

Развивая тему бэкапа и восстановления на СХД с новой архитектурой, рассмотрим нюансы работы с дедуплицированными данными в сценарии disaster recovery, где защищаются СХД с собственной дедупликацией, а именно, как эта технология эффективного хранения может помочь или помешать восстанавливать данные.
Предыдущая статья находится здесь: Подводные камни резервного копирования в гибридных системах хранения.
Введение
Раз дедуплицированные данные занимают меньше места на дисках, то логично предположить, что резервное копирование и восстановление должны занимать меньше времени. Действительно, почему бы не бэкапить/восстанавливать дедуплицированные данные сразу же в компактном дедуплицированном виде? Ведь в этом случае:
- В бэкап помещаются только уникальные данные.
- Не надо редуплицировать (регидрировать) данные на продуктивной системе.
- Не надо обратно дедуплицировать данные на СРК.
- И наоборот, восстановить можно лишь те уникальные данные, которые необходимы для реконструкции. Ничего лишнего.
Но если рассмотреть ситуацию внимательнее, то оказывается, что не всё так просто, прямой путь не всегда более эффективен. Хотя бы потому, что в СХД общего назначения и СХД резервного копирования используется разная дедупликация.
Дедупликация в СХД общего назначения
Дедупликация, как метод исключения избыточных данных и повышения эффективности хранения, была и остаётся одним из ключевых направлений развития в индустрии СХД.

Принцип дедупликации.
В случае с продуктивными данными, дедупликация предназначена не только и не столько для уменьшения места на дисках, сколько для повышения скорости доступа к данным за счёт их более плотного размещения на быстрых носителях. Кроме того, дедуплицированные данные удобны для кэширования.
Один дедуплицированный блок в кэш-памяти, на верхнем уровне многоуровневого хранения, или просто размещённый на флэше, может соответствовать десяткам или даже сотням идентичных пользовательских блоков данных, которые раньше занимали место на физических дисках и имели совершенно разные адреса, а потому не могли быть эффективно кэшированы.
Сегодня дедупликация на СХД общего назначения бывает очень эффективна и выгодна. Например:
- На флэш-системы (All-Flash Array) можно положить существенно больше логических данных, чем обычно позволяет их «сырая» ёмкость.
- При использовании гибридных систем дедупликация помогает выделить «горячие» блоки данных, поскольку при этом сохраняются лишь уникальные данные. И чем выше дедупликация, тем больше обращений к одним и тем же блокам, а значит — выше эффективность многоуровневого хранения.

Эффективность решения задачи хранения при помощи сочетания дедупликации и тиеринга. В каждом варианте достигается равная производительность и ёмкость.
Дедупликация в СХД резервного копирования
Изначально дедупликация получила широкое распространение именно в этих системах. Благодаря тому, что однотипные блоки данных копируются на СРК десятки, а то и сотни раз, то за счёт исключения избыточности можно достичь существенной экономии места. В своё время это стало причиной «наступления» на ленточные системы дисковых библиотек для резервного копирования с дедупликацией. Диск сильно потеснил ленты, потому что стоимость хранения резервных копий на дисках стала очень конкурентоспособной.
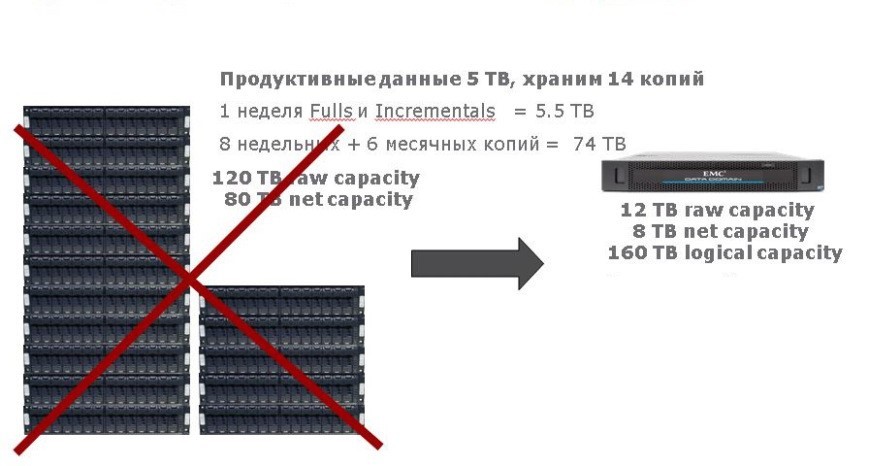
Преимущество дедуплицированного бэкапа на диски.
В итоге, даже такие приверженцы лент, как Quantum, стали развивать у себя дисковые библиотеки с дедупликацией.
Какая дедупликация лучше?
Таким образом, в мире хранения в настоящий момент есть, два разных способа дедупликации – в резервном копировании и в системах общего назначения. Технологии в них используются разные — с переменным и фиксированным блоком соответственно.

