
В какой-то момент времени я превратился в педанта брюзгу. В фильмах малейшие нестыковки и провалы в логике портят мне весь просмотр. В чатах меня бесит it's вместо its. А в статьях про программирование... Всё плохо. За меня всё уже сказал @AlexanderAstafiev, я лишь процитирую:
Простите, я не могу так больше. Я слишком хорошо знаю Python, чтобы молчать при виде такого кода.
Я устал. Я не могу это читать. Простите за токсичную критику, накипело.
Самое забавное, что, по моим ощущениям, везде я вижу одни и те же классы проблем. Я даже запилил сервис, где можно закинуть код и получить код ревью, и, собрав немного статистики, понял, что 50 типов ошибок достаточно, чтобы покрыть большую часть проблем в чужом коде. Но выборка у меня была небольшая, и я подумал: а что, если проверить много кода? И всё заверте...
Давайте вспомним про гругов

Где-то тут проскакивала замечательная статья про гругов: на русском, на английском.
разработчик с мозгом груга не очень умный, но разработчик с мозгом груга программирует много лет и научился кое чему, хоть всё равно часто запутывается
Я как прочитал её, так сразу и понял: это я. Не очень умный программист, но за плечами горы опыта, и это формирует мой подход к написанию кода: не усложняй. На работе у нас есть чел - большая голова, он держит весь проект в своей "оперативной памяти" и пишет просто полотна кода с кучей ветвлений, и где-то в конце он ещё помнит, что в начале был if и нужно рассмотреть else. Я так не могу, я когда прыгаю jump-to-definition, на четвёртом уровне вложенности уже забываю, откуда я пришёл и что я делал. Я как бельчонок с хорошеньким хвостиком, если вы понимаете, о чём я.
Что же касается бельчонка, то он сидел в лесной чаще и рассеянно поглядывал то на одно дерево, то на другое. Он не мог, даже если бы пришлось пожертвовать своим хвостиком, вспомнить, в дупле какого дерева он жил и вообще ради чего он прискакал в лес и что там искал.
Я не могу писать большие и сложные штуки, а если и напишу, то там же и умру. Поэтому философия гругов мне очень подходит:
главный охотник на груга это сложность
сложность плохо
скажу снова:
сложность очень плохо
теперь ты скажи сам:
сложность очень, очень плохо
если выбрать между сложность и биться с динозавром, груг выбери динозавр: груг хотя бы видеть динозавра
И в этой статье я хотел немного поделиться тем, как можно бороться со сложностью в питоне.
Разработчик с мозгом груга хочет собрать знания в маленькую, простую и интересную страницу
Если вы умный
... то всё равно нужно стремиться упрощать. Потому что если вы пишете статью или вкладываете что-то в опенсорс, ваш код (внезапно) читают и/или запускают. Давайте заботиться о пользователях вашего кода? Кстати, пользователем вашего когда можете стать вы сами через несколько лет.
Что значит "упрощать" и "заботиться о пользователях"?
Я понимаю это как написание кода, который
легко читать
легко изменять
легко отлаживать
легко тестировать
Как писать такой код? Использовать линтеры и мозг, чтобы уменьшать сложность. Давайте обсудим типичные ошибки и антипаттерны.
Ты не сможешь рассмотреть все возможные ошибки
Действительно, выстрелить себе в ногу можно миллионом способов, особенно в динамически типизированном языке. Но мне поможет мой хоуми aka Николай Гумилёв Вильфредо Парето.

Закон Парето
В большинстве случаев около 80% результата происходят из 20% причин.
А вдруг мы можем рассмотреть топ 20% ошибок и надеяться, что покроем 80% случаев?
А как ты узнаешь самые распространённые ошибки?
Автоматически.
Вообще не всё можно отловить программно. Например, плохой дизайн классов и модулей. Как-то я видел что-то вроде:
def swagger_support(func):
@wraps(func)
def wrapper(self, *args, **kwargs):
if args[0] == 1:
return getattr(super(type(self), self), func.__name__)(*args, **kwargs)
else:
return func(self, *args, **kwargs)
return wrapper
Не знаю, какой там был контекст, но если в зависимости от какого-то параметра вызывается либо родительский метод, либо метод наследника, то, возможно, где-то на уровне выше нужно было в зависимости от параметра передать либо объект родителя, либо объект наследника - наследование так и работает, оно переопределяет метод, вместо того чтобы заставлять вас писать if. Как подобное отлавливать - я не знаю. Это самый интересный класс ошибок, но в этой статье их не будет, сорян.
Итак, как автоматически искать ошибки? Для этого я построю вундервафлю, прям как аннигилятор в "Полицейский из Беверли-Хиллз 3".

Если эта штука напоминает вам flake8 с плагинами, то вы угадали - это он и есть.
Почему не pylint | mypy | dlint | black | ...? Мне нужен был линтер (не форматтер), в котором есть максимальное число подходящих мне плагинов, и для которого я мог бы легко написать свои. Flake8 мне показался наиболее подходящим.
Итак, я прошёлся по awesome flake8, поскрёб по закоулкам гитхаба, написал свой мини-плагин с тем, чего не хватало, и получилось вот это:
flake8==5.0.4
flake8-json==21.7.0
flake8-adjustable-complexity==0.0.6
flake8-annotations-coverage==0.0.6
flake8-annotations==2.9.1
flake8-builtins==1.5.3
flake8-cognitive-complexity==0.1.0
flake8-commas==2.1.0
flake8-comprehensions==3.10.0
flake8-eradicate==1.3.0
flake8-expression-complexity==0.0.11
flake8-functions==0.0.7
flake8-simplify==0.19.3
flake8-scream==0.1.0
git+https://github.com/i02sopop/flake8-global-variables
pep8-naming==0.13.1
flake8-bugbear==22.7.1
flake8-pie==0.16.0
flake8-print==5.0.0
flake8-use-pathlib==0.3.0
git+https://github.com/c0ntribut0r/flake8-grug
pylint==2.14.5
flake8-pylint==0.1.3
Я постарался отобрать те плагины, которые сделают код чище, но не стал включать спорные штуки (например, всякие следилки за докстрингами) и базовые и очевидные вещи (форматирование, всякие там отступы и пробелы). Даже среди того, что я выбрал, было много мусора, поэтому я отбирал ошибки поштучно, если интересно - вот мой .flake8, он человекочитаем:
.flake8
[flake8]
# statistics = True
select =
# -------- https://github.com/best-doctor/flake8-adjustable-complexity --------
CAC001,
# func is too complex (complexity > max allowed complexity)
CAC002,
# func is too complex (complexity). Bad variable names penalty is too high (penalty)
# -------- https://github.com/best-doctor/flake8-annotations-coverage --------
TAE001,
# Too few type annotations in file
# -------- https://github.com/sco1/flake8-annotations --------
ANN001,
# Missing type annotation for function argument
ANN002,
# Missing type annotation for *args
ANN003,
# Missing type annotation for **kwargs
; ANN101,
# Missing type annotation for self in method
; ANN102,
# Missing type annotation for cls in classmethod
ANN201,
# Missing return type annotation for public function
ANN202,
# Missing return type annotation for protected function
ANN203,
# Missing return type annotation for secret function
ANN204,
# Missing return type annotation for special method
ANN205,
# Missing return type annotation for staticmethod
ANN206,
# Missing return type annotation for classmethod
ANN301,
# PEP 484 disallows both type annotations and type comments
ANN401,
# Dynamically typed expressions (typing.Any) are disallowed.2
# -------- https://github.com/gforcada/flake8-builtins --------
A001,
# variable "max" is shadowing a python builtin
A002,
# argument "dict" is shadowing a python builtin
# -------- https://github.com/Melevir/flake8-cognitive-complexity --------
CCR001,
# Cognitive complexity is too high (X > Y)
# -------- https://github.com/PyCQA/flake8-commas --------
# C812, # too many FPs
# missing trailing comma
C813,
# missing trailing comma in Python 3
# C814,
# missing trailing comma in Python 2
C815,
# missing trailing comma in Python 3.5+
C816,
# missing trailing comma in Python 3.6+
C818,
# trailing comma on bare tuple prohibited
C819,
# trailing comma prohibited
# -------- https://github.com/adamchainz/flake8-comprehensions --------
C400,
C401,
C402,
# Unnecessary generator - rewrite as a <list/set/dict> comprehension.
C403,
C404,
# Unnecessary list comprehension - rewrite as a <set/dict> comprehension.
C405,
C406,
# Unnecessary <list/tuple> literal - rewrite as a <set/dict> literal.
# C408,
# Unnecessary <dict/list/tuple> call - rewrite as a literal.
C409,
C410,
# Unnecessary <list/tuple> passed to <list/tuple>() - (remove the outer call to <list/tuple>``()/rewrite as a ``<list/tuple> literal).
C411,
# Unnecessary list call - remove the outer call to list().
C413,
# Unnecessary <list/reversed> call around sorted().
C414,
# Unnecessary <list/reversed/set/sorted/tuple> call within <list/set/sorted/tuple>().
C415,
# Unnecessary subscript reversal of iterable within <reversed/set/sorted>().
C416,
# Unnecessary <list/set> comprehension - rewrite using <list/set>().
C417,
# Unnecessary map usage - rewrite using a generator expression/<list/set/dict> comprehension.
# -------- https://github.com/wemake-services/flake8-eradicate --------
# E800,
# Found commented out code
# -------- https://github.com/best-doctor/flake8-expression-complexity --------
ECE001,
# Expression is too complex (X > Y)
# -------- https://github.com/best-doctor/flake8-functions --------
CFQ001,
# function length (default max length is 100)
# CFQ002,
# function arguments number (default max arguments amount is 6)
CFQ003,
# function is not pure.
; CFQ004,
# function returns number (default max returns amount is 3)
# -------- https://github.com/MartinThoma/flake8-simplify --------
# Python-specific rules:
SIM101,
# Multiple isinstance-calls which can be merged into a single call by using a tuple as a second argument (example)
SIM104,
#: Use 'yield from iterable' (introduced in Python 3.3, see PEP 380) (example)
SIM105,
# Use 'contextlib.suppress(...)' instead of try-except-pass (example)
SIM107,
# Don't use return in try/except and finally (example)
SIM108,
# Use the ternary operator if it's reasonable (example)
SIM109,
# Use a tuple to compare a value against multiple values (example)
SIM110,
# Use any(...) (example)
SIM111,
# Use all(...) (example)
SIM113,
# Use enumerate instead of manually incrementing a counter (example)
SIM114,
# Combine conditions via a logical or to prevent duplicating code (example)
SIM115,
# Use context handler for opening files (example)
SIM116,
# Use a dictionary instead of many if/else equality checks (example)
SIM117,
# Merge with-statements that use the same scope (example)
SIM119,
# Moved to flake8-scream due to issue 63
SIM120,
#: Use 'class FooBar:' instead of 'class FooBar(object):' (example)
SIM121,
# Reserved for SIM908 once it's stable
SIM125,
# Reserved for SIM905 once it's stable
SIM126,
# Reserved for SIM906 once it's stable
SIM127,
# Reserved for SIM907 once it's stable
# Simplifying Comparisons:
SIM201,
# Use 'a != b' instead of 'not a == b' (example)
SIM202,
# Use 'a == b' instead of 'not a != b' (example)
SIM203,
# Use 'a not in b' instead of 'not (a in b)' (example)
SIM204,
# Moved to flake8-scream due to issue 116
SIM205,
# Moved to flake8-scream due to issue 116
SIM206,
# Moved to flake8-scream due to issue 116
SIM207,
# Moved to flake8-scream due to issue 116
SIM208,
# Use 'a' instead of 'not (not a)' (example)
SIM210,
# Use 'bool(a)' instead of 'True if a else False' (example)
SIM211,
# Use 'not a' instead of 'False if a else True' (example)
SIM212,
# Use 'a if a else b' instead of 'b if not a else a' (example)
SIM220,
# Use 'False' instead of 'a and not a' (example)
SIM221,
# Use 'True' instead of 'a or not a' (example)
SIM222,
# Use 'True' instead of '... or True' (example)
SIM223,
# Use 'False' instead of '... and False' (example)
SIM224,
# Reserved for SIM901 once it's stable
SIM300,
# Use 'age == 42' instead of '42 == age' (example)
# Simplifying usage of dictionaries:
SIM401,
# Use 'a_dict.get(key, "default_value")' instead of an if-block (example)
SIM118,
# Use 'key in dict' instead of 'key in dict.keys()' (example)
# General Code Style:
SIM102,
# Use a single if-statement instead of nested if-statements (example)
SIM103,
# Return the boolean condition directly (example)
SIM106,
# Handle error-cases first (example). This rule was removed due to too many false-positives.
SIM112,
# Use CAPITAL environment variables (example)
SIM122,
#/ SIM902: Moved to flake8-scream due to issue 125
SIM123,
#/ SIM902: Moved to flake8-scream due to issue 130
SIM124,
# Reserved for SIM909 once it's stable
# Current experimental rules:
SIM901,
# Use comparisons directly instead of wrapping them in a bool(...) call (example)
SIM904,
# Assign values to dictionary directly at initialization (example)
SIM905,
# Split string directly if only constants are used (example)
SIM906,
# Merge nested os.path.join calls (example)
SIM907,
# Use Optional[Type] instead of Union[Type, None] (example)
SIM908,
# Use dict.get(key) (example)
SIM909,
# Avoid reflexive assignments (example)
# -------- https://github.com/MartinThoma/flake8-scream --------
SCR119,
#: Use dataclasses for data containers (example)
SCR902,
# Use keyword-argument instead of magic boolean (example)
SCR903,
# Use keyword-argument instead of magic number (example)
# -------- https://github.com/i02sopop/flake8-global-variables --------
# W001,
# Global variable {0} defined
W002,
# Global variable {0} used
# ---- https://github.com/PyCQA/pep8-naming ----
# N801,
# class names should use CapWords convention (class names)
# N802,
# function name should be lowercase (function names)
# N803,
# argument name should be lowercase (function arguments)
N804,
# first argument of a classmethod should be named 'cls' (function arguments)
N805,
# first argument of a method should be named 'self' (function arguments)
N806,
# variable in function should be lowercase
N807,
# function name should not start and end with '__'
N811,
# constant imported as non constant (constants)
N812,
# lowercase imported as non-lowercase
N813,
# camelcase imported as lowercase
N814,
# camelcase imported as constant (distinct from N817 for selective enforcement)
N815,
# mixedCase variable in class scope (constants, method names)
N816,
# mixedCase variable in global scope (constants)
N817,
# camelcase imported as acronym (distinct from N814 for selective enforcement)
N818,
# error suffix in exception names (exceptions)
# -------- https://github.com/PyCQA/flake8-bugbear --------
B001,
# Do not use bare except:, it also catches unexpected events like memory errors, interrupts, system exit, and so on. Prefer except Exception:. If you're sure what you're doing, be explicit and write except BaseException:. Disable E722 to avoid duplicate warnings.
B002,
# Python does not support the unary prefix increment. Writing ++n is equivalent to +(+(n)), which equals n. You meant n += 1.
B003,
# Assigning to os.environ doesn't clear the environment. Subprocesses are going to see outdated variables, in disagreement with the current process. Use os.environ.clear() or the env= argument to Popen.
B004,
# Using hasattr(x, '__call__') to test if x is callable is unreliable. If x implements custom __getattr__ or its __call__ is itself not callable, you might get misleading results. Use callable(x) for consistent results.
B005,
# Using .strip() with multi-character strings is misleading the reader. It looks like stripping a substring. Move your character set to a constant if this is deliberate. Use .replace() or regular expressions to remove string fragments.
B006,
# Do not use mutable data structures for argument defaults. They are created during function definition time. All calls to the function reuse this one instance of that data structure, persisting changes between them.
B007,
# Loop control variable not used within the loop body. If this is intended, start the name with an underscore.
B008,
# Do not perform function calls in argument defaults. The call is performed only once at function definition time. All calls to your function will reuse the result of that definition-time function call. If this is intended, assign the function call to a module-level variable and use that variable as a default value.
B009,
# Do not call getattr(x, 'attr'), instead use normal property access: x.attr. Missing a default to getattr will cause an AttributeError to be raised for non-existent properties. There is no additional safety in using getattr if you know the attribute name ahead of time.
B010,
# Do not call setattr(x, 'attr', val), instead use normal property access: x.attr = val. There is no additional safety in using setattr if you know the attribute name ahead of time.
B011,
# Do not call assert False since python -O removes these calls. Instead callers should raise AssertionError().
B012,
# Use of break, continue or return inside finally blocks will silence exceptions or override return values from the try or except blocks. To silence an exception, do it explicitly in the except block. To properly use a break, continue or return refactor your code so these statements are not in the finally block.
B013,
# A length-one tuple literal is redundant. Write except SomeError: instead of except (SomeError,):.
B014,
# Redundant exception types in except (Exception, TypeError):. Write except Exception:, which catches exactly the same exceptions.
B015,
# Pointless comparison. This comparison does nothing but waste CPU instructions. Either prepend assert or remove it.
B016,
# Cannot raise a literal. Did you intend to return it or raise an Exception?
B017,
# self.assertRaises(Exception): should be considered evil. It can lead to your test passing even if the code being tested is never executed due to a typo. Either assert for a more specific exception (builtin or custom), use assertRaisesRegex, or use the context manager form of assertRaises (with self.assertRaises(Exception) as ex:) with an assertion against the data available in ex.
B018,
# Found useless expression. Either assign it to a variable or remove it.
B019,
# Use of functools.lru_cache or functools.cache on methods can lead to memory leaks. The cache may retain instance references, preventing garbage collection.
B020,
# Loop control variable overrides iterable it iterates
B021,
# f-string used as docstring. This will be interpreted by python as a joined string rather than a docstring.
B022,
# No arguments passed to contextlib.suppress. No exceptions will be suppressed and therefore this context manager is redundant. N.B. this rule currently does not flag suppress calls to avoid potential false positives due to similarly named user-defined functions.
B023,
# Functions defined inside a loop must not use variables redefined in the loop, because late-binding closures are a classic gotcha.
# -------- https://github.com/sbdchd/flake8-pie --------
; PIE781,
# assign-and-return
# Based on Clippy's let_and_return and Microsoft's TSLint rule no-unnecessary-local-variable.
# PIE783,
# celery-explicit-names
# Warn about Celery task definitions that don't have explicit names.
# PIE784,
# celery-explicit-crontab-args
# The crontab class provided by Celery has some default args that are suprising to new users. Specifically, crontab(hour="0,12") won't run a task at midnight and noon, it will run the task at every minute during those two hours. This lint makes that call an error, forcing you to write crontab(hour="0, 12", minute="*").
# PIE785,
# celery-require-tasks-expire
# Celery tasks can bunch up if they don't have expirations.
PIE786,
# precise-exception-handlers
# Be precise in what exceptions you catch. Bare except: handlers, catching BaseException, or catching Exception can lead to unexpected bugs.
PIE787,
# no-len-condition
# Empty collections are fasley in Python so calling len() is unnecessary when checking for emptiness in an if statement/expression.
PIE788,
# no-bool-condition
# If statements/expressions evalute the truthiness of the their test argument, so calling bool() is unnecessary.
PIE789,
# prefer-isinstance-type-compare
# Using type() doesn't take into account subclassess and type checkers won't refine the type, use isinstance instead.
PIE790,
# no-unnecessary-pass
# pass is unnecessary when definining a class or function with an empty body.
PIE791,
# no-pointless-statements
# Comparisions without an assignment or assertion are probably a typo.
# PIE792, # same as SIM120
# no-inherit-object
# Inheriting from object isn't necessary in Python 3.
PIE793,
# prefer-dataclass
# Attempts to find cases where the @dataclass decorator is unintentionally missing.
PIE794,
# dupe-class-field-definitions
# Finds duplicate definitions for the same field, which can occur in large ORM model definitions.
PIE795,
# prefer-stdlib-enums
# Instead of defining various constant properties on a class, use the stdlib enum which typecheckers support for type refinement.
PIE796,
# prefer-unique-enums
# By default the stdlib enum allows multiple field names to map to the same value, this lint requires each enum value be unique.
PIE797,
# no-unnecessary-if-expr
# Call bool() directly rather than reimplementing its functionality.
PIE798,
# no-unnecessary-class
# Instead of using class to namespace functions, use a module.
PIE799,
# prefer-col-init
# Check that values are passed in when collections are created rather than creating an empty collection and then inserting.
PIE800,
# no-unnecessary-spread
# Check for unnecessary dict unpacking.
PIE801,
# prefer-simple-return
# Return boolean expressions directly instead of returning True and False.
PIE802,
# prefer-simple-any-all
# Remove unnecessary comprehensions for any and all
PIE803,
# prefer-logging-interpolation
# Don't format strings before logging. Let logging interpolate arguments.
PIE804,
# no-unnecessary-dict-kwargs
# As long as the keys of the dict are valid Python identifier names, we can safely remove the surrounding dict.
# PIE805,
# prefer-literal
# Currently only checks for byte string literals.
PIE806,
# no-assert-except
# Instead of asserting and catching the exception, use an if statement.
PIE807,
# prefer-list-builtin
# lambda: [] is equivalent to the builtin list
PIE808,
# prefer-simple-range
# We can leave out the first argument to range in some cases since the default start position is 0.
PIE809,
# django-prefer-bulk
# Bulk create multiple objects instead of executing O(N) queries.
# -------- https://github.com/JBKahn/flake8-print --------
T201,
# print found
T203,
# pprint found
T204,
# pprint declared
# -------- https://gitlab.com/RoPP/flake8-use-pathlib --------
PL100,
# os.path.abspath("foo") should be replaced by foo_path.resolve()
PL101,
# os.chmod("foo", 0o444) should be replaced by foo_path.chmod(0o444)
PL102,
# os.mkdir("foo") should be replaced by foo_path.mkdir()
PL103,
# os.makedirs("foo/bar") should be replaced by bar_path.mkdir(parents=True)
PL104,
# os.rename("foo", "bar") should be replaced by foo_path.rename(Path("bar"))
PL105,
# os.replace("foo", "bar") should be replaced by foo_path.replace(Path("bar"))
PL106,
# os.rmdir("foo") should be replaced by foo_path.rmdir()
PL107,
# os.remove("foo") should be replaced by foo_path.unlink()
PL108,
# os.unlink("foo") should be replaced by foo_path.unlink()
PL109,
# os.getcwd() should be replaced by Path.cwd()
PL110,
# os.path.exists("foo") should be replaced by foo_path.exists()
PL111,
# os.path.expanduser("~/foo") should be replaced by foo_path.expanduser()
PL112,
# os.path.isdir("foo") should be replaced by foo_path.is_dir()
PL113,
# os.path.isfile("foo") should be replaced by foo_path.is_file()
PL114,
# os.path.islink("foo") should be replaced by foo_path.is_symlink()
PL115,
# os.readlink("foo") should be replaced by foo_path.readlink()
PL116,
# os.stat("foo") should be replaced by foo_path.stat() or foo_path.owner() or foo_path.group()
PL117,
# os.path.isabs should be replaced by foo_path.is_absolute()
PL118,
# os.path.join("foo", "bar") should be replaced by foo_path / "bar"
PL119,
# os.path.basename("foo/bar") should be replaced by bar_path.name
PL120,
# os.path.dirname("foo/bar") should be replaced by bar_path.parent
PL121,
# os.path.samefile("foo", "bar") should be replaced by foo_path.samefile(bar_path)
PL122,
# os.path.splitext("foo.bar") should be replaced by foo_path.suffix
PL123,
# open("foo") should be replaced by Path("foo").open()
PL124,
# py.path.local is in maintenance mode, use pathlib instead
# -------- https://github.com/c0ntribut0r/flake8-grug --------
GRG001,
# copy-paste
GRG002,
# early quit
GRG003,
# eval
GRG004,
# try too much
GRG005,
# requests no status check
Маленькие открытия, пока я всё это собирал:
Нашёл репо от команды BestDoctor. Они написали несколько плагинов для flake8, плюс вообще у них приятно - рекомендую python styleguide и погулять по репе. BestDoctor, оплату переводите на карту, как и договаривались.
flake8-simplify тоже вполне хорош, я джва года искал набор таких правил
Всякие code quality tools живут в PyCQA, могут пригодиться
Аннигилятор уже изобрели в wemake, но мне не все правила подходили, и у него фатальный недостаток
Когда после всех настроек я запустил аннигилятор, я понял: я создал такого же брюзгу, как я. Ура!

