
Привет, Хабр!
Меня зовут Ольга Калинина я Data Scientist и являюсь участником профессионального сообщества NTA. В данной публикации рассмотрю расчет CATE посредством «причинных» случайных лесов с помощью библиотеки EconML, а также визуализацию результатов посредством библиотеки SHAP в Python.

При проведении эксперимента (А/Б теста) возникает потребность посчитать эффект воздействия (treatment) – меру изменения целевого признака (outcome) в результате этого эксперимента. Проще всего посчитать средний эффект воздействия (average treatment effect (ATE))– разницу средних целевого показателя в тритмент и в контрольной группах. А что, если эффект гетерогенен – то есть изменение целевой метрики – разное для разных групп? Рассмотрим простой пример: банк повысил льготную ключевую ставку, что повлекло за собой снижение спроса на квартиры. Но если рассмотреть квартиры в разрезе следующих категорий: эконом-класс, премиум и элитное жилье, то спрос на квартиры эконом-класса снизился значительно, в то время как спрос на элитное жилье никак не изменился, так как люди, покупающие элитное жилье, чаще всего не берут ипотеку, и на них изменение льготной ставки никак не повлияло. В таком случае рассчитывают CATE (Conditional Average Treatment Effect).
Фундаментальная проблема при проведении эксперимента – невозможность точного определения
для каждого наблюдения, так как наблюдаемый объект попадает либо в группу воздействия либо в контрольную группы. Средний эффект воздействия (ATE) помогает решить данную проблему: давайте найдем разницу целевого признака между одинаковыми людьми – то есть такими людьми, характеристики которых примерно равны. Простую разницу средних потенциальных исходов в качестве оценки эффекта воздействия можно использовать, если соблюдается баланс ковариат – характеристики людей в контрольной группе в среднем примерно равны характеристикам людей в группе воздействия.
Все осложняется реальной жизнью и реальными данными. В реальной жизни при проведении эксперимента на целевой признак может влиять не только наличие какого-либо treatment, но и ковариаты – характеристики наблюдения (см. Рисунок 1).
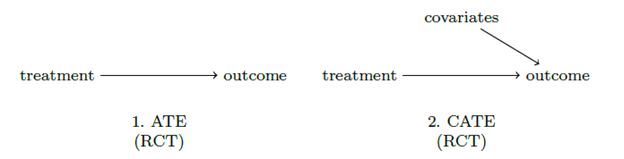
Рисунок 1: Влияние эффекта воздействия и ковариат на исход. Источник: (Jacob et al., 2021)
Из этого следует, что внутри каждой группы эффект воздействия будет разный. Почему же тогда нельзя посчитать простую разницу средних внутри каждой группы каждой характеристики? Во-первых, потому что в реальной жизни большинство данных – небинарные и соответственно, непрерывные, что делает расчет разницы средних в разрезе определенной характеристики невозможным. Во-вторых, ни обратной, ни прямой корреляции может и не быть между характеристикой и целевым признаком, поэтому считать разницу средних и интерпретировать её не имеет никакого смысла (см. Рисунок 1).

Рисунок 1 Соотношение значения характеристики и потенциального исхода. Показательный пример того, что попадание в группу воздействия никак не влияет на потенциальный исход
Одним из методов определения наиболее важных ковариат в части «вложения» в эффект воздействия является причинный случайный лес (causal random forest). Причинный случайный лес похож на случайный лес. В то время как случайный лес делает сплит, основываясь на следующих критериях: ошибке классификации, энтропии или индексу Джини, причинный случайный лес делает сплит таким образом, чтобы максимизировать разницу эффекта воздействия между ветками дерева. Формально (Athey and Imbens (2016)) – критерий сплита - С:
То есть разделение дерева на листья максимизирует функцию критерия, которая вознаграждает разделение, увеличивающее дисперсию разницы эффекта между листьями и наказывает за разделение, увеличивающее дисперсию внутри листа. Цель состоит в том, чтобы точно оценить эффект воздействия между листьями, сохраняя при этом неоднородность по листьям. Разделение выполняется до тех пор, пока оно увеличивает функцию критерия по сравнению с отсутствием разделения.
После построения дерева внутри каждого листа считается эффект воздействия как простое ATE. Заключительный шаг состоит в следующем: возвращаемся к полной выборке, изучаем, к какому листу принадлежит каждое наблюдение, основываясь на значениях его ковариат и определяем, что прогнозируемый эффект воздействия наблюдения равен эффекту воздействия внутри листа. Учитывая, что оценка эффекта воздействия одного дерева может иметь высокую дисперсию, для её снижения строим несколько таких деревьев, которые в совокупности и образуют причинный случайный лес. Итоговый эффект воздействия для каждого наблюдения равен усредненным эффектам воздействия наблюдения от каждого дерева.
