

Безусловно, способы защиты данных от потери определяются как объемом информации, так и самим устройством, на котором они хранятся. И то, и другое постоянно эволюционирует.
Поэтому давно ведутся споры между сторонниками традиционного подхода к резервному копированию и теми, кто ищет новые способы защиты данных, более удобные с точки зрения архитектуры используемых систем хранения. Сейчас этот спор обострился, поскольку в последнее время резко выросло разнообразие типов систем хранения. Использование некоторых из них требует менять подходы к привычным задачам эксплуатации и обеспечению доступности, включая резервное копирование, о котором я хочу здесь поговорить.
Традиционный подход заключается даже не в сохранении резервной копии на ленту. Речь идет о наличии резервной копии в системе хранения, предназначенной специально для бэкапа. Будь то дисковая СРК, или ленточная — без разницы. Этот традиционный подход подразумевает, что есть продуктивная система, хранящая самые актуальные производственные данные, и есть система, куда регулярно сохраняются копии этих данных. В частности, EMC предлагает для этого СХД Data Domain.
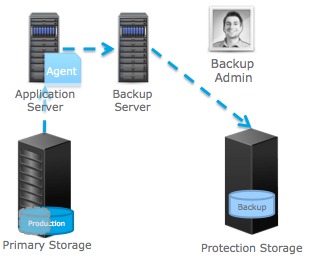
Схема традиционного бэкапа.
Также обычно применяется сервер резервного копирования, централизованно управляющий этим процессом. Он же осуществляет и восстановление информации, если исходные данные были повреждены или потеряны. В этом сегменте хорошо себя зарекомендовал программный продукт Networker. Это проверенный временем инструмент защиты данных, удовлетворяющий массе регулирующих законов. А благодаря наличию программных клиентов для приложений, Networker идеально интегрируется с ними, за что многими заслуженно любим.
В противовес традиционному подходу ставится репликация данных средствами систем хранения. В этом случае продуктивные данные реплицировались (зеркалировались) на ту же, а лучше на другую систему хранения. Для создания множества точек восстановления, с этого зеркала регулярно создаются «снэпшоты», которых может быть до нескольких сотен. Благодаря своему удобству, этот подход постепенно завоевывал популярность на протяжении последних лет. Чаще всего его выбирали:
- администраторы систем производства NetApp, в которых снэпшоты глубоко зашиты в архитектуру,
- те, кто не особо обращал внимание на регулирующее законодательство про отчуждаемые носители,
- и те, кого не волновала идеальная интеграция с приложениями.
В общем, борьба между этими двумя подходами хоть и шла, но без особого накала. На мой взгляд, причина в том, что эти два мира мало пересекаются. Мои размышления на эту тему, кстати, есть тут: http://denserov.com/2013/01/30/bu-vs-rep/.
Я считаю, что мир резервного копирования начал принципиально меняться, когда появились системы хранения новых типов, которые стали быстро набирать вес.
В контексте меняющегося подхода к резервному копированию я вижу три основных новых типа СХД.
- Гибридные СХД с применением двух- и трехуровневого хранения (SSD/SAS/NL-SAS). Такие системы как VNX, VMAX и их аналоги.
- Сверхмасштабируемые СХД (massive scale-out) Isilon, ScaleIO, Elastic Cloud Storage и их аналоги.
- Системы с дедупликацией продуктивных данных. Например, XtremIO. В некоторых случаях — VNX.
Возможно, многие давно заметили, что эти три типа СХД нуждаются в особом подходе к резервному копированию. Ниже я изложу соображения по резервному копированию для гибридных систем, как для самых распространенных, а в будущих публикациях рассмотрю оставшиеся два типа.
Бэкап
В настоящее время это самые распространенные СХД в корпоративном сегменте. Архитектуры большинства из них стали результатом развития традиционных систем хранения, которые, как правило, комбинировались с традиционными же средствами бэкапа (EMC Networker и его аналоги). Традиционные СХД мутировали в гибридные, а подход к бэкапу во многом остался прежним. В чем же заключается проблема с бэкапами в этих системах, если там всё традиционно?

Типичная гибридная СХД содержит быстрые, средние и медленные носители.
