
Введение
Представляю вашему вниманию вторую часть статьи о создании расширения web-браузера Chrome, которое позволяет извлечь все изображения с web-страницы.
Данный материал, как и материал первой статьи предназначен для разработчиков, которые умеют писать web-приложения на современном JavaScript, но не пробовали создавать web-расширения для Google Chrome и хотели бы начать это делать. Эта и предыдущая статьи не являются исчерпывающим руководством или справочником о всех возможностях, которые доступны при создании расширений браузера, однако могут помочь быстро начать. Затем расширять свои знания можно с помощью официальной документации и справочника по API.
Первая часть опубликована здесь: https://habr.com/ru/post/703330/.
Напомню, что по итогам первой части мы создали расширение web-браузера, которое умеет извлекать URL-пути всех изображений текущей web-страницы и копировать их список в буфер обмена.
В этой части я покажу как автоматически упаковать все изображения этого списка в ZIP-архив и предложить пользователю его скачать. Также, мы создадим дополнительную страницу интерфейса, где пользователь сможет выбирать, какие картинки добавлять в ZIP-архив, а какие нет.
В итоге при правильном выполнении всех действий вы получите web-расширение браузера, которое будет выглядеть и работать так как показано на этом видео:
В итоге я опишу процесс публикации готового расширения в магазин Chrome Web Store.
Создание вкладки со списком изображений
Итак, в первой части список извлеченных изображений копировался в буфер обмена. Далее мы сделаем чтобы вместо буфера обмена, этот список отображался на новой странице в отдельной вкладке браузера. На этой странице мы создадим интерфейс, позволяющий пользователю выбрать все или некоторые из этих картинок для дальнейшей выгрузки в zip-архив.
Напомню, что список изображений формировался и копировался в буфер обмена при нажатии на кнопку "GRAB NOW" во всплывающем окне popup.html, в функции onResult, определенной в файле popup.js так, как показано ниже.
/**
* Выполняется после того как вызовы grabImages
* выполнены во всех фреймах удаленной web-страницы.
* Функция объединяет результаты в строку и копирует
* список путей к изображениям в буфер обмена
*
* @param {[]InjectionResult} frames Массив результатов
* функции grabImages
*/
function onResult(frames) {
// Если результатов нет
if (!frames || !frames.length) {
alert("Could not retrieve images from specified page");
return;
}
// Объединить списки URL из каждого фрейма в один массив
const imageUrls = frames.map(frame=>frame.result)
.reduce((r1,r2)=>r1.concat(r2));
// Скопировать в буфер обмена полученный массив
// объединив его в строку, используя возврат каретки
// как разделитель
window.navigator.clipboard
.writeText(imageUrls.join("\n"))
.then(()=>{
// закрыть окно расширения после
// завершения
window.close();
});
}Заменим все что связано с копированием в буфер обмена (все строки начиная с window.navigator.clipboard) на вызов функции openImagesPage(urls), которая будет открывать отдельную вкладку и показывать в ней все изображения из списка urls.
/**
* Выполняется после того как вызовы grabImages
* выполнены во всех фреймах удаленной web-страницы.
* Функция объединяет результаты в строку и копирует
* список путей к изображениям в буфер обмена
*
* @param {[]InjectionResult} frames Массив результатов
* функции grabImages
*/
function onResult(frames) {
// Если результатов нет
if (!frames || !frames.length) {
alert("Could not retrieve images from specified page");
return;
}
// Объединить списки URL из каждого фрейма в один массив
const imageUrls = frames.map(frame=>frame.result)
.reduce((r1,r2)=>r1.concat(r2));
// Скопировать в буфер обмена полученный массив
// объединив его в строку, используя возврат каретки
// как разделитель
openImagesPage(imageUrls)
}
/**
* Открывает новую вкладку браузера со списком изображений
* @param {*} urls - Массив URL-ов изображений для построения страницы
*/
function openImagesPage(urls) {
// TODO:
// * Открыть новую закладку браузера с HTML-страницей интерфейса
// * Передать массив `urls` на эту страницу
}Создадим теперь эту страницу и напишем функцию openImagesPage, которая будет ее открывать.
Расширение Chrome может содержать любое количество страниц. На данном этапе есть только popup.html. Это главная страница расширения. В ней список изображений извлекается и формируется. Теперь создадим вторую страницу, в которую этот список будет передаваться. Назовем ее page.html. Создайте эту страницу со следующим содержимым и сохраните ее в корневой папке расширения, то есть там же где и popup.html:
<!DOCTYPE html>
<html>
<head>
<title>Image Grabber</title>
</head>
<body>
<div class="header">
<div>
<input type="checkbox" id="selectAll"/>
<span>Select all</span>
</div>
<span>Image Grabber</span>
<button id="downloadBtn">Download</button>
</div>
<div class="container">
</div>
</body>
</html>Данная страница состоит из двух блоков. Для них назначены CSS-классы header и container. Блок заголовка содержит чекбокс для выбора всех изображений из списка и кнопку "Download", для их выгрузки. Блок container в данный момент пуст. Он будет содержать список изображений, которые будут переданы функцией openImagesPage из страницы popup.html.