Только посмотрите:
И когда мой мега-линтер начал подсвечивать мой собственный код и бесить меня, я понял: он готов к работе.
Время запускать аннигилятор
Всё началось со статей Хабра, поэтому я решил соскрапать их все и скормить flake8. Я написал простую обёртку над Хабром и оставил на ночь. А потом запустил аннигилятор на всех постах.
flake8 --config .flake8 --format json samples/posts/ > results/posts-results.jsonВот цифры:
115,661 статья в потоке "разработка"
5,500 постов в Хабе "python"
1,723 поста про питон без кода или код меньше 5 строчек
¯\_(ツ)_/¯
Кодом я считал секции с тегом <code>. Иногда там не код, а командная строка или дурацкое форматирование, так что где flake8 смог переварить - хорошо, где не смог - не обессудьте.
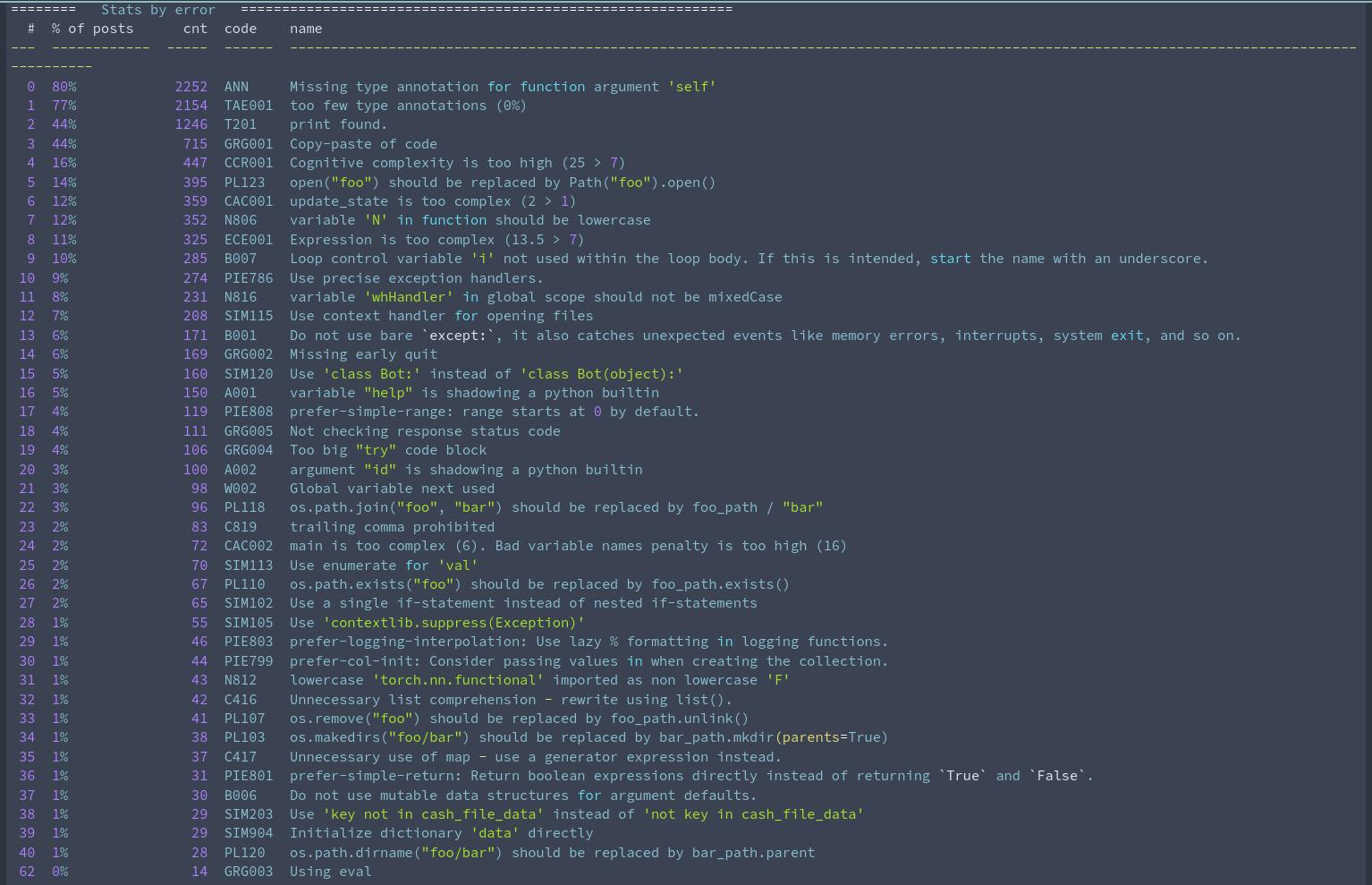
Total posts: 2,791
Overall issues: 63,614
Unique issues (one per post): 12,166И вот, наконец, долгожданная статистика.
% of posts- процент постов, в которых ошибка встечалась хотя бы один разcnt- то же, но в абсолютном значении (количество)code- код ошибки в Flake8-
name- пример текста ошибки, может отличаться от случая к случаю
Ну что, поехали?

Мы прогуляемся по топчику из списка, и ещё я добавлю немного того, что не попало в список, потому что я не запрограммировал или запрограммировать невозможно.
Чтобы не сойти с ума, разобьём всё по секциям, упомянутым выше. Устранив ошибки секции, код можно будет
легко читать
легко изменять
легко отлаживать
легко тестировать
Легко читать
Легко читать > Самодокументация
Лень - двигатель прогресса. Ленивые программисты не любят писать документацию (да и кто вообще любит?), поэтому они стараются писать код, который сам себя документирует и его можно читать как книгу. Бонусом идёт то, что документация всегда в актуальном состоянии.
Легко читать > Самодокументация > Типы
Это питонушка. Тут в переменной может быть всё что угодно, хотите int, хотите гетерогенный список объектов вперемежку со словарями и числами с плавающей точкой. Считаю ли я это преимуществом питона? Нет. В большинстве случаев такая гибкость не нужна, и на этапе написания кода известно, где какие типы, так почему бы это не использовать ? (извините, не удержался от пропаганды)
Но мы имеем то, что имеем:
def fn(items):
# ...
Проблема: а что можно подавать в items, и что возвращается из fn?
Решение 1: смотреть код.
Топорное решение - посмотреть код и понять. И никто не гарантирует успех - может, вы поймёте, что items - это коллекция каких-то объектов, но вот чтобы понять, каких - нужно будет попрыгать по вызовам функции fn и посмотреть, что туда передаётся. Ну такое.
Решение 2: смотреть docstring.
Пещерные люди жили в неведении, но потом открыли для себя докстринги, где можно писать, что делает функция, что получает и что возвращает.
def fn(items):
"""
Sort items using mega-algo.
Args:
items: list - list of items
Returns:
list of sorted elements
"""
# ...
Это почти нормально, если бы не:
разные стили: где-то google-style, где-то sphinx-style
много писать (но помогают плагины)
нужно всё время следить за актуальностью: убрали аргумент, добавили аргумент, поменяли название - будьте добры обновить докстринг (я всё время забываю)
Решение 3: смотреть type hints
Потом пещерные люди посмотрели на статически типизированные языки и внезапно увидели, что это удобно, и захотели так же. Ну хотя бы чтоб было похоже. Поэтому вот:
from typing import List, Union, Optional
def fn(items: List[Optional[Union[int, float]]]) -> list[Union[int, float]]:
# ...
Смешно, что, хотя для items объявлен тип, по факту вы можете передать туда что угодно. Поэтому всё равно нужно следить, что куда передаётся, но, по крайней мере, это проще, и всякие линтеры могут помогать.
Решение 4: использовать python >= 3.10 и не импортировать лишнего
Наконец, пещерные люди посмотрели на List[Optional[Union[int, float]]], прифигели немного (это ведь только один аргумент!) и решили всё упростить:
def fn(items: list[int | float | None]) -> list[int, float]: # а ещё лучше TypeVar ;)
# ...
Согласитесь, эволюция налицо. Но проблемы всё равно есть:
type hints могут быть слишком большими. Постоянная тема:
dict[str, list[dict]]- это что вообще там? Если это тип для аргумента, то название аргумента подскажет, что имел в виду автор. А если это тип возвращаемого значения, то...return type hint никак не помогает!
Вот посмотрите сами:
def get_orientation(obj: Ufo) -> tuple[float, float, float]: # WAT? это что такое?
# ...
return pitch, roll, yaw # plot twist: я прочитал функцию до конца и узнал, что было в начале
Решение тут пока - в использовании namedtuple или иных заранее определённых типов для возвращаемого значения, но как по мне - слишком много boilerplate кода:
from collections import namedtuple
Orientation = namedtuple('FunctionResult', ('pitch', 'roll', 'yaw'))
def get_orientation(obj: Ufo) -> Orientation:
# ...
return Orientation(
pitch=...,
roll=...,
yaw=...,
)
Выглядит ужасно. Да здравствует питон!
Решение 5?
И пока пещерные люди выходят на новый виток эволюции, большинство разработчиков вообще живут мимо эволюции и не используют type annotations - в 80% постов они отсутствуют.
0 80% 2252 ANN Missing type annotation for function argument 'self'
1 77% 2154 TAE001 too few type annotations (0%)
Почему? Я не знаю. Питон 3.5 (а с ним и аннотации типов) вышел 7 лет назад!

Поэтому я напишу это здесь ещё раз: пожалуйста, используйте type hints. Это не сложно (кроме Generator[yield type, send type, return type], они реально бесят).
Легко читать > Самодокументация > Название функции
Ладно, вот вам новая проблема: что делает функция?
def fn(items: list[int | float | None]) -> list[int, float]:
Правильный ответ: а хрен её знает!
Решение 1: читать код
def fn(items: list[int]) -> list[int]:
return sorted(items, key=math.sin)
Сложность: O(n). Нет, пожалуйста.
Решение 2: читать docstring
def fn(items: list[int]) -> list[int]:
"""Sorts items by their sin() values"""
# ...
Это удобнее, но, как я уже говорил, эти докстринги должны быть, причём в актуальном состоянии.
Решение 3: нормально называть
def sorted_by_sin(items: list[int]) -> list[int]:
# ...
Тут сразу понятно: итемсы сортируются по грехам их. Стоп, что?
Ну короче вы поняли. Правильное название функции и короткий, читаемый код заменяют docstring. Признаться, раньше я был свидетелем докстринговым и везде старался их писать, но теперь я их пишу только во всяких публичных функциях публичных либ, чтобы документация красиво собиралась.
Вопрос в кассу: как проверить, что название хорошее? Ответ: люди в чёрном.

Берёте Уилла Смита, он стирает вам память, после чего показывает аннотацию функции. Если вы примерно угадываете, что функция делает - название хорошее.
Легко читать > Самодокументация > Названия переменных
Та же тема с названиями переменных. Дополнительно хочу отметить: никто вас не наругает, если вы используете несколько слов в названии переменной, и она вдруг от этого станет понятной.
Если хорошее название - дело субъективное, то вот переопределение встроенных символов (например, list, set, next) - очевидное зло. Чтобы вы не теряли бдительность, в 5% постов авторы переопределяют встроенные символы при помощи переменных, а в 3% - при помощи аргументов.
5% 150 A001 variable "xxx" is shadowing a python builtin
3% 100 A002 argument "xxx" is shadowing a python builtin
2% 72 CAC002 function is too complex. Bad variable names penalty is too highЯ написал скрипт, который по коду ошибки выдаёт примеры прям из статей с Хабра, так что вот живой пример: какой-то дурачок переопределил repr.
def repr(group_start, group_end) -> str: # <--------------------------------!!!
# это просто правильно печатает группу
if last_group_start == last_group_end:
return str(last_group_end)
Что-то знакомое... Блин, да это ж я! Так, забыли.
Как понять, что название хорошее?

