
Если вы работаете с вебом, вы обязательно столкнётесь с брокерами сообщений. Они бывают разные, но чаще остальных встречаются Kafka, RabbitMQ и AWS SNS/SQS. У каждого из них есть свои особенности, плюсы и минусы — выбирать брокер нужно под свою задачу.
О том, как сделать правильный выбор, рассказали эксперты из команды курса «Go-разработчик» Яндекс Практикума:
Анастасия Бошнякович, старший программист в xpate;
Александр Передерей, Engineering Manager DeliveryHero;
Дмитрий Шеламов, старший разработчик DeliveryHero.
Эта статья — дополненная текстовая версия бесплатного вебинара Яндекс.Практикума по Go. Можете посмотреть видео — кроме теории там есть примеры кейсов применения брокеров.
Зачем нужны брокеры сообщений
Начнём с теории — для тех, кто забыл или не знает о брокерах сообщений. И прежде чем перейти к ним, рассмотрим модели взаимодействия между сервисами и более крупными модулями.
Моделей взаимодействия две: асинхронная и синхронная. Когда разработчик пишет код или выполняет http-запрос, он работает с синхронным взаимодействием: какая-то функция вызывает другую функцию, ждёт ответа и только потом продолжает работу. То есть появляется момент ожидания ответа: первой функции нужно синхронизироваться со второй, чтобы работать дальше.
При асинхронном взаимодействии функция отправляет данные, но не ожидает ответа и продолжает работу. Например, в JavaScript это конструкция async await. Такая функция запускает логику, которая выполняется в фоне, а сам код продолжает выполняться дальше.
Теперь перейдём от общей теории к бэкенду и брокерам. Представим, что у нас есть сервисы А и В. А делает синхронный запрос в В и ждёт, пока В на своей стороне его обработает и вернёт ответ. Потом на основе этого ответа А решает, что именно делать дальше.

Обычно ждать ответ нужно пару секунд, но есть вещи, которые требуют больше времени: например, рендеринг видео или запрос в большую базу. В таком случае клиенту приходится ждать очень долго. Представьте, что посетитель сайта нажимает кнопку «Скачать» или «Купить» и получает в ответ иконку загрузки на несколько минут.
Чтобы избежать подобного сценария, синхронное взаимодействие заменяют на асинхронное. Сервис А отправляет большой запрос сервису В, а потом идёт заниматься своими делами — например, позволяет пользователю дальше просматривать сайт.
Но если мы не дожидаемся ответа, как убедиться, что В получил запрос и рано или поздно его обработает? В таком случае нам поможет ещё один узел системы, который будет работать как курьерская служба, — брокер сообщений. Он берёт на себя роль гаранта доставки данных — принимает запросы от А и ждёт ответа от В, пока А продолжает работу.
Эта модель предполагает, что асинхронное взаимодействие осуществляется согласно следующей логике двух ролей:
Publishers публикуют новую информацию в виде сгруппированных по некоторому атрибуту сообщений;
Subscribers подписываются на потоки сообщений с определёнными атрибутами и обрабатывают их.
Например, у нас есть сервис нотификации, который хочет считывать только дискретные потоки данных с сообщениями. Он подписывается на такую очередь и берёт только сообщения о том, что нужно отправить СМС юзеру, а сообщения о рендеринге видео игнорирует.
Получается, что брокер — это служба в инфраструктуре, к которой подключаются отправители и получатели данных. Брокер отвечает за группировку потоков данных от отправителей, создание очередей и выдачу данных получателям. А вот как именно он это делает, зависит от технологии конкретного брокера.
RabbitMQ
RabbitMQ — это брокер сообщений, основанный на протоколе AMQP, Advanced Message Queuing Protocol. Это открытый протокол передачи сообщений, который нужен для общения разных частей системы между собой.
