
Привет, хабр! С удивлением обнаружил, что здесь нет ни одного упоминания Grafana OnCall, Incident Response Tool с открытым исходным кодом от Grafana Labs. И это нужно исправлять, ведь мы бурно растем как по звездочкам на гитхабе, так и как часть Grafana Cloud, а в issues на гитхабе, в основном, встречаются техлиды из FAANG.
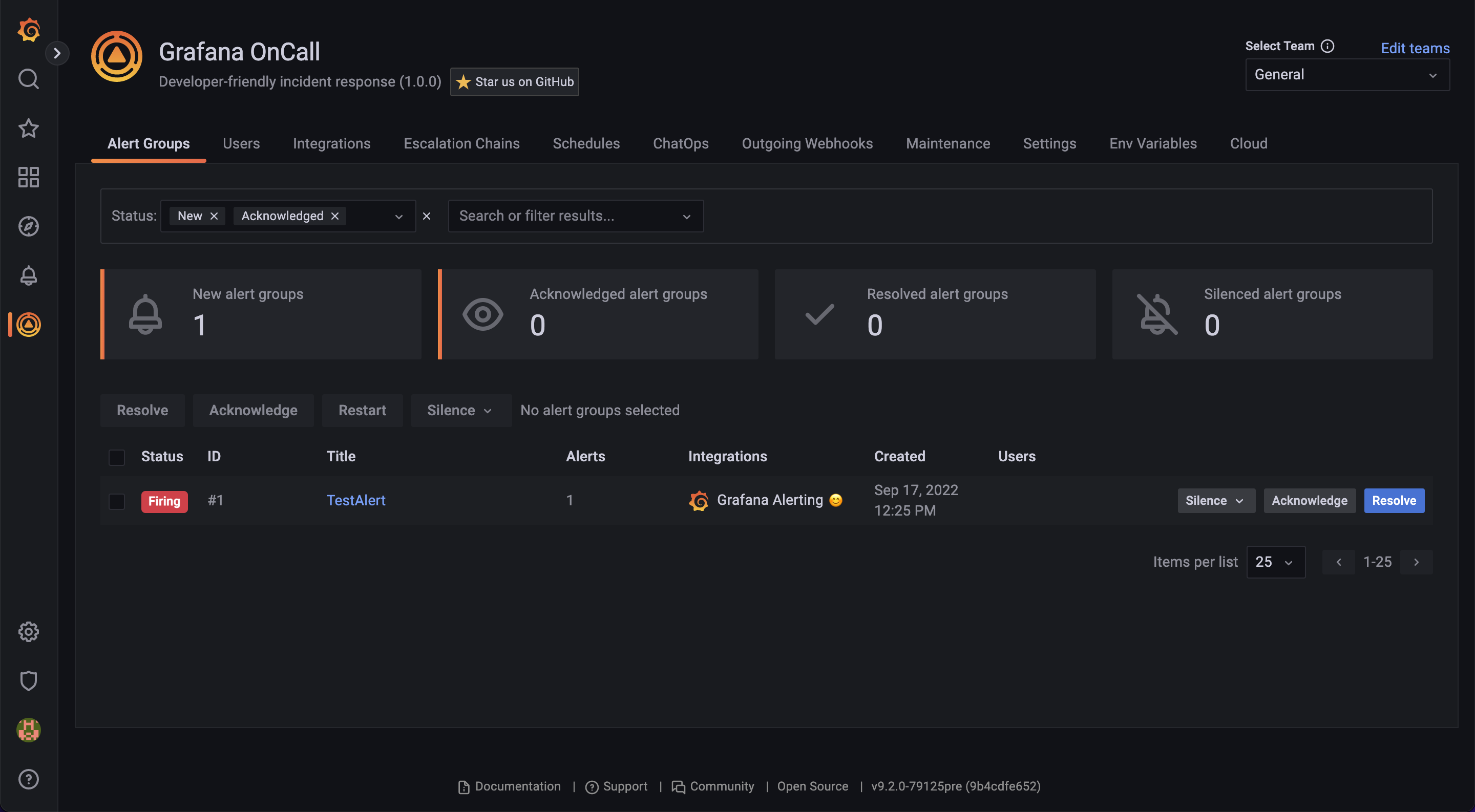
Если кратко, OnCall — это инструмент, который поможет организовать надежные оповещения/реагирование на инциденты в команде, соблюдать SLA и не просыпаться ночью от звонков.
OnCall — новичок в мире Open Source, но уже совсем не новичок как продукт. Он начался как отдельный SaaS под названием Amixr.IO несколько лет назад. Потом Amixr.IO приобрела Grafana Labs и интегрировала в свою экосистему. И вот недавно, наконец, мы смогли выложить исходный код OnCall в открытый доступ ???? А это значит, что он стал доступен большему кругу пользователей — и тем, кто работает в инфраструктуре без интернета, и тем, кто просто любит Open Source.