После заполнения массивом URL-ов изображений и после применения CSS-стрилей, страница page.html будет выглядеть так:

Как видно, у каждой картинки будет чекбокс, позволяющий ее либо добавить, либо убрать из выборки.
Открытие новой вкладки браузера из расширения
Открыть новую вкладку браузера можно с помощью функции chrome.tabs.create из Chrome Tabs API, которая определена следующим образом:
chrome.tabs.create(createProperties, callback)createProperties- объект с параметрами, говорящими Chrome что открыть в новой вкладке и как. В частности, в параметре url указывается путь к странице, которую нужно открыть.callback- функция обратного вызова, которая исполняется после того как вкладка открылась. В качестве единственного параметра ей передается ссылка на созданную вкладку. Это объект Tab, содержащий различные методы и свойства созданной вкладки, включая ее уникальный идентификатор.
Теперь перепишем функцию openImagesPage, чтобы открыть новую вкладку:
function openImagesPage(urls) {
// TODO:
// * Открыть новую закладку браузера с HTML-страницей интерфейса
chrome.tabs.create({"url": "page.html"},(tab) => {
alert(tab.id)
// * Передать массив `urls` на эту страницу
});
}Если теперь вы запустите расширение и нажмете кнопку GRAB NOW, то должна открыться новая вкладка браузера с содержимым созданной ранее страницы page.html:

При вызове chrome.tabs.create была указана callback-функция, которая должна показывать оповещение с идентификатором созданной вкладки - alert(tab.id). В дальнейшем, эта функция будет отправлять список путей к картинкам в эту новую вкладку. Однако это не сработает и вы не увидите никакого оповещения. Это интересная ошибка, которую стоит подробнее рассмотреть.
Сначала вы нажимаете кнопку GRAB NOW на странице popup.html. При этом открывается страница page.html в новой вкладке браузера и эта вкладка активируется. При активации вкладки фокус перемещается на страницу page.html и уходит с всплывающего окна popup.html. В момент потери фокуса, всплывающее окно уничтожается и исчезает. Это происходит до того, как срабатывает функция callback, которая должна выполнить alert(tab.id). Как это исправить? Например, можно открыть новую вкладку, но не активировать ее в момент открытия, а активировать ее из кода позже, в самой функции callback, после того как она выполнится. Для этого нужно указать дополнительный параметр создания новой вкладки selected:false :
chrome.tabs.create({url: 'page.html', selected: false}, ...)Далее, callback должна передать данные в открытую вкладку и в конце активировать ее. В терминах Chrome API, активировать вкладку это значит "изменить статус вкладки на активный". Для изменения параметров вкладки, включая ее статус, используется функция chrome.tabs.update, определяемая следующим образом:
chrome.tabs.update(tabId, updateOptions, callback);tabId- идентификатор вкладки.updateOptions- объект с параметрами, которые нужно изменить.callback- функция обратного вызова, которая выполняется после того как изменения произведены.
Соответственно, для того чтобы активировать новую вкладку, нужно сделать такой вызов:
chrome.tabs.update(tab.id, {active: true});Свойство active устанавливается для только что созданной вкладки tab. Здесь мы не указывали callback-функцию за ненадобностью, так как все действия с новой вкладкой будут осуществлены до ее активации.
function openImagesPage(urls) {
// TODO:
// Открыть новую закладку браузера с HTML-страницей интерфейса
chrome.tabs.create({"url": "page.html"},(tab) => {
alert(tab.id)
// Передать массив `urls` на эту страницу
// сделать вкладку активной
chrome.tabs.update(tab.id, {active: true});
});
}Теперь все должно работать правильно при нажатии кнопки GRAB NOW - сначала создается вкладка со страницей page.html, затем появляется оповещение с идентификатором вкладки, затем вкладка с этим идентификатором активируется и только после этого, всплывающее окно с кнопкой GRAB NOW исчезает.
Теперь пришло время убрать этот временный alert и вместо него написать код, который будет передавать список путей к изображениям на страницу page.html.
Передача списка путей в новую вкладку
Для передачи данных на вновь созданную страницу мы воспользуемся встроенным механизмом обмена сообщениями. С его помощью, скрипт одной страницы может отправить сообщение с произвольными данными, а скрипт другой страницы может принять это сообщение, заполнить страницу данными из него и ответить отправителю о завершении.
Для отправки сообщений используется функция
chrome.tabs.sendMessage(tabId, message, responseFn)tabId- идентификатор вкладки браузера, в которую нужно передать сообщение.message- произвольный объект Javascript. В данном случае это будет массив путей к изображениям.responseFn- функция обратного вызова, которая выполнится после того, как принимающая сторона ответит на полученное сообщение. Эта функция получает один лишь аргументresponseObject. Это произвольный объект Javascript, который принимающая сторона может отправить вместе с ответом. (Об отправке ответов будет рассказано чуть позже)
Добавим отправку сообщения со списком URL в функцию openImagesPage:
function openImagesPage(urls) {
// Открыть новую закладку браузера с HTML-страницей интерфейса
chrome.tabs.create({"url": "page.html"},(tab) => {
chrome.tabs.sendMessage(tab.id, urls, (resp) => {
// сделать вкладку активной
chrome.tabs.update(tab.id, {active: true});
})
});
}Теперь эта функция сначала создает новую вкладку со страницей page.html, затем отправляет в нее массив urls как сообщение и после того как принимающая сторона ответит, делает эту вкладку активной.
