
Представьте, что у вас есть функция random(), которая генерируют случайным образом значения в промежутке
Вычислите значение числа
Это один из популярных вопросов на собеседовании в топовую IT компанию
В первую секунду может показаться, что ваш интервьюер слегка издевается над вам, но если вспомнить основы из теории вероятности, то все становится гораздо проще. Let's go!
База из теории вероятности
Классическое определение вероятности.
Вероятность, что событие A произойдет, равно отношению количеству благоприятных исходов к количеству всех возможных исходов
На языке математики это выглядит так:
Например у нас есть кубик. Какая вероятность что выпадет грань с четными значениями?
Решение
Набор всех исходов {}
Набор благоприятных исходов {
}
Значит
Геометрическое определение вероятности.
Предыдущее определение вероятности отличное, но оно обладает несколькими существенными ограничениями. Одним из таких ограничений является тот факт, что оно неприменимо к испытаниям с бесконечным количеством исходов.
Чтобы стало понятно о чем речь - давайте решим задачку.
На отрезок случайным образом брошена точка
Найдите вероятность того, что она попадет в промежуток
Понятно, что здесь не получится использовать классическое определение, поскольку на отрезке бесконечно много точек. Тогда нам идет на помощь геометрическое определение
вероятности , в нашем случае
,
Следовательно
Решение задачи
Концепция
Построим геометрическую модель.
Введем систему координат с осями и
Расположим квадрат с единичной стороной, так чтобы начало системы координат находилось в левом углу.
Нарисуем единичный круг с центром в начале координат.

Будем случайным образом располагать точку в квадрате.
Наша исходная задача сводится к следующему вопросу.
Какая вероятность, что точка попадет в верхнюю правую четверть круга (область A)
Мы знаем, что , а
Значит вероятность того, что точка попадет в искомую область равна
С другой стороны, после распределения n точек по квадрату, мы можем оценить количество точек, которое попало внутрь круга. Для этого точка с координатами
должна удовлетворять неравенству
Тогда вероятность , где
количество точек попавших внутрь круга, а n общее число точек.
Значит из верних соотношений имеем
Программируем
import random
def estimate_pi(n):
num_point_circle = 0 #кол-во точек внутри круга
num_point_total = n
for i in range(n):
x = random.uniform(0,1)
y = random.uniform(0,1)
distance = x**2 + y**2
if distance <= 1: #определяем, что точка попала внутрь круга
num_point_circle += 1
return 4 * num_point_circle/num_point_total
n = 10000000 #общее количество точек (чем больше точек, тем лучше точность)
pi = estimate_pi(n)
print(pi)На этом все!
Надеюсь вам понравилась задача! Делитесь своими интересными задачками с собеседований, будем разбирать)
Связаться со мной @polozovs
Комментарии (33)

Markscheider
29.10.2022 21:35+5Элегантно и просто. Спасибо.
Единственное что -- вместо
круг с центром в начале координат едичного радиуса
привычнее читать "единичная окружность".


cax
29.10.2022 21:38+23Если мне не изменяет память, этот метод называется "метод Монте-Карло" ?

Source
30.10.2022 00:48+11Я удивился, что в статье его не назвали. Это имхо и есть ответ на вопрос из собеседования: "Надо применить метод Монте-Карло", дальше всё довольно очевидно.
Сомневаюсь, что кто-то не зная о нём, сможет прямо на собеседовании его придумать.


panteleymonov
30.10.2022 00:51+1Плохо соображаю на ночь глядя, но в целях оптимизации подумалось - если взять вместо круга сферу, то вероятность от трехмерной точки будет Пи/6. И таким образом увеличится вызов генератора случайного числа на одну итерацию до трех. Можно ли пойти в обратном направлении и уменьшить его до одного?

thevlad
30.10.2022 01:17+5Там надо не количество вызовов рандома оптимизировать, а сходимость у данного метода, которая достаточно паршивая и пропорциональна sqrt(n).

