
Привет! Я Андрей Татаринов, директор AGIMA.AI. Мы занимаемся проектами в области машинного обучения и анализа данных. В этой статье расскажу про продвинутую персонализацию, основанную на ML-модели. Отдельно поговорим о том, как разработать систему рекомендаций, которая будет встраиваться во все листинги на сайте и учитывать максимум пользовательских интересов. А в конце покажу, как такие рекомендации влияют на конверсию.

Персонализация — это топливо для e-commerce-проектов. Без него мотор вашего бизнеса не заведется. Если пользователь не находит нужный товар в интернет-магазине, он уходит, а вы теряете деньги. С каждым годом значение персонализации растет, так как пользователи становятся всё более искушенными и ждут от бизнеса большего понимания их потребностей.
За счет персонализированных рекомендаций пользователи не только быстро находят нужные товары, но и покупают больше. Доказано нашим опытом работы с YouTravel.me — маркетплейсом авторских туров.
На YouTravel почти 40 000 предложений. В большинстве случаев пользователь даже не видит весь объем предложений под свой запрос, поэтому делает выбор из того, что находит на первых двух страницах поиска или в блоках «Рекомендовано» на главной.
Эта весьма распространенная ситуация для сайтов такого типа. Поэтому персонализация — очень важная история для маркетплейсов и интернет-магазинов с большим ассортиментом. Но персонализация бывает разной.
Что не так с персонализацией в e-commerce
В большинстве случаев персонализация в e-commerce работает только в отдельных блоках вроде «Также вам понравится», «С этим товаром покупают» или через Upsell-рекомендации в корзине. Так происходит не потому, что это самые эффективные варианты. Просто интеграция в эти места самая дешевая и простая.
На самом же деле предметом для персонализации должен быть любой листинг на маркетплейсе. Однако в любой листинг встраиваться сложно, потому что в каждом своя нетривиальная логика, по которой этот листинг формируется: на основании каких фильтров, по каким критериям активности, предложения и т. д. Поэтому большинство игроков предпочитают вариант попроще и подешевле — внедрение виджета «Также вам понравится», который довольно ограничен не только в функционале, но и в эффективности.
Просто сравните: виджет из 4 объектов или 100 персонализированных товаров из листинга. Конечно, профита больше в том, чтобы пересортировать основной листинг, чем внедрить маленький блок с ограниченным предложением.
Несмотря на сложность персонализации в листингах на рынке есть e-commerce-системы, которые реализуют персонализацию в основной ленте. Например, AliExpress. Если вы нажмете там на любую радиоуправляемую машинку, то при следующем апдейте у вас вся лента будет завалена этими машинками. Такая же история и в TikTok.
Мы в AGIMA.AI вдохновились этими примерами и придумали стратегию персонализации, которая позволяет интегрироваться на уровне пересортировки любого листинга со своей логикой формирования. Мы не просто отдаем список рекомендованных объектов по API, мы реализуем:
сбор ленивых просмотров и большого количества поведенческой информации;
метод пересортировки любого списка товаров под каждого отдельного клиента.
Именно такую стратегию мы реализовали на сайте YouTravel.
Погружение в детали
Расскажем подробнее про наш метод пересортировки и стратегию персонализации в целом.
Сценарий тут такой: например, пользователь что-то ищет на сайте, выставляет в поиске фильтр «Россия», по нему находит 15 000 туров. Мы получаем все эти туры на вход — они уже отфильтрованы по некоторой логике, корректной для нашей системы. Дальше мы отвечаем на вопрос, какие 20 туров показать на первой странице, чтобы увеличить вероятность конверсии пользователя в клик или покупку.
У нас это называется API пересортировки. Именно пересортировка была фундаментом для внедрения нашей API.
Сбор и процессинг данных
Чтобы персонализация работала, нужен сбор данных про пользователя. Совместно с YouTravel мы сделали систему по сбору информации о том, что пользователь видел на странице, на что кликнул, куда перешел. Команда YouTravel выполняла доработки на стороне фронтенда, мы делали приемную часть и часть регулярной обработки данных.
Ключевой момент в нашем сборе данных — это учет ленивых просмотров. В типичном трекинге сбор информации про просмотры без взаимодействия отсутствует. А нам важно знать, что пользователь видел вот эти 20 товаров, но ничего не выбрал и не совершил никакого действия. Эта информация необходима для статистики и для обучения ML-модели.