Вкладке нужно некоторое время, чтобы загрузить страницу и скрипт, который будет принимать сообщение. Поэтому рекомендую сделать небольшую паузу после открытия вкладки и до отправки сообщения, то есть обернуть в setTimeout. Я добавил паузу в 100 миллисекунд:
function openImagesPage(urls) {
// Открыть новую вкладку браузера с HTML-страницей интерфейса
chrome.tabs.create({"url": "page.html"},(tab) => {
setTimeout(()=>{
// отправить список URL в новую вкладку
chrome.tabs.sendMessage(tab.id, urls, (resp) => {
// сделать вкладку активной
chrome.tabs.update(tab.id, {active: true});
})
},100)
});
}Прием списка путей и отображение их на странице page.html
Теперь перейдем к приему сообщения страницей page.html. Сообщение может быть принято только скриптом, поэтому создайте файл page.js и добавьте этот скрипт в page.html:
<!DOCTYPE html>
<html>
<head>
<title>Image Grabber</title>
</head>
<body>
<div class="header">
<div>
<input type="checkbox" id="selectAll"/>
<span>Select all</span>
</div>
<span>Image Grabber</span>
<button id="downloadBtn">Download</button>
</div>
<div class="container">
</div>
<script src="/page.js"></script>
</body>
</html>За прием сообщений отвечает событие chrome.runtime.onMessage. Этот объект содержит метод addEventListener(func), который позволяет установить функцию func для реакции на новые сообщения. В ней запустится процесс генерации HTML-разметки, показывающей список изображений на этой странице в блоке div с классом container. Добавьте следующий код в файл page.js:
chrome.runtime.onMessage
.addListener(function(message,sender,sendResponse) {
addImagesToContainer(message);
sendResponse("OK");
});
/**
* Функция, которая будет генерировать HTML-разметку
* списка изображений
* @param {} urls - Массив путей к изображениям
*/
function addImagesToContainer(urls) {
// TODO Создать HTML-разметку в элементе <div> с
// классом container для показа
// списка изображений и выбора изображений,
// для выгрузки в ZIP-архив
document.write(JSON.stringify(urls));
}
В этом коде мы добавили функцию реакции на сообщение. Эта функция содержит три параметра:
message- Принятый объект сообщения. В нашем случае это отправленный массивurlssender- Объект, который инициировал отправку сообщения. Это объект класса MessageSender.sendResponse- Функция, которую можно вызвать, чтобы отправить ответ объекту отправителю. В качестве параметра можно указать любые данные, которые необходимо отправить. В данном случае мы отправили строку "ОК", так как в данном случае не важно, что конкретно отправить, важен сам факт отправки ответа, чтобы отправляющая функция отреагировала на это событие.
В итоге мы приняли сообщение со списком URL, передали этот список в функцию addImagesToContainer и ответили отправителю фразой "OK". В ответ на это, отправляющая функция openImagesPage должна активировать данную вкладку.
На данном этапе, функция addImagesToContainer это просто прототип. Она выводит список изображений как JSON-строку:

Настоящий интерфейс предстоит создать в следующем разделе.
Создание функционала выгрузки изображений в ZIP-архив
Итак, используя кнопку "GRAB NOW" мы извлекли список путей ко всем картинкам текущей web-страницы и передали этот список на страницу page.html. Это все что нам было нужно от страницы popup.html и скрипта popup.js. С этого момента мы будем работать только со страницей page.html и в частности с ее скриптом page.js. Напомним, что эта страница содержит блок заголовка с кнопкой "Download" и флажком "Select all", а также блок container. Следующая задача это показать картинки из полученного списка в этом контейнере, а затем, запрограммировать флажок "Select all" и кнопку "Download", чтобы выделить их все и скачать в ZIP-архиве.
Создание HTML-разметки списка изображений
Измените функцию addImagesToContainer(urls) следующим образом:
/**
* Функция, для генерации HTML-разметки
* списка изображений
* @param {} urls - Массив путей к изображениям
*/
function addImagesToContainer(urls) {
if (!urls || !urls.length) {
return;
}
const container = document.querySelector(".container");
urls.forEach(url => addImageNode(container, url))
}
/**
* Функция создает элемент DIV для каждого изображения
* и добавляет его в родительский DIV.
* Создаваемый блок содержит само изображение и флажок
* чтобы его выбрать
* @param {*} container - родительский DIV
* @param {*} url - URL изображения
*/
function addImageNode(container, url) {
const div = document.createElement("div");
div.className = "imageDiv";
const img = document.createElement("img");
img.src = url;
div.appendChild(img);
const checkbox = document.createElement("input");
checkbox.type = "checkbox";
checkbox.setAttribute("url",url);
div.appendChild(checkbox);
container.appendChild(div)
}Функция addImagesToContainer сначала проверяет что список путей к изображениям не пуст и затем вызывает для каждого элемента функцию addImageNode. Эта функция генерирует HTML-элемент для каждой картинки и добавляет этот элемент в DIV с классом container. Для каждого элемента списка генерируется следующая разметка:
<div class="imageDiv">
<img src={url}/>
<input type="checkbox" url={url}/>
</div>Это обычный блок с классом "imageDiv". Этот класс будет использоваться в CSS. Этот блок содержит картинку с переданным url и флажок. Флажок также имеет атрибут url, который в дальнейшем будет использоваться для добавления картинки в ZIP-архив, если ее флажок включен.
