
В части 1 мы познакомились с понятием энтропии.
В этой части я рассказываю про Взаимную Информацию (Mutual Information) – концепцию, которая открывает двери в помехоустойчивое кодирование, алгоритмы сжатия, а также даёт новый взгляд на задачи регрессии и Machine Learning.
Это необходимая компонента, чтобы в следующей части перейти к задачам ML как к задачам извлечения взаимной информации между факторами и прогнозируемой величиной. Один из способов объяснения успешности ML моделей заключается в том, что они создают естественное бутылочное горлышко, ограниченное автоподстраиваемым значением бит информации, через которое пропускается (дистиллируется) информация о входных данных. Но про это – в следующей части.
Здесь будет три важных картинки:
первая – про визуализацию энтропий двух случайных величин и их взаимную информацию;
вторая – про понимание самой концепции зависимости двух случайных величин и про то, что нулевая корреляция не значит независимость;
и третья – про то, что пропускная способность информационного канала имеет простую геометрическую интерпретацию через меру выпуклости функции энтропии.
Также мы докажем упрощённый вариант теоремы Шаннона-Хартли о максимальной пропускной способности канала с шумом.
Материал довольно сложный, изложен неподробно и больше похож на заметки для лектора. Подразумевается, что вы будете самостоятельно изучать непонятные моменты или писать мне вопросы, чтобы я раскрыл их понятнее и подробнее.
2. Mutual Information
Когда есть две зависимые величины, можно говорить о том, сколько информации об одной содержится в другой. Последние задачи в части 1 по сути были про это – про Взаимную Информацию двух случайных величин.
Рассмотрим, для примера, пару= (вес_человека, рост_человека). Для простоты будем считать, что это целые числа в килограммах и сантиметрах с конечным числом возможных значений. Теоретически, мы могли бы собрать данные 7 млрд. людей и построить двумерное распределение для пары
— распределение двух зависимых случайных величин. Можно построить отдельно распределение только веса
(забыв про рост), и распределение роста
(забыв о существовании веса). Эти два распределения называются маржинальными распределениями для совместного распределения на плоскости
Эти маржинальные распределения естественно в данном контексте называть априорными распределениями — они соответствуют нашему знанию о весе и росте, когда мы ничего не знаем про человека.
Ясно, что информация о росте человека заставит нас пересмотреть распределение веса, например, сообщение "рост = 2 метра 10 см" сместит распределение веса в область больших значений. Новое распределение веса после получения сообщения естественно назвать апостериорным. Соответственно, можно записать формулу информации, полученной в этом сообщении, как разность энтропий априорного и апостериорного распределений:
Здесь снаружи фигурных скобок я пишу индекс, по которому нужно "бежать" внутри фигурных скобок, чтобы получить список, а если индексов два, то матрицу.
Важно отметить, что никто не гарантирует, что эта величина будет положительная. Возможно такое совместное распределение при котором условное распределение
имеет большую энтропию (неопределенность), нежели маржинальное распределение
. Но в среднем для зависимых случайных величин значение
положительно, а именно, мат. ожидание этой величины положительно:
Эту величину естественно назвать информацией о величине в величине
. Оказывается, она симметрична относительно перестановки в паре
.
Опр. 2.1: Взаимная информация двух случайных величин – это
или
или
Это три эквивалентных определения. — это энтропия дискретного распределения, у которого значения не числа, а пары чисел
. Эквивалентность докажем ниже.