Ninil
30.10.2022 01:47+20Хмм... Уровень статей на Хабре непрерывно падает... мы этот метод разбирали в кружке информатики, когда я был в 6 классе. Метод Монте-Карло называется, причём первая же ссылка в поисковике(у меня по крайней мере) — на статю на хабре https://habr.com/ru/post/128454
Ждём статей с программами вида «Звездное небо» и «вычисление факториала» %)))
Source
30.10.2022 03:48+4причём первая же ссылка в поисковике(у меня по крайней мере) — на статю на хабре
которую справедливо заминусовали за бессодержательность и округления)
Да, 11 лет назад Хабр был более требователен к качеству материала.

ne555
30.10.2022 09:48+1Да, 11 лет назад Хабр был более требователен к качеству материала.
Такие высказывания встречаются нередко в комментах, типо: "статьи на Хабре раньше были лучше". Не соглашусь. Иногда в поисковике попадаются ссылки на статьи 10-летней давности и качество там "стыд 2010". Пример.
Source
30.10.2022 12:58Не соглашусь. Иногда ..
Ключевое слово "иногда"
ne555
30.10.2022 13:20+1Да, иногда, но рандомно поманипулировал с url-Хабра рядом с 2010г., получаю низкосортные заметки, а не статьи технического уровня:
-
https://habr.com/ru/company/asus/blog/109641/
Какие либо торты я не встречал в прошлом.
Source
30.10.2022 13:50А вы по какой логике их отбираете? Из 4 статей, только одна с рейтингом больше 20. И то в дисклеймере честно написано, что это комментарий выделенный в статью. Значит на тот момент на это был запрос, т.к. лицензии Creative Commons были не столь известны, как сейчас.
Вы сравнивайте как сообщество реагирует на схожие статьи, а надёргать из поисковика то, что и в ленты то в своё время не попадало, всегда можно.
P.S. А статьи из хабов "Блог компании X" вообще редко отличаются качеством, но они тут в качестве рекламы.
ne555
30.10.2022 14:28А вы по какой логике их отбираете?
рандомно поманипулировал с url-Хабра рядом с 2010г.
т.е. я даже не пытался выбрать что-то самое level уровня: 10 предложений.
от момент на это был запрос, т.к. лицензии Creative Commons
Там даже не постеснялись метку поставить "tutorial".
"Блог компании X" вообще редко отличаются качеством, но они тут в качестве рекламы.
Не хочу более спорить, но в некоторых корп.блогах пишут технически подкованные авторы, которые умеют и понимают (они также бы могли выдавать контент на высоком уровне и без рекламы, но их нашли и привлекли, контент не пострадал).
А вывод я озвучил в своём первом комментарии в этой ветке. Ищите качественный контент, не стоит ограничиваться Хабром. Браузер с переводчиком, поиск по сайту и Nature; Science или Гугловская Академия. Там не так всё скверно с материалом прошлой эпохи. И пожалуй близкий к Хабру сайт — Slashdot.

andrejjm78
01.11.2022 17:15А почему бы и нет. Лет 15 назад столкнулся с тем, что отсутствует толковое решение для комбинаторного расчета. Надо было найти число сочетаний из n объектов по k, причем точно. EXEL2003 вообще иногда выдавал дробные числа.
С(7;1913)=18399302838933135756.


longclaps
30.10.2022 07:01+17У статьи два тэга: Python и Математика. Это прекрасно.
Начнем с питона, перепишем авторское решение, сохранив его идею:
from random import random def estimate_pi(n): s = 0. for _ in range(n): x, y = random(), random() if 1. >= x * x + y * y: s += 4. return s / nХм, в CPython 3.10 это работает в 3.5 раза быстрее. Как же так, дружище? Как же тэг Python?
Ладно, что там с математикой? Про сходимость тут уже высказались, хорошо бы немного практики, чтобы цифры пощупать. Считаем по-всякому площадь сектора OAC.
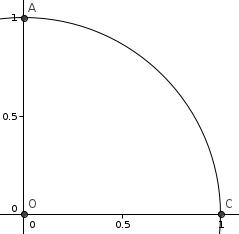
Я умею интегрировать трапециями!
from math import sqrt def trapezoid_pi(n): s = .5 # значения в крайних точках интервала # берутся с весом 0.5, а значения эти - 1 и 0 x = step = 1. / n for _ in range(n - 1): s += sqrt(1. - x * x) x += step return s * 4. / nЯ могу интегрировать по Симпсону!
from math import fsum def simpson_pi(n): x, step, res = 0, 1. / n, [.5] for _ in range(n): x += step res.append(sqrt(1. - x * x)) return (fsum(res[::2]) + fsum(res[1::2]) * 2.) * 8. / (n * 3)Правда, это даёт выигрыш в точности против трапеции всего 2.5 раза. Всё из-за особенности в точке C - там касательная к окружности идёт отвесно. Так это можно обойти: отдельно посчитаем площадь сегмента AB и четырехугольника OABC.
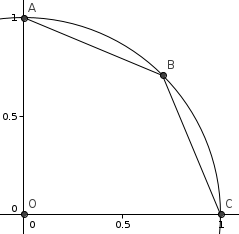
from math import fsum, sqrt def simpson45_pi(n): x, step, res, s5 = 0., 1. / n, [.0], sqrt(.5) for _ in range(n): x += step res.append(sqrt(1. - x * x * .5) - 1. + (1. - s5) * x) AB = (fsum(res[::2]) + fsum(res[1::2]) * 2.) * s5 * 2. / (n * 3) OABC = s5 # взял аналитически return (OABC + AB * 2.) * 4.Да, а как же цифры? Вот они:
Абсолютная погрешность против библиотечного значения π для n = 2 ** 3 == 8 (разбиение интервала на степень двойки дает мне выигрыш в точности) estimate_pi 0.47564011559266456 # усредненно по большой выборке trapezoid_pi 0.05177350923261992 simpson_pi 0.02040348381437518 simpson45_pi 0.00003003695260295 Погрешность для n = 2 ** 13, мельчить сильнее вроде незачем estimate_pi 0.01486375361227077 # усредненно trapezoid_pi 0.00000158604010281 simpson_pi 0.00000061939277884 simpson45_pi 0.00000000000000000Ну что тут скажешь? Друзья, не суйте Монте-Карло куда попало.
А можно еще и с NumPy, но уж это как-нибудь в другой раз.
panteleymonov
30.10.2022 12:09+9А где генератор случайного числа? С таким же успехом можно арксинус от единицы на два умножить.