Необходимо обратить внимание на то, что важно использовать независимые случайные выборки, чтобы растить дерево и оценивать эффект воздействия внутри каждого листа дерева. Это свойство называется честностью. Честность ведет к двум важным аспектам. Во-первых, она уменьшает смещение от переобучения. Во-вторых, делает вывод обоснованным, так как асимптотические свойства оценок эффекта воздействия такие же, как если бы структура дерева была задана экзогенно. Подробнее параметры модели будут рассмотрены далее.
Перейдем к практике. Будем использовать предобработанный “игрушечный” датасет компании, которая занимается продажей билетов на разные виды транспорта на своем сайте и зарабатывает на наценке. Предположим, в качестве эксперимента наценка была увеличена с 3% до 6%. В нашем датасете более 30 ковариат и бинарная зависимая переменная - “buy”, которая равна 1, если пользователь приобрел билет, и 0, если нет. Полное описание переменных можно посмотреть здесь, но для понимания достаточно знать, что:
buy - факт совершения покупки билета;
final_rating_{min, max, mean} - характеристики рейтинга в выдаче (на основе отзывов пользователей);
dist – расстояние, на которое осуществляется перевозка (км);
depth – глубина поиска (т.е. через сколько дней планируется поездка);
direction_conv – показатель, связанный с конверсией по данному направлению;
dep_fr_sat_sun – бинарная характеристика поиска: =1, если отъезд в пятницу, субботу или воскресенье;
global_source_marketing = 1, если пользователь пришёл в интернет-магазин через рекламное объявление, 0 иначе.
Загружаем данные.
import pandas as pd
df= pd.read_excel('/Users/olgakalinina/Desktop/dataset_for_cate.xlsx')
df.sample(5)
Перед тем, как растить причинный случайный лес, посмотрим на описательную статистику переменных.
Строим корреляционную матрицу для тех переменных, у которых корреляция по модулю больше 0.5 (см. Рисунок 2)
import matplotlib.pyplot as plt
dfCorr = df.drop(['ID'], axis=1).corr()
filteredDf = dfCorr[((dfCorr >= .5) | (dfCorr <= -.5)) & (dfCorr !=1.000)]
for column in filteredDf.columns:
if filteredDf[column].isna().sum() == len(filteredDf):
filteredDf=filteredDf.drop(column, axis=1)
filteredDf=filteredDf.drop(column)
plt.figure(figsize=(15,5))
sns.heatmap(filteredDf, annot=True, vmin=-1, vmax=1, center= 0, cmap= 'coolwarm')
plt.show()
Посчитаем VIF между переменными и выведем переменные, VIF которых > 10 (см. Таблицу 1). (Подробнее о VIF можно почитать здесь, но понятийно: VIF между переменными больше 10 говорит о высокой мультиколлинеарности между переменными).
from statsmodels.stats.outliers_influence import variance_inflation_factor
X=['T', 'bus_offers_count', 'passenger_count', 'direction_conv',
'price_mean', 'price_min', 'price_max', 'price_std',
'final_rating_mean', 'final_rating_min', 'final_rating_max',
'final_rating_std', 'dist', 'depth', 'global_source_direct',
'global_source_marketing', 'bus_entry', 'serch_wen_th',
'serch_fr_sat_sun', 'dep_wen_th', 'dep_fr_sat_sun', 'arrival_huge_city',
'arrival_avg_city', 'departure_huge_city', 'departure_avg_city',
'arrival_msk', 'departure_msk', 'arrival_spb', 'departure_spb',
'avia_pages', 'train', 'etrain', 'bus_pages', 'tours', 'avia_orders',
'bus_orders', 'zhd']
def vif (data, X):
vif_data = pd.DataFrame()
vif_data["feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i)
for i in range(len(X.columns))]
return(pd.DataFrame(vif_data))
vif=vif(df, df[X])
vif=vif[vif['VIF'] > 10].round(3)feature |
VIF |
price_mean |
283,028 |
price_min |
125,601 |
price_max |
65,615 |
final_rating_mean |
1398,219 |
final_rating_min |
392,789 |
final_rating_max |
1383,856 |
final_rating_std |
13,031 |
dist |
26,198 |
Таблица 1: VIF ковариат больше 10
Коэффициент корреляции и VIF показал, что существует высокая мультиколлинеарность между переменными. Неудивительно, учитывая, что у нас 37 характеристик. Можно было бы отобрать характеристики вручную, основываясь на логике, коэффициенте корреляции и VIF, но тогда существует вероятность выкинуть неочевидную важную характеристику. Причинный случайный лес, основываясь на функции критерия, помогает нам определить наиболее важные характеристики, поэтому растим причинный случайный лес на всем датасете.
