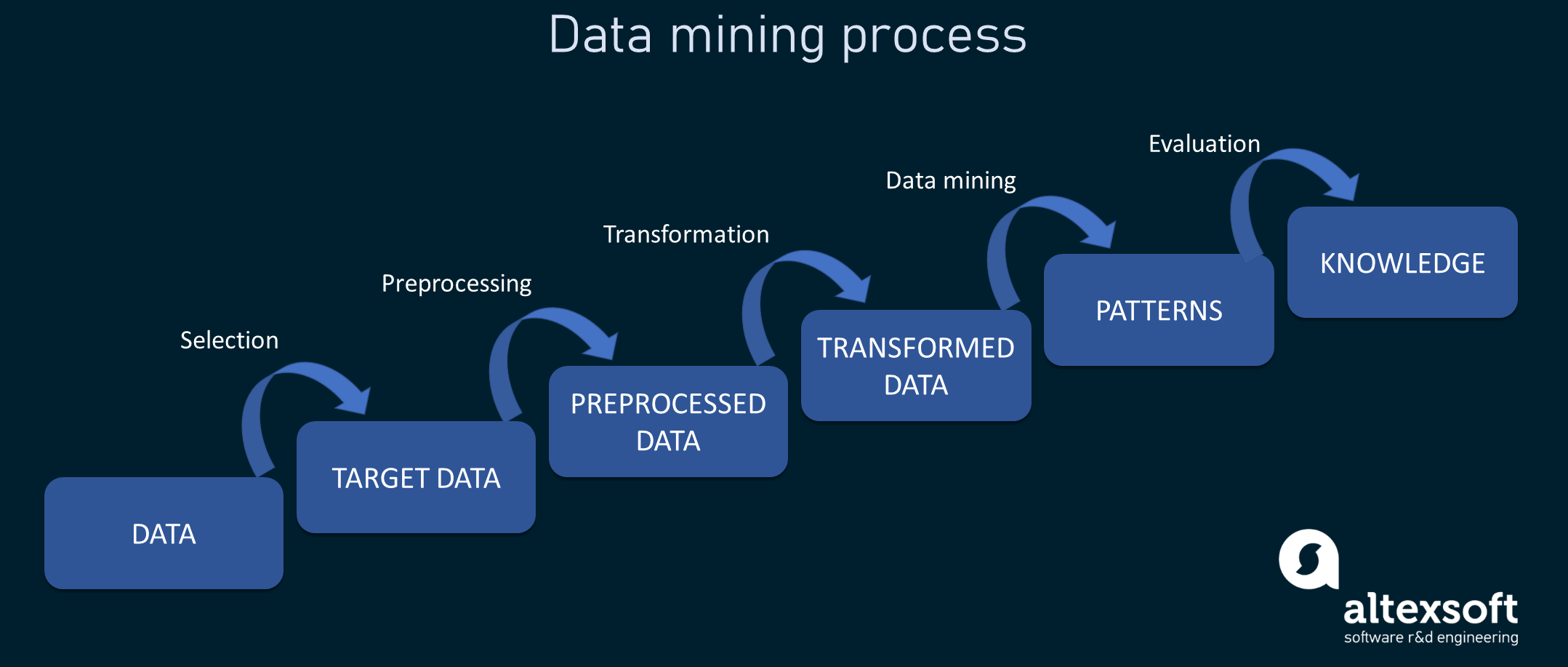
Общая схема этапов процесса data mining.
Практическое применение data mining неограниченно, поскольку его методики полезны в любой отрасли, имеющей дело с данными. Но в первую очередь методики data mining используются организациями, реализующими проекты, основанные на data warehousing. Например, анализ схожести корзин, предназначенный для выявления продуктов, которые покупатели склонны покупать вместе, широко применяется в электронной коммерции и розничной торговле.

Раздел «Frequently bought together» сайта Amazon — пример трендов, выявленных при помощи data mining.
На скриншоте представлено три разных товара, продаваемых на Amazon; утверждается, что люди часто покупают эти товары вместе, и поначалу связи между ними не видно. Да, перчатки и шарф выглядят логично, однако обмотанная колючей проволокой бейсбольная бита кажется здесь неподходящей. На самом деле, такое сочетание товаров очень популярно из-за сериала «Ходячие мертвецы». Благодаря data mining можно выявлять даже такие сложные взаимосвязи и странные паттерны в поведении покупателей.
Что такое машинное обучение?