Легко читать > Самодокументация > Комментарии
Тут всё просто: код рассказывает компьютеру, что делать. Когда человек читает код, он понимает, что компьютер будет делать. Поэтому в большинстве случаев комментировать это не надо. Такие комментарии только занимают место и не приносят никакой пользы.
# делаем проверку по индексу 26
data.loc[26]Но вот если после Уилла Смита вы не понимаете, что делает этот код (или зачем) - комментарий будет совсем не лишним:
Легко читать > Low RAM
Я уже говорил, что у меня в голове место ограничено, поэтому я стараюсь как можно сильнее снизить когнитивную нагрузку - иначе говоря, минимизировать количество информации, которую мне нужно держать в голове. Для этого я стараюсь уменьшать, разбивать и упрощать функции.
Легко читать > Low RAM > Невысокая функция
Тут всё просто: чем короче функция, тем проще её понять.
Разбитие функции
Функция слишком длинная? Рецепт прост: разбейте её на несколько! Увы, в 16% постов авторы пишут мега-функции:
16% 447 CCR001 Cognitive complexity is too high
12% 359 CAC001 function is too complexНу вот, например:
def run(self):
pixels = pygame.surfarray.pixels3d(self.display)
index = 0
running = True
while running:
self.model.stimulate()
pixels[:, :, :] = (255 * (self.model.activity > 0))[:, :, None]
pygame.display.flip()
for event in pygame.event.get():
if event.type == pygame.QUIT:
running = False
elif event.type == pygame.KEYDOWN:
if event.key == pygame.K_ESCAPE:
running = False
elif event.key == pygame.K_s:
imsave("{0:04d}.png".format(index), pixels[:, :, 0])
index = index + 1
elif event.type == pygame.MOUSEBUTTONDOWN:
position = pygame.mouse.get_pos()
self.model.activity[position] = 1
Тут игровой цикл, где смешались вызов симуляции, отрисовка пикселей, обработка клавиатуры, скриншоты... Как упростить? Разбейте на функции:
def run(self):
while self.is_running:
self.model.simulate()
self.draw()
self.handle_input()
Группировка присваиваний в one-liner
Магическое превращение четырёх строчек в одну! Следите за руками:
if a > b:
max_ = a
else:
max_ = b
# ...вжух!
max_ = a if a > b else b
Я люблю такие присваивания, потому что они занимают меньше места. Но ещё важная фишка в том, что у меня одно присваивание в коде вместо двух, значит, меньше шансов на ошибку.
Легко читать > Low RAM > Неширокая функция
Когда у вас слишком много отступов в коде - это знак, что что-то можно упростить. Например:
Циклы
Если у вас в цикле много всего, то можно это всё вынести в отдельную функцию. Вы не только упрощаете код, но и "сдвигаете" всё из цикла на один уровень вложенности меньше:
def run():
for event in pygame.event.get():
if event.type == pygame.QUIT: # тут уровень отступов == 2
running = False # тут уровень отступов == 3
# ...
# ...вжух!
def process_event(event: Event):
if event.type == pygame.QUIT: # тут уровень отступов == 1
running = False # тут уровень отступов == 2
# ...
def run():
for event in pygame.event.get():
process_event(event)
Мини-бонус: если в цикле вызывается одна функция, то этот цикл очень просто распараллелить (при помощи ThreadPoolExecutor, например).
Длинные выражения
Ну любит народ писать зубодробительные выражения (11%):
11% 325 ECE001 Expression is too complex (13.5 > 7)Вот, например:
# constraints on communist's or zhulik's votes
def findVariants(s, aim, cnt, suffix):
s.add((r9916['com'] - aim['com'] == \ # <--------------------------------!!!
Sum([If(Bool('v_%d_%s' % (i, suffix)), rewritten_pecs[i]['increase']['com'], 0) for i in range(19)]) + \
Sum([If(Bool('a_%d_%s' % (k, suffix)), 0, approved_pecs[k]['first']['com']) for k in range(53)])))
Я не знаю, что можно сделать с выражением выше, но если у вас какая-то строчка эпической длины, то хотя бы попробуйте разбить её на несколько - так легче читается. В этом очень помогают скобки, ведь то, что нельзя делать в обычном мире, в мире скобок дозволено.
Вот тут скобки позволяют писать + что-то с новой строчки, да ещё и комментарии можно добавлять:
missing_set = ( # <--------------------------------!!!
[(all_letters, '-' * len(all_letters))] * 3 # тут считаем все буквы пропущенными
+ [(all_letters, all_letters)] * 10 # тут считаем все буквы НЕ пропущенными
+ [('aeiouy', '------')] * 30 # тут считаем пропущенными только гласные
)
Или вот простыня текста разрулена скобками:
fragment = (
'Абсолютная идея есть для себя, потому что в ней нет ни перехода, '
'ни предпосылок и вообще никакой определенности, которые не были бы '
'текучи и прозрачны; она есть чистая форма понятия, которая созерцает '
'свое содержание как самое себя. Она есть свое собственное содержание, '
'поскольку она есть идеальное различение самой себя от себя, и одно из '
'этих различий есть тождество с собой, которое, однако, содержит в себе '
'тотальность форм как систему содержательных определений. '
'Это содержание есть система логического.'
f'({author})'
)
Nested conditions
Тут всё просто: зачем два if, если можно один? Вроде банальщина, а тем не менее - 2%:
2% 65 SIM102 Use a single if-statement instead of nested if-statementsif min_val is not None and max_val is not None:
if max_val < min_val:
raise ValueError("max_val is greater than min_val") # тут уровень отступов == 2
# ...вжух!
if min_val is not None and max_val is not None and max_val < min_val:
raise ValueError("max_val is greater than min_val") # тут уровень отступов == 1
Pathlib
pathlib (о котором я замолвлю словечко позже) позволяет читать и писать в одну строчку:
with open('test.txt') as file:
content = open.read() # тут уровень отступов == 1
# ...вжух!
content = Path('test.txt').read_text() # тут уровень отступов == 0Redundant else
Один из моих любимых способов уменьшения отступов: если в теле после if у вас return или raise, то else не нужен. Проще на примере:
if user_profile:
# ...
return HttpResponseRedirect(reverse("main:dashboard")) # или raise
else:
# ...
messages.success(request, _("Успешная регистрация.")) # тут уровень отступов == 1
return HttpResponseRedirect(reverse("main:dashboard"))
# ...вжух!
if user_profile:
# ...
return HttpResponseRedirect(reverse("main:dashboard"))
# ...
messages.success(request, _("Успешная регистрация.")) # тут уровень отступов == 0
return HttpResponseRedirect(reverse("main:dashboard"))
Легко читать > Low RAM > Небольшой контекст
Каждый if заставляет вас запоминать, что было ветвление на 2 или более случая. Каждая переменная заставляет вас помнить, что она есть и в ней что-то лежит. Каждый try заставляет ожидать исключения в каждой строчке до самого except. Вроде пустяки, но чем их больше, тем сложнее за всем уследить. Всё, что нужно держать в голове, я называю "контекстом", и в этой секции мы будем его уменьшать.
Early quit
Я уже рассказывал про него, но это такой классный паттерн, что я даже добавил его в плагин для flake8 (правда, там много false positives). Правило такое: старайтесь выйти из функции / цикла как можно быстрее. На любой развилке if-else первым проверяйте то условие, которое позволит выйти из тела функции / цикла.
Пример:
if rate is not None:
# в этом месте мы должны помнить, что есть ещё случай `if rate is None`, и его нужно потом рассмотреть
r1 = (df[minus] / df[column] - 1).abs()
r2 = (df[plus] / df[column] - 1).abs()
return df.loc[(df['new_cases'].ge(100)) & ((r1.notnull() & (r1 <= rate)) | (r2.notnull() & (r2 <= rate)))]
else: # и вот мы наконец его рассматриваем
raise Exception
# ...вжух!
if rate is None: # сначала рассматриваем случай, который нас выкинет из текущего контекста
raise Exception
# если не выкинул - то хотя бы не нужно про него больше помнить
r1 = (df[minus] / df[column] - 1).abs()
r2 = (df[plus] / df[column] - 1).abs()
return df.loc[(df['new_cases'].ge(100)) & ((r1.notnull() & (r1 <= rate)) | (r2.notnull() & (r2 <= rate)))]
Или вот:
if response.status == httplib.OK:
parser = DNSParser()
parser.feed(response.read())
return parser.saved_data
else:
return 'Error ' + str(response.status)
# ...вжух!
if response.status != httplib.OK:
return 'Error ' + str(response.status)
parser = DNSParser()
parser.feed(response.read())
return parser.saved_data
Обобщая, после этой оптимизации код должен выглядеть так:
если что-то не так:
return
если что-то ещё не так:
return
если ошибка:
raise
# тут мы уверены, что всё в порядке
код, делающий что-то полезное
Small try blocks
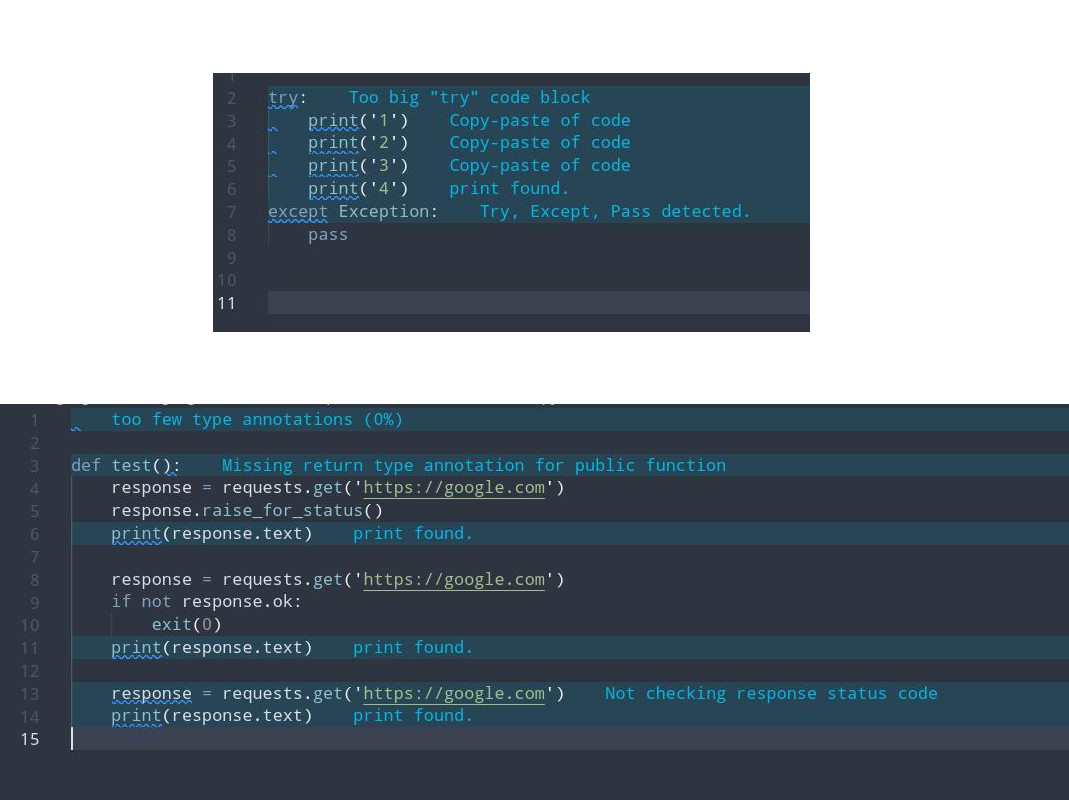
В 4% постов авторы пытаются скормить в try как можно больше всего. Наверно, это какие-то корни рыболовов дают о себе знать - натянул сеть пошире и ловишь себе всё, что есть, иногда даже не гнушаясь ловить просто Exception.
4% 106 GRG004 Too big "try" code blockВ идеале вы должны знать, что конкретно и где вы ловите - тогда при срабатывании блока except вы точно будете знать, из какой строчки что прилетело. Поэтому в идеале между try и except должно быть 1-3 строчки, а если больше - задумайтесь, возможно, вы не понимаете, что у вас происходит в коде.
Кстати, try-except вводят дополнительный отступ, а чем больше отступов... ну вы помните.
def new_from_file(self, filename, selected=True):
try:
file_path = normalize_path(filename, True)
obj = DesktopParser(file_path)
sname = obj.get('Name',locale=LOCALE)
desc = obj.get('Comment',locale=LOCALE)
icon = obj.get('Icon')
pix = IconManager().get_icon(ThemedIcon('image-missing'),32)
if icon:
if icon.rfind('.') != -1:
pix = IconManager().get_icon(FileIcon(File(icon)),32)
else:
pix = IconManager().get_icon(ThemedIcon(icon),32)
data = (pix, '%s' % sname, obj, sname.upper(), file_path)
return self.launcher_view.add_row(data,selected)
except:
return None
# ...вжух!
def new_from_file(self, filename, selected=True):
file_path = normalize_path(filename, True)
try:
obj = DesktopParser(file_path)
except DesktopParserError:
return
sname = obj.get('Name',locale=LOCALE)
desc = obj.get('Comment',locale=LOCALE)
icon = obj.get('Icon')
try:
pix = IconManager().get_icon(ThemedIcon('image-missing'),32)
except IconError:
return
if icon:
if icon.rfind('.') != -1:
pix = IconManager().get_icon(FileIcon(File(icon)),32)
else:
pix = IconManager().get_icon(ThemedIcon(icon),32)
data = (pix, '%s' % sname, obj, sname.upper(), file_path)
return self.launcher_view.add_row(data,selected)
Если у вас прям какая-то ненадёжная функция и вы хотите весь её код завернуть в try-except, то хотя бы юзайте декоратор.
Context manager
7% 208 SIM115 Use context handler for opening filesВнезапно, в 7% постов авторы обходятся без контекстных менеджеров для открытия файлов. Они, наверно, супермены и всегда помнят, что надо закрывать файлы?
@profile
def create_file():
x = [(random.random(),
random_string(),
random.randint(0, 2 ** 64))
for _ in xrange(1000000)]
pickle.dump(x, open('machin.pkl', 'w'))
Я вот могу и забыть про file.close(). Эти ваши интернеты говорят, что если самому не вызвать close(), то cpython закрывает файлы, когда их refcount = 0 и сборщик мусора добирается до них, а вот pypy - только при завершении процесса. Так что лучше использовать контекстные менеджеры, и пусть оно там само помнит, когда что закрыть и отключить:
with open('machin.pkl', 'w') as out_file:
pickle.dump(x, out_file)
Здесь мы рассмотрели контекстный менеджер для open(), но есть и контекстные менеджеры для разного - соединения с базой данных, к примеру - полезные штуки!
Yagni
В коде не должно быть ненужного. Если у вас код под VCS, то смело выбрасывайте мёртвый код - потому что потом можно будет всегда вернуть (но, скорей всего, до этого не дойдёт). Ну и просто по мелочи:
Заменяйте ненужные переменные на underscore
10% 285 B007 Loop control variable 'i' not used within the loop body. If this is intended, start the name with an underscore.for i in range(32):
print(quantum_randbit(), end='')
# ...вжух!
for _ in range(32):
print(quantum_randbit(), end='')
Для путешестеовенников во времени: у нас в 2022 object уже необязателен.
5% 160 SIM120 Use 'class Bot:' instead of 'class Bot(object):'class DataItem(object):
__slots__ = ['name', 'age', 'address']
# ...вжух!
class DataItem:
__slots__ = ['name', 'age', 'address']
Не надо создавать контейнер, а потом наполнять его. Наполняйте сразу!
1% 44 PIE799 prefer-col-init: Consider passing values in when creating the collection.Contour=[]
Contour.append( [pcbnew.Millimeter2iu(plane_size[0]), pcbnew.Millimeter2iu(plane_size[1]) ])
Contour.append( [pcbnew.Millimeter2iu(plane_size[0]), -pcbnew.Millimeter2iu(plane_size[1]) ])
Contour.append( [-pcbnew.Millimeter2iu(plane_size[0]), -pcbnew.Millimeter2iu(plane_size[1]) ])
Contour.append( [-pcbnew.Millimeter2iu(plane_size[0]), pcbnew.Millimeter2iu(plane_size[1]) ])
# ...вжух!
Countour = [
[pcbnew.Millimeter2iu(plane_size[0]), pcbnew.Millimeter2iu(plane_size[1]) ],
[pcbnew.Millimeter2iu(plane_size[0]), -pcbnew.Millimeter2iu(plane_size[1]) ],
[-pcbnew.Millimeter2iu(plane_size[0]), -pcbnew.Millimeter2iu(plane_size[1]) ],
[-pcbnew.Millimeter2iu(plane_size[0]), pcbnew.Millimeter2iu(plane_size[1]) ],
]
Легко читать > Low RAM > Best practices
А ещё код легчо читать, если его пишут так, как общепринято и актуально по нынешней спецификации.
Range
Внезапно для 4%, range уже начинается с нуля!
4% 119 PIE808 prefer-simple-range: range starts at 0 by default.for i in range(0, n):
dydt[i] = y[i + n]
# ...вжух!
for i in range(n):
dydt[i] = y[i + n]
Enumerate
Если в цикле вы используете счётчик и увеличиваете его на 1 в конце каждой итерации, то, скорее всего, доктор вам пропишет enumerate().
2% 70 SIM113 Use enumerate for 'val'counter = 0
for vk in vk_apis:
change_photo(vk)
print(counter, 'done')
counter += 1
# ...вжух!
for i, vk in enumerate(vk_apis):
change_photo(vk)
print(i, 'done')
Suppress
1% 55 SIM105 Use 'contextlib.suppress(Exception)'Сам недавно узнал! Позволяет укоротить try-except-pass:
try:
flatPriceDelta = float(flatPriceInfo) - float(oldFlatPriceInfo)
except ValueError:
pass
# ...вжух!
with suppress(ValueError):
flatPriceDelta = float(flatPriceInfo) - float(oldFlatPriceInfo)
Pathlib
pathlib - это как type hints: полезная штука, которую почему-то часто игнорируют. Если вы используете os.path, то время сесть в делореан, переместиться в будущее и начать пользоваться pathlib.
1% 41 PL107 os.remove("foo") should be replaced by foo_path.unlink()
1% 38 PL103 os.makedirs("foo/bar") should be replaced by bar_path.mkdir(parents=True)
14% 395 PL123 open("foo") should be replaced by Path("foo").open()
3% 96 PL118 os.path.join("foo", "bar") should be replaced by foo_path / "bar"
2% 67 PL110 os.path.exists("foo") should be replaced by foo_path.exists()os.remove("../m3u8_downloader/segments/temp.ts")
# ...вжух!
Path("../m3u8_downloader/segments/temp.ts").unlink()
if not os.path.exists(tools_path):
os.makedirs(tools_path)
# ...вжух!
tools_path.mkdir(parents=True, exist_ok=True)
with open('posts.txt') as file:
# ...вжух!
with Path('posts.txt').open() as file:
def SaveDriverFile(self):
winPath = os.environ['WINDIR']
sys32Path = os.path.join(winPath, "System32")
targetPath = os.path.join(sys32Path, "drivers\\" + self.name + ".sys")
file_data = open(self.file_path, "rb").read()
open(targetPath, "wb").write(file_data)
# ...вжух!
def SaveDriverFile(self):
winPath = Path(os.environ['WINDIR'])
sys32Path = winPath / "System32"
targetPath = sys32Path / "drivers" / self.name + ".sys"
file_data = self.file_path.read_bytes()
targetPath.write_bytes(file_data)
if not os.path.exists(HOME_DIR+'/'+'ShootAndView'):
# ...вжух!
if not (HOME_DIR / 'ShootAndView').exists():
Кстати, pathlib можно использовать в argparse:
from argparse import ArgumentParser
parser = ArgumentParser()
parser.add_argument('path', type=Path)
args = parser.parse_args()
subpath = args.path / 'subpath'
Boolean expressions
1% 31 PIE801 prefer-simple-return: Return boolean expressions directly instead of returning `True` and `False`.if q.measure()[:~0] == '0' * n:
return True
else:
return False
# ...вжух!
return q.measure()[:~0] == '0' * n
Filter / map
1% 37 C417 Unnecessary use of map - use a generator expression instead.В большинстве случаев filter и map легко заменяются на генетаторы или list comprehension, а бонусом приходит лучшая читаемость.
key_dicts = map(lambda key: key.as_key(), keys)
return dict(keys=list(key_dicts), nextApplicationKeyId=next_application_key_id)
# ...вжух!
key_dicts = [key.as_key() for key in keys]
return dict(keys=key_dicts, nextApplicationKeyId=next_application_key_id)
Настоящие злодеи используют filter(map(...)), вот вам мой шедевр:
params = {
'--write-buffer-size': 123,
'--skip-hash-verification': None,
'--max-download-streams-per-file': 8,
}
args = list(map(str, filter(None, chain.from_iterable(params.items()))))
Не делайте так.
Легко читать > Low RAM > Well-known libs
Чтобы не писать зубодробительный код, можно использовать библиотеки, которые этот код уже написали. Тут я опишу лишь те, о которых не могу промолчать.
Requests
Да-да, мы все их используем, но многие не знают двух фишек:
requests.get(...)создаёт новую сессию для каждого вызова, что накладно, если вы делаете запросы к одному и тому же сайту. Правильный подход - использовать сессии, но описано это почему-то в "advanced usage"¯\_(ツ)_/¯По умолчанию нет никакого таймаута на запрос, поэтому если сайт долго отвечает, то ваш код тоже будет тормозить.
Tenacity
После того, как я увидел tenacity, я не хочу пользоваться никакими другими retry-библиотеками. Только посмотрите, как он легко читается:
@retry(
reraise=True,
wait=wait_incrementing(start=1, increment=2),
stop=stop_after_attempt(20),
)
def request(self, method: str, path: str, **kwargs) -> requests.Response:
if path.startswith('/'):
path = self.BASE_URL + path
kwargs.setdefault('timeout', self.TIMEOUT)
response = self.session.request(method, path, **kwargs)
if response.status_code == requests.codes.too_many_requests:
raise TryAgain()
return response
Пожалуйста, не изобретайте велосипеды, если вам нужно запилить retry логику. Используйте tenacity.
More-itertools
Если вы не слышали про itertools из стандартной библиотеки, то самое время почитать. itertools.chain меня постоянно выручает.
Но если itertools вам уже не хватает, то вэлкам: more-itertools. Тут есть chunked, spy, first, one, only, unique_everseen и прочие прелести. Осторожно, с этой дряни невозможно слезть.
Легко изменять
Может, вы сами, а может, кто-то из интернета однажды захочет что-то изменить в вашем коде. И этот кто-то мысленно скажет вам спасибо, если вы заранее позаботитесь об этом.
Легко изменять > Классы
Внезапно, классы полезны не только для инкапсуляции состояния объекта, но и для наследования! Вот, например, просто функция:
SOME_CONSTANT = 5
def do_something(value: int) -> int:
return value * SOME_CONSTANT
Как сделать, чтоб функция работала с другой константой? Передавать константу явно в функцию и в каждом месте, где вызывается функция, передавать новую константу. Или определить new_do_something = partial(do_something, constant=6) и везде использовать новую функцию. Но...
Вот то же, но через класс. Теперь кто угодно может переопределить и константу, и функцию, и всё вместе, и надстроить что-то поверх.
class Something:
SOME_CONSTANT = 5
@classmethod
def do_something(cls, value: int) -> int:
return value * cls.SOME_CONSTANT
class Other(Something):
SOME_CONSTANT = 6
@classmethod
def do_something(cls, value: int) -> int:
result = super().do_something(value)
return result - 3
Не то чтобы я топил за использование классов везде - иногда это излишне, и старые добрые функции будут решать задачу без проблем. Но если планируется какое-то переиспользование кода - я бы смотрел в сторону классов.
Легко изменять > Функции
Я прям сразу вспоминаю внутренности Django. Не дай бог мне вдруг не понравится что-то в стандартной инициализации модели - вы только посмотрите, какое там полотно!
base.py (осторожно, опасно для глаз)
class ModelBase(type):
"""Metaclass for all models."""
def __new__(cls, name, bases, attrs, **kwargs):
super_new = super().__new__
# Also ensure initialization is only performed for subclasses of Model
# (excluding Model class itself).
parents = [b for b in bases if isinstance(b, ModelBase)]
if not parents:
return super_new(cls, name, bases, attrs)
# Create the class.
module = attrs.pop("__module__")
new_attrs = {"__module__": module}
classcell = attrs.pop("__classcell__", None)
if classcell is not None:
new_attrs["__classcell__"] = classcell
attr_meta = attrs.pop("Meta", None)
# Pass all attrs without a (Django-specific) contribute_to_class()
# method to type.__new__() so that they're properly initialized
# (i.e. __set_name__()).
contributable_attrs = {}
for obj_name, obj in attrs.items():
if _has_contribute_to_class(obj):
contributable_attrs[obj_name] = obj
else:
new_attrs[obj_name] = obj
new_class = super_new(cls, name, bases, new_attrs, **kwargs)
abstract = getattr(attr_meta, "abstract", False)
meta = attr_meta or getattr(new_class, "Meta", None)
base_meta = getattr(new_class, "_meta", None)
app_label = None
# Look for an application configuration to attach the model to.
app_config = apps.get_containing_app_config(module)
if getattr(meta, "app_label", None) is None:
if app_config is None:
if not abstract:
raise RuntimeError(
"Model class %s.%s doesn't declare an explicit "
"app_label and isn't in an application in "
"INSTALLED_APPS." % (module, name)
)
else:
app_label = app_config.label
new_class.add_to_class("_meta", Options(meta, app_label))
if not abstract:
new_class.add_to_class(
"DoesNotExist",
subclass_exception(
"DoesNotExist",
tuple(
x.DoesNotExist
for x in parents
if hasattr(x, "_meta") and not x._meta.abstract
)
or (ObjectDoesNotExist,),
module,
attached_to=new_class,
),
)
new_class.add_to_class(
"MultipleObjectsReturned",
subclass_exception(
"MultipleObjectsReturned",
tuple(
x.MultipleObjectsReturned
for x in parents
if hasattr(x, "_meta") and not x._meta.abstract
)
or (MultipleObjectsReturned,),
module,
attached_to=new_class,
),
)
if base_meta and not base_meta.abstract:
# Non-abstract child classes inherit some attributes from their
# non-abstract parent (unless an ABC comes before it in the
# method resolution order).
if not hasattr(meta, "ordering"):
new_class._meta.ordering = base_meta.ordering
if not hasattr(meta, "get_latest_by"):
new_class._meta.get_latest_by = base_meta.get_latest_by
is_proxy = new_class._meta.proxy
# If the model is a proxy, ensure that the base class
# hasn't been swapped out.
if is_proxy and base_meta and base_meta.swapped:
raise TypeError(
"%s cannot proxy the swapped model '%s'." % (name, base_meta.swapped)
)
# Add remaining attributes (those with a contribute_to_class() method)
# to the class.
for obj_name, obj in contributable_attrs.items():
new_class.add_to_class(obj_name, obj)
# All the fields of any type declared on this model
new_fields = chain(
new_class._meta.local_fields,
new_class._meta.local_many_to_many,
new_class._meta.private_fields,
)
field_names = {f.name for f in new_fields}
# Basic setup for proxy models.
if is_proxy:
base = None
for parent in [kls for kls in parents if hasattr(kls, "_meta")]:
if parent._meta.abstract:
if parent._meta.fields:
raise TypeError(
"Abstract base class containing model fields not "
"permitted for proxy model '%s'." % name
)
else:
continue
if base is None:
base = parent
elif parent._meta.concrete_model is not base._meta.concrete_model:
raise TypeError(
"Proxy model '%s' has more than one non-abstract model base "
"class." % name
)
if base is None:
raise TypeError(
"Proxy model '%s' has no non-abstract model base class." % name
)
new_class._meta.setup_proxy(base)
new_class._meta.concrete_model = base._meta.concrete_model
else:
new_class._meta.concrete_model = new_class
# Collect the parent links for multi-table inheritance.
parent_links = {}
for base in reversed([new_class] + parents):
# Conceptually equivalent to `if base is Model`.
if not hasattr(base, "_meta"):
continue
# Skip concrete parent classes.
if base != new_class and not base._meta.abstract:
continue
# Locate OneToOneField instances.
for field in base._meta.local_fields:
if isinstance(field, OneToOneField) and field.remote_field.parent_link:
related = resolve_relation(new_class, field.remote_field.model)
parent_links[make_model_tuple(related)] = field
# Track fields inherited from base models.
inherited_attributes = set()
# Do the appropriate setup for any model parents.
for base in new_class.mro():
if base not in parents or not hasattr(base, "_meta"):
# Things without _meta aren't functional models, so they're
# uninteresting parents.
inherited_attributes.update(base.__dict__)
continue
parent_fields = base._meta.local_fields + base._meta.local_many_to_many
if not base._meta.abstract:
# Check for clashes between locally declared fields and those
# on the base classes.
for field in parent_fields:
if field.name in field_names:
raise FieldError(
"Local field %r in class %r clashes with field of "
"the same name from base class %r."
% (
field.name,
name,
base.__name__,
)
)
else:
inherited_attributes.add(field.name)
# Concrete classes...
base = base._meta.concrete_model
base_key = make_model_tuple(base)
if base_key in parent_links:
field = parent_links[base_key]
elif not is_proxy:
attr_name = "%s_ptr" % base._meta.model_name
field = OneToOneField(
base,
on_delete=CASCADE,
name=attr_name,
auto_created=True,
parent_link=True,
)
if attr_name in field_names:
raise FieldError(
"Auto-generated field '%s' in class %r for "
"parent_link to base class %r clashes with "
"declared field of the same name."
% (
attr_name,
name,
base.__name__,
)
)
# Only add the ptr field if it's not already present;
# e.g. migrations will already have it specified
if not hasattr(new_class, attr_name):
new_class.add_to_class(attr_name, field)
else:
field = None
new_class._meta.parents[base] = field
else:
base_parents = base._meta.parents.copy()
# Add fields from abstract base class if it wasn't overridden.
for field in parent_fields:
if (
field.name not in field_names
and field.name not in new_class.__dict__
and field.name not in inherited_attributes
):
new_field = copy.deepcopy(field)
new_class.add_to_class(field.name, new_field)
# Replace parent links defined on this base by the new
# field. It will be appropriately resolved if required.
if field.one_to_one:
for parent, parent_link in base_parents.items():
if field == parent_link:
base_parents[parent] = new_field
# Pass any non-abstract parent classes onto child.
new_class._meta.parents.update(base_parents)
# Inherit private fields (like GenericForeignKey) from the parent
# class
for field in base._meta.private_fields:
if field.name in field_names:
if not base._meta.abstract:
raise FieldError(
"Local field %r in class %r clashes with field of "
"the same name from base class %r."
% (
field.name,
name,
base.__name__,
)
)
else:
field = copy.deepcopy(field)
if not base._meta.abstract:
field.mti_inherited = True
new_class.add_to_class(field.name, field)
# Copy indexes so that index names are unique when models extend an
# abstract model.
new_class._meta.indexes = [
copy.deepcopy(idx) for idx in new_class._meta.indexes
]
if abstract:
# Abstract base models can't be instantiated and don't appear in
# the list of models for an app. We do the final setup for them a
# little differently from normal models.
attr_meta.abstract = False
new_class.Meta = attr_meta
return new_class
new_class._prepare()
new_class._meta.apps.register_model(new_class._meta.app_label, new_class)
return new_class
Чтобы пропатчить одну строчку в этой функции, мне нужно полностью эту функцию переписать! А потом в следующем релизе разрабы джанго там что-то поменяют, и мой патч сломается.
Мораль? Чем меньше метод, тем легче его заменить.
Легко изменять > Переменные
Как я уже говорил выше, если вы хотите, чтобы можно было изменять переменные - то либо делайте их class variables, либо передавайте явно как параметр в функцию. Никаких magic numbers в теле функции!
# бро
class Some:
CONST = 5
# бро
def do(const: int = 5):
# ...
# не бро
def do():
for i in range(5):
# ...
Легко изменять > Dependency injection
Справедливости ради следует упомянуть dependency injection, как вариант, облегчающий модификацию и тестирование кода, но, кажется, за меня про это уже написали тут.
Легко дебажить
Легко дебажить - это значит иметь место для брейкпоинта, и чтоб можно было понять, что вообще происходит.
Легко дебажить > except или except Exception
Я уже упоминал про моряков, которые ловят всё. И это плохо, потому что, отлавливая всё подряд, вы пытаетесь пофиксить своё непонимание - вы не понимаете, какие исключения могут прилететь. Разберитесь в коде, а не пытайтесь поставить заплатку!
6% 171 B001 Do not use bare `except:`, it also catches unexpected events like memory errors, interrupts, system exit, and so on.
9% 274 PIE786 Use precise exception handlers.for node in G.nodes():
try:
labels[node]=names['keysets']['generated'][nodeStdict[node]+'-name']['ru']
except: labels[node]='error'
# ...вжух!
for node in G.nodes():
try:
labels[node]=names['keysets']['generated'][nodeStdict[node]+'-name']['ru']
except KeyError:
labels[node] = 'error'
Легко дебажить > mega-statements
Чем длиннее выражение, тем сложнее его отлаживать.
Например, в этом случае нет места для брейкпоинта, потому что мега-объект создаётся несколько раз в цикле из itertools.product, и сразу с ним делается assert. Это просто ужасно!
assert replication_status_json in [
{
"replication-one":
[
{
"count": 1,
"destination_replication_status": None,
"hash_differs": None,
"metadata_differs": None,
"source_has_file_retention": None,
"source_has_hide_marker": None,
"source_has_large_metadata": None,
"source_has_legal_hold": None,
"source_has_sse_c_enabled": None,
"source_replication_status": None,
}
],
"replication-two":
[
{
"count": 1,
"destination_replication_status": None,
"hash_differs": None,
"metadata_differs": None,
"source_has_file_retention": False,
"source_has_hide_marker": False,
"source_has_large_metadata": False,
"source_has_legal_hold": True,
"source_has_sse_c_enabled": False,
"source_replication_status": first,
}, {
"count": 1,
"destination_replication_status": None,
"hash_differs": None,
"metadata_differs": None,
"source_has_file_retention": False,
"source_has_hide_marker": False,
"source_has_large_metadata": False,
"source_has_legal_hold": False,
"source_has_sse_c_enabled": False,
"source_replication_status": second,
}, {
"count": 1,
"destination_replication_status": None,
"hash_differs": None,
"metadata_differs": None,
"source_has_file_retention": False,
"source_has_hide_marker": False,
"source_has_large_metadata": False,
"source_has_legal_hold": False,
"source_has_sse_c_enabled": True,
"source_replication_status": None,
}, {
"count": 1,
"destination_replication_status": None,
"hash_differs": None,
"metadata_differs": None,
"source_has_file_retention": False,
"source_has_hide_marker": False,
"source_has_large_metadata": False,
"source_has_legal_hold": True,
"source_has_sse_c_enabled": True,
"source_replication_status": None,
}
]
} for first, second in itertools.product(['FAILED', 'PENDING'], ['FAILED', 'PENDING'])
]
Легко дебажить > думать вперёд
Иногда можно писать сразу так, чтобы потом не дебажить :)
Copy-paste
Хотите сделать опечатку? Юзайте copy-paste! За пруфами отсылаю вас к PVS Studio, а на Хабре... на Хабре копи-пасту можно найти очень часто.
44% 715 GRG001 Copy-paste of codeИ хотя в моём плагине много false positives, проблема действительно есть:
xn = fincoords[0][:,0]
yn = fincoords[0][:,1]
zn = fincoords[0][:,2]
l=[labels[idi] for idi in myIDs]
Чем больше строчек скопировано, тем легче будет ошибиться - забыть поменять что-то в одной из строчек. Решение - выделять общий функционал в цикл / отдельную функцию.
Response status
Вот вам забавный факт: в 4% постов разработчику вообще плевать, что там вернул сервер. Не стоит прогибаться под изменчивый сервер, пусть лучше он прогнётся под нас!
4% 111 GRG005 Not checking response status codedef uncapcha(url):
imager = requests.get(url)
r = requests.post('http://rucaptcha.com/in.php', data = {'method': 'base64', 'key': RUCAPTCHA_KEY, 'body': base64.b64encode(imager.content)})
if (r.text[:3] != 'OK|'):
print('captcha failed')
return -1
capid = r.text[3:]
sleep(5)
response.ok или response.raise_for_status() в помощь!
Проблема print() в том, что им очень просто пользоваться. Вот все им и пользуются, но через какое-то время возникает другая проблема: а как его заткнуть?
Поэтому я рекомендую сразу, прям с самого начала использовать модуль logging и разделять вывод на debug, info, warning и error. Тогда во время отладки программы вы будете выводить все сообщения, даже отладочные, а потом просто смените уровень на info или warning, и отладочные сообщения не будут засорять вам вывод.
44% 1246 T201 print found.async def fun2(x):
print(x**0.5)
await asyncio.sleep(3)
print('fun2 завершена')
# ...вжух!
import logging
log = logging.getLogger(__name__)
async def fun2(x):
print(x**0.5)
await asyncio.sleep(3)
log.debug('fun2 завершена')
if __name__ == '__main__':
logging.basicConfig(level=logging.DEBUG)
Легко тестировать
Легко тестировать
Как сделать тестирование лёгким и приятным? А вот как: пишите функции, которые
ни от чего не зависят, кроме входных параметров
делают только одну вещь
без side effects, а если и с ними, то это единственное их назначение
Я собрал джекпот для примера:
items = [1, 2]
def append_double(el: int) -> int:
# функция имеет side effect: изменяет items
double = el * 2
items.append(double) # функция зависит от глобальной переменной items
return double # помимо side effect, функция ещё что-то возвращаетДля всех случаев у меня нет авто-детекторов, но вот статистика по использованию ключевого слова global:
3% 98 W002 Global variable next usedНе делайте так!
def format_time(x, pos=None):
global duration, nframes, k
progress = int(x / float(nframes) * duration * k)
# ...Время статистики
Давайте применим наше знание, чтобы что-нибудь понять.
Статистика по постам
Рейтинг от общего количества ошибок на пост:

Похоже, чем более грязный код вы пишете, тем меньше у вас шансов получить высокий рейтинг. Но это неточно.
Статистика по популярным питон-библиотекам
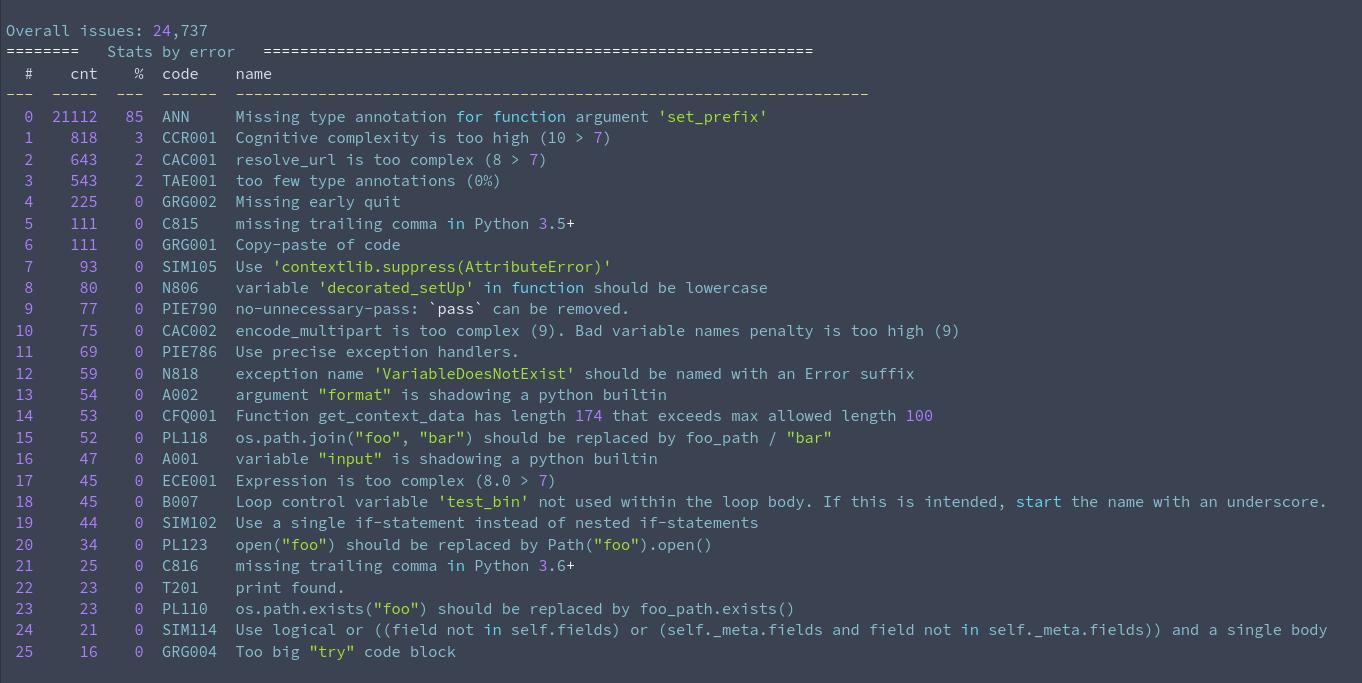
Ставил последние версии на 1.09.2022.
django
У меня с django довольно нежные отношения, поэтому мне было интересно: так ли там всё плохо, как мне кажется?
Хех, похоже, что да!
Во-первых, джанго кладёт огроменный болт на type annotations. У них так принято
python show-me-sample.py --results results/libs-results-django.json --order random --context 8 ANN
-------------------- samples/libs/django/contrib/postgres/validators.py ---- --------------------
ANN Missing type annotation for function argument 'a'
class RangeMinValueValidator(MinValueValidator):
def compare(self, a, b): # <--------------------------------!!!
return a.lower is None or a.lower < b
-------------------- samples/libs/django/contrib/admin/utils.py ---- --------------------
ANN Missing type annotation for function argument 'obj'
def model_format_dict(obj): # <--------------------------------!!!
"""
Return a `dict` with keys 'verbose_name' and 'verbose_name_plural',
typically for use with string formatting.
`obj` may be a `Model` instance, `Model` subclass, or `QuerySet` instance.
Во-вторых, джанго любит повыносить мозг:
-------------------- samples/libs/django/utils/translation/__init__.py ---- --------------------
CCR001 Cognitive complexity is too high (17 > 7)
def lazy_number(func, resultclass, number=None, **kwargs): # <--------------------------------!!!
if isinstance(number, int):
kwargs["number"] = number
proxy = lazy(func, resultclass)(**kwargs)
else:
original_kwargs = kwargs.copy()
class NumberAwareString(resultclass):
def __bool__(self):
return bool(kwargs["singular"])
def _get_number_value(self, values):
try:
return values[number]
except KeyError:
raise KeyError(
"Your dictionary lacks key '%s'. Please provide "
"it, because it is required to determine whether "
# ...
-------------------- samples/libs/django/db/models/base.py ---- --------------------
CCR001 Cognitive complexity is too high (67 > 7)
class Model(metaclass=ModelBase):
def __init__(self, *args, **kwargs): # <--------------------------------!!!
# Alias some things as locals to avoid repeat global lookups
cls = self.__class__
opts = self._meta
_setattr = setattr
_DEFERRED = DEFERRED
if opts.abstract:
raise TypeError("Abstract models cannot be instantiated.")
pre_init.send(sender=cls, args=args, kwargs=kwargs)
# Set up the storage for instance state
self._state = ModelState()
# There is a rather weird disparity here; if kwargs, it's set, then args
# overrides it. It should be one or the other; don't duplicate the work
# The reason for the kwargs check is that standard iterator passes in by
# args, and instantiation for iteration is 33% faster.
if len(args) > len(opts.concrete_fields):
# Daft, but matches old exception sans the err msg.
raise IndexError("Number of args exceeds number of fields")
if not kwargs:
fields_iter = iter(opts.concrete_fields)
# The ordering of the zip calls matter - zip throws StopIteration
# when an iter throws it. So if the first iter throws it, the second
# is *not* consumed. We rely on this, so don't change the order
# without changing the logic.
for val, field in zip(args, fields_iter):
if val is _DEFERRED:
continue
_setattr(self, field.attname, val)
else:
# Slower, kwargs-ready version.
# ...
Всякие ненужные if-else - тоже есть в наличии, можете брать оптом.
-------------------- samples/libs/django/contrib/auth/views.py ---- --------------------
GRG002 Missing early quit
class LoginView(RedirectURLMixin, FormView):
# ...
def get_default_redirect_url(self):
"""Return the default redirect URL."""
if self.next_page: # <--------------------------------!!!
return resolve_url(self.next_page)
else:
return resolve_url(settings.LOGIN_REDIRECT_URL)
GRG002 Missing early quit
def distinct_sql(self, fields, params):
"""
Return an SQL DISTINCT clause which removes duplicate rows from the
result set. If any fields are given, only check the given fields for
duplicates.
"""
if fields: # <--------------------------------!!!
raise NotSupportedError(
"DISTINCT ON fields is not supported by this database backend"
)
else:
return ["DISTINCT"], []
-------------------- samples/libs/django/utils/cache.py ---- --------------------
GRG002 Missing early quit
def learn_cache_key(request, response, cache_timeout=None, key_prefix=None, cache=None):
"""
Learn what headers to take into account for some request URL from the
response object. Store those headers in a global URL registry so that
later access to that URL will know what headers to take into account
without building the response object itself. The headers are named in the
Vary header of the response, but we want to prevent response generation.
The list of headers to use for cache key generation is stored in the same
cache as the pages themselves. If the cache ages some data out of the
cache, this just means that we have to build the response once to get at
the Vary header and so at the list of headers to use for the cache key.
"""
if key_prefix is None:
key_prefix = settings.CACHE_MIDDLEWARE_KEY_PREFIX
if cache_timeout is None:
cache_timeout = settings.CACHE_MIDDLEWARE_SECONDS
cache_key = _generate_cache_header_key(key_prefix, request)
if cache is None:
cache = caches[settings.CACHE_MIDDLEWARE_ALIAS]
if response.has_header("Vary"): # <--------------------------------!!!
is_accept_language_redundant = settings.USE_I18N
# If i18n is used, the generated cache key will be suffixed with the
# current locale. Adding the raw value of Accept-Language is redundant
# in that case and would result in storing the same content under
# multiple keys in the cache. See #18191 for details.
headerlist = []
for header in cc_delim_re.split(response.headers["Vary"]):
header = header.upper().replace("-", "_")
if header != "ACCEPT_LANGUAGE" or not is_accept_language_redundant:
headerlist.append("HTTP_" + header)
headerlist.sort()
cache.set(cache_key, headerlist, cache_timeout)
return _generate_cache_key(request, request.method, headerlist, key_prefix)
else:
# if there is no Vary header, we still need a cache key
# for the request.build_absolute_uri()
cache.set(cache_key, [], cache_timeout)
return _generate_cache_key(request, request.method, [], key_prefix)
Ну и любимая нами копипаста, куда ж без неё!
-------------------- samples/libs/django/db/backends/postgresql/client.py ---- --------------------
GRG001 Copy-paste of code
class DatabaseClient(BaseDatabaseClient):
executable_name = "psql"
@classmethod
def settings_to_cmd_args_env(cls, settings_dict, parameters):
args = [cls.executable_name]
options = settings_dict.get("OPTIONS", {}) # <--------------------------------!!!
host = settings_dict.get("HOST")
port = settings_dict.get("PORT")
dbname = settings_dict.get("NAME")
user = settings_dict.get("USER")
passwd = settings_dict.get("PASSWORD")
passfile = options.get("passfile")
service = options.get("service")
sslmode = options.get("sslmode")
-------------------- samples/libs/django/contrib/postgres/apps.py ---- --------------------
GRG001 Copy-paste of code
if (
not enter
and setting == "INSTALLED_APPS"
and "django.contrib.postgres" not in set(value)
):
connection_created.disconnect(register_type_handlers) # <--------------------------------!!!
CharField._unregister_lookup(Unaccent)
TextField._unregister_lookup(Unaccent)
CharField._unregister_lookup(SearchLookup)
TextField._unregister_lookup(SearchLookup)
CharField._unregister_lookup(TrigramSimilar)
TextField._unregister_lookup(TrigramSimilar)
CharField._unregister_lookup(TrigramWordSimilar)
TextField._unregister_lookup(TrigramWordSimilar)
# Disconnect this receiver until the next time this app is installed
-------------------- samples/libs/django/template/smartif.py ---- --------------------
GRG001 Copy-paste of code
"and": infix(7, lambda context, x, y: x.eval(context) and y.eval(context)),
"not": prefix(8, lambda context, x: not x.eval(context)),
"in": infix(9, lambda context, x, y: x.eval(context) in y.eval(context)),
"not in": infix(9, lambda context, x, y: x.eval(context) not in y.eval(context)),
"is": infix(10, lambda context, x, y: x.eval(context) is y.eval(context)),
"is not": infix(10, lambda context, x, y: x.eval(context) is not y.eval(context)),
"==": infix(10, lambda context, x, y: x.eval(context) == y.eval(context)),
"!=": infix(10, lambda context, x, y: x.eval(context) != y.eval(context)), # <--------------------------------!!!
">": infix(10, lambda context, x, y: x.eval(context) > y.eval(context)),
">=": infix(10, lambda context, x, y: x.eval(context) >= y.eval(context)),
"<": infix(10, lambda context, x, y: x.eval(context) < y.eval(context)),
"<=": infix(10, lambda context, x, y: x.eval(context) <= y.eval(context)),
-------------------- samples/libs/django/contrib/gis/geos/io.py ---- --------------------
GRG001 Copy-paste of code
from django.contrib.gis.geos.geometry import GEOSGeometry
from django.contrib.gis.geos.prototypes.io import (
WKBWriter,
WKTWriter,
_WKBReader,
_WKTReader, # <--------------------------------!!!
)
Мы-то теперь с вами знаем про suppress(), а вот джанго - нет ;)
-------------------- samples/libs/django/views/debug.py ---- --------------------
SIM105 Use 'contextlib.suppress(OSError)'
try:
source = loader.get_source(module_name)
except ImportError:
pass
if source is not None:
source = source.splitlines()
if source is None:
try: # <--------------------------------!!!
with open(filename, "rb") as fp:
source = fp.read().splitlines()
except OSError:
pass
return source
fastapi
Ставлю всё на то, что чел, написавший pydantic и fastapi, знает дело и пишет сразу годноту!

