
Один из важных вопросов как в нашей жизни, так и в бизнесе, и в IT — вопрос эффективности. Эффективно ли мы планируем наше время, те ли задачи решает бизнес, тот ли код мы оптимизируем? Чтобы ответить на эти вопросы, результат должен обладать главным критерием — измеримость. Измеримость результата новых фич для бизнеса и IT обеспечивает платформа А/B-тестов. О том, как её можно построить, выдерживать большой RPS и при этом не облажаться уронить прод, я расскажу в этой статье.
В конце статьи вы узнаете, как мы задетектили проблемы инфраструктуры, оптимизация которых значительно повлияла на скорость всего Ozon.

Без А/B, как измерить результат ХЗ
Приведём один из самых интересных и отчаянных примеров А/B-тестов, который может ответить на вопрос, интересующий как IT, так и бизнес:
— На фига мы упарываемся с оптимизацией времени ответа?
или
— Как скорость ответа влияет на деньги?
Чтобы ответить, мы можем сделать ухудшающий тест — деградацию скорости сайта (слабоумие и отвага) — и посмотреть, реально ли просядут денежные метрики.
Становится интереснее.
Давайте представим, что мы делаем фичу, в которой, к примеру, на 100 мс замедляем весь сайт, и хотим измерить, как это повлияет на наш GMV (оборот). Самый простой вариант: мы её просто выкатываем в прод и смотрим, как меняются метрики.
Ожидание
Как только мы включим нашу фичу, просядут бизнес-метрики:
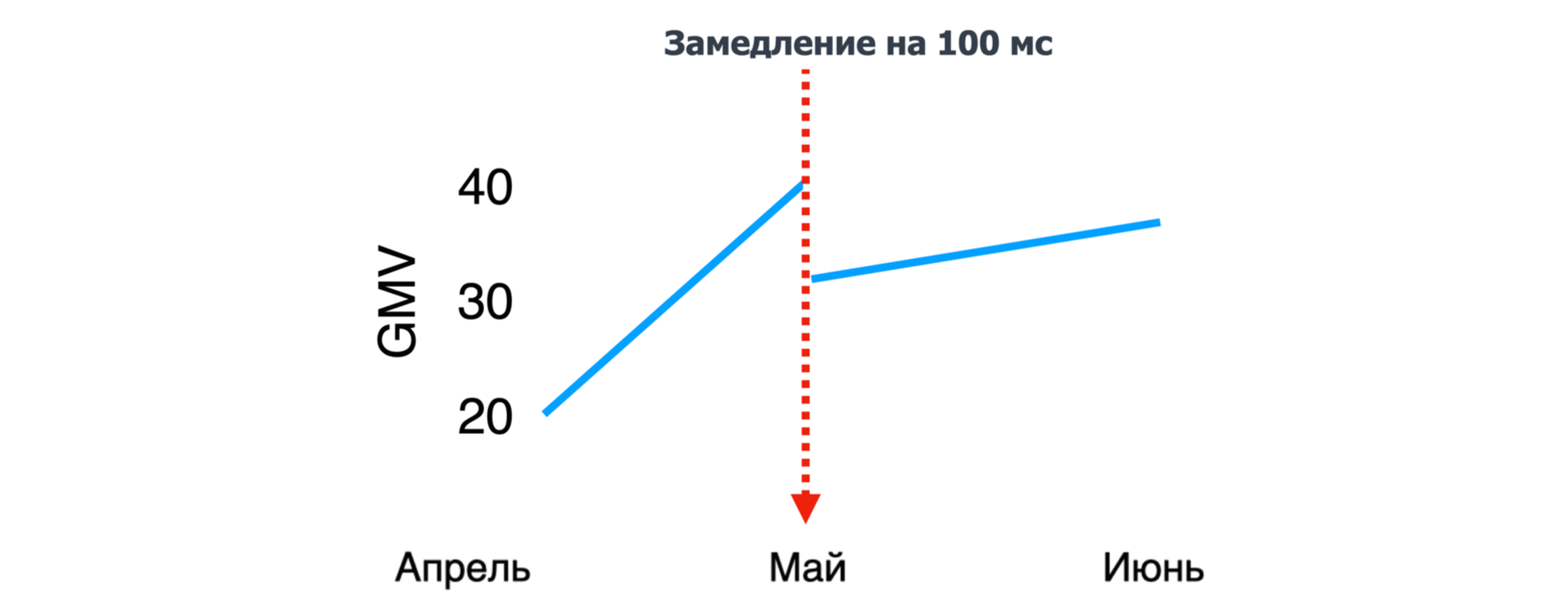
Реальность

Метрики пошли вверх!

Возможно, просто наступил высокий сезон, и выручка за счёт распродаж стала больше. Непонятно, повлияло ли на это наше замедление.
Что же делать? Как измерить? На помощь приходит команда А/B-тестов с девизом:

Можно запустить А/B-тест — эксперимент, в котором нужно разделить (сплитовать) пользователей на две группы. Первой группе включать замедление (тестовая группа / слабоумие и отвага), второй группе — не замедлять (контрольная группа).
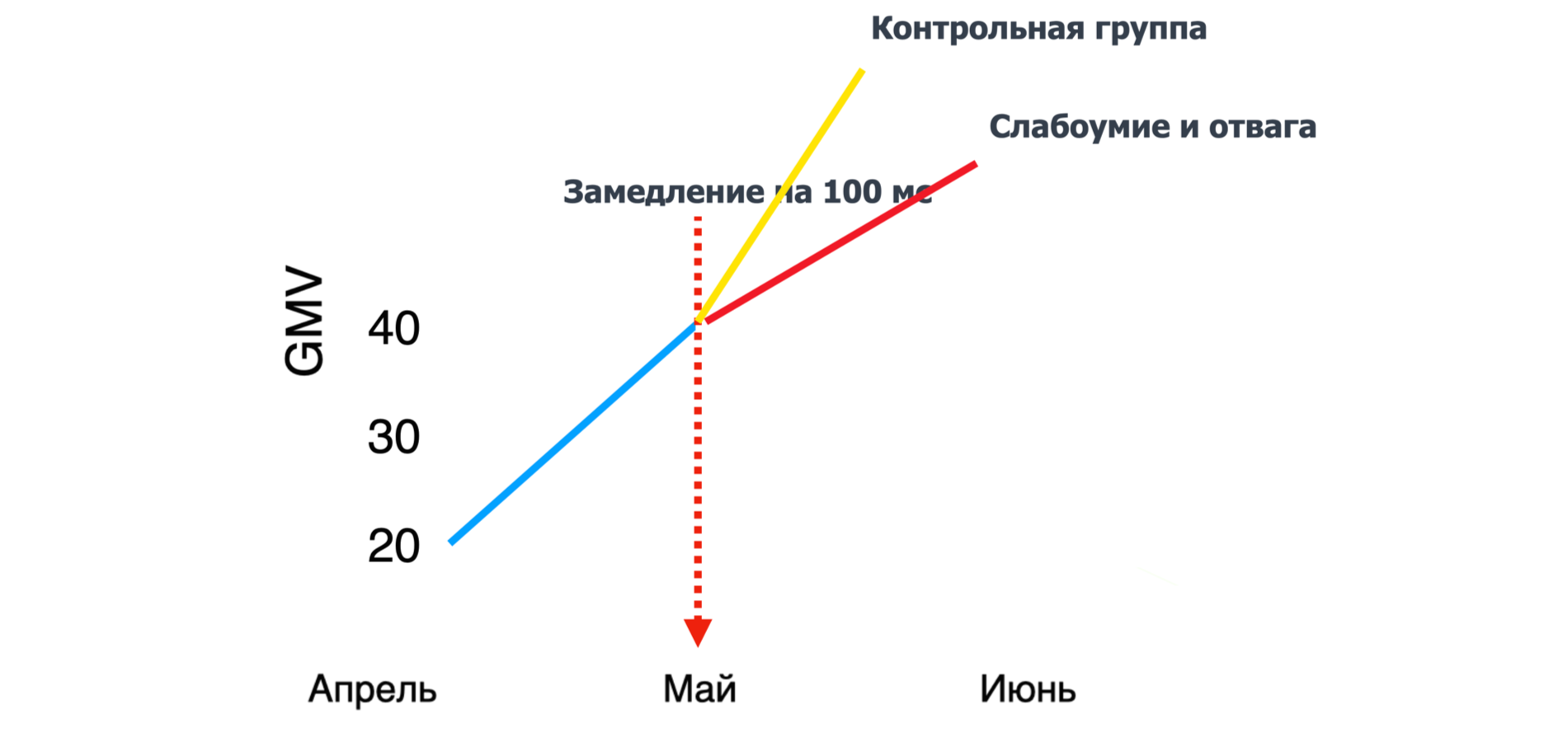
Не забываем также до запуска определить необходимые бизнес-метрики и рассчитать продолжительность эксперимента. По завершении эксперимента мы можем сравнить результаты в тестовой и контрольной группах и определить, были ли статистически значимые изменения или нет. Profit! ????
Эксперимент с замедлением скорости интересен тем, что, замедляя на определённое время наш сайт, мы ожидаем, что просядут бизнес-метрики, а в реальности этого может не происходить. И проводя ряд экспериментов с разным замедлением, мы можем определить точку эластичности скорости ответа — точку, начиная с которой замедление сайта влияет на деньги. Тем самым вы можете найти критическое значение задержки, после которого может начаться ваш личный Армагеддон (о нашем Армагеддоне расскажу ниже).
Также могут быть полезны А/B-тесты на увеличение производительности — чтобы измерить явное влияние оптимизации IT на бизнес-метрики.
Прочитать об экспериментах с деградацией скорости можно в главе 5 «Скорость имеет значение» книги «Доверительное А/В-тестирование» Кохави Р., Тан Д., Сюй Я.
В чем специфика А/B-тестов?
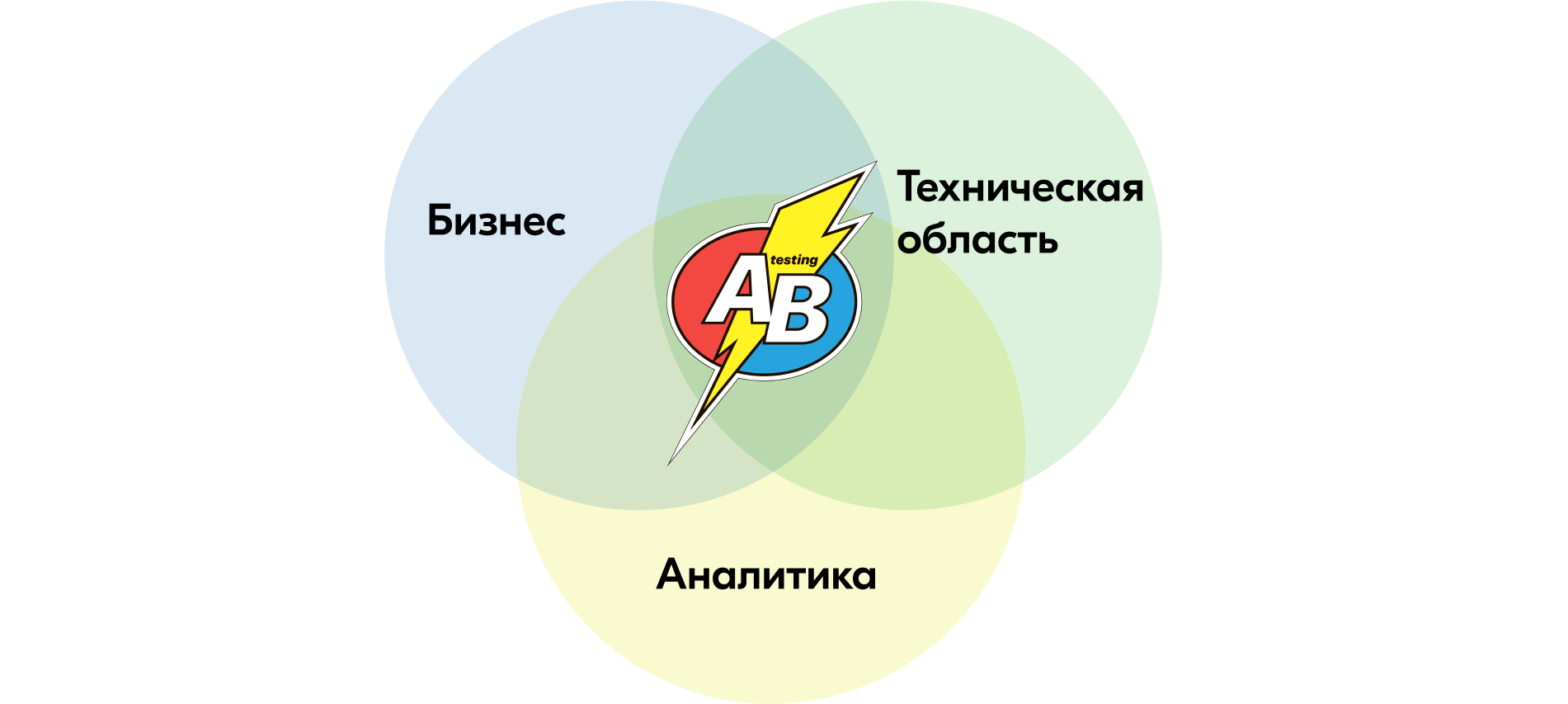
А/B-тесты находятся на пересечении трёх областей:
Бизнеса. Бизнесу важно иметь инструмент проверки своих гипотез и измерения эффективности новых фич.
Аналитики (статистики). Необходимо сформировать методологию проведения эксперимента, выбрать необходимый набор метрик, вычислить длительность эксперимента, определить критерии статистической значимости для каждой из метрик.
Технической области. Нужно обеспечить инфраструктуру для проведения А/B-тестов.
Техническую область можно разделить на две составляющие:
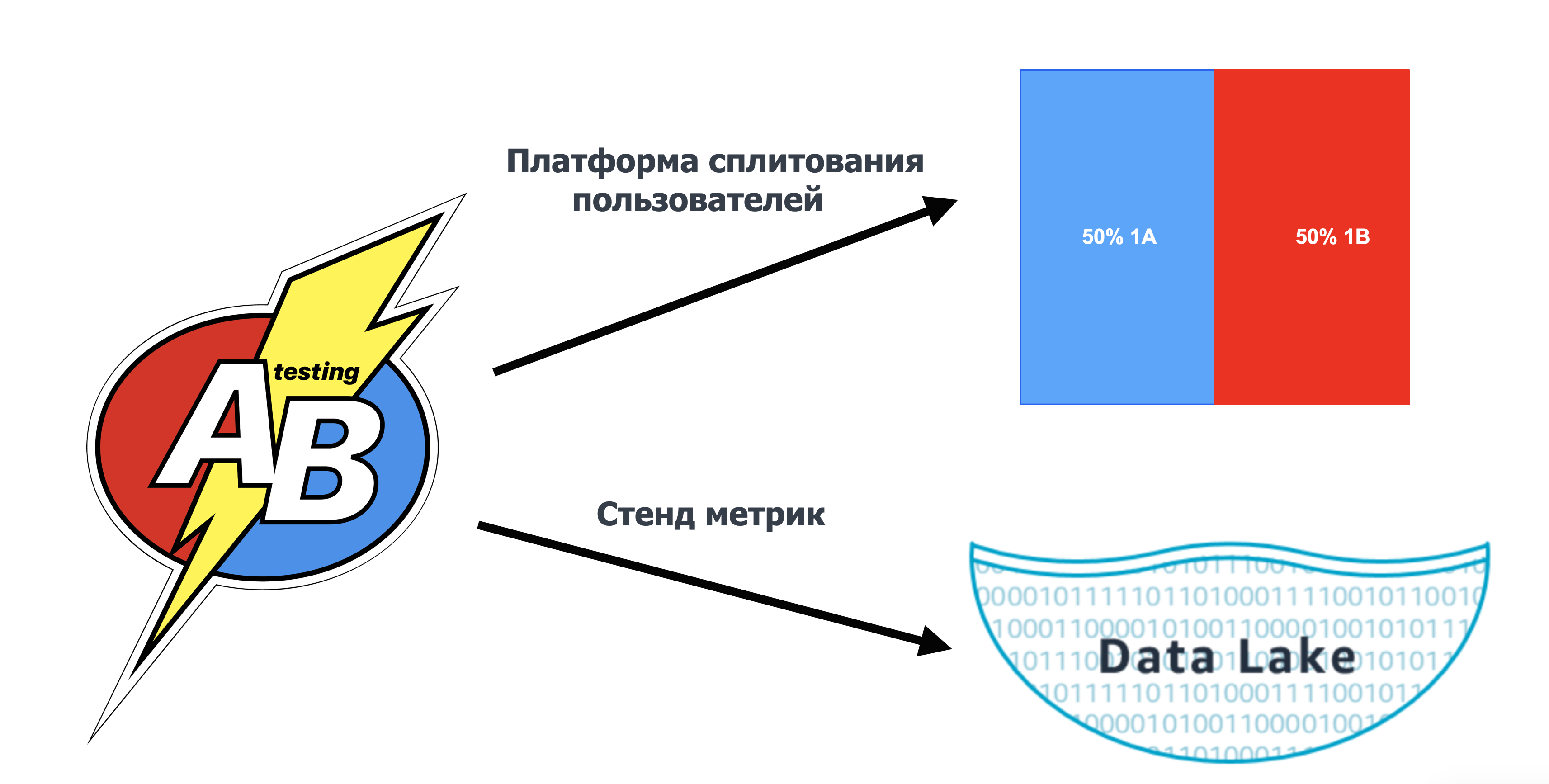
Платформа сплитования пользователей. Она предоставляет возможность в реалтайме делить пользователей на группы (тестовую и контрольную), определять, в какие эксперименты попал пользователь, возвращая включённые для него фичи. Система сплитования пользователей обеспечивает выдерживание большого RPS, инструменты интеграции с фронтенд- и бэкенд-микросервисами, отвечает за запуск и остановку экспериментов и выполняет другие функции.
Стенд метрик. Он обеспечивает расчёт метрик из разных источников данных, обрабатывая терабайты информации, вычисляет критерии статистической значимости и отдаёт результаты экспериментов.
В этой статье речь пойдёт о платформе сплитования пользователей. О стенде метрик, надеюсь, выйдет отдельная статья.
О платформе А/B-тестов в Ozon
Нашей платформе А/B-тестов четыре года. За это время она прошла несколько этапов взросления (рефакторинга). На основе нашего опыта я опишу возможные подходы к построению платформы А/B-тестов и наши инсайты в области решения проблем, с которыми мы сталкивались во время эксплуатации платформы.
Вы можете увидеть, как за время существования платформы кратно выросло количество экспериментов — и, соответственно, увеличилась нагрузка на бэкенд и инфраструктуру:

Первым клиентом платформы А/B-тестов в 2019 году стала наша команда, когда мы запускали сравнение рекомендательных алгоритмов. Помню, как ребята из Data Science думали, что сейчас будет суперпушка-алгоритм, запускали тест, а статистически значимых результатов часто не наблюдали. И это было хорошим стимулом для улучшения наших рекомендаций.
Если посмотреть на график выше, можно заметить, что в апреле этого года было запущено более 100 экспериментов. И их становится только больше. Это происходит не только благодаря высокой скорости ответа платформы А/B-тестов, удобной интеграции и т. д., но также вследствие того, что меняются процессы в компании. Но это уже совсем другая история...
Как построить платформу А/B-тестов?
Далее я расскажу о подходах, используя которые можно построить платформу А/B-тестов. Мы рассмотрим их минусы и поймём, как прийти к «идеальной» архитектуре А/B-тестов.
Для этого обратимся к истории.

C чего всё начиналось?
А начиналось всё, как водится, с Exсel-ки. В ней была информация обо всех запущенных экспериментах для руководителя команды аналитики. Как известно, действительность может отличаться от ожиданий, а конфиг бэкенда с реально запущенными экспериментами — от прекрасной Exсel-ки.

