

Я провел в изучении JMM много часов и теперь делюсь с вами знаниями в простой и понятной форме.
В этой статье мы подробно разберем Java Memory Model (JMM) и применим полученные знания на практике. Да, в интернете накопилось достаточно много информации про JMM/happens-before, и, кажется, что очередную статью про такую заезженную тему можно пропускать мимо. Однако я постараюсь дать вам намного большее и глубокое понимание JMM, чем большинство информации в интернете. После прочтения этой статьи вы будете уверенно рассуждать о таких вещах как memory ordering, data race и happens-before. JMM — сложная тема и не стоит верить мне на слово, поэтому большинство моих утверждений подтверждается цитатами из спеки, дизассемблером и jcstress тестами.
Введение: контекст
В современном мире код часто выполняется не в том порядке, в котором он был написан в программе. Он часто переупорядочивается на уровне:
- Компилятора байткода (в частности, javac)
- Компилятора машинного кода (в частности, JIT компилятор HotSpot C1/C2). Например, среди компиляторов широко распространена такая оптимизация как Instruction scheduling
- Процессора. Например, в мире процессоров широко распространены такие практики как Out-of-order execution, Branch Prediction + Speculation, Prefetching, а также многие другие
Также в современных процессорах каждое ядро имеет собственный локальный кэш, который не видим другим ядрам. Более того, записи могут удерживаться в регистрах процессора, а не сбрасываться в память. Это ведет к тому, что поток может не видеть изменений, сделанных из других потоков.
Все эти оптимизации делаются с целью повысить производительность программ:
- Переупорядочивание необходимо для того, чтобы найти самый оптимальный путь к выполнению кода, учитывая стоимость выполнения процессорных инструкций. Например, процессор может инициировать загрузку значения из памяти заранее, даже если в порядке программы это чтение идет позднее. Операции чтения из памяти стоят дорого, поэтому эта оптимизация позволяет максимально эффективно утилизировать процессор, избежав простаивания, когда это чтение действительно понадобится
- Чтение из регистра и кэша стоит сильно дешевле, чем чтение из памяти. Более того, локальный кэш необходим для того, чтобы ядра не простаивали в ожидании доступа к общему кэшу, а могли работать с кэшем независимо друг от друга
Хорошо, но как в таком хаосе мы вообще можем написать корректную программу?
Есть хорошие новости, и плохие. Начнем с хорошей:
- Java дает гарантию as-if-serial выполнения кода — вне зависимости от используемой JDK итоговый результат выполнения будет не отличим от такого порядка, как если бы действия выполнялись действительно последовательно согласно порядку в коде
- Процессоры тоже делают только такие переупорядочивания, которые не изменят итогового результата выполнения инструкций
- Процессоры имеют Cache Coherence механизм, который гарантирует консистентность данных среди локальных кэшей: как только значение попадает в локальный кэш одного ядра, оно будет видно всем остальным ядрам
Рассмотрим на примере — этот однопоточный код может быть переупорядочен как угодно под капотом, но в итоге мы гарантированно увидим результат обеих записей при чтении:
a = 5;
b = 7;
int r1 = a; /* always 5 */
int r2 = b; /* always 7 */Какой порядок инструкций мог быть под капотом?
Например, такой:
b = 7;
a = 5;
int r2 = b; /* 7 */
int r1 = a; /* 5 */Или такой:
b = 7;
int r2 = b; /* 7 */
a = 5;
int r1 = a; /* 5 */Но здесь важно лишь то, что выполняемые под капотом действия в итоге приводят к ожидаемому результату. Такие переупорядочивания легальны потому, что эти 2 набора из записи/чтения никак не связаны друг с другом.
Теперь плохие новости:
- Java дает as-if-serial гарантию только для единственного треда в изоляции. Это означает, что в многопоточной программе при работе с shared данными мы можем не увидеть записи там, где полагаемся на порядок выполнения действий в коде другого треда. Другими словами, для первого треда в изоляции валидно переупорядочивать инструкции местами, если это не повлияет на его результат выполнения, но переупорядочивание может повлиять на другие треды
- Процессор также дает гарантию только для единственного ядра в изоляции
- Cache Coherence действительно гарантирует чтение актуальных значений, но пропагация записи происходит не мгновенно, а с некоторой задержкой
Обо всем этом мы еще поговорим далее.
А теперь давайте перейдем к примеру из заголовка к статье (кстати, эта программа отражает идиому Dekker lock):
public class MemoryReorderingExample {
private int x;
private int y;
public void T1() {
x = 1;
int r1 = y;
}
public void T2() {
y = 1;
int r2 = x;
}
}Проанализируем программу:
- Обе записи идут до чтений, поэтому выполнение программы начинается или с записи x, или с записи y
- Перед любым из чтений должна была произойти как минимум одна запись
Таким образом, кажется, что мы никогда не можем получить такой результат выполнения программы, когда увидим 0 на обоих чтениях. Иначе это означало бы, что выполнение программы началось с чтений, что не соответствует порядку программы.
Однако, хоть это и может показаться странным, в данной программе мы вполне можем наблюдать результат чтения (r1, r2) = (0, 0). А причины следующие:
- Instructions reordering. Оба треда могли поменять местами инструкции записи и чтения, так как эти действия никак не связаны
- Visibility. Даже если переупорядочивания не было, записи могут быть просто не видны другому треду из-за оптимизаций компилятора или задержки при пропагации записи на уровне кеша
Совсем не нужно верить мне на слово, поэтому давайте напишем тест при помощи инструмента jcstress, который позволяет писать concurrency тесты для Java:
@JCStressTest
@Description("Classic test that demonstrates memory reordering")
@Outcome(id = "1, 1", expect = Expect.ACCEPTABLE, desc = "Have seen both writes")
@Outcome(id = {"0, 1", "1, 0"}, expect = Expect.ACCEPTABLE, desc = "Have seen one of the writes")
@Outcome(id = "0, 0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "Have not seen any write")
public class JmmReorderingDekkerTest {
@Actor
public final void actor1(DataHolder dataHolder, II_Result r) {
r.r1 = dataHolder.actor1();
}
@Actor
public final void actor2(DataHolder dataHolder, II_Result r) {
r.r2 = dataHolder.actor2();
}
@State
public static class DataHolder {
private int x;
private int y;
public int actor1() {
x = 1;
return y;
}
public int actor2() {
y = 1;
return x;
}
}
}Вот как нужно интерпретировать результат теста:
-
(1, 1): Expect.ACCEPTABLE— мы прочитали обе записи. Это корректное поведение -
(0, 1), (1, 0): Expect.ACCEPTABLE— мы прочитали одно из значений слишком рано. Это корректное поведение -
(0, 0): Expect.ACCEPTABLE_INTERESTING— мы не увидели ни одной записи. Это случай instructions reordering/visibility
Запускаем тест на Intel Core i7-11700 (x86), Windows 10 x64, OpenJDK 17 (инструкцию по сборке и запуску тестов вы сможете найти в моем репозитории, который я приведу в конце статьи):
RESULT SAMPLES FREQ EXPECT DESCRIPTION
0, 0 2,188,517,311 18,91% Interesting Have not seen any write
0, 1 4,671,980,718 40,36% Acceptable Have seen one of the writes
1, 0 4,708,890,866 40,68% Acceptable Have seen one of the writes
1, 1 5,569,185 0,05% Acceptable Have seen both writesКак видите, в 18,91% случаев от общего количества прогонов мы не увидели ни одной записи. Стало страшно? Читайте далее, чтобы не попасть в такую ситуацию.
Введение: JMM
Теперь, получив контекст и поняв проблемы, можно начать говорить о JMM.
Мы поняли, что as-if-serial семантики недостаточно для многопоточных программ. Почему же не распространить as-if-serial гарантию на всю программу и ядра процессора? Ответ простой — это сильно ударило бы по производительности программ или процессора.
Одно из решений описанных проблем — это начать полагаться на строгие гарантии определенной микро-архитектуры процессора или имплементации компилятора/JVM. Но это очень хрупкое решение, которое заставляет думать о среде запуска программы, что препятствует кросс-платформенности. Например, ARM архитектура обладает гораздо более слабыми гарантиями по сравнению с x86: мы можем обнаружить намного больше багов в программе, если однажды стабильно работавшую на x86 программу запустим на ARM. Более того, обычно компиляторы не дают никаких гарантий, а вольны делать любые оптимизации.
В общем, нам нужна поддержа со стороны спецификации языка. Поэтому более надежное решение — это создание так называемой модели памяти (memory model), которая строго описывает какое выполнение программы является валидным. Модель памяти делает легальными многие оптимизации компилятора, JVM и процессора, но в то же время закрепляет условия, при которых программа будет вести себя корректно в многопоточной среде даже в присутствие оптимизаций. Таким образом, модель памяти:
- Разрешает выполнение различных оптимизаций компилятора, JVM или процессора
- Строго закрепляет условия, при которых программа считается правильно синхронизированной, и закрепляет поведение правильно синхронизированных программ
- Описывает отношение между высокоуровневым кодом и памятью
- Является trade-off между строгостью исполнения кода и возможными оптимизациями
Так вот, Java имеет свою модель памяти под названием Java Memory Model (JMM). По умолчанию JMM разрешает любые переупорядочивания и не гарантирует видимости изменений. Однако при выполнении определенных условий нам гарантируется порядок действий, консистентный с порядком в коде, а также видимость всех изменений. Таким образом, JMM позволяет нам писать программы, которые будут полностью корректно работать среди множества различных имплементаций JDK и микро-архитектур процессоров, в то же время сохраняя преимущества оптимизаций.
Введение: Memory Ordering
Для полного понимания модели памяти нам необходимо разобрать такое понятие как Memory Ordering.
Memory Ordering описывает наблюдаемый программой порядок, в котором происходят действия с памятью.
Смотрите: со стороны программы есть только действия записи/чтения и их порядок в коде. Также со стороны программы кажется, что мы имеем единую общую память, записи в которую становятся сразу видны другим тредам. Программа не подозревает ни о каких compiler reordering/instructions reordering/caching/register allocation и прочих оптимизациях под капотом. Если по какой-то причине мы наблюдаем результат, не консистентный с порядком в программе, то со стороны программы (высокоуровнево) это выглядит так, что действия c памятью просто были переупорядочены. Другими словами, порядок взаимодействия с памятью (memory order) может отличаться от порядка действий в коде (program order).
Для большего понимания давайте взглянем на уже знакомую нам программу с точки зрения Memory Ordering:
| Thread 0 | Thread 1 |
|---|---|
| x = 1 | y = 1 |
| r1 = y | r2 = x |
В случае результата выполнения (r1, r2) = (0, 0) мы можем просто сказать, что произошел StoreLoad memory reordering, то есть чтение произошло до записи. Не важно, по какой низкоуровневой причине это случилось, а важно лишь то, что в итоге со стороны программы действия с памятью были выполнены в неконсистентном порядке.
Таким образом, в многопоточной программе нам важно знать ответы на следующие вопросы:
- Как сохраняется порядок программы при работе с памятью?
- Валиден ли наблюдаемый memory order?
Дать ответ на каждый из вопросов — это и есть задача модели памяти. Java Memory Model разрешает все возможные переупорядочивания в отсутствие синхронизации, поэтому ответ на эти вопросы такой:
- Если программа не синхронизирована, то разрешены все переупорядочивания. Если программа правильно синхронизирована, запрещены все переупорядочивания
- Если программа не синхронизирована, то memory order, неконсистентный с program order, валиден с точки зрения JMM. Если программа правильно синхронизирована, то валиден только консистентный порядок
Ваша программа отрабатывает в одном из порядков, валидных с точки зрения JMM. Таким образом, если программа не правильно синхронизирована, не стоит удивляться некорретному результату выполнения. Ведь важно то, валиден ли результат выполнения с точки зрения модели памяти, а не то, валиден он или нет для вас как пользователя.
Однако то, что какой-то неконсистентный порядок валиден, еще не значит, что вы всегда получите некорректный результат, ведь и консистентный порядок возможен в отсутствие синхронизации. Понятно, что вы не хотите надеяться на волю случая, поэтому необходимо ограничить возможный сет порядков выполнения до только валидных. А для этого необходимо использовать предоставляемые моделью примитивы синхронизации, которые мы рассмотрим позднее.
В свою очередь, Memory Reordering — это высокоуровневое понятие, которое абстрагирует и обобщает низкоуровневые проблемы, которые мы рассматривали выше. Всего существует 4 типа memory reordering:
-
LoadLoad: переупорядочивание чтений с другими чтениями. Например, действия
r1, r2могут выполниться в порядкеr2, r1 -
LoadStore: переупорядочивание чтений с записями, идущими позже в порядке программы. Например, действия
r, wмогут выполниться в порядкеw, r -
StoreStore: переупорядочивание записей с другими записями. Например, действия
w1, w2могут выполниться в порядкеw2, w1 -
StoreLoad: переупорядочивание записей с чтениями, идущими позже в порядке программы. Например, действия
w, rмогут выполниться в порядкеr, w
В дальнейшем, когда я буду говорить "переупорядочивание" или "reordering", я буду иметь в виду именно Memory Reordering, если не сказано обратное.
Memory Model описывает, какие переупорядочивания возможны. В зависимости от строгости модели памяти подразделяются на следующие типы:
- Sequential Consistency: запрещены все переупорядочивания
- Relaxed Consistency: разрешены некоторые переупорядочивания
- Weak Consistency: разрешены все переупорядочивания
Модель памяти существует как на уровне языка, так и на уровне процессора, но они не связаны напрямую. Модель языка может предоставлять как более слабые, так и более строгие гарантии, чем модель процессора.
В частности, как уже было сказано выше, Java Memory Model не дает никаких гарантий, пока не использованы необходимые примитивы синхронизации. И напротив, посмотрите на главу Memory Ordering из Intel Software Developer’s Manual:
- Reads are not reordered with other reads [запрещает LoadLoad reordering]
- Writes are not reordered with older reads [запрещает LoadStore reordering]
- Writes to memory are not reordered with other writes [запрещает StoreStore reordering]
- Reads may be reordered with older writes to different locations but not with older writes to the same location [разрешает StoreLoad reordering]
Как видите, Intel разрешает только StoreLoad переупорядочивания, а все остальные запрещены. Да, модель памяти x86 достаточно строга, но есть и намного более слабые модели памяти процессоров — например, ARM разрешает все переупорядочивания.
