

Изучение проблемы с производительностью и поиск путей решения знакомы многим не понаслышке. Существует большое количество инструментов визуализации и парсинга статистики ввода-вывода. В настоящее время набирает обороты автоматизация интеллектуального анализа на базе интернет-сервисов.
В этом посте я хочу поделиться примером анализа проблемы с производительностью СХД на базе одного из таких сервисов (Mitrend) и предложу пути ее решения. На мой взгляд, этот пример представляет собой интересный этюд, который, как я думаю, может оказаться полезным широкому кругу ИТ-читателей.
Итак, заказчик попросил EMC посмотреть производительность развёрнутой у него в SAN гибридной системы хранения VNX5500. К СХД подключены серверы VMware, на которых крутится «вообще всё»: от инфраструктурных задач до файловых шар и серверов БД. Поводом к проведению этой экспресс-оценки послужили жалобы на подвисания приложений, развёрнутых на подключённых к VNX серверах.
Для предварительной обработки я воспользовался свободно доступным сервисом Mitrend.
Подробное описание данного сервиса не входит в цели данного поста, поэтому я приглашаю всех желающих узнать о нем больше — зайти на его сайт и посмотреть самим.
Mitrend получает на входе файлы со статистикой ввода-вывода от изучаемой системы и подготавливает графики по наиболее часто востребованным параметрам, а так же делает предварительную аналитику, результаты которой будут использованы далее.

Одним из примеров такой аналитики является тепловая карта, показывающая насколько загружены различные компоненты системы в разные моменты времени. По сути, это схематическое изображение системы и ее составных частей, внутри каждой из которых построен график ее загрузки. Общий взгляд на нее позволяет увидеть потенциально проблемные места. В данном случае видно, что проблемным местом является кэш-память на запись. Вот этот график:

Утилизация кэша записи находится на высоком уровне, откуда происходят регулярные «прострелы» в красную зону (выше 90%).
Это типичный симптом проблем с производительностью. Своего рода «высокая температура». В данном случае нам предстоит изучить, что именно приводит к такой ситуации и наметить пути решения.
Диски, процессоры, порты ввода-вывода, дисковая шина не нагружены. И это немного странно, на фоне того, что «забит» кэш записи.



Давайте теперь взглянем на диски более подробно. Для наглядности я обвел разноцветными линиями диски разного типа и подписал снизу легенду. В самом файле с анализом это видно и без легенды.
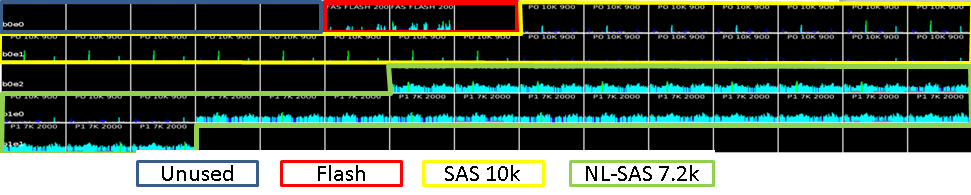
Давайте посмотрим более подробно, что вообще собой представляет рассматриваемая дисковая система: три флэш-накопителя по 200ГБ, два из которых сконфигурированы в FAST Cache с полезным объемом 183ГБ, а третий поставлен в горячий резерв. Т.е. очень надежная зеркалированная кэш-память на флэшах с горячим резервом. Эффективность ее работы можно увидеть на графике ниже:

В системе есть 5 дисков 900 ГБ, которые не используются вообще. Поскольку это системные диски, и их по привычке стараются не трогать, потому что бытует мнение, что это вызывает проблемы с производительностью. Мое мнение на этот счет — что их можно использовать, если делать это осмысленно. Проблемы с производительностью обычно бывают совсем по другим причинам.
Обычно, диски разных типов объединяют в гибридные пулы, чтобы система сама определила где лучше размещать данные (при помощи FAST VP). Но в данном случае выполнявшие внедрение специалисты не доверили ей это ответственное дело и жестко разделили данные по типам дисков. Поэтому диски поделены на 2 отдельные группы — Pool 0 и Pool 1. Сделали это, чтобы изолировать их с точки зрения производительности, и чтобы некритичные приложения не влияли на те, которым скорость нужна.
Pool 0 (RAID5) предназначен для критичных серверов приложений и состоит из дисков SAS 10k.
Pool 1 (RAID6) — это пользовательские «шары» и всякие нетребовательные к производительности среды. Он состоит из дисков NL SAS 7.2k.
Изучение сводки по группам дисков показывает, что FAST Cache отключен на группе Pool 1.

