

Логистическая регрессия — это алгоритм классификации в машинном обучении для прогнозирования вероятности категориально зависимой переменной. В логистической регрессии зависимые переменные — это двоичные (бинарные) переменные, содержащие 1 (да, успех, и так далее) или 0 — нет, неудача, и так далее. Другими словами, логистическая регрессия прогнозирует P(Y=1) как функцию от X. Подробный и ясный пример — к старту нашего флагманского курса по Data Science.
Допущения логистической регрессии:
- Двоичная логистическая регрессия требует двоичной зависимой переменной.
- В случае двоичной регрессии уровень фактора 1 должен представлять из себя желаемый исход.
- Включены должны быть только значимые переменные.
- Независимые переменные должны быть независимы друг от друга, то есть модель должна обладать малой мультиколлинеарностью или не обладать ею.
- Зависимые переменные линейно связаны с логарифмическими коэффициентами.
- Логистическая регрессия требует довольно большого размера выборок.
Имея в виду эти допущения, посмотрим на набор данных.
Данные
Набор данных из реозитория UCI Machine Learning связан с целевыми маркетинговыми компаниями (телефонными звонками) Португальского банка. Задача классификации — спрогнозировать (0/1), то есть откроет ли клиент срочный вклад (переменная y). Загрузить набор можно отсюда.
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)Набор посвящён клиентам банка и содержит 41188 записей с 21 полем:
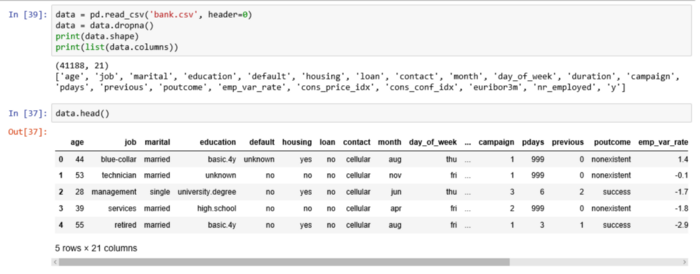
- age: возраст (числовая);
- job: работа (категориальная: "admin", "blue-collar", "entrepreneur", "housemaid", "management", "retired", "self-employed", "services", "student", "technician", "unemployed", "unknown");
- marital: семейное положение (категориальная: "divorced", "married", "single", "unknown");
- education: образование (категориальная: "basic.4y", "basic.6y", "basic.9y", "high.school", "illiterate", "professional.course", "university.degree", "unknown");
- default: есть невыплаченный кредит? (категориальная: "no", "yes", "unknown");
- housing: есть жилищный кредит? (категориальная: "no", "yes", "unknown");
- loan: есть кредит на личные нужды? (категориальная: "no", "yes", "unknown");
- contact: мобильный или стационарный телефон? (категориальная: "cellular", "telephone");
- month: месяц последнего звонка (категориальная: "jan", "feb", "mar", …, "nov", "dec");
- day_of_week: день недели последнего звонка (категориальная: "mon", "tue", "wed", "thu", "fri");
- duration: продолжительность разговора в секундах (числовая). Важное примечание: этот атрибут сильно влияет на конечный результат (например, если duration=0, то y=’no’); Продолжительность не известна до выполнения вызова, кроме того, после окончания вызова y, очевидно, известна. Таким образом, эти входные данные должны включаться только для сравнения и отбрасываться, когда нужна реалистичная прогностическая модель;
- campaign: число контактов в ходе этой кампании и для этого клиента (числовая), включая последний контакт);
- pdays: количество дней, прошедших с последнего контакта с клиентом, с предыдущей кампании (числовая); 999 означает, что ранее контакта не было);
- previous: количество контактов до этой кампании для данного клиента (числовая)
- poutcome: исход предыдущей кампании (категориальная: "failure", "nonexistent", "success")
- emp.var.rate: коэффициент вариации занятости — (числовая);
- cons.price.idx: индекс потребительских цен — (числовая);
- cons.conf.idx: индекс доверия потребителей — (числовая);
- euribor3m: ставка EURIBOR за 3 месяца — (числовая);
- nr.employed: количество работников — (числовая).