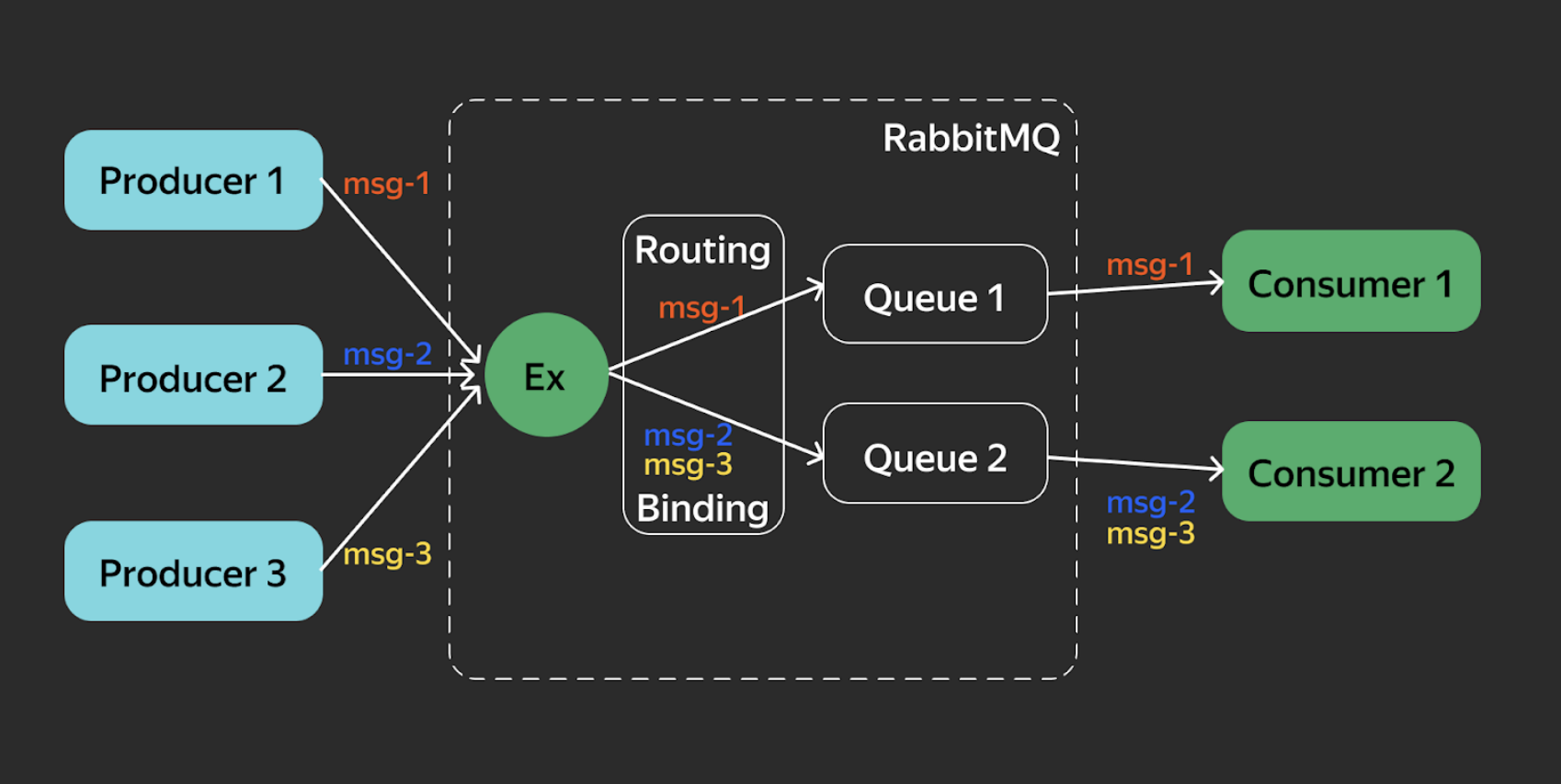
Система состоит из нескольких компонентов:
AMQP-брокер маршрутизирует сообщения и помогает частям системы общаться между собой;
Producer (отправитель) отправляет сообщения в брокер;
Consumer (читатель) получает эти сообщения;
Exchange (обменник) получает сообщения и распределяет их между очередями;
Queue (очередь) хранит сообщения и отдаёт их подписанным получателям;
Binding хранит правила для обменника.
Пунктирной линией на схеме обозначен брокер. Любой Producer отправляет в него сообщения, причём обязательно в формате JSON, а каждый Consumer получает их. Причем парсить сообщения они должны сами — RabbitMQ ничего за них не делает.
Внутри брокера Exchange получает сообщения и отправляет через Routing — карту маршрутизации с правилами Binding. Дальше сообщения распределяются по