
Генерация изображений при помощи ИИ — одна из самых новых возможностей искусственного интеллекта, поражающая людей (в том числе и меня). Способность создания потрясающих изображений на основании текстовых описаний похожа на магию; компьютер стал ближе к тому, как творит искусство человек. Выпуск Stable Diffusion стал важной вехой в этом развитии, поскольку высокопроизводительная модель оказалась доступной широкой публике (производительная с точки зрения качества изображения, скорости и относительно низких требований к ресурсам и памяти).
Поэкспериментировав в генерацией изображений, вы можете задаться вопросом, как же она работает.
В этой статье я вкратце расскажу, как функционирует Stable Diffusion.

Stable Diffusion гибка, то есть может использоваться множеством разных способов. Давайте сначала рассмотрим генерацию изображений на основе одного текста (text2img). На картинке выше показан пример текстового ввода и получившееся сгенерированное изображение. Кроме превращения текста в изображение, другим основным способом применения модели является изменение изображений (то есть входными данными становятся текст + изображение).

Давайте начнём разбираться со внутренностями модели, потому что это поможет нам объяснить её компоненты, их взаимодействие и значение опций/параметров генерации изображений.
Stable Diffusion — это система, состоящая из множества компонентов и моделей. Это не единая монолитная модель.
Изучая внутренности, мы первым делом заметим, что в модели есть компонент понимания текста, преобразующий текстовую информацию в цифровой вид, который передаёт заложенный в текст смысл.

Мы начнём с общего обзора, а позже углубимся в подробности машинного обучения. Однако для начала можно сказать, что этот кодировщик текста — это специальная языковая модель Transformer (технически её можно описать как текстовый кодировщик модели CLIP). Она получает на входе текст и выдаёт на выходе список чисел (вектор), описывающий каждое слово/токен в тексте.
Далее эта информация передаётся генератору изображений, который состоит из двух компонентов.

Генератор изображений выполняет два этапа:
1- Создание информации изображения.
Этот компонент является секретным ингредиентом Stable Diffusion. Именно благодаря нему возник такой рост качества по сравнению с предыдущими моделями.
Этот компонент выполняется в несколько шагов (step), генерируя информацию изображения. Это параметр steps в интерфейсах и библиотеках Stable Diffusion, который часто по умолчанию имеет значение 50 или 100.
Этап создания информации изображения действует полностью в пространстве информации изображения (или в скрытом пространстве). Подробнее о том, что это значит, мы расскажем ниже. Это свойство ускоряет работу по сравнению с предыдущими моделями диффузии, работавшими в пространстве пикселей. Этот компонент состоит из нейросети UNet и алгоритма планирования.
Слово «диффузия» (diffusion) описывает происходящее в этом компоненте. Это пошаговая обработка информации, приводящая в конечном итоге к генерации высококачественного изображения (при помощи следующего компонента — декодера изображений).

2- Декодер изображений.
Декодер изображений рисует картину на основе информации, которую он получил на этапе создания информации. Он выполняется только один раз в конце процесса и создаёт готовое пиксельное изображение.

На изображении выше мы видим три основных компонента (каждый со своей собственной нейросетью), из которых состоит Stable Diffusion:

Диффузия — это процесс, выполняемый внутри розового компонента «image information creator» (этапа создания информации изображения). Имея эмбеддинги токенов, описывающие введённый текст, и случайный начальный массив информации изображения (также они называются latent), процесс создаёт массив информации, который декодер изображения использует для рисования готового изображения.

Это процесс выполняется поэтапно. Каждый шаг добавляет больше релевантной информации. Чтобы представить процесс в целом, мы можем изучить массив случайных latent, и увидеть, что он преобразуется в визуальный шум. В данном случае визуальное изучение — это прохождение данных через декодер изображений.

Диффузия выполняется в несколько шагов, каждый из которых работает с входным массивом latent и создаёт ещё один массив latent, ещё больше напоминающий введённый текст, а вся визуальная информация модели собирается из всех изображений, на которых была обучена модель.

Мы можем визуализировать набор таких latent, чтобы увидеть, какая информация добавляется на каждом из шагов.

Наблюдать за этим процессом довольно увлекательно.
В данном случае нечто особо восхитительное происходит между шагами 2 и 4. Как будто контур возникает из шума.
Основная идея генерации изображений при помощи диффузионной модели использует тот факт, что у нас есть мощные модели компьютерного зрения. Если им передать достаточно большой массив данных, эти модели могут обучаться сложным операциям. Диффузионные модели подходят к задаче генерации изображений, формулируя задачу следующим образом:
Допустим, у нас есть изображение, сделаем первый шаг, добавив в него немного шума.

Назовём «срез» (slice) добавленного нами шума «noise slice 1». Сделаем ещё один шаг, добавив к шумному изображению ещё шума («noise slice 2»).

На этом этапе изображение полностью состоит из шума. Теперь давайте возьмём их в качестве примеров для обучения нейронной сети компьютерного зрения. Имея номер шага и изображение, мы хотим, чтобы она спрогнозировала, сколько шума было добавлено на предыдущем шаге.