Наша цель — прогноз переменной Y, то есть того, есть ли у клиента срочный вклад? (0 — нет, 1 — да).
У поля об образовании (education) много категорий. Чтобы сделать модель лучше, количество этих категорий нужно сократить:

Для этого сгруппируем "basic.4y", "basic.9y" и "basic.6y", назовём их "Basic":
data['education']=np.where(data['education'] =='basic.9y', 'Basic', data['education'])
data['education']=np.where(data['education'] =='basic.6y', 'Basic', data['education'])
data['education']=np.where(data['education'] =='basic.4y', 'Basic', data['education'])Вот поля после группировки:

Исследование данных

count_no_sub = len(data[data['y']==0])
count_sub = len(data[data['y']==1])
pct_of_no_sub = count_no_sub/(count_no_sub+count_sub)
print("percentage of no subscription is", pct_of_no_sub*100)
pct_of_sub = count_sub/(count_no_sub+count_sub)
print("percentage of subscription", pct_of_sub*100)- без вклада — 88,73458288821988;
- с вкладом — 11.265417111780131.
Классы наших данных не сбалансированы, а соотношение клиентов без вклада и с вкладом составляет 89 к 11. До балансировки классов проведём ещё несколько исследований:

Вот новые наблюдения:
- Средний возраст клиентов, открывших вклад, выше среднего возраста тех, кто этого не сделал.
- Количество дней с последнего контакта с клиентом по понятным причинам меньше у клиентов, открывших депозит. А чем она меньше, тем лучше запомнился последний звонок, а значит, выше шанс открытия счёта.
- Удивительно, но кампания, то есть количество звонков за одну кампанию, меньше у клиентов, которые открыли депозит.
Чтобы чётче представлять данные, рассчитаем категориальное среднее других категориальных переменных, таких как образование и семейное положение.


Визуализация
%matplotlib inline
pd.crosstab(data.job,data.y).plot(kind='bar')
plt.title('Purchase Frequency for Job Title')
plt.xlabel('Job')
plt.ylabel('Frequency of Purchase')
plt.savefig('purchase_fre_job')
Частота открытия депозита во многом зависит от должности клиента, а значит, эта категориальная переменная может служить хорошим фактором прогнозирования.
table=pd.crosstab(data.marital,data.y)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('Stacked Bar Chart of Marital Status vs Purchase')
plt.xlabel('Marital Status')
plt.ylabel('Proportion of Customers')
plt.savefig('mariral_vs_pur_stack')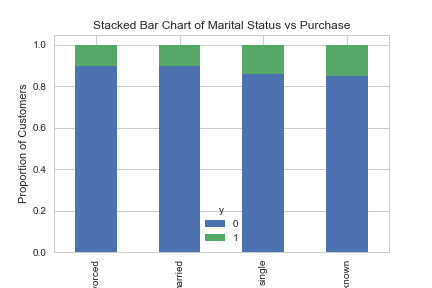
Семейное положение сильным фактором прогнозирования не выглядит:
table=pd.crosstab(data.education,data.y)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('Stacked Bar Chart of Education vs Purchase')
plt.xlabel('Education')
plt.ylabel('Proportion of Customers')
plt.savefig('edu_vs_pur_stack')
Также хорошим фактором прогнозирования выглядит категория образования:
pd.crosstab(data.day_of_week,data.y).plot(kind='bar')
plt.title('Purchase Frequency for Day of Week')
plt.xlabel('Day of Week')
plt.ylabel('Frequency of Purchase')