очередям, и очереди уже отдают их нужному Consumer. Причём в идеальном сценарии именно Consumer должен создавать нужные себе очереди — тогда всё будет работать правильно.
Теперь подробнее рассмотрим работу Exchange в RabbitMQ. Они бывают трёх видов.
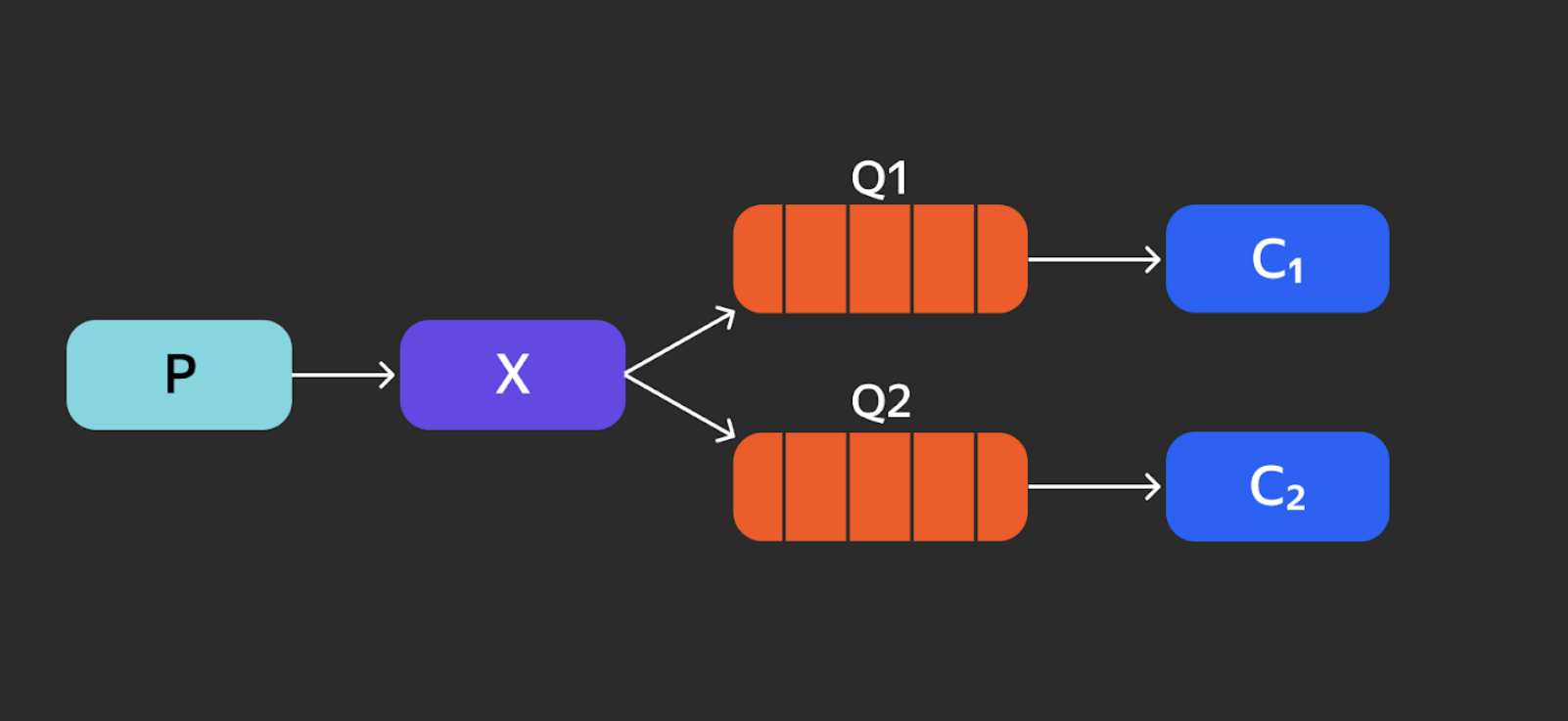
Fanout Exchange. Это «маршрутизация без маршрутизации» — то есть мы отправляем сообщения во все очереди.
Direct Exchange. Это маршрутизация по ключу. В RabbitMQ существует routing-key. Ключ маршрутизации — это категория сообщения. В данном случае orange, black и green. Они распределяются по разным очередям в зависимости от ключа.
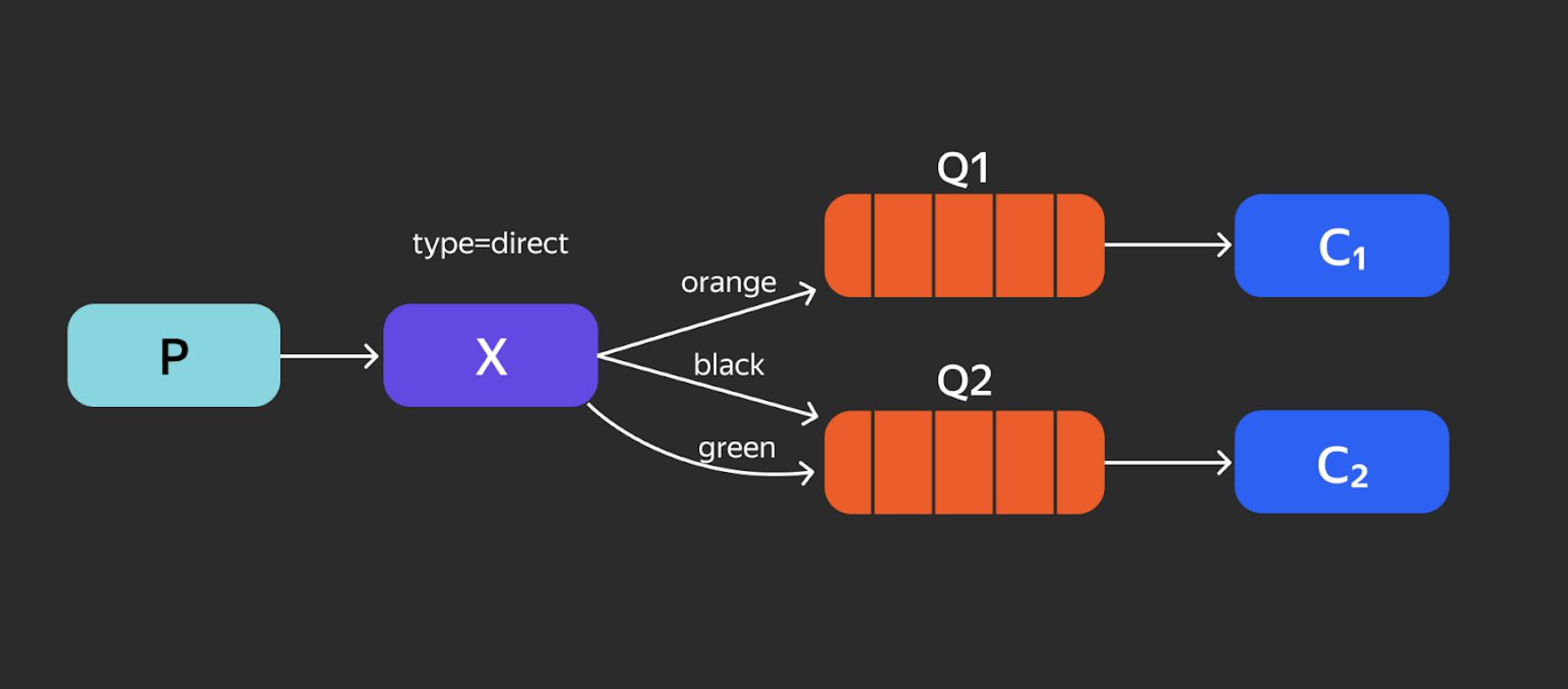
Total Exchange. Это уже более сложный Binding. Сообщения, не попадающие под ключ, удаляются, так как никому не нужны. То, что остаётся, передаётся в сами очереди.