Однако даже если вы пишите программу под x86, вам все равно необходимо считаться с более слабой Java Memory Model, так как последняя разрешает все переупорядочивания на уровне компилятора. Модель памяти языка — прежде всего.
Memory Ordering vs Instructions Ordering
Еще раз закрепим: Memory Ordering и Instructions Ordering — это не одно и то же. Инструкции могут переупорядочиваться под капотом как угодно, но их memory effect должен подчиняться некоторым Memory Ordering правилам, которые гарантируются (или не гарантируются) Memory Model. Наконец, memory ordering — это высокоуровневое понятие, созданное для простоты понимания работы с памятью.
Например, Intel запрещает LoadLoad переупорядочивания, но под капотом все равно делает спекулятивные чтения. Как это возможно? Дело в том, что процессор следит за тем, чтобы результат выполнения инструкций не нарушал memory ordering правил. Если какое-то правило нарушается, то процессор возвращается к более раннему состоянию: результат чтения отбрасывается, а записи не коммитятся в память. Например, из того же Intel Software Developer’s Manual:
The processor-ordering model described in this section is virtually identical to that used by the Pentium and Intel486 processors. The only enhancements in the Pentium 4, Intel Xeon, and P6 family processors are:
- Added support for speculative reads, while still adhering to the ordering principles above.
Введение: Sequential Consistency
Sequential Consistency Model (SC) — это очень строгая модель памяти, которая гарантирует отсутствие переупорядочиваний.
Интуитивно SC можно понять очень просто: возьмите действия тредов, как они идут в порядке программы, и просто выполните их последовательно, возможно переключаясь между тредами.
Формальное определение SC также достаточно простое:
[Lamport, 1979 — How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs] ...the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
Давайте разберем SC на примере. Возьмем все тот же Dekker lock, который мы рассматривали выше:
| Thread 0 | Thread 1 |
|---|---|
| x = 1 | y = 1 |
| r1 = y | r2 = x |
В SC модели могут быть следующие memory order и никакие больше:
write(x, 1) -> write(y, 1) -> read(y):1 -> read(x):1
write(x, 1) -> write(y, 1) -> read(x):1 -> read(y):1
write(x, 1) -> read(y):0 -> write(y, 1) -> read(x):1
write(y, 1) -> write(x, 1) -> read(x):1 -> read(y):1
write(y, 1) -> write(x, 1) -> read(y):1 -> read(x):1
write(y, 1) -> read(x):0 -> write(x, 1) -> read(y):1Назовем такие порядки "sequentially consistent memory orders".
А вот такой memory order, где присутствует StoreLoad переупорядочивание и которое дает нам результат (r1, r2) = (0, 0), запрещен в SC:
read(y):0 -> read(x):0 -> write(x, 1) -> write(y, 1)Введение: Sequential Consistency-Data Race Free
Отлично, все это звучит здорово, но как же нам получить такую модель памяти? Ведь как мы уже поняли, JMM — это слабая модель памяти, которая не гарантирует консистентного порядка памяти.
Однако я уже упоминал выше, что при соблюдении некоторых условий наша программа будет считаться правильно синхронизированной и всегда работать корректно. Так вот, Java Memory Model — это Sequential Consistency-Data Race Free (SC-DRF) модель: нам предоставляется sequential consistency, но только в том случае, если мы избавимся от всех data race в программе — про это мы еще поговорим далее.
Sequential Consistency: Why?
Вы наверное сейчас сидите и думаете: абстракция над абстракцией и абстракцией погоняет… Memory model, memory order, sequential consistency… Ну зачем, зачем же все эти абстракции? Давайте вместе разбираться.
Посмотрим на определение Sequential Consistency еще раз:
...the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
Обратите внимание на выделенное в определении "is the same as if" — это очень важная деталь. Это означает, что инструкции под капотом не должны выполняться именно в sequential порядке. Важно лишь то, чтобы результат выполнения был не отличим от одного из таких порядков.
Хорошо, а нам то что с этого? А нам ничего. Зато разработчикам JMM такое определение позволяет делать любые оптимизации под капотом, пока они не приводят к результату, который не возможен в SC выполнении.
Давайте разберем подробнее. Снова возвращаемся к нашей программе:
| Thread 0 | Thread 1 |
|---|---|
| x = 1 | y = 1 |
| r1 = y | r2 = x |
Снова перечисляем все возможные sequentially consistent порядки, где каждому выполнению запишем конечный результат:
write(x, 1) -> write(y, 1) -> read(y):1 -> read(x):1 // result: (x,y)=(1, 1)
write(x, 1) -> write(y, 1) -> read(x):1 -> read(y):1 // result: (x,y)=(1, 1)
write(x, 1) -> read(y):0 -> write(y, 1) -> read(x):1 // result: (x,y)=(1, 0)
write(y, 1) -> write(x, 1) -> read(x):1 -> read(y):1 // result: (x,y)=(1, 1)
write(y, 1) -> write(x, 1) -> read(y):1 -> read(x):1 // result: (x,y)=(1, 1)
write(y, 1) -> read(x):0 -> write(x, 1) -> read(y):1 // result: (x,y)=(0, 1)В итоге мы получаем следующий сет возможных результатов: (0, 1), (1, 0), (1, 1). Назовем такие результаты "sequentially consistent results".
Так вот, любая имплементация нашей программы, которая гарантированно приводит к одному из sequentially consistent результатов, является валидной вне зависимости от того, какие оптимизации были сделаны. Главное то, чтобы эти оптимизации не могли привести к sequentially inconsistent результату.
Например, в SC модели памяти компилятор не может переставить в нашей программе чтение с записью, потому что такая имплементация может привести к результату (r1, r2)=(0, 0):
| Thread 0 | Thread 1 |
|---|---|
| r1 = y | y = 1 |
| x = 1 | r2 = x |
Ведь порядок выполнения инструкций мог быть таким:
| Thread 0 | Thread 1 |
|---|---|
| r1 = y // 0 | |
| y = 1 | |
| r2 = x // 0 | |
| x = 1 |
А поэтому компилятору запрещается делать такую оптимизацию, ведь результат (r1,r2)=(0, 0) не входит в набор sequentially consistent результатов, который мы определили выше.
А вот, например, какую оптимизацию компилятор может сделать:
| Thread 0 | Thread 1 |
|---|---|
| r1 = 1 | r2 = 1 |
Компилятор полностью убрал записи и просто заинлайнил значения в чтения. Нарушает ли это Sequential Consistency? Совсем нет, ведь эта имплементация всегда приводит нас к результату (r1, r2)=(1, 1), который является sequentially consistent результатом. То есть, если существует как минимум один sequentially consistent порядок, который дает такой результат, то такая оптимизация валидна. Конечно, это очень и наивный простой пример. Но расширьте обзор до всей программы и всех умных оптимизаций компилятора и JVM, и вы получите высоко-производительную программу, которая все равно выполняется полностью корректно.
Таким образом, представить себе работу SC модели памяти можно следующим образом:
- Модель памяти "смотрит" на оригинальную программу и исходя из порядка действий в программе "просчитывает" сет всех возможных sequentially consistent порядков и их результатов
- С учетом получившегося сета результатов модель памяти разрешает делать любые оптимизации, пока они приводят к одному из sequentially consistent результатов, и запрещает делать такие оптимизации, которые могут привести к sequentially inconsistent результату
Что получается в итоге? А в итоге модель памяти, memory order, sequential consistency — это все абстракция между нами, пользователями JMM, и собственно самой имплементацией JMM. Но кроме этого, данные абстракции позволяют нам рассуждать о корректности нашей программы без вдавания в низкоуровневые подробности. В теории, вы могли бы вообще не знать о низкоуровневых оптимизациях и проблемах и все еще писать корректные программы, если бы правильно пользовались механизмами синхронизации, которые предоставляет JMM. Однако, вы читаете эту статью не просто так, поэтому мы все с вами склоняемся к тому мнению, что иметь полную картину все таки надо.
So, here's the deal: вы избавляетесь от data race в программе и получаете программу, результат которой не отличим от одного из sequentially consistent порядков, а разработчики JMM получают возможность делать любые оптимизации под капотом, пока они приводят к валидному результату.
Введение: data race
Data race возникает тогда, когда с shared данными работает одновременно два или больше тредов, где как минимум один из них пишет и их действия не синхронизированы. Для действий в гонке не гарантируется никакого консистентного memory order, поэтому не стоит удивляться неожиданным результатам.
Data race в рамках JMM — это ключевая вещь, которая позволяет нам формально добиться sequential consistency: если мы избавимся от всех data race, то получим sequentially consistent выполнение.
Давайте пройдемся по формальным определениям в спеке.
Для начала взглянем на определение data race:
-
JLS §17.4.1. Shared Variables:
Memory that can be shared between threads is called shared memory or heap memory.
All instance fields,staticfields, and array elements are stored in heap memory. In this chapter, we use the term variable to refer to both fields and array elements.
Two accesses to (reads of or writes to) the same variable are said to be conflicting if at least one of the accesses is a write.
-
JLS §17.4.5. Happens-before Order:
When a program contains two conflicting accesses (§17.4.1) that are not ordered by a happens-before relationship, it is said to contain a data race.
А теперь найдем ответ на следующий вопрос: как же нам добиться полной корректности многопоточной программы? Смотрим на JLS §17.4.3. Programs and Program Order:
A set of actions is sequentially consistent if all actions occur in a total order (the execution order) that is consistent with program order, and furthermore, each read r of a variable v sees the value written by the write w to v such that:
- w comes before r in the execution order, and
- there is no other write w' such that w comes before w' and w' comes before r in the execution order.
Sequential consistency is a very strong guarantee that is made about visibility and ordering in an execution of a program. Within a sequentially consistent execution, there is a total order over all individual actions (such as reads and writes) which is consistent with the order of the program, and each individual action is atomic and is immediately visible to every thread.
If a program has no data races, then all executions of the program will appear to be sequentially consistent.
Вот и то самое SC-DRF, про которое мы говорили выше: чтобы добиться sequential consistency, необходимо избавиться от всех data race в программе. Все это звучит просто, но не так просто это сделать.
Как вы уже заметили, JMM определяет понятие data race через так называемое happens-before. А это значит, что для написания корректных многопоточных программ нам придется изучить и понять, что такое happens-before. Обещаю: это последнее, что нам придется изучить в этих дебрях абстракций.
Ну что ж, поехали!
JMM: Happens-before
Happens-before определяется как отношение между двумя действиями:
- Пусть есть поток
T1и потокT2(необязательно отличающийся от потокаT1), и действияxиy, выполняемые в потокахT1иT2соответственно - Если
xhappens-beforey, то во время выполненияyтредуT2должны быть видны все изменения, сделанные вxтредомT1
JLS (§17.4.5. Happens-before Order):
Two actions can be ordered by a happens-before relationship. If one action happens-before another, then the first is visible to and ordered before the second.
Happens-Before — это то, с помощью чего мы добьемся Sequential Consistency. Смотрите:
- Если мы свяжем conflicting доступ к shared переменной с помощью happens-before, то избавимся от data race
- Если мы избавимся от data race, то получим Sequential Consistency
- Если мы получим Sequential Consistency, то наша программа всегда будет выдавать консистентный с порядком в программе результат
Давайте сразу проясним один момент: нет, happens-before не означает, что инструкции будут действительно выполняться в таком порядке. Если переупорядочивание инструкций все равно приводит к консистентному результату, то такое переупорядочивание инструкций не запрещено. JLS:
It should be noted that the presence of a happens-before relationship between two actions does not necessarily imply that they have to take place in that order in an implementation. If the reordering produces results consistent with a legal execution, it is not illegal.
Далее мы рассмотрим все действия, для которых JMM гарантирует отношение happens-before.
[Happens-Before] Same thread actions
Если действие x идет перед y в коде программы и эти действия происходят в одном и том же треде, то x happens-before y:
Ifxandyare actions of the same thread andxcomes beforeyin program order, thenhb(x, y).
Это формальное определение as-if-serial семантики, которую я уже упоминал в начале статьи: если действие A идет перед действием B в порядке программы, то B гарантированно увидит все изменения, которые должны быть сделаны в A.
Еще раз закрепим: happens-before не означает, что инструкции будут действительно выполняться в таком порядке под капотом. Посмотрите на первый тред из нашего примера:
| Thread 0 |
|---|
| x = 1 |
| r1 = y |
Для этого треда гарантируется, что x = 1 happens-before r1 = y. Однако эти действия никак не связаны: запись в x не влияет на чтение y. Другими словами, на чтении y нам не нужно видеть изменений, сделанных при записи в x. Поэтому даже если инструкции будут переупорядочены, то happens-before между этими действиями не будет нарушено.
Сравните:
| Thread 0' |
|---|
| x = 1 |
| y = x + 1 |
В такой программе действия связаны — на записи в y нам необходимо наблюдать запись в x. Именно в данном случае happens-before запрещает переупорядочивание инструкций, гарантируя, что при записи в y мы увидим результат записи в x.
[Happens-Before] Monitor lock
Освобождение монитора happens-before каждый последующий захват того же самого монитора.
An unlock action on monitormhappens-before all subsequent lock actions onm
[Happens-Before] Volatile
Запись в volatile переменную happens-before каждое последующее чтение той же самой переменной.
A write to a volatile variablevhappens-before all subsequent reads ofvby any thread
[Happens-Before] Final thread action
Финальное действие в треде T1 happens-before любое действие в треде T2, которое обнаруживает, что тред T1 завершен.
The final action in a threadT1happens-before any action in another threadT2that detects thatT1has terminated.
Это приводит нас к таким happens-before:
- Финальное действие в
T1happens-before завершение вызоваT1.join()вT2 - Финальное действие в
T1happens-before завершение вызоваT1.isAlive()вT2(если вызов возвращаетfalse)
[Happens-before] Thread start action
Действие запуска треда (Thread.start()) happens-before первое действием в этом треде.
An action that starts a thread happens-before the first action in the thread it starts.
[Happens-before] Thread interrupt action
Если тред T1 прерывает тред T2, то интеррапт happens-before обнаружение интеррапта. Обнаружить интеррапт можно или по исключению InterruptedException, или с помощью вызова Thread.interrupted/Thread.isInterrupted.
If threadT1interrupts threadT2, the interrupt byT1happens-before any point where any other thread (includingT2) determines thatT2has been interrupted (by having anInterruptedExceptionthrown or by invokingThread.interruptedorThread.isInterrupted).
[Happens-Before] Default initialization
Дефолтная инициализация (0, false или null) при создании переменной happens-before любое другое действие в треде.