plt.savefig('pur_dayofweek_bar')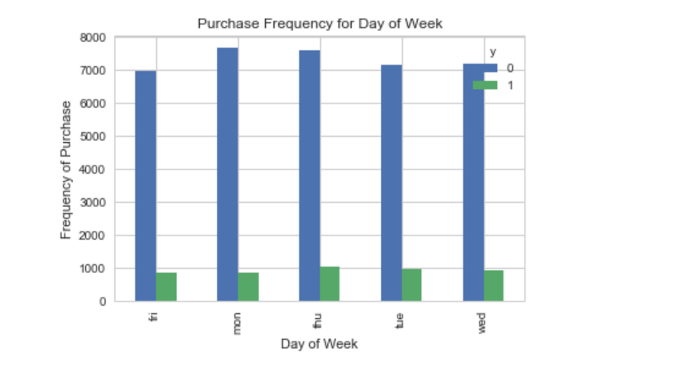
А день недели — нет:
pd.crosstab(data.day_of_week,data.y).plot(kind='bar')
plt.title('Purchase Frequency for Day of Week')
plt.xlabel('Day of Week')
plt.ylabel('Frequency of Purchase')
plt.savefig('pur_dayofweek_bar')
Хорошим фактором прогнозирования может быть месяц:
data.age.hist()
plt.title('Histogram of Age')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.savefig('hist_age')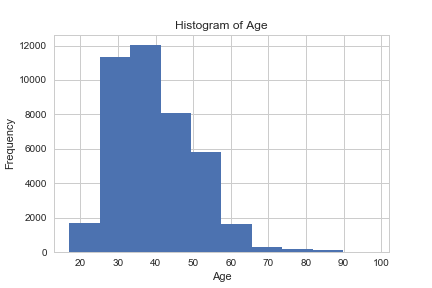
Большинству клиентов банка в этом наборе данных от 30 до 40 лет.
pd.crosstab(data.poutcome,data.y).plot(kind='bar')
plt.title('Purchase Frequency for Poutcome')
plt.xlabel('Poutcome')
plt.ylabel('Frequency of Purchase')
plt.savefig('pur_fre_pout_bar')
Наконец, хорошим фактором прогнозирования выглядит Poutcome.
Переменные-заглушки
Эти переменные содержат только значения 0 и 1.
cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
for var in cat_vars:
cat_list='var'+'_'+var
cat_list = pd.get_dummies(data[var], prefix=var)
data1=data.join(cat_list)
data=data1
cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
data_vars=data.columns.values.tolist()
to_keep=[i for i in data_vars if i not in cat_vars]И последние поля:
data_final=data[to_keep]
data_final.columns.values
Обогащение синтетическими данными через SMOTE
Я увеличу выборку данных о клиентах без вклада при помощи алгоритма SMOTE (Synthetic Minority Oversampling Technique). На высоком уровне он работает так:
- Генерирует синтетические выборки из минорного класса, а не создаёт копии.
- Случайно выбирает одного из k ближайших соседей и использует его, чтобы создать подобное, но случайно подстроенное наблюдение.
Реализуем этот алгоритм на Python:
X = data_final.loc[:, data_final.columns != 'y']
y = data_final.loc[:, data_final.columns == 'y']
from imblearn.over_sampling import SMOTE
os = SMOTE(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
columns = X_train.columns
os_data_X,os_data_y=os.fit_sample(X_train, y_train)
os_data_X = pd.DataFrame(data=os_data_X,columns=columns )
os_data_y= pd.DataFrame(data=os_data_y,columns=['y'])
# we can Check the numbers of our data
print("length of oversampled data is ",len(os_data_X))
print("Number of no subscription in oversampled data",len(os_data_y[os_data_y['y']==0]))
print("Number of subscription",len(os_data_y[os_data_y['y']==1]))
print("Proportion of no subscription data in oversampled data is ",len(os_data_y[os_data_y['y']==0])/len(os_data_X))
print("Proportion of subscription data in oversampled data is ",len(os_data_y[os_data_y['y']==1])/len(os_data_X))
Теперь данные сбалансированы идеально! Вы могли заметить, что я увеличила выборки только тренировочных данных; никакая информация из тестовых данных не используется для генерации синтетических наблюдений, то есть никакая информация тестового набора не утечёт в обучающие данные.