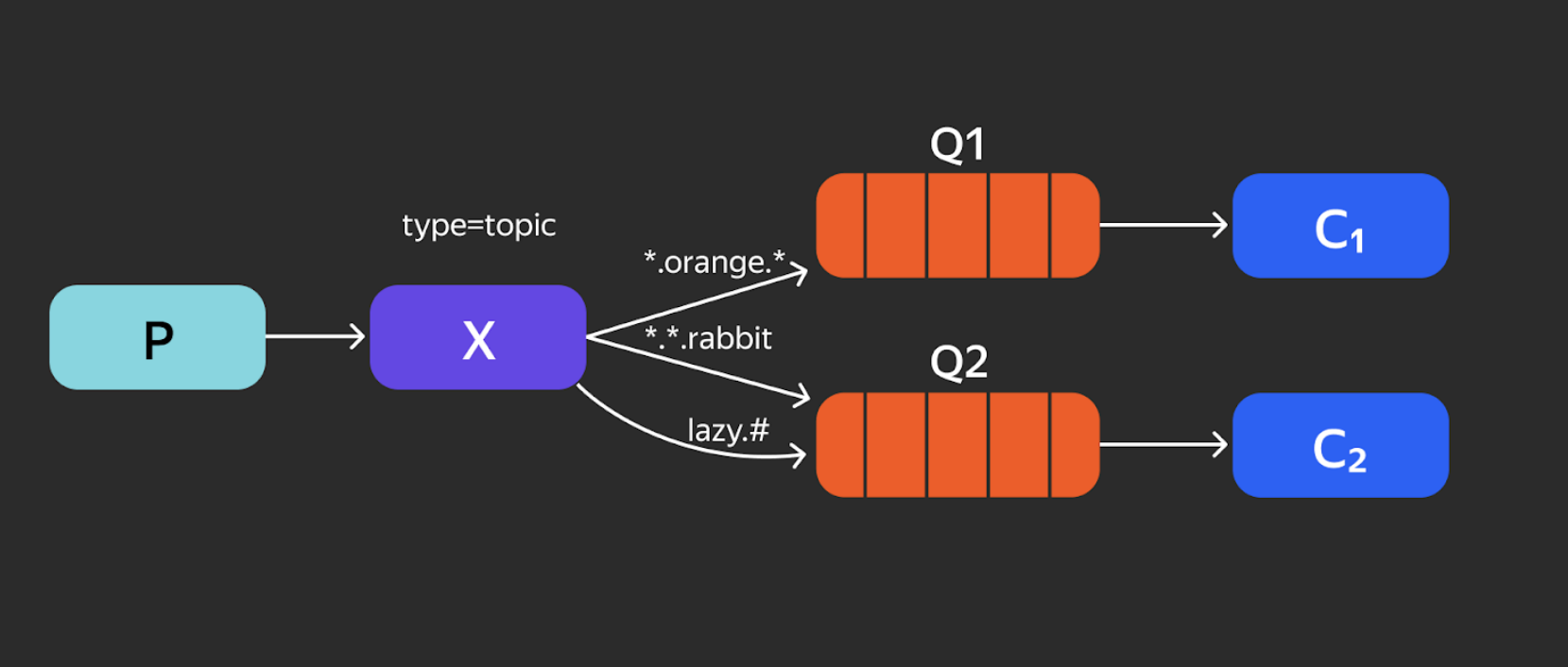
Есть и другие виды Exchange: например, Headers Exchange, когда на основе пар «ключ — значение» мы определяем, что и куда передаём. Также можно комбинировать различные виды Exchange.
Плюсы RabbitMQ
Лёгкость разработки. У RabbitMQ есть библиотеки клиента для большинства современных языков и открытый исходный код, чтобы в нём разбираться.
Простое администрирование. У RabbitMQ удобная админка, где вы можете в режиме реального времени разбираться с тем, что происходит. Роутинги можно настраивать в процессе, переключая нагрузку и меняя правила обработки.
Тонкая настройка. Многие параметры можно менять, чтобы подстроить систему под свои нужды. Особенно это касается очередей.
Минусы RabbitMQ
Работа при высокой нагрузке. У RabbitMQ есть сложности при горизонтальном масштабировании в кластере. Приходится добавлять настройки кластеризации над очередями, а они сложные и работают плохо. Приходится выбирать, чем пожертвовать — гибкостью или скоростью.
В каких случаях использовать RabbitMQ
Когда важна гибкость маршрутизации сообщений внутри системы. В таком случае он предоставляет инструменты для построения путей доставки данных и способен решить самые хитрые сценарии в организации потоков событий.