import numpy as np
from econml.dml import CausalForestDML
X=['bus_offers_count', 'passenger_count', 'direction_conv',
'price_mean', 'price_min', 'price_max', 'price_std',
'final_rating_mean', 'final_rating_min', 'final_rating_max',
'final_rating_std', 'dist', 'depth', 'global_source_direct',
'global_source_marketing', 'bus_entry', 'serch_wen_th',
'serch_fr_sat_sun', 'dep_wen_th', 'dep_fr_sat_sun', 'arrival_huge_city',
'arrival_avg_city', 'departure_huge_city', 'departure_avg_city',
'arrival_msk', 'departure_msk', 'arrival_spb', 'departure_spb',
'avia_pages', 'train', 'etrain', 'bus_pages', 'tours', 'avia_orders',
'bus_orders', 'zhd']
y=['buy']
X=df[X]
Y=np.ravel(df[y])
T = df['T']
W=None
causal_forest_buy = CausalForestDML(criterion='het', n_estimators=10000,
min_samples_leaf=10,
max_depth=4,
cv=10,
min_samples_split=50)Стоит подробнее остановиться на некоторых параметрах модели.
1) criterion ({"mse", "het"}, default=”mse”). MSE - средняя квадратическая ошибка. Для оценки гетерогенного эффекта выбираем HTE (heterogeneous treatment effect).
2) n_estimators - количество деревьев в лесу.
3) min_samples_leaf - минимальное количество наблюдений в листе.
4) max_depth - максимальная глубина дерева. Предпочтительнее выбирать меньше 7, чтобы деревья не переобучались.
5) cv - количество частей для кросс-валидации
6) min_samples_split - минимальное количество наблюдений в листе для дальнейшего сплита.
Обучаем модель
causal_forest_buy.fit(Y, T, X=X, W=W)Оцениваем ATE - средний эффект воздействия
print(causal_forest_buy.const_marginal_effect(X).mean())0.006
Смотрим на статистические значения среднего эффекта воздействия.
causal_forest.const_marginal_ate_inference(X)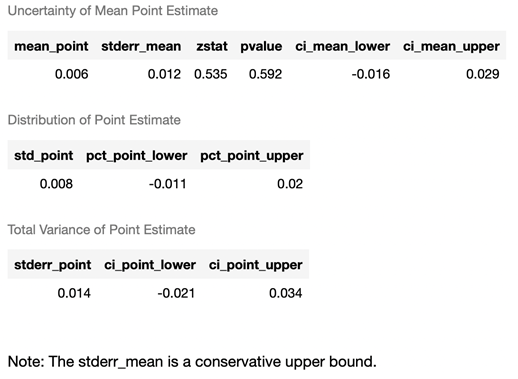
Эффект положительный, но так как p-value > 0.1 то он статистически незначимый даже на 10%-ном уровне значимости.
Рассмотрим топ-5 наиболее важных характеристик в нашем лесу (см. Таблицу 2). Важность характеристики прямо зависит от степени неоднородности значений, которая она принимает. Важность признака вычисляется как (нормализованная) общая неоднородность, которую создает ковариата. Каждое разделение, в котором была выбрана характеристика, увеличивает важность характеристики. Каждое разделение также взвешивается по глубине разделения. Чем меньше глубина, тем больше вес данной характеристики в расчете важности. По умолчанию разбиения ниже max_depth=4 не используются в расчете.
features=[]
features=np.array(list(zip(causal_forest_buy.cate_feature_names(), causal_forest_buy.feature_importances_.tolist())))
features=pd.DataFrame(features).rename(columns={0: 'covariate', 1: 'importance'}).round(3)
features_table=features.sort_values(by='importance', ascending=False).head(5)covariate |
importance |
direction_conv |
0.218 |
final_rating_min |
0.117 |
depth |
0.097 |
final_rating_mean |
0.079 |
price_std |
0.057 |
Таблица 2: топ-5 переменных по важности
Также можно рассчитать эффект воздействия для каждого наблюдения, найти его стандартную ошибку и прочие статистические значения.
treatment_effects = causal_forest_buy.const_marginal_effect(X)
te_lower, te_upper = causal_forest_buy.const_marginal_effect_interval(X)
res = causal_forest_buy.const_marginal_effect_inference(X)
res.summary_frame()
Перейдем к визуализации эффекта. В библиотеке SHAP для оценки важности характеристик рассчитывают значения Шепли. Понятийно происходит оценка предсказаний модели с и без данной характеристики. Формально (см. Рисунок 2):
)")
P (S U {i})— это предсказание модели с i-той характеристикой,
p(S) — это предсказание модели без i-той характеристики,
n — количество характеристик,
S — произвольный набор фичей без i-той характеристики.