demoth
30.10.2022 14:09+1Ну раз питон-питон, то тогда так :)
def estimate_pi(n: int) -> float: return sum(4 for _ in range(n) if (x := random()) * x + (y := random()) * y < 1) / n

9982th
01.11.2022 17:15Львиную долю ускорения в вашем варианте дает замена random.uniform на random.random, из вызова которого первый, собственно, и состоит, убирая лишний вызов функции. На втором месте замена возведения в степень на умножение, эффект от которой не столь впечатляющий, но хорошо заметный.
Не могли бы вы пояснить смысл остальных оптимизаций, в частности, замены int на float и инкремента на 4 вместо 1 в счетчике?



MUTbKA98
30.10.2022 08:19+2Я вижу по коду, что на самом деле разрешается не только RNG, но и сложения, умножения, возведения в степень. Не проще ли тогда сразу взять и вычислить ряд, например, а на RNG забить? Так и быстрее, и точнее.

Newm
30.10.2022 08:37Кстати задача довольно интересная... Для проверки качества функции псевдослучайных чисел.
Когда я запускал такую программку почти 40 лет назад на агате, точность оказалась так себе...
ne555
30.10.2022 09:29-6Например у нас есть кубик. Какая вероятность что выпадет грань с четными значениями? 1/2
Набор всех исходов 6
А вот и нет, решение неверное. В задаче называется "кубик", у кубика есть не только грани (6), но и рёбра (12) и их вершины (8). И какова же вероятность, что кубик выпадет не на чёт.числе/грани, а на вершине или ребре? явно не 1/2, более того кубик на практике реально иногда встает не на грань.
На отрезок
![[0;1]](https://habrastorage.org/getpro/habr/upload_files/97a/01f/abd/97a01fabd885fd29d0464e36ea49161d.svg) .
.на отрезке бесконечно много точек
Тоже не верно, отрезок конечный и точек у него также конечное число, зависит от шага.

SilverHorse
01.11.2022 00:13+1И какова же вероятность, что кубик выпадет не на чёт.числе/грани, а на вершине или ребре?
Ноль. С математическими абстракциями вы не знакомы, похоже...
Тоже не верно, отрезок конечный
...как и с теорией множеств и определениями конечного множества и отрезка...


chelaxe
30.10.2022 13:22
P=lambda n:sum([(1-(1/n/2+i/n)**2)**.5/n for i in range(0,n)])*4 P(1_000_000)


Naf2000
30.10.2022 20:51+3Метод Монте-Карло именно на примере числа пи описан в школьном учебнике информатике (Кушниренко и другие) издательство 1989 года. Этому детей учили

ilia_bonn
01.11.2022 17:14У меня метод монте карло ни в школе не проходили (13 классов гимназии в Германии), ни в институте по статистике при обучении на бакалавра по психологии (статистика была как предмет из блока методологии в первых двух семестрах по 4 академических часа в неделю в каждом).

Batyr1992
01.11.2022 17:15Статья довольно баянистая, хотя мне данная иллюстрация нравится) мне кажется стоило добавить оценку погрешности , обычно такое рассматривается в численных методах
middle
Испокон веков для подсчёта числа пи использовали иголку.
apolozov Автор
Почитал, очень интересно и необычно)