The write of the default value (zero,false, ornull) to each variable happens-before the first action in every thread.
Although it may seem a little strange to write a default value to a variable before the object containing the variable is allocated, conceptually every object is created at the start of the program with its default initialized values.
Happens-before transitivity
Важно отметить, что отношение happens-before является транзитивным. То есть, если hb(x,y) и hb(y,z), то hb(x,z).
Это приводит нас к одному очень важному и интересному наблюдению. Мы знаем, что два последовательных действия в одном и том же треде связаны с помощью happens-before (same thread actions). Тогда если действие A в одном треде связано отношением happens-before с действием B в другом треде, то благодаря транзитивности второму треду во время и после выполнения действия B будут видны все изменения, сделанные первым тредом до и во время выполнения действия A.
Еще раз: если есть последовательные действия [A1, A2] в первом треде, последовательные действия [B1, B2] во втором треде, и hb(A2, B1), то hb(A1, B1), hb(A1, B2) и hb(A2, B2), потому что:
- Для последовательных действий в треде гарантируется happens-before:
hb(A1, A2),hb(B1, B2) - happens-before транзитивен: если
hb(A1, A2)(same thread),hb(A2, B1)(hb),hb(B1, B2)(same thread), тоhb(A1, B1),hb(A1, B2)иhb(A2, B2)
Вот как мы можем применить это знание:
- Не только освобождение монитора, но и все действия до освобождения будут видны другому треду после захвата этого же монитора
- Не только запись в volatile поле, но и все действия до записи будут видны другому треду после чтения этого же поля
- Не только финальное действие, но и все предыдущие действия треда T1 будут видны другому треду после завершения
T1.join() - … не будем продолжать — идея понятна
Давайте с учетом этой информации запишем более полное определение happens-before:
- Пусть есть поток
T1и потокT2(необязательно отличающийся от потокаT1), и действияxиy, выполняющиеся в потокахT1иT2соответственно - Если
xhappens-beforey, то во время и после выполненияyтредуT2должны быть видны все изменения, сделанные до и во время выполненияxтредомT1
Happens-before: Practice
Мы уже на полпути к написанию корректных многопоточных программ — теперь осталось только применить полученные значения на практике. За основу для дальнейших примеров возьмем следующую нерабочую программу:
public class MemoryReorderingExample {
private int x;
private boolean initialized = false;
public void writer() {
x = 5; /* W1 */
initialized = true; /* W2 */
}
public void reader() {
boolean r1 = initialized; /* R1 */
if (r1) {
int r2 = x; /* R2, may read default value (0) */
}
}
}Можно подумать, что если мы прочитали значение true на R1, то прочитаем и значение 5 на R2, так как в порядке программы запись в x идет перед записью в initialized. Но на самом деле мы можем наблюдать значение по умолчанию (0) при чтении x по следующим причинам:
- Instructions reordering (1/2) — записи W1 и W2 были переставлены местами
- Instructions reordering (2/2) — чтения R1 и R2 были переставлены местами
-
Visibility — запись в
xне пропагирована другим ядрам на момент чтения
Другими словами, с точки зрения программы мы говорим, что произошел StoreStore или LoadLoad memory reordering.
Давайте лично убедимся в том, что такие переупорядочивания возможны, написав jcstress тест:
@JCStressTest
@Description("Triggers memory reordering")
@Outcome(id = "-1", expect = Expect.ACCEPTABLE, desc = "Not initialized yet")
@Outcome(id = "5", expect = Expect.ACCEPTABLE, desc = "Returned correct value")
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "Initialized but returned default value")
public class JmmReorderingPlainTest {
@Actor
public final void actor1(DataHolder dataHolder) {
dataHolder.writer();
}
@Actor
public final void actor2(DataHolder dataHolder, I_Result r) {
r.r1 = dataHolder.reader();
}
@State
public static class DataHolder {
private int x;
private boolean initialized = false;
public void writer() {
x = 5;
initialized = true;
}
public int reader() {
if (initialized) {
return x;
}
return -1; // return mock value if not initialized
}
}
}Запускаем тест на Intel Core i7-11700 (x86), Windows 10 x64, OpenJDK 17 и получаем следующие результаты:
Results across all configurations:
RESULT SAMPLES FREQ EXPECT DESCRIPTION
-1 5,004,050,680 38,73% Acceptable Not initialized yet
0 168,651 <0,01% Interesting Initialized but returned default value
5 7,916,756,029 61,27% Acceptable Returned correct valueКак видите, в <0,01% случаев мы получили неконсистентный Memory Order.
Далее мы доведем эту программу до полной корректности, используя happens-before.
Monitor lock
Monitor lock (Intrinsic lock) не только предоставляет happens-before между освобождением и взятием лока, но также является и мьютексом, который позволяет обеспечить эксклюзивный доступ к критической секции (критическая секция — это секция, в которой ведется работа с shared данными). Каждый объект в Java содержит внутри себя такой лок (отсюда и название intrinsic), но его нельзя использовать напрямую — чтобы воспользоваться им, необходимо применить keyword synchronized.
Вот как мы можем исправить приведенную выше программу с помощью монитора:
public class SynchronizedHappensBefore {
private final Object lock = new Object();
private int x;
private boolean initialized = false;
public void writer() {
synchronized (lock) {
x = 5; /* W1 */
initialized = true; /* W2 */
} /* RELEASE */
}
public synchronized void reader() {
synchronized (lock) { /* ACQUIRE */
boolean r1 = initialized; /* R1 */
if (r1) {
int r2 = x; /* R2, guaranteed to see 5 */
}
}
}
}В данном примере мы используем монитор объекта lock, свойство happens-before которого гарантирует, что после получения монитора reader увидит все изменения, которые сделал writer до освобождения монитора. Следите внимательно: если hb(W1, W2) (same thread), hb(W2, RELEASE) (same thread), hb(RELEASE, ACQUIRE) (monitor lock), hb(ACQUIRE, R1) (same thread), hb(R1, R2) (same thread), то hb(W2, R1) и hb(W1, R2) (transitivity).
Таким образом, если writer освободил монитор и мы захватили его после в reader, то благодаря happens-before нам гарантируется видимость всех действий, которые идут перед освобождением монитора в порядке программы.
Volatile
Volatile предоставляет happens-before гарантию между записью и чтением из volatile переменной. Семантика volatile отличается от монитора только тем, что не устанавливает exclusive access.
Вот так с помощью volatile мы исправляем ту же самую программу:
public class VolatileHappensBefore {
private int x;
private volatile boolean initialized;
public void writer() {
x = 5; /* W1 */
initialized = true; /* W2 */
}
public void reader() {
boolean r1 = initialized; /* R1 */
if (r1) {
int r2 = x; /* R2, guaranteed to see 5 */
}
}
}В данном примере мы синхронизируемся на volatile поле initialized, свойство happens-before которого гарантирует, что мы увидим все изменения, которые сделал writer до записи в volatile переменную. Следите внимательно: если hb(W1, W2) (same thread), hb(W2, R1) (volatile), hb(R1, R2) (same thread), то hb(W1, R2) (transitivity).
Таким образом, если мы прочитали true на R1, то нам гарантируется видимость всех действий, которые идут перед записью в volatile переменную в коде программы.
Как видите, пользоваться happens-before достаточно просто. Это все, что вам нужно, чтобы писать свободные от data race и корректные с точки зрения Memory Ordering программы.
Cache Coherence
В самом начале статьи я уже затрагивал тему Cache Coherence, а теперь разберемся в ней подробнее.
Перед тем как идти дальше, рассмотрим устройство кэша на базовом уровне:
- Процессор никогда не работает с памятью напрямую — все операции чтения и записи проходят через кэш. Когда процессор хочет загрузить значение из памяти, то он обращается в кэш. Если значения там нет, то кэш сам ответственнен за выгрузку значения из памяти с последующим сохранением в кэше. Когда процессор хочет записать значение в память, то он записывает значение в кэш, который в свою очередь ответственен за сброс значения в память
- Кэш состоит из множества "линий" (cache line) фиксированного размера, в которые кладутся значения из памяти. Размер линий варьируется от 16 до 256 байт в зависимости от архитектуры процессора. Кэш сам знает, как мапить адрес линии кэша в адрес памяти
- Кэш имеет фиксированный размер, поэтому может хранить ограниченное количество записей. Например, если размер кэша 64 KB, а размер линии кэша 64 байт, то всего кэш может содержать 1024 линии. Поэтому, если при выгрузке нового значения места в кэше не хватает, то из кэша вымещается одно из значений
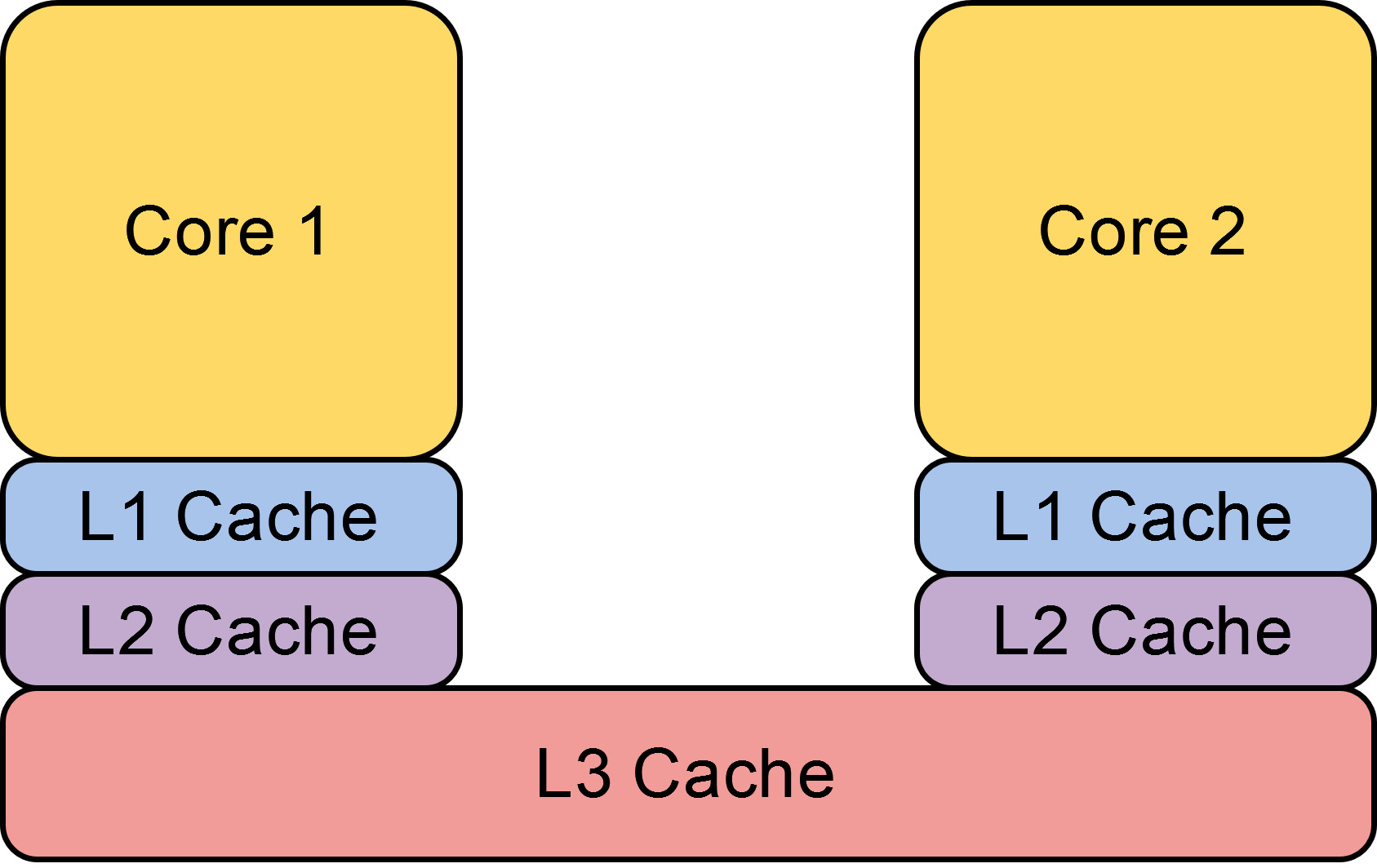
- Большинство современных архитектур процессоров имеют несколько уровней кэша: обычно это L1, L2, и L3. Верхние уровни кэша (L1, L2) являются локальными — каждое ядро процессора имеет собственный, отдельный от других ядер кэш. Кэш на самом нижнем уровне (L3) является общим и шарится между всеми ядрами
- Доступ к каждому последующему уровню кэша стоит дороже, чем к предыдущему. Например, доступ к L1 может стоить 3 цикла, L2 — 12 циклов, а к L3 — 38 циклов
- Каждый последующий кэш имеет больший размер, чем предыдущий. Например, L1 может иметь размер 80 KB, L2 — 1.25 MB, а L3 — 24 MB
Из-за того, что ядра имеют собственный локальный кэш, возникает потенциальная проблема чтения неактуальных значений. Например, пусть два ядра прочитали одно и то же значение из памяти и сохранили в свой локальный кэш. Затем первое ядро записывает новое значение в свой локальный кэш, но другое ядро не видит этого изменения и продолжает читать устаревшее значение. Как итог, данные среди локальных кэшей не консистентны. Если бы в процессоре существовал только общий кэш, то проблемы чтения неактуальных значений просто не существовало бы: так как все записи и чтения проходят через кэш, а не идут напрямую в память, то общий кэш по сути был бы master копией памяти, где всегда лежали бы актуальные значения. Но это сильно ударило бы по производительности процессора, так как кэш может обрабатывать только один цикл единовременно, а значит ядра простаивали бы в очереди. Более того, локальный кэш распаян физически ближе к ядру, поэтому доступ к нему стоит дешевле. Именно поэтому и необходим локальный кэш, чтобы каждое ядро могло эффективно работать с кэшем независимо от других ядер.