Так и есть! Код классный, в основном ошибки - не ошибки, а false positives, лишь иногда встречается всякое:
-------------------- samples/libs/fastapi/dependencies/models.py ---- --------------------
CCR001 Cognitive complexity is too high (8 > 7)
class Dependant:
def __init__( # <--------------------------------!!!
self,
*,
path_params: Optional[List[ModelField]] = None,
query_params: Optional[List[ModelField]] = None,
header_params: Optional[List[ModelField]] = None,
cookie_params: Optional[List[ModelField]] = None,
body_params: Optional[List[ModelField]] = None,
dependencies: Optional[List["Dependant"]] = None,
security_schemes: Optional[List[SecurityRequirement]] = None,
name: Optional[str] = None,
call: Optional[Callable[..., Any]] = None,
request_param_name: Optional[str] = None,
websocket_param_name: Optional[str] = None,
http_connection_param_name: Optional[str] = None,
response_param_name: Optional[str] = None,
background_tasks_param_name: Optional[str] = None,
security_scopes_param_name: Optional[str] = None,
security_scopes: Optional[List[str]] = None,
use_cache: bool = True,
path: Optional[str] = None,
) -> None:
self.path_params = path_params or []
self.query_params = query_params or []
self.header_params = header_params or []
self.cookie_params = cookie_params or []
self.body_params = body_params or []
self.dependencies = dependencies or []
self.security_requirements = security_schemes or []
self.request_param_name = request_param_name
self.websocket_param_name = websocket_param_name
self.http_connection_param_name = http_connection_param_name
self.response_param_name = response_param_name
self.background_tasks_param_name = background_tasks_param_name
mypy