Машинное обучение — это набор методик, инструментов и компьютерных алгоритмов, используемый для обучения машин анализу, пониманию и нахождению сокрытых паттернов в данных, а также для создания прогнозов. Конечная цель машинного обучения заключается в использовании данных для самообучения, устраняющего необходимость программирования машин вручную. После обучения на массивах данных машины могут применять запомненные паттерны к новым данным, делая благодаря этому более точные прогнозы.
Машинное обучение бывает разных видов:
При обучении с учителем машины обучаются находить решение нужной задачи при помощи людей, собирающих размечающих данные, которые затем передаются системам. Машине указывают, на какие характеристики данных нужно обращать внимание, чтобы она могла выявлять паттерны, помещать объекты в соответствующие классы и оценивать правильность своих прогнозов.
При обучении без учителя машины учатся распознавать паттерны и тренды в неразмеченных данных обучения без надсмотра пользователей.
При обучении с частичных привлечением учителя модели обучаются на небольшом объёме размеченных данных и гораздо большем объёме неразмеченных данных, используя обучение с учителем и без учителя.
При обучении с подкреплением модели, помещённые в незнакомое им окружение, должны найти решение задачи путём последовательных проб и ошибок. Аналогично системе, используемой во многих играх, машины получают наказание за ошибку и вознаграждение за успешную попытку. Таким образом они учатся находить оптимальное решение.
Процесс машинного обучения и примеры его использования
Для демонстрации работы машинного обучения мы возьмём классический пример фильтрации спама в электронной почте. Если вы откроете папку спама в своём аккаунте электронной почты, то увидите множество ненужных и раздражающих сообщений. Системы распознавания спама помогают в отфильтровывании неуместных сообщений от важных пользователям.
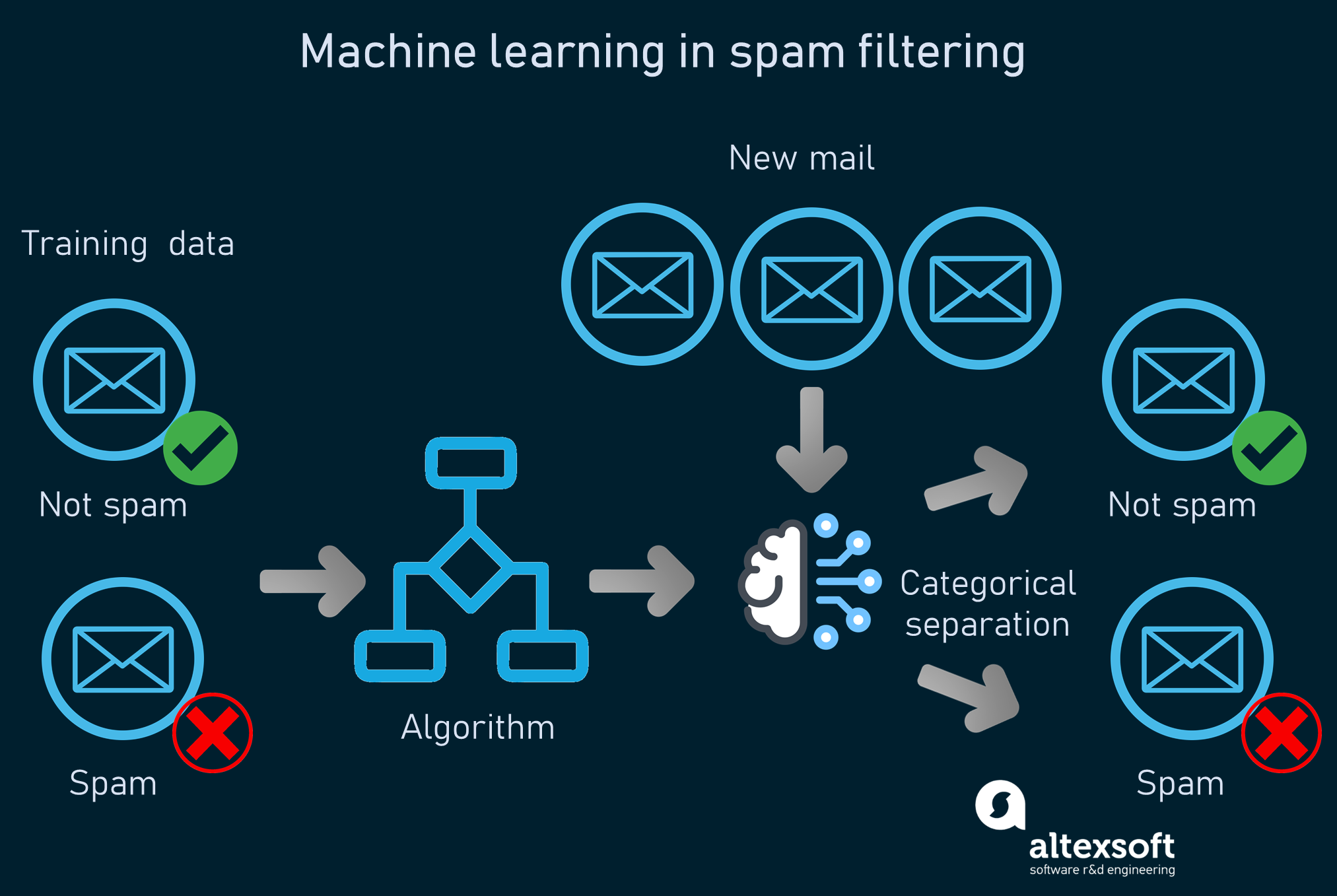
Как работает машинное обучение в распознавании спама.
