
Привет! Меня зовут Алексей Салаев, я Java-разработчик команды Corp Digital в Росбанке. В этом посте я расскажу, как можно оптимизировать и кастомизировать запросы в Spring: опишу потенциальные проблемы, оценю возможные пути решения и проиллюстрирую всё примерами.

Представим, что у нас есть сервис по работе с документами. Это могут быть ордера, заявки, платежи или что-то другое. У каждого документа есть жизненный цикл — создание, подписание и затем исполнение (отправка в целевую систему).
С созданием всё понятно: сделали документ и положили в базу. На подписании остановимся подробней. Как оно может проходить? Представим, что у нас есть три уровня подписи: руководитель (HEAD), эксперт (EXPERT) и бухгалтер (ACCOUNTANT). И есть пользователи, каждых из которых уполномочен те или иные подписи проставлять:
руководителю доступны все три — HEAD, EXPERT и ACCOUNTANT;
эксперту — только своя, EXPERT;
бухгалтеру — HEAD и ACCOUNTANT.
Рассмотрим, как может выглядеть запрос подписания:
Проверка прав пользователя на возможность подписания. Для этого необходимо обратиться в сервис USER, который по определенному идентификатору возвратит нам уровни подписей пользователя. С ними мы сможем проверить, уполномочен пользователь подписывать документ или нет.
Сам процесс подписания. Для этого необходимо снова обратиться в сервис USER за уровнями подписей пользователя, на основе которых уже пройдет само предписание.
Постобработка запроса — например, это может быть возврат в вызывающую систему для уровней других подписей, которые пользователь может проставить. Поскольку пользователь может иметь несколько уровней подписей, а проставить не все, то необходимо снова обратиться в сервис USER за уровнями подписей пользователя. Далее сервис определит, какие подписи не были проставлены, и вернет в вызывающую систему список уровней подписей, который пользователь еще может проставить.
Как это реализовано в коде? Мы получаем запрос в controller и затем идем в service в метод sign, где работает основная логика:
Вызывается метод checkPermissions , которые отвечают за проверку прав.
Вызывается метод signing, который отвечает за сам процесс подписания.
Вызывается метод getActions, который отвечает за постобработку.
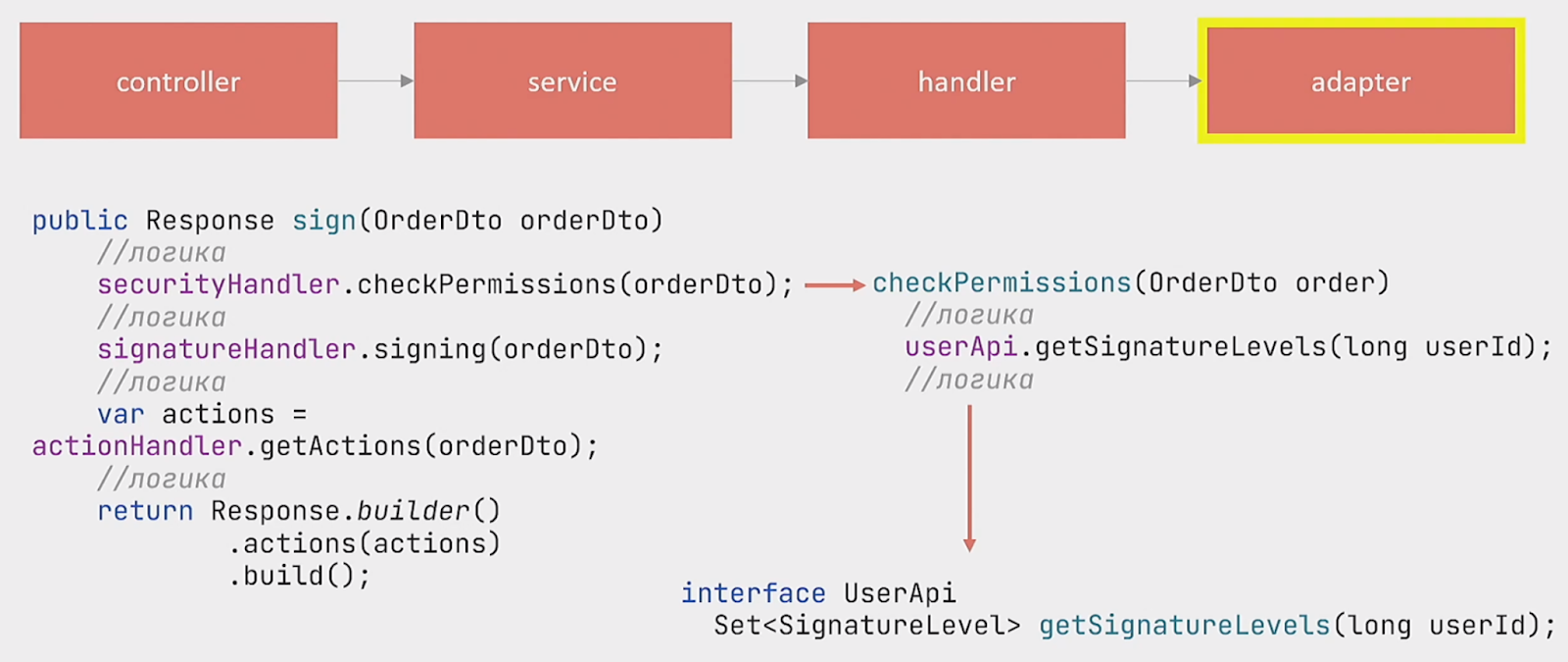
В каждом из этих методов в адаптере сервиса USER вызывается метод getSignatureLevels, который возвращает уровни пользователя. То есть вызов сервиса User происходит трижды.