Если вам важен сам факт доставки сообщений и порядок их получения.
Apache Kafka
Kafka устроен проще RabbitMQ, и сущностей у него меньше. А ещё он часто встречается в вакансиях: после 2020 года Kafka заметно потеснил RabbitMQ. Давайте разберёмся, почему это произошло.
Концептуально в Kafka нет многообразия конфигураций, сложных механизмов распределения сообщений по очередям и процесса доставки каждого отдельного сообщения. Ядро его функциональности — запись данных, хранение их в течение заданного времени и выдача этих данных по запросу.
Все остальные особенности можно рассматривать как следствие этого концепта. И в этом его преимущество перед другими opensource-решениями, которые работают по пуш-механизму или протоколу AMQP.
В Kafka данные физически хранятся на диске в виде партиций. Новые сообщения добавляются в commit log. Они помещаются строго в конец, и их порядок после этого не меняется, благодаря чему в каждой отдельной партиции сообщения всегда расположены в порядке их добавления.
Само сообщение с точки зрения Kafka — просто набор байт, хранящийся в ячейке партиции под индексом с названием offset. Содержимое и структура не имеют значения для Kafka. Сообщение может содержать ключ, также представляющий из себя набор байт. Ключ позволяет получить больше контроля над механизмом распределения сообщений по партициям.
Функцию очереди в Kafka выполняет topic, который нужен для объединения нескольких партиций в общий поток. Таким образом сообщение, которое относится к одному топику, может храниться в двух разных партициях, из которых Consumer вытаскивает их по запросу.
Почему «вытаскивает»? В Kafka используется pull-, а не push-механизм. В RabbitMQ сообщения загружаются в читателей, а в Kafka они приходят сами и берут, что нужно. Чтобы начать читать сообщения с произвольного места в очереди, Consumer сообщает брокеру номер сообщения и номер партиции. Процесс чтения сообщений аналогичен проходу по массиву: Consumer получает их одно за другим, слева направо.
Данные персистентны: они лежат в партиции нужное вам время, пока остаются актуальны или хватает места на диске. Персистентность позволяет заново использовать данные и читать их пачками, что полезно для пропускной способности сети.

На схеме в центре находится топик с двумя партициями. Сервис А — отправитель, который шлёт сообщение в топик и решает, в какую партицию его добавить. Это позволяет хранить смежные данные, например по одному юзеру, в одной партиции в хронологическом порядке.
После выбора отправитель помечает сообщение номером партиции и отправляет в Kafka. Kafka добавляет сообщение в топик и кладёт в прописанную партицию.
Слева — consumer group, которая объединяет несколько реплик одного сервиса. Чаще всего в современных распределённых системах сервисы работают на множестве экземпляров для горизонтального масштабирования. Получается, что считывание разными сервисами — это по сути одна и та же работа. Если обе реплики это сделают, получится дублирование, которое никому не нужно.
Consumer group позволяет этого избежать: она разрешает читать партицию только одному участнику из группы. Соответственно, реплики В1 и В2 будут читать разные партиции и выполнять разную работу.
Если появится В3, то в Kafka есть правило, чтобы она не простаивала: количество партиций должно быть равно количеству параллельных читателей или реплик одного сервиса.
Плюсы Kafka
Делает всего две вещи: записывает и отдаёт. Если использовать брокер вместе с надкластером ZooKeeper, то можно наладить кластерные трансферы — Kafka долго этого не умел.
Пропускная способность — миллионы сообщений в секунду. Причём её можно эффективно наращивать: добавить датчик в кластер и при переполнении просто создавать новый, настраивая между ними репликацию. Именно поэтому Kafka стал промышленным стандартом.
Позволяет перечитывать сообщения. Если мы прочитали сообщение, а потом потеряли изменение в базе, можно откатить офсет назад и прочитать сообщение снова.
Позволяет читать сообщения пачками. Можно запросить сразу 1000 сообщений, что снижает нагрузку на сеть.
Минусы Kafka
-
Проблемы с обработкой битых сообщений. В RabbitMQ необработанное сообщение мы заново закидываем в очередь, и оно крутится, пока его не получится обработать. В Kafka для обработки следующего сообщения нам нужно обработать его или пропустить текущее. Битое мы просто потеряем навсегда.
В Kafka для этого применяют концепцию dead letter queue — отдельного места для сохранения битых сообщений. Мы берём что-то битое, кладём отдельно и потом пытаемся обработать снова. Но это всё равно дополнительная сложность.
Нужно вести учёт последнего прочитанного сообщения, причём для каждого читателя. Потому что данные неизменны, и мы раскидываем не их, а читателей по одному и тому же массиву данных. То есть храним те точки, где они остановились в чтении. Для этого есть несколько решений, но все они, конечно, утяжеляют систему.
Когда использовать Kafka
При конвейерной обработке данных. Kafka хорошо работает как общая шина для нескольких сервисов. Сервис что-то сделал, записал результат, следующий по конвейеру считал — записал, и так далее. В RabbitMQ это сработает хуже, так как конвейерность может нарушиться.
При Event-driven architecture. В этом случае сообщения можно бродкастить всем необходимым сервисам, и нужные адресаты их получат. В RabbitMQ обязательно нужно знать, сколько у вас получателей. Особенно это актуально в микросервисном мире, где количество реплик сервиса меняется динамически.