Некоторые продукт оунеры могли проводить эксперименты, о которых не знал глава команды аналитики. Эти «подпольные» эксперименты могли оказывать влияние на бизнес-метрики других экспериментов — и об этом не знал никто.
Прикол в том, что файл с конфигом экспериментов был не один, а их было два. Был ещё один для мобильных приложений — и синхронизировать эти Excel-ки для аналитики экспериментов Ozon было больно.
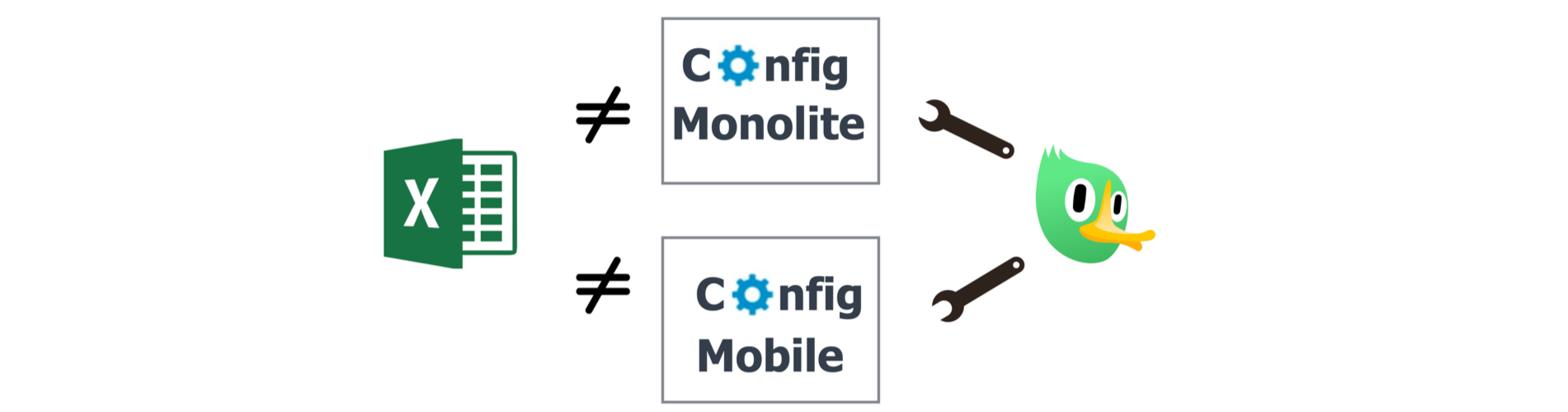
Также из основных проблем можно выделить то, что не было единого стандарта учета экспериментов (описания их целей, метрик и т. д.), их реалтайм-запуска и остановки, истории запусков и возможности запуска мультисервисных экспериментов.
Для того чтобы определиться, как решить эти проблемы и построить А/B-платформу мечты, давайте рассмотрим возможные варианты её архитектуры.
OldSchool монолит
Самый простой способ построения платформы А/B-тестов, который исторически был в Ozon, как и во всех компаниях того времени — это архитектура из 90-х и это конечно же монолит.
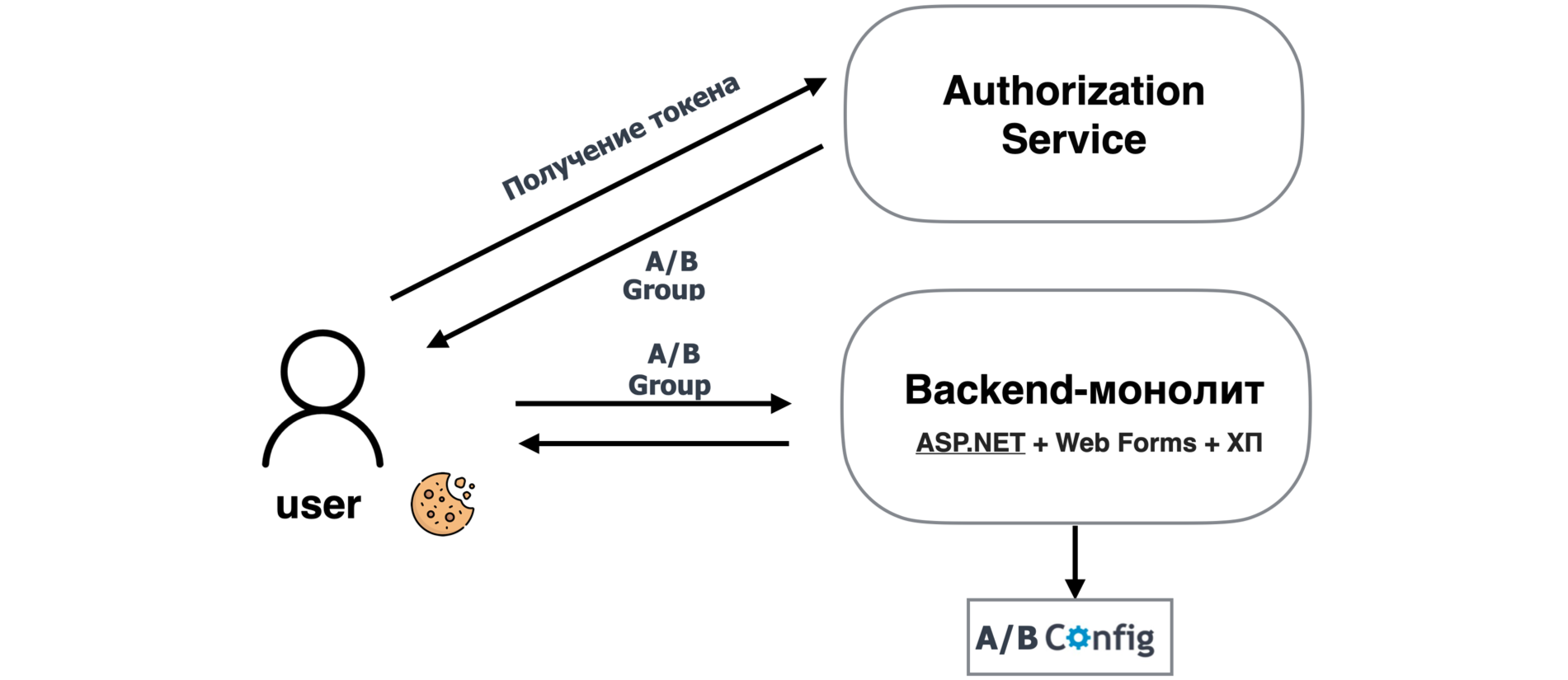
Пользователь при запросе токена авторизации автоматически получает А/B-группу как рандом с равномерным распределением от 0 до 99.
abGroup = random % 100
Грубо говоря, пользователю присваивается процент распределения, в который он попал при авторизации. Далее этот процент сохраняется в куках и передаётся с фронта в каждом запросе.
Бэкенд-монолит при старте читает конфиг с указанием набора фич и указанием, для какого процента пользователей (набора А/B-групп) включается каждая фича.
Получая А/B-группу из кук, бэкенд определяет, какой набор фич включён для данного пользователя. На примере конфига ниже: если нам при авторизации выдали 40-ю А/B-группу, то нам вернулся следующий набор фич: abGroupNewCheckout (так как ей соответствует набор А/B-групп с 35-й по 65-ю) и DeliveryVariant_1 (так как ей соответствует набор А/B-групп в интервале с 40-й до 54-й).
Пример конфига:
<?xml version="1.0" encoding="UTF-8"?>
<config>
<!-- A/B-группы для нового чекаута -->
<add key="abGroupNewCheckout" value=” 35-65" />
<!-- A/B-группы для тарифной подсказки на странице выбора способа доставки-->
<add key="DeliveryVariant_1" value="40-54" />
<add key="DeliveryVariant_2" value="55-69" />
<add key="DeliveryVariant_3" value="15-19,70-79" />
<add key="DeliveryVariant_4" value="0-14" />
<!-- A/B-группы для пропуска страницы region для пользователей, у которых нет сохранённых адресов -->
<add key="AbGroupSkipRegionPageForNewUsers" value="0-40,60-100,500" />
</config>Боль: очень неудобно деплоить огромный монолит, чтобы включить или выключить небольшую фичу.
Давайте теперь представим, что мы перенеслись из 90-х — и у нас уже не монолит, а современная мультисервисная архитектура.
Молодёжная мультисервисная архитектура
Рассмотрим её на примере отображения карточки товара:
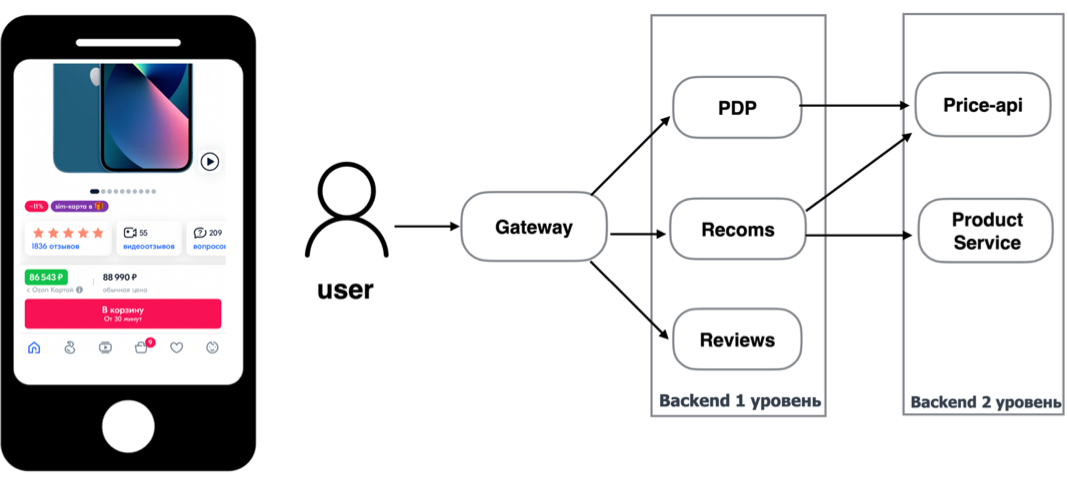
Запросы пользователей сначала идут на шлюз Ozon. Далее на шлюзе определяется, на какой бэкенд нужно пойти, чтобы отрисовать страницу. В нашем примере шлюз идёт в сервисы: PDP (product detail page), рекомендательный и отзывы. Мы этот бэкенд называем бэкендом первого уровня по удалённости от gateway.
Далее для того чтобы получить дополнительную информацию, бэкенд первого уровня идёт в бэкенд второго уровня. В нашем примере сервис Recoms (сервис первого уровня) запрашивает цены рекомендуемых товаров у price-api (сервис второго уровня) и описание товаров — у product service (сервис второго уровня).
Наложим паттерн с локальным конфигом и А/B-группой из 90-х на молодёжную мультисервисную архитектуру — и получим следующее решение:
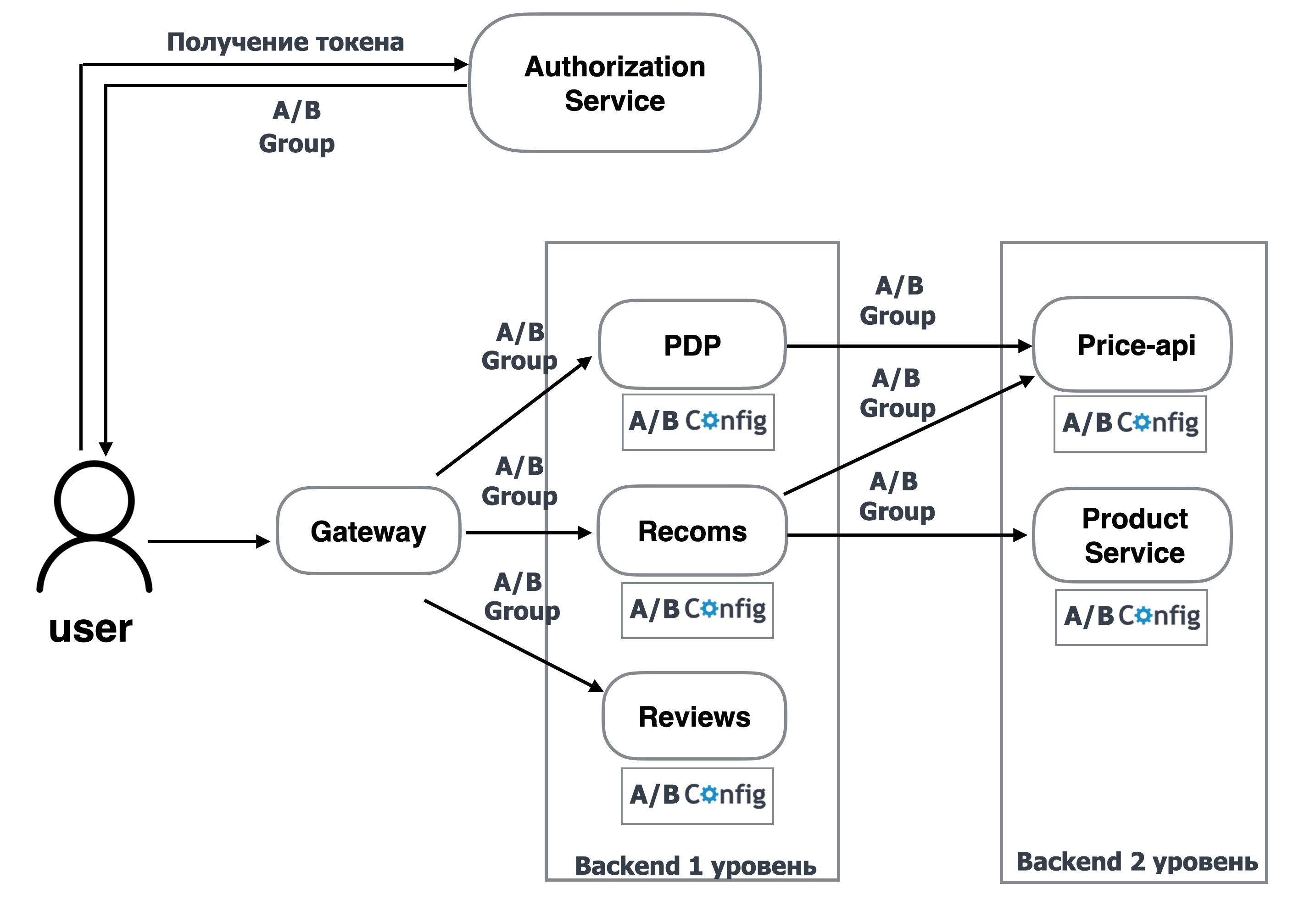
Бэкенд первого и второго уровней при старте загружают конфиг с настройкой экспериментов по А/B-группам.