Хотя этот пример показывает два шага от изображения к полному шуму, мы можем управлять тем, сколько шума добавляется к изображению, поэтому можно распределить его на десятки шагов, создав десятки примеров для обучения на каждое изображение для всех изображений в обучающем массиве данных.

Красота здесь в том, что после того, как эта сеть прогнозирования шума начнёт работать правильно, она, по сути, сможет рисовать картины, удаляя шум на протяжении множества шагов.
Примечание: это небольшое упрощение алгоритма диффузии. На ресурсах по ссылкам в конце статьи представлено более подробное математическое описание.
Обученный предсказатель шума может взять шумное изображение и количество шагов устранения шума, и на основании этого способен спрогнозировать срез шума.

Срез шума прогнозируется таким образом, что если мы вычтем его из изображения, то получим изображение, которое ближе к изображениям, на которых обучалась модель.

Если обучающий массив данных состоял из эстетически приятных изображений (например, LAION Aesthetics, на котором обучалась Stable Diffusion), то получившееся изображение будет иметь склонность к эстетической приятности.

В этом по большей мере и заключается описание генерации изображений диффузионными моделями, представленное в статье Denoising Diffusion Probabilistic Models. Теперь, когда мы понимаем, что такое диффузия, нам понятно, как работают основные компоненты не только Stable Diffusion, но и Dall-E 2 с Google Imagen.
Обратите внимание, что описанный выше процесс диффузии генерирует изображения без использования текстовых данных. В последующих разделах мы расскажем, как в процесс внедряется текст.
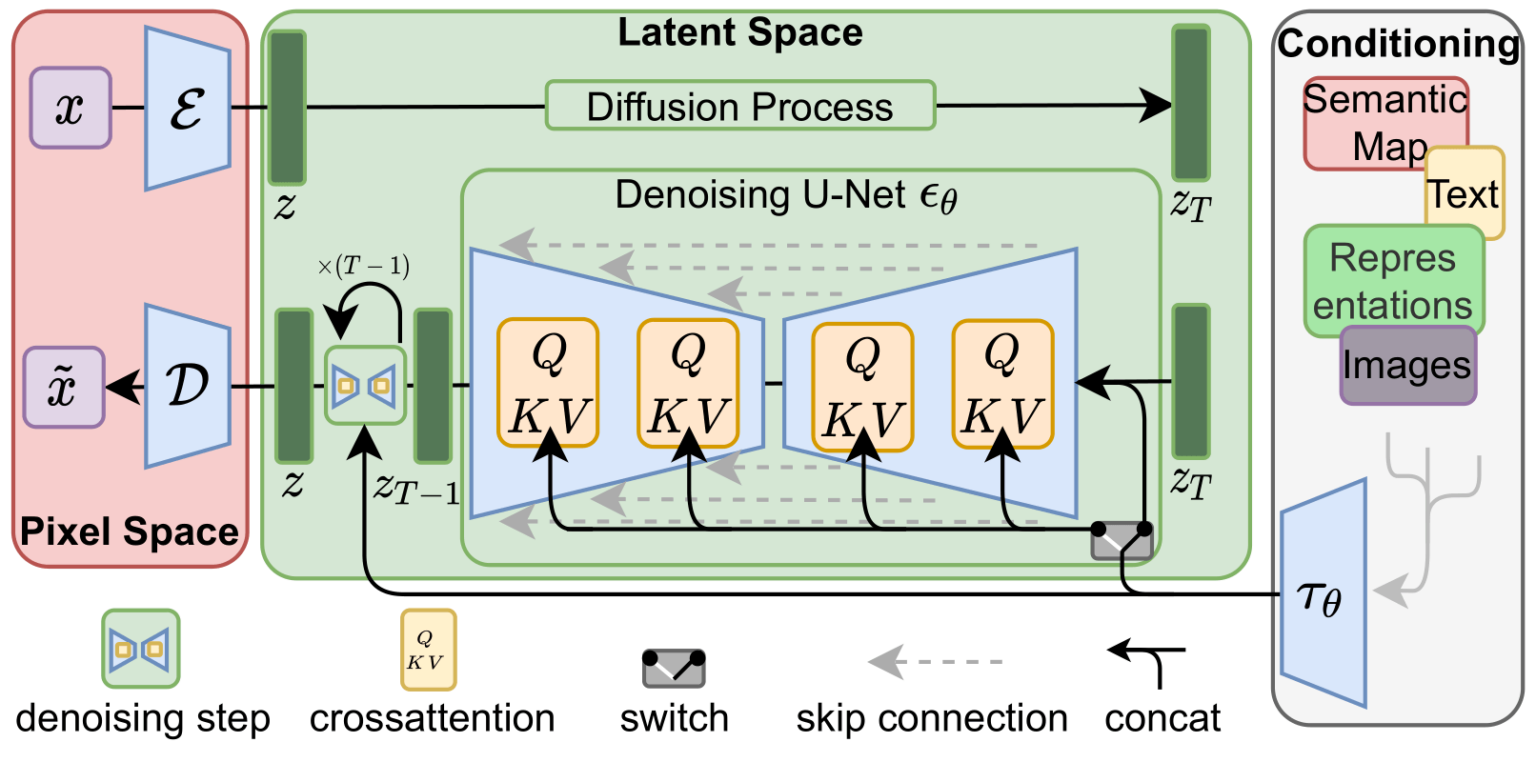
Для ускорения процесса генерации изображений Stable Diffusion (по информации из исследовательской статьи) выполняет процесс диффузии не с самими пиксельными изображениями, а со сжатой версией изображения. В статье это называется «переходом в скрытое пространство».
Это сжатие (и последующая распаковка/рисование) выполняется при помощи автокодировщика. Автокодировщик сжимает изображение в скрытое пространство при помощи своего кодировщика, а затем воссоздаёт его при помощи декодера на основе только сжатой информации.