Что умеет Grafana OnCall?
Фич достаточно много, опишу основные.
Собирать алерты со всех источников
Каждая инитеграция — это набор шаблонов, которые применяются к данным, пришедшим от мониторинга по webhook. Из коробки доступны несколько, мы работаем над тем, чтобы увеличить список и покрыть все опенсорсные системы мониторинга. Даже, если вашего источника нет, ничего не мешает принять алерты на вебхук и отредактировать шаблоны. Самое важное — в OnCall можно собрать алерты со всего зоопарка мониторингов от Prometheus до PRTG в едином месте.
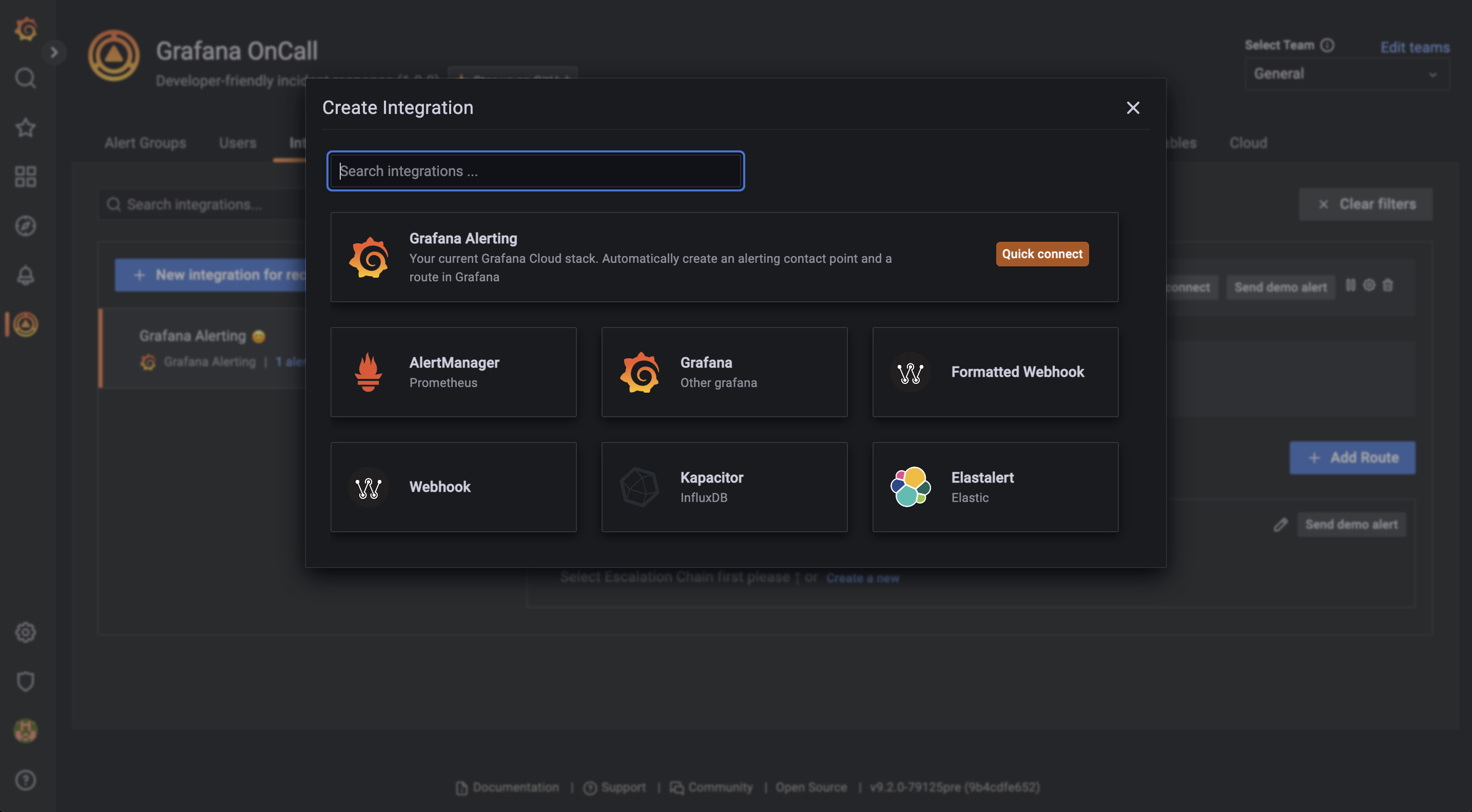
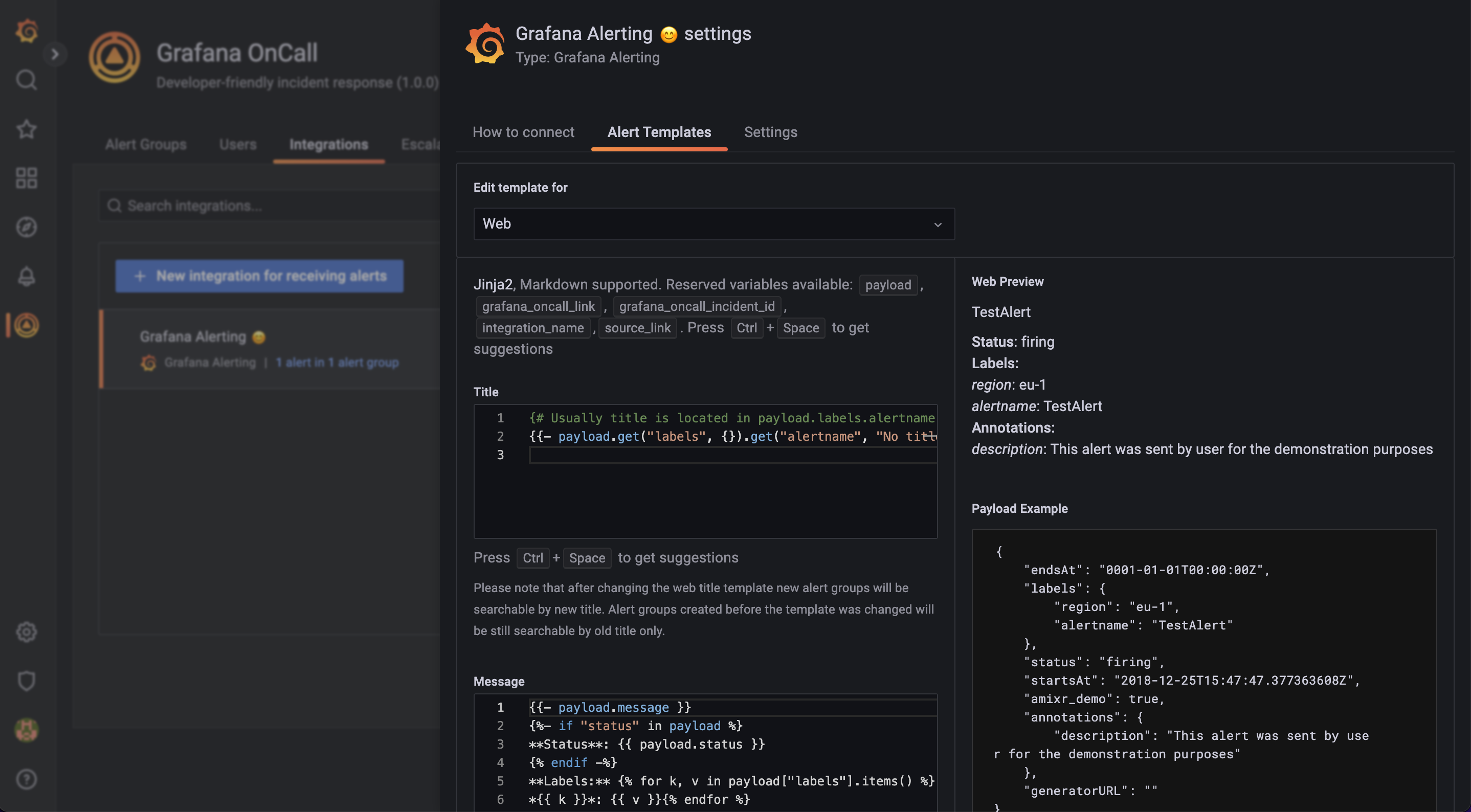
Форматировать алерты в шаблонами
Внутри OnCall с помощью шаблонов можно творить много магии. Например, можно менять внешний вид алертов, прицеплять к ним ссылки на ранбуки, вырезать