Разговор с заказчиком прояснил, что сделано это было с целью повышения приоритета ресурсов для критичного к производительности Pool 0.
Интересно отметить, что несмотря на это жалобы идут именно со стороны приложений, использующих Pool 0, диски которого почти не загружены. Более того — 80% всех операций чтения и 91% всех операций записи этого пула обслуживаются FAST Cache.

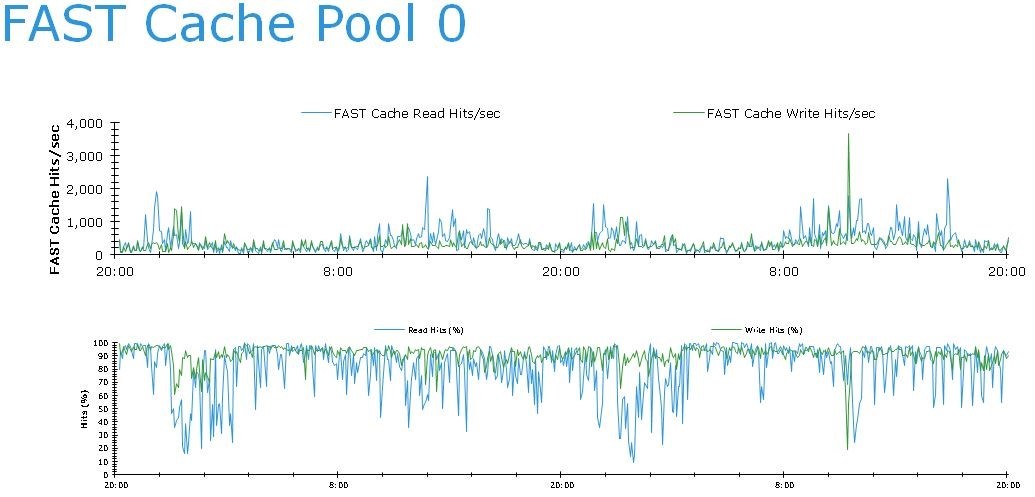
То есть, несмотря на потрясающую эффективность FAST Cache приложения испытывают проблемы. Почему? Чтобы продвинуться дальше, давайте посмотрим на LUN-ы и распределение по ним нагрузки.
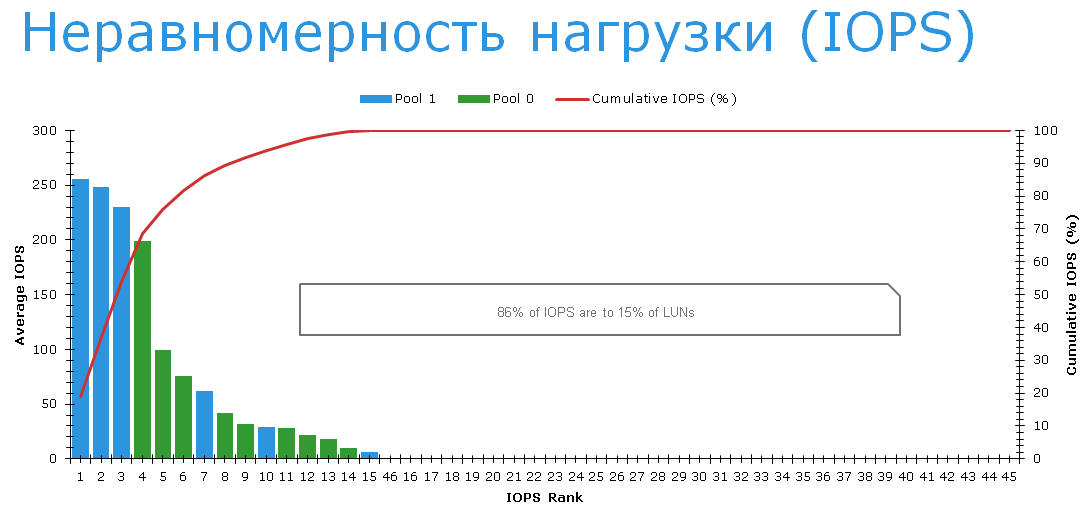
Оказывается, что три самых нагруженных LUN-а размещены именно на медленных NL-SAS дисках в RAID6. На них жалоб как раз нет. Разговор с пользователями, показал, что они исключительно довольны тем, как быстро стали работать их файловые сервера после перехода на VNX.
Жалобы есть на LUN-ы на Pool 0 (зеленый на графике сверху). Конкретно — речь идет о LUN-ах c номерами с 0 по 8, которые перечислены в таблице ниже