При обращении пользователя к сайту в момент авторизации он получает А/B-группу. Фронтенд передаёт её в gateway, gateway, проксируя запросы, передаёт А/B-группу в бэкенд первого уровня. Бэкенд первого уровня по А/B-группе определяет набор включённых фич, передаёт А/B-группу в бэкенд второго уровня, который по ней тоже определяет набор включённых фич.
Минусы этого подхода:
нет истории экспериментов;
нет возможности планировать эксперименты;
информация об экспериментах разрознена;
нет возможности остановки/запуска экспериментов в реалтайме: остановка/запуск производится только через деплой, так как для этих операций нужно менять конфиг и рестартить сервисы;
пользователи могут неравномерно распределяться между экспериментами, так как одна и та же А/B-группа используется для разных экспериментов;
нет возможности задавать условия попадания пользователей в эксперименты.
Один из ключевых минусов — отсутствие возможности запуска/остановки эксперимента в реалтайме.
EventDream
Для того чтобы решить проблему с реалтаймом, мы можем сделать сервис ab-test-api, который будет оповещать сервисы о запуске экспериментов и их остановке.
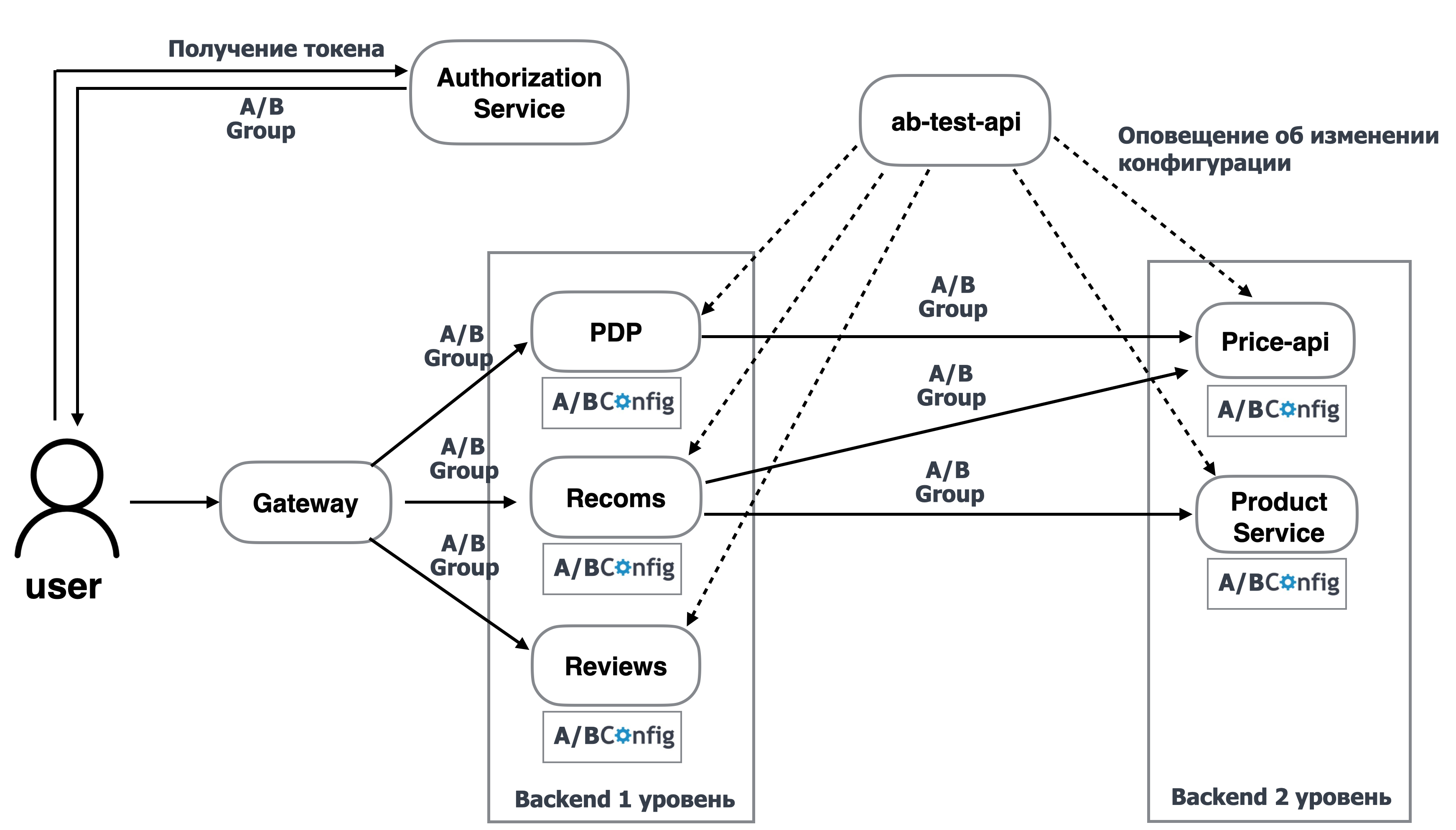
Логика такая же, как в подходе выше, только информация об экспериментах может легко обновляться и всегда актуальная.
Однако остались другие минусы:
нет истории экспериментов;
нет возможности планировать эксперименты;
информация об экспериментах разрознена;
пользователи могут неравномерно распределяться между экспериментами, так как одна и та же А/B-группа используется для разных экспериментов;
нет возможности задавать условия попадания пользователей в эксперименты.
Нас это не очень устраивает, поэтому попробуем другой подход, который решит сразу три проблемы. И этот подход конечно же...
Single Responsibility
В этом подходе мы будем использовать архитектуру, в которой центральным сервисом будет ab-test-api.
Функции этого сервиса:
хранить информацию обо всех экспериментах с историей для всех сервисов;
отдавать для каждого сервиса набор включённых фич.
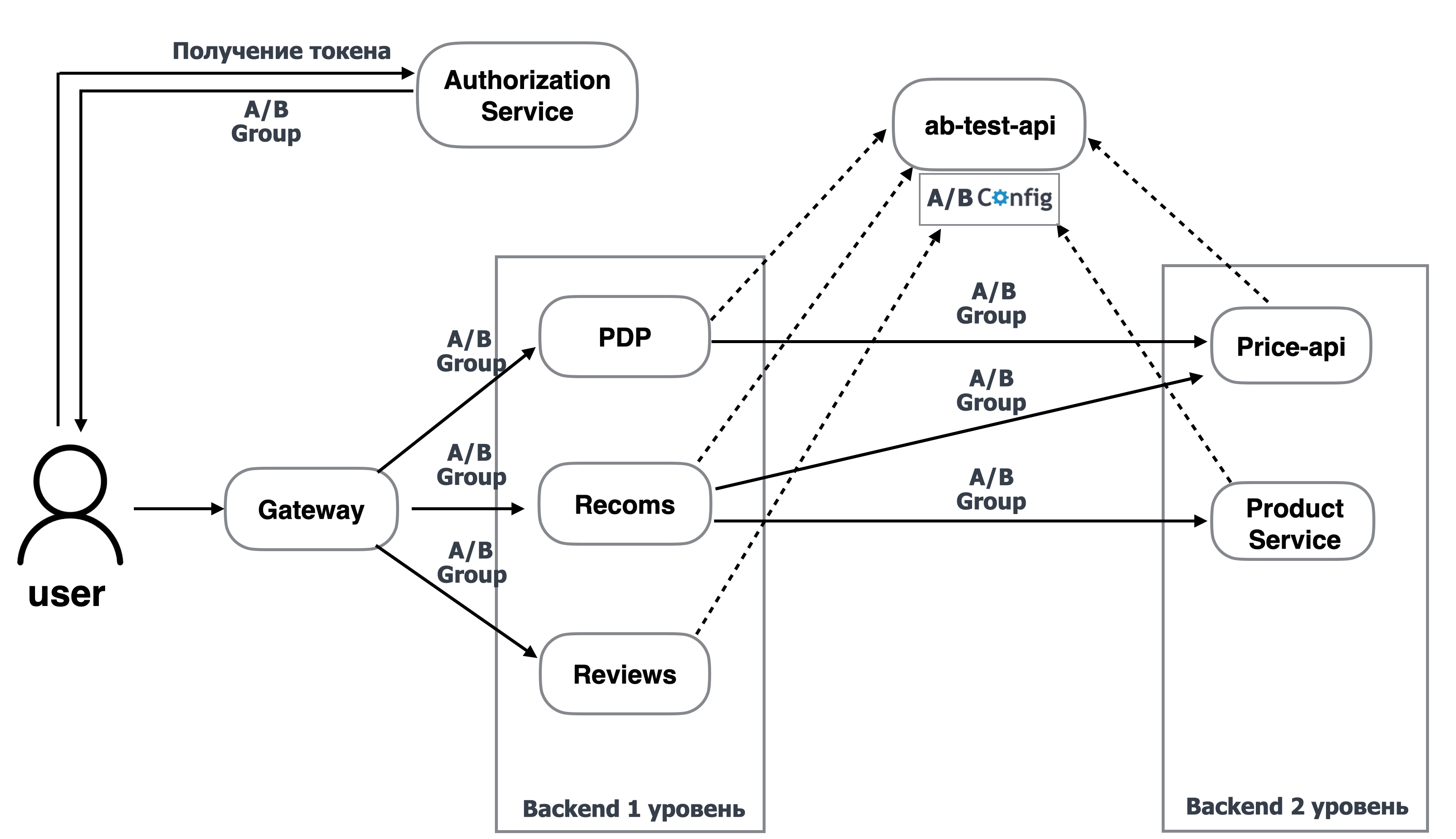
Общая логика с А/B-группой остаётся неизменной, только теперь бэкенд для получения данных о наборе включённых фич будет идти в сервис ab-test-api, передавая в него A/B-группу.
Таким образом, в каждом из сервисов самостоятельно не нужно определять, какая фича включена для какой А/B-группы, и хранить свой локальный конфиг.
Минусы этого подхода:
высокий RPS, так как каждый сервис идёт за экспериментами;
пользователи могут неравномерно распределяться между экспериментами, так как одна и та же А/B-группа используется для разных экспериментов;
нет возможности задавать условия попадания пользователей в эксперименты.
Архитектура стала намного лучше, правда появилась проблема с высоким RPS: как говорится, за всё нужно платить.
Давайте рассмотрим, как мы можем решить важнейшую проблему для аналитики — неравномерное распределение пользователей между экспериментами.
Динамически определяемая А/B-группа, или Свой шейкер в каждом эксперименте
Для того чтобы убрать зависимость попадания пользователя в эксперименты от глобальной А/B-группы, вследствие чего может возникать неравномерное распределение пользователей между экспериментами. Мы будем вычислять в каждом эксперименте свою А/B-группу.
Для этого убираем поход в сервис авторизации (лишняя зависимость уходит — ура!) — и вместо А/B-группы будем передавать идентификатор пользователя.
Теперь в сервисе ab-test-api в каждом эксперименте мы можем определять динамически А/B-группу для пользователя. Вычислять её как хеш-функцию от идентификатора пользователя, подмешивая salt:
ABGroup = hash(userID + salt) %100
Это позволяет также делать в A/B-тестах слои и равномерно размазывать пользователей между всеми экспериментами.