ненужный хлам и так далее. Можно сделать алерты приятными. Например, они могут выглядеть так:
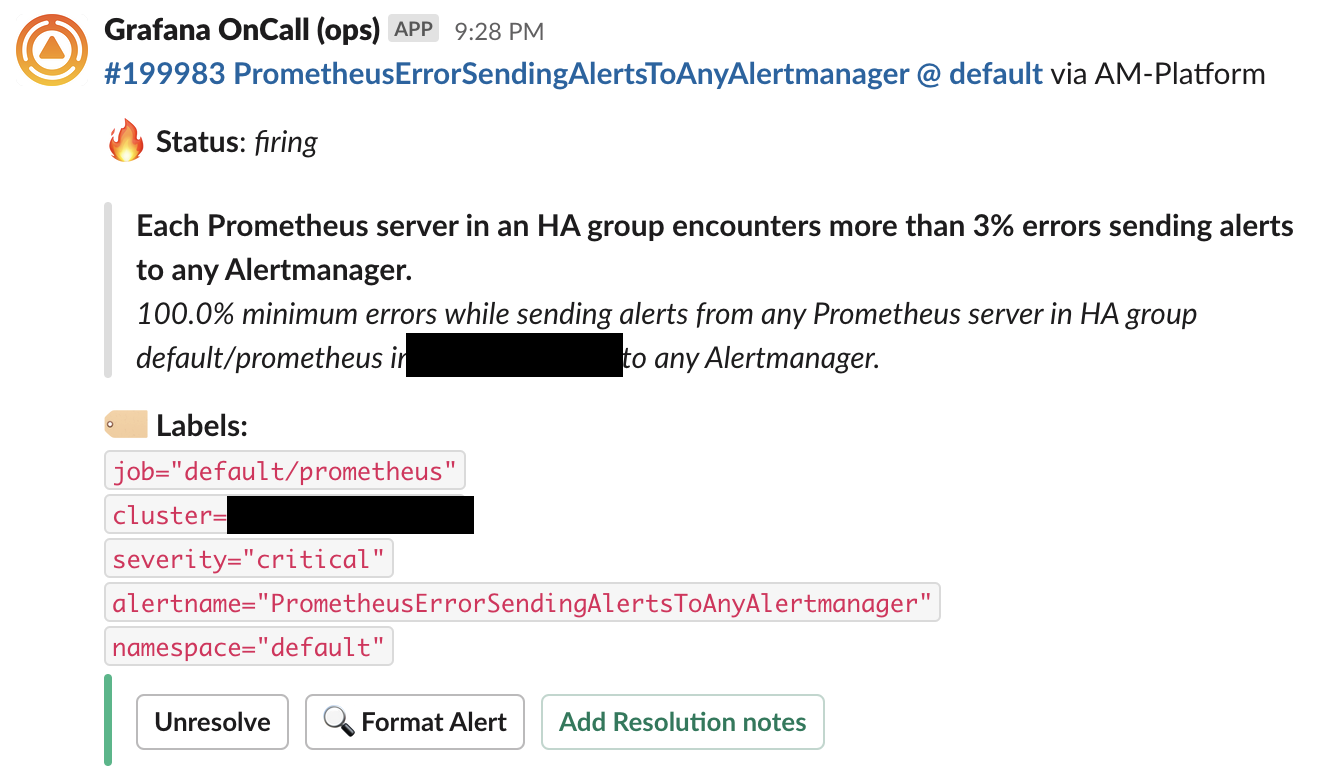
Или еще аккуратнее:
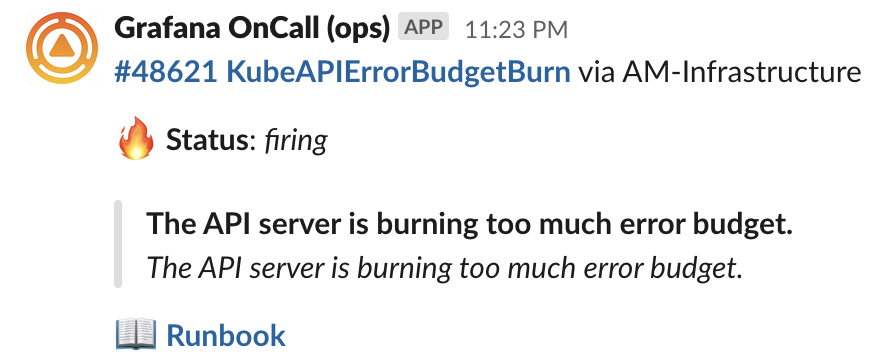
Доступно мощное форматирование при помощи Jinja 2, есть условные операторы, есть итераторы. Все поля можно форматировать по-отдельности:
Группировать
Одна из задач OnCall — бороться со штормом алертов в чатиках. Группировка работает на основе вот этого шаблона:
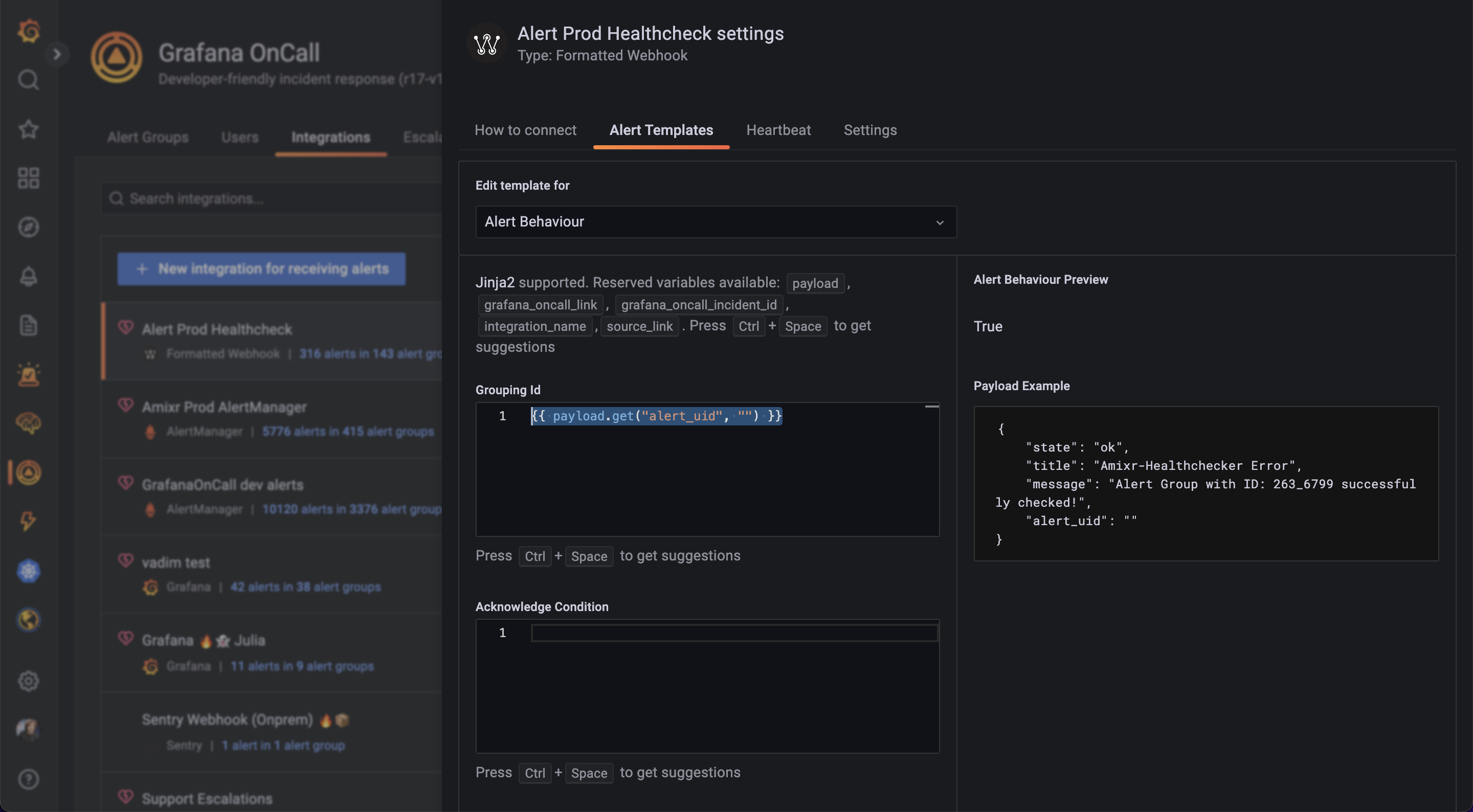
Все алерты, результат выполнения этого шаблона которых, будет одинаковым, будут сгруппированы. Например, можно группировать по всем лейблам: "{{ payload.labels }}", или по сервису: "{{ payload.labels['service'] }}", или по сервису и региону: "{{ payload.labels['service'] }}_{{ payload.labels['region'] }}".