Если теперь посмотреть на степень утилизации LUN-ов, то видно, что LUN-ы из Pool 0 утилизированы достаточно слабо. На нижеприведенном графике по горизонтали указаны номера LUN-ов, так что легко опознать, какие LUN-ы «наши». Самый «нагруженный» из них занят работой всего на 40%.
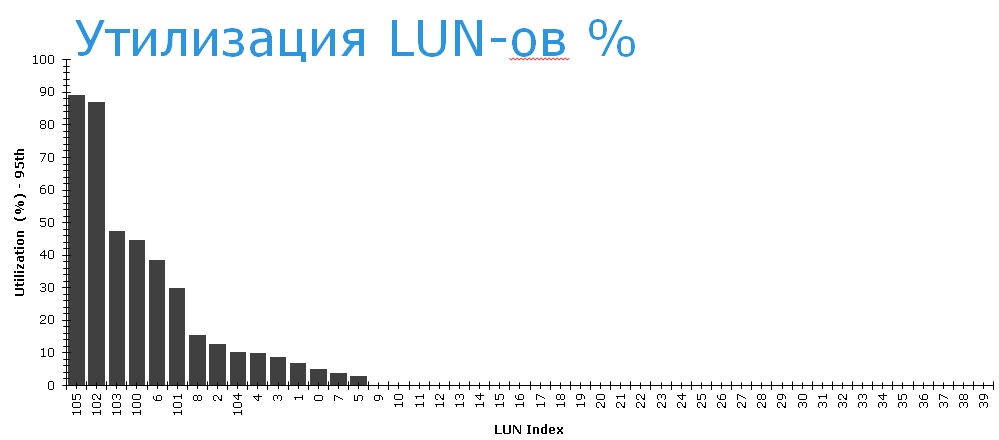
Система работает «в среднем хорошо». Среднее время отклика томов в пределах 10 мс. Это средняя температура по госпиталю.
На фоне того, что нагрузка на проблемные LUN-ы невысокая, можно заключить, что проблемы вызывает их конкуренция за какой-то общий ресурс.

Посмотрим, как работает системный кэш. Чтение из кэша очень эффективно.

Анализ работы кэша записи показывает, что его загруженность держится в пределах заданных рамок 60-80% с периодическими всплесками до 90% и более. Это не очень хорошо.