Какие остались минусы:
высокий RPS, так как каждый сервис идёт за экспериментами;
нет возможности задавать условия попадания пользователей в эксперименты.
Вместо тысячи ̶с̶л̶о̶в̶ каскадных запросов → gateway
Для того чтобы решить проблему каскадного увеличения RPS, мы будем запрашивать данные для всех сервисов в gateway и передавать их во все бэкенды.
Всё красиво. Правда, тут мы сталкиваемся с новой проблемой: а как именно нам передавать информацию обо всех экспериментах в бэкенд первого и второго уровней? Мы можем передавать её явно, но для этого нужно будет менять контракты всех хендлеров, что довольно проблематично и неудобно. К нам на помощь приходит смекалочка и идея для этого использовать header. В результате мы один раз пишем информацию об экспериментах в header-запросах gateway — и дальше она автоматически проксируется во все запросы бэкенда.
Для того чтобы реализовать фильтрацию пользователей в экспериментах, мы просто в gateway делаем дополнительный запрос к сервису user_profile. Данный сервис отвечает за информацию о пользователе и отдает нам её. Далее gateway передаёт информацию о пользователе в сервис ab-test-api и запрашивает данные об экспериментах. ab-test-api находит эксперименты, удовлетворяющие данным пользователя, и только для них отдаёт набор включённых фич.
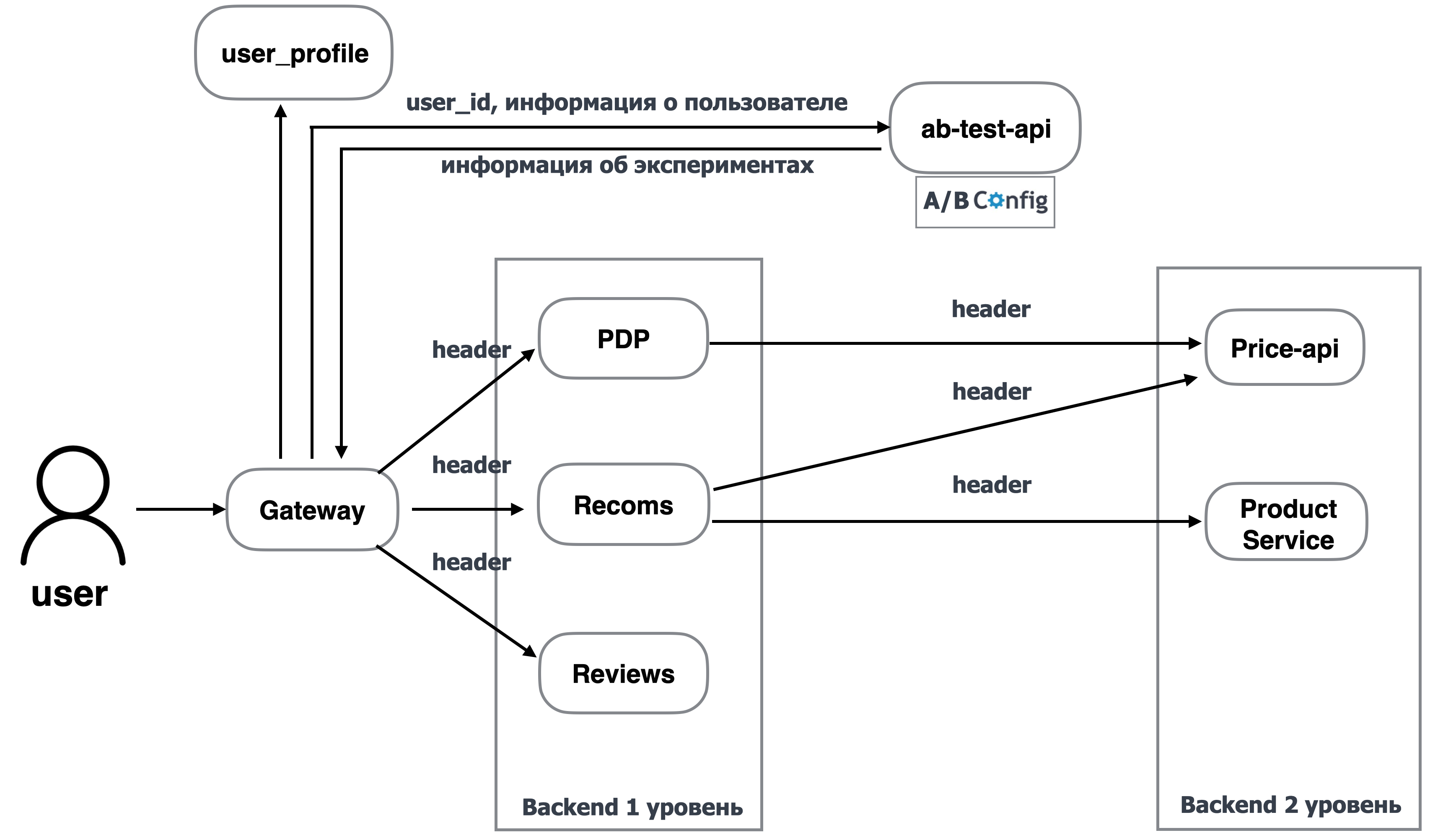
Минус:
всё ещё остаётся высокий RPS, так как каждый запрос gateway идёт в платформу A/B-тестов.
Как мы справляемся с высоким RPS?
Для ответа на этот вопрос давайте разберёмся, как происходит добавление эксперимента в платформу A/B-тестов.
При добавлении эксперимента в платформу A/B-тестов через веб-интерфейс запрос идёт в A/B-контроллер — сервис, отвечающий за справочник всех экспериментов. Он сохраняет данные о новом эксперименте в базу данных и добавляет их в etcd (key-value storage). На изменения в etcd подписан сервис ab-test-api, который отвечает за быстрый ответ на запросы бэкенда.
Поскольку данный сервис подписан на все изменения, касающиеся экспериментов, он сохраняет информацию в локальный кэш. В локальном кэше оказывается информация обо всех экспериментах, текущих и будущих, по которым можно быстро отдать информацию о попадании в них пользователей.