Если нажать GRAB NOW сейчас, то вы увидите примерно такой интерфейс:

Под заголовком мы видим список изображений. С каждым изображением связан флажок. На данный момент и сами картинки и их флажки расположены хаотично. В дальнейшем мы применим CSS-стили чтобы это исправить.
Теперь сделаем так, чтобы этот интерфейс заработал, а именно, активируем флажок "Select All" и кнопку "Download".
Реализация функции для выбора всех картинок
Флажок выбора всех элементов имеет id=selectAll. Воспользуемся этим id для написания обработчика "change" этого флажка:
document.getElementById("selectAll")
.addEventListener("change", (event) => {
const items = document.querySelectorAll(".container input");
for (let item of items) {
item.checked = event.target.checked;
};
});Данная функция будет срабатывать при включении/выключении этого флажка. Ее задача установить статус этого флажка всем остальным флажкам страницы, то есть, всем флажкам картинок. Статус флажка selectAll находится в свойстве события event.target.checked. Если запустить интерфейс после добавления этого кода, то все флажки будут либо включаться, либо отключаться вместе с флажком Select All.
Реализация функции Download
При нажатии на кнопку Download должны происходить следующие действия:
Получение списка путей ко всем помеченным флажками изображениям
Загрузка всех этих изображений из интернета и добавление их в ZIP-архив
Показ пользователю приглашения скачать этот ZIP-архив
Кнопка "Download" имеет идентификатор downloadBtn. Соответственно, приведенные выше действия должны выполняться в функции обработчике события нажатия этой кнопки. Определим структуру этой функции:
document.getElementById("downloadBtn")
.addEventListener("click", async() => {
try {
const urls = getSelectedUrls();
const archive = await createArchive(urls);
downloadArchive(archive);
} catch (err) {
alert(err.message)
}
})
function getSelectedUrls() {
// TODO: Получить список всех включенных флажков,
// извлечь из каждого из них значение атрибута "url"
// и вернуть массив этих значений
}
async function createArchive(urls) {
// TODO: Создать пустой ZIP-архив, затем используя
// массив "urls", скачать каждое изображение, поместить
// его в виде файла в этот ZIP-архив и в конце
// вернуть этот ZIP-архив
}
function downloadArchive(archive) {
// TODO: Создать невидимую ссылку (тег <a>),
// которая будет указывать на переданный ZIP-архив "archive"
// и автоматически нажать на эту ссылку. Таким образом
// браузер откроет окно сохранения загруженного файла или
// автоматически загрузит его (зависит от типа ОС)
}В этом коде функция обработчик нажатия кнопки Download делает в точности 3 действия из списка выше. Для каждого действия будет использоваться отдельная функция. Все содержимое обработчика помещено в блок try/catch чтобы единообразно обработать любые исключения, возникающие в каждой из функций. Также, функция createArchive, которая скачивает картинки и создает из них ZIP-архив асинхронна и возвращает Promise. Здесь для работы с promise я использую метод async/await, вместо then(), чтобы сделать код проще и чище. Соответственно и функция createArchive объявлена как async, и сам обработчик нажатия кнопки Download, так как в нем используется ключевое слово await.
Реализуем эти функции одну за другой.
Получение списка выделенных изображений
Функция getSelectedUrl() запрашивает список всех флажков внутри контейнера, извлекает из каждого и них атрибут url и возвращает массив значений этих аттрибутов:
function getSelectedUrls() {
const urls =
Array.from(document.querySelectorAll(".container input"))
.filter(item=>item.checked)
.map(item=>item.getAttribute("url"));
if (!urls || !urls.length) {
throw new Error("Please, select at least one image");
}
return urls;
}Здесь запрашиваются все теги "input" внутри элемента с классом "container". В данном случае теги "input" это только флажки. Других полей ввода в списке изображений нет.
Если пользователь нажмет на кнопку не включив ни одного флажка, то будет выброшено исключение "Please select at least one image". Это исключение будет обработано вышестоящей функцией.
Загрузка изображений из списка
Функция createArchive получает список "urls" для скачивания. Картинки будем скачивать с помощью fetch. Это универсальная функция для выполнения HTTP-запросов любого типа и у нее может быть множество параметров. Однако в данном случае, достаточно отправить запрос GET с указанием пути:
const response = await fetch(url);Функция fetch выполняет запрос по указанному адресу и возвращает Promise с результатом выполнения этого запроса. Конструкция await разрешает этот Promise и возвращает результат запроса как объект Response, либо выбрасывает исключение, если запрос выполнить не удалось.