Посмотрим, насколько часто системе приходится прибегать к крайним мерам для того, чтобы очистить кэш до приемлемого уровня.
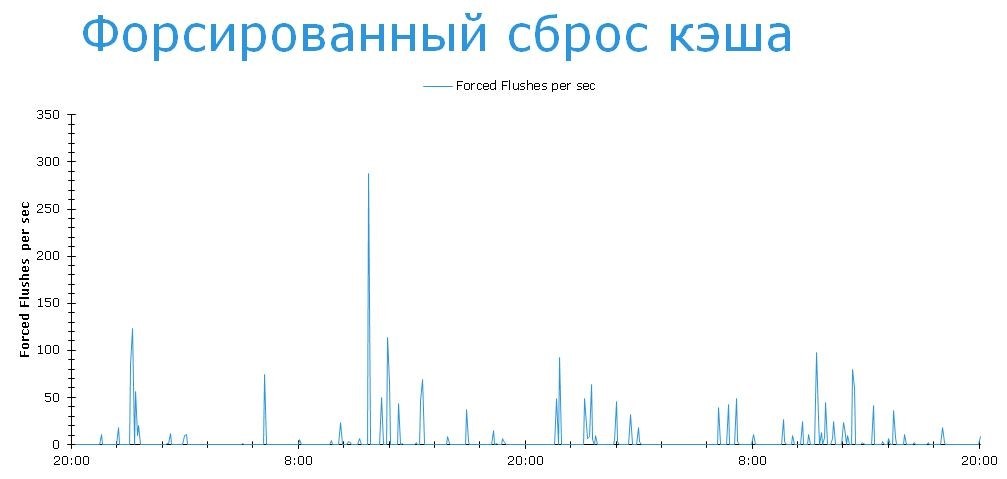
Это значит, что система не успевает отрабатывать всплески записи. Но системные настройки можно поменять, сдвинув верхнюю и нижнюю границу до более комфортных уровней. 30-50%, например. Но это все равно, что сбить температуру у больного. Делать это надо сначала поставив диагноз и первопричину. Посмотрим теперь на пулы и попробуем понять, что именно вызывает форсированные сбросы кэша.
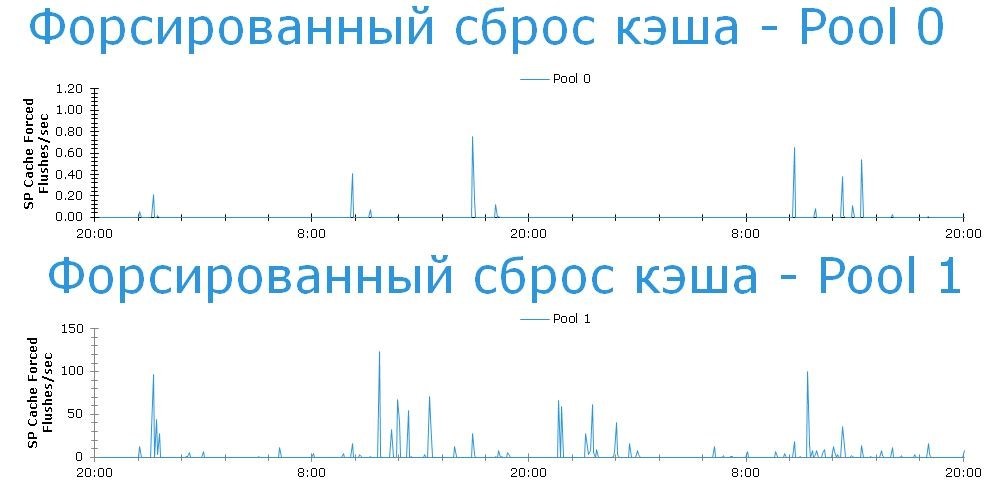
Видим, что на обоих дисковых пулах случаются регулярные форсированные сбросы. Причем если на Pool 0 это случается крайне редко (единичные случаи), то на Pool 1 эта ситуация имеет весьма тяжелый характер (десятки и сотни событий в час). Но нас интересует именно Pool 0. Там все хорошо, не так ли?
Мы вплотную подошли к разгадке. Но чтобы двинуться дальше — лирическое отступление, поскольку нужно пояснить логику управления наполненностью кэша записи в VNX. Она продемонстрирована ниже.
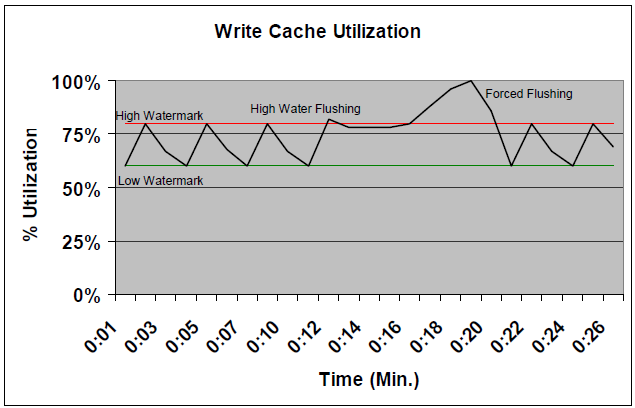
В обычном режиме система поддерживает кэш между двумя границами — High и Low watermarks.
Нижняя граница — это тот порог ниже которого кэш записи не сбрасывается, поскольку данные которые в нем содержатся могут понадобиться для чтения, или быть перезаписаны. Кроме того, кэш записи VNX по своей природе удерживает некоторое количесто блоков данных, в надежде, что их можно будет объединить для записи с другими, близрасположенными блоками, для записи на физические диски. Это позволяет сократить нагрузку на back-end.
Верхняя граница — порог включения сброса кэша записи на диски. Когда включается режим High Watermark Flushing, сброс данных из кэша на диски выполняется до нижнего уровня, после чего снова переходит в ждущий режим.
Мы не хотим, чтобы кэш заполнялся до 100%, поскольку тогда не сможем обеспечить место для новых записей. Поэтому верхнюю границу стараются держать на безопасном расстоянии от 100%. Обычно 80% — нормально. Но может быть и ниже. Все зависит от характера нагрузки.
Если кэш заполняется до 100%, то из режима High Watermark flush система включает форсированный сброс кэша, или Forced Flush.
Режим Forced Flush оказывает серьезное влияние на все операции записи на СХД. Новые данные пишутся на СХД с дополнительной задержкой. Т.е. для того чтобы записать блок данных в СХД надо сначала освободить место от старых данных, используя алгоритм LRU (Least Recently Used) и др.
Вернемся к нашей ситуации. Очевидно, что медленный Pool 1 является слабым звеном с точки зрения кэша записи. Данные, которые приходят на медленные диски в RAID6 задерживаются в кэше дольше, чем нужно, а когда дело доходит до Forced Flush, слишком долго переходят на физические диски.
Нужно обратить внимание на то, что Pool 0 использует FAST Cache, и большая часть запросов обслуживается с флэш дисков. До тех пор, пока не наступает Forced Flush, и время отклика flash начинает зависеть от того, как быстро будут сброшены данные на NL-SAS. Очень похоже, что слабое звено найдено. Насколько это заключение верно — должна показать проверка гипотезы на практике.
Как можно тогда объяснить алиби «подозреваемого» — низкую загрузку дисков NL-SAS? Так как значнеие нагрузки — среднее за интервал времени, а в данном случае интервал сбора статистики составлял 10 минут, возможно за это время проходил короткий всплеск записи данных, вызывающий короткое «зависание» приложений, а в среднем за 10 минут нагрузка оказывалась не такая уж большая. Так как мы нашли, где происходит наибольшее значение Forced Flush-ей — сомнений в «виновности» этого дискового пула быть не может.