Кто-то уже догадался, что проблема кроется в самом нижнем уровне хранения, куда «съезжают» самые «холодные» данные. Этот уровень, для экономии, порой составляют из весьма небольшого количества дисков большого объема (NL-SAS, 7200 rpm, от 1 до 6 ТБ).
Никогда, никогда, никогда не используйте в гибридных системах для автоматического многоуровневого хранения диски NL-SAS объемом больше 2ТБ! Не поддавайтесь искушению. И вот почему.
Будет ошибкой считать, что если вы спроектировали систему по емкости и производительности, то с бэкапом все утрясется как-нибудь само.
Проектируя трехуровневые системы, нужно помнить, что с нижнего уровня данные тоже иногда надо быстро поднимать для различных задач — от резервного копирования до формирования отчетности.
С печальной регулярностью приходится сталкиваться с проектированием гибридных СХД под базы данных объемом сотни ТБ. Иногда даже делают базы MS SQL такого объема, складывая в БД электронные документы. При этом никто не считает, сколько времени займет резервное копирование, и в ТЗ прописывают многоуровневое хранение с нижним уровнем на 6ТБ дисках. Иногда даже 5400 rpm, чтобы было дешевле.
Рассмотрим, небольшую гибридную систему с не самым плохим набором дисков:
- 16 дисков 200ГБ SSD в RAID 5(7+1)
- 32 дисков 600ГБ 15000 rpm в RAID 1
- 8 дисков 2000ГБ 7200 rpm в RAID6 (6+2)
Десятичная емкость (с учетом RAID):
- SSD — 2800 ГБ
- SAS 15000 rpm — 9600 ГБ
- NL-SAS 7200 rpm — 24000 ГБ
ИТОГО 36 400 ГБ.
Сырая производительность:
- SSD 16 * 3500 = 80000 IOPS
- SAS 15000 rpm 32 * 180 = 5760 IOPS
- NL-SAS 7200 rpm 8 * 80 = 640 IOPS
ИТОГО 86 400 IOPS.
Объем и производительность такой системы всего на 56 дисках получились впечатляющие. Сейчас это все можно уместить в 1 дисковую полку на 60 дисков. В худшем случае — 4 полки по 15 дисков.
Аналогичная «плоская» система, без применения технологий «Auto-Tiering», состояла бы из 480 дисков 15000 rpm, потребляла бы в разы больше электричества и занимала бы в разы больше места. Экономический выигрыш «гибридного» подхода очевиден.
Мы здесь допускаем, конечно, что дизайн этой системы по профилю рабочей нагрузки был выбран правильный, и горячие и холодные данные «разлеглись» на ней корректно (хотя решение этой увлекательной задачи — тема отдельной и очень интересной статьи).
Сейчас я бы хотел рассмотреть именно то, как будет происходить бэкап такой «успешно спроектированной» гибридной системы. Предположим, что используется традиционное резервное копирование. Т.е. полный бэкап в пятницу вечером, и затем серия инкрементальных. И так каждую неделю.
Посчитаем в нулевом приближении, сколько времени займет полный бэкап 36 ТБ с гибридной системы в отсутствии продуктивной нагрузки.

Расчет сделан исходя из предположения, что в процессе резервного копирования нет других узких мест, и ни контроллеры СХД, ни целевая система резервного копирования не мешают дискам отдавать данные для бэкапа.
Из иллюстрации мы видим, что нижний уровень хранения «съел» 94% времени бэкапа и занял 7 дней. Это неприемлемо. По сути, это следствие применения многоуровневого хранения. Быстродействие приложения определяется скоростью верхнего уровня и его объемом. А скорость резервного копирования (и восстановления!) — скоростью нижнего уровня и его объемом. Значит ли это, что гибридные системы мало приспособлены к реальной жизни? Кто-то скажет «да». Но уж очень значительные выгоды дает их применение с точки зрения эффективности хранения. Поэтому, надо просто переосмыслить правила их эксплуатации и следовать здравому смыслу.
Я вижу следующие варианты решений (или их комбинацию) для гибридных систем:
Первое. Отказаться от полных бэкапов больших объемов данных. Перейти к синтетическим полным бэкапам, распределять бэкапы во времени. Т.е. уменьшать объем передаваемых данных в заданный интервал времени. Преимущество этого варианта — условная дешевизна.