Объект response содержит сырой HTTP-ответ и набор методов и свойств, упрощающих работу с ним. В частности, в нем есть методы для получения тела ответа в различных форматах. Например, метод .text() позволяет получить ответ в виде текста, а .json() в виде объекта JSON. Однако мы скачиваем картинку и необходимо получить двоичные данные этой картинки. Для этого служит метод .blob(). Напишем часть функции, которая скачивает картинки и получает их двоичные данные:
async function createArchive(urls) {
for (let index in urls) {
const url = urls[index];
try {
const response = await fetch(url);
const blob = await response.blob();
console.log(blob);
} catch (err) {
console.error(err);
}
};
}Для каждого URL из списка, функция выполняет fetch запрос и затем извлекает объект BLOB из ответа на этот запрос. При возникновении исключения, она просто выводит сообщение об ошибке в консоль и пропускает эту картинку. (Можно обрабатывать исключения связанные с каждой картинкой как-то по другому, но я здесь не стал усложнять).
Двоичные данные каждой картинки это объект BLOB - Binary Large Object. Кроме непосредственно данных, он содержит некоторые полезные свойства для работы с ними, такие, как:
type- MIME-тип двоичных данных: https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types. Мы будем использовать это свойство, для того чтобы проверить, является ли загруженный файл картинкой. Для того чтобы это было так, MIME-тип должен бытьimage/jpeg,image/pngилиimage/webpили другим, начинающимся на "image/". Если загрузилось что-то иное, то этот файл можно пропустить и не обрабатывать.size- Размер двоичных данных. Если размер равен 0, то это значит что картинка пустая или не загрузилась и можно ее пропустить не обрабатывая.
У объектов BLOB есть и другие свойства, описанные в документации.
Далее нужно помещать загруженные файлы в архив, но есть одна проблема. У нас нет имен файлов. BLOB содержит только двоичные данные и их описание, но не имя файла. С одной стороны, можно использовать часть URL как имя файла, но далеко не всегда URL картинки это имя файла. Эти пути могут содержать много разного мусора, поэтому я решил не использовать их для этого. Вместо этого, в качестве имени файла будет использоваться просто порядковый номер, а в качестве расширения, последняя часть MIME-типа после "/".
Я решил написать отдельную функцию, которая проверит полученные двоичные данные и присвоит для них имя файла, если эти данные действительно являются не пустой картинкой. Вспомогательная функция называется checkAndGetFileName(index,blob):
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
const [type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension;
}Эта функция принимает порядковый номер изображения и его двоичные данные. Дальше она проверяет размер этих данных и их MIME-тип. Если размер положителен и MIME-тип содержит "image" в качестве первого компонента, то функция возвращает имя, состоящее из порядкового номера и второго компонента MIME-типа. Если проверка не пройдена, то выбрасывается исключение и эта картинка игнорируется.
Теперь все готово к созданию ZIP-архива.
Создание ZIP-архива
Самим реализовывать этот процесс довольно трудоемко, поэтому мы воспользуемся сторонней библиотекой JSZip: https://stuk.github.io/jszip/. Нужно скачать архив с этой библиотекой и распаковать. Можно использовать прямую ссылку на архив: https://github.com/Stuk/jszip/zipball/main.
Это довольно объемный архив, но нужен только один файл из него: dist/jszip.min.js. Нужно импортировать его в расширение. Для этого создайте какую-нибудь папку в корне расширения, например lib, скопируйте этот файл в эту папку и подключите в страницу page.html перед page.js:
<!DOCTYPE html>
<html>
<head>
<title>Image Grabber</title>
</head>
<body>
<div class="header">
<div>
<input type="checkbox" id="selectAll"/>
<span>Select all</span>
</div>
<span>Image Grabber</span>
<button id="downloadBtn">Download</button>
</div>
<div class="container">
</div>
<script src="/lib/jszip.min.js"></script>
<script src="/page.js"></script>
</body>
</html>При загрузке страницы с этой библиотекой, создается глобальный класс JSZip, который может использоваться для создания ZIP-архивов и добавления файлов в них. Процесс работы с ZIP-архивом с помощью этой библиотеки можно описать следующим псевдокодом:
const zip = new JSZip();
zip.file(filename1, blob1);
zip.file(filename2, blob2);
.
.
.
zip.file(filenameN, blobN);
const blob = await zip.generateAsync({
type:'blob',
compression:'DEFLATE',
compressionOptions:{
level: 9
}
});Сначала создается объект zip, затем в него добавляются файлы. Каждый файл определяется его именем и двоичным объектом BLOB. Затем, конструируется двоичный объект самого архива с помощью функции generateAsync. Эта функция принимает объект options с различными параметрами создания ZIP-архива. Среди них:
type- в каком виде сгенерировать ZIP-архив. Мы указали "blob", чтобы вернуть его как BLOB-объект. Бывают другие варианты, например ArrayBuffercompression- сжимать архив или нет.DEFLATE- сжимать,STORE- не сжимать.compressionOptions- параметры сжатия. В частности, параметрlevelопределяет уровень сжатия. Максимальный уровень это 9.
Здесь описаны только параметры, которые мы используем. Список всех возможностей библиотеки JSZip можно узнать в документации.