Благодаря тому, что у сервиса ab-test-api всё находится в оперативке и он подписан на все изменения, касающиеся экспериментов, мы его можем легко горизонтально масштабировать и выдерживать любой RPS.
Минусы:
их нет ????
О чём мы забыли в архитектуре?
О том, без чего А/B-тесты лишены смысла, — об аналитике.
Отправка данных в аналитику
Для анализа данных эксперимента необходимо, чтобы информация о том, в какие эксперименты попал пользователь, была в Data Lake.
Мы это обеспечили следующим образом. Когда gateway получает ответ от бэкенда, он всю собранную информацию передаёт в мобильное приложение / фронтенд. Мобильное приложение / фронтенд отображает ответ бэкенда и, реагируя на действия пользователя, накапливает батч ивентов. В нужный момент времени они отправляют их в трекер аналитики. Он обогащает все ивенты информацией об экспериментах: для этого он передаёт информацию о пользователе в сервис ab-test-api, получает ответ и уже обогащённые ивенты отправляет в Data Lake.
Теперь любой аналитик может пойти в Data Lake и выцепить все интересующие его ивенты для каждого эксперимента. Profit! ????
Прекрасная архитектура, мы выдерживаем любой RPS. Внимание, вопрос:

А дальше был...

У нас умер стейдж, и мы долго не могли понять, что произошло. Оказалось, что всё-таки у нашей архитектуры была проблема. И проблемой этой был header, в который мы не стеснялись писать данные и передавали информацию обо всех экспериментах, которые проходили в Ozon. И когда его размер превысил 4 Кбайт, мы превысили ограничение Nginx — и на каждый запрос возвращалась ошибка.
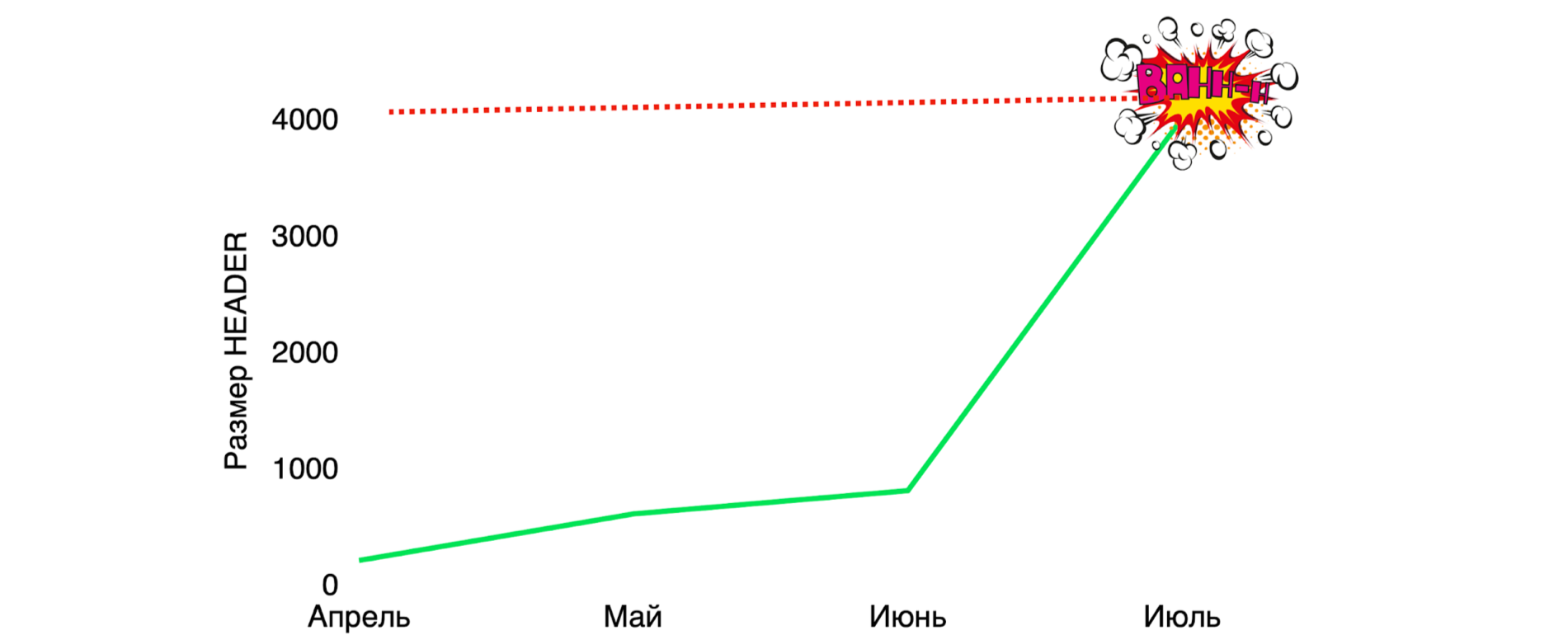
Чтобы понять, в чём была проблема, рассмотрим два сервиса, в которых проходят эксперименты:
сервис поиска c параметром
rankingAlgorithm string,сервис корзины с параметром
IsNewCart string.
Если для этих сервисов представить JSON, который мы передавали в header, то он будет примерно следующего вида:
{
"search": {
"config": {
"rankingAlgo": "newAlgo"
},
"experiments": [{"ID":1,"variantID":2}]
},
"cart": {
"config": {
"isNewCart": true
},
"experiments": [{"ID":2,"variantID":4}]
} И если экспериментов становится много, то этот JSON может набирать килобайтные размеры.
Для уменьшения гигантского размера JSON мы придумали следующий FastFix.
FastFix
Идея: вместо этого прекрасного JSON в header будем передавать компактный UUID.

Для этого ab-test-api при получении запроса от gateway вычисляет JSON, генерит UUID и далее этот JSON по ключу UUID сохраняет в Memcached. Теперь по этому ключу бэкенд может получить данные.
Поэтому сервис ab-test-api вместе с конфигом бэкенда возвращает UUID в gateway и далее gateway передаёт в header UUID всем сервисам бэкенда. Когда бэкенд-сервису необходимо узнать, какие фичи включены для пользователя, он идёт в ab-test-api, передавая туда UUID. ab-test-api в свою очередь идёт по этому ключу в Memcached, получает JSON и из него отдаёт набор включённых фичей для сервиса.
Также для сервисов первого уровня можно передавать из gateway явным образом набор включённых фич в body, чтобы убрать лишнее обращение к ab-test-api.
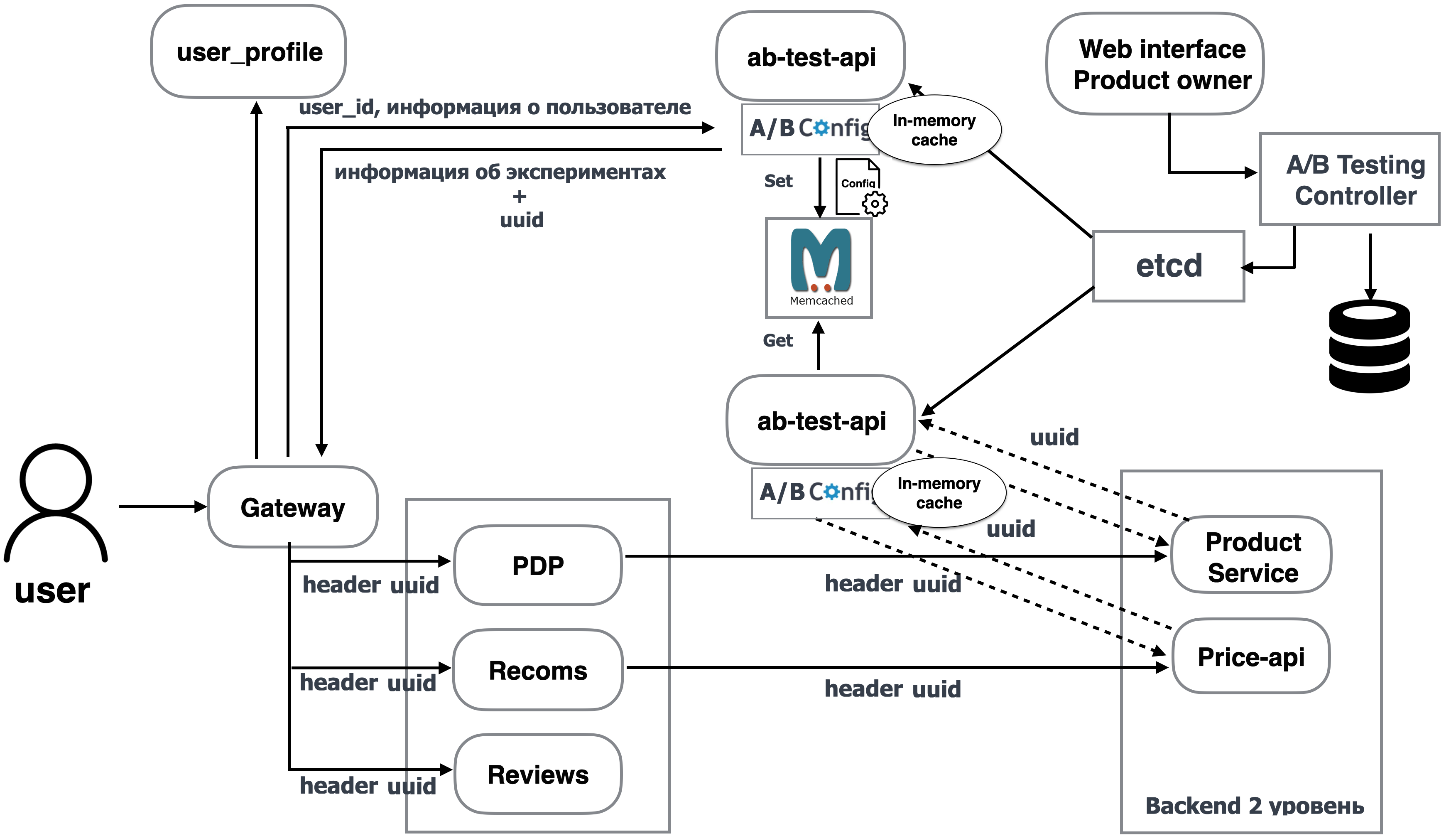
Так мы решили проблему большого header — теперь его размер всегда фиксирован.
Кажется, можно было на этом остановиться, но у данного подхода есть минусы:
дополнительный RPS сервисов второго уровня;
дополнительная зависимость архитектуры от Memcached, который на стресс-тестах нужно масштабировать.
Поскольку мы упоротые инженеры и боремся за миллисекунды, то придумали, как избавиться от этих двух минусов и сделать идеальную архитектуру ????
Идеальная архитектура
Как сказал Жак Пеше,

Поэтому план такой:
чтобы избавиться от Memcached, нужно передавать данные об экспериментах в header, как в старые добрые времена;
чтобы решить проблему RPS сервисов второго уровня, нужно сделать на клиенте кэш;
чтобы не наступил Армагеддон с размером header, нужно придумать минимальный формат сжатия данных об экспериментах.
Инструмент, который решает всё эти проблемы — бинарный протокол передачи информации об экспериментах, в которые попал пользователь.

Цель бинарного протокола — в как можно более сжатом виде представить информацию об экспериментах, в которые попал пользователь.
Реализация данного протокола даёт возможность использовать его как уникальный идентификатор включённых для пользователя экспериментов, то есть в качестве ключа кэша для клиентов бэкенда. Это позволяет нам реализовать кэш для клиентов бэкенда второго уровня, чтобы значительно уменьшить RPS.
Мы придумали следующий формат бинарного протокола:
первые 10 бит используются для передачи идентификатора сервиса (мы отталкиваемся от того, что максимальное количество сервисов — 2^10);
4 бита номер ревизии, когда добавляются новые эксперименты/удаляются меняется номер ревизии. Таким образом мы решили одну из главных проблем в IT — проблему инвалидации кэша;
n бит для передачи битовой маски вариантов экспериментов, в которые попал пользователь.
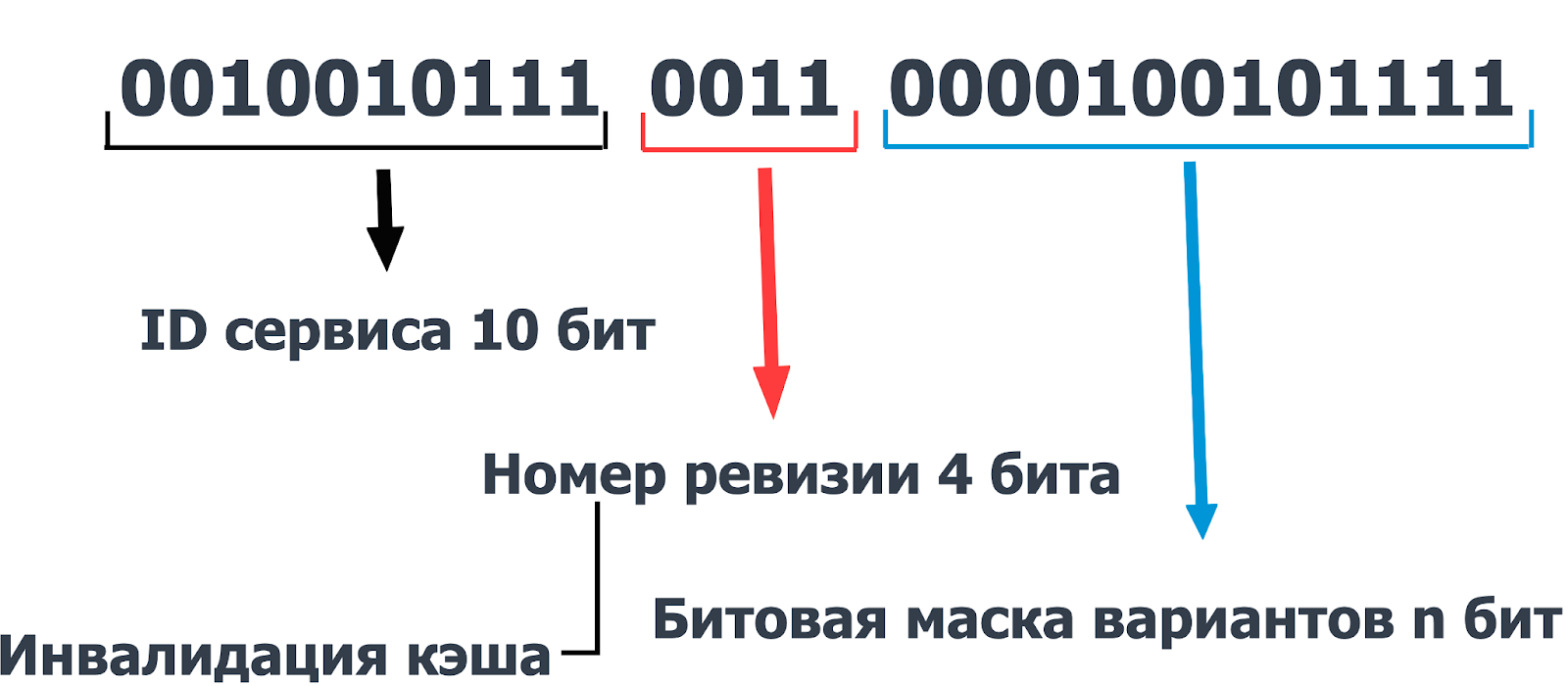
Таким образом, JSON из нашего примера конвертируется в этот красивый формат:

Получается прекрасная архитектура, в которой ab-test-api при получении запроса от gateway вычисляет для каждого пользователя значение нашего бинарного ключа (binary key) как набор уникальных экспериментов, в которые попал пользователь. Теперь по этому ключу бэкенд может взять данные из кэша или запросить их для прогрева.
Поэтому мы проксируем binary key вместо UUID из gateway во все сервисы бэкенда в header. Когда бэкенд-сервису необходимо узнать, какие фичи включены для пользователя, он смотрит, есть ли данные по бинарному ключу в кэше? Если есть, сразу берёт их, если нет — идёт в ab-test-api с binary key, получает набор включённых для пользователя фич и сохраняет их в кэш. Таким образом, если с таким же бинарным ключом придёт ещё один запрос, результат возьмём из кэша.
Также для сервисов первого уровня мы передаём из gateway явным образом набор включённых фич в body для каждого сервиса.
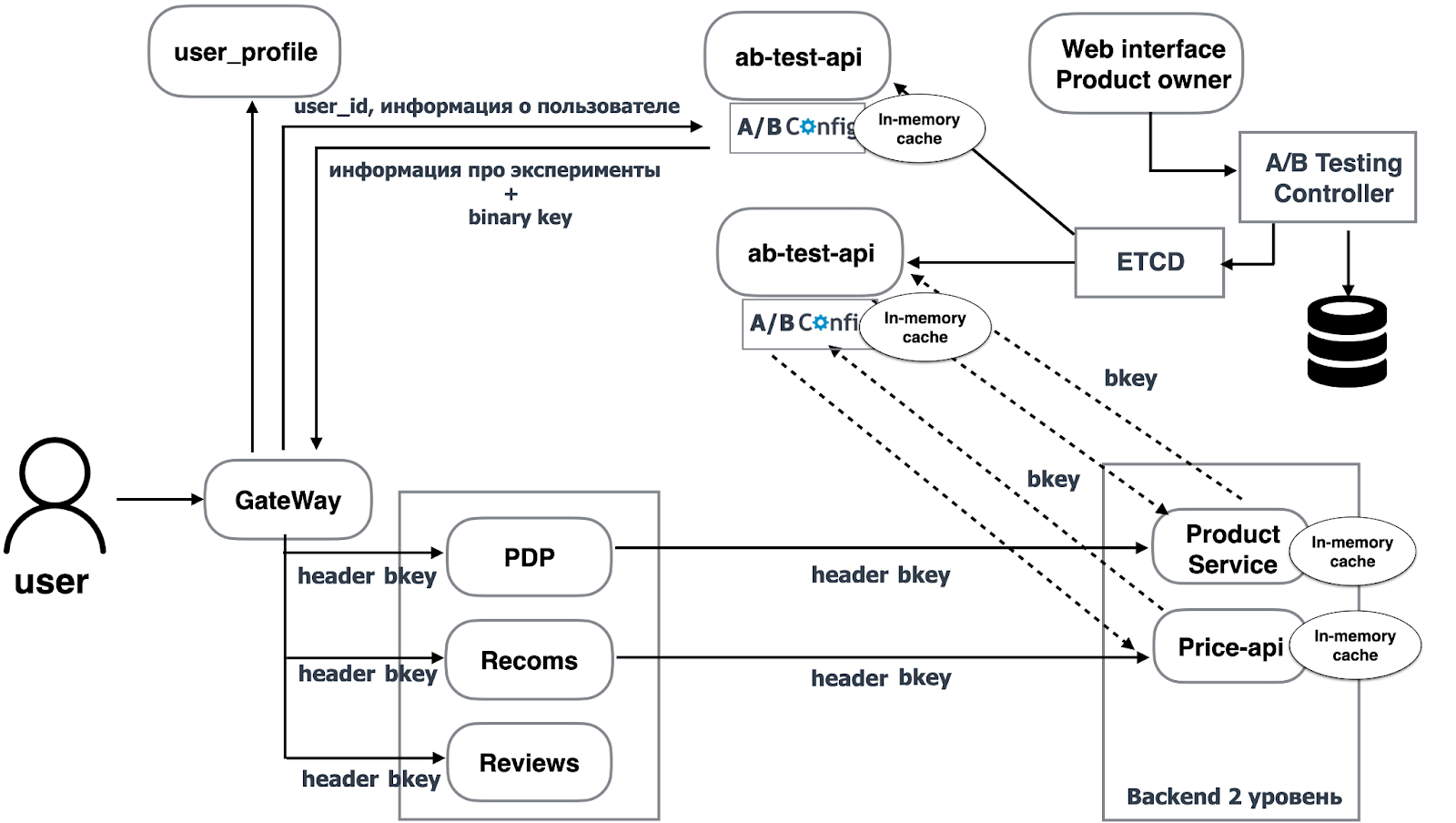
В результате мы убрали лишнюю зависимость от Memcached — и можете увидеть на сколько упал RPS для сервисов второго уровня:


А/B на острие атаки RPS
Благодаря простоте, масштабируемости и красоте платформы А/B-тестов наша команда часто находила проблемы инфраструктуры и стояла у истоков больших открытий Ozon.
За время моей работы в компании были запущены революционные фичи, которые оказали большое влияние на оптимизацию скорости ответа всего бэкенда. И без стеснения могу сказать, что часто всё начиналось с нашей платформы А/B-тестов.
В начале было словоВ начале был А/B-тест
Проблема клиентской балансировки
Вводная информация:
время ответа ab-test-api по 99 квантили < 1 мс;
однако мы отваливались по тайм-ауту от gateway, который шёл со временем ожидания 10 мс. Таких запросов было