Потенциальные проблемы такого подхода — долгое выполнение запросов и нагрузка на вызываемый сервис. Что можно с этим сделать?
Остановиться на последовательном выполнении, то есть оставить всё как есть. Да, проблемы сохранятся, но если мы делаем какой-нибудь пилот, но нам куда важнее скорость разработки.
Передача в параметрах метода. Делаем один запрос, при первом обращении данные сохраняются в переменную метода, после чего полученные данные передаются в сигнатуре методов везде, где потребуется. Плюс такого подхода — простота. Минус — мы смешиваем бизнес-логику и техническую часть; их лучше разделять, потому что со временем это будет всё сложнее поддерживать и дорабатывать.
Локальное кеширование. Делается один запрос, при первом обращении данные сохраняются в поле класса, а при последующих обращениях подтягиваются из него. Если данные еще не сохранились, то мы снова обращаемся в сервис USER.
Кеширование с использованием Spring Cache. При первом обращении данные кешируются, при последующих подтягиваются из кеша. На мой взгляд, это самый логичный подход. Его преимущества — достаточно простое подключение, легкая кастомизация и последующая работа.
О двух последних подходах я расскажу подробнее.
Кеширование с использованием Spring Cache
В Spring Cache абстракцию нам предоставляет Spring, а реализацию cache мы подключаем сами. Есть много доступных вариантов:
EhCache
JCache
Hazelcast
Infinispan
Couchbase
Redis
Caffeine
Simple
Я остановлюсь на Caffeine, так как этот вариант достаточно простой и лучше всего подходит для примера.
Spring Cache подключается легко. Мы ставим аннотацию @Cachable над тем методом, которым хотим закешировать, указываем, какое имя кеша использовать, и добавляем аннотацию @EnableCaching для поддержки кеширования.
@Cacheable(cacheNames = {"signature"})
public Set<SignatureLevel> getSignatureLevels(long userId) {
//логика
}Что представляет собой Cache? По сути, это мапа, в которой есть ключ и значение. По ключу мы добавляем данные, а затем берем значение, если они там есть. По умолчанию Spring использует генератор ключей SimpleKeyGenerator, который можно заменить на свой. Но мы остановимся на стандартном.
SimpleKeyGenerator берет сигнатуру метода и смотрит, есть ли в ней параметры:
Если параметров нет, он берет 0.
Если параметр один, он берет хеш-код этого параметра.
Если параметров несколько, то на основе хеш-кодов всех параметров вычисляется общее значение, которое используется в качестве ключа кеширования.