Теперь все готово для завершения функции createArchive:
async function createArchive(urls) {
const zip = new JSZip();
for (let index in urls) {
try {
const url = urls[index];
const response = await fetch(url);
const blob = await response.blob();
zip.file(checkAndGetFileName(index, blob),blob);
} catch (err) {
console.error(err);
}
};
return zip.generateAsync({
type:'blob',
compression: "DEFLATE",
compressionOptions: {
level: 9
}
});
}
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
[type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension;
}Сначала создается пустой ZIP-архив. Далее, в цикле, каждая картинка загружается и добавляется в архив. При этом с помощью функции checkAndGetFileName для нее генерируется имя. При возникновении ошибок на этапе загрузки или на этапе проверки функцией checkAndGetFileName часть картинок может быть отброшена. В итоге функция генерирует двоичные данные ZIP-архива и возвращает их.
Осталось последнее - дать пользователю скачать этот архив.
Создание ссылки для скачивания ZIP-архива
Чтобы дать пользователю возможность скачать файл, нужно создать ссылку на этот файл. В нашем случае нужно создать ссылку не на файл, а на BLOB. Для этого есть функция:
window.URL.createObjectURL(blob)Она возвращает ссылку, которую можно вставить как значение поля href в теге <a>. В данном случае мы не просто создадим ссылку, но и автоматически кликнем по ней, потому что пользователь уже и так нажал кнопку "Download" и зачем ему еще раз нажимать какую-то ссылку. Поэтому мы создадим невидимую ссылку и автоматически кликнем по ней из кода, чтобы пользователь просто скачал файл.
Все это реализуется в функции downloadArchive:
function downloadArchive(archive) {
const link = document.createElement('a');
link.href = URL.createObjectURL(archive);
link.download = "images.zip";
document.body.appendChild(link);
link.click();
URL.revokeObjectURL(link.href);
document.body.removeChild(link);
}Функция принимает BLOB с ZIP-архивом, создает HTML-элемент <a>, затем генерирует ссылку на переданный BLOB и устанавливает ее параметру href. Также в параметре download указывается имя файла, которое увидит пользователь. Затем ссылка добавляется на HTML-страницу и автоматически нажимается. Это приводит к скачиванию архива. Файл будет называться images.zip. Сразу же после этого ссылка удаляется из документа.
Вот и все с автоматизацией. Теперь стоит немного почистить код.
Итоговый код page.js
Чтобы освежить в памяти все что было сделано привожу полный листинг файла page.js с комментариями:
chrome.runtime.onMessage
.addListener(function(message,sender,sendResponse) {
addImagesToContainer(message);
sendResponse("OK");
});
/**
* Функция, генерирует HTML-разметку
* списка изображений
* @param {} urls - Массив путей к изображениям
*/
function addImagesToContainer(urls) {
if (!urls || !urls.length) {
return;
}
const container = document.querySelector(".container");
urls.forEach(url => addImageNode(container, url))
}
/**
* Функция создает элемент DIV для каждого изображения
* и добавляет его в родительский DIV.
* Создаваемый блок содержит само изображение и флажок
* чтобы его выбрать
* @param {*} container - родительский DIV
* @param {*} url - URL изображения
*/
function addImageNode(container, url) {
const div = document.createElement("div");
div.className = "imageDiv";
const img = document.createElement("img");
img.src = url;
div.appendChild(img);
const checkbox = document.createElement("input");
checkbox.type = "checkbox";
checkbox.setAttribute("url",url);
div.appendChild(checkbox);
container.appendChild(div)
}
/**
* Обработчик события "onChange" флажка Select All
* Включает/выключает все флажки картинок
*/
document.getElementById("selectAll")
.addEventListener("change", (event) => {
const items = document.querySelectorAll(".container input");
for (let item of items) {
item.checked = event.target.checked;
};
});
/**
* Обработчик события "onClick" кнопки Download.
* Сжимает все выбранные картинки в ZIP-архив
* и скачивает его.