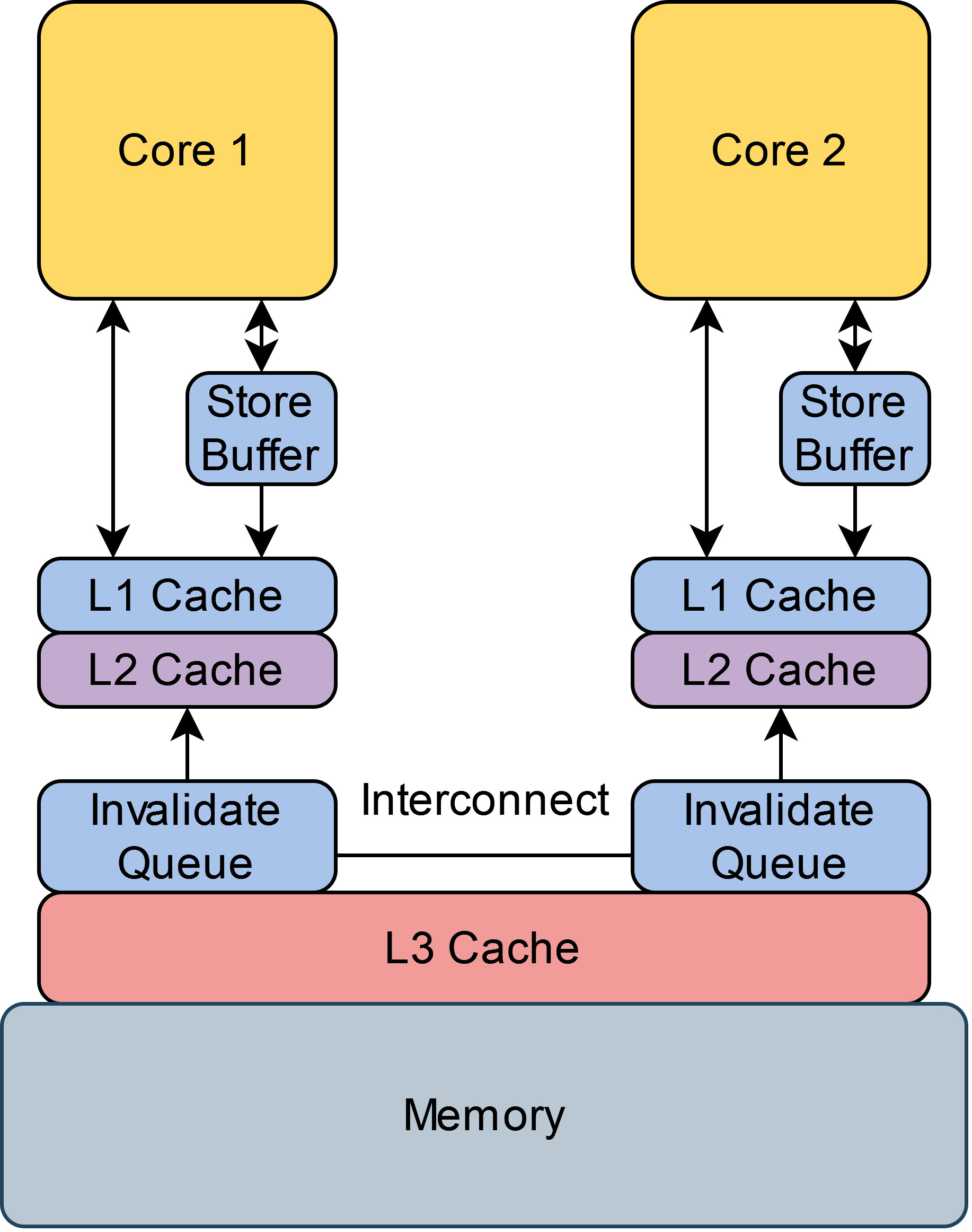
На самом деле, процессоры умеют поддерживать консистентность данных среди локальных кэшей так, что любое из ядер всегда читает актуальное значение одного и того же адреса памяти.
Cache Coherence (когерентность кэша) — это механизм процессора, гарантирующий, что любое ядро всегда читает самое актуальное значение из кэша. Данным механизмом обладают многие современные архитектуры процессоров в той или иной имплементации. Самый популярный из протоколов — это MESI протокол и его производные. Например, Intel использует MESIF, а AMD — MOESI протокол.
В MESI протоколе линия кэша может находиться в одном из следующих состояний:
- Invalid — линия кэша устарела (содержит неактуальные значения), поэтому из нее нельзя читать
- Shared — линия кэша актуальна и эквивалентна памяти. Процессор может только читать из такой линии кэша, но не писать в нее. Если несколько ядер читают один и тот же адрес памяти, то эта линия кэша будет реплицирована сразу в несколько локальных кэшей, отсюда и название "shared"
- Exclusive — линия кэша актуальна и эквивалентна памяти. Однако как только одно из ядер процессора переводит линию кэша в это состояние, никакое другое ядро не может держать эту линию кэша у себя, отсюда и название "exclusive". Когда значение из памяти только первые загружается в кэш, то линия кэша устанавливается именно в это состояние. Если одно из ядер процессора хочет перевести линию кэша из shared в exclusive состояние, то все остальные ядра должны пометить свою копию как invalid
- Modified — линия кэша была изменена (dirty), то есть ядро записало в нее новое значение. Именно в это состояние переходит exclusive линия кэша после записи в нее. Аналогично, только одно из ядер процессора может держать линию кэша в Modified состоянии. Если линия вымещается из кэша, то кэш ответственен за то, чтобы записать новое значение в память перед выгрузкой
Когда одно из ядер процессора хочет изменить линию кэша, то оно должно установить exclusive доступ к ней. Для этого ядро посылает всем остальным ядрам сообщение о том, что указанную линию кэша необходимо пометить как invalid в их локальном кэше. Только после того, как ядра обработают запрос, пометив свою копию как invalid, ядро сможет записать новое значение вместе с этим помечая линию кэша как modified. Таким образом, при записи только одно ядро может удерживать значение в локальном кэше, а значит неконсистентность данных просто невозможна.
Когда любое ядро хочет прочитать какой-нибудь адрес в памяти, то алгоритм действий выглядит так:
- Ядро обращается в L1 кэш и проверяет, присутствует ли там искомое значение. Если линия кэша присутствует и находится в состоянии Shared, Exclusive или Modified, то происходит ее чтение. Если значение в локальном кэше не обнаружено (или линия кэша находится в состоянии Invalid), то говорится, что произошел (local) "cache miss"
- По специальной общей шине всем остальным ядрам передается запрос на чтение значения. Все остальные ядра видят этот запрос, и если одно из ядер содержит искомое значение в состоянии Shared, Exclusive или Modified, то оно отдает актуальное значение в ответ.
- Если линия кэша была установлена в Modified состояние, то перед тем как отдать значение, измененное значение сбрасывается в память, а затем линия кэша переводится в Shared состояние
- Если значение не обнаружено ни в одном из локальных кэшей, то происходит чтение из памяти
- Вне зависимости от того, где мы нашли значение, читающее ядро сохраняет данные в свой локальный кэш, помечая линию кэша как shared
Это очень упрощенное описание работы кэша — я опустил многие детали, но надеюсь, что примерная картина вам понятна. Скажу сразу, что я не претендую на полную корректность вышенаписанного: где-то я мог и соврать, ибо не являюсь специалистом в такой низкоуровневой теме как процессоры. Более того, многие моменты могут отличаться в зависимости от микроархитектуры процессора и используемого Cache Coherence протокола. В конце статьи я приведу ссылки на другие полезные источники, где вы сможете узнать подробнее о работе кэша.
Таким образом, как только значение попадает в локальный кэш, оно сразу же становится видно другим ядрам.
Теперь наверняка у вас возник закономерный вопрос: так что же, значит visibility проблемы на уровне процессора не существует? На самом деле, не все так просто.
Invalidation Queue
Когда ядро получает запрос на инвалидацию записи в кэше, он может быть обработан не сразу, а поставиться в очередь Invalidation Queue (IQ). Эта оптимизация необходима по следующим причинам: во-первых, ядро может быть занято другой работой, и во-вторых, мы хотим, чтобы при большом количестве запросов ядро не заблокировалось на долгое время в их обработке, а обработало все постепенно. Таким образом, можно сказать, что invalidate запросы являются асинхронными
Проблема в том, что мы рискуем не прочитать самое актуальное значение просто потому, что запрос в invalidation queue еще не был обработан, а в кэше лежало еще не инвалидированное, но уже устаревшее значение.
Например:
| CORE 0 | CORE 1 |
|---|---|
| Cached (shared): x(5) | Cached (shared): x(5) |
| send invalidate request | |
| accept invalidate request, put in IQ and respond with acknowledgement | |
| Cached (exclusive): x(5) | Cached (shared): x(5) |
| x = 10 | |
| r = x / 5 / | |
| handle invalidate request / too late! / |
Как видите, мы прочитали устаревшее значение, хотя запрос на invalidate уже пришел.
Store Buffer
В некоторых микро-архитектурах (как x86) каждое ядро имеет локальный FIFO Store Buffer (SB, write buffer), который является прослойкой между CPU и кэшем. В этот буфер ядро кладет все записи, которые будут ожидать там сброса в локальный кэш до тех пор, пока все остальные ядра не инвалидируют эту запись в своем кэше и не пришлют acknowledgement. Эта оптимизация требуется для того, чтобы не задерживать работу пишущего ядра, пока остальные ядра обрабатывают запрос на инвалидацию. При чтении ядро сперва смотрит в свой SB перед тем, как идти в локальный кэш, чтобы избежать чтения неактуальных значений и таким образом поддержать as-if-serial гарантию внутри одного ядра
Проблема в том, что другие ядра не увидят новой записи, пока пишущее ядро не сбросит запись из SB в локальный кэш, так как SB — это часть ядра, но не кэша. Другими словами, Cache Coherence механизм не распространяется на Store Buffer. Соответственно, некоторый промежуток времени пишущее ядро будет оперировать актуальным значением, но все остальные — устаревшим.
Например:
| CORE 0 | CORE 1 |
|---|---|
| Cached (exclusive): x(0) | Cached: none |
| x = 5 / put in SB / | |
| r2 = x / 5, read from SB / | |
| r1 = x / 0 / | |
| flushed from sb to cache | |
| r3 = x / 5, read from local cache / |
Как видите, CORE 0 произвело запись в x, а затем CORE 1 пытается прочитать эту переменную. Однако CORE 1 не найдет актуального значения ни в памяти, ни в кэше CORE 0, так как эта запись все еще лежит в Store Buffer. Соответственно, CORE 1 увидит 0 на чтении r1, хотя CORE 0 оперирует актуальным значением на r2, чем нарушается консистентность данных.
Итак, ядра действительно всегда видят актуальное значение, но только кроме короткого временного окна после записи. Другими словами, нам гарантируется eventual visibility изменений.
В заключение приведу полное устройство кэша:
Eventual Visibility
Можно наивно предположить, что благодаря Cache Coherence нам гарантируется eventual visibility и на уровне Java для обычных записей и чтений, то есть не связанных happens-before. Однако, это не правда, так как мы работаем на уровне языка, а не процессора. Компилятор может оптимизировать код так, что запись никогда не станет видна другому треду. Яркий пример — это такой busy wait, где в бесконечном цикле проверяется значение shared переменной.
JCStress уже имеет готовый тест для этого случая — BasicJMM_04_Progress#PlainSpin:
@JCStressTest(Mode.Termination)
@Outcome(id = "TERMINATED", expect = ACCEPTABLE, desc = "Gracefully finished")
@Outcome(id = "STALE", expect = ACCEPTABLE_INTERESTING, desc = "Test is stuck")
@State
public static class PlainSpin {
boolean ready;
@Actor
public void actor1() {
while (!ready); // spin
}
@Signal
public void signal() {
ready = true;
}
}Смотрим на результаты запуска теста:
RESULT SAMPLES FREQ EXPECT DESCRIPTION
STALE 4 50.00% Interesting Test is stuck
TERMINATED 4 50.00% Acceptable Gracefully finishedКак видите, в половине случаев тред завис навсегда. Это произошло по той причине, что компилятор оптимизировал цикл while (!ready) в while(true). Компилятор свободен это делать, так как переменная не изменяется ни до, ни внутри цикла, а также не связана отношением happens-before с действиями в других тредах.
Исправить этот пример можно пометив переменную как volatile — только в этом случае нам гарантируется eventual visibility изменений.
Таким образом, пока мы работаем с обычными записями и чтениями, не связанными отношением happens-before, нам не гарантируется видимость изменений, сделанных из других тредов.
Memory Barriers
Процессор может переупорядочивать выполняемые им инструкции, даже если на уровне компилятора мы обеспечили необходимый порядок. Хотя процессор делает только такие переупорядочивания, которые не меняют итогового результата, но это гарантируется только для единственного ядра в изоляции, поэтому переупорядочивание может повлиять на другие ядра. Более того, все еще существует проблема видимости изменений, которую мы обсудили выше. Именно поэтому JMM ответственна и за синхронизацию на уровне процессора, ведь необходимо согласовать и исполняемые процессором инструкции, чтобы обеспечить happens-before.
Для решения этих проблем Java использует готовые низкоуровневые механизмы синхронизации под названием "memory barrier", предоставляемые самим процессором. Задача барьеров памяти — запретить (memory) переупорядочивания, которые обычно разрешены моделью памяти процессора. Таким образом, точно так же как мы используем примитивы синхронизации volatile/synchronized в высокоуровневом коде, сама Java под капотом тоже использует похожие низкоуровневые примитивы синхронизации.
Memory barrier (memory fence, барьер памяти) — это тип процессорной инструкции, которая заставляет процессор гарантировать memory ordering для инструкций, работающих с памятью.
Всего существует 4 типа барьеров памяти — они напрямую матчатся в возможные memory reordering и запрещают каждый из них:
-
LoadLoad
- дает гарантию, что все load операции до барьера произойдут перед load операциями после барьера
-
LoadStore
- дает гарантию, что все load операции до барьера произойдут перед store операциями после барьера
-
StoreStore
- дает гарантию, что все store операции до барьера произойдут перед store операциями после барьера. Таким образом, все store операции до барьера будут тоже видны, если станет видна любая store операция после барьера
-
StoreLoad
- дает гарантию, что все store операции до барьера произойдут перед load операциями после барьера. Таким образом, все store операции до барьера станут видны другим ядрам перед тем, как произойдет любая load операция после барьера
То, как имплементированы барьеры — это дело процессора. К примеру, они могут запрещать переупорядочивание инструкций и ожидать полной обработки Store Buffer/Invalidation Queue, но мы не знаем точной имплементации. На самом деле, знание таких деталей и не нужно — мы просто мыслим в терминах Memory Ordering и тех гарантий порядка, которые дают нам барьеры.
