
…или рассказ о self service на JupyterHub для дата саентистов

Всем привет, сегодня я расскажу о том, как мы переехали на наш велосипед в виде JupyterHub, и он оказался удобным. У нас в компании работают ~20 дата саентистов и в своей работе они используют множество Open Source-инструментов: Airflow, Hadoop, Hive, Spark и т.д. Но в данной статье речь пойдет исключительно о JupyterHub, точнее говоря о боли, которая преследовала администраторов, и как мы успешно ее побороли.
Почему мы выбрали JupyterHub
JupyterHub — это тот же Jupyter, только ставится он на отдельный сервер и работает как клиент-серверное веб-приложение.
Преимущества тут очевидны:
Вам не нужно беспокоиться об установке Jupyter’а и его окружения;
Не тратятся локальные ресурсы на вычисления;
Серверные мощности обычно выше локальных.
Но есть и недостатки:
Ресурсы сервера делятся на всех пользователей. По сути кто первый – того и тапки;
Одна среда на всех: вы будете пользоваться только тем ПО, которое установлено на сервере.
Обновление через боль. Установка нового ПО или обновление существующего требует согласования со всеми пользователями JupyterHub’а.
Просто представьте насколько задача усложнится, если на ваших серверах нет интернета. А политика безопасности настолько забюрократизирована, что процедура установки ПО будет съедать всё ваше время.
В игру вступает Kernel
Частично вышеописанные проблемы решаются с помощью kernel’ов — виртуальных сред (venv). Вы устанавливаете в них необходимые пакеты, затем переносите их на JupyterHub, после чего данное ядро становится доступным для выбора в интерфейсе лэптопа. А весь код, написанный на лэптопе, будет работать именно в этом окружении.
Но на практике оказалось, что kernel’ы оказались еще бо́льшей бедой: их также необходимо поддерживать и регулярно обновлять, плюс со временем они обрастали зависимостями и legacy-кодом. А до бесконечности создавать новые kernel’ы невозможно.
Все это вызывало негатив со всех сторон: дата саентисты не могли получить своевременный доступ к нужному ПО. А администраторам приходилось постоянно что-то досогласовывать, устанавливать и переустанавливать. Так продолжать мы не могли, поэтому мы решили оптимизировать работу дата саентистов.
Что придумали
Чтобы избавить саентистов (и админов) от боли, мы поставили перед собой следующие цели:
Установить/обновить любое ПО можно без привлечения администраторов;
Установить/обновить ПО можно в любой момент;
Установленное одним пользователем ПО не должно влиять на работу остальных пользователей;
Установленное ПО не должно негативно влиять на сервер в целом.
После исследования мы решили использовать связку Jupyterhub + Docker, а kernel’ы собирать в GitLab CICD, чтобы затем доставлять их на сервера Jupyterhub.

Схема работы
Схема работы следующая: для каждого пользователя в GitLab создана отдельная папка и, когда пользователю необходимо создать новый kernel, он:
Создает в своей папке новый проект (папку);
-
Создает файл requirements.json и описывает в нем:
2.1 Название kernel’а
2.2 Имя docker-образа (скачивается из DockerHub’а, либо с нашего локального репозитория, где хранятся наши кастомные образы).
2.3 Python-библиотеки для установки и их версии
В случае необходимости редактирует Dockerfile;
-
Запускает CICD-процесс, в котором:
4.1 Собирается ядро;
4.2 Выполняются команды из Dockerfile.
4.3 Устанавливаются библиотеки из requirements.json.
4.4 Ядро копируется на сервер JupyterHub.

Новое ядро сразу становится доступными для работы в JupyterHub’е. А в случае необходимости дата саентист самостоятельно правит параметры своего ядра и пересобирает его.
Что это нам дало
Теперь большая часть работы выполняется дата саентистами без привлечения администраторов. После 10 тысяч сборок kernel’ов мы сэкономили массу времени на процедурах согласований и самой установке.
Эффективность обоих сторон увеличилась, а админы привлекаются крайне редко —только для решения сложных вопросов. Цели 1 и 2 выполнены.