4% ошибок А/B-тестов, прыгающих фич и проблем в аналитике — это беда.
Когда ты приходишь к команде инфраструктуры и говоришь, что вроде проблема в инфраструктуре, тебе всегда уверенно отвечают:
«Ваш код —
????не очень, оптимизируйте».
Если ты отвечаешь, что архитектурочка — огонь, тебе отвечают: «См. п. 1».
Пришлось засучить рукава и доказывать, что проблема не на нашей стороне. Для этого было решено сделать два сервиса:
ab-poligonc методомPing, который не делает ровным счётом ничего, кроме того что сразу возвращает ответ, чтобы невозможно было придраться к неоптимальному коду;ab-shooter, чтобы стрелять по нашему сервису полигона с нужным RPS и измерять нужным образом скорость ответа (заданными бакетами в Prometheus).
Далее мы делали ряд стрельб из shooter и заметили, что сервис, который не делает ровным счётом ничего при 1k RPS, отвечает в 4% запросах дольше 10 мс при любом количестве подов, так же, как и мы.
Proof! ???? То есть мы доказали, что ни один сервис не может отвечать быстрее 10 мс по 96 квантили, даже не по 99.
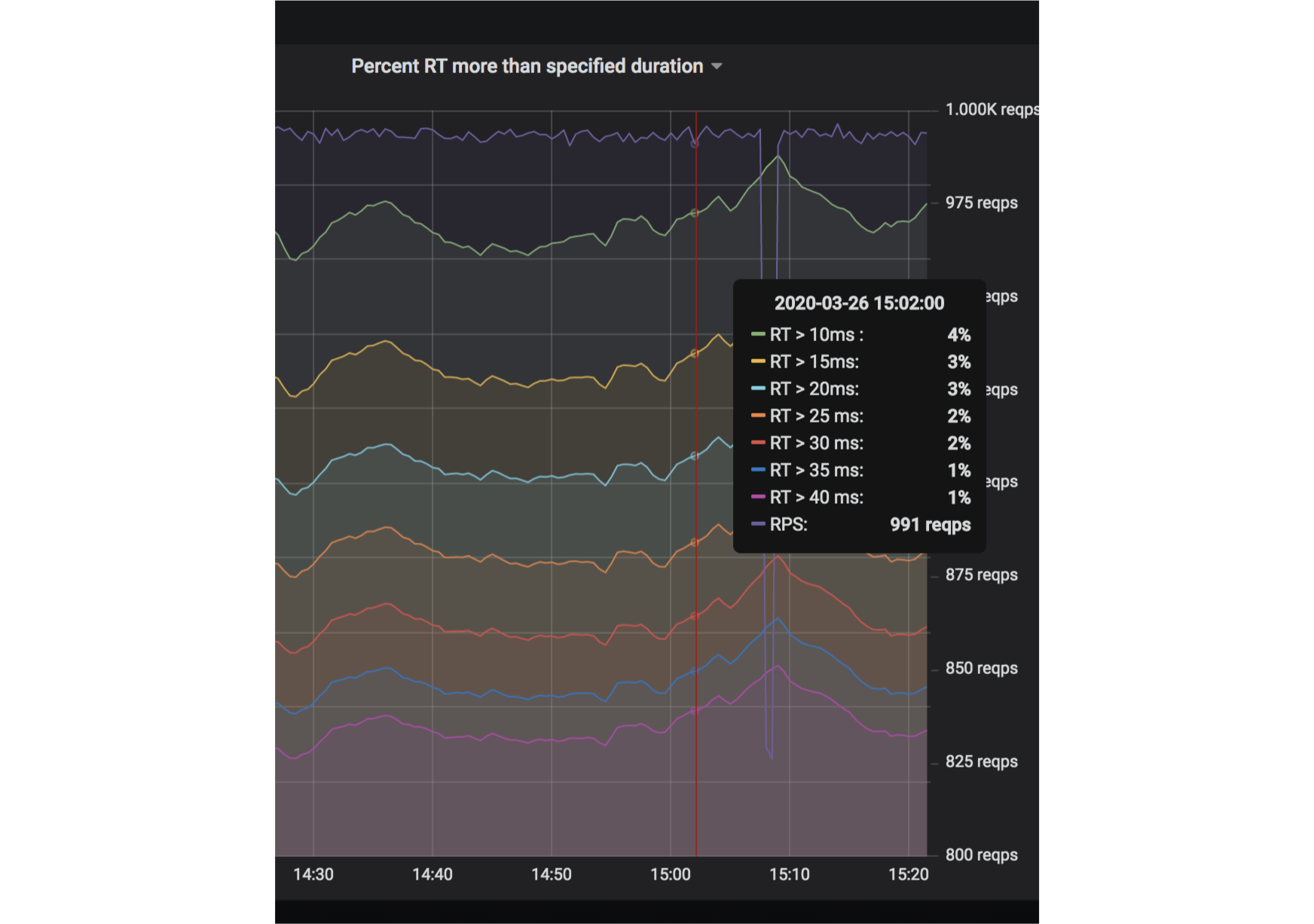
Далее после общения с командой инфраструктуры мы решили попробовать делать запрос в наш в бэкенд минуя Ingress Controller:
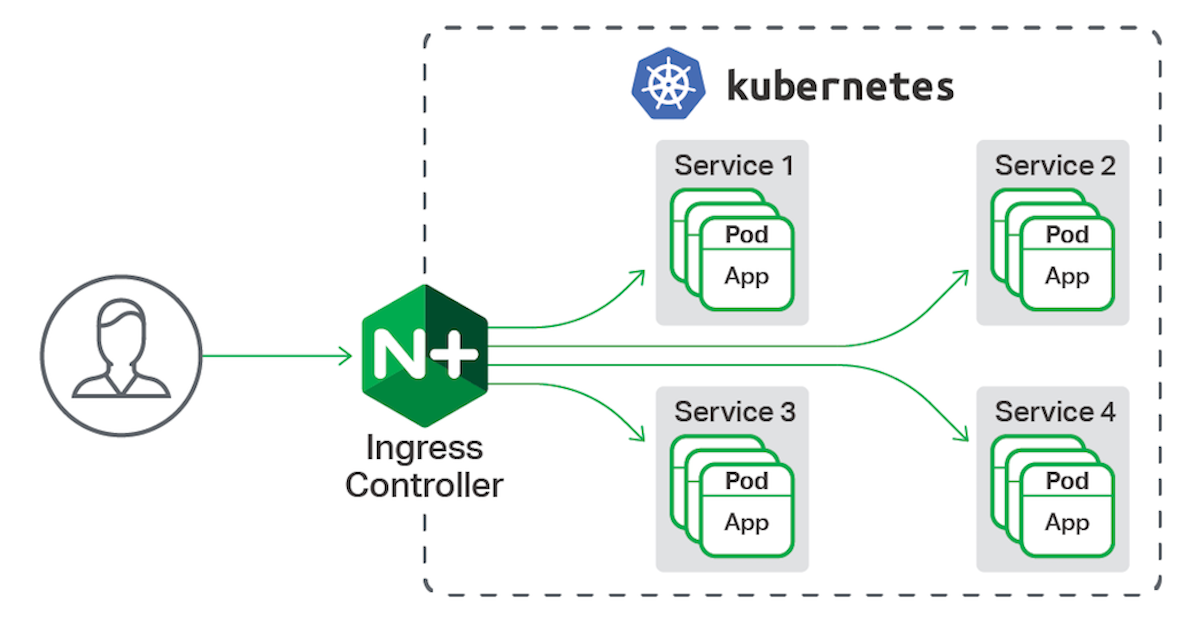
Мы стали делать запросы по IP из shooter в полигон и это привело нас к следующему результату: вместо 4% запросов, которые отвечали дольше 10 мс, их стало меньше 1%. По 0,9 квантили время ответа Ping с 5 мс уменьшилось до 1 мс, то есть в пять раз, а по 0,99 — в семь раз.
В результате процент ошибок gateway по тайм-ауту уменьшился с 4% до 0,2% — то есть в 20 раз.
Это привело к системному решению внутри компании: убрать балансировку на уровне Ingress Controller и перенести её на клиентскую сторону. Это в разы уменьшило время на Round Trip для ответов бэкенда всего Ozon.
Далее мы жили-не тужили ровно год, как к нам в дверь снова постучалось долгое время ответа и мы столкнулись со следующей ситуацией.
Проблема ядер сетевых карт
Мы заметили, что наш сервис отвечает дольше 40 мс по 99 квантили, что невозможно, учитывая нашу архитектуру. Всё находится в оперативке, и при хорошем масштабировании подов сервис просто по определению не может отвечать долго.
Мы пришли к команде инфраструктуры, история повторилась:
«Ваш код —
????не очень, оптимизируйте. Если что-то непонятно, см. п. 1».
Нам пришлось расчехлить наши shooter с полигоном, которые показали, что Round Trip больше 40 мс в 1,266% ответов для сервиса, который ровным счётом ничего не делает. Это говорит о том, что по 99 квантили скорость ответа любого бэкенда по априори не может быть меньше 40 мс и безусловно это аффектит весь Ozon.
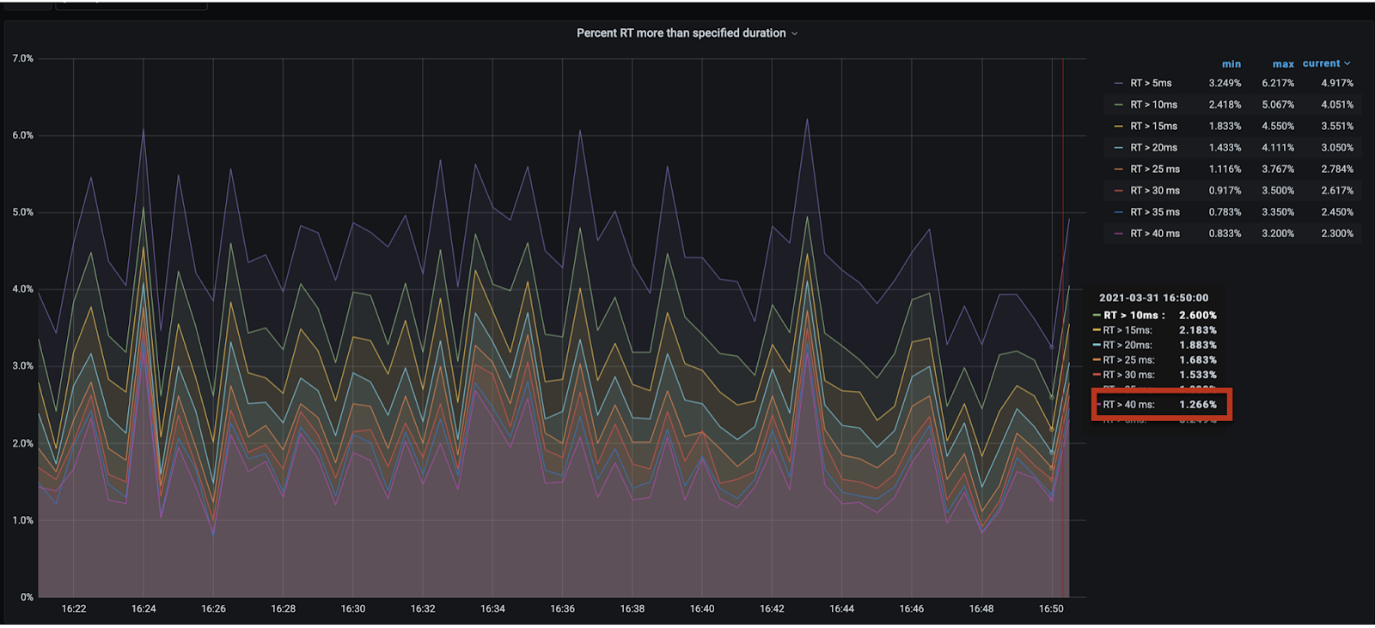
Далее мы забили в колокол, собрали доказательную базу, передали все материалы ребятам из команды платформы, они взяли на вооружение наш шутер с полигоном, расследовали проблему и решили её. Это сильно оптимизировало скорость всего Ozon. А ребята написали прекрасную статью (рекомендую к прочтению), в которой есть пасхалочка о нашей платформе А/B-тестов:

Заключение

Вне зависимости от того, какую именно систему вы строите:
• основываясь на опыте нашего Армагеддона, рекомендую заранее учесть все нюансы её пропускной способности и иметь перед глазами метрику, которая говорит о том, сколько времени/ресурсов осталось до огня на продакшене;
• основываясь на продемонстрированных восьми возможных подходах (модифицикациях) платформы А/B-тестов, рекомендую изо всех сил бороться за максимально простую архитектуру с минимальным количеством зависимостей, даже если для этого нужно упороться и придумать какую-то мульку (в нашем случае — свой бинарный протокол сжатия данных).
Если вы будете уверены в вашей архитектуре, то сможете доказать любой команде, что проблема не на вашей стороне. Тем самым помочь найти реальный батлнек, избавившись от которого, компания сможет получить большой профит, в нашем случае — уменьшение времени Round Trip по 99 квантили в семь раз.
За четыре года мы прошли огромный путь от двух до 100 экспериментов в месяц. Мы не раз оптимизировали нашу платформу, оперативно решали проблемы горящего продакшена, меняли процессы и придумывали инновационные решения. Хочу сказать большое спасибо всем бэкендерам, тимлидам, продукт оунерам, тестировщикам, фронтендерам, дизайнерам, аналитикам, которые вложили свою душу в нашу платформу А/B-тестов, продолжают её пилить и совершенствовать. Также отдельное спасибо руководству за доверие и наставничество.
Наша команда благодаря команде валидации, прекрасному продукт оунеру и нашему CTO @AntonStepanenko пилит очень интересные инструменты А/B-тестирования, о которых, надеюсь, мы расскажем в следующих статьях.
Cпасибо A/B Team: без вас не было бы прекрасной платформы и этой статьи ????

Отдельное спасибо за титанический труд редактору, вдохновителю и деврелу @golden_oar и главному коучу, контент-менеджеру и просто крутому аналитику @p0b0rchy, благодаря которому родился доклад на Saint HighLoad и эта статья ????
Комментарии (3)

Mhapach
22.09.2022 12:07+2Отличная статья. Сам не раз сталкивался с АВ /АВС и проблемами разработки инструментов для тестирования.
Но как всегда самое страшное интерпретация эксперта:)
Удачи:)
lambdafoonction
Молодцы ;)