Системы анализируют содержимое электронных писем и классифицируют данные при помощи алгоритмов машинного обучения. Задача таких моделей — определять, является ли письмо спамом. Так как распознавание спама — задача для машинного обучения с учителем, модель сначала обучается на размеченных массивах данных — примерах спама и обычных сообщений, выбранных людьми. Подробнее о подготовке данных в машинном обучении можно узнать из нашей статьи или из видео:
Основы подготовки данных для машинного обучения
Один из популярных способов обучения модели — это наивный байесовский алгоритм, вычисляющий вероятность событий или результатов на основании полученных ранее знаний. Этот способ выполняет корреляцию одних признаков с спам-сообщениями и других признаков — с обычной почтой. Признаки — это слова или фразы, находящиеся в теле и заголовке письма. Затем он вычисляет вероятность того, что конкретное сообщение является спамом.
Вам известно, что сообщение с заголовком «Вы выиграли 1000000 долларов», скорее всего, является спамом, но машине сначала нужно этому научиться. В процессе изучения моделью паттернов она может точно присваивать каждому новому письму оценку. Письма, оценка которых превышает пороговое значение, попадают во входящие, а письма с более низкой оценкой помечаются как мусорные. При пользовании сервисами электронной почты люди вручную помечают некоторые входящие сообщения как спам, добавляя новые данные в массив данных обучения системы. Это часть конвейера машинного обучения называется переобучением модели, она гарантирует актуальность системы и обеспечение ею точных результатов.
Ещё одним примером машинного обучения является медицинское прогнозирование того, какие пациенты имеют повышенную вероятность заболевания, при помощи анализа их электронных медицинских записей и жалоб. Замечательный пример машинного обучения — это системы распознавания мошенничества. Они помогают сигнализировать о возможном мошенничестве, анализируя подозрительное поведение пользователей.
Что такое глубокое обучение?
Глубокое обучение — это подмножество машинного обучения, однако дополненное сложными нейронными сетями, источником для создания которых послужили биологические нейронные сети в человеческом мозге. Нейросети содержат узлы, находящиеся в нескольких взаимосвязанных слоях, выполняющие коммуникацию друг между другом для понимания объёмных входящих данных.
Существует множество видов нейросетей, например, свёрточные, рекурсивные и рекуррентные. Типичная нейронная сеть состоит из входного слоя, нескольких скрытых слоёв и выходного слоя, наложенных друг на друга.

Иллюстрация глубокой нейронной сети с тремя скрытыми слоями.
Процесс глубокого обучения и примеры его использования
На показанном ниже изображении мы с лёгкостью можем отличить корги и буханки хлеба. Машины не могут выполнять эту задачу столь же просто. Прежде чем понять, что находится на изображении, и выдать точные результаты, им нужно учиться на огромных объёмах данных, создавать алгоритмы и преобразовывать входящие данные в машинночитаемый вид.
Пример распознавания изображения «корги или буханка хлеба». Источник: Imgur
Допустим, нам нужно создать программу, распознающую на фотографиях корги, или, в более общем случае, распознающую на изображениях определённые объекты. Для распознавания изображений, а также других данных, которые можно преобразовать в визуальный формат (например, звуковых спектрограмм) лучше всего подходят модели глубокого обучения.
Давайте вернёмся к нашему примеру. Мы берём множество фотографий корги и буханок; каждое изображение имеет размер 30×30 пикселей. Группа нейронов будет соответствовать каждому пикселю входящего изображения (суммарно 900), а каждый нейрон обозначает свою активацию (число, обозначающее значение конкретного пикселя). Активации в одном слое определяют активации в следующем.