Доступ в интернет для скачивания библиотек мы реализовали посредством прокси-сервера, с которого разрешено обращаться только к репозиторию pip. Все ПО работает исключительно внутри контейнера. Что бы там не произошло — это никак не повлияет на работу других пользователей. Так мы закрыли вопрос с целями 3 и 4.
А теперь пара технических моментов:
Пример конфига ядра
kernel.json
{
"argv": [
"/usr/bin/docker",
"run",
"--network=host",
"--rm",
"-v",
"{connection_file}:/connection-spec",
"-v",
"/home/anikishin/work:/root/work",
"************/docker/registry/anikishin_dataflow:latest",
"python",
"-m",
"ipykernel_launcher",
"-f",
"/connection-spec"
],
"display_name": "anikishin_dataflow",
"language": "python",
"env": {}
}Использование --network=host объясняется тем, что во время работы pyspark на машине открывается случайный порт и кластер Hadoop должен иметь доступ к клиенту.
Пример сборки ядра
$ LOGIN=`echo "${GITLAB_USER_LOGIN}" | awk '{print tolower($0)}'`
$ echo -e "export PATH_TO_KERNEL=/${LOGIN}/${KERNEL}\nLOGIN=${LOGIN}\nKERNEL=${KERNEL}" >.env
$ source ./.env
$ PYTHON_VERSION=`/bin/python3 ${CI_PROJECT_DIR}/parser.py ${CI_PROJECT_DIR}/${PATH_TO_KERNEL}/requirements.json python_version`
$ sed "s/PYTHON_VERSION/${PYTHON_VERSION}/g" ${CI_PROJECT_DIR}/${PATH_TO_KERNEL}/Dockerfile
FROM python:3.8-slim
WORKDIR /root/work
COPY requirements.txt /tmp/requirements.txt
RUN pip install --upgrade -r /tmp/requirements.txt$ sed -i "s/PYTHON_VERSION/${PYTHON_VERSION}/g" ${CI_PROJECT_DIR}/${PATH_TO_KERNEL}/Dockerfile
$ /bin/python3 ${CI_PROJECT_DIR}/parser.py ${CI_PROJECT_DIR}/${PATH_TO_KERNEL}/requirements.json libs > ${CI_PROJECT_DIR}/${PATH_TO_KERNEL}/requirements.txt
$ echo "IMAGE_NAME=`/bin/python3 ${CI_PROJECT_DIR}/parser.py ${CI_PROJECT_DIR}/${PATH_TO_KERNEL}/requirements.json image_name`" >> ./.env
$ echo "IMAGE_VERSION=`/bin/python3 ${CI_PROJECT_DIR}/parser.py ${CI_PROJECT_DIR}/${PATH_TO_KERNEL}/requirements.json image_version`" >> ./.env
$ source ./.env
$ docker build --no-cache -t ************:5005/docker/registry/${LOGIN}_${IMAGE_NAME}:${IMAGE_VERSION} ${CI_PROJECT_DIR}/${PATH_TO_KERNEL}/
Step 1/4 : FROM python:3.8-slim
3.8-slim: Pulling from library/python
42c077c10790: Already exists
f63e77b7563a: Pulling fs layer
5215613c2da8: Pulling fs layer
9ca2d4523a14: Pulling fs layer
e97cee5830c4: Pulling fs layer
e97cee5830c4: Waiting
9ca2d4523a14: Verifying Checksum
9ca2d4523a14: Download complete
f63e77b7563a: Verifying Checksum
f63e77b7563a: Download complete
5215613c2da8: Verifying Checksum
5215613c2da8: Download complete
f63e77b7563a: Pull complete
5215613c2da8: Pull complete
9ca2d4523a14: Pull complete
e97cee5830c4: Verifying Checksum
e97cee5830c4: Download complete
e97cee5830c4: Pull complete
Digest: sha256:0e07cc072353e6b10de910d8acffa020a42467112ae6610aa90d6a3c56a74911
Status: Downloaded newer image for python:3.8-slim
---> 61c56c60bb49
Step 2/4 : WORKDIR /root/work
---> Running in 4baf6a21fb37
Removing intermediate container 4baf6a21fb37
---> 0f5165f4c567
Step 3/4 : COPY requirements.txt /tmp/requirements.txt
---> 40490bed96d2
Step 4/4 : RUN pip install --upgrade -r /tmp/requirements.txt
---> Running in a79389decbc4
Collecting ipykernel
Downloading ipykernel-6.13.1-py3-none-any.whl (133 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 133.2/133.2 KB 1.4 MB/s eta 0:00:00
Collecting ipython
Downloading ipython-8.4.0-py3-none-any.whl (750 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 750.8/750.8 KB 7.4 MB/s eta 0:00:00