Интегрироваться со Slack и Telegram
Интеграция с мессенджерами — это то, чем мы гордимся по-настоящему. Посмотрите на скрин:
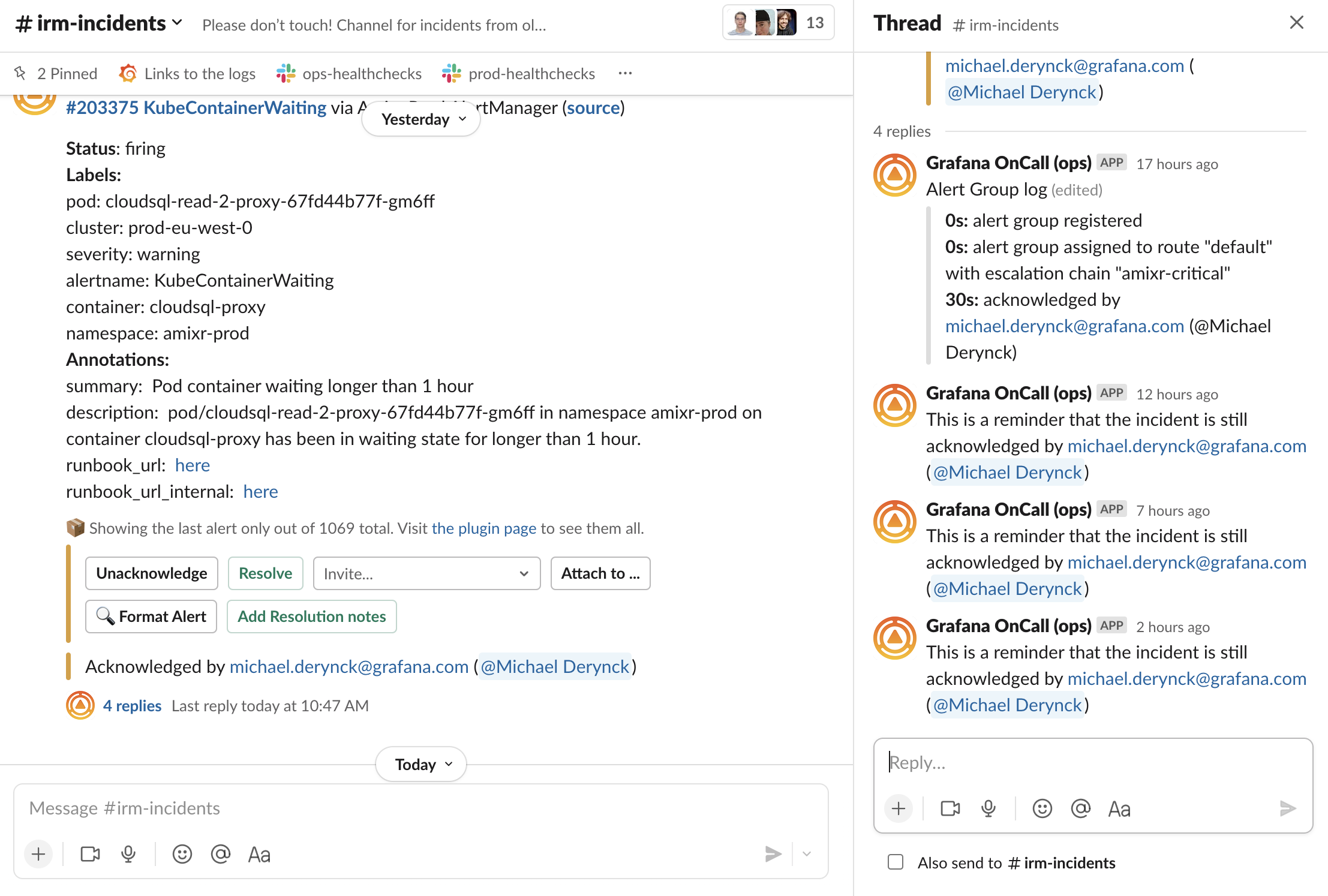
Здесь есть несколько классных деталей:
В общий канал ушло всего одно сообщение, 1069! алертов было сгруппировано. Мы спрятали весь этот "мусор".
OnCall аккуратно тегнул дежурного в тредике.
OnCall добавил в тредик лог эскалации (об этом дальше). Когда инцидент был открыт, в логе отображались будущие шаги.
OnCall регулярно проверяет, не забыл ли дежурный про инцидент, который от не закрыл, но пометил как Acknowledged. Если дежурный куда-то пропадет, OnCall заново переэскалирует инцидента.
Эскалировать
"Эскалатор" — сердце OnCall. Мало принять инцидент, нам нужно оповестить кого-то об этом инциденте, да еще так, чтобы быть уверенным в соблюдении SLA. В OnCall есть такой вот редактор эскалаций:

Можно эскалировать дежурному по расписанию (об этом дальше), можно создавать многоуровневую систему защиты, когда если один человек пропустил -> инцидент уходит другому, можно придерживать эскалации на ночь и так далее... Главное — это помогает точно удостовериться, что инцидент будет взят дежурным в работу и вы соблюдете SLA.