Далее со сжатыми latent выполняется прямой процесс диффузии. Используются срезы шума, применяемые к этим latent, а не к пиксельному изображению. То есть предсказатель шума на самом деле обучается прогнозировать шум в сжатом описании (в скрытом пространстве).

При помощи прямого процесса (с использованием кодировщика автокодировщика) мы генерируем данные для обучения предсказателя шума. После его обучения мы можем генерировать изображения, выполняя обратный процесс (при помощи декодера автокодировщика).

Эти два потока показаны на рисунке 3 статьи про LDM/Stable Diffusion:
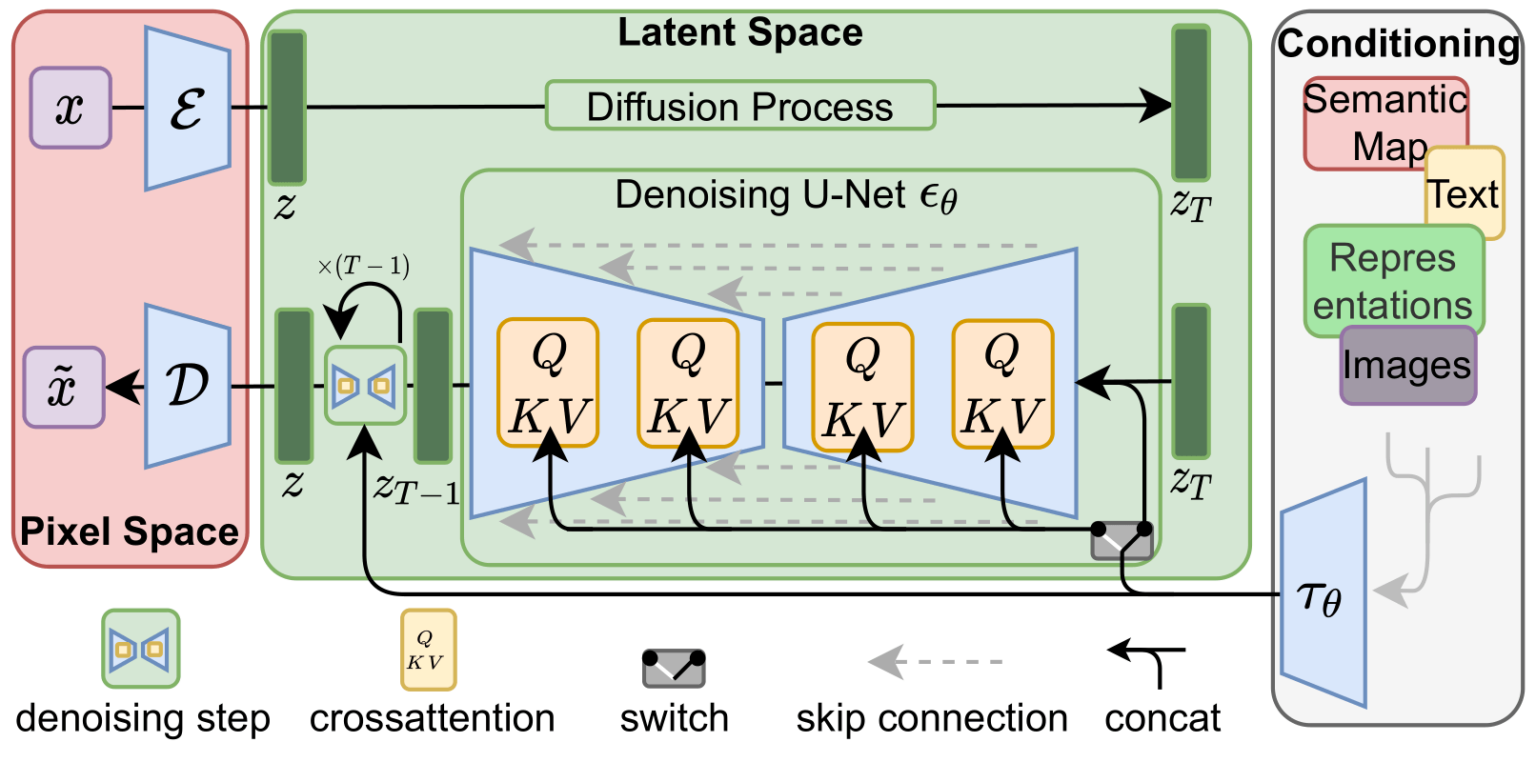
Также на этом рисунке показаны компоненты «согласования», которые в данном случае являются текстовыми строками, описывающими изображение, которое должна генерировать модель. Поэтому давайте рассмотрим эти текстовые компоненты.
Языковая модель Transformer используется в качестве компонента понимания языка, она получает текстовую строку и создаёт эмбеддинги токенов. В опубликованной модели Stable Diffusion используется ClipText (модель на основе GPT), а в статье применяется BERT.
В статье, посвящённой Imagen, показано, что выбор языковой модели важен. Замена на более объёмные языковые модели сильнее влияет на качество генерируемого изображения, чем более объёмные компоненты генерации изображений.