Есть визуализация того, чему равно значение MI:
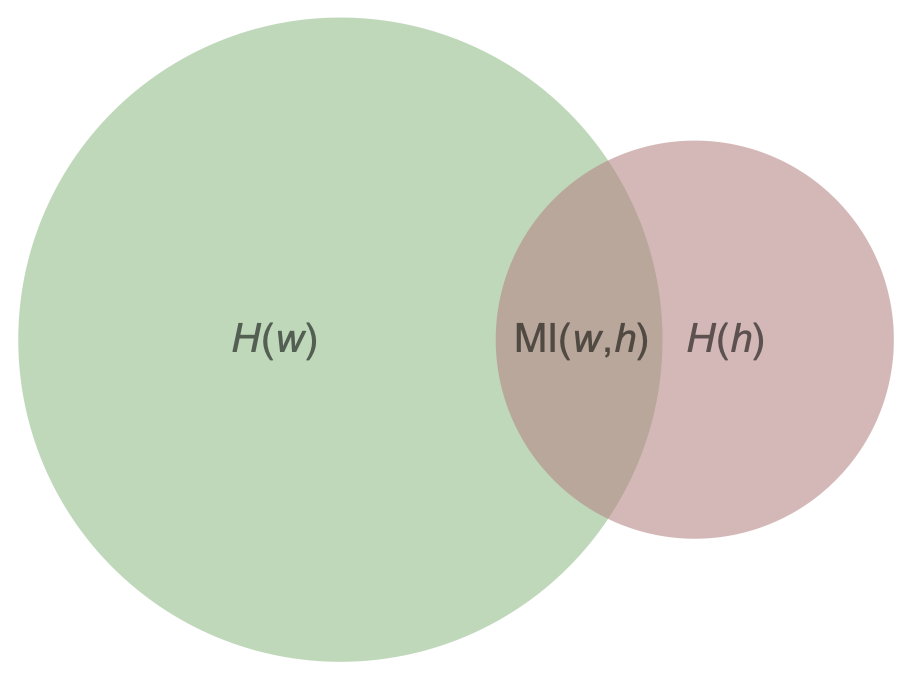
Энтропиям случайных величин соответствуют круги – зелёный и красноватый, их площади равны и
, а коричневая площадь их пересечения как раз равна
Энтропия как мера
Эта визуализация, с одной стороны, не более чем визуализация, подчёркивающая, что энтропия – это неотрицательная величина, и чтотоже неотрицательная величина, которая меньше либо равна обеих энтропий
и
. Но, с другой стороны, есть интересные результаты, что можно построить пространство с мерой, в котором случайная величина соответствует подмножеству, объединение подмножеств соответствует прямому произведению случайных величин (то есть объединение в пару), а мера подмножеств и есть энтропия соответствующих случайных величин.
Распишем подробнее первое выражение:
Запись — это просто сокращение для
и называется условной энтропией.
Для независимых случайных величин
так как по определению независимости для любого
а значит для независимых случайных величин взаимная информация равна 0.
Оказывается, в обратную сторону тоже верно, то есть утверждение эквивалентно независимости случайных величин. А вот для корреляции двух случайных величин аналогичное утверждение было бы неверным.
Чтобы увидеть эквивалентность определений MI, удобно ввести обозначения:
— вероятности того, что рост и вес равны.
— вероятности того, что рост равен(маржинальное распределение роста).
— вероятности того, что вес равен(маржинальное распределение веса).
Будем считать, что все эти числа не равны 0.
Во-первых, заметим, что
Далее делаем подстановки и простые преобразования и получаем эквивалентность первого и третьего определения:
Рассмотрение случая, когда какие-то из вероятностей равны нулю оставим учебникам.
Задача 2.1: Приведите пример случайных величин, для которых корреляция равна нулю, а не равна нулю.
Задача 2.2: Две случайные величины много раз измерили и нанесли точки на плоскость. Какие картинки соответствуют зависимым случайным величинам, а какие – независимым?
Для каких из них корреляция x и y равна 0?

Ответы
Зависимые: 3-й, 4-й, 5-й, 8-й, 11-й, 12-й.
Корреляция равна нулю для всех, кроме 4-го, 5-го, 8-го и 12-го.
Задача 2.3: Посчитайте MI(w="число делится на 6", h="число делится на 15"). Предполагается, что мы берём одно из натуральных чисел случайно и все числа равновероятны. Чтобы не мучатся с понятием равномерного распределения на натуральных числах, считайте, что мы случайно берём число из множества {1, ..., 30}.
Ответ
Мы знаем маржинальные распределения: и
Кроме того, мы знаем что вероятность делится и на 6, и на 15 равна 1/30. Из этого выводится матрица совместных вероятностей:
Используем формулу и получаем
MI=0.0311278
Задача 2.4: Докажите, что есть ещё одно эквивалентное определение
то есть MI – это то, насколько код Хаффмана для потока пар построенный в предположении независимости случайных величин (то есть в предположении, что совместное распределение равно произведению маржинальных), будет менее эффективен, чем код Хаффмана, построенный на настоящем совместном распределении. Измеряется в сэкономленных битах на символ (символ – измерение пары
).
