
Вновь привет, уважаемые читатели Хабра! Работая с одной из систем хранения метаданных о файлах в «Лаборатории Касперского» вспомнил, что давно хотел написать об оптимизации поиска по большому полю в базах данных. О чем далее и расскажу более подробно.
В данной публикации будет рассмотрена оптимизация поиска по полю бинарного массива и, в частности, по равномерно распределенным данным, а также сравнение между собой выявленных способов.

Итак, представьте: у вас есть таблица в базе данных MS SQL, в которой десятки миллиардов строк данных. И в эту таблицу вставляются и удаляются суммарно десятки и сотни тысяч строк в секунду. Назовем эту таблицу dbo.metadata.
Замечание. Для проведенного анализа ниже была создана новая база данных TEST, в которой были созданы две таблицы dbo.metadata и dbo.sha256_checksum (о второй таблице будет написано ниже) и сгенерированы синтетические данные на 1+ млрд строк в каждую. После каждого вызова запроса проводился полный сброс кэша планов для базы данных TEST (DBCC FREEPROCCACHE), чтобы план для запроса каждый раз строился заново, а не брался уже готовый.
Таблица dbo.metadata упрощенно выглядит так:
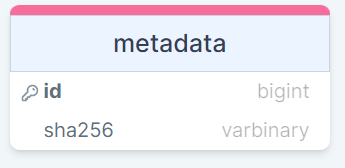
Определение таблицы dbo.metadata
и определяется следующим образом:
Здесь получили следующую структуру таблицы dbo.metadata:
Стоит задача быстро искать по хэшу, то есть по полю sha256.
Реализовать это можно следующим образом:

Определение индекса по полю sha256
И далее искать по этому полю:
Здесь и далее будем использовать вывод статистики по операциям ввода-вывода и времени выполнения запроса:
Получили следующую статистику для запроса:
Получили следующий план запроса:

Действительный план выполнения запроса при использовании индекса IX_sha256_metadata
В свойствах элемента «Поиск в индексе» (Index Seek) получили следующие данные:

Свойства элемента «Поиск в индексе» (Index Seek) действительного плана выполнения запроса при использовании индекса IX_sha256_metadata
То есть из плана видим, что нужный индекс IX_sha256_metadata используется правильно для поиска нужного значения. Также предполагаемое количество операций и количество строк совпадают с фактическим, то есть план «не поехал». Так как в выборке мы вытаскиваем только поле id — идентификатор записи, то нам не нужно обращаться к кластерному индексу за ним, так как все некластерные индексы содержат в себе ключевые поля кластерного индекса. А в нашем случае как раз поле id является ключевым полем кластерного индекса pk_metadata в таблице dbo.metadata.
Теперь узнаем, сколько весит сам индекс IX_sha256_metadata. Для этого воспользуемся следующим запросом:
В нашем случае получилось почти 6 ГБ для 1 млрд строк данных.
Здесь мы использовали системную функцию CHECKSUM, которая возвращает хэш по входящему значению.
Проиндексировать данное поле с включением поля sha256:
И по этому полю делать фильтрацию:
Получили следующую статистику для запроса:
Получили следующий план запроса:

Действительный план выполнения запроса при использовании индекса IX_sha256_checksum_metadata
В свойствах элемента «Поиск в индексе» (Index Seek) получили следующие данные:

Свойства элемента «Поиск в индексе» (Index Seek) действительного плана выполнения запроса при использовании индекса IX_sha256_checksum_metadata
То есть из плана видим, что нужный индекс IX_sha256_checksum_metadata используется правильно для поиска нужного значения. Также предполагаемое количество операций и количество строк совпадают с фактическим, то есть план «не поехал». Так как в выборке мы вытаскиваем только поле id — идентификатор записи, то нам не нужно обращаться к кластерному индексу за ним, так как все некластерные индексы содержат в себе ключевые поля кластерного индекса. А в нашем случае как раз поле id является ключевым полем кластерного индекса pk_metadata в таблице dbo.metadata. Также, так как мы включили поле sha256 в индекс IX_sha256_checksum_metadata, мы можем данное поле использовать в запросе как в выборке, так и в фильтрации без обращений к кластерному индексу pk_metadata.
Теперь узнаем, сколько весит сам индекс IX_sha256_checksum_metadata. Для этого воспользуемся следующим запросом:
В нашем случае получилось почти 10 ГБ для 1 млрд строк данных (то есть в 1,6 раз больше, чем занимает предыдущий рассматриваемый индекс IX_sha256_metadata в 6 ГБ).
В чем разница между использованием индекса IX_sha256_metadata и индекса IX_sha256_checksum_metadata? По статистике операций ввода-вывода видим, что все идентично, кроме следующей секции: SQL Server parse and compile time. Для индекса IX_sha256_metadata получили CPU time = 750 ms, elapsed time = 762 ms, а для индекса IX_sha256_checksum_metadata получили CPU time = 516 ms, elapsed time = 542 ms.
Давайте сымитируем нагрузку на таблицу dbo.metadata, а именно асинхронно включим вставки в 1000–10 000 строк в секунду синтетических данных. Тогда получим, что разница будет в использовании этих двух индексов между собой только опять в этой секции SQL Server parse and compile time, при этом значения будут следующими:
Секция SQL Server parse and compile time говорит о том, что выигрыш будет, когда по каким-либо причинам плана запроса нет в кэше. Но в нагруженной системе нередко бывает, когда план запроса в кэше как раз находится недолго или вообще не гарантирует сохраняться.
Таким образом, видим, что лучше всего поиск сначала проводить не по значению большого поля sha256, а по его маленькой части (например, хэша) sha256_checksum. И затем уже из найденного множества значений искать по значению большого поля sha256.
Примечание. Такая же идея поиска лежит во многих языках программирования с управляемой памятью: C#, Java и т. д. То есть сначала сравниваются значения хэшей объектов ссылочного типа, и если они совпадают, то только тогда идет сравнение по заранее предопределенному кодом правилу (в нашем случае каждое поле).
Можно пойти дальше в оптимизации. Тогда большое поле, такое как sha256, необходимо хранить отдельно от основной таблицы dbo.metadata. Например, определив для этого таблицу dbo.sha256_checksum следующим образом:

Определение таблицы dbo.sha256_checksum и ее связь с таблицей dbo.metadata
Здесь получили следующую структуру таблицы dbo.sha256_checksum:
Первичным ключом pk_sha256_checksum таблицы dbo.sha256_checksum, реализованным через уникальный кластерный индекс, является пара полей (sha256_checksum, file_id).
Тогда поиск нужного id записи будет осуществляться следующим запросом:
Примечание. Здесь скорость чтения получили примерно такую же, как при использовании индекса IX_sha256_checksum_metadata в таблице dbo.metadata. Но, отделив большое поле от основной таблицы dbo.metadata, мы тем самым убрали его из хранения кластерного индекса pk_metadata таблицы dbo.metadata, что снизит нагрузку на операцию чтения и записи для этой таблицы. Данное разделение особенно полезно, если поле sha256 было бы очень большим, то есть свыше 4000 байт.
И далее при необходимости с полученным идентификатором записи можно обратиться к основной таблице dbo.metadata для получения нужных полей со следующим запросом:
Таким образом, мы разделили данные, что позволит более оптимально хранить, записывать и читать данные.
Еще большей оптимизации можно добиться в нашем примере, если вместо функции CHECKSUM использовать подстроку substring (sha256, 1, 8). Возвращаемый тип будет bigint:
Тогда поиск нужно осуществлять следующим запросом:
Получили следующую статистику для запроса:
Получили следующий план запроса:

Действительный план выполнения запроса при использовании индекса IX_sha256_prefix
В свойствах элемента «Поиск в индексе» (Index Seek) получили следующие данные:

Свойства элемента «Поиск в индексе» (Index Seek) действительного плана выполнения запроса при использовании индекса IX_sha256_prefix
То есть из плана видим, что нужный индекс IX_sha256_prefix используется правильно для поиска нужного значения. Также предполагаемое количество операций и количество строк совпадают с фактическим, то есть план «не поехал». Так как в выборке мы вытаскиваем только поле file_id — идентификатор записи, то нам не нужно обращаться к кластерному индексу за ним, так как все некластерные индексы содержат в себе ключевые поля кластерного индекса. А в нашем случае как раз поле file_id является ключевым полем кластерного индекса pk_file_sha256_checksum в таблице dbo.sha256_checksum. Также, так как мы включили поле sha256 в индекс IX_sha256_prefix, мы можем данное поле использовать в запросе как в выборке, так и в фильтрации без обращений к кластерному индексу pk_sha256_checksum.
Напомню, что при 10 000 000 000 строк данных в таблице dbo.sha256_checksum и при использовании индекса IX_sha256_checksum_metadata мы получили время выполнения запроса 1506 мсек:
А при использовании индекса IX_sha256_prefix таблицы dbo.sha256_checksum мы видим, что время выполнения почти в 2 раза меньше, то есть 800+ мсек:
Такую скорость удается достичь, только если значения столбца sha256 равномерно распределены, а метод как раз обеспечивает это.
Источники:
В данной публикации будет рассмотрена оптимизация поиска по полю бинарного массива и, в частности, по равномерно распределенным данным, а также сравнение между собой выявленных способов.
Итак, представьте: у вас есть таблица в базе данных MS SQL, в которой десятки миллиардов строк данных. И в эту таблицу вставляются и удаляются суммарно десятки и сотни тысяч строк в секунду. Назовем эту таблицу dbo.metadata.
Замечание. Для проведенного анализа ниже была создана новая база данных TEST, в которой были созданы две таблицы dbo.metadata и dbo.sha256_checksum (о второй таблице будет написано ниже) и сгенерированы синтетические данные на 1+ млрд строк в каждую. После каждого вызова запроса проводился полный сброс кэша планов для базы данных TEST (DBCC FREEPROCCACHE), чтобы план для запроса каждый раз строился заново, а не брался уже готовый.
Таблица dbo.metadata упрощенно выглядит так:
Определение таблицы dbo.metadata
и определяется следующим образом:
CREATE TABLE [dbo].[metadata](
[id] [bigint] NOT NULL,
[sha256] [varbinary](32) NOT NULL,
CONSTRAINT [pk_metadata] PRIMARY KEY CLUSTERED
(
[id] ASC
));
GO
Здесь получили следующую структуру таблицы dbo.metadata:
- id — идентификатор записи (тип bigint). Это поле является первичным ключом pk_metadata, реализованным через уникальный кластерный индекс;
- sha256 — хэш записи (тип varbinary(32)). Это поле не может быть NULL;
- и прочие поля.
Стоит задача быстро искать по хэшу, то есть по полю sha256.
Реализовать это можно следующим образом:
Способ 1. Создать индекс по полю sha256
Определение индекса по полю sha256
CREATE NONCLUSTERED INDEX [IX_sha256_metadata] ON [dbo].[metadata]
(
[sha256] ASC
);
GO
И далее искать по этому полю:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT t.id
FROM dbo.metadata AS t WITH (NOLOCK)
WHERE (t.sha256 = 0x05678DE1464B7184D1B81364A61E34FC24E555AD911787ECCE688EB78F401B66);
Здесь и далее будем использовать вывод статистики по операциям ввода-вывода и времени выполнения запроса:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;Получили следующую статистику для запроса:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 750 ms, elapsed time = 762 ms.
(затронута одна строка)
Table 'metadata'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(затронута одна строка)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Время выполнения: 2022-12-10T21:03:48.2160884+03:00Получили следующий план запроса:
Действительный план выполнения запроса при использовании индекса IX