Collecting numpy
Downloading numpy-1.22.4-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (16.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 16.9/16.9 MB 50.1 MB/s eta 0:00:00
Collecting psutil
Downloading psutil-5.9.1-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (284 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 284.7/284.7 KB 24.1 MB/s eta 0:00:00
Collecting tornado>=6.1
Downloading tornado-6.1-cp38-cp38-manylinux2010_x86_64.whl (427 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 427.5/427.5 KB 38.0 MB/s eta 0:00:00
Collecting packaging
Downloading packaging-21.3-py3-none-any.whl (40 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 40.8/40.8 KB 5.0 MB/s eta 0:00:00
Collecting matplotlib-inline>=0.1
Downloading matplotlib_inline-0.1.3-py3-none-any.whl (8.2 kB)
Collecting nest-asyncio
Downloading nest_asyncio-1.5.5-py3-none-any.whl (5.2 kB)
Collecting debugpy>=1.0
Downloading debugpy-1.6.0-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (1.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 71.2 MB/s eta 0:00:00
Collecting traitlets>=5.1.0
Downloading traitlets-5.2.2.post1-py3-none-any.whl (106 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 106.8/106.8 KB 18.8 MB/s eta 0:00:00
Collecting jupyter-client>=6.1.12
Downloading jupyter_client-7.3.3-py3-none-any.whl (131 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 132.0/132.0 KB 18.9 MB/s eta 0:00:00
Collecting pygments>=2.4.0
Downloading Pygments-2.12.0-py3-none-any.whl (1.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 68.7 MB/s eta 0:00:00
Collecting backcall
Downloading backcall-0.2.0-py2.py3-none-any.whl (11 kB)
Collecting pickleshare
Downloading pickleshare-0.7.5-py2.py3-none-any.whl (6.9 kB)
Collecting prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0
Downloading prompt_toolkit-3.0.29-py3-none-any.whl (381 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 381.5/381.5 KB 41.8 MB/s eta 0:00:00
Collecting pexpect>4.3
Downloading pexpect-4.8.0-py2.py3-none-any.whl (59 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 59.0/59.0 KB 12.4 MB/s eta 0:00:00
Collecting decorator
Downloading decorator-5.1.1-py3-none-any.whl (9.1 kB)
Collecting jedi>=0.16
Downloading jedi-0.18.1-py2.py3-none-any.whl (1.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 82.1 MB/s eta 0:00:00
Requirement already satisfied: setuptools>=18.5 in /usr/local/lib/python3.8/site-packages (from ipython->-r /tmp/requirements.txt (line 2)) (57.5.0)
Collecting stack-data
Downloading stack_data-0.2.0-py3-none-any.whl (21 kB)
Collecting parso<0.9.0,>=0.8.0
Downloading parso-0.8.3-py2.py3-none-any.whl (100 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.8/100.8 KB 23.1 MB/s eta 0:00:00
Collecting python-dateutil>=2.8.2
Downloading python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 247.7/247.7 KB 36.0 MB/s eta 0:00:00
Collecting jupyter-core>=4.9.2
Downloading jupyter_core-4.10.0-py3-none-any.whl (87 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 87.3/87.3 KB 21.7 MB/s eta 0:00:00
Collecting entrypoints
Downloading entrypoints-0.4-py3-none-any.whl (5.3 kB)
Collecting pyzmq>=23.0
Downloading pyzmq-23.1.0-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (1.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 68.4 MB/s eta 0:00:00
Collecting ptyprocess>=0.5
Downloading ptyprocess-0.7.0-py2.py3-none-any.whl (13 kB)
Collecting wcwidth
Downloading wcwidth-0.2.5-py2.py3-none-any.whl (30 kB)
Collecting pyparsing!=3.0.5,>=2.0.2
Downloading pyparsing-3.0.9-py3-none-any.whl (98 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 98.3/98.3 KB 19.7 MB/s eta 0:00:00
Collecting executing
Downloading executing-0.8.3-py2.py3-none-any.whl (16 kB)
Collecting asttokens
Downloading asttokens-2.0.5-py2.py3-none-any.whl (20 kB)
Collecting pure-eval
Downloading pure_eval-0.2.2-py3-none-any.whl (11 kB)
Collecting six>=1.5
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Installing collected packages: wcwidth, pure-eval, ptyprocess, pickleshare, executing, backcall, traitlets, tornado, six, pyzmq, pyparsing, pygments, psutil, prompt-toolkit, pexpect, parso, numpy, nest-asyncio, entrypoints, decorator, debugpy, python-dateutil, packaging, matplotlib-inline, jupyter-core, jedi, asttokens, stack-data, jupyter-client, ipython, ipykernel
Successfully installed asttokens-2.0.5 backcall-0.2.0 debugpy-1.6.0 decorator-5.1.1 entrypoints-0.4 executing-0.8.3 ipykernel-6.13.1 ipython-8.4.0 jedi-0.18.1 jupyter-client-7.3.3 jupyter-core-4.10.0 matplotlib-inline-0.1.3 nest-asyncio-1.5.5 numpy-1.22.4 packaging-21.3 parso-0.8.3 pexpect-4.8.0 pickleshare-0.7.5 prompt-toolkit-3.0.29 psutil-5.9.1 ptyprocess-0.7.0 pure-eval-0.2.2 pygments-2.12.0 pyparsing-3.0.9 python-dateutil-2.8.2 pyzmq-23.1.0 six-1.16.0 stack-data-0.2.0 tornado-6.1 traitlets-5.2.2.post1 wcwidth-0.2.5
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
WARNING: You are using pip version 22.0.4; however, version 22.1.2 is available.
You should consider upgrading via the '/usr/local/bin/python -m pip install --upgrade pip' command.
Removing intermediate container a79389decbc4
---> 942cfb92669c
Successfully built 942cfb92669c
Successfully tagged ************:5005/docker/registry/anikishin_proj3:latest
$ docker push ************:5005/docker/registry/${LOGIN}_${IMAGE_NAME}:${IMAGE_VERSION}
The push refers to repository [************:5005/docker/registry/anikishin_proj3]
ca238036b879: Preparing
5083b2b128f1: Preparing
92487648c84b: Preparing
9df5b2f53554: Preparing
590db2877d9d: Preparing
3d5419adeeb6: Preparing
2c9f341968bc: Preparing
ad6562704f37: Preparing
2c9f341968bc: Waiting
3d5419adeeb6: Waiting
ad6562704f37: Waiting
92487648c84b: Pushed
5083b2b128f1: Pushed
590db2877d9d: Pushed
2c9f341968bc: Pushed
9df5b2f53554: Pushed
3d5419adeeb6: Pushed
ca238036b879: Pushed
latest: digest: sha256:bc36a9bcc6be914a9b7f8ee6ea6c940409f32c57a528c521651442235309239a size: 1996
Running after_script
00:00
Saving cache
00:00
Uploading artifacts for successful job
00:00
Uploading artifacts...
Runtime platform arch=amd64 os=linux pid=27359 revision=c5874a4b version=12.10.2
./.env: found 1 matching files
Uploading artifacts to coordinator... ok id=38302 responseStatus=201 Created token=************
Job succeeded
Какие проблемы могут возникнуть
У нас все получилось не сразу. По пути возникали проблемы, из-за которых мы не смогли быстро перейти на новую схему:
1. Нет онбординга
Понадобилось некоторое время на обучение дата саентистов работе с докер-образами;
Изначально у коллег не было понимания, что данные в контейнере не сохранятся если их не писать в специальную директорию. Плюс ваши дата саентисты должны знать, что простого pip install может оказаться недостаточно: в контейнере должны быть установлены дополнительные зависимости, если этого требует Python-модуль.
Решение: сделайте инструкцию, проводите онбординг новых сотрудников, помогайте в случае проблем со сборкой кернелов.
2. Сохранность данных
Поскольку kernel’ы работают в докер-образах, то их перезагрузка приводит к потере всех сохраненных данных.
Решение: создайте отдельную общую папку на сервере, которая монтируется к докер-образу и в которую сохраняются все необходимые дата саентисту артефакты.
3. Ограничение ресурсов
Без лимитов и рычагов один дата саентист может навалить такую нагрузку, что другие не смогут нормально работать:

Это один контейнер с kernel.
И так может случиться не один раз
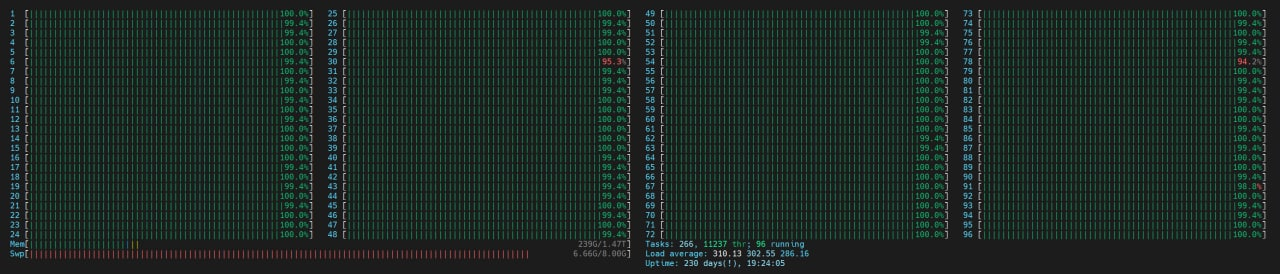
Решение: мониторьте нагрузку по CPU\RAM. Когда получаете алерт определяйте кто грузит машину и идите наказывать виновника попросите коллегу сбавить обороты.
4. Версионность
Как мы пришли к тегу #latest: изначально мы планировали версионировать все создаваемые докер-образы. Но дата саентисты стали делать такое множество версий своих образов, что в результате место в Docker registry быстро закончилось.
Решение: используйте версионность только для продуктивных процессов.
Планы на развитие
Резюмируя: мы получили современное решение, дата саентисты больше не дергают админов, они рады что могут самостоятельно править свои kernel в любое время, не прибегая к помощи со стороны.
Сейчас мы думаем о том, как реализовать удобное и гибкое ограничение ресурсов для контейнеров. Если у вас есть идеи как это сделать — напишите в комментариях.
Комментарии (4)

Mihij
14.10.2022 09:24Одной из "фишек" данного похода, как я понял, является децентрализованное обновление пакетов и компонетов. это отдано на откуп пользователя, дата-саентисту. А если что-то пошло не так? Система предусматривает автоматическое резервное хранение прошлый ядер-кернелов? И вопрос по версионности, есть ли какой-то единый регламент, хотя бы на уровне рекомендаций? Например, я могу создавать и сохранять хоть ежеминутно новые докер-образы или я апеллирую условными 100 ГБ. закончилось место - удаляю старые, неактуальные.

yumupdate Автор
14.10.2022 13:20+11. А если что-то пошло не так? Система предусматривает автоматическое резервное хранение прошлый ядер-кернелов?
Во первых, если билд кернела не проходит, старый кернел на машинах с юпитером не удаляется.
Откатить можно! Все ведется в гите, любое изменение можно откатить и запустить CI\CD снова, кернел соберётся и запушиться на сервера.
2.И вопрос по версионности, есть ли какой-то единый регламент, хотя бы на уровне рекомендаций?
Когда мы не контролировали использование тегов, место в регистри быстро кончилось.
Для кернелов юзеров используйте тег latest, самое верное решение на текущий момент.
Версионность образов используем только для продуктивных процессов.
V1RuS
а почему не подошел какой-нибудь TLJH? емнип, там для каждого пользователя свое окружение сразу "из коробки"
yumupdate Автор
Цель была - автоматизировать и изолировать рабочее окружение каждого пользователя.
В контейнерах можно поставить разные версии hadoop client \ hive \ pyhive и т.д. не боясь нарушить работу соседа, некоторые пакеты влияют на всю систему, venv нам не подходит.