Улучшение/увеличение языковых моделей существенно влияет на качество моделей генерации изображений. Источник: Статья про Google Imagen, написанная Saharia и соавторами. Рисунок A.5.
В первых моделях Stable Diffusion просто подключалась предварительно обученная модель ClipText, выпущенная OpenAI. Возможно, будущие модели перейдут на новые и гораздо более объёмные OpenCLIP-варианты CLIP. В эту новую группу входных векторов включены текстовые модели размерами до 354 миллионов параметров, в отличие от 63 миллионов параметров в ClipText.
CLIP обучается на массиве изображений и подписей к ним. Массив данных выглядит примерно так, только состоит из 400 миллионов изображений и подписей:

CLIP — это сочетание кодировщика изображений и кодировщика текста. Обучающий процесс модели можно упрощённо представить как кодирование изображения и его подписи кодировщиками изображений и текста.

Затем мы сравниваем получившиеся эмбеддинги при помощи косинусного коэффициента. В начале процесса обучения схожесть будет низкой, даже если тест описывает изображение правильно.

Мы обновляем две модели так, чтобы в следующий раз при создании эмбеддингов получившиеся эмбеддинги были схожими.

Повторяя этот процесс со всем массивом данных и группами входных векторов большого размера, мы получаем кодировщики, способные создавать эмбеддинги, в которых изображение собаки и предложение «a picture of a dog» схожи. Как и в word2vec, процесс обучения также должен включать в себя отрицательные примеры изображений и подписей, которые не совпадают, а модель должна присваивать им низкую оценку схожести.
Чтобы сделать текст частью процесса генерации изображений, нам нужно модифицировать предсказатель шума так, чтобы он использовал в качестве входных данных текст.

Теперь наш массив данных содержит закодированный текст. Так как мы работаем в скрытом пространстве, то входные изображения и прогнозируемый шум находятся в скрытом пространстве.

Чтобы лучше понять, как текстовые токены используются в Unet, давайте глубже разберёмся с Unet.
Для начала рассмотрим диффузионную Unet, не использующую текст. Её входы и выходы выглядят так:
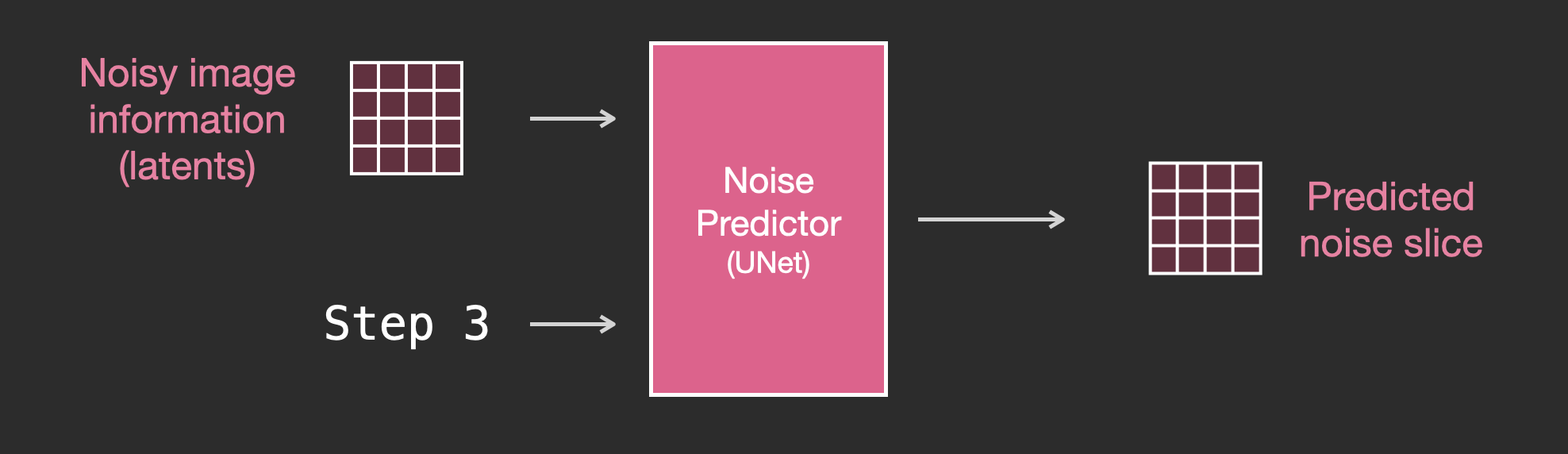
Внутри мы видим следующее:

Давайте посмотрим, как изменить эту систему, чтобы уделить внимание тексту.