Соответственно, мы доработали систему сбора данных (и со стороны заказчика, и с нашей) таким образом, чтобы получать информацию:
про ленивые просмотры;
про глубокие просмотры (просмотры карточки товара);
про покупки.
Полное решение выглядит так:
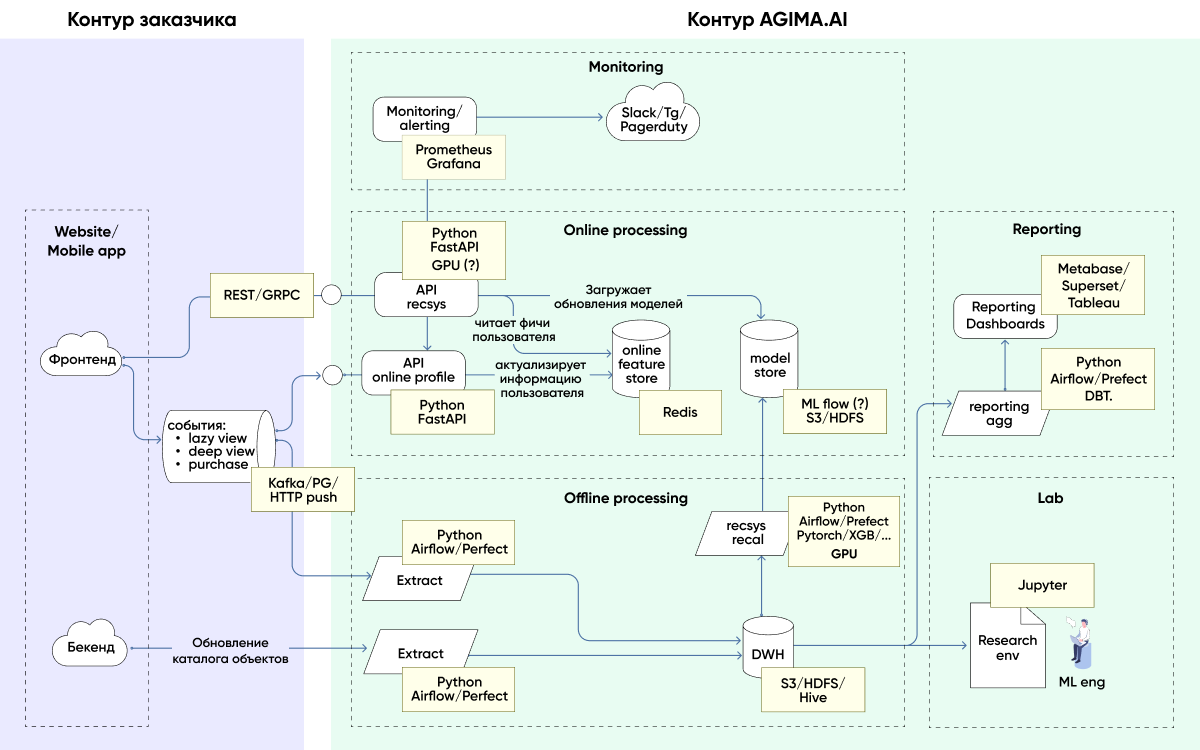
С фронтенда льются данные, мы их принимаем, кладем в два места:
Долгосрочное хранилище для переобучения модели подсчета статистики.
Онлайн-профиль, который в моменте отвечает на вопрос, какие предпочтения у пользователя, какое поведение он проявил только что.
Наш идеальный сценарий таков: пользователь кликает на страницу товара, производит активное действие с каким-то туром и на следующей странице он уже видит выдачу, которая персонализирована на основании того, что он с этим туром провзаимодействовал.
Для этого у нас есть вторая ветка от онлайн-профиля пользователя, куда в реальном времени поступает поток событий с фронтенда и поддерживается урезанное, но реалтайм-представление о том, что мы знаем про пользователя.
Рядом с этим стоит наша API рекомендаций на основе ML-модели, которая реализует самый главный метод — метод пересортировки списка товаров. Она пользуется информацией из онлайн-профиля, чтобы узнать, какими свойствами обладает пользователь, для которого мы делаем пересортировку, и держит в памяти модель персонализации — их может быть несколько, модели могут подменяться.
Это онлайн-цикл работы — то, что происходит за полсекунды в процессе работы сайта с пользователем.
Есть еще длинный цикл взаимодействия — ежечасно мы забираем статистику, которая накопилась, пересчитываем матрицы рекомендаций и принудительно обновляем модель в API. Примерно раз в час мы обновляем предрасчитанные рекомендации по каждому отдельному пользователю.
Стратегии рекомендаций
У нас есть три ситуации, в которых мы делаем рекомендации для пользователя:
Самая комфортная: к нам пришел пользователь, который находится на сайте больше 30 минут. Значит, он уже попал в ежечасный цикл переобучения. Тогда мы просто пользуемся хорошо рассчитанным вектором свойств пользователя и делаем хорошие рекомендации. Они получаются самыми качественными.
Пользователь пришел недавно, его еще нет в рассчитанных фичах, но он уже успел проявить каким-то образом свое поведение. Например, кликнул на один товар. В этом случае мы делаем хорошее предположение относительно его предпочтений на основании свойств товара, к которому он проявил интерес, и формируем для него рекомендации.
И самый сложный случай — это холодный пользователь. Он только что пришел, мы о нем ничего не знаем, но нам надо ему что-то порекомендовать. В этом случае мы стараемся использовать статические фичи, которые выражаются не в его поведении, а в его свойствах (какой язык на сайте выбран, из какого региона, с какого устройства и т. п.). Пытаемся из этого сделать предположение, что ему лучше порекомендовать.
Все три стратегии работают одновременно.