Использовать в качестве ключей данные из сигнатуры метода — это не очень хорошая практика. Со временем данные могут меняться, и туда могут добавляться поля, которые в кешировании участвовать не должны. Чтобы этого избежать, лучше указывать именно те параметры, которые мы хотим использовать в качестве ключа. В данном случае я указал userId:
@Cacheable(cacheNames = {"signature"}, key = "{#userId}")
public Set<SignatureLevel> getSignatureLevels(long userId) {
//логика
}Мы запрашиваем уровни подписей пользователя по его идентификатору (userId) в сервисе USER, получаем данные и кешируем их. При последующих вызовах запрос в сервис USER выполняться не будет, а данные поступят из кеша. Вроде все просто.
Теперь давайте рассмотрим, как закешировать данные на основе еще одного параметра, которого нет в сигнатуре метода. Например, мы хотим иметь кеш в рамках одного запроса. Если параллельно придет другой запрос, то данные необходимо закешировать отдельно и не использовать кеш парольного запроса. Для этого будем использовать рассчитанный на основе userId ключ из сигнатуры метода и requestId, который может быть передан в заголовках http-запроса.
Возникает вопрос: как мы можем передать данные из заголовка запроса в качестве ключа кеширования. Можно, например, использовать ThreadLocal — он позволяет хранить данные, которые будут доступны только определенному потоку. Для этого настроим фильтр, который будет сохранять в ThreadLocal данные из заголовка http-запроса.
В качестве ключа для кеша мы можем использовать любой дополнительный параметр, поэтому в примере я назвал его Custom-ID, чтобы это показать.
@Component
public class CustomFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest httpRequest = (HttpServletRequest) request;
try {
ThreadLocalCustom.setContext(new Context(httpRequest.getHeader("Custom-ID")));
chain.doFilter(request, response);
} finally {
ThreadLocalCustom.clearContext();
}
Теперь осталось только указать данный параметр из ThreadLocal в качестве ключа для кеширования. Для этого можем использовать язык выражений SpEL:
@Cacheable(cacheNames = {"signature"},
key = "{#userID, T(ru.rosbank.ThreadLocalCustom).getCustomId()}")
public Set<SignatureLevel> getSignatureLevels(long userId) {
//логика
}Мы рассмотрели, как можем в качестве ключа использовать любой параметр из запроса. Преимущество этого подхода: мы можем кешировать данные в рамках одного запроса, одной сессии или вообще на основе любого параметра.
Теперь представим, что у нас есть два пользователя — руководитель и исполняющий обязанности руководителя (и.о. руководителя). По бизнес-логике для и.о. руководителя мы можем кешировать, например, на одну минуту после записи. А для реального руководителя — на пять минут. Как это сделать?
Сначала нужно настроить CacheManager, который будет отвечать, сколько будут жить данные в кеше. Покажу на примере Caffeine. Создадим бин defaultCacheManager.
@Bean("defaultCacheManager")
public CacheManager defaultCacheManager() {
var cacheManager = new CaffeineCacheManager("signature");
cacheManager.setCaffeine(caffeineCacheBuilder());
return cacheManager;
}
public Caffeine<Object, Object> caffeineCacheBuilder() {
return Caffeine.newBuilder()
.maximumSize(5000)
.expireAfterWrite(Duration.ofSeconds(60)) //истечение после последней записи
//.expireAfterAccess(Duration.ofDays(1)) //истечение после последнего доступа
}После создания мы можем указать его в качестве cacheManager для кеширования:
@Cacheable(cacheNames = {"signature"},
cacheManager = "defaultCacheManager")
public Set<SignatureLevel> getSignatureLevels(long userId) {
//логика
}
Мы, кстати, можем не указывать здесь cacheManager, если укажем Spring, чтобы он использовал бин defaultCacheManager по умолчанию, через аннотацию @Primary.
Мы настроили кеш для пользователей с одной минутой кеширования. Теперь настроим кеш для пользователей с пятью минутами после добавления в кеш. Назовем его constantLifetimeCacheManager.
@Bean("constantLifetimeCacheManager")
public CacheManager constantLifetimeCacheManager() {
var cacheManager = new CaffeineCacheManager(“signatureConst”);
cacheManager.setCaffeine(constantLifetimeCacheBuilder());
return cacheManager;
}
// фиксированное время жизни 5 минут
public Caffeine<Object, Object> constantLifetimeCacheBuilder() {
return Caffeine.newBuilder()
.initialCapacity(1000)
.maximumSize(5000)
.expireAfter(new Expiry<>() {
@Override
public long expireAfterCreate(Object key, Object value, long currentTime)
{
return TimeUnit.MINUTES.toNanos(5);
}
...