Соответствующие процессорные инструкции или отображаются 1-в-1 в эти типы, или же объединяют в себе сразу несколько типов барьеров. Все процессоры имеют как минимум одну full memory barrier инструкцию, которая объединяет в себя сразу все типы барьеров, запрещая memory reordering как load, так и store инструкций вокруг барьера. Например, на x86 мы имеем mfence и lock prefix, которые являются full memory barrier. Однако процессоры могут предоставлять и более дешевые, гранулярные барьеры памяти.
Обычно Load- и Store- барьеры используются в паре: Store барьер гарантирует, что записи будут видны другому ядру, а Load барьер гарантирует, что чтения будут выполнены в необходимом порядке.
Например, вот как мы можем исправить уже знакомый нам по вступлению пример с помощью барьера:
| Thread 0 | Thread 1 |
|---|---|
| x = 1 | y = 1 |
| [StoreLoad] | [StoreLoad] |
| r1 = y | r2 = x |
Если мы поставим StoreLoad барьер после записи, то процессору запрещается переупорядочивать store инструкции до барьера с load инструкциями после барьера. В такой программе мы можем быть точно уверены, что не получим результата (r1, r2) = (0, 0). Если рассматривать этот пример со стороны Java, то нам достаточно было бы пометить обе переменные как volatile.
Давайте лично убедимся в наличии барьеров под капотом Java на примере volatile. В JSR-133 Cookbook, неофициальном гайдлайне по имплементации JMM за авторством Doug Lea, сказано:
- Issue a
StoreStorebarrier before each volatile store.- Issue a
StoreLoadbarrier after each volatile store.- Issue
LoadLoadandLoadStorebarriers after each volatile load.
Пусть есть такая простая программа с использованием volatile:
public class VolatileMemoryBarrierJIT {
private static int field1;
private volatile static int field2;
private static void write(int i) {
field1 = i << 1;
/* StoreStore */
field2 = i << 2;
/* StoreLoad */
}
private static void read() {
int r1 = field2;
/* LoadLoad + LoadStore */
int r2 = field1;
}
public static void main(String[] args) throws Exception {
// invoke JIT
for (int i = 0; i < 10000; i++) {
write(i);
read();
}
Thread.sleep(1000);
}
}Теперь возьмем дизассемблер hsdis и посмотрим на сгенерированный JIT-компилятором нативный код (инструкция по самостоятельному запуску будет в моем репозитории, который я приведу в конце статьи). Запускаем дизассемблер на Intel Core i7-11700 (x86), Windows 10 x64, OpenJDK 17. Вот сгенерированный ASM код для write():
[Verified Entry Point]
# {method} {0x00000175a1400310} 'write' '(I)V' in 'jit_disassembly/VolatileMemoryBarrierJIT'
# parm0: rdx = int
# [sp+0x40] (sp of caller)
0x000001758817dae3: mov DWORD PTR [rsi+0x70],edi ;*putstatic field1 {reexecute=0 rethrow=0 return_oop=0}
; - jit_disassembly.VolatileMemoryBarrierJIT::write@3 (line 9)
0x000001758817dae6: shl edx,0x2
0x000001758817dae9: mov DWORD PTR [rsi+0x74],edx
0x000001758817daec: lock add DWORD PTR [rsp-0x40],0x0 ;*putstatic field2 {reexecute=0 rethrow=0 return_oop=0}
; - jit_disassembly.VolatileMemoryBarrierJIT::write@9 (line 10)В mov инструкциях мы записываем значения полей field1/field2. Теперь обратите внимание на инструкцию lock add DWORD PTR [rsp-0x40],0x0. Это может показаться странным, что мы добавляем 0 к значению на стеке (rsp), но эта инструкция выступает лишь в качестве дешевой по стоимости "заглушки". Все дело в наличии lock префикса, который является full memory barrier на x86, что и дает нам StoreLoad барьер после записи в volatile. JVM могла бы использовать mfence барьер, но на современных процессорах lock add с добавлением 0 на стек является эффективнее.
Наверняка у вас возник вопрос: где же StoreStore барьер? Как мы уже видели во вступлении, x86 дает достаточно сильные гарантии порядка. Из Intel Software Developer's Manual:
- Reads are not reordered with other reads [запрещает LoadLoad reordering]
- Writes are not reordered with older reads [запрещает LoadStore reordering]
- Writes to memory are not reordered with other writes [запрещает StoreStore reordering]
- Reads may be reordered with older writes to different locations but not with older writes to the same location [разрешает StoreLoad reordering]
Из этого следует, что нет необходимости использовать LoadLoad, LoadStore, и StoreStore барьеры на x86 микроархитектуре, а нужен только StoreLoad барьер. JVM достаточно умна, чтобы не использовать дорогие барьеры памяти там, где процессор уже дает необходимые гарантии, поэтому мы и не видим применения барьера в сгенерированном нативном коде.
Теперь посмотрим на ASM код для read():
[Verified Entry Point]
# {method} {0x00000175a14003a8} 'read' '()V' in 'jit_disassembly/VolatileMemoryBarrierJIT'
# [sp+0x40] (sp of caller)
0x000001758817de5e: mov edi,DWORD PTR [rsi+0x74] ;*getstatic field2 {reexecute=0 rethrow=0 return_oop=0}
; - jit_disassembly.VolatileMemoryBarrierJIT::read@0 (line 14)
0x000001758817de61: mov esi,DWORD PTR [rsi+0x70] ;*getstatic field1 {reexecute=0 rethrow=0 return_oop=0}
; - jit_disassembly.VolatileMemoryBarrierJIT::read@4 (line 15)И снова заметим, что барьеры LoadLoad и LoadStore отсутствуют при чтении volatile переменной благодаря строгим гарантиям x86 микроархитектуры. Однако на более слабой микроархитектуре как ARM мы будем наблюдать барьеры в этих местах (смотрите volatile_jit_asm_arm64.txt).
Happens-before: Recap
Итак, давайте просуммируем то, что делает happens-before на каждом из уровней:
- Compiler memory ordering
- Уровень компилятора байткода (
javac)- Обеспечивает такой порядок сгенерированных bytecode инструкций, который будет консистентен с порядком действий в коде
- Уровень компилятора машинного кода (
HotSpot JIT Compiler C1/C2)- Обеспечивает такой порядок сгенерированных машинных инструкций, который будет консистентен с порядком действий в коде
- Уровень компилятора байткода (
- CPU memory ordering
- Расставляет барьеры памяти в нужных местах так, чтобы Memory Ordering машинных инструкций был консистентен с порядком действий в коде
Первые два уровня зависят полностью от самой Java — именна она имплементирует гарантию порядка. Уровень процессора же зависит не только от Java, но и от самого процессора, который предоставляет и имплементирует барьеры памяти.
JMM: Atomicity
Важная часть JMM, которую я не упоминал ранее, это атомарность некоторых базовых действий. А именно:
- Чтения и записи reference переменных (ссылок) являются атомарными
- Чтения и записи примитивов (кроме long/double) являются атомарными
- Чтения и записи long/double переменных, помеченных как
volatile, являются атомарными
Что же нам дают эти свойства в многопоточной среде? Нам гарантируется, что при shared чтении переменной мы увидим или значение по умолчанию (0, false, null), или полное консистентное значение, но не половинное значение. Даже если в переменную пишут одновременно несколько тредов, то мы увидим результат записи одного из них, но не будет такой ситуации, что чтение увидит первую половину битов из одной записи, а вторую половину из другой записи.
Таким образом, свойство atomicity дополняет happens-before: happens-before гарантирует нам чтение актуальных изменений, а atomicity гарантирует, что прочитанные данные будут консистентными.
Но почему мы вообще могли бы прочитать половинное значение? Дело в том, что некоторые типы в языке имеют размер (в битах) больший, чем длина машинного слова процессора. Например, 32-х битный процессор оперирует словами по 32 бита, но тип long/double содержит 64 бита. Соответственно, языку требуется совершить 2 записи по 32 бит, чтобы полностью записать значение. Из JLS §17.7. Non-Atomic Treatment of double and long:
For the purposes of the Java programming language memory model, a single write to a non-volatilelongordoublevalue is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.
Writes and reads of volatilelonganddoublevalues are always atomic.
Writes to and reads of references are always atomic, regardless of whether they are implemented as 32-bit or 64-bit values.
JCStress имеет готовый тест для этого случая — BasicJMM_02_AccessAtomicity.java:
@JCStressTest
@Outcome(id = "0", expect = ACCEPTABLE, desc = "Seeing the default value: writer had not acted yet.")
@Outcome(id = "-1", expect = ACCEPTABLE, desc = "Seeing the full value.")
@Outcome( expect = ACCEPTABLE_INTERESTING, desc = "Other cases are violating access atomicity, but allowed under JLS.")
@Ref("https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jls-17.7")
@State
public static class Longs {
long v;
@Actor
public void writer() {
v = 0xFFFFFFFF_FFFFFFFFL;
}
@Actor
public void reader(J_Result r) {
r.r1 = v;
}
}Результаты запуска теста оттуда же:
This test would yield interesting results on some 32-bit VMs, for example x86_32:
RESULT SAMPLES FREQ EXPECT DESCRIPTION
-1 8,818,463,884 70.12% Acceptable Seeing the full value.
-4294967296 9,586,556 0.08% Interesting Other cases are violating access atomicity, but allowed u...
0 3,747,652,022 29.80% Acceptable Seeing the default value: writer had not acted yet.
4294967295 86,082 <0.01% Interesting Other cases are violating access atomicity, but allowed u...Как видите, в некоторых случаях мы увидели неконсистентное состояние переменной. То есть мы наблюдали переменную прямо посередине записи — writer записал первую половину битов, но еще не успел записать вторую.
Один из способов обеспечить атомарность записи и чтения для long/double — это пометить переменную как volatile. Другой способ — это работать с переменной под монитором, который обеспечивает атомарность всех действий, выполняемых внутри synchronized блока. Замечу, что эти манипуляции необходимы только в том случае, если переменная шарится между тредами — для локальных переменных это не имеет смысла.
JMM: final fields
JMM дает очень полезную гарантию порядка и видимости записей для final полей: если ссылка на создаваемый объект не утекла во время работы конструктора (так, что ее мог увидеть другой тред), то все остальные треды, которые увидели non-null ссылку на этот объект, гарантированно прочитают актуальные значения всех внутренних final полей объекта вне зависимости от того, была гонка при чтении ссылки или нет.
Из спеки JLS §17.5. final Field Semantics:
An object is considered to be completely initialized when its constructor finishes. A thread that can only see a reference to an object after that object has been completely initialized is guaranteed to see the correctly initialized values for that object'sfinalfields.
The usage model forfinalfields is a simple one: Set thefinalfields for an object in that object's constructor; and do not write a reference to the object being constructed in a place where another thread can see it before the object's constructor is finished. If this is followed, then when the object is seen by another thread, that thread will always see the correctly constructed version of that object'sfinalfields.
Это очень сильная гарантия, которая полностью избавляет нас от проблем memory reordering при чтении состояния объекта.
Обычно под капотом эта гарантия имплементируется с помощью StoreStore + LoadLoad барьера памяти. Именно это и сказано в JSR-133 Cookbook:
- Issue a
StoreStorebarrier after all stores but before return from any constructor for any class with a final field.- If on a processor that does not intrinsically provide ordering on indirect loads, issue a
LoadLoadbarrier before each load of a final field.
Таким образом, вот так JVM создает объект с final полями:
Object _obj = <new> // memory allocation
_obj.f = 5; // write final field in constructor
[StoreStore]
obj = _obj; // publishБлагодаря тому, что StoreStore барьер запрещает переупорядочивание store операций вокруг барьера, нам гарантируется, что после записи ссылки мы также записали и все поля из конструктора. Более того, StoreStore гарантирует видимость всех изменений до барьера, если читатель увидел запись, сделанную после барьера.
Читаем объект мы следующим образом:
Object _obj = obj;
[LoadLoad]
r1 = _obj.f; // read final fieldЗдесь LoadLoad барьер требуется для того, чтобы процессор не переупорядочил чтение ссылки с чтениями полей объекта.
Однако как и в случае с volatile, эти барьеры не требуются там, где процессор уже дает необходимые гарантии. Например, таких барьеров точно не будет на x86.
Интересно, что благодаря такой имплементации, которая, например, используется в HotSpot JVM (см. http://hg.openjdk.java.net/jdk/jdk/file/ee1d592a9f53/src/hotspot/share/opto/parse1.cpp#l1001), нам неявно гарантируется видимость и всех остальных non-final полей. Однако это деталь имплементации, а не гарантия спеки, поэтому на это лучше не полагаться.
Семантика final полей напрямую касается иммутабельных объектов. Известно, что такие объекты можно безопасно шарить между тредами. Но без данной гарантии JMM это было бы не правдой, ведь проблема переупорядочивания все еще никуда не делась. Именно благодаря тому, что JMM автоматически берет на себя задачу по синхронизации final полей, мы имеем возможность корректно шарить иммутабельные объекты без использования примитивов синхронизации.
Давайте рассмотрим использование final полей на примере. Пусть мы имеем такой объект:
public class Foo {
private final int a; /* always visible */
public Foo() {
this.a = 5;
}
}
public class Bar {
private final int b; /* always visible */
public Foo() {
this.b = 7;
}
}
public class DataHolder {
private final Foo foo; /* always visible */
private final int c; /* always visible */
private Bar bar; /* may not be visible */
private int d; /* may not be visible */
public DataHolder() {
this.foo = new Foo();
this.bar = new Bar();
this.c = 9;
this.d = 10;
/* StoreStore */
}
}Тогда мы имеем следующие гарантии — смотрите комментарии в коде:
public class FinalFieldExample {
private DataHolder instance;
public void writer() {
instance = new DataHolder();
}
public void reader() {
DataHolder instance = this.instance; /* data race */
/* LoadLoad */
if (instance != null) {
Foo foo = instance.foo; /* guaranteed to see non-null reference */
int a = foo.a; /* guaranteed to see 5 */
int c = instance.c; /* guaranteed to see 9 */
Bar bar = instance.bar; /* no guarantee - may be null */
if (bar != null) {
int b = bar.b; /* guaranteed to see 7 */
}
int d = instance.d; /* no guarantee - may be 0 (default value) */
}
}
}Интересные наблюдения:
- Хотя переменная
instanceи читается в гонке, но если мы увидели non-null ссылку, то нам гарантируется видимость всех внутреннихfinalполей вне зависимости от наличия гонки - Так как нам гарантируется видимость всех
finalполей, включая ссылки (reference variable), то по определению гарантируется и видимостьfinalполей этих вложенных объектов. Это видно, например, по объектуFoo, который вложен вDataHolder - На самом деле во всех местах, которые я пометил как
no guarantee, я вам немного соврал. Как минимум на HotSpot JVM мы все равно прочитаем актуальные значения всех полей, так как все записи происходят до StoreStore барьера. Однако это деталь имплементации, а не гарантия языка
Benign data races
Интересно, что наличие data race не всегда плохо, если это не влияет на корректность программы, а в некоторых случаях гонка даже является намеренной. Такие гонки называются benign data race.