Различие двух методов дедупликации.
Дедупликация с фиксированным блоком проще в реализации. Она хорошо подходит для данных, к которым нужен регулярный доступ, поэтому чаще используется в СХД общего назначения. Её главным минусом является меньшая способность к распознаванию одинаковых последовательностей данных в общем потоке. То есть два одинаковых потока с небольшим смещением будут восприняты как совершенно разные, и не будут дедуплицированы.
Дедупликация с переменным блоком может лучше распознавать повторы в потоке данных, но для этого ей требуется больше ресурсов процессора. К тому же, она малопригодна для предоставления блочного или многопоточного доступа к данным. Это связано со структурой хранения дедуплицированной информации: если говорить упрощённо, то она тоже хранится переменными блоками.
Со своими задачами оба метода помогают отлично справляться, но с несвойственными задачами всё обстоит куда хуже.
Давайте рассмотрим ситуацию, возникающую на стыке взаимодействия этих двух технологий.
Проблемы резервного копирования дедуплицированных данных
Разница между обоими подходами в отсутствие их координированного взаимодействия приводит к тому, что если с системы хранения, которая хранит уже дедуплицированные данные, осуществлять резервное копирование с дедупликацией, то данные каждый раз «редуплицируются», а потом дедуплицируются обратно в процессе сохранения их на систему резервного копирования.
Например, физически хранится 10 Тб продуктивных дедуплицированных данных с суммарным коэффициентом 5:1. Тогда в процессе резервного копирования происходит следующее:
- Копируется не 10, а полностью 50 Тб.
- Продуктивной системе, в которой хранятся исходные данные, придется выполнить работу по регидрации («редупликации») данных в обратную сторону. В то же время она должна обеспечивать работу продуктивных приложений и поток данных резервного копирования. То есть три одновременных тяжёлых процесса, нагружающих системные шины ввода-вывода, кэш-память и процессорные ядра обеих систем хранения.
- Целевой системе резервного копирования придётся обратно дедуплицировать данные.
С точки зрения использования процессорных ресурсов — это можно сравнить с одновременным нажатием на газ и тормоз. Возникает вопрос — можно ли это как-то оптимизировать?
Проблема восстановления дедуплицированных данных
При восстановлении данных на тома с включённой дедупликацией придётся весь процесс повторить в обратную сторону. Далеко не во всех системах хранения данный процесс работает «на лету», а во многих решениях используется принцип «post process». То есть данные сначала записываются на физические диски (пусть даже на флэш) как есть, потом анализируются, сравниваются блоки данных, выявляются дубликаты, и только потом производится очистка.