При использовании буфера для логов и метрик. Промежуточное хранилище для большого количества данных, где они будут сохранны и упорядочены.
Amazon Simple Queue Service (SQS)
И ещё один брокер — SQS от Amazon. Это управляемый сервис очередей сообщений, с помощью которого можно так же, как и с помощью других брокеров, изолировать и масштабировать микросервисы и бессерверные приложения.
SQS предлагает два типа очередей сообщений:
Стандартные очереди обеспечивают максимальную пропускную способность и доставку сообщений по принципу «хотя бы один раз». Стандартная очередь старается соблюдать порядок сообщений, но он может быть нарушен. Если система требует сохранения порядка, то лучше использовать очередь FIFO.
Очереди FIFO с ограниченной пропускной способностью гарантируют, что сообщения будут обрабатываться строго однократно и исключительно в порядке отправления. Они предназначены для улучшения обмена сообщениями между приложениями, когда порядок операций и событий имеет решающее значение или когда дублирование недопустимо.
SQS работает в связке с SNS — сервисом обмена сообщениями для связи между приложениями, а также между приложениями и пользователями. Обмен происходит по модели pub-sub («издатель — подписчик»): получатели подписываются на тему (топик), а издатель публикует в эту тему сообщения, которые может считывать множество получателей.
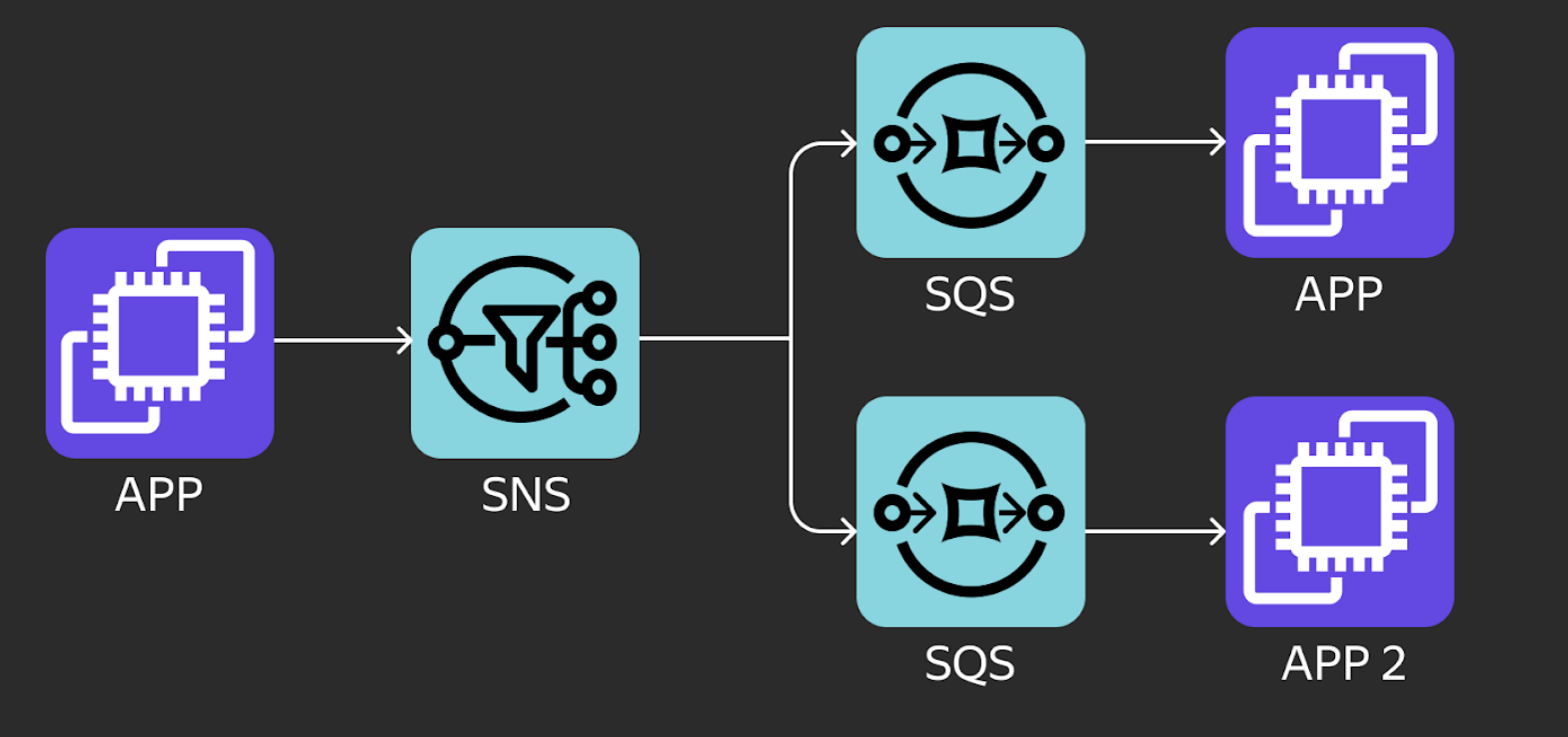
SNS предназначен для обмена сообщениями в масштабных распределённых системах: например, для параллельной обработки данных на большом количестве агентов, для отправки пользователям уведомлений, для обновления записей в базах данных.