Мы до сих пор жили в области дискретных распределений. Переход к непрерывным величинам получается просто.
Вспомним про задачу 1.7. Давайте предположим, что у нас есть вещественные случайные величины , но мы их дискретизировали — первую на корзинки размера
, а вторую — на корзинки размера
. Подставив в выражение
вместо H приближенную формулу (см. задачу 1.7)
для энтропий дискретизированного непрерывного распределения, мы получим, что из первого слагаемого вылезет из второго слагаемого —
а из третьего вычитаемого —
и эти три кусочка сократятся.
Таким образом, взаимную информацию непрерывных величин естественно определить как предел MI дискретизированных случайных величин при стремлении к корзинкам нулевого размера.
Опр. 2.2: Взаимная информация двух непрерывных случайных величин равна
Здесь мы пользуемся H из определения 1.6 части 1.
Задача 2.5: Оцените для какой-либо имеющейся у вас задачи прогноза чего-либо. Посчитайте
, насколько близко это отношение к 1?
Задача оценки MI двух случайных величин по множеству их измерений по сути сводится к задаче расчета матрицы совместного распределения для дискретизированных значений этих случайных величин. Чем больше корзинок в дискретизации, тем меньше неточность, связанная с этой дискретизацией, но тем меньше статистики для точной оценки
.
Оценка MI по наблюдаемым измерениям — отдельная большая тема, и мы к ней ещё вернёмся в задаче 3.1.
Задача 2.6: Докажите, что для любой строго монотонной функции верно, что
Ответ
Пусть . Возьмём две формулы
Первые слагаемые просто совпадают, а вычитаемые равны, так как их физический смысл — это среднее значение , где
— это разные случайные величины, получаемые из
при фиксирования значения
или, что то же самое при фиксировании значения
. Усреднение происходит по распределению значений
или
, что, опять же, неважно.
Посмотрите на интегралы. Значения и
просто совпадают, и в обоих формулах происходит усреднение этой величины по одной и той же вероятностной мере
просто по-разному параметризованной:
.
Опр. 2.6: Информационный канал — это цепь Маркова длины 2, задающая зависимость между между двумя зависящими случайными величинами, одна из которых называется input, а другая — output. Часто под информационным каналом имеют в виду лишь матрицу переходных вероятностей: без фиксирования значения входного распределения. Распределение на входе будем обозначать как вектор
а распределение значений на выходе как вектор
Для дискретных распределений мы для каждого из M возможных входов имеем распределение на N возможных значениях выхода, то есть мы по сути имеем матрицу из M столбцов и N строчек, в которой все числа неотрицательные, а сумма чисел в каждом столбце равна 1.
Такие матрицы называются стохастическими матрицами, а точнее левыми стохастическими матрицами (left stochastic matrix).
Про левые и правые стохастические матрицы
У левых стохастических матриц сумма чисел в каждом столбце равна 1, а у правых – в каждой строчке. Бывают ещё дважды стохастические матрицы, в которых и столбцы и строчки суммируются в 1. Я выбрал вариант, когда вектор вероятностей значений на входе рассматривается как столбец, и чтобы получить вектор вероятностей значений на выходе нужно проделать обычное матричное умножение .
В англоязычной литературе вектор вероятностей принято рассматривать как строчку, матрицу переходов транспонировать (и она станет правой стохастической) и умножать на матрицу слева: . Я боюсь, это будет многим непривычно , поэтому выбрал вариант столбцов и левых стохастических матриц перехода.
Таким образом, информационный канал суть левая стохастическая матрица T. Задавая распределение на входе, вы получаете распределение
на выходе, просто умножая матрицу
на вектор
:
Пропускной способностью информационного канала
называется максимальное значение
, достижимое на некотором распределении
на входе.
Информационный канал для передачи бит, в котором 1 из-за помех превращается в 0 с вероятностью а 0 превращается в 1 c вероятностью
задается матрицей
Задача 2.7: Пусть есть информационный канал с помехами, в котором 1 превращается в 0 с вероятностью а 0 превращается в 1 c вероятностью
Чему равно значение
при условии, что на вход поступает случайный бит с распределением
? На каком распределении на входе достигается максимум
и чему он равен, то есть какая пропускная способность у этого канала?