Сравнение In-line и Post-Process Dedupe.
Это значит, что в системе хранения при первом проходе может потенциально не хватить места для полного восстановления всех недедуплицированных данных. И тогда придётся делать восстановление в несколько проходов, на каждый из которых может уйти немало времени, складывающегося из времени восстановления и времени дедупликации с освобождением места на СХД общего назначения.
Этот возможный сценарий относится не столько к восстановлению данных из бэкапа (Data recovery), минимизирующего риски класса Data loss, сколько к восстановлению после катастрофически большой потери данных (которая классифицируется как катастрофа, т.е. Disaster). Однако такой Disaster Recovery мягко говоря не оптимален.
Кроме того, при катастрофическом сбое совсем не обязательно восстанавливать все данные сразу. Достаточно начать лишь с самых необходимых.
В итоге, бэкап, который призван быть средством последней надежды, к которому обращаются, когда уже ничто другое не сработало, работает не оптимально в случае с дедуплицирующими СХД общего назначения.
Зачем тогда вообще нужен бэкап, из которого в случае катастрофы можно восстановиться лишь с огромным трудом, и почти наверняка не полностью? Ведь существуют встроенные в продуктивную систему хранения средства репликации (зеркалирование, снэпшоты), которые не оказывают существенного влияния на производительность (например, VNX Snapshots, XtremIO Snapshots). Ответ на этот вопрос будет всё тот же. Однако, любой нормальный инженер попытался бы эту ситуацию как-то оптимизировать и улучшить.
Как совместить два мира?
Старая организация работы с данными при бэкапе и восстановлении выглядит, по меньшей мере, странно. Поэтому предпринималось немало попыток оптимизации бэкапа и восстановления дедуплицированных данных, и ряд проблем удалось решить.
Вот лишь несколько примеров:
- Windows 2012 Deduplication with Networker
- Windows Server 2012 Deduplication and Backup Exec
- Backup and Restore Considerations for Deduplicated Volumes
- Backup and Restore of Data Deduplication-Enabled Volumes
Но это всего лишь «заплатки» на уровне операционных систем и отдельных изолированных серверов. Они не решают задач на общем аппаратном уровне в СХД, где это действительно сложно сделать.
Дело в том, что в СХД общего назначения и в системах резервного копирования используются разные, специально разработанные алгоритмы дедупликации — с фиксированным и переменным блоками.
С другой стороны, далеко не всегда требуется делать полное резервное копирование, и значительно реже — полное восстановление. Совсем не обязательно подвергать дедупликации и сжатию все продуктивные данные. Тем не менее, нужно помнить о нюансах. Потому, что катастрофические потери данных никто не отменял. И для их предотвращения разработаны стандартные промышленные решения, которые должны быть предусмотрены по регламенту. Так что если восстановить данные из бэкапа за нормальное время не удаётся, то ответственным людям это может стоить карьеры.

Давайте рассмотрим, как наилучшим образом подготовиться к подобной ситуации и избежать неприятных сюрпризов.
Резервное копирование
- Используйте по возможности инкрементальный бэкап и синтетические полные (synthetic full) копии. В Networker, например, эта возможность есть, начиная с версии 8.
- Закладывайте больше времени на полный бэкап, учитывая необходимость регидрации данных. Выбирайте время минимальной утилизации процессоров системы. В ходе бэкапов лучше понаблюдать за утилизацией процессоров продуктивной СХД. Лучше, чтобы она не превышала 70% хотя бы в среднем за период бэкапа.
- Осмысленно применяйте дедупликацию. Если данные не дедуплицируются и не жмутся, то зачем тратить процессорную мощность в ходе бэкапа? Если же система дедуплицирует всегда, то она должна быть достаточно мощной, чтобы справиться со всей работой.
- Принимайте во внимание процессорную мощность, выделенную для дедупликации в СХД. Эта функция встречается даже в системах начального уровня, которые не всегда справляются с одновременным выполнением всех задач.
Полное восстановление данных, Disaster Recovery
- Подготовьте вменяемый Disaster Recovery или Business Continuity Plan, учитывающий поведение систем хранения с дедупликацией. Многие вендоры, включая EMC, а так же системные интеграторы, предлагают услуги подобного планирования, потому что в каждой организации есть своя уникальная комбинация факторов, влияющих на процесс восстановления работы приложений
- Если СХД общего назначения использует механизм дедупликации post-process, то я бы рекомендовал предусмотреть в ней буфер свободной ёмкости, на случай восстановления из бэкапа. Например, размер буфера можно принять как 20% от логической ёмкости дедуплицированных данных. Старайтесь хотя бы в среднем поддерживать этот параметр.
- Ищите возможности архивировать старые данные, чтобы они не мешали быстрому восстановлению. Даже если дедупликация хороша и эффективна, не дожидайтесь сбоя, после которого придётся восстанавливать из бэкапа и полностью дедуплицировать тома во много десятков Тб. Все неоперативные/исторические данные лучше перенести в онлайновый архив (например, на основе Infoarchive).
- Дедупликация данных «на лету» в СХД общего назначения имеет преимущество перед post-process с точки зрения скорости. Она может сыграть особое значение при восстановлении после катастрофической потери.
Таковы мои некоторые соображения относительно резервного копирования и восстановления дедуплицированных данных. Буду рад услышать здесь ваши отзывы и мнения по этому вопросу.
И, надо сказать, что здесь ещё не затронут один интересный частный случай, требующий отдельного рассмотрения. Так что продолжение следует.
Денис Серов