*/
document.getElementById("downloadBtn")
.addEventListener("click", async() => {
try {
const urls = getSelectedUrls();
const archive = await createArchive(urls);
downloadArchive(archive);
} catch (err) {
alert(err.message)
}
})
/**
* Функция возвращает список URL всех выбранных картинок
* @returns Array Массив путей к картинкам
*/
function getSelectedUrls() {
const urls =
Array.from(document.querySelectorAll(".container input"))
.filter(item=>item.checked)
.map(item=>item.getAttribute("url"));
if (!urls || !urls.length) {
throw new Error("Please, select at least one image");
}
return urls;
}
/**
* Функция загружает картинки из массива "urls"
* и сжимает их в ZIP-архив
* @param {} urls - массив путей к картинкам
* @returns BLOB-объект ZIP-архива
*/
async function createArchive(urls) {
const zip = new JSZip();
for (let index in urls) {
try {
const url = urls[index];
const response = await fetch(url);
const blob = await response.blob();
zip.file(checkAndGetFileName(index, blob),blob);
} catch (err) {
console.error(err);
}
};
return await zip.generateAsync({
type:'blob',
compression: 'DEFLATE',
compressionOptions: {
level:9
}
});
}
/**
* Проверяет переданный объект blob, чтобы он был не пустой
* картинкой и генерирует для него имя файла
* @param {} index - Порядковый номер картинки в массиве
* @param {*} blob - BLOB-объект с данными картинки
* @returns string Имя файла с расширением
*/
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
const [type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension.split("+").shift();
}
/**
* Функция генерирует ссылку на ZIP-архив
* и автоматически ее нажимает что приводит
* к скачиванию архива браузером пользователя
* @param {} archive - BLOB архива для скачивания
*/
function downloadArchive(archive) {
const link = document.createElement('a');
link.href = URL.createObjectURL(archive);
link.download = "images.zip";
document.body.appendChild(link);
link.click();
URL.revokeObjectURL(link.href);
document.body.removeChild(link);
}Теперь если нажать кнопку GRAB NOW, затем выбрать либо все, либо определенные картинки и нажать кнопку Download, то zip-архив с именем images.zip будет загружен браузером. На данном этапе интерфейс выглядит примерно так:
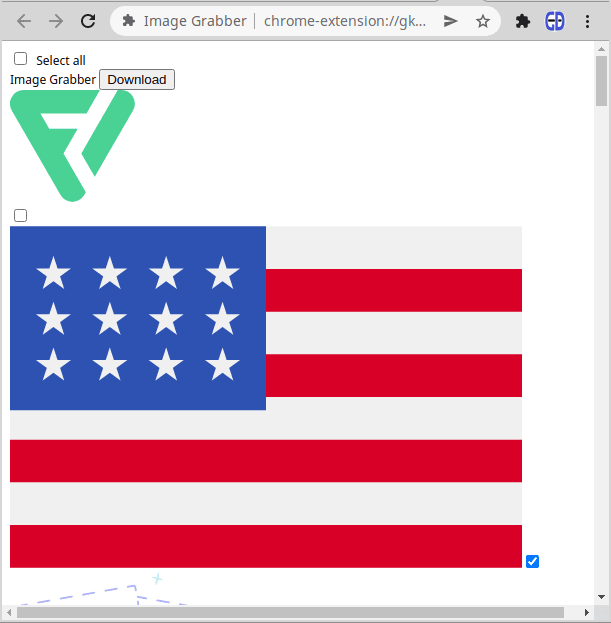
Этот интерфейс работает, но пользоваться совсем не удобно. Давайте стилизуем его.
Добавление CSS
Процесс стилизации страницы расширения не отличается от стилизации обычной HTML-страницы. Создайте файл page.css и добавьте ссылку на него на странице page.html.
<!DOCTYPE html>
<html>
<head>
<title>Image Grabber</title>
<link href="/page.css" rel="stylesheet" type="text/css"/>
</head>
<body>
<div class="header">
<div>
<input type="checkbox" id="selectAll"/>
<span>Select all</span>
</div>
<span>Image Grabber</span>
<button id="downloadBtn">Download</button>
</div>
<div class="container">
</div>
<script src="/lib/jszip.min.js"></script>
<script src="/page.js"></script>
</body>
</html>Как стилизовать интерфейс это дело вкуса, я например стилизовал так, как показано ниже. Добавьте следующий код в page.css:
body {
margin:0px;
padding:0px;
background-color: #ffffff;
}
.header {
display:flex;
flex-wrap: wrap;
flex-direction: row;
justify-content: space-between;
align-items: center;
width:100%;
position: fixed;
padding:10px;
background: linear-gradient( #5bc4bc, #01a9e1);
z-index:100;
box-shadow: 0px 5px 5px #00222266;
}
.header > span {
font-weight: bold;
color: black;
text-transform: uppercase;
color: #ffffff;
text-shadow: 3px 3px 3px #000000ff;
font-size: 24px;
}
.header > div {
display: flex;
flex-direction: row;
align-items: center;
margin-right: 10px;
}
.header > div > span {
font-weight: bold;
color: #ffffff;
font-size:16px;
text-shadow: 3px 3px 3px #00000088;
}
.header input {
width:20px;
height:20px;
}
.header > button {
color:white;
background:linear-gradient(#01a9e1, #5bc4bc);
border-width:0px;
border-radius:5px;
padding:10px;
font-weight: bold;
cursor:pointer;
box-shadow: 2px 2px #00000066;
margin-right: 20px;
font-size:16px;
text-shadow: 2px 2px 2px#00000088;
}
.header > button:hover {
background:linear-gradient( #5bc4bc,#01a9e1);
box-shadow: 2px 2px #00000066;
}
.container {
display: flex;
flex-wrap: wrap;
flex-direction: row;
justify-content: center;
align-items: flex-start;
padding-top: 70px;
}
.imageDiv {
display:flex;
flex-direction: row;
align-items: center;
justify-content: center;
position:relative;
width:150px;
height:150px;
padding:10px;
margin:10px;
border-radius: 5px;
background: linear-gradient(#01a9e1, #5bc4bc);
box-shadow: 5px 5px 5px #00222266;
}
.imageDiv:hover {
background: linear-gradient(#5bc4bc,#01a9e1);
box-shadow: 10px 10px 10px #00222266;
}
.imageDiv img {
max-width:100%;
max-height:100%;
}
.imageDiv input {
position:absolute;
top:10px;
right:10px;
width:20px;
height:20px;
}Данный стиль построен на базе Flexbox с использованием свойства flex-wrap. Благодаря этому интерфейс перестраивает себя так, чтобы корректно выглядеть на экранах различного размера.