Большой недостаток — время полного восстановления. Здесь уже не имеет значения, синтетический был бэкап или нет. Придется заливать данные полностью даже на нижний уровень. Это прибавит к суточной потере данных еще и около недели простоя.
Второе. Стараться делать нижний уровень не таким медленным. Ведь можно его составить из дисков по 1 Тб, которые по цене за Гб находятся примерно в той же ценовой категории, что и 2 Тб. Можно заложить дополнительные шпиндели в нижний уровень хранения именно с целью обеспечения приемлемого времени бэкапа. Об этом нужно думать заранее. Т.е. увеличивать как скорость «отдачи» данных для бэкапа, так и планировать скорость потенциального восстановления.
Это чуть дороже, чем первый вариант, но может быть в разы быстрее. Первый и второй варианты можно свободно комбинировать.
Третье. Избегать 100%-утилизации третьего уровня хранения для многоуровневых томов. Ведь он может быть заполнен «боевыми» данными не на 100%, а на 15-20%, а остальные 80% отводятся, например, под архивные данные, которые можно реже бэкапить. В этом заключается принципиальная разница между архивными и оперативными данными. Для кого-то, может быть, до сих пор странно звучит, но архив и бэкап — это принципиально разные вещи. Архив — это долговременное хранилище неизменных данных, которые туда перемещаются из оперативного хранилища. А бэкап — это регулярно создаваемая копия оперативных данных для возможного восстановления. Другими словами, архив это операция move, а бэкап — copy. Подробнее про архивирование можно почитать на сайте EMC.

Комбинация архива и бэкапа.
Четвертое. Если все вышеперечисленное не позволяет кардинально улучшить ситуацию, то, может быть, стоит пересмотреть принципиальный подход к бэкапу. Уже давно существуют системы резервного копирования с дедупликацией данных на источнике, например, Avamar или Vmware Data Protection Advanced. Эта технология весьма эффективно сокращает объем передаваемых данных между клиентом и сервером резервного копирования. Еще одна альтернатива — непрерывная репликация данных со снэпшотами на другую систему хранения. Например, при помощи RecoverPoint.
Как видите, при проектировании гибридных СХД надо учитывать контекст резервного копирования. Даже когда хранение и бэкап — это разные проекты.
Восстановление
Представим теперь, что у нас есть система с автоматизированным многоуровневым хранением и мы успешно делаем с нее бэкапы. Кроме того, в процессе проектирования у нас учтена скорость восстановления, и с этим тоже серьезных вопросов не возникает.
Приложение работает на гибридной системе хранения, производительность достаточная. Однако, вспомним, что в современных окружениях большая часть нагрузки приходится лишь на небольшой объем данных.
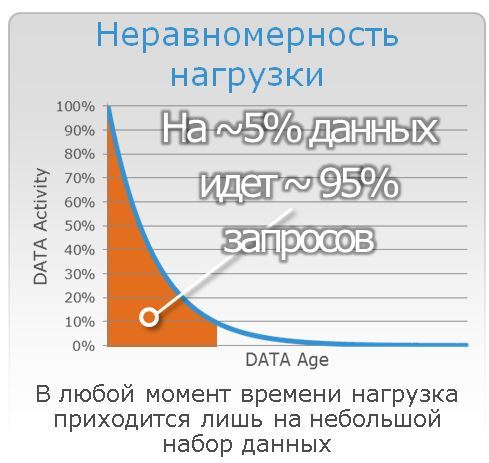
Возникает вопрос: с какой скоростью будет работать приложение после успешного восстановления из бэкапа, сделанного полдня назад? Никто не гарантирует, что при восстановлении с СРК блоки данных обязательно разлягутся по носителям в точном соответствии с их «температурой» перед сбоем. Если учесть, что самые-пресамые «горячие» данные находятся не в кэше СХД, а в оперативной памяти серверов БД и приложений, которые при восстановлении данных из бэкапа тоже должны «разогревать» с нуля всю свою память, то нагрузка на дисковую систему будет еще выше, чем обычно. Ситуация не из приятных.