Основное изменение системы, которое необходимо для добавления поддержки текстового ввода (техническое название: text conditioning) — добавление слоя attention между блоками ResNet.
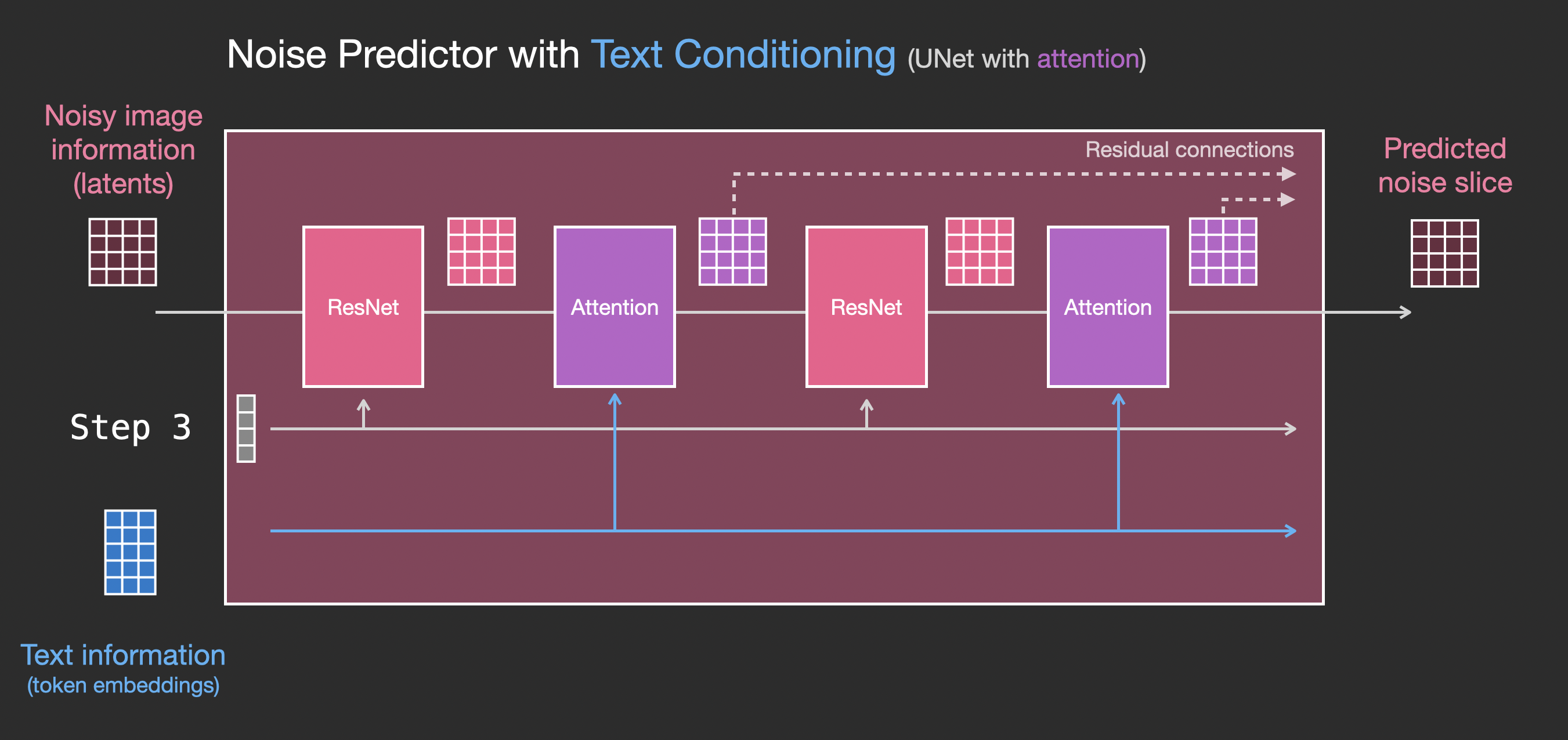
Обратите внимание, что блок resnet не смотрит непосредственно на текст. Слои attention объединяют эти текстовые описания в latent. И теперь следующий ResNet может использовать эту встроенную текстовую информацию в своей обработке.
Надеюсь, это даст вам поверхностное понимание работы Stable Diffusion. В ней задействовано множество других концепций, но я считаю, что их проще понять, если вы знаете описанные выше строительные блоки. Для дальнейшего изучения можно воспользоваться представленными ниже полезными ресурсами.
Благодарю Робина Ромбаха, Дэнниса Сомерса, Яна Сидякина и сообщество Cohere For AI за отзывы о ранних версиях этой статьи.
Поэкспериментировав в генерацией изображений, вы можете задаться вопросом, как же она работает.
В этой статье я вкратце расскажу, как функционирует Stable Diffusion.
Stable Diffusion гибка, то есть может использоваться множеством разных способов. Давайте сначала рассмотрим генерацию изображений на основе одного текста (text2img). На картинке выше показан пример текстового ввода и получившееся сгенерированное изображение. Кроме превращения текста в изображение, другим основным способом применения модели является изменение изображений (то есть входными данными становятся текст + изображение).
Давайте начнём разбираться со внутренностями модели, потому что это поможет нам объяснить её компоненты, их взаимодействие и значение опций/параметров генерации изображений.
Компоненты Stable Diffusion
Stable Diffusion — это система, состоящая из множества компонентов и моделей. Это не единая монолитная модель.
Изучая внутренности, мы первым делом заметим, что в модели есть компонент понимания текста, преобразующий текстовую информацию в цифровой вид, который передаёт заложенный в текст смысл.
Мы начнём с общего обзора, а позже углубимся в подробности машинного обучения. Однако для начала можно сказать, что этот кодировщик текста — это специальная языковая модель Transformer (технически её можно описать как текстовый кодировщик модели CLIP). Она получает на входе текст и выдаёт на выходе список чисел (вектор), описывающий каждое слово/токен в тексте.
Далее эта информация передаётся генератору изображений, который состоит из двух компонентов.
Генератор изображений выполняет два этапа:
1- Создание информации изображения.
Этот компонент является секретным ингредиентом Stable Diffusion. Именно благодаря нему возник такой рост качества по сравнению с предыдущими моделями.
Этот компонент выполняется в несколько шагов (step), генерируя информацию изображения. Это параметр steps в интерфейсах и библиотеках Stable Diffusion, который часто по умолчанию имеет значение 50 или 100.
Этап создания информации изображения действует полностью в пространстве информации изображения (или в скрытом пространстве). Подробнее о том, что это значит, мы расскажем ниже. Это свойство ускоряет работу по сравнению с предыдущими моделями диффузии, работавшими в пространстве пикселей. Этот компонент состоит из нейросети UNet и алгоритма планирования.
Слово «диффузия» (diffusion) описывает происходящее в этом компоненте. Это пошаговая обработка информации, приводящая в конечном итоге к генерации высококачественного изображения (при помощи следующего компонента — декодера изображений).
2- Декодер изображений.
Декодер изображений рисует картину на основе информации, которую он получил на этапе создания информации. Он выполняется только один раз в конце процесса и создаёт готовое пиксельное изображение.
На изображении выше мы видим три основных компонента (каждый со своей собственной нейросетью), из которых состоит Stable Diffusion:
-
ClipText для кодирования текста.
Входные данные: текст.
Выходные данные: 77 векторов эмбеддингов токенов, каждый в 768 измерениях. -
UNet + Scheduler для постепенной обработки/диффузии информации в пространстве информации (скрытом пространстве).
Входные данные: эмбеддинги текста и исходный многомерный массив (структурированные списки чисел, также называемые тензором), состоящий из шума.
Выходные данные: массив обработанной информации -
Декодер автокодировщика, рисующий готовое изображение при помощи массива обработанной информации.
Входные данные: массив обработанной информации (размеры: (4,64,64))
Выходные данные: готовое изображение (размеры: (3, 512, 512) — (красный/зелёный/синий, ширина, высота))
Что такое диффузия?
Диффузия — это процесс, выполняемый внутри розового компонента «image information creator» (этапа создания информации изображения). Имея эмбеддинги токенов, описывающие введённый текст, и случайный начальный массив информации изображения (также они называются latent), процесс создаёт массив информации, который декодер изображения использует для рисования готового изображения.