Ответ:
Здесь удобно воспользоваться формулой
Имеем:
Распределение на входе:
Распределение на выходе:
Совместное распределение, то есть распределение на парах (вход, выход):
-
И два условных распределения:
Если воспользоваться формулой MI, то получим:
А эта формула не что иное как мера выпуклости функции (aka JSD, см. ниже) на отрезке
, а именно, это значение этой функции на выпуклой сумме абсцисс концов этого отрезка минус выпуклая сумма значений этой функции на концах отрезка (ординат отрезка).

На рисунке показана функция . Отрезок KL делится точкой A в пропорции
. Длина отрезка AB и есть значение MI.
Максимальная длина отрезка достигается в такой точке, в которой производная равна углу наклона отрезка.
Обобщая задачу 2.7 на многомерный случай, получаем:
Утверждение 2.1: Пропускная способность канала определяется мерой выпуклости функции в симплексе, который является образом стохастического преобразования, задаваемым информационным каналом, а именно, максимальным значением разницы
от афинной (aka выпуклой) суммы вершин симплекса и афинной суммы значений функции
на вершинах симплекса. Максимум берётся по всем возможным весам, задающих афинную сумму.
Интересно, что на значение пропускной способности канала можно посмотреть как на некоторую меру объема, заключённого в симплексе, задаваемом множеством условных распределений как вершинами.
Опр. 2.4: Пусть есть несколько распределений на одном и том же множестве значений. Дивергенция Шаннона-Джейсона (Jensen–Shannon Divergence, JSD) этого набора c весами
вычисляется как
для
то есть
Чем сильнее распределения отличаются друг от друга, тем больше JSD. Максимум
и есть пропускная способность канала
Задача 2.8: Пусть есть две зависимые нормальные величины , с дисперсиями
и
соответственно, и пусть первая получается из второй добавлением независимого нормального шума c дисперсией
:
Тогда
Чему равна взаимная информация
?
Ответ
Энтропии величин и
равны
Энтропия пары вещественных случайных величин равна
Последнее равно после сумме энтропий двумерного распределения пары (энтропия пары независимых равна сумме их энтропий). А энтропия пары
равна энтропии пары
потому что линейное преобразование вектора случайных величин даёт вектор с той же энтропией (докажите это!).
Поэтому по формуле мы получаем
Замечание 1: Когда дисперсия (мощность) шума равна дисперсии (мощности) сигнала
каждое измерение
содержит 0.5 бита информации о значении
Замечание 2: Собственно, этот результат и есть теорема Шаннона-Хартли в упрощённом виде.
Задача 2.9: Пусть есть две зависимые величины , где
имеет экспоненциальное распределение с параметром
, а
. Чему равна взаимная информация
? Другими словами, сколько информации сохраняется при округлении экспоненциальной случайной величины до какого-то знака. Сравните
и
Ответ
Задача на понимание. Из первой случайной величины однозначно определяется значение второй. Значит информация MI равна просто энтропии второй величины, то есть .
Задача 2.10: Пусть есть две зависимые величины , где
имеет бета-распределение с параметрами
, а
сэмплируется из биномиального распределения с параметрами
. Чему равна взаимная информация
? Другими словами, сколько бит информации про истинный CTR рекламного объявления можно извлечь в среднем из статистики кликов на k показах.
Задача 2.11: Две зависимые величины получаются следующим образом – сначала сэмплируется случайная величина
из экспоненциального распределения со средним
, а потом сэмплируются две пуассоновские случайные величины
с параметром
. Чему равна взаимная информация
? Одна из возможных интерпретаций этой задачи такая: чему равна взаимная информация между числом продаж в одну неделю и числом продаж в другую неделю некого неизвестного нам товара.
Последние задачи являются примером того, как зависимости случайных величин можно моделировать с помощью графических вероятностных моделей, в частности, байесовских сетей.
Задача 2.12: Случайная величина получается из независимых случайных величин
с распределением
по формуле
Константные веса вам неизвестны, но априорное знание о них, это то, что они независимо были сэплированы из
. Вы решаете задачу вычисления оценок весов
классическим методом регрессии и строите прогноз
Как будет расти квадратичная ошибка и значение
с ростом размера обучающего пула? Проанализируйте ответ для случая
.