Нейроны соединены линиями, называемыми синапсами, и каждая из этих линий имеет вес, определяемый значениями активации. Чем больше вес, тем сильнее он будет доминировать в следующем слое нейросети.
В каждом слое есть нейроны смещения, перемещающие функции активации в разных направлениях. Сумма весов, значений активации и значений смещения называется взвешенной суммой слоя нейросети. Взвешенная сумма в одном слое создаёт входящие данные для другого, пока они не достигнут последнего выходного слоя.

Процесс глубокого обучения.
Активация нейронов в выходном слое обозначает величину того, насколько, по мнению системы, изображение соответствует задаче классификации. В нашем случае это вероятность того, что на конкретном фото представлен корги, а не буханка хлеба. Нейросеть считается успешно обученной, когда значение весов, создающих результат, ближе всего к реальности.
Работа алгоритмов глубокого обучения в задачах распознавания изображений
Глубокое обучение находит множество практических применений: от технологий распознавания речи, позволяющих преобразовывать устную речь в текстовый формат (это помогает тысячам людей, испытывающим трудности с вводом кнопками и клавишами), до систем поиска лекарств, способных прогнозировать фармакологические свойства лекарств в различных биологических условиях. Ещё одним примером успешной реализации алгоритмов глубокого обучения является Google Переводчик, создающий качественные переводы письменного текста на более чем ста языках.
Что такое искусственный интеллект?
В традиционной терминологии искусственный интеллект (ИИ) — это просто алгоритм, код или техника, позволяющая машинам имитировать, развивать и демонстрировать человеческое понимание или поведение. В мире бизнеса ИИ — это продукт для обработки данных в реальном времени, способный выполнять операции и решать задачи примерно так же, как это делает человек. В функции систем ИИ включены обучение, планирование, рассуждение, принятие решений и решение задач.
Проблема в том, что понятию ИИ сложно дать точное и недвусмысленное определение.
Мы живём в эпоху так называемого слабого ИИ, или узкого искусственного интеллекта (artificial narrow intelligence, ANI), то есть такие технологические продукты умеют делать только то, чему их научили. Сильный ИИ, или artificial general intelligence (AGI) встречается пока только в фильмах и книгах, где машины могут обобщённо решать различные задачи так, как это делают люди. Можно вспомнить такие фильмы, как «Я, робот» (2004 год) или «Чаппи» (2015 год). Также существует третий тип ИИ — искусственный сверхинтеллект (artificial superintelligence, ASI), обладающий более мощными способностями, чем человек. Естественно, до его реализации нам ещё далеко.
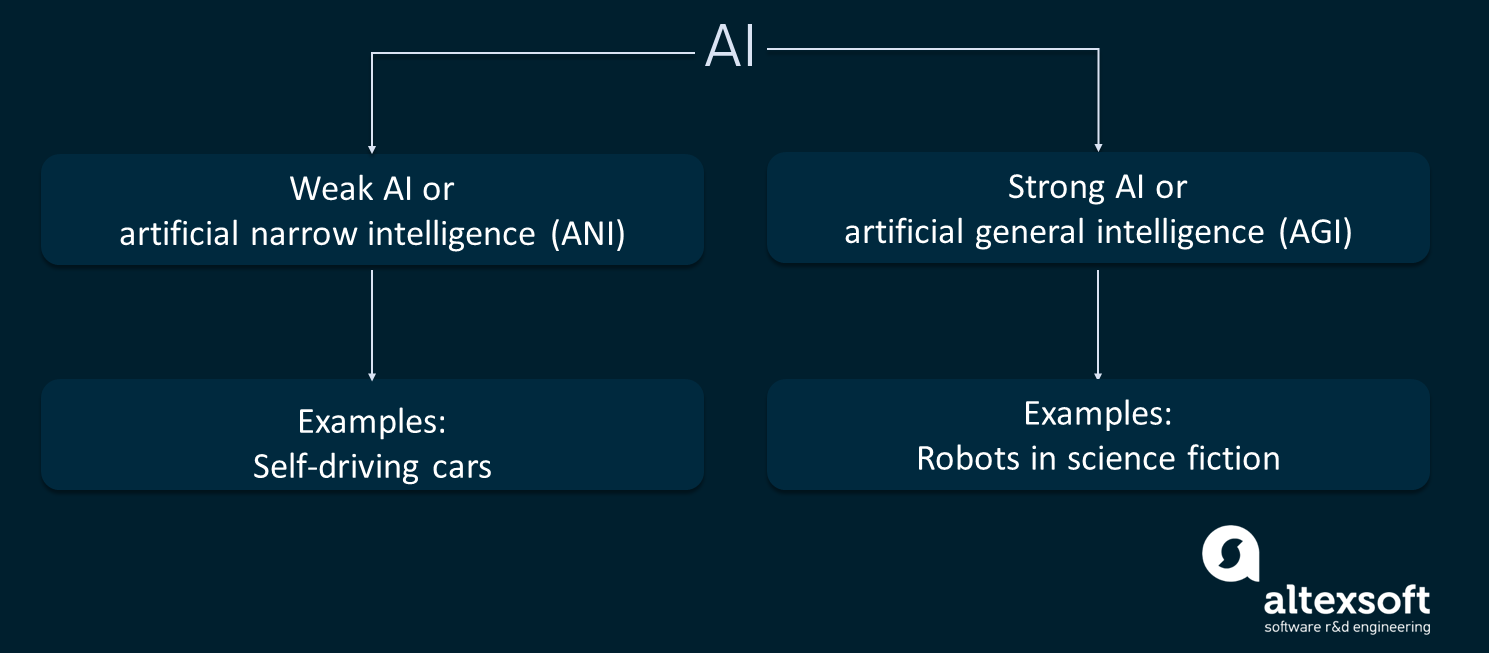
Слабый и сильный ИИ.