Что можно с этим сделать?
Само по себе сделанное внедрение содержит ошибки планирования, поскольку использован старый подход к конфигурации в системе с архитектурой нового поколения. Общение с заказчиком помогло прояснить, что дело в принятых ранее стандартах, которые не были пересмотрены на момент планирования. Но так как система уже боевая, и нельзя ее пересобрать, остается искать пути решения в области онлайн реконфигураций, чтобы не прерывать работы приложений.
Я нашел как минимум три меры, которые могут быть приняты либо по отдельности, либо вместе, дополняя друг друга. Перечисляю по степени сложности реализации.
- Для того чтобы СХД успевала отрабатывать периодические всплески нагрузки, надо понизить Low/High watermarks до уровня 30/50 и посмотреть, насколько успешно будут отрабатываться эти всплески. В идеале заполнение кэша записи во время всплесков не должно доходить до 90%.
- Включить FAST Cache на Pool 1. Наиболее часто обновляемые данные перейдут с медленных дисков на SSD. Сброс кэша записи на SSD происходит существенно быстрее. Это снизит вероятность возникновения Forced Flush
- Создать RAID группу RAID10 на свободных дисках SAS 900GB 10k (4 штуки) и перенести на них данные наиболее часто обновляемые LUN-ы с Pool 1. В созданной RAID группе отключить кэш записи.
Есть и другие способы оптимизации, однако, я специально старался не усложнять данный пример, чтобы более компактно продемонстрировать один из возможных подходов.
Начать можно и с этих мер, поскольку все перечисленные изменения обратимы и могут быть применены или отменены в любом порядке.
В процессе дальнейшего исследования поведения системы могут быть сделаны другие полезные выводы.
Послесловие
Интеллектуальные системы хранения обладают богатым встроенным функционалом как анализа, так и настройки производительности. Однако подробный ручной анализ и настройка представляют собой довольно трудоемкие задачи, которые мы в данном посте затронули лишь поверхностно. Обычно на полноценное изучение работы СХД и ее оптимизацию у администраторов остается крайне мало времени. В условиях динамических рабочих нагрузок и усложняющихся ИТ-инфраструктур требуется выход на новый уровень развития и автоматизации.
Для решения этих задач сейчас разработан целый комплекс технологий на всех уровнях.
От более удобного и быстрого анализа производительности до новых интеллектуальных и самооптимизирующихся систем.
Вот лишь некоторые примеры:
- 1. Mitrend — свободно доступный для всех автоматизированный анализ работы ИТ-инфраструктуры разных производителей
2. Автоматизированное многоуровневое хранение и кэш на SSD: FAST VP и FAST Cache
3. В системах следующего поколения внедрен адаптивный кэш VNX2 с интеллектуальной авто-настройкой скорости сброса данных на каждый LUN (см. whitepaper стр 13).
lovecraft
Я правильно понимаю, что проблема была в том, что DRAM кэш был включен для обоих пулов и его сбросы, вызванные запросами с «медленного» пула тормозили «быстрый» пул?
dserov
Да, скорее всего проблема именно в этом. Она усугубляется тем, что в пулах нельзя отключить кэш записи. Для однородных дисковых групп лучше бы использовали классические RAID группы. Там можно управлять кэшем значительно более тонко.
В данном случае при внедрении были сделаны однородные пулы, в которых возможности управления DRAM кэшем отсутствуют.
Все было бы хорошо, если бы не повышенная нагрузка по записи именно на медленный пул. Т.е. в нем содержатся какие-то области, которые регулярно обновляются.
Средства же для настройки у пулов «заточены» под FAST VP, который тоже использовать не получается из-за однородности дискового состава.
Остается в результате не такой уж большой выбор маневров ресурсами.