Рекурсивное устранение признаков
Рекурсивные устранение признаков построено на идее повторяющегося конструирования модели и выбора лучших и худших в смысле производительности признаков, а затем отбрасывания признака и повторения процесса до исчерпания всех данных. Цель — выбирать признаки, рекурсивно рассматривая всё меньшие и меньшие их множества.
data_final_vars=data_final.columns.values.tolist()
y=['y']
X=[i for i in data_final_vars if i not in y]
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
rfe = RFE(logreg, 20)
rfe = rfe.fit(os_data_X, os_data_y.values.ravel())
print(rfe.support_)
print(rfe.ranking_)
Метод помог выбрать следующие признаки: "euribor3m", "job_blue-collar", "job_housemaid", "marital_unknown", "education_illiterate", "default_no", "default_unknown", "contact_cellular", "contact_telephone", "month_apr", "month_aug", "month_dec", "month_jul", "month_jun", "month_mar", "month_may", "month_nov", "month_oct", "poutcome_failure", "poutcome_success".
cols=['euribor3m', 'job_blue-collar', 'job_housemaid', 'marital_unknown', 'education_illiterate', 'default_no', 'default_unknown',
'contact_cellular', 'contact_telephone', 'month_apr', 'month_aug', 'month_dec', 'month_jul', 'month_jun', 'month_mar',
'month_may', 'month_nov', 'month_oct', "poutcome_failure", "poutcome_success"]
X=os_data_X[cols]
y=os_data_y['y']Реализация модели
import statsmodels.api as sm
logit_model=sm.Logit(y,X)
result=logit_model.fit()
print(result.summary2())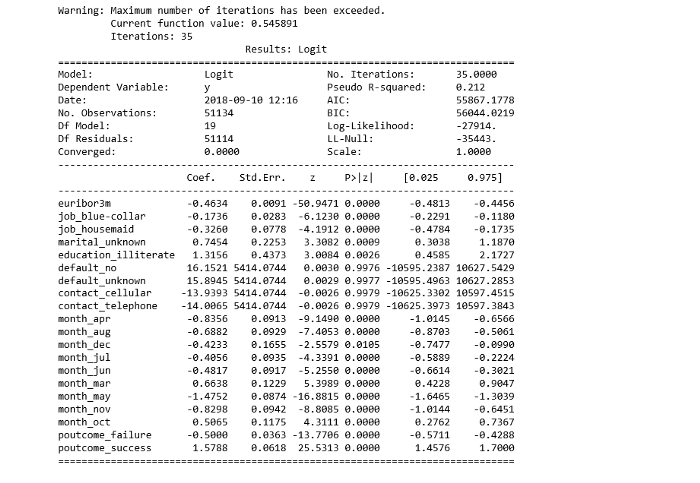
p-значение большинства переменных меньше 0,05, кроме четырёх, которые мы удалим:
cols=['euribor3m', 'job_blue-collar', 'job_housemaid', 'marital_unknown', 'education_illiterate',
'month_apr', 'month_aug', 'month_dec', 'month_jul', 'month_jun', 'month_mar',
'month_may', 'month_nov', 'month_oct', "poutcome_failure", "poutcome_success"]
X=os_data_X[cols]
y=os_data_y['y']
logit_model=sm.Logit(y,X)
result=logit_model.fit()
print(result.summary2())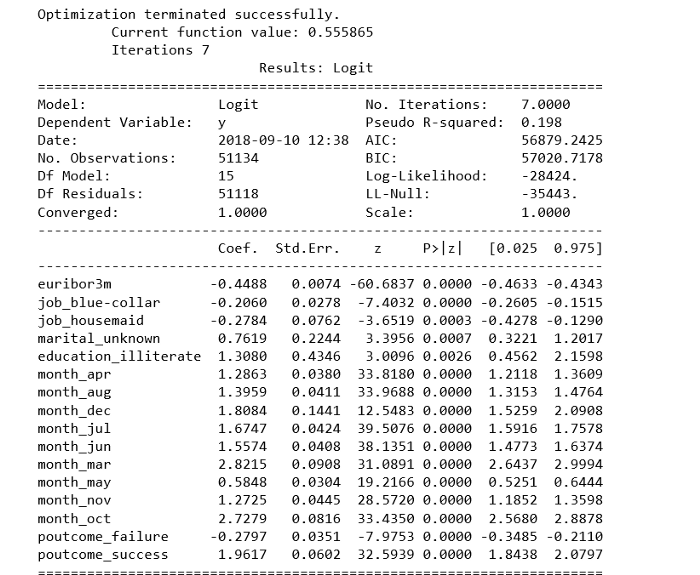
Обучение модели логистической регрессии
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
Прогноз на тестовом наборе и расчёт точности:
y_pred = logreg.predict(X_test)
print('Accuracy of logistic regression classifier on test set: {:.2f}'.format(logreg.score(X_test, y_test)))Точность классификатора логистической регрессии на тестовом наборе: 0,74
Матрица путаницы
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_pred)
print(confusion_matrix)[[6124 1542]
[2505 5170]]У нас 6124+5170 верных и 2505+1542 неверных прогнозов.