Пропускная способность SNS практически не ограничена, но со стандартными топиками он не гарантирует сохранение последовательности сообщений и отсутствие дупликации: сообщение доставляется как минимум один раз примерно в нужном порядке.
SNS не регулирует частоту доставки получателю. Если конечный сервис недоступен, SNS повторяет отправку в соответствии с установленными правилами. Это значит, что, если получатель какое-то время был недоступен, впоследствии он может быть завален повторными сообщениями. Избежать этого помогает правильная настройка dead letter queue (DLQ).
Dead Letter Queue (DLQ) — это очередь, куда перенаправляются сообщения, которые не смогли обработать получатели в обычных очередях. Сообщения могут не обработаться по ряду причин, например из-за изменения состояний отправителя или получателя. Перенаправленные в DLQ сообщения будут храниться там для дальнейшей диагностики и больше не помешают работе приложений.
AWS устанавливает некоторые ограничения SQS и SNS:
-
Лимит на отправленные сообщения. Это те сообщения в SQS, которые были получены потребителем, но ещё не были удалены. Каждая очередь SQS ограничена 120 000 сообщениями — или 20 000, если это очередь FIFO.
Чтобы избежать этого ограничения, удаляйте сообщения сразу после их обработки, чтобы они больше не отправлялись, а также разделите сообщения между несколькими очередями.
-
Лимит на размер сообщения. Атрибут максимального размера сообщения в очереди определяет размер сообщений, поступающих в очередь. Сообщения, превышающие лимит, отклоняются, поэтому превысить лимит фактически невозможно.
Чтобы избежать ошибок отправки сообщений, убедитесь, что максимальный размер сообщения не больше, чем отправляемые вами сообщения. Если размер сообщений превышает 256 КБ, вы можете использовать связку между SQS и S3. SQS API умеет автоматически сохранять большие сообщения в S3, а в самом сообщении передавать ссылку на S3.
Лимит на пропускную способность очереди FIFO. Очереди FIFO могут поддерживать только 300 операций отправки, получения или удаления в секунду. При использовании пакетной обработки 10 сообщений производительность увеличивается до 3000 операций в секунду.
При совместном использовании SQS и SNS могут стать основой масштабируемого надёжного распределённого приложения. Благодаря интеграции со множеством других сервисов Amazon эти два инструмента могут сочетаться и с другими, чтобы разрешить проблемы взаимодействия между микросервисами.
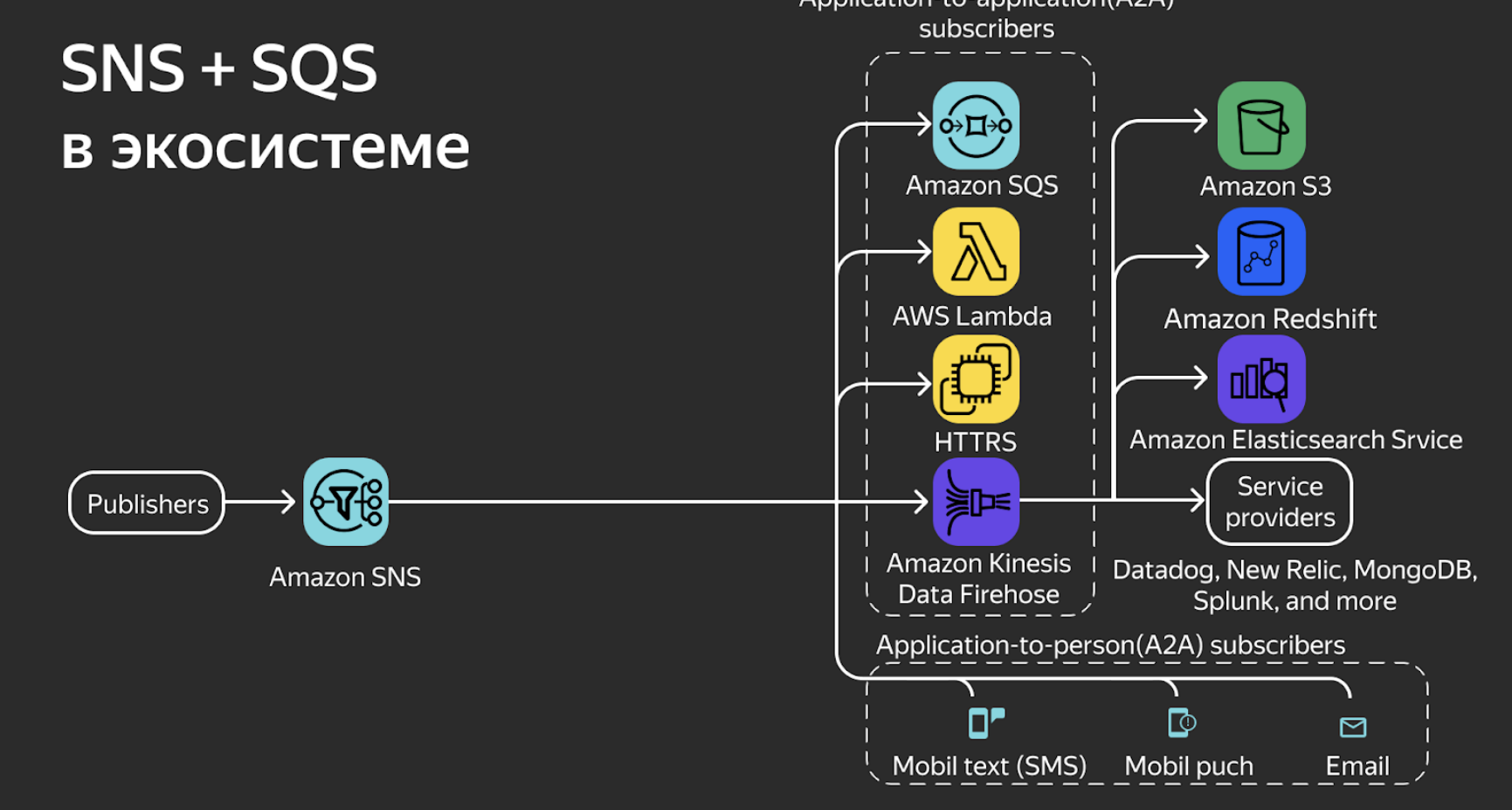
Здесь SNS выступает как единая точка сбора данных от отправителей, а SQS — как один из доступных сервисов. И внутри этой экосистемы мы можем применить множество других инструментов AWS:
Lambda для вычислений в облаке. Сервис позволяет выполнять код для разных типов приложений. Здесь как раз часто используется связка SNS+SQS;
HTTP-endpoint позволяет отправлять запросы из SNS. Микросервис посылает данные в SNS, а SNS автоматически посылает запрос (GET или POST) по HTTP. При этом можно настроить механизмы повтора и действия в случае ошибки;
Kinesis Data Firehose обеспечивает надёжный сбор, преобразование и доставку потоковых данных в хранилища данных и аналитические службы;