mypy больше всего любит взрывать мозг. Простите за пример:
-------------------- samples/libs/mypy/exprtotype.py ---- --------------------
CCR001 Cognitive complexity is too high (62 > 7)
def expr_to_unanalyzed_type(expr: Expression,
options: Optional[Options] = None,
allow_new_syntax: bool = False,
_parent: Optional[Expression] = None) -> ProperType:
"""Translate an expression to the corresponding type.
The result is not semantically analyzed. It can be UnboundType or TypeList.
Raise TypeTranslationError if the expression cannot represent a type.
If allow_new_syntax is True, allow all type syntax independent of the target
Python version (used in stubs).
"""
# The `parent` parameter is used in recursive calls to provide context for
# understanding whether an CallableArgument is ok.
name: Optional[str] = None
if isinstance(expr, NameExpr):
name = expr.name
if name == 'True':
return RawExpressionType(True, 'builtins.bool', line=expr.line, column=expr.column)
elif name == 'False':
return RawExpressionType(False, 'builtins.bool', line=expr.line, column=expr.column)
else:
return UnboundType(name, line=expr.line, column=expr.column)
elif isinstance(expr, MemberExpr):
fullname = get_member_expr_fullname(expr)
if fullname:
return UnboundType(fullname, line=expr.line, column=expr.column)
else:
raise TypeTranslationError()
elif isinstance(expr, IndexExpr):
base = expr_to_unanalyzed_type(expr.base, options, allow_new_syntax, expr)
if isinstance(base, UnboundType):
if base.args:
raise TypeTranslationError()
if isinstance(expr.index, TupleExpr):
args = expr.index.items
else:
args = [expr.index]
if isinstance(expr.base, RefExpr) and expr.base.fullname in ANNOTATED_TYPE_NAMES:
# TODO: this is not the optimal solution as we are basically getting rid
# of the Annotation definition and only returning the type information,
# losing all the annotations.
return expr_to_unanalyzed_type(args[0], options, allow_new_syntax, expr)
else:
base.args = tuple(expr_to_unanalyzed_type(arg, options, allow_new_syntax, expr)
for arg in args)
if not base.args:
base.empty_tuple_index = True
return base
else:
raise TypeTranslationError()
elif (isinstance(expr, OpExpr)
and expr.op == '|'
and ((options and options.python_version >= (3, 10)) or allow_new_syntax)):
return UnionType([expr_to_unanalyzed_type(expr.left, options, allow_new_syntax),
expr_to_unanalyzed_type(expr.right, options, allow_new_syntax)])
elif isinstance(expr, CallExpr) and isinstance(_parent, ListExpr):
c = expr.callee
names = []
# Go through the dotted member expr chain to get the full arg
# constructor name to look up
while True:
if isinstance(c, NameExpr):
names.append(c.name)
break
elif isinstance(c, MemberExpr):
names.append(c.name)
c = c.expr
else:
raise TypeTranslationError()
arg_const = '.'.join(reversed(names))
# Go through the constructor args to get its name and type.
name = None
default_type = AnyType(TypeOfAny.unannotated)
typ: Type = default_type
for i, arg in enumerate(expr.args):
if expr.arg_names[i] is not None:
if expr.arg_names[i] == "name":
if name is not None:
# Two names
raise TypeTranslationError()
name = _extract_argument_name(arg)
continue
elif expr.arg_names[i] == "type":
if typ is not default_type:
# Two types
raise TypeTranslationError()
typ = expr_to_unanalyzed_type(arg, options, allow_new_syntax, expr)
continue
else:
raise TypeTranslationError()
elif i == 0:
typ = expr_to_unanalyzed_type(arg, options, allow_new_syntax, expr)
elif i == 1:
name = _extract_argument_name(arg)
else:
raise TypeTranslationError()
return CallableArgument(typ, name, arg_const, expr.line, expr.column)
elif isinstance(expr, ListExpr):
return TypeList([expr_to_unanalyzed_type(t, options, allow_new_syntax, expr)
for t in expr.items],
line=expr.line, column=expr.column)
elif isinstance(expr, StrExpr):
return parse_type_string(expr.value, 'builtins.str', expr.line, expr.column,
assume_str_is_unicode=expr.from_python_3)
elif isinstance(expr, BytesExpr):
return parse_type_string(expr.value, 'builtins.bytes', expr.line, expr.column,
assume_str_is_unicode=False)
elif isinstance(expr, UnicodeExpr):
return parse_type_string(expr.value, 'builtins.unicode', expr.line, expr.column,
assume_str_is_unicode=True)
elif isinstance(expr, UnaryExpr):
typ = expr_to_unanalyzed_type(expr.expr, options, allow_new_syntax)
if isinstance(typ, RawExpressionType):
if isinstance(typ.literal_value, int) and expr.op == '-':
typ.literal_value *= -1
return typ
raise TypeTranslationError()
elif isinstance(expr, IntExpr):
return RawExpressionType(expr.value, 'builtins.int', line=expr.line, column=expr.column)
elif isinstance(expr, FloatExpr):
# Floats are not valid parameters for RawExpressionType , so we just
# pass in 'None' for now. We'll report the appropriate error at a later stage.
return RawExpressionType(None, 'builtins.float', line=expr.line, column=expr.column)
elif isinstance(expr, ComplexExpr):
# Same thing as above with complex numbers.
return RawExpressionType(None, 'builtins.complex', line=expr.line, column=expr.column)
elif isinstance(expr, EllipsisExpr):
return EllipsisType(expr.line)
else:
raise TypeTranslationError()
flake8
flake8 оказался очень хорош. Я хотел поглумиться, типа "написали линтер, а сами пишут кое-как", но оказалось ровно наоборот.
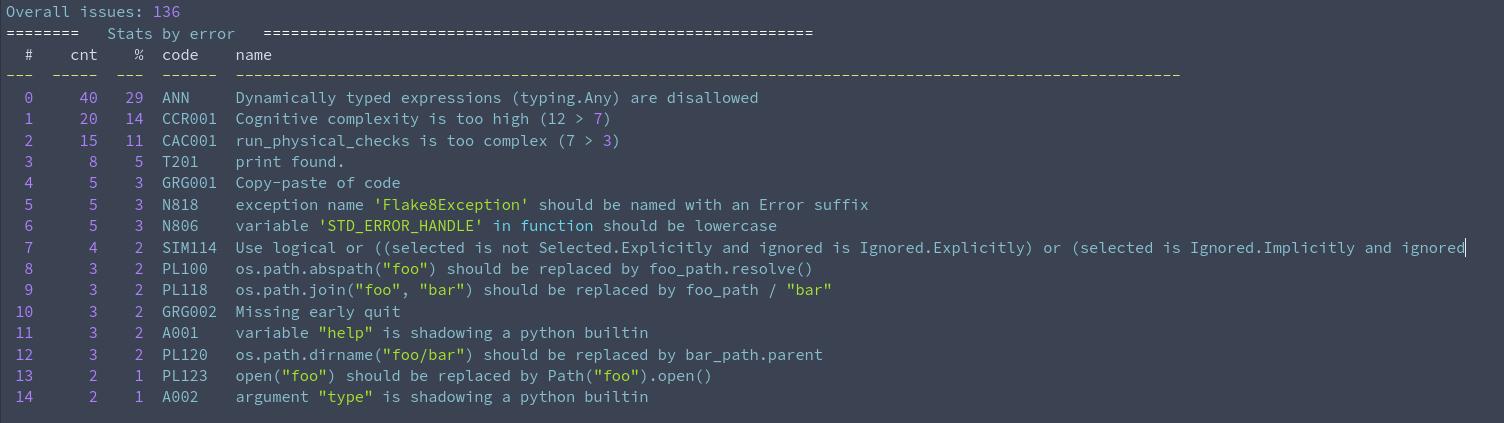
-------------------- samples/libs/flake8/utils.py ---- --------------------
CCR001 Cognitive complexity is too high (23 > 7)
def parse_files_to_codes_mapping( # noqa: C901 # <--------------------------------!!!
value_: Union[Sequence[str], str]
) -> List[Tuple[str, List[str]]]:
"""Parse a files-to-codes mapping.
A files-to-codes mapping a sequence of values specified as
`filenames list:codes list ...`. Each of the lists may be separated by
either comma or whitespace tokens.
:param value: String to be parsed and normalized.
"""
if not isinstance(value_, str):
value = "\n".join(value_)
else:
value = value_
ret: List[Tuple[str, List[str]]] = []
if not value.strip():
return ret
class State:
seen_sep = True
seen_colon = False
filenames: List[str] = []
codes: List[str] = []
def _reset() -> None:
if State.codes:
for filename in State.filenames:
ret.append((filename, State.codes))
State.seen_sep = True
State.seen_colon = False
State.filenames = []
State.codes = []
requests
Почти хорошо. Не любит type hints, в редких случаях выносит мозг.
scrapy
О, у меня большие подозрения насчёт scrapy. Мне вообще не нравится их подход к скрейпингу, и мне кажется, что там уж точно что-то нечисто!
Прав ли я? Конечно, нет! scrapy, как и многие, не уважает type hints и иногда мудрит, но в целом терпим.

pytest
Люблю pytest.

Но он почему-то иногда рыбачит:
PIE786 Use precise exception handlers.
def _should_repr_global_name(obj: object) -> bool:
if callable(obj):
return False
try:
return not hasattr(obj, "__name__")
except Exception: # <--------------------------------!!!
return True
И любит лесенки:
-------------------- samples/libs/_pytest/recwarn.py ---- --------------------
CCR001 Cognitive complexity is too high (25 > 7)
@final
class WarningsChecker(WarningsRecorder):
# ...
def __exit__( # <--------------------------------!!!
self,
exc_type: Optional[Type[BaseException]],
exc_val: Optional[BaseException],
exc_tb: Optional[TracebackType],
) -> None:
super().__exit__(exc_type, exc_val, exc_tb)
__tracebackhide__ = True
# only check if we're not currently handling an exception
if exc_type is None and exc_val is None and exc_tb is None:
if self.expected_warning is not None:
if not any(issubclass(r.category, self.expected_warning) for r in self):
__tracebackhide__ = True
fail(
"DID NOT WARN. No warnings of type {} were emitted. "
"The list of emitted warnings is: {}.".format(
self.expected_warning, [each.message for each in self]
)
)
elif self.match_expr is not None:
for r in self:
if issubclass(r.category, self.expected_warning):
if re.compile(self.match_expr).search(str(r.message)):
break
else:
fail(
"DID NOT WARN. No warnings of type {} matching"
" ('{}') were emitted. The list of emitted warnings"
" is: {}.".format(
self.expected_warning,
self.match_expr,
[each.message for each in self],
# ...
sentry-sdk
Вы уже видите тенденцию? Везде проблемы с аннотациями типов и излишней сложностью:

boto3
По моему опыту, амазон не умеет делать что-то просто. Давайте их разнесём!..
Не аннотировано почти ничего, но всё супер-просто. Вынужден признать, это всё-таки очень неплохой результат.
pandas
Ну что, датасаентисты? У меня даже flake прилично задумался, когда анализировал pandas, и я приготовился к худшему.
Я протестировал все остальные библиотеки, пока готовился pandas, и вот что я увидел:

А ничего! К отсутствию типов мы привыкли, выносом мозга нас не удивишь:
-------------------- samples/libs/pandas/core/window/common.py ---- --------------------
CCR001 Cognitive complexity is too high (70 > 7)
def flex_binary_moment(arg1, arg2, f, pairwise=False): # <--------------------------------!!!
if isinstance(arg1, ABCSeries) and isinstance(arg2, ABCSeries):
X, Y = prep_binary(arg1, arg2)
return f(X, Y)
elif isinstance(arg1, ABCDataFrame):
from pandas import DataFrame
def dataframe_from_int_dict(data, frame_template):
result = DataFrame(data, index=frame_template.index)
if len(result.columns) > 0:
result.columns = frame_template.columns[result.columns]
return result
results = {}
if isinstance(arg2, ABCDataFrame):
if pairwise is False:
if arg1 is arg2:
# special case in order to handle duplicate column names
for i in range(len(arg1.columns)):
results[i] = f(arg1.iloc[:, i], arg2.iloc[:, i])
return dataframe_from_int_dict(results, arg1)
else:
if not arg1.columns.is_unique:
raise ValueError("'arg1' columns are not unique")
if not arg2.columns.is_unique:
raise ValueError("'arg2' columns are not unique")
X, Y = arg1.align(arg2, join="outer")
X, Y = prep_binary(X, Y)
res_columns = arg1.columns.union(arg2.columns)
for col in res_columns:
if col in X and col in Y:
results[col] = f(X[col], Y[col])
return DataFrame(results, index=X.index, columns=res_columns)
elif pairwise is True:
results = defaultdict(dict)
for i in range(len(arg1.columns)):
for j in range(len(arg2.columns)):
if j < i and arg2 is arg1:
# Symmetric case
results[i][j] = results[j][i]
else:
results[i][j] = f(
*prep_binary(arg1.iloc[:, i], arg2.iloc[:, j])
)
from pandas import concat
result_index = arg1.index.union(arg2.index)
if len(result_index):
# construct result frame
result = concat(
[
concat(
[results[i][j] for j in range(len(arg2.columns))],
ignore_index=True,
)
for i in range(len(arg1.columns))
],
ignore_index=True,
axis=1,
)
result.columns = arg1.columns
Конец
В статье могут быть неточности. Я не проверял все 2к статей с 60к ошибок и все исходники библиотек. Но я часто смотрел живые примеры ошибок. И вот что я в итоге понял.
type hints никто не любит
все склонны переусложнять код
А теперь plot twist: почти все примеры ошибок я брал из статей с самым высоким рейтингом. Какой из этого вывод? Его озвучил @economist75:
Статья понравилась. Не кодом, который почти что ужасен, а темой макросов в графических пакетах.
Поэтому, в общем-то, не важно, как вы пишете, важно, что вы пишете. Но если вы будете при этом писать чистый, легко читаемый код - это будет вишенка на торте.
Моя повозка: Блог погромиста.
Комментарии (104)

vagon333
02.09.2022 19:16+2У вас собрана большая коллекция ошибок.
А где их можно посмотреть все вместе?
Код ошибки - описание - исходник проверки.
Может вы дали линк на GitHub, но я не заметил.По ошибкам:
Ошибка №13: часто нужно отлавливать любой exception (catch all), не важно, чем он вызван.
Не уверен что для на все случаи жизни можно предусмотреть в try/except все возможные except.Ошибка №23: отсутствует 'is'. Мелочь, но глаз режет.
По всем ошибкам я бы определился - либо все с заглавной, либо lowercase. Тоже режет глаз.
В чатах меня бесит
it'sвместоitsНо это же кошерно-неверное написание! :)
It's a kind of magic! :)
me21
02.09.2022 22:58+1It's как краткая форма it is - да. А если притяжательное местоимение - то its.

kesn Автор
03.09.2022 08:28+2В статье есть файл .flake8 под спойлером, там код ошибки, описание и ссылка на гитхаб

Murtagy
05.09.2022 09:52Не уверен что для на все случаи жизни можно предусмотреть в try/except все возможные except.
Как минимум есть разница между
`except`и
`except Exception`.
Думаю линтит именно первую форму


igor_suhorukov
02.09.2022 19:59Чем не устроил готовый "матерый" статический анализатор кода? В Java много всего в open source. Думаю из доступного джавистам богатства Sonar для Python должен сработать

dolfinus
03.09.2022 13:50У сонара очень мало встроенных проверок для Python. Flake8 с плагинами позволяет найти гораздо больше code smells и ошибок
igor_suhorukov
04.09.2022 11:51Спасибо, понял. Но можно использовать Sonar в дополнение Pylint, Bandit, Flake8
sonar.python.flake8.reportPathsdolfinus
04.09.2022 12:23Можно, но какой в этом смысл, если локальный flake8 умеет все ровно тоже самое?
По моему опыту, единственное, ради чего стоит использовать сонар - так это для отображения покрытия кода тестами, если этого не умеет CI/CD. Например, GitlabCI умеет отображать его только в рамках MR, и только для измененных файлов, а если нужно просто посмотреть на текущее покрытие пофайлово, то увы.
igor_suhorukov
04.09.2022 12:53IMHO, преимущество сонара в комплексности метрик и их зрелости + приличная база знаний почему конкретный "душок" кода вреден проекту. Ну и к долгосрочным последствиям использования - наблюдение за эволюцией качества (не 100% верная) но лучше чем эфимерные размышления о нем. По крайней мере это позволяет переводить споры о тех долге в более конструктивное русло. Последнее не применимо к теме этой статьи, но первое очень даже!


danilovmy
02.09.2022 21:04+6Привет, @kesn. Как всегда годно, и как всегда в твоих статьях, я не со всем согласен. ;) это кстати хорошо, что есть разные взгляды, это развивает.
Спор про типы оставим я придерживаюсь противоложных взглядов. Ранний выход, кстати, тоже спорно. Мусорные переменные как '_' тоже так себе. get_text as '_' слегка в недоумении.
в последнее время использую raise ... from ..., удивительно улучшает работу с отладкой кода. https://docs.python.org/3/tutorial/errors.html#exception-chaining рекомендую.
Жаль, что, в той же Django, ты не отметил как ошибку формирование листа в куеву хучу элементов, а потом break в цикле прохода по этому листу. Вот это точно бесит.
А в остальном да, все так и есть.
kesn Автор
03.09.2022 07:52+1Критика от Макса многого стоит! Спасибо за коммент.
raise from для меня как-то само собой разумеещееся, даже не подумал про это писать.
Про типы готов биться до последнего :)danilovmy
03.09.2022 13:10Я про то, что можно еще поискать, как мало используется raise from. Уверен, что попадет в топ. Типа если исключительная ситуация обрабатывается и бросается другое или то же исключение но без создания цепочки исключений. И вообще, это была не критика а только восхищение и белая зависть к рукам из правильного места :)

randomsimplenumber
02.09.2022 21:13pathlibпозволяет читать и писать в одну строчку:Обычный open тоже так позволяет.
kesn Автор
03.09.2022 07:54Кажется, у меня тут пробел в знаниях. Как?
randomsimplenumber
03.09.2022 09:18open ("file.txt", "w"). write ("hello world \n")
open возвращает обычный file object, не вижу никаких препятствий вызывать его методы в этой же строчке.
kesn Автор
03.09.2022 09:27+6А закрывать кто будет? ) Pathlib делает это автоматически

iig
03.09.2022 10:11При выходе из области видимости (при переходе на следующую строку то есть) вызовется деструктор.
Hidden text
class t: def __init__(self): print("create") def __del__(self): print("delete") def do(self): print("do") t().do()python3 test.py
create
do
deleteВнутри IOBase деструктор явно вызывает close()
def __del__(self): """Destructor. Calls close()."""Все нормально, так можно ;)

Shev4ik
03.09.2022 11:55+9Нельзя. В спецификации языка нигде не указано когда выполняется удаление объекта, потому имеет право вообще не удаляться. GC на основе счётчика ссылок это особенность cpython, и если его отрубить/вырезать, то всё сломается.
iig
03.09.2022 12:16+1имеет право вообще не удаляться
UB теперь и в python завезли ;)
Тогда согласен, pathlib надежнее.def read_text(self, encoding=None, errors=None): """ Open the file in text mode, read it, and close the file. """
kesn Автор
03.09.2022 12:05+3Я ж кидал ссылку в статье - чувак исследовал garbage collection на файлах, в cpython вроде ещё ничего, в pypy - нет. Я бы вообще не стал полагаться на сборщик мусора, имплементации могут быть разными...

mayorovp
03.09.2022 11:05Насколько я знаю, в pathlib только пути до файлов (что следует из названия). Сама работа с файлами реализована в стандартной библиотеке, в том числе закрытие.