Визуализируем важность характеристик с помощью библиотеки SHAP (см. Рисунок 2).
shap_values = causal_forest_buy.shap_values(X)
shap.summary_plot(shap_values['Y0']['T'])
Характеристики на рисунке 2 ранжированы по важности - сверху самые важные характеристики, снизу наименее важные. Основываясь на критерии Шепли, наиболее важные характеристики - direction_conv, final_rating_min, depth, dep_fr_sat_sun, final_rating_mean. Эти результаты почти совпадают с наиболее важными характеристиками, полученными причинным случайным лесом, а также с логикой. Визуализация, полученная с помощью библиотеки SHAP, позволяет сделать конструктивные выводы. Напомню, что причинный случайный лес показал, что эффект воздействия положительный, но статистически незначимый. Но в разрезе категорий получается следующие результаты:
1) Чем выше конверсия (direction_conv), средний (final_rating_mean) и минимальный рейтинг (final_rating_min) на направление, тем выше эффект воздействия на факт свершения покупки после повышения наценки. Это можно объяснить тем, что билеты на популярные направления и качественные билеты всегда будут раскуплены, несмотря на высокие цены. К тому же, повышение цены на популярные направления и качественные билеты может даже создать “ажиотажный спрос” - люди будут думать, что билетов осталось очень мало, что их вот-вот раскупят, поэтому также покупают их, несмотря на высокую наценку.
2) Существует отрицательный эффект воздействия между глубиной поиска (depth) и вероятностью покупки билетов. Очевидно, что если люди ищут билеты заранее, то у них остается время на поиск билетов без комиссии и они отказываются от покупки билетов с наценкой. В то время как людям, ищущим билеты на незапланированные поездки, за день или за два дня, все равно на наценку, им важнее приобрести билеты на срочную поездку.
3) Вероятность покупки на билеты на пятницу/субботу/воскресенье (dep_fr_sat_sun) увеличивается после введение наценки, скорее всего, из-за создания “ажиотажного” спроса, как и в случае с конверсией и рейтингом.
4) Интересно также отметить, обратную связь между переменной (global_source_marketing) и вероятностью покупки после введения большей наценки. Если человек пришел на сайт через рекламное объявление, то, как показывают результаты, он, видя наценку, покидает сайт, не купив ничего.
Результат
Итак, рассмотрев эффект воздействия среди разных групп внутри одной характеристики, можно контролировать эффект воздействия в будущем. В нашем примере, если компания хочет повысить наценку и все равно сохранить количество купленных билетов на сайте, после анализа данных можно прийти, например, к следующей ценовой политики:
1) Увеличить наценку на билеты с высокой конверсией, высоким средним и минимальным рейтингом, а также на билеты на пятницу/субботу/воскресенье.
2) Оставить такую же наценку для билетов, которые покупаются заранее, а также для людей, которые пришли на сайт через рекламное объявление.
С одной стороны, такая ценовая политика позволит увеличить общее количество покупаемых билетов, с другой стороны, оставить (не снизить) количество покупаемых билетов на том же уровне для людей, покупающих билеты заранее, а также для людей, которые приходят на сайт с рекламного объявления.
CATE - удобный алгоритм, чтобы посчитать гетерогенный эффект воздействия, а также определить наиболее важные характеристики. В Python причинный случайный лес можно строить с помощью библиотеки EconML. В то время как библиотека SHAP позволяет визуализировать результаты для дальнейшего представления выводов.
Источники:
1) Филипп Картаев “Введение в эконометрику”: учебник. – М.: Экономический фа- культет МГУ имени М.В. Ломоносова, 2019. – 472 с. ISBN 978-5-906932-22-8
2) S Athey and GW Imbens. Machine learning methods economists should know about, arxiv. 2019
3) Jacob, Daniel, CATE meets ML - Conditional Average Treatment Effect and Machine Learning (March 30, 2021). Available at SSRN: https://ssrn.com/abstract=3816558 or http://dx.doi.org/10.2139/ssrn.3816558