A2P на базе SNS, чтобы напрямую отправлять смс, мобильные пуши или email;
S3 — это хранилище файлов. Связка с SNS/SQS — классический пример работы бессерверных операций.
В итоге получается, что SNS+SQS с инструментами Amazon позволяет построить экосистему, где всё уже отлажено и работает.
Плюсы SQS
Популярность за рубежом. Практически все крупные компании используют инфраструктуру Amazon, поэтому и этот брокер актуален. Если вы ищете работу за рубежом, то знание сервисов Amazon будет большим плюсом.
Безопасность. Тщательное шифрование всех сообщений, которые идут в брокера и от брокера.
Автоматические бэкапы.
Простая прямая отправка имейлов, СМС, http-запросов.
Встроенный DLQ. Битые сообщения можно хранить и обрабатывать позже.
Интеграция со всеми другими сервисами Amazon. У него тот же тип авторизации, понятная структура, дизайн и SDK.
Минусы SQS
Vendor lock. Полная зависимость от Amazon. Перейти на другого поставщика, если что-то случится, будет сложно.
Когда применять SQS
Если вы уже работаете с продуктами экосистемы Amazon и вам нужен брокер сообщений.
Если вы хотите выстроить единую экосистему и выбираете для этого Amazon.
Если вам нужно стабильное и готовое к работе решение.
Вывод
Однозначно сказать, что какой-то брокер лучше другого, нельзя. У каждого есть свои архитектурные особенности, плюсы и минусы, так что их нужно всегда выбирать под задачу, с которой вам предстоит работать. А чтобы разбираться, в каком случае понадобится тот или иной брокер, приходите учиться на курс «Go-разработчик».
Комментарии (7)

arheops
21.11.2022 22:02+1Основной минус SQS — он периодически выдает задержки по секунде и типичные порядка 30мс(для сравнения, rabbit в тех же условиях — 5мс). И стоит как ракета.
Вы вообще его использовали на практике?
SQS имеет хоть какойто смысл только когда вы лямбда-функции там же пишите.

foatto
21.11.2022 22:26Плюс к RabbitMQ - есть приоритезация сообщений в очередях;
Минус к Kafka - нет приоритезации сообщений в очередях, надо велосипедить;И не пора ли добавлять Apache Pulsar к таким сравнениям (или ещё рано)?

AstarothAst
22.11.2022 11:39В Kafka для этого применяют концепцию dead letter queue — отдельного места для сохранения битых сообщений.
DLQ есть и в кролике.
bugy
22.11.2022 11:43Более того, в RabbitMQ оно есть из коробки.
А в Kafka его нужно как-то самому велосипедить.
bugy
Я бы не утверждал так однозначно. Kafka может потерять сообщения, а в RabbitMQ есть, как вы написали, есть Fanout Exchange, который должен работать с любым динамическим числом подов.
Я не работал в продакшене ни с той, ни с другой технологией, но когда выбирал платформу для event-driven, решил не в пользу кафки. Там слишком много минусов. У классических брокеров гораздо больше фишек, за что приходится платить масштабированием.
ITweb
Опишите пожалуйста механику?
В Kafka он тоже есть
bugy
https://developer20.com/when-you-can-nose-messages-in-kafka/
Я не про это писал, извините. Я не полностью скопировал цитату из поста. Там утверждалось, что
В случае Fanout Exchange количество получателей и тем более реплик, значения не имеет. Либо я неправильно понял, как это работает, по описанию
Разумеется, в kafka это тоже есть. Там по факту только это и есть.