Назначать дежурных по расписанию
Одна из основных фич Grafana OnCall для распределенных команд. Например, в нашей команде расписание выглядит вот так:
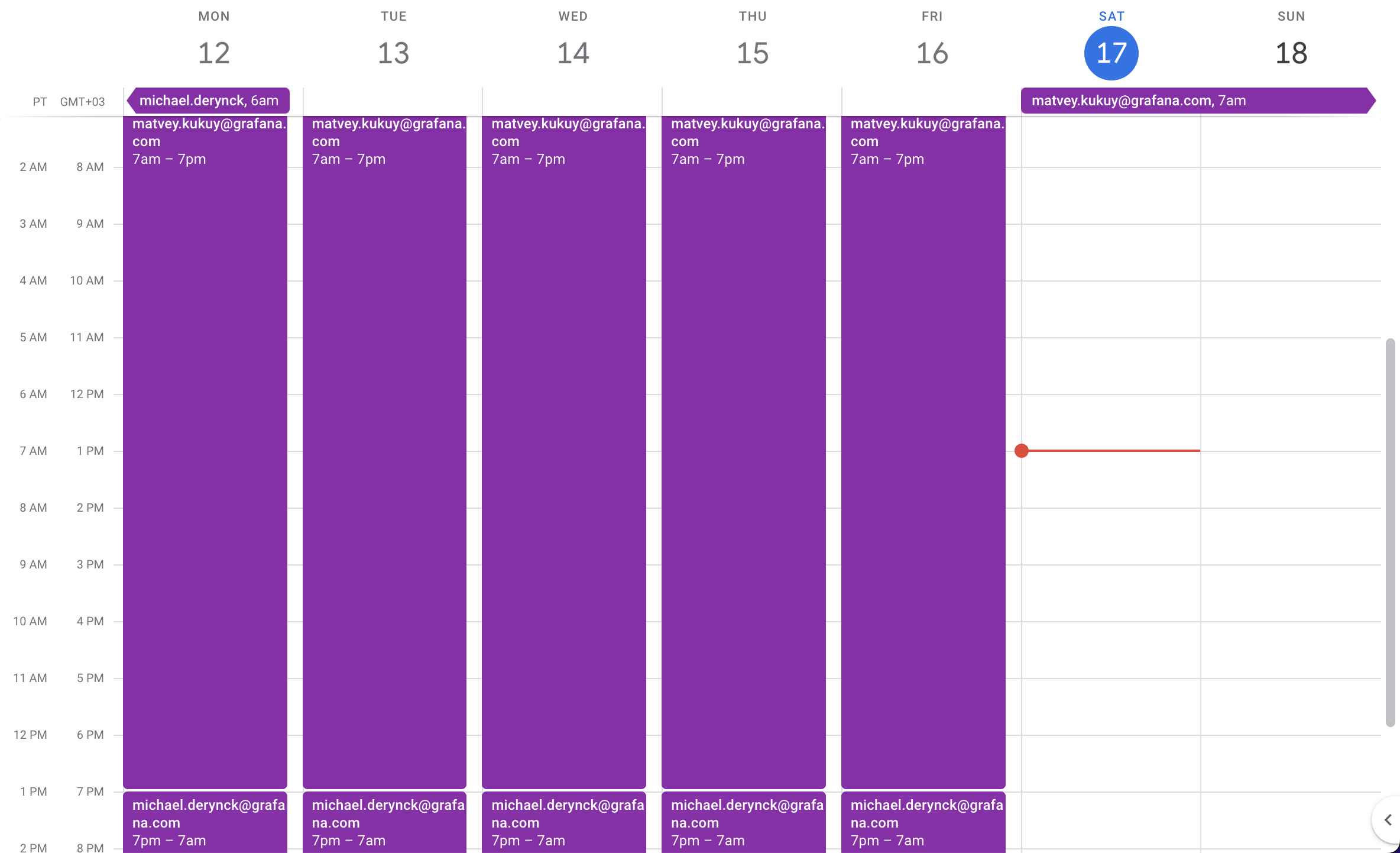
И да, мы редактируем расписание дежурств прямо в Google Calendar, а Grafana OnCall подтягивает обновления к себе и именно так узнаёт, кому отправить уведомление об инциденте.
Для вдумчивых, мы подготовили Terraform Provider, благодаря которому можно хранить расписание дежурств в Git и конфигурировать очень-очень-очень сложные ротации, а изменения принимать через Pull/Merge Request: https://grafana.com/blog/2022/08/29/get-started-with-grafana-oncall-and-terraform/
Что под капотом
Система оповещений — то, что должно, в первую очередь, доставить оповещение, а уже потом все остальное. Из-за этого, мы используем то, что называем: "скучный стек", что зарекомендовало себя годами и то, что мы очень хорошо знаем: Django, Celery, MySQL, RabbitMQ, Redis.
Когда мы аннонсировали Open Source на Hackernews, то получили ушат критики. Комментатором показалось, что OnCall требует слишком много зависимостей. Хоть он и упакован в Helm и Docker-compose, и в большинстве случаев запускается парой команд, всех напрягают "лишняя" база данных, очередь и кеш.