InternetStalker
03.09.2022 09:32open ("file.txt", "w"). write ("hello world \n")Кхм, а файл закрыть не надо?


sunnybear
03.09.2022 00:45+1Type hints делают код более понятным?

vkni
03.09.2022 05:52+1Если применять умеренно, то да.
Другое дело, зачем использовать Питон, если взять за правило "везде расставлять Type hints". Есть же языки, в которых это делает автоматика.
ReadOnlySadUser
03.09.2022 14:14+2Как на счёт того, чтобы читатель кода не охреневал от догадок, что тут вообще происходит)
vkni
03.09.2022 15:27Для этого не обязательно их расставлять "везде".
ReadOnlySadUser
03.09.2022 15:29+3Ровно в том месте, где этого не сделано, возникает точка "а теперь происходит всё что угодно". После этого непонятно становится ровным счётом нихрена.
Никто не хочет читать ВСЮ функцию, чтобы понять что ожидается на входе и что ожидается на выходе.
vkni
03.09.2022 20:17Понимаете, вы этими расставлениями аннотаций типов делаете из Питона какой-то недоML-недоХаскель. В результате проверка типов проводится не сплошняком/нелинейно, а возможности динамически типизированных языков сильно урезаются. Да, где-то расстановка типов разумна, но не везде же.
И как там с ad-hock polymorphism, кстати?
Ровно в том месте, где этого не сделано, возникает точка "а теперь происходит всё что угодно". После этого непонятно становится ровным счётом нихрена.
Это всегда так — даже теорема есть.
Если не нравится — попробуйте Хаскель или Идрис. Там тоже происходить в функции может много чего, но очень часто сигнатура действительно определяет одно разумное поведение. К примеру, мы можем искать функцию bind по сигнатуре `[a]->(a -> [b]) -> [b]` или функцию map по сигнатуре `[a]->(a -> b) -> [b]`.ReadOnlySadUser
03.09.2022 22:50+3Понимаете, вы этими расставлениями аннотаций типов делаете из Питона какой-то недоML-недоХаскель.
Вы так говорите, как будто бы это что-то плохое. Статическая типизация - это хорошо, даже JS-ники это поняли и придумали TypeScript. Любой проект больше 2000 строк на динамически-типизированном - помойка из костылей и проблем.
а возможности динамически типизированных языков сильно урезаются
Моя бы воля, я бы их вообще запретил :) Может быть я мало на них писал, конечно, но на сегодняшний день я не понимаю в чём динамически-типизированные языки превосходят статически-типизированные. Ладно, я еще могу понять претензии к языкам вроде C++ или того же Haskell, где почти нет внятной рефлексии. В остальных случаях динамически-типизированные языки - это почти гарантированный бардак))
Если не нравится — попробуйте Хаскель или Идрис
Это как-то из крайности в крайность. Если еще Хаскель можно натянуть на ту же область, где используется Питон, то Идрис - это вообще не продакшн язык, служащий больше математикам для доказательства теорем. Людям попроще оно нафиг не упёрлось, формально верифицировать корректность программ.
Как бы если не нравится, наверное лучше-таки попробовать Go или там C#. Если хочется упороться, то можно и Scala / Rust / C++. Ну или тот же Haskell. Очень приятный язык, который, к сожалению, совершенно упоролся по чистоте функций и потому малоприменим в мире, где ничего не постоянно.

AnthonyMikh
04.09.2022 19:44-1Любой проект больше
20000 строк на динамически-типизированном — помойка из костылей и проблем.Исправил.
Может быть я мало на них писал, конечно, но на сегодняшний день я не понимаю в чём динамически-типизированные языки превосходят статически-типизированные.
Пережиток тех времён, когда практически применимых языков с выводом типов не было, а писать всюду типы не хотелось.
vkni
05.09.2022 00:20+1Пережиток тех времён, когда практически применимых языков с выводом типов не было, а писать всюду типы не хотелось.
Есть ситуации, когда даже Хиндли-Милнер с разными доработками является обузой и стесняет полёт мысли. Разумеется, эти ситуации крайне далеки от классического цикла "написал-протестировал-PR-проверка CI-рецензия-слияние-проверка на Alpha/Beta/PROD".
Ну и поскольку я буквально только что писал очередной интерпретатор на Scheme, ответственно заявляю, что проект на 200 строк не превращается в помойку, если писать аккуратно. Проблемы начинаются именно с нескольких тысяч.
vkni
05.09.2022 00:18Вы так говорите, как будто бы это что-то плохое.
Конечно. Вместо простого, полезного инструмента получается какая-то фигня. Я не сторонник забивать шурупы молотком и гвозди отвёрткой.
В своё время я сделал пару экспериментов Haskell/Python и подтвердил для себя то, что в ряде случаев разработка идёт быстрее на языке с динамической типизацией, а в ряде случаев — со статической. Это, конечно, банальности, но банальности полезно перепроверять.
Так вот, если программа настолько линейна, что за один прогон проверяется целиком, а прогон занимает меньше 10 секунд, то на Питоне её ваять, скорее всего, быстрее, чем на Haskell.
В то же время, когда логика крайне развесиста, программа сложна, то тут Haskell чудовищно выигрывает по времени разработки и умственным усилиям.
Поэтому каждому инструменту своё поле применения.но на сегодняшний день я не понимаю в чём динамически-типизированные языки превосходят статически-типизированные
На них проще пишутся короткие скриптовые программы, простые программы-черновики.
Заметьте, встречаются ситуации, когда вас устроит даже программа, в которой корректно только начало (классический пример, это Mathematica notebook, где только часть выражений вам нужна, а остальные — мусор, оставшийся от многочисленных правок). В таком случае полное сведение типов, компиляция, только замедлят цикл run-check results-correct и будут раздражать. Даже если это Ocaml или Clean с их компиляцией за 0.1 сек, а не GHC!ReadOnlySadUser
05.09.2022 00:27Пока что, все что вы написали лишь подтверждает то, что я говорю. Все ваши примеры сводятся к тому, что если вам надо что-то одноразовое наваять на коленке, то языки с динамической типизацией подойдут.
Я, если честно, могу расширить это утверждение ещё шире: абсолютно не важно на чем вы напишете write-only код.
Когда я защищал статическую типизацию, я прежде всего говорил о проектах, которые живут долго (от года и выше) и обновляются регулярно, и любые проекты над которыми работает больше трёх программистов.
P.S.
С аргументом про то, что уменьшается простота и понятность не согласен. Простота и понятность как раз-таки кратно возрастают, но да, за счёт того, что над кодом приходится немножечко больше думать, когда ты его пишешь.
vkni
05.09.2022 04:34Все ваши примеры сводятся к тому, что если вам надо что-то одноразовое наваять на коленке, то языки с динамической типизацией подойдут.
Если надо что-то небольшое, несложное, одноразовое наваять, то языки с динамической типизацией подойдут лучше, чем языки со статической типизацией и полным выводом типов.
А раз так, то не надо пытаться из крокодила делать крокодила летающего.
Я, если честно, могу расширить это утверждение ещё шире: абсолютно не важно на чем вы напишете write-only код.
Я этих устриц ел, и ответственно заявляю, что на OCaml, а уж тем более с включённым -Werror одноразовый write-only код писать менее комфортно, чем на Питоне. Вас задолбает компилятор, необходимость где-то таки описывать типы и т.д.
Простота и понятность как раз-таки кратно возрастают, но да, за счёт того, что над кодом приходится немножечко больше думать, когда ты его пишешь.
Я писал про простоту и понятность языка, а не кода. Код же, в контексте, write-only => как он будет там пониматься через месяц, не важно. В конце-концов, на тип прекрасно можно намекнуть названием переменных, если нет привычки использовать Хаскельно-Фортрановский подход (основные имена — i, j, k, l, m), конечно.
Сейчас же, усилиями разных комитетов Питон разросся по размеру до C++.
ReadOnlySadUser
05.09.2022 13:06+1Я всё ещё не понимаю о чём мы спорим :) Я согласен с тем, что для задач "сделать за пару дней и забыть" - динамически типизированные языке вполне норм. Можно ничего нигде не указывать и делать как хочешь. Даже документацию можно не писать.
Однако и статья не о таких задачах, да и ветка комментариев по сути начинается с утверждения, что type hints нужны, чтобы читающий мог что-то понять в написанном коде.
Если читателя нет - то и проблемы нет. Хотя вероятно и программа никому не нужна, кроме писателя :)

H737
03.09.2022 07:52-9Самое забавное, что, по моим ощущениям, везде я вижу одни и те же классы проблем. Я даже запилил сервис, где можно закинуть код и получить код ревью, и, собрав немного статистики, понял, что 50 типов ошибок достаточно, чтобы покрыть большую часть проблем в чужом коде. Но выборка у меня была небольшая, и я подумал: а что, если проверить много кода? И всё заверте...
А что если один раз "изобретенный велосипед" использовать во всем мире, а не изобретать его вновь и вновь в каждой компании и стране, где он нужен?
На кой разрабатывают однотипные программы в разных точках мира?
Да и не только программы, но и товары, придумывают, как оказать одни и теже услуги и еще много чего.
У организатора этого всего плохо с памятью и координацией?
Вполне допустимо, что "правая рука" не в курсе, что делает левая. А мозг то что? Тоже не в курсе, что делают руки?
А если в курсе, то на кой делать одно и тоже обеими руками, если каждой рукой можно делать что-то свое. Типа одна рука держит гвоздь, а другая машет молотком. Да, иногда нужно что-то держать обеими руками, но тогда в помощь другой чел, чтобы махать молотком.
Это упрощенная аналогия.
А что если посмотреть на деятельность всего человечества глобально?
Типа так достигается совершенствование технологий и товаров?
Так а зачем некоторые технологии разрабатываются с нуля?
Вот, например, есть Яндекс-доставка, там организован процесс доставки, создано ПО.
Но другая компания создает свой сервис доставки и создает свое ПО, типа наше будет лучше.И да, конкуренция и все такое прочее сопуствующее.
А где развитие и оптимизация хотя бы на уровне регионов и стран?
andrey_ssh
03.09.2022 08:05-165,500 постов в Хабе "python"
Пять с половиной постов?
А зачем в количестве постов точность до третьего знака после запятой?

Maksim-Burtsev
03.09.2022 09:17+1Есть некоторые мелочи, с которыми я не согласен, но в целом получилась очень полезная и интересная статья. Большое спасибо!


MagicWolf
03.09.2022 10:28+6Статья познавательная, спасибо.
Но вот пассаж про использование наследования классов для переиспользования кода - это та самая жесть, которой ООП мысль переболела в прошлом и теперь настойчиво рекомендует так не делать. Если очень нужны классы - то рекомендуется переиспользовать код путем агрегации. Если не нужны - хорош тот же функциональный подход типа partial.
Проблема в том, что иерархия наследования и переиспользование кода - это ортогональные вещи, которые могут по-другому сочетаться в другом проекте/ домене, который захочет переиспользовать ваш код. Или просто с течением времени это сочетание может измениться в изначальном проекте. А отделять их друг от друга в большой "заматеревшей" кодовой базе - тот еще квест.

Andrey_Solomatin
03.09.2022 11:25+2Спасибо за статью, у меня похожий шаблон для flake8, обогащу его вашими находками.
Я использую совместно с black, это автоматом исключает многие ворнинги.
Сложные аннотации типов можно вынести в переменную. Часто вместо типа
Generatorможно указатьIteratorтак проще. Когда я хочу подчеркнуть, что dict который я возвращаю менять не надо, я использую аннотациюMappingКогнитивную сложность у себя я отключил. Цикломатическая и когнитивная на маленьких цифрах очень похожа, а так плагином меньше.
Они, наверно, супермены и всегда помнят, что надо закрывать файлы?
Если быть педантом, то нужно еще через try-finally
Для настраеваемых функций часто использую класс с
__call__. Его потом легко подменять в тестах.from typing import Callable from requests import Session class Get: def __init__(self, session: Session): self._session = session def __call__(self, url: str) -> bytes: res = self._session.get(url) res.raise_for_status() return res.content def application(getter: Callable[[str], bytes], url: str) -> bytes: return getter(url) application(Get(session=Session()), "https://google.com") def stub(_: str): return b"test" application(stub, "https://google.com")

amarao
03.09.2022 12:18+3У меня боевой язык программирования питон, а любимый - rust. И я не понимаю почему я должен писать типы в питоне. Я нажимаю много кнопок (и даже думаю про всякие там суммы типов), а в обмен мне ничего не дают, кроме жалкой подсказки в автокомплите. Как насчёт правильной валидации типов? Ах, да, где-то там есть код без аннотаций типов, так что вывести типы не получается никаким образом. А у кого-то вот этот самый
super(args[0])(**kwargs)и угадай какой у него там тип.В сравнении с нормальной типизацией, type hinting в питоне - чистой воды карго-культ. О, у Больших Белых Людей есть Большая Ржавая Компилятора, которая Умеет Типы. Надо нам добавить Типы и тогда мы будем как Большая Ржавая Компилятора и мы сможем гордиться и любить наши Типы.
Нет, не сможем. type hinting помогает для фиксации контракта, но этот контракт никем не энфорсится.
Более того, я даже НЕ МОГУ написать сигнатуру условного выхода.
def conditional_exit(condition: bool) -> ?: if not condition: return False os.exit(0)Какой тип у нас после вызова os.exit(0)?
None? Но это не правда, os.exit не возвращаетNone. Где мой '!'? (AKA⊥)?
igor6130
03.09.2022 12:29+2Наверное все же sys.exit(). И он возвращает тип NoReturn.
amarao
03.09.2022 13:15Ага, а какой тогда у нас возвращаемый тип у функции?
Union[bool, NoReturn]? Но это же не правда! Типом должен быть bool, а NoReturn - это его subtype. Стоп. А питон поддерживает subtyping?igor6130
03.09.2022 13:35bool относится к базовым типам. Но есть еще дополнительные из модуля typing.
mayorovp
03.09.2022 16:39Стоп. А питон поддерживает subtyping?
А почему бы не взять и не проверить?
def conditional_exit(condition: bool) -> bool: if not condition: return False sys.exit(0)Success: no issues found in 1 source file

tzlom
05.09.2022 13:34почему вообще должен быть здесь NoReturn ? Эта функция может вернуть только bool, NoReturn нужен только для функций которые безусловно завершаются чтобы проверить что мы не забираем значение и вообще не ожидаем что дальше может быть что-то кроме Exception.Oh wait а как же мы декорируем исключения ? :)
amarao
03.09.2022 14:06os._exit, пардон. Алсо, я посмотрел help на них обоих (sys.exit и os._exit) и ни один из них не имеет типосигнатуры (Python 3.10.6)
igor6130
03.09.2022 18:57О том, какой тип возвращает функция, мне подсказал Pylance в VSC.

amarao
03.09.2022 19:25Вот это интересно.

То есть в самой функции этого нет, информация о типах где-то в другом месте. Или питон не показывает сигнатуры в справке? Ещё чудеснее.

andreymal
03.09.2022 19:57+1В стандартной библиотеке аннотаций типов нет, они в сторонней либе typeshed
Вообще, это сейчас стандартная практика костылять аннотации отдельно (и зачастую неофициально), для того же несчастного Django есть django-stubs например
amarao
03.09.2022 22:04Грустно. Интересно, как бы выглядел питон с статической типизацией но полным выведением типов? (то есть без обязательных сигнатур у функций). Я не думаю, что сильно распухшим по сравнению с "без типов" сейчас.
А вот пользы было бы...
kesn Автор
03.09.2022 12:30Тайп хинтс нужны, чтобы понять, что вообще куда можно передавать и что имел в виду разработчик. Да, контракт на минималках. Я сам обожаю nim, но там до коммерческой разработки как до луны, а rust меня победил

lgorSL
03.09.2022 13:20Не так уж много языков, в которых явно есть bottom type. В java или C++ в аналогичном случае conditional_exit будет возвращать bool и всё.
И, насколько я понимаю, bottom type | bool == bool, так что это вполне корректно.amarao
03.09.2022 13:23Да, так вопрос в том, будет ли валидатор типов (линтеры там или что у питона) правильно понимать, что os.exit в конце функции - это subtype от return bool.
lgorSL
03.09.2022 13:47Скорее всего нет, но можно по-другому написать:
def conditional_exit(condition: bool) -> bool: if condition: os.exit(0) return Falseamarao
03.09.2022 14:05Можно и так, но я специально написал в форме, которая показывает странность системы type hinting для питона.

inkelyad
03.09.2022 15:27И линтер ругается на недостижимый код после os.exit(0) или еще что-нибудь похожее в том смысле "что-то такое излишне странное написал"
Murtagy
05.09.2022 09:59Очень слабо подтвержденный наброс.
Ты можешь написать условный выход используя typing.overload.
Типы и контракты в типах в коде поддерживает анализатор, который встроен в CI.
Как ты вообще притянули сюда раст не очень понятно. "Большая Ржавая Компилятора" связи с типизацией в питоне имеет не больше чем с любым другим языком



Hungryee
03.09.2022 12:24Прекрасная статья! В свое время заменила бы мне первый год разработки на питоне)

bugy
03.09.2022 12:30+10Крутая статья, спасибо :)
Выскажусь про "длинные методы". Тут очень деликатный вопрос как по мне. В погоне за короткими методами можно получить ещё более трудночитаемый код:
Часто единый флоу нарезают по методам, и чтобы понять, что делает паблик функция (или, вернее, как конкретно работает), нужно попрыгать по всем вызываемым методам. И это не решается правильными названиями, поскольку реально алгоритм/флоу сложный. И искусственное деление его по 7 строк никому лучше не сделает.
В погоне за правилом "не более N строк", разработчики будут просто пихать больше кода на одну строку

Megadeth77
03.09.2022 15:59+1def get_orientation(obj: Ufo) -> tuple[float, float, float]: # WAT? это что такое?
UserId = int FooId = int BarId = int def return_something() -> Tuple[UserId, FooId, BarId]: ...Частенько выручает. Но не в этом случае.