Это процесс выполняется поэтапно. Каждый шаг добавляет больше релевантной информации. Чтобы представить процесс в целом, мы можем изучить массив случайных latent, и увидеть, что он преобразуется в визуальный шум. В данном случае визуальное изучение — это прохождение данных через декодер изображений.
Диффузия выполняется в несколько шагов, каждый из которых работает с входным массивом latent и создаёт ещё один массив latent, ещё больше напоминающий введённый текст, а вся визуальная информация модели собирается из всех изображений, на которых была обучена модель.
Мы можем визуализировать набор таких latent, чтобы увидеть, какая информация добавляется на каждом из шагов.
Наблюдать за этим процессом довольно увлекательно.
В данном случае нечто особо восхитительное происходит между шагами 2 и 4. Как будто контур возникает из шума.
Как работает диффузия
Основная идея генерации изображений при помощи диффузионной модели использует тот факт, что у нас есть мощные модели компьютерного зрения. Если им передать достаточно большой массив данных, эти модели могут обучаться сложным операциям. Диффузионные модели подходят к задаче генерации изображений, формулируя задачу следующим образом:
Допустим, у нас есть изображение, сделаем первый шаг, добавив в него немного шума.
Назовём «срез» (slice) добавленного нами шума «noise slice 1». Сделаем ещё один шаг, добавив к шумному изображению ещё шума («noise slice 2»).
На этом этапе изображение полностью состоит из шума. Теперь давайте возьмём их в качестве примеров для обучения нейронной сети компьютерного зрения. Имея номер шага и изображение, мы хотим, чтобы она спрогнозировала, сколько шума было добавлено на предыдущем шаге.
Хотя этот пример показывает два шага от изображения к полному шуму, мы можем управлять тем, сколько шума добавляется к изображению, поэтому можно распределить его на десятки шагов, создав десятки примеров для обучения на каждое изображение для всех изображений в обучающем массиве данных.
Красота здесь в том, что после того, как эта сеть прогнозирования шума начнёт работать правильно, она, по сути, сможет рисовать картины, удаляя шум на протяжении множества шагов.
Примечание: это небольшое упрощение алгоритма диффузии. На ресурсах по ссылкам в конце статьи представлено более подробное математическое описание.
Рисование изображений устранением шума
Обученный предсказатель шума может взять шумное изображение и количество шагов устранения шума, и на основании этого способен спрогнозировать срез шума.
Срез шума прогнозируется таким образом, что если мы вычтем его из изображения, то получим изображение, которое ближе к изображениям, на которых обучалась модель.
Если обучающий массив данных состоял из эстетически приятных изображений (например, LAION Aesthetics, на котором обучалась Stable Diffusion), то получившееся изображение будет иметь склонность к эстетической приятности.
В этом по большей мере и заключается описание генерации изображений диффузионными моделями, представленное в статье Denoising Diffusion Probabilistic Models. Теперь, когда мы понимаем, что такое диффузия, нам понятно, как работают основные компоненты не только Stable Diffusion, но и Dall-E 2 с Google Imagen.
Обратите внимание, что описанный выше процесс диффузии генерирует изображения без использования текстовых данных. В последующих разделах мы расскажем, как в процесс внедряется текст.
Увеличение скорости: диффузия сжатых (скрытых) данных, а не пиксельного изображения
Для ускорения процесса генерации изображений Stable Diffusion (по информации из исследовательской статьи) выполняет процесс диффузии не с самими пиксельными изображениями, а со сжатой версией изображения. В статье это называется «переходом в скрытое пространство».
Это сжатие (и последующая распаковка/рисование) выполняется при помощи автокодировщика. Автокодировщик сжимает изображение в скрытое пространство при помощи своего кодировщика, а затем воссоздаёт его при помощи декодера на основе только сжатой информации.
Далее со сжатыми latent выполняется прямой процесс диффузии. Используются срезы шума, применяемые к этим latent, а не к пиксельному изображению. То есть предсказатель шума на самом деле обучается прогнозировать шум в сжатом описании (в скрытом пространстве).
При помощи прямого процесса (с использованием кодировщика автокодировщика) мы генерируем данные для обучения предсказателя шума. После его обучения мы можем генерировать изображения, выполняя обратный процесс (при помощи декодера автокодировщика).
Эти два потока показаны на рисунке 3 статьи про LDM/Stable Diffusion:
Также на этом рисунке показаны компоненты «согласования», которые в данном случае являются текстовыми строками, описывающими изображение, которое должна генерировать модель. Поэтому давайте рассмотрим эти текстовые компоненты.
Текстовый кодировщик: языковая модель Transformer
Языковая модель Transformer используется в качестве компонента понимания языка, она получает текстовую строку и создаёт эмбеддинги токенов. В опубликованной модели Stable Diffusion используется ClipText (модель на основе GPT), а в статье применяется BERT.
В статье, посвящённой Imagen, показано, что выбор языковой модели важен. Замена на более объёмные языковые модели сильнее влияет на качество генерируемого изображения, чем более объёмные компоненты генерации изображений.
Улучшение/увеличение языковых моделей существенно влияет на качество моделей генерации изображений. Источник: Статья про Google Imagen, написанная Saharia и соавторами. Рисунок A.5.
В первых моделях Stable Diffusion просто подключалась предварительно обученная модель ClipText, выпущенная OpenAI. Возможно, будущие модели перейдут на новые и гораздо более объёмные OpenCLIP-варианты CLIP. В эту новую группу входных векторов включены текстовые модели размерами до 354 миллионов параметров, в отличие от 63 миллионов параметров в ClipText.
Как обучается CLIP
CLIP обучается на массиве изображений и подписей к ним. Массив данных выглядит примерно так, только состоит из 400 миллионов изображений и подписей:
CLIP — это сочетание кодировщика изображений и кодировщика текста. Обучающий процесс модели можно упрощённо представить как кодирование изображения и его подписи кодировщиками изображений и текста.
Затем мы сравниваем получившиеся эмбеддинги при помощи косинусного коэффициента. В начале процесса обучения схожесть будет низкой, даже если тест описывает изображение правильно.
Мы обновляем две модели так, чтобы в следующий раз при создании эмбеддингов получившиеся эмбеддинги были схожими.
Повторяя этот процесс со всем массивом данных и группами входных векторов большого размера, мы получаем кодировщики, способные создавать эмбеддинги, в которых изображение собаки и предложение «a picture of a dog» схожи. Как и в word2vec, процесс обучения также должен включать в себя отрицательные примеры изображений и подписей, которые не совпадают, а модель должна присваивать им низкую оценку схожести.
Передача текстовой информации в процесс генерации изображений
Чтобы сделать текст частью процесса генерации изображений, нам нужно модифицировать предсказатель шума так, чтобы он использовал в качестве входных данных текст.
Теперь наш массив данных содержит закодированный текст. Так как мы работаем в скрытом пространстве, то входные изображения и прогнозируемый шум находятся в скрытом пространстве.
Чтобы лучше понять, как текстовые токены используются в Unet, давайте глубже разберёмся с Unet.
Слои предсказателя шума Unet (без текста)
Для начала рассмотрим диффузионную Unet, не использующую текст. Её входы и выходы выглядят так:
Внутри мы видим следующее:
- Unet — это последовательность слоёв, работающая над преобразованием массива latent.
- Каждый слой обрабатывает выходные данные предыдущего слоя.
- Часто выходных данных подается (через остаточные соединения) для обработки на дальнейших этапах сети.
- Шаг времени преобразуется в вектор эмбеддингов шага времени, который используется в слоях.
Слои предсказателя шума Unet с текстом
Давайте посмотрим, как изменить эту систему, чтобы уделить внимание тексту.
Основное изменение системы, которое необходимо для добавления поддержки текстового ввода (техническое название: text conditioning) — добавление слоя attention между блоками ResNet.
Обратите внимание, что блок resnet не смотрит непосредственно на текст. Слои attention объединяют эти текстовые описания в latent. И теперь следующий ResNet может использовать эту встроенную текстовую информацию в своей обработке.
Заключение
Надеюсь, это даст вам поверхностное понимание работы Stable Diffusion. В ней задействовано множество других концепций, но я считаю, что их проще понять, если вы знаете описанные выше строительные блоки. Для дальнейшего изучения можно воспользоваться представленными ниже полезными ресурсами.
Ресурсы
- У меня есть одноминутный клип на YouTube по использованию Dream Studio для генерации изображений при помощи Stable Diffusion.
- Stable Diffusion with ???? Diffusers
- The Annotated Diffusion Model
- How does Stable Diffusion work? – Latent Diffusion Models EXPLAINED [Видео]
- Stable Diffusion — What, Why, How? [Видео]
- High-Resolution Image Synthesis with Latent Diffusion Models [Статья про Stable Diffusion]
- Более подробное изучение алгоритмов и математики представлено в статье Лилиан Венг What are Diffusion Models?
Благодарности
Благодарю Робина Ромбаха, Дэнниса Сомерса, Яна Сидякина и сообщество Cohere For AI за отзывы о ранних версиях этой статьи.
Комментарии (11)