С одной стороны, они действительно лишние, если вы хотите запустить OnCall для "игр", с другой стороны под капотом у OnCall наш 3-летний опыт эксплуатации на несколько тысяч клиентов. За эти три года каждый недоставленный или задержанный инцидент был расследован и повлек за собой какое-то улучшение. Сейчас OnCall умеет и правильно частично деградировать, и корректно рейтлимитить, когда один из нескольких источников взбесился, и не падать, когда чудит API Slack, и мгновенно восстанавливаться. Думаю, все эти детали — хорошая тема для отдельной статьи.
Для тех случаев, когда стабильность не так важна, мы готовим миниатюрную версию.
Как поставить
Мы подготовили три основных окружения — окружение разработчика, прод. окружение (пока только helm для kubernetes) и окружение для "потыкать". Если вам не хватает окружения, пожалуйста, немедленно дайте нам об этом знать в Issues на GitHub.
Как поучаствовать
Grafana OnCall — Open Source проект и мы неверноятно радуемся каждый раз, когда получаем PR от коммьюнити. Если вы хотите добавить интеграцию с новой системой мониторинга, или новым мессенджером, или просто пофиксить что-то простенькое, добро пожаловать к нам в гитхаб: https://github.com/grafana/oncall
У нас есть русскоязычный чатик в телеграме, где сидят разработчики: https://t.me/amixr_ru
А еще у нас есть ежемесячные Zoom звонки, следующий будет 28-го сентября, там мы покажем секретную фичу, над которой работали почти 2 месяца ????, а еще соберем рабочую группу для работы над интеграцией с Mattermost, чтобы закрыть самый популярный Issue. Приходите на звонок, это отличный шанс влиться в Open Source разработку! : https://github.com/grafana/oncall/discussions/451
Комментарии (12)

celebrate
17.09.2022 14:22А можно этот софт поставить как замену алертменеджеру? То есть алерты брать напрямую из Прометеуса.

Matvey-Kuk Автор
17.09.2022 14:53Можно, но если у вас уже есть прометеус, лучше пред-группировку сделать в алертменеджере.

slava_k
17.09.2022 18:15Автоэскалация при отсутствии обязательной реакции (для выполнения временнЫх SLO) и определения обязательного типа реакции (нажал на кнопочку "вижу, ща займусь", письмо на электропочту, действие в других внешних системах) возможны?
Ну и совсем опционально - построение дерева/графа вообще всех событий и условий, для общего понимания всей системы реагирования на инциденты. По идее, это можно попробовать сделать как специфичный дашборд/-ы: общая картина и отдельные деревья/графы реакций, уведомлений по каждому актору (человеку/системе). Конечная цель - иметь карту всех описанных событий, реакций на них и исполнителей с требованиями на такую реакцию. Ещё более опционально - генерация метрик по таким реакциям (с привязкой/ссылкой к исходному событию), для того же prometheus. Из подобного уже можно будет пробовать вынимать KPI для команд, и не только.
Было бы здОрово иметь ту же ansible роль для установки, не все готовы сразу закидывать в кубкластер новый продукт для детальной оценки и тестов. Одного инстанса и роли вполне может хватить для этого.
Спасибо за развитие продукта.
numb
19.09.2022 09:10+1В ближайшем будущем планирую реализовать роль. Есть проект с алертами, но без кубера(

sergeykons
18.09.2022 22:20Хотим пощупать с самого момента выхода на гитхабе.
А можно допилить поддержку постгри для продукта? Иссуе №80Matvey-Kuk Автор
18.09.2022 22:21Было бы здорово, если бы вы присоединились к разработке) Postgres дотащим

pon007
18.09.2022 22:20Поправьте, если не прав, но что то до боли знакомое делал в zabbix пару лет назад. Кончно, без гугл таблиц для расписания, но с аггрегацией, эскалацией и подавлением алертов.

shrapneel
18.09.2022 22:20Интересно было бы послушать сравнение со стороны пользователей pagerduty (до которого тоже пока масштаб моей команды не дошел)
MechanicusJr
Чего?
так эскалировать и собирать группировку умеет наверное примерно все, от того же прома?
И все это в контейнере. то есть с сетью придется отдельно воевать.
приклад хороший, но сколько ж портов он требует пробросить?
Matvey-Kuk Автор
Graceful Degradation, Rate Limiting
Пром умеет группировать, но эскалировать не умеет. Grafana Alerting до версии 9 не умел группировать. А вообще систем мониторинга на рынке 370+, кто-то что-то умеет, а кто-то что-то не умеет.
В нескольких контейнерах*. Пока именно с сетью проблем ни у кого особенных не было, все достаточно легко менеджерится helm'ом.
MechanicusJr
я про дергадировать".
что то я не уверен, что helm и легко можно писать в одной фразе