Расчёт точности, полноты, F-меры и носителя
Цитата от Scikit Learn:
Точность — это отношение tp/(tp + fp), где tp — число истинных и ложных срабатываний, а интуитивно — это способность модели не отмечать истинные примеры как ложные.
Полнота — это отношение tp/(tp + fn), то есть числа истинных и ложных срабатываний, а интуитивно — способность модели найти все истинные примеры.
Оценку F-beta можно понимать как взвешенное гармоническое среднее точности и полноты. Лучшее значение оценки — 1, худшее — 0. Эта оценка взвешивает полноту тщательнее точности, умножая её на коэффициент бета. Бета, равная 1.0, означает одинаковую важность полноты и точности.
Носитель — это количество вхождений каждого класса в y_test.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))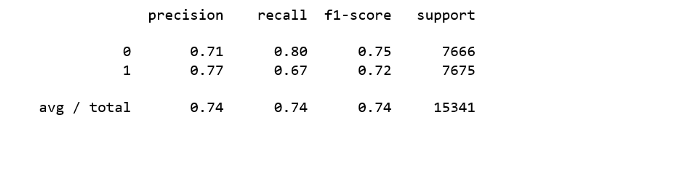
Интерпретация:
- 74% рекламируемых срочных депозитов из набора данных понравились клиентам.
- 74% срочных депозитов, которые предпочли клиенты, были прорекламированы.
ROC-кривая
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
logit_roc_auc = roc_auc_score(y_test, logreg.predict(X_test))
fpr, tpr, thresholds = roc_curve(y_test, logreg.predict_proba(X_test)[:,1])
plt.figure()
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.savefig('Log_ROC')
plt.show()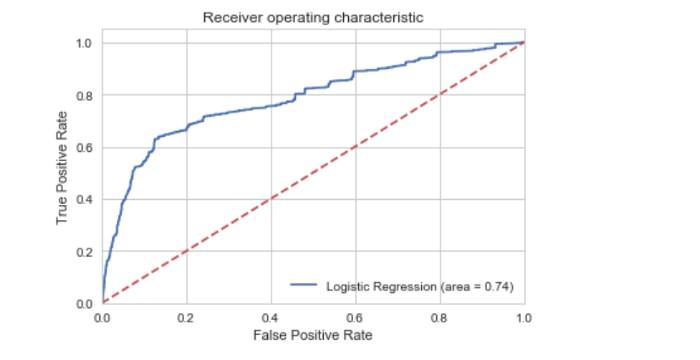
Рабочая характеристика приёмника — другой распространённый в бинарной классификации инструмент. Пунктирная линия здесь представляет кривую рабочей характеристики приёмника для чисто случайного классификатора, при этом график хорошего классификатора держится от пунктира как можно дальше, к левому верхнему углу.
Интерактивный блокнот для этого поста лежит здесь. Мне будет приятно получить отзыв или вопрос в комментариях.
Ссылка: Learning Predictive Analytics with Python
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом. Если вы не найдёте работу, мы просто вернём деньги (возврат — акция в рамках «Чёрной пятницы»).

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также