К сожалению, большая часть показов приходится на долю холодных пользователей. Поэтому мы активно работаем над улучшением холодных рекомендаций. Стараемся включить как можно больше статической информации в рекомендации. Например, пробуем учитывать рекламную кампанию, по которой пришел пользователь, учимся понимать текст объявления и забирать это в рекомендации. Помимо этого, учитываются:
лендинг, на котором пользователь приземлился;
модель телефона, с которого он зашел;
язык сайта/браузера, который определился для пользователя;
его география.
Конечно, список таких типов данных конечен, но это именно то, что мы можем знать про пользователя вхолодную.
Результаты
Наша мечта — чтобы каждый список объектов на сайте был пересортирован нашей стратегией пересортировки. Потому что ее кликабельность точно выше, чем дефолтная.
Сейчас на сайте YouTravel стратегия интегрирована в часть листингов. Статус на текущий момент можно описать так: внедрились в бой, прошли стадию первоначального запуска, находимся на этапе инкрементального улучшения. С нуля до запуска прошло 2 месяца, и мы готовы поделиться первыми результатами.
Средняя конверсия из показа в клик без рекомендаций — от 3% до 4,5%. У персонализированных предложений кликабельность на старте проекта — от 6% до 9%. Двукратное увеличение целевого действия — весьма приличный результат. При том, что мы продолжаем работать над проектом.

Наши холодные рекомендации работают пока так же, как сортировка по популярности у заказчика. Мы активно прокачиваем это направление, чтобы сделать холодные рекомендации сильнее. Фундаментальная проблема с такими рекомендациями в том, что мы почти ничего не знаем про пользователя, но мы экспериментируем с имеющимися данными и пробуем выжать из них максимум.
Комментарии (2)

mostodont32
23.08.2022 22:57Неплохо было бы сделать рандомный сбор для обучения. А то у вас всегда будет смещение в дефолтную сортировку товаров. Может быть поэтому у вас на холодных пользователях не получается лучше, чем сортировка по популярности.
VasiliyTerkin
Вы не ошиблись, именно 40 000 предложений, не 4000?