Поскольку гибридные СХД кое-где стали почти стандартным подходом к решению задач хранения, то вопрос о потенциальном восстановлении после сбоя, я думаю, не раз возникал и возникнет перед администраторами в процессе эксплуатации.
Если с бэкапом люди сталкиваются повседневно, то до полномасштабного восстановления дело доходит, я думаю, в сотни раз реже. Поэтому, когда на практике сталкиваются с рассматриваемым здесь сценарием, это оказывается неприятным, но вполне предсказуемым событием. Возможно, стоит его заранее предвидеть и учитывать?
Но поскольку при проектировании бэкапов речь всё-таки идет о копировании/восстановлении данных, а не гарантированной производительности после восстановления, то эта тема чаще всего остается где-то на границе внимания архитекторов. Да и непонятно, из какого бюджета этот проект финансировать. Бэкап или СХД? Возможно, именно поэтому я до сих пор не встречал четких и ясных рекомендаций на этот счет при планировании архитектуры. Видимо, многие считают, что при восстановлении главное — именно восстановиться. А дальнейшее — это мелкие нюансы.
Тут нужно заметить, что известны случаи, когда успешное восстановление данных из бэкапа не позволяло произвести успешный пуск приложения. Сотни и тысячи пользователей буквально «ломились» на «непрогретую» систему хранения, успешно ее заваливая, вводя сервер приложения в кому, и иногда даже повреждая тем самым данные. Подобные ситуации возникают даже на обычных системах хранения, не говоря уже о гибридных.

Поэтому нужно помнить, что восстановление из полного бэкапа — это средство последней надежды. И если уж к нему прибегать, то не стоит ожидать моментального выхода приложений на полную мощность. К тому же, в большинстве случаев всё равно придется решать организационные вопросы, связанные с откатом данных на некоторое время назад. Но это не снимает с повестки вопрос технического обеспечения.
Решение проблемы
Что я могу посоветовать для решения это проблемы, характерной для всех дисковых систем, в том числе и гибридных?
Первое: учитывайте возможности разогрева системы хранения. Алгоритмы одних гибридных СХД используют Flash в качестве расширения кэш-памяти, и могут реагировать на потребности приложений за минуты, а другим нужно не менее трех суток, чтобы после восстановления из бэкапа «поднять» данные с медленных дисков на быстрые. Так что, если гибридная система не очень быстро реагирует, то важно не переусердствовать с медленными дисками. Они могут существенно ограничивать способность системы «разогреться» под нагрузкой.
Второе: резервное копирование на внешнюю СРК это всегда средство последней надежды, «План Б», когда ничто другое уже не сработало (см. в другой статье). Поэтому, чтобы минимизировать неопределенность в быстродействии приложения после восстановления данных, я бы использовал средства оперативного восстановления, которые позволяют восстанавливать данные более «точечно», «поблочно».
Речь идет как о репликации на уровне СХД (клоны, снэпшоты), так и о репликации на уровне приложения (Data Guard и т.п.). Такой подход минимизирует не только время восстановления и потери данных, но и сбережет нервы администраторов с точки зрения более предсказуемой производительности после восстановления. То есть, лучше всего комбинировать бэкап на внешние устройства с репликацией данных, отдавая себе отчет, для чего они предназначены.
Третье: если первые два положения учтены, но хочется большего, то можно использовать две гибридные системы, работающие в синхронной, устойчивой к авариям кластерной паре, которая обеспечивает не только хранение одинаковых экземпляров данных, но и полностью идентичное размещение этих данных на уровнях хранения. Даже если одна из систем хранения будет целиком выведена из строя, то потеря данных или остановка приложения не произойдут, а после восстановления сбойной системы кластер может синхронизировать данные и их размещение по уровням на обеих системах.
В целом, я разделяю мнение, что хорошее резервное копирование должно быть интегрировано не только с уровнем приложения, но и с продуктивной системой хранения, и уметь как бэкапить, так и восстанавливать отдельные блоки данных аналогично снэпшотам. И похоже, что примерно такая тенденция отмечается в данный момент на рынке резервного копирования.
В этих рассуждениях я намеренно придерживался только защиты и восстановления гибридных СХД. Вопрос о флэш-системах будет обсуждаться в одной из следующих статей. Stay tuned!
Денис Серов