Не будем далеко ходить за примером — взгляните на имплементацию String#hashCode() из OpenJDK (оригинальные комментарии в коде сохранены как есть):
public final class String {
/** Cache the hash code for the string */
private int hash; // Default to 0
/**
* Cache if the hash has been calculated as actually being zero, enabling
* us to avoid recalculating this.
*/
private boolean hashIsZero; // Default to false;
public int hashCode() {
// The hash or hashIsZero fields are subject to a benign data race,
// making it crucial to ensure that any observable result of the
// calculation in this method stays correct under any possible read of
// these fields. Necessary restrictions to allow this to be correct
// without explicit memory fences or similar concurrency primitives is
// that we can ever only write to one of these two fields for a given
// String instance, and that the computation is idempotent and derived
// from immutable state
int h = hash;
if (h == 0 && !hashIsZero) {
h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
if (h == 0) {
hashIsZero = true;
} else {
hash = h;
}
}
return h;
}
}Как видите, поля hash и hashIsZero не помечены как volatile, а соответственно и нет happens-before между записью и чтением. Это означает, что даже если один тред уже записал значение hash или hashIsZero, то другой тред может не увидеть изменений. Однако это не опасный data race, так как мы восстанавливаемся из этой ситуации повторно вычисляя и записывая значения полей. Это валидно, так как результат вычисления hashCode остается неизменным для иммутабельного объекта (а все строки в Java являются иммутабельными), то есть запись идемпотентна.
Заключение
Надеюсь, данная статья дала вам некоторое понимание JMM, а полученные знания помогут вам писать безопасные и корректные многопоточные программы.
Хотя я и привёл здесь много низкоуровневой информации, но на самом деле запоминать такие детали совершенно не обязательно — я лишь хотел дать вам более глубокое понимание того, что происходит под капотом JMM. Просто пользуйтесь предоставленными примитивами синхронизации, а JMM сделает все за вас, ведь она создана как раз с той целью, чтобы скрыть, абстрагировать нижние уровни и предоставить гарантии, избавляющие вас от проблем memory reordering.
Пользуйтесь JMM, и да пребудет с вами thread safety.
P.S: и запомните: data races are evil.
Ресурсы
Обратите внимание на репозиторий в поддержку данной статьи — https://github.com/blinky-z/JmmArticleHabr. Там вы сможете найти еще больше, не включенных в статью jcstress тестов и дизассемблированных программ, а также инструкции и результаты запуска тестов и дизассемблера на x86/arm64.
Основы:
- Memory model, Wikipedia
- Memory ordering, Wikipedia
- JLS §17.4. Memory Model, спецификация
- The Java Memory Model — "домашняя страница" JMM, содержащая кучу полезной информации
- The JSR-133 Cookbook — неофициальный гайдлайн по имплементации JMM для разработчиков JDK, Doug Lea
- Memory Barriers — a Hardware View for Software Hackers — крайне подробный обзор работы CPU, кэша и барьеров памяти
- How does memory reordering help processors and compilers?, StackOverflow
Memory Model:
- Memory Consistency Models: A Tutorial
- Sequential consistency, Wikipedia
- The Happens-Before Relation, blog post
Блог Алексея Шипилева — это целая кладезь знаний про JMM и не только. Крайне советую прочитать следующие его статьи:
- Java Memory Model Pragmatics, blog post by Shipilev
- Safe Publication and Safe Initialization in Java, blog post by Shipilev
- Close Encounters of The Java Memory Model Kind, blog post by Shipilev
- All Fields Are Final, blog post by Shipilev
Compiler Memory Ordering:
- Memory Ordering at Compile Time, blog post
- Instruction scheduling, Wikipedia
CPU Memory ordering/Memory Barrier:
- Memory Consistency Models: A Tutorial, blog post
- Memory Barriers Are Like Source Control Operations, blog post
- Weak vs. Strong Memory Models, blog post
- Sequential Consistency & Total Store Order, slides
- Memory barrier, Wikipedia
- Memory Barriers/Fences, blog post
- Linux kernel memory barriers, Linux kernel docs
- Сводная таблица возможных переупорядочиваний среди различных микроархитектур
- Intel (x86):
- Intel Memory Ordering
- Does an x86 CPU reorder instructions?, StackOverflow
- Making sense of Memory Barriers
- what is a store buffer?, StackOverflow
- Size of store buffers on Intel hardware? What exactly is a store buffer?, StackOverflow
- ARM:
CPU Cache:
- CPU cache, Wikipedia
- Cache hierarchy, Wikipedia
- Cache coherence, Wikipedia
- MESI protocol, Wikipedia
- Mechanical Sympathy: CPU Cache Flushing Fallacy, blog post
- Cache coherency primer, blog post
- Memory barriers force cache coherency?, StackOverflow
Volatile:
- Volatile, blog post
- Volatile and memory barriers, blog post
- Java theory and practice: Managing volatility, blog post by Brian Goetz
Книги:
Комментарии (52)

titbit
30.08.2022 22:06+2А на ARM совсем другая ситуация. Там разрешены переупорядочивания записи в память, поэтому код работавший на intel/amd корректно может потребовать дополнительных барьеров. Особенно это заметно на всяких lock-free алгоритмах, где барьеры надо ставить с особой тщательностью.

blinky-z Автор
30.08.2022 22:12+1Вы абсолютно правы, x86 обладает намного более строгими гарантиями по сравнению с ARM/Power. Об этом я также упоминал несколько раз в статье
blinky-z Автор
31.08.2022 11:42+1Кстати, вот яркий пример. Взгляните на данный тест - https://github.com/blinky-z/JmmArticleHabr/blob/main/jcstress/tests/object/JmmReorderingObjectTest.java. Суть его в том, что мы можем прочитать неконсистентное состояние объекта, даже если увидели non-
nullссылку. Он воспроизводится на ARM, но совсем не воспроизводится на x86, т.к. последний запрещаетStoreStore/LoadLoadreordering.
PVoLan
31.08.2022 19:39Так. Тут происходит что-то очень интересное, но не совсем очевидное.
1) Я так понимаю, что в некоторых случаях в ссылку Foo.mock оказывается записан валидный объект ДО того, как констуктор этого Foo.mock отработает. Ноооо... в каком треде происходит выполнение инструкции
static final Foo mock = new Foo();и почему?2) У вас в строке 90 приписан комментарий
return instance; // can return nullЭто сбивает с толку - действительно ли в этой строке может вернуться null? Это же нарушает reordering в пределах одного потока. И в ваших тестах нет ни одного подобного случая.blinky-z Автор
31.08.2022 20:18Не обращайте внимания на mock - с ним все нормально. Это лишь заглушка, чтобы вернуть что-то из метода, если
readerсработал раньше, чемwriter. В тесте это@Outcome(id = "-1", expect = Expect.ACCEPTABLE, desc = "Object is not seen")Да, это очень тонкий момент. Суть в том, что может произойти LoadLoad reordering и второе чтение (которое мы возвращаем из метода) произойдет раньше, чем первое, так как они не связаны. К сожалению, у меня его не получилось воспроизвести этот reordering в этом тесте, поэтому я написал отдельный тест - https://github.com/blinky-z/JmmArticleHabr/blob/main/jcstress/tests/object/JmmReorderingObjectSameReadNullTest.java. В нем LoadLoad воспроизводится даже на x86 из-за переупорядочивания инструкций в компиляторе
Ну и последний кейс, который воспроизводится в этом тесте - это обнаружение неконсистентного состония объекта. Можно наивно предположить, что если мы увидели non-
nullссылку на объект, то увидим и внутренние поля объекта, но это не так. Например, writer мог вызвать конструктор после записи адреса в ссылку. То есть, порядок инструкций мог быть такой после переупорядочивания:| Writer | Reader | |:---------------------------------------------:|:-----------------:| | _instance = <new> /* memory allocation */ | | | instance = _instance /* publish */ | | | | r1 = instance | | | r2 = r1.x /* 0 */ | | _instance.<init> /* constructor invocation */ | |PVoLan
31.08.2022 21:38Эмммм, по-моему вы заблуждаетесь.
В п.2 чтения как раз таки связаны, и они не могут быть поменяны местами, т.к. это ломает консистентность в пределах одного потока. Точнее, сами чтения-то не связаны, а вот чтение + последующая return - очень даже связаны. Если в строке 87
instance == nullвыполняется, инструкцияreturn instance;не может быть выполнена, ибо они в одном потоке.А вот в процедуре создания объекта mock как раз таки возможна та самая перестановка, о которой я говорю в своем пункте 1, а вы - в своем последнем абзаце, когда вызов конструктора и присваивание ссылки на созданный объект меняются местами. В этом случае (очевидно предположить, что инициализация статической переменной mock случается в каком-то третьем потоке [утверждение требует проверки - ред.]) в строке 88 может быть возвращен "недозаполненный" объект mock, который триггерит
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "Object's data is null")PVoLan
31.08.2022 21:48Подумал еще раз и понял, что ситуацию с перестановкой местами вызова конструктора и присваивания ссылки мы также можем видеть и для
instance = new Foo();в строке 83. В этом случае строка 90return instance;тоже может возвращать недозаполненный объект и триггерить outcome 0.Но возвращать null строка 90 все равно не может
PVoLan
01.09.2022 10:30Подумал третий раз и увидел, что в тех случаях, когда мы возвращаем объект mock, мы не делаем проверок на его содержимое и всегда возвращаем -1, так что моя гипотеза в п.1 скорее всего неактуальна (хотя стоило бы проверить на всякий случай)
blinky-z Автор
01.09.2022 17:01+1По поводу объекта
mock:он всегда консистентен, так как static поля инициализируются во время инициализации класса, как это сказано в JLS §12.4. Initialization of Classes and Interfaces. Имплементация инициализации такова, что static поля инициализируются внутри уникального для каждого класса лока, который и дает видимость объекта - см. JLS §12.4.2. Detailed Initialization Procedure
он нужен нам только для того, чтобы вернуть что-то, если мы прочитали
instanceслишком рано (до вызоваwriter)
В данном тесте следует смотреть только на работу с переменной
instance.В п.2 чтения как раз таки связаны, и они не могут быть поменяны местами, т.к. это ломает консистентность в пределах одного потока. Точнее, сами чтения-то не связаны, а вот чтение + последующая return - очень даже связаны. Если в строке 87
instance == nullвыполняется, инструкцияreturn instance;не может быть выполнена, ибо они в одном потоке.А что такое консистентность в пределах одного потока, это happens-before для действий в потоке? Но если компилятор/процессор переупорядочит эти инструкции, разве нарушится happens-before? Ведь эти чтения никак не аффектят друг друга и между ними нет никакой записи (обычно говорится, что это independent reads). Другими словами, со стороны одного потока кажется, что эта переменная не изменяется, поэтому он может переупорядочить инструкции чтения.
Запомните: чтения в гонке могут быть переупорядочены как угодно и даже для одной и той же переменной.
Именно поэтому, обычно при работе с benign data race мы вычитываем только единожды переменную в локальную, чтобы далее больше не иметь гонки и работать с локальной переменной. Например, если бы мы переписали
readerтак:public Foo cachingReader() { Foo local = instance; if (local == null) { return Foo.mock; // return mock value if not initialized } return local; // can not return null }То никогда не могли бы вернуть
null.Да, я не смог воспроизвести этот случай в этом тесте, но это все равно возможно хотя бы потому, что некоторые микроархитектуры как ARM разрешают LoadLoad переупорядочивание, а мы не используем барьер при чтении.
Конечно, не надо верить мне на слово, поэтому посмотрите на этот тест - https://github.com/blinky-z/JmmArticleHabr/blob/main/jcstress/tests/object/JmmReorderingObjectSameReadNullTest.java. Он воспроизводится даже на x86 (где запрещены LoadLoad переупорядочивания) из-за оптимизаций компилятора.
Также советую прочитать статью Алексея Шипилева Safe Publication and Safe Initialization in Java, там этот момент тоже затрагивается.
blinky-z Автор
02.09.2022 03:10Кстати, вот еще у Алексея Шипилева есть пункт про этот момент, где мы читаем
nullна повторном чтении - https://shipilev.net/blog/2016/close-encounters-of-jmm-kind/#wishful-benign-is-resilient
Сильно советую прочитать эту статью целиком - рассказывает о многих интересных фактах о JMM, которые остались за рамками моей статьи.
PVoLan
02.09.2022 10:55Конечно, не надо верить мне на слово, поэтому посмотрите на этот тест - https://github.com/blinky-z/JmmArticleHabr/blob/main/jcstress/tests/object/JmmReorderingObjectSameReadNullTest.java. Он воспроизводится даже на x86 (где запрещены LoadLoad переупорядочивания) из-за оптимизаций компилятора.
С этим тестом как раз все понятно, там чтения и потенциальная возможность/целесообразность их переупорядочивания вполне очевидна.
С п.2 все не так очевидно. Хотя, я, кажется, начинаю понимать, что вы имеете в виду.
Теоретически, можно предположить, что скомпилированный код
а) сначала прочитает значение переменной instance для использования в строке 90
return instance;В этот момент может прочитаться nullб) позднее еще раз прочитает значение переменной instance для использования в строке 87
if (instance == null), и в этот момент прочитается не-nullТак получается?
Теоретически, вроде бы, действительно я не вижу противоречия упомянутым правилам happens-before при таком раскладе. Но выглядит как-то совсем бредово...
blinky-z Автор
02.09.2022 15:46а) сначала прочитает значение переменной instance для использования в строке 90
return instance;В этот момент может прочитаться nullб) позднее еще раз прочитает значение переменной instance для использования в строке 87
if (instance == null), и в этот момент прочитается не-nullТак получается?