Указываем данный CacheManager в параметрах аннотации:
@Cacheable(cacheNames = {“signature”},
cacheManager = “constantLifetimeCacheManager”)
public Set<SignatureLevel> getSignatureLevels(long userId) {
//логика
Представим, что по бизнес-логике мы, используя маску, можем определить по id пользователя, является ли он руководителем или и.о. руководителя. А как сделать, чтобы у нас по данной маске использовался либо defaultCacheManager, либо constantLifetimeCacheManager?
Самый простой вариант — через if-else. Создаем два метода, getSignatureLevels_1 и getSignatureLevels_2, с разными настройками кеширования и в зависимости от маски вызываем соответствующий метод. Но Spring предоставляет нам другую реализацию, на основе CacheResolver. Для этого нам необходимо реализовать метод Collection<? extends Cache> resolveCaches(CacheOperationInvocationContext<?> context) интерфейса CacheResolver:
public class MultipleCacheResolver implements CacheResolver {
@Qualifier("defaultCacheManager")
private final CacheManager defaultCacheManager;
@Qualifier("constantLifetimeCacheManager")
private final CacheManager constantLifetimeCacheManager;
@Override
public Collection<? extends Cache> resolveCaches(CacheOperationInvocationContext<?> context) {
var caches = new ArrayList<Cache>();
var userId = (long) context.getArgs()[0];
if (userId % 2 == 0) { //маска, например, четный или не четный id
caches.add(defaultCacheManager.getCache(CaffeineCacheConfig.CACHE_NAME_SIGNATURE));
} else {
caches.add(constantLifetimeCacheManager.getCache(CaffeineCacheConfig.CACHE_NAME_SIGNATURE_CONST));
}
return caches;
}Здесь мы получаем из CacheOperationInvocationContext данные сигнатуры метода — в нашем случае это единственный параметр userId. Проверяем по маске: в примере выше смотрим, четный параметр или нечетный. В зависимости от результата проверки используется тот или иной CacheManager.
Осталось указать данный CacheResolver в параметрах @Cacheable:
@Override
@Cacheable(cacheNames = {"signature"},
key = "{#param, T(ru.rosbank.ThreadLocalCustom).getCustomId()}",
cacheResolver = "multipleCacheResolver")
public Set<SignatureLevel> getSignatureLevels(long userId) {
//логика
}Перед выполнением метода getSignatureLevels вызывается CacheResolver, который определяет, какой кеш использовать, и использует его.
Мы рассмотрели, как можно кастомизировать кеш с использованием CacheResolver и SimpleKeyGenerator. Теперь я вернусь к третьему пункту списка: расскажу о подходе с локальным кешированием и, главное, о том, как можно провести в нем аналогичную (похожую) кастомизацию.