Не существует консенсуса о том, какие из открытий больше связаны с ИИ, чем остальные, как и нет согласия в том, чем же является ИИ — угрозой или спасением. Вот что говорил Билл Гейтс в одном из своих интервью:
«Google, Facebook, Apple, Microsoft — все они быстро совершенствуют своё ПО искусственного интеллекта […] искусственный интеллект будет чрезвычайно полезен, а риск того, что он станет сверхумным, далеко в будущем».
Чтобы спать спокойно, прочитайте нашу статью о том, захватит ли AGI мир.
Примеры использования искусственного интеллекта
Хотя от человекоподобного уровня ИИ роботов нас отделяет не менее нескольких десятков лет, учёные уже сегодня могут решать при помощи слабого ИИ кучу потрясающих задач. Возьмём для примера чат-ботов. Благодаря пониманию речи и текста на естественном языке системы ИИ общаются с людьми естественным образом. Другими замечательными примерами ИИ являются беспилотные автомобили, промышленные роботы и спам-фильтры.
Ключевые различия между ИИ, машинным обучением, глубоким обучением, Data Science и Data Mining
Подводя итоги, мы выделим ключевые различия между data science, data mining, искусственным интеллектом, машинным обучением и глубоким обучением.
- Data science можно рассматривать как зонтичный термин для всех дисциплин, используемых для понимания больших объёмов данных. Исследования data science — основа для создания умных ИИ-продуктов с использованием машинного или глубокого обучения.
- В отличие от data science, data mining — это набор техник и инструментов, используемых для сбора, очистки и анализа данных с целью извлечения из них интересных паттернов и трендов. Также data mining обычно используется при работе над проектами ИИ.
- ИИ связан с процессом создания функционального продукта для обработки данных, который может самостоятельно решать поставленные задачи, что отдалённо напоминает решение задач человеком.
- Машинное обучение — это система ИИ, которая может самообучаться на основании алгоритмов и ранее выученных паттернов.
- Глубокое обучение — это разновидность машинного обучения, однако в нём используются нейронные сети для создания прогнозов на основе обработанных данных.
- В большинстве проектов ИИ используется или машинное, или глубокое обучение, поскольку так называемое «интеллектуальное» поведение машин требует огромного количества данных, что, в свою очередь, требует исследований в сфере data science и data mining.
Описанные в статье дисциплины обработки данных применяются совместно. Они уже сегодня имеют множество практических применений в различных сферах, от менеджмента и продаж до здравоохранения и финансов, и в дальнейшем нас ждут новые инновации и прорывы.
Комментарии (3)

R7R
19.08.2022 16:39+2Хотя от человекоподобного уровня ИИ роботов нас отделяет не менее нескольких десятков лет,
Я бы добавил — «по счастью».
Так как первым их применением, станет, безусловно, военное, и никто не знает, к каким последствиям это приведет (хотя Чапек смог предугадать их сразу)
R7R
19.08.2022 16:43+1от технологий распознавания речи, позволяющих преобразовывать устную речь в текстовый формат (это помогает тысячам людей, испытывающим трудности с вводом кнопками и клавишами)
В первую очередь это используется программами-переводчиками, трудности с вводом тут не причем :)
R7R
Естественный интеллект обучается довольно быстро и элементарно вычисляет чат-ботов, несмотря на естественный язык их общения.
На удочку попадаются только неопытные граждане :)