ВСЕ! На этом мы заканчиваем создание расширения. Конечно его можно улучшать и отлаживать дальше, например, добавить больше проверок на типы загружаемых картинок, чтобы убрать лишний мусор. Однако в целом расширение готово к публикации в Chrome Web Store.
Публикация расширения в Chrome Web Store
После того как вы достаточно протестировали расширение установленное локально, пришло время дать другим возможность его скачивать и устанавливать. Процесс публикации расширения в Chrome Web Store чем-то похож на публикацию мобильного приложения в Google PlayMarket или в Apple AppStore. В связи с этим сразу оговорюсь: всё что будет описано далее может стать неактуальным при изменении правил в Google. Наиболее актуальное руководство по процессу и условиям публикации расширения есть на их сайте по этой ссылке: https://developer.chrome.com/docs/webstore/publish/. Соответственно, прежде чем выгружать расширение в Web Store, изучите эти материалы.
Все описанное ниже лишь отражает мой собственный опыт. Относитесь к этому критично и используйте только в качестве дополнительной информации.
Запакуйте папку с расширением в ZIP-архив.
Зарегистрируйтесь в Chrome Web Store по адресу https://chrome.google.com/webstore/devconsole/. При регистрации можно использовать уже существующий аккаунт Google, например зарегистрированный в GMail.
Оплатите разовую комиссию 5$.
В консоли Chrome Web Store создайте новый продукт (это и есть расширение).
При создании продукта нужно заполнить форму различной информацией о расширении и загрузить ZIP-архив с ним. Эту информацию будет видеть пользователь на странице расширения в Web Store. Она также включает изображения расширения различного размера. Также, можно предварительно создать видео для расширения, загрузить его в YouTube и указать ссылку на это видео в этой форме.
Необязательно заполнять всю форму сразу. Можно указать часть информации, затем нажать кнопку "Save Draft" и вернуться к заполнению позже. Когда оставшаяся информация будет готова, нужно будет найти данное расширение в списке продуктов, открыть его и продолжить заполнение.
После заполнения всей формы, нажмите кнопку "Submit for Review" и если все указано без ошибок, расширение будет отправлено на проверку в Google. Проверка может занять несколько дней. Статус проверки будет отображаться в списке продуктов.
В процессе ожидания периодически заходите и проверяйте статус, потому что Google может не оповестить по почте о том что проверка завершена.
Если расширение не прошло проверку, то будут указаны ошибки, которые необходимо исправить. После исправления нужно создать новый ZIP-файл, загрузить его в эту же форму и снова отправить на проверку. Насколько я знаю, ограничений на количество отправок нет или не было, когда я отправлял в последний раз.
После того как расширение успешно пройдет проверку, его статус изменится на "Published" и оно будет доступно для поиска и установки в Chrome Web Store: https://chrome.google.com/webstore/.
Отдельно остановлюсь на создании архива с расширением для проверки. Архив должен иметь как можно меньший размер, так как пользователи будут его скачивать себе на компьютеры. Расширение не должно содержать никаких лишних файлов. Должно быть только то, что реально используется расширением. Соответственно, если вы использовали различные фреймворки для создания интерфейса, то в архиве, отправляемом на проверку не должно быть никаких вспомогательных файлов WebPack, никаких package.json и т.п. Только manifest.json, HTML-страницы указанные в нем и JavaScript файлы, картинки и другие данные, используемые этими страницами. С другой стороны, все внешние библиотеки, используемые расширением тоже должны быть в составе расширения, то есть загружены в папку с расширением и использованы из нее. В коде не должно быть никаких внешних ссылок на скрипты в Интернете. Наличие ссылок на внешние библиотеки является основанием отклонить расширение при проверке из соображений безопасности, даже если это CDN-ссылка на безобидную JQuery. Файл manifest.json тоже не должен содержать ничего лишнего, к чему можно было бы придраться. Например, мое расширение один раз завернули из-за того, что в разделе "permissions" были указаны разрешения, которые реально не использовались в коде. Поэтому не нужно указывать как можно больше разрешений "на всякий случай". Это не пройдет. В описании каждого метода Chrome API указывается, какие разрешения для него требуются, поэтому добавляйте только то что нужно.
Расширение Image Grabber, созданное в этой статье, успешно прошло проверку с первого раза и было опубликовано. На весь процесс ушло два дня. Расширение можно найти и установить здесь.
Рекомендую создать его с нуля читая статью, однако для нетерпеливых его исходный код доступен здесь: https://github.com/AndreyGermanov/image_grabber.
Это расширение использует не более 5% из того что можно сделать с помощью Chrome API. Например, я опубликовал еще одно расширение для сервиса распознавания текста. Оно позволяет распознавать текст из картинок в браузере с помощью контекстного меню: https://chrome.google.com/webstore/detail/image-reader/acaljenpmopdeajikpkgbilhbkddjglh.
Все возможности можно узнать в документации. Изучайте и пробуйте! Успехов в учебе и в бою работе!
DonAlPAtino
Про setTimeout в openImagesPage() в статье ни слова. А без него не работает :-(. Причем с какой-то невнятной ошибкой.
germanov_dev Автор
Да действительно, пропустил этот блок. Теперь исправлено. Спасибо за замечание.