Локальное кеширование
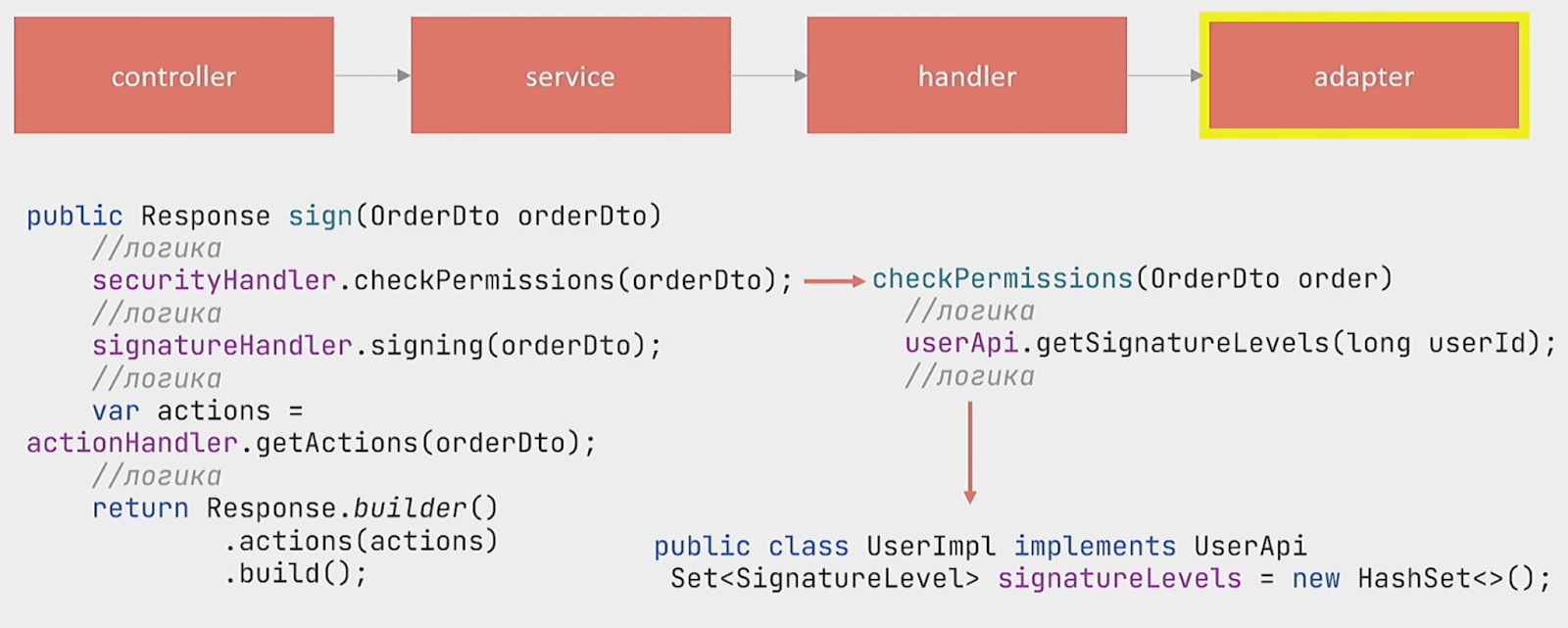
Для начала хотелось бы уточнить, что понимается под локальным кешированием. У нас есть адаптер, который непосредственно обращается к сервису. В данном адаптере имеется коллекция, которая принадлежит классу UserImpl:
public class UserImpl implements UserApi {
private final Set<SignatureLevel> signatureLevels = new HashSet<>();
...В эту коллекцию сохраняется результат запроса из сервиса USER:
public class UserImpl implements UserApi
private final Set<SignatureLevel> signatureLevels
= new HashSet<>();
private boolean isCache = false;
public Set<SignatureLevel> getSignatureLevels(long userId) {
if (!isCache) {
signatureLevels.addAll(//запрос в сервис);
isCache = true;
}
return signatureLevels;
}
@Bean
public UserApi getUserApi(){
return new UserImpl();
}Вначале мы проверяем, заполнена ли коллекция. Если нет, то идем в сервис, получаем оттуда данные, добавляем в коллекцию и возвращаем результат. Если данные есть, то сразу возвращаем их из коллекции.
Вроде всё сделано хорошо… но работать не будет. Ведь Spring создаёт бины singleton. Так что когда к нам придет следующий запрос, в коллекции signatureLevels будут данные от предыдущего запроса. Как решить эту проблему? Логично сделать бин UserImpl prototype:
public class UserImpl implements UserApi {
private final Set<SignatureLevel> signatureLevels = new HashSet<>();
...
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public UserApi getUserApi()
return new UserImpl();Но это всё равно не сработает. Вспомним, как Spring создает бины. У нас есть два бина, handler или сервис, который является singleton, и UserApi — prototype, который, в свою очередь, заинжекчен в бин singleton. При создании бина singleton будут сначала созданы все зависимые бины, а затем один раз заинжекчены. Поэтому бин UserImpl для singleton будет один и тот же.
Один из вариантов заставить всё работать — использовать @Lookup:
@Lookup
private UserApi getUserApi()
return null;Рассмотрим, как можно кастомизировать это по аналогии с кешированием. Предлагаю достаточно простой способ — с помощью пользовательской области видимости.