kchhay
03.09.2022 20:08+6Я, вообще, не разработчик на питоне, я пишу на плюсах, но иногда приходится читать питон-код и он всегда ужасен. Каждый раз, когда я спрашиваю у интернета "лучший способ сделать что-то", интернет мне отвечает: "Смотри! Есть отличный способ! Давай засунем все в одну строку! Это самый лучший путь!".
Когда начал читать статью - был приятно удивлен. А потом дошел до пункта о nested if и погрустнел.
Почему бы в этом чудесном примере не использовать описанный немного позже прием "Early quit"?if min_val is not None and max_val is not None: if max_val < min_val: raise ValueError("max_val is greater than min_val") # тут уровень отступов == 2 # ...вжух! if min_val is not None and max_val is not None and max_val < min_val: raise ValueError("max_val is greater than min_val") # тут уровень отступов == 1 # ...вжух! ...вжух-вжух! if min_val is None or max_val is None: raise InvalidValue("max_val or/and min_val are None!") if minval > maxval: # в условном операторе только логика, никакой дополнительной нагрузки raise ValueError() # все еще уровень отступов == 1Возможно, я слишком избалован best-practices на привычном мне языке и тяну оттуда вещи, которые невалидны в других местах, но если нужно всунуть множество разных проверок в один if - то лучше этого не делать. Разбейте на функции, вынесите в отдельные переменные, разбейте на несколько if-ов - это немного увеличит код. Но это немного упростит чтение. Кажется, игра стоит свеч.
Еще из примеров, с которыми я категорически не согласен в заданном виде, это об использовании условного тернарного оператора. Возможно, это я недостаточно умен, но имхо, если там что-то сложнее, чем то, что указано в примере - лучше вынести это в отдельную функцию (которую вы потом отдельно протестируете), чем нагружать одну строку тонной логики. Терпеть не могу что-то в духе такого:
if abs(a) > abs(b): abs_diff = abs(a) - abs(b) else: abs_diff = abs(b) - abs(a) # ...вжух! ...??????? abs_diff = abs(a) - abs(b) if abs(a) > abs(b) else abs(b) - abs(a) # Конечно, совсем корректным было бы сказать abs(abs(a)-abs(b)), но в качестве иллюстрации сойдет...Длинная строка. Длинная. С кучей слов. Где тут вызовы функций, где начинается одно выражение, где заканчивается другое, в каком порядке все это исполняется? На все эти вопросы можно найти ответ. Но взгляд спотыкается. (Где-то также, как на ужасной практике в С++ писать if (CONST_VALUE == variable) вместо if(variable == CONST_VALUE)), которая, слава умным людям, уже отходит в прошлое).
Конечно, условный тернарный оператор - это хорошо, если у вас тривиальный код. Но если там есть хоть что-то сложнее, чем "одна проверка, одно присваивание" - то пожалуйста, сделайте это функцией. Это проще читать. Это проще тестировать. Это проще.
Вещь, которую (насколько я разобрался) понял автор - код пишут намного реже, чем читают. Наверняка в статье есть еще вещи, к которым можно придраться. Есть вещи, которые можно сделать еще проще. Но мне очень нравится, что хоть где-то, хоть кто-то согласился с тем, что код на питоне - непомерно-сложный для чтения. Теперь я чувствую, что я не один такой.
Автору спасибо.
Murtagy
04.09.2022 00:45С совмещением условий в один if также не согласен с автором, условие стало сложнее и текст набрал плотности
genvox
05.09.2022 10:45Отличная статья; во многом советы универсальны и не зависят от языка программирования. Не являясь специалистом Python (и поэтому буду стараться писать в общих терминах), все же отмечу моменты, с которыми не согласен:
1) Redundant else - нарушается блочная структура. Есть старое доброе правило - один вход, один выход. Вполне допуская оправданность конструкций вида:
if check_1: return if check_2: return ... main codeотмечу, что при такой структуре идет разрушение кода функции как одного блока, который можно во что-нибудь обернуть. Нередко встречал ситуации, когда в начале нужно вызвать какой-нибудь обработчик (логирование?) и в конце тоже нужно вызвать какой-нибудь обработчик (профилирование?). Оптимальным здесь считаю goto в конец, сразу перед return. Здесь можно возразить, что тогда следует написать функцию-обертку, но все же, все же... вариант с goto более "модульный" какой-то, что ли.
2) "Заменяйте ненужные переменные на underscore " - не понял смысл этого. Потом логика изменится, понадобится сослаться на эту переменную цикла, и придется изменить с "_" на "i"? Идея менять имя чего-то только потому, что оно вдруг понадобилось, выглядит довольно странной.
Но по большому счету, это мелочи.
kesn Автор
05.09.2022 10:55Как раз хотел сказать: напишите враппер :) Но вообще да, вы правы, и когда нужно что-то сделать "после" в любом из вариантов выхода, то предложенный подход не катит.
Да, если придётся сослаться, то надо будет заменить на
i. Это как с мёртвым или закоментированным кодом: от него нет толку, но он занимает место.iтоже занимает место в голове, не неся смысловой нагрузки, в то время как_глаз проскакивает, не обращая внимания. В питоне_для неиспользуемых переменных вроде как типа стандарт, поправьте меня, если я не прав. Ну и сравните:
roll, pitch, yaw, speed = get_many_params(object) # vs _, pitch, _, speed = get_many_params(object)Имхо, второй вариант несёт меньше нагрузки.
genvox
05.09.2022 11:58Имхо, второй вариант несёт меньше нагрузки.
Почему-то мое имхо с точностью до наоборот :)
Один из важнейших принципов читаемости, который я вывел за много лет кодинга (на pl/sql) - чтение кода должно вызывать как можно меньше вопросов. Вот я читаю первый вариант
roll, pitch, yaw, speed = get_many_params(object)И тут нет особых вопросов. Также здесь соответствие принципу
Легко читать > Самодокументация > Названия переменных
Если меня вдруг заинтересует, где именно используется roll, и как именно - я либо воспользуюсь поиском, либо выделю слово, чтобы редактор его подсветил во всех остальных местах. Учитывая то, что функции у нас не километровые (в соответствии с другими вышеоговоренными принципами), проблем с этим нет.
Читая же
_, pitch, _, speed = get_many_params(object)У меня сразу в голове возникают вопросы - а что именно скрывается за этими "_" - и будьте уверены, я пойду ковырять этот
get_many_paramsв попытке это понять. А потом изменится алгоритм, бизнес-процессы, понадобится мне тот же roll, и придется после полугода забытья опять ковырять get_many_params, чтобы понять, где именно этот roll возвращается. В случае же первого варианта я сразу воспользуюсь этим roll. Здесь также нарушается принцип понятных имен. То есть принцип понятных имен входит в конфликт с принципом "неиспользуемое называем "_" ".Исходя из всего вышесказанного, я бы предпочел сразу явно видеть, что к чему. Мне претит мысль, что из-за дизайна вызываемых функций надо вмешиваться в имена объектов вызывающих функций - это какое-то нарушение независимости получается.
Насчет стандартов ничего не могу сказать, ибо не специалист в python. Поэтому сужу с точки зрения "в целом", используя опыт кодинга на pl/sql :)
kesn Автор
05.09.2022 12:08+2Я думаю, у питонистов таких вопросов не возникает, к подчеркиваниям все привыкли и им понятно. И мне кажется, тут всё-таки yagni важнее :P Ну каждому своё ????♂️, сверху уже писали, что Джанго, например, зарезервировали "_" под локализацию текста
iig
05.09.2022 12:55roll, pitch, yaw, speed = get_many_params(object)КМК, ужасная практика (все так делают, да). Потом функция стала возвращать не 4 параметра, а 5 - и всё сломалось. Или при вызове функции программист их неправильно сосчитал. Или, чтобы не ошибиться с подсчетом, скопипастил правильный вызов, но не до конца исправил.
genvox
05.09.2022 13:34+2Потом функция стала возвращать не 4 параметра, а 5 - и всё сломалось
В python такое считается нормальным? Ну, в смысле, когда кто-то меняет api функции и при этом не просматривает все места, откуда она вызывается? Дескать, не мои проблемы? :) При работе с компилируемым ЯП я бы только рад был, если бы такое ломалось и уже на этапе компиляции валилось с ошибкой.
Или при вызове функции программист их неправильно сосчитал. Или, чтобы не ошибиться с подсчетом, скопипастил правильный вызов, но не до конца исправил
А вот это уже манипулятивные аргументы :) Потому что это вообще здесь не при чем. Программист может ошибиться в чем угодно и где угодно. Чтобы не ошибаться при копипасте, надо не копипастить. А чтобы не ошибаться в написании кода, надо его не писать. Приведу пример из мира баз данных:
можно писать везде
select * from tblвместо
select fld_1, fld_2, ..., fld_n from tblдескать, если еще одно поле добавится, его не надо прописывать лиший раз. Но это может не только негативно сказаться на производительности, но и по сути означает потерю контроля над кодом. В этом месте нужно только эти поля, в этом - только вот эти. Читая везде все скопом сразу - по сути создается помойка, где непонятно, что именно нам нужно, ради мимолетного удобства программиста (не нужен копи-паст имени поля в те места, где оно нужно). Возможность ошибиться исключается, но возможностей ошибиться вообще бесконечно много, чтобы ради этого поступать в ущерб другим, важным областям (читабельность, производительность, контролируемость кода разработчиком, контроль зависимости объектов).

cadovvl
05.09.2022 11:04+2Все очень хорошо, но...
* В статье на хабре я могу приводить примеры плохого кода. Например: вот тут копипаста, а вот таким изящным способом я могу ее избежать.
* Я могу ссылаться на чужой плохой код, который мне не нравится. Разные причины могут заставить меня вставить чужую работу, например, на задачу FizzBuzz по-сеньорски уже пяток ответок прилетело.
* В демонстративных целях я могу писать код, отличающийся от того, который я напишу в рабочих проектах. Например, в рабочих проектах я никогда не поставлю магическую константу, а в примере на хабре я не буду занимать лишнюю строчку под переменную. Я же писал, почему здесь 42 в предыдущем абзаце, не думаю, что вы забыли.
И вот я написал действительно полезную статью, вместо чтения ее проверили на соответствие формальным параметрам, и оценили как "негодную".
Выдайте, пожалуйста, список формальных параметров, и я натренирую нейросеть писать вам годные статьи. Вам же их потом читать.
git-merge
Всё нижележащее - моё имхо
Хорошие рассуждения: вместо докстринги использовать хорошее имя функции.
Но продолжаем думать в этом направлении и приходим к чему?
хорошее именование переменных позволит выбросить монструозный тайп-хинтинг на помойку по той же логике, почему выбрасываем докстринг
всё равно тайпхинтинг не работает в рантайме
количество ошибок, которые позволяет обнаружить тайпхинтинг меньше того количества ошибок, которые позволят обнаружить тесты, содержащие столько же букв сколько потрачено на тайпхинтинг
За смешивание декораторов с объектно-ориентированным программированием где-то в аду для того, кто это придумал предусмотрен отдельный котёл. По мне, так это прямо образец "неправильно"
danilovmy
Я только из Ада. Там у них для пользователей класс декораторов котел задекорированный под сковородку.
fransua
А расскажите, что не так с декораторами и ООП, это особенность питона?
Я про питон мало знаю, но в C# и JS с декораторами в классах все классно.
amarao
Хорошие декораторы хороши, но проблема в том, что из-за отсутствия проверки типов перед запуском у нас одна функция что-то делает с аргументами другой функции и подсовывает её вместо оригинальной функции, так что когда что-то ломается, то программист точно знает, что что-то где-то не так, наверное.
arheops
ИИ не завезли и IDE не настолько продвинуты, чтоб помогать пользователю искать ошибки в функции, когда он ее переопределяет в рандомных местах.
git-merge
В ООП поведение методов принято изменять при помощи штатного механизма - наследования..
В ФП поведение функций принято менять при помощи функций-обёрток (врапперы).
Декораторы - это мир ФП. Применение декораторов к ООП приводит к тому, что
декораторы почти всегда применяются к инстансу, а не классу
получается хак на саму парадигму программирования.
Давайте повсюду смешивать тёплое и мягкое и будет хорошо! Нет, этот принцип из разряда плохих советов, даже если очень многие или слишком многие ему следуют. Как-то так.
fransua
Еще есть аспектно-ориентированное программирование, которое вполне про декораторы в классах.
git-merge
Да, но нет.
если например в Вики почитать описание зачем нужно АОП, то там написано "для таких вещей как обеспечение сквозной функциональности". Например доступ к системе логгирования отовсюду итп.
и тут наверное декораторы в классах можно было бы как-то применять (хотя и не очень они туда ложатся)
но я что хотел сказать: декораторы обычно применяются не для АОП, а как ФП-хак над ООП. Например, популярная в питон FastAPI
Скопирую кусок из документации сюда:
Что мы тут видим? а мы тут видим вместо создания наследника с определением нужного поведения - извращения над инстансом класса.
К чему это приводит?
Человек создаёт два сервера API с разным набором методов
При помощи декораторов наделяет два разных инстанса разным поведением
Затем когда он хочет для первого и второго сделать что-то специфичное, то
вернуться к наследованию ему крайне сложно (кода уже дофига написано)
поэтому приходится извращаться вводя дополнительные хаки
Если бы декораторы использовались в массе своей для ФП и даже для АОП, то я бы против них ничего не имел, но увы, чаще всего декораторы применяются не для этого
VPryadchenko
Ни над каким инстансом класса никаких извещений здесь не происходит, ведь меняется поведение функций, а не инстанса класса FastAPI. Ну это так, скорее придирка. А вот проблемы, честно говоря, не понятны, слишком уж высокая степень абстракции: что, например, такого специфичного можно захотеть сделать, чтобы стало нестерпимо больно от отсутствия наследования?
Охотно верю, что вы приедете пример, но, подозреваю, что вероятность такой ситуации нивелируется удобством и гибкостью, который даёт описанный выше подход, и это общее правило (ООП тоже не безупречно). Существуй универсальный удобный и лишённый изъянов способ сделать все, что угодно - все бы только им и пользовались.
git-merge
Инстанс создаётся в строке
Затем, используя декораторы проставляются обработчики запросов.
Я говорю о том, что заколачивание гвоздей микроскопами, даже если оно почему-то в конкретном случае удобнее - есть зло в чистой форме
VPryadchenko
То-то и оно, что здесь вполне себе заколачивание гвоздей молотком. Проблемы могут возникнуть от неправильной эксплуатации.
Повторюсь, над объектом FastAPI глумление не имеет места быть.
mayorovp
Ну вот представьте, что вместо декораторов обработчики запросов проставляются более прямым способом:
Или вообще представим чистый ООП-способ:
Стало ли лучше? Сомневаюсь.
Кстати, где вы тут вообще увидели применение декораторов к методам?
kesn Автор
Не кидайте в меня помидорами, но первый вариант таки лучше, имхо. Сразу в одном месте определено, куда пойдёт юзер в зависимости от
url, вместо того, чтобы ходить по функциям и в декораторе смотреть их путь.mayorovp
Но при написании каждой конечной точки надо править сразу два места в программе. Причём в этих двух местах надо согласовывать имена параметров маршрута. К тому же второе место, вмещая в себя вообще все маршруты, будет регулярно становиться источником конфликтов в гите.
Тем не менее, при желании так всё же можно сделать и с текущим api:
tzlom
ого, да вы питонист который понимает декораторы
git-merge
я не понимаю почему используя "чистый ООП-способ" Вы строите таблицу роутинга после создания инстанса.
Для меня этому находится только следующее объяснение: подход с декораторами настолько сильный отпечаток оставил, что не удаётся от него избавиться :-\
mayorovp
Это обыкновенный паттерн "Строитель" ("Builder"). Появился он, может, и позже Питона — но задолго до декораторов в нём.
Murtagy
Тайп хинты крайне полезны не только как "тестирование" когда, но и как документация (валидируемая), и как инструмент помогающий изменять код (измените тип - сразу покажет в каких местах отваливается код).
Мне кажется в целом противопоставление тестов типизации это ложное сравнение. Вы же не будете рассказывать разработчику на С++ или Go что типы не нужны?
Питон хорош тем, что можно постепенно добавлять в кодовую базы как тесты, так и тайпинг. И скорее всего, если у вас серьезный проект, с самого начала там будут и тесты, и тайпинг, как средства помогающие сдерживать фрустрацию команды
git-merge
Автор статьи сделал потрясающий вывод (который я много лет пытаюсь вкладывать в головы людей, но заходит временами крайне тяжело): если из названия функции понятно что она делает, то документировать её поведение не обязательно. (то есть потратить силы на выбор хорошего названия всегда выгодно)
То же самое касается аргументов и возвращаемого значения.
Для чего нужны тесты?
Чтобы выявить проблемы в коде
Чтобы выявлять проблемы, возникающие в коде после внесения в него правок
Для чего нужны типы? (в контексте тайпхинтов)
Чтобы выявить проблемы в коде: ожидаются килограммы, программист передаёт градусы
То есть сравнение не ложное, пересечение "зачем" очень обширное.
Мне крайне нравится то что Go взял в язык парадигму параллельности.
Мне крайне не нравится, то, что он отказался от исключений (и программисты де-факто при помощи кортежей
nil, errorреализуют исключения самиМне так же очень хочется язык без возни с типами, но с аналогичной парадигмой на борту. Я не буду рассказывать что типы в Go не нужны, но язык с возможностями Go (многотред + файберы из коробки на борту) и на базе скриптовой парадигмы был бы конфеткой.
как-то так
Murtagy
"Выявить проблемы" это упрощение:
Допустим в автомобиле тормоза - это система для спасения жизни, и подушки безопасности - это система для спасения жизни.
Хочется убрать одно из двух?
Думаю нет.
У меня отношение к типизации-тестированию такое же, убирать одно из двух не хочется. Несмотря на общие цели, более детальный фокус иной.
По поводу исключений я думаю что вопрос спорный. Как по мне это неявная передача контекста выполнения в крайних условиях, без гарантируемой обработки этих крайних условий.
Мастадонты индустрии (например разработчик языка D, Александреску) также отмечают проблемы с исключениями. Свое мнение крайней инстанцией не считаю.
Я считаю что типы упрощают а) восприятие (простота) кода, б) изменение (рефакторинг) кода, в) поиск зависимостей и крайних случаев.
И я есть обычный груг, если что-то помогает сдерживать сложность (главный враг груг), учитывая что время есть бесконечность, груг брать типы в свой код!
git-merge
тайпхинты, не работающие в рантайме, не несут иной функциональной нагрузки, кроме выявления проблем на стадии редактирования.
Передавать строки вместо словарей по прежнему возможно.
Писать неверные тайпхинты по прежнему возможно
итп
Murtagy
так... и?
тесты тоже в рантайме ошибки не ловят
и то, и другое нужно предварительно запустить
git-merge
Я комментировал тезис что "тайпхинты для выявления проблем на стадии редактирования" - это упрощение.
Это не упрощение, а факт.
Murtagy
Мое замечание направлено в сторону "выявления проблем". Проблемы бывают разные, что я пытался показать на примере тормозов и подушек безопасности.
То что тесты работают также не работают в рантайме решили не замечать?