Именно так. Выглядит бредово, да) Но к сожалению, независимые чтения в гонке и даже для одной и той же переменной могут быть переставлены как угодно. Вот если бы мы поставили LoadLoad барьер после первого чтения и до второго, так такого бы не случилось. Например:
public Foo reader() { if (instance == null) { return Foo.mock; // return mock value if not initialized } VarHandle.loadLoadFence(); return instance; // can return null }
blinky-z Автор
31.08.2022 11:42Кстати, вот яркий пример. Взгляните на данный тест - https://github.com/blinky-z/JmmArticleHabr/blob/main/jcstress/tests/object/JmmReorderingObjectTest.java. Суть его в том, что мы можем прочитать неконсистентное состояние объекта, даже если увидели non-
nullссылку. Он воспроизводится на ARM, но совсем не воспроизводится на x86, т.к. последний запрещаетStoreStore/LoadLoadreordering.

dyadyaSerezha
31.08.2022 00:36Заметил несколько фактических ошибок, некоторые существенные, например, при синхронизации через volatile.
blinky-z Автор
31.08.2022 01:16Укажите, пожалуйста, на ошибки. Буду только рад поправить и сделать материал лучше
dyadyaSerezha
31.08.2022 06:42Проанализируем программу: если в первом треде мы видим
0при чтенииy, то запись вxточно произошлаНе 0, а 1. И далее во всем абзаце.
Writes are not reordered with older reads [запрещает LoadStore reordering]
Не LoadStore, а StoreLoad.
Reads may be reordered with older writes to different locations but not with older writes to the same location [разрешает StoreLoad reordering]
Не StoreLoad, а LoadStore.
В разделе "volatile", код с volatile неверный, так так если поток reader читает в r1, потом поток writer выполняет "initialized = true; /* W2 */", по проверка в reader "if (r1)" не пройдёт, хотя x уже гарантировано имеет значение 5. Уберите ненужное присваивание "boolean r1 = initialized; /* R1 */" и сразу пишите "if (initialized)".
Дальше не читал ещё :)
blinky-z Автор
31.08.2022 15:00Не 0, а 1. И далее во всем абзаце.
Нет, я говорю именно про ситуацию, когда читаем 0. Давайте посмотрим еще раз на пример:
private int x; private int y; public void T1() { x = 1; // W1 int r1 = y; // R1 } public void T2() { y = 1; // W2 int r2 = x; // R2 }Если мы прочитали на R1 любое значение (хоть 0, хоть 1, но нас интересует именно 0), то запись W1 точно произошла, а значит на чтении R2 мы должны будем увидеть
1. Аналогично рассуждаем и о втором треде. Таким образом, мы можем увидеть0только на одном из чтений, но никак не на обоих, так как это просто невозможно если смотреть с точки зрения порядка в программе, ведь хотя бы одна запись должна была произойти.
Другими словами, выполнение программы начинается или с записиx, или с записиy. Если мы прочитали (0, 0), то это означало бы, что выполнение программы началось с чтений, но ведь они идут после записей? Однако это происходит по причине memory reordering, так как Java не дает sequential consistency по умолчанию.Не LoadStore, а StoreLoad.
Нет, это называется именно
LoadStore(читать так: loads can be reordered after stores).Не StoreLoad, а LoadStore.
И здесь тоже именно
StoreLoad(читать так: stores can be reordered after loads). Кстати, причина наличия такого переупорядочивания в x86 - это Store Buffer.dyadyaSerezha
01.09.2022 08:40Насчёт 0 или 1 - именно, что любое число, а не только 0, как написано (было написано) в статье.
Насчёт LoadStrore и StoreLoad, ваши же определения выше противоречат им. Или поменяйте определения, или поменяйте тут. То есть, вы смешиваете memory reordering и memory barrier.
blinky-z Автор
01.09.2022 17:24Да, наверное момент с
0мог запутать, но я специально хотел сделать акцент на том, что мы можем прочитать0только в одном из чтений. В любом случае, уже переписал понятнее.Насчет LoadStore/StoreLoad - перечитал несколько раз, все равно не понимаю.
К примеру, если взять LoadStore reordering, я даю такое определение:
LoadStore: переупорядочивание чтений с записями, идущими позже в порядке программы. Например, действия
r, wмогут выполниться в порядкеw, rЗатем привожу цитату из Intel Software Developer’s Manual (8.2.2 Memory Ordering in P6 and More Recent Processor Families):
- Writes are not reordered with older reads [запрещает LoadStore reordering]
Здесь говорится, что записи не будут переупорядочены с чтениями, которые идут ранее (older) в программе. Соответственно, это запрещает LoadStore переупорядочивание, определение которого я дал выше.
И наконец, определение LoadStore барьера:
2. LoadStore
- дает гарантию, что все load операции до барьера произойдут перед store операциями после барьера
Данный барьер запрещает переупорядочивание load операций с store операциями, которые идут позже в программе, а точнее после барьера. Соответственно, этот барьер тожеи запрещает LoadStore переупорядочивание.
dyadyaSerezha
01.09.2022 21:48Блин)
Writes are not reordered with older reads [запрещает LoadStore reordering]
То что older, пишется вторым.
И таки признайте, что с volatile код неправильный.
quackQZS
31.08.2022 15:06Проанализируем программу: если в первом треде мы видим 0 при чтении y, то запись в x точно произошла
Не 0, а 1. И далее во всем абзаце.
Код в статье правильный: вот этот же пример в JCStress.
Возможно, из описания не совсем понятно, что этот код делает.
Можно попробовать объяснить вот так:
Код:
public class MemoryReorderingExample { private int x; private int y; public void T1() { x = 1; int r1 = y; } public void T2() { y = 1; int r2 = x; } }Тут
T1()выполняется в первом потоке,T2()- во втором.Обычно люди, незнакомые с JMM, полагают, что в таком случае действия в каждом потоке выполняются последовательно.
И в итоге, они считают, что есть всего 4 варианта того, в каком порядке выполняются действия потоков:x = y = 0; T1 | T2 T1 | T2 -------------------------- -------------------------- x = 1; | x = 1; | int r1 = y; | | y = 1; | y = 1; int r1 = y; | | int r2 = x; | int r2 = x; T1 | T2 T1 | T2 -------------------------- -------------------------- | y = 1; x = 1; | x = 1; | | y = 1; int r1 = y; | | int r2 = x; | int r2 = x; int r1 = y; |Как видите, во всех четырёх случаях первым всегда идёт либо
x = 1;либоy = 1;, а значит результата(r1==0, r2==2)быть не должно.А в JMM такой результат допустим.
Значит описанный выше "интуитивный" подход не работает в java, и программистам нужно разбираться сhappens-before,volatileи остальной JMM.blinky-z Автор
31.08.2022 15:14Все верно. Другими словами, выполнение программы начинается всегда с какой-либо записи. Если мы прочитали (0, 0), то это означало бы, что выполнение программы началось с чтений, но это противоречит порядку программы.
К сожалению, JMM не дает sequential consistency по умолчанию. Если говорить просто, sequential consistency - это когда мы берем действия всех тредов, как они идут в порядке программы, и просто перемешиваем как угодно.
JMM дает более слабую, "data race free", гарантию - sequential consistency гарантируется только в том случае, если программа не имеет data race. В вышеприведенном примере мы явно имеем data race, так как читаем и пишем в shared переменную из разных тредов без установки отношения happens-before
quackQZS
01.09.2022 18:19В коментарии выше ошибка: вариантов 6, а не четыре.
x = y = 0; T1 | T2 T1 | T2 -------------------------- -------------------------- x = 1; | | y = 1; int r1 = y; | | int r2 = x; | y = 1; x = 1; | | int r2 = x; int r1 = y; | T1 | T2 T1 | T2 -------------------------- -------------------------- x = 1; | | y = 1; | y = 1; x = 1; | int r1 = y; | | int r2 = x; | int r2 = x; int r1 = y; | T1 | T2 T1 | T2 -------------------------- -------------------------- x = 1; | | y = 1; | y = 1; x = 1; | | int r2 = x; int r1 = y; | int r1 = y; | | int r2 = x;
blinky-z Автор
31.08.2022 17:30+1В разделе "volatile", код с volatile неверный, так так если поток reader читает в r1, потом поток writer выполняет "initialized = true; /* W2 /", по проверка в reader "if (r1)" не пройдёт, хотя x уже гарантировано имеет значение 5. Уберите ненужное присваивание "boolean r1 = initialized; / R1 */" и сразу пишите "if (initialized)".
Вы не поверите, но это абсолютно одинаковый код :) Чтобы выполнить if-условие, необходимо сначала выполнить чтение. Нет разницы, вынесем мы это чтение в отдельную переменную или нет.
Чтобы подтвердить свои слова, приведу дизассемблер обоих вариантов:
public static void reader1() { boolean r1 = initialized; /* R1 */ if (r1) { int r2 = x; /* R2 */ } /* x86: 0x000002239b45b5de: movsx esi,BYTE PTR [rsi+0x74] ;*getstatic initialized {reexecute=0 rethrow=0 return_oop=0} ; - jit_disassembly.JmmVolatileConditionRead::reader1@0 (line 14) 0x000002239b45b5e2: cmp esi,0x0 0x000002239b45b5e5: movabs rsi,0x223b7c037e0 ; {metadata(method data for {method} {0x00000223b7c032d8} 'reader1' '()V' in 'jit_disassembly/JmmVolatileConditionRead')} 0x000002239b45b5ef: movabs rdi,0x110 0x000002239b45b5f9: je 0x000002239b45b609 0x000002239b45b5ff: movabs rdi,0x120 0x000002239b45b609: mov rbx,QWORD PTR [rsi+rdi*1] 0x000002239b45b60d: lea rbx,[rbx+0x1] 0x000002239b45b611: mov QWORD PTR [rsi+rdi*1],rbx 0x000002239b45b615: je 0x000002239b45b628 ;*ifeq {reexecute=0 rethrow=0 return_oop=0} ; - jit_disassembly.JmmVolatileConditionRead::reader1@5 (line 15) 0x000002239b45b61b: movabs rsi,0x7114bd448 ; {oop(a 'java/lang/Class'{0x00000007114bd448} = 'jit_disassembly/JmmVolatileConditionRead')} 0x000002239b45b625: mov esi,DWORD PTR [rsi+0x70] ;*getstatic x {reexecute=0 rethrow=0 return_oop=0} ; - jit_disassembly.JmmVolatileConditionRead::reader1@8 (line 16) */ } public static void reader2() { if (initialized) { /* R1 */ int r2 = x; /* R2 */ } /* x86: 0x000002239b45b25e: movsx esi,BYTE PTR [rsi+0x74] ;*getstatic initialized {reexecute=0 rethrow=0 return_oop=0} ; - jit_disassembly.JmmVolatileConditionRead::reader2@0 (line 21) 0x000002239b45b262: cmp esi,0x0 0x000002239b45b265: movabs rsi,0x223b7c03930 ; {metadata(method data for {method} {0x00000223b7c03388} 'reader2' '()V' in 'jit_disassembly/JmmVolatileConditionRead')} 0x000002239b45b26f: movabs rdi,0x110 0x000002239b45b279: je 0x000002239b45b289 0x000002239b45b27f: movabs rdi,0x120 0x000002239b45b289: mov rbx,QWORD PTR [rsi+rdi*1] 0x000002239b45b28d: lea rbx,[rbx+0x1] 0x000002239b45b291: mov QWORD PTR [rsi+rdi*1],rbx 0x000002239b45b295: je 0x000002239b45b2a8 ;*ifeq {reexecute=0 rethrow=0 return_oop=0} ; - jit_disassembly.JmmVolatileConditionRead::reader2@3 (line 21) 0x000002239b45b29b: movabs rsi,0x7114bd448 ; {oop(a 'java/lang/Class'{0x00000007114bd448} = 'jit_disassembly/JmmVolatileConditionRead')} 0x000002239b45b2a5: mov esi,DWORD PTR [rsi+0x70] ;*getstatic x {reexecute=0 rethrow=0 return_oop=0} ; - jit_disassembly.JmmVolatileConditionRead::reader2@6 (line 22) */ }Ссылка на программу, которую я тестировал (также привел там disasm и для arm64) - https://gist.github.com/blinky-z/bd0143794421878ee10dd4846da59df3
dyadyaSerezha
02.09.2022 04:33Чтобы выполнить if-условие, необходимо сначала выполнить чтение. Нет разницы, вынесем мы это чтение в отдельную переменную или нет.
Если между этим чтением и if переменная initialized сменит значение, то if пойдёт по уже неправильной ветке. Ну очевидно же.
blinky-z Автор
02.09.2022 16:07А я еще раз настаиваю: чтение и if condition - это две разные операции. Между чтением и сравниванием есть некоторый интервал времени, поэтому нет разницы, вынесете вы чтение в отдельную переменную или нет. Мы ведь не CAS используем здесь. Посмотрите приведенный выше disasm - там это очень наглядно видно.
И даже если представить, что вы правы, то нас интересует только валидность memory order, а не когда произойдет что-то.
Например, оба этих порядка полностью валидны (с точки зрения Sequential Consistency):
write(x, true) -> write(initialized, true) -> read(initialized):true -> read(x): 5
write(x, true) -> read(initialized):false -> write(initialized, true)

BinDecHex
31.08.2022 12:34Раздел Happens-before: Practice
Instructions reordering (2/2) — чтения R1 и R2 были переставлены местами
и чуть ниже
hb(R1, R2)(same thread)blinky-z Автор
31.08.2022 13:18Но ведь данные чтения никак не аффектят друг друга, а поэтому их можно переупорядочить :) Перечитайте раздел [Happens-Before] Same thread actions - там написано о том, как переупорядочивание действий в треде не нарушает happens-before.
Только в том случае, если связать с помощью happens-before действия в разных тредах, happens-before будет гарантировать, что инструкция чтенияR2произойдет только послеR1(запретит LoadLoad memory reordering), а инструкция записиW1произойдет доW2(запретит StoreStore memory reordering), иначе happens-before в цепочке действий(W1,W2,R1,R2)было бы нарушено.
Другими словами, пока мы не свяжемW2иR1с помощью happens-before (что дает нам volatile), то не будет happens-before между наборами действий(W1,W2)и(R1,R2).
quackQZS
31.08.2022 12:34Прекрасная статья.
У Вас действительно хорошо получается объяснять понятным языком: читая статью я несколько раз ловил себя на мысли, что сам я не смог бы объяснить данный момент проще и понятней.В качестве конструктивной критики: боюсь что таких слов "имплементация" и "консистентность" в русском языке нет. Я так понимаю это implementation и consistency написанные русскими буквами.
Это не критично, но всё-таки немного режет глаз.
Как вариант, эти слова можно заменить на "реализация" и "согласованность/соответсвие", или даже просто использовать английские термины.Также я заметил вот такую ошибку в тексте:
Shared — линия кэша актуальна и эквивалентна памяти. Когда значение из памяти первые загружается в кэш, то линия кэша устанавливается именно в shared состояние.
Судя по Table 1.1 в статье о MESI на вики, в этом случае состояние будет Exclusive.
blinky-z Автор
31.08.2022 13:41Да, это про implementation и consistency. Лично я придерживаюсь мнения, что говорить "имплементация" - наоборот корректнее, чем "реализация". Та же вики под Реализацией имеет в виду что-то другому, чем Имплементация. Не знаю, насколько валидно говорить "консистентность" (наверное правильнее "согласованность"?), но это понятие используется повсеместно и если всем все понятно, то проблемы нет :)
Насчет перевода в Exclusive состояние еще уточню, но кажется вы правы, спасибо!
quackQZS
31.08.2022 14:56+1Понятно.
Я, почему-то, наоборот, слово "имплементация" встречал в основном в политическо-юридическом контексте.
А в программировании и в IT - я в основном встречал "реализация": "реализация алгоритма на языке java", "реализация наследуемых абстрактных методов в дочернем классе" и т.п.Кстати, определение термина имплементация в википедии использует термин "реализация":
Имплементация (программирование) — программная или аппаратная реализация какого-либо протокола, алгоритма, технологии

kacetal
31.08.2022 19:46Вообще-то имплементация есть в русском языке. И до информатики она применялась в юриспруденции с тем же самым смыслом, например "имплементация закона".
quackQZS
31.08.2022 15:19+1Итак, ядра действительно всегда видят актуальное значение, но только кроме короткого временного окна после записи. Другими словами, нам гарантируется eventual visibility изменений.
Исправить этот пример можно пометив переменную как
volatile— только в этом случае нам гарантируется eventual visibility изменений.Любопытный факт: cтрого говоря, в java нет гарантий того, что
volatileзапись должна в течение какого-то времени стать видимой другим потокам.В итоге формально допустима
volatileзапись, которая никогда не станет видимой другим потокам.
Более того, допустима реализация JVM, в которой все записи никогда не видны другим потокам.Конечно же, java-программисты надеются, что в используемых на практике реализациях JVM таких "оптимизаций" нет.
А вот в c++ eventual visibility гарантируется:
18 An implementation should ensure that the last value (in modification order) assigned by an atomic or synchronization operation will become visible to all other threads in a finite period of time.
11 Implementations should make atomic stores visible to atomic loads within a reasonable amount of time.
blinky-z Автор
31.08.2022 15:52Стандарт нигде не говорит явно, что запись в
volatileпеременную должна стать видимой. Однако этот факт неявно исходит из следующего определения sequential consistency в JMM:A set of actions is sequentially consistent if all actions occur in a total order (the
execution order) that is consistent with program order, and furthermore, each read
r of a variable v sees the value written by the write w to v such that:w comes before r in the execution order, and there is no other write w' such that w comes before w' and w' comes before r in the execution order.
Sequential consistency is a very strong guarantee that is made about visibility and
ordering in an execution of a program. Within a sequentially consistent execution,
there is a total order over all individual actions (such as reads and writes) which is
consistent with the order of the program, and each individual action is atomic and
is immediately visible to every thread.Таким образом, если мы пометим переменную как volatile, то нам гарантируется видимость изменений.
Разберем на примере. Обозначим запись в переменную как
write(x, V)и чтение какread(x):V, где V - записываемое или читаемое значение. Пусть где-то в программе мы пишем значение1в shared переменнуюxи где-то читаем эту переменную. Тогда возможны такие execution order:...read(x):0 -> ... -> write(x, 1)
...write(x, 1) -> ... -> read(x):?Первый случай нас не очень интересует. А вот во втором случае, если мы не пометим переменную как
volatile, нам не гарантируется видимости изменений, так как между записью и чтением нет отношения happens-before, а значит и нет sequential consistency. Но если бы мы пометили переменную какvolatile, то между этими действиями был бы установлен happens-before, а значит есть sequential consistent, а значит есть и видимость изменений.quackQZS
31.08.2022 21:54+1По-моему, immediately visible to every thread тут означает, что чтение переменной всегда возвращает последнюю с точки зрения execution order запись в эту переменную.
При этом этот так называемый "execution order" при Sequential consistency не подразумевает привязки к реальному времени исполнения инструкций.
И поэтому я не думаю, что приведённая цитата гарантирует, чтоvolatileзаписи обязательно становятся видимыми в других потокам.Почему я так считаю:
-
Sequential consistency (SC) (в отличии от Strict consistency) обычно не подразумевает, что действия становятся видимы мгновенно.
При этом в SC:есть общий для всех потоков порядок чтений и записей (т.н. execution order)
program order чтений и записей каждого потока соблюдается в execution order
упорядоченность операций по реальному времени исполнения в execution order соблюдать не требуется
Пример.
Реальное время выполнения инструкций процессором:T1 T2 | ------------ |t=0 x=1; | | | |t=10ns y=2; | | | |t=20ns | x=3; VВозможные execution order:
x=1 -> y=2 -> x=3x=1 -> x=3 -> y=2x=3 -> x=1 -> y=2
Опять же, насколько я понимаю, в SC не ограничена задержка, с которой запись в одном потоке становится видимой другим потокам.
И поэтому, например,x=3из T2 может стать видимым в T1, допустим, через год - и это не нарушит SC. -
в остальной JMM реальное время не соблюдается и никакого immediately visible to every thread нет.
В частности, в статье выше упоминалось про happens-before:
Давайте сразу проясним один момент: нет, happens-before не означает, что инструкции будут действительно выполняться в таком порядке. Если переупорядочивание инструкций все равно приводит к консистентному результату, то такое переупорядочивание инструкций не запрещено.
Если инструкции переупорядочиваются, значит в случае с happens-before привязки к реальному времени исполнения инструкций нет — важно лишь чтобы результат был таким же.
Логично предположить, что в и случае SC - инструкции внутри, к примеру,
synchronized{}блоков также разрешено переупорядочивать.
Соответсвенно эти инструкции также не будут выполняться по одной и сразу становиться immediately visible to every thread.Также было бы странно, если бы eventual visibility гарантировалась только для SC (т.е. только для data-race-free программ): ведь самые заоптимизированные по многопоточной производительности алгоритмы (типа содержимого java.util.concurrent) частенько используют всякие хаки типа кода с data race-ами.
Было бы странно, если бы именно таким алгоритмам не гарантировалась eventual visibility.
blinky-z Автор
01.09.2022 12:38-1Все-таки Sequential Consistency - это про обеспечение такого memory order, который консистентен с порядком действий всех тредов в программе без привязки к реальному времени выполнения. Вы правы насчет видимости в strict consistency - это действительная самая строгая гарантия, но совсем не нужная в Memory Model.
Как я это понимаю. Возьмем тот же Dekker алгоритм. Вот его program order тредов:
Thread 0 | Thread 1 ------------------- x = 1 | y = 1 r1 = y | r2 = xДля него, например, среди множества других валидны такие SC execution order (он же memory order):
x = 1 y = 1 r1 = y // 1 r2 = x // 1 ------ x = 1 r1 = y // 0 y = 1 r2 = x // 1Причем мы не знаем, как действительно выполнялись инструкции под капотом, но нам это и не важно.
Однако давайте все-таки заглянем на уровень процессорных инструкций. Возьмем для разбора второй memory order. Для него порядок выполнения инструкций мог быть таким:
CORE 0 : write(x, 1) read(y):0 CORE 0 time: |--------->--------|-------> CORE 1 : write(y, 1) read(x):1 CORE 1 time: --------------|--------------->-----|---------> time : --------------------------------------------->Как видите, порядок выполнения инструкций не совпадает с memory order. Например,
read(y)был вызван послеwrite(y), но все равно обнаруживает 0. Это вызвано тем, что write операции занимают некоторое время (что включает в себя и полную пропагацию записи на все локальные кэши процессора).И наоборот, если бы в теории мы имели strict consistency модель, то операции записи должны были бы завершаться мгновенно. Другими словами, memory order должен быть полностью эквивалентен порядку выполнения инструкций:
CORE 0: write(x, 1) -> read(y):1 CORE 1: write(y, 1) -> read(x):1Но это не возможно просто физически. Об этом же говорится в wiki SC:
The sequential consistency is weaker than strict consistency, which requires a read from a location to return the value of the last write to that location; strict consistency demands that operations be seen in the order in which they were actually issued.
quackQZS
01.09.2022 17:31Небольшое замечание по поводу strict consistency.
Вы пишите:
если бы в теории мы имели strict consistency модель, то операции записи должны были бы завершаться мгновенно
...
Но это не возможно просто физически.И потом приводите такую цитату:
The sequential consistency is weaker than strict consistency, which requires a read from a location to return the value of the last write to that location; strict consistency demands that operations be seen in the order in which they were actually issued.
Но эта цитата не утверждает, что операции должны завершаться мгновенно.
Она утверждает, что, начиная с момента времени, когда операция становится выполненной, она должна стать видимой другим процессорам.
Но при этом выполнение операции вполне может занимать какое-то время.В Вашем примере если
write(x,1)становится выполненным в момент времениt, то любойread(x)начатый позжеtдолжен возвратить1или более позднюю запись.Пример процессора, которые мог бы реализовать это физически:
с когерентным кэшем без Invalidation Queue и Store Buffer
следующая инструкция начинает выполняться только после того, как выполнилась текущая инструкция
writeстановится выполненным когда означение записано в cache linereadстановится выполненным когда значение прочитано из кэша
blinky-z Автор
01.09.2022 18:22Но разве
...strict consistency demands that operations be seen in the order in which they were actually issued.
Не говорит как раз это? Например, в моем примере инструкция
read(y)"issued" послеwrite(y), но со стороны программы memory order такой:write(x,1) -> read(y):0 -> write(y, 1) -> read(x):1quackQZS
01.09.2022 19:35Не совсем понятно, что Вы имеете ввиду под "как раз это".
Я так понял, что Вы написали, что у процессора, соответсвующего strict consistency, операции записи должны выполняться мгновенно (в смысле физического времени) и что это невозможно физически.
На мой взгляд, приведённая Вами цитата не требует от процессора мгновенных(в смысле физического времени) операций записи, и что процессор, соответсвующий strict consistency, создать вполне возможно.
blinky-z Автор
02.09.2022 00:24Да, понял вас. Ошибся, операции действительно могут не выполняться мгновенно, и ваша наивная имплементация выше это доказывает.
blinky-z Автор
01.09.2022 14:53Поразмыслил еще раз и понял, что я действительно не прав. Спасибо за такое полезное замечание!
Для начала, укажу на свою ошибку: "immediately visible to every thread" надо понимать так, как вы и сказали. То есть, если запись становится видной хотя бы одному треду, то и все остальные треды увидят эту запись.
Далее я буду излагать свой порядок мыслей по порядку, чтобы мы единообразно понимали написанное в спеке.
На уровне SC модели действительно нет никакого времени, а есть лишь порядок и видимость предыдущих действий. Разберем еще раз определение в спеке:
A set of actions is sequentially consistent if all actions occur in a total order (the execution order) that is consistent with program order, and furthermore, each read r of a variable v sees the value written by the write w to v such that:
- w comes before r in the execution order, and
- there is no other write w' such that w comes before w' and w' comes before r in the execution order.
Здесь говорится следующее:
SC говорит, что программа будет выполнена в execution order (он же memory order), который консистентен с program order
SC говорит, что если произошла запись ранее (по порядку) в memory order, то мы увидим эту запись. Но SC не говорит, когда будет видна запись
Sequential consistency можно имплементировать или исполняя все на одном ядре, или исполняя на многоядерном процессоре, но имея блокирующий "switch", который разрешает доступ к памяти только ядру (треду) за раз, причем в program order:

Теперь снова вернемся к Dekker алгоритму и рассмотрим его в рамках sequential consistency. Благодаря тому, что в Dekker алгоритме
x = 1POr1 = y,y = 1POr2 = x(PO = program order), то SC соблюдет этот порядок и выполнит чтения только после одной из записей.Но здесь действительно есть подвох: пропагация записи может занять и год, и два, и вообще не случиться. Со стороны модели главное то, что и чтение не будет выполнено, пока не завершится запись. Но нам то этого не достаточно - мы хотим увидеть эту запись когда-нибудь.
Таким образом, если мы не гарантируем eventual visibility для записей, то это не нарушит sequential consistency модель.
В итоге хочу сказать, что вы правы. Я поискал по всей спеке слова "visibility" и "eventual" и не нашел ни единого подтверждения этому.
quackQZS
01.09.2022 16:08+1Хорошо, что в итоге разобрались.
Похожее обсуждение было недавно на stackoverflow.
Видимо подобные вопросы продолжат возникать у java-программистов и в будущем.
И возможно эта ветка комментариев кому-нибудь из них поможет разобраться.
-
quackQZS
31.08.2022 23:51+1Кстати, даже если эта цитата действительно означает eventual visibility для
volatile, то это будет работать только в data-race-free программах (ведь java гарантирует Sequential consistency только в таких случаях).Как мы знаем, программа data-race-free только если в ней вообще нет data race.
В итоге, стоит только добавить в java-приложение какой-нибудь тестовый класс с data race внутри, и гарантия eventual visibility дляvolatileисчезает сразу во всех классах нашего приложения.Кроме того, в
String.hashCode()чтение и запись поляhash- это data race.
Получается тем, кто в java хочет eventual visibility дляvolatile, нельзя использовать строки.blinky-z Автор
01.09.2022 12:40Я это вижу так, что в JMM только некоторый набор операций может быть быть выполнен в SC memory order. Если есть другие data race, то для них не гарантируется никакого консистентного порядка, но для связанных happens-before гарантируется. Кажется, на этом делает акцент и спека:
A set of actions is sequentially consistent if all actions occur in a total order
blinky-z Автор
01.09.2022 15:03Да, и здесь я должен исправиться. SC никак не связана с eventual visibility, и в частности эта цитата совсем не означает eventual visibility - выше ответил.

anfanik
Продвинулся в понимании того, с чем работаю, спасибо!
blinky-z Автор
Рад стараться!