Пользовательская область видимости
Попробуем сделать и использовать свой кастомный Scope, для этого необходимо:
реализовать метод
Object get(String name, ObjectFactory<?> objectFactory)интерфейса Scope. Он обязателен для реализации. Все другие методы этого интерфейса опциональны.зарегистрировать новый scope:
public class CustomScope implements Scope {
@Override
public Object get(String name, ObjectFactory<?> objectFactory) {
// логика
}
...Для регистрации нового Scope необходимо реализовать интерфейс BeanFactoryPostProcessor и в методе PostProcessBeanFactory зарегистрировать новый Scope. В примере новый бин получил название CustomScope:
@Component
public class CustomBeanFactoryPostProcessor implements BeanFactoryPostProcessor
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory)
beanFactory.registerScope("customScope", new CustomScope());Рассмотрим пример реализации пользовательской области видимости. Для хранения созданных бинов будем также использовать Caffeine. Можно использовать и обычную ConcurrentHashMap, но тогда придётся реализовывать механизм удаления бинов из хранилища в зависимости от того, сколько они должны жить. При использовании Caffeine всё будет само очищаться по заданной логике, рассмотренной в предыдущем разделе. Пример реализации:
public class CustomScope implements Scope {
private final Cache<Object, Object> defaultCacheManager;
private final Cache<Object, Object> constantLifetimeCacheManager;
@Override
public Object get(String name, ObjectFactory<?> objectFactory) {
if (Long.parseLong(ThreadLocalCustom.getContext().getCustomId()) % 2 == 0) {
return defaultCacheManager.get(name + ThreadLocalCustom.getContext().getCustomId(), k -> objectFactory.getObject());
} else {
return constantLifetimeCacheManager.get(name + ThreadLocalCustom.getContext().getCustomId(), k -> objectFactory.getObject());
}
}
...В примере указано два CacheManager, с которыми мы работали. В качестве ключа для кеша используем название класса и CustomId из ThreadLocal, а значением будем непосредственно сам созданный бин.
Здесь, в отличие от предыдущего примера, для определения CacheManager’а используется CustomId, потому что параметр UserId получить достаточно сложно. Это решаемый вопрос, но в нашем случае я решил не усложнять примеры лишним кодом и использовал CustomId из ThreadLocal в качестве маски.
Осталось указать, что мы используем кастомный @Scope для UserImpl, и подсказать Spring, что надо брать новый @Bean из контекста в соответствии с нашими настройками, ведь мы имеем дело с разными scope’ами для бинов:
public class UserImpl implements UserApi
private final Set<SignatureLevel> signatureLevels = new HashSet<>();
private boolean isCache = false;
public Set<SignatureLevel> getSignatureLevels(long params) {
if (!isCache) {
signatureLevels.addAll(//запрос в сервис);
isCache = true;
}
return signatureLevels;
}
@Bean
@Scope(scopeName = "customScope", proxyMode = ScopedProxyMode.TARGET_CLASS)
public UserApi getUserApi(){
return new UserImpl();Опишем, как работает данный механизм в целом. Когда запрос попадает в handler, для определения, какой бин использовать UserImpl, будет вызван метод get класса CustomScope. Если в методе get бин находится в кеше, он будет возвращен, если его нет в кеше, то будет создан, помещен в кеш и возвращен.
И уже в возвращенном бине UserImpl будет отрабатываться логика нахождения уровней подписи SignatureLevels.
Подведем итоги
Если вы столкнулись с проблемами, описанными в начале статьи, правильное кеширование запросов сможет вам помочь в их решении. Сделать это несложно, запросы легко поддаются кастомизации, и мы можем делать разные настройки для разных задач. Также можно использовать решение на основе пользовательской области видимости, но данный подход сложнее, в нем нужно учесть ряд важных нюансов, связанных с синхронизацией.
maxzh83
Вот же отличный вариант. Вам конечно виднее, но кажется, что тут нет особого смешения техники и бизнеса. А вот нижеописанные приседания с кэшами несильно располагают к надежности. Много мест, где легко ошибиться на ровном месте. Даже в статье про это есть ("всё сделано хорошо… но работать не будет"). А помимо этого, на такой вариант труднее писать тесты (чтобы проверить именно с кэшем) и можно, например, на ровном месте поймать неочевидную ошибку, типа такой, причем уже на проде