e-zig
19.10.2022 10:55после того, как эта сеть прогнозирования шума начнёт работать правильно, она, по сути, сможет рисовать картины, удаляя шум на протяжении множества шагов.
Слишком резкий скачок для понимания. (Почему удаление шума равно рисованию (новой?) картины?).

freeExec
19.10.2022 17:20Потому что если из шума постепенно стирать не нужное и дорисовывать нужное — можно получить любое изображение.
Все же помню шутку:У вас в слове кот 3 опечатки, должно быть слон
kitaisky
Я так и не понял, как используется векторное представление текста. На вход ResNet у нас подается картинка с шумом(или ее проекция во внутреннее пространство?), а как на ее обработку сеткой влияет этэншн и текстовый вектор?
freeExec
Слой attention подмешивает туда ембендинги слов. Грубо говоря двигает шумную картинку в сторону текста в латентном пространстве.
kitaisky
Подмешивает в вектор картинки в латентном пространстве? А в резнет она потом перед подачей разворачивается обратнотв картинку?
freeExec
Да там всё работает в латентном пространстве и только в самом конце превращают в картинку.
kitaisky
Там u-net для одномерных векторов используется? Не мог в это въехать, спасибо.
freeExec
Почему одномерный. Судя по статье написано что формируют «типа пиксельное изображение» 77 * 768. Или я не так понял вопрос.
kitaisky
77 этт количество векторов из текстового описания, как я понимаю, а юнет вроде для картинок изначально, типа 512х512х3. Видимо этеншн подмешивает в латентное представление сумму из этих 77
freeExec
Я думаю не нужно воспринимать U-Net как нечто монолитное, не изменяемое и то что вы привыкли видеть за этим словом. Скорее всего там просто общий подход к конфигурации свёрточной сети.
kitaisky
Я не спорю, но в статье визуализация входа как матрица 3х3, что отсылает таки к стандартным методам обработки именно изображений. С ваших слов это матрица 77х[размерность датентного пространства] - мне кажется это не логично, и что скорее там тогда одномергый вектор, к которому как раз из 77 векторов текстового представления подмешивается новая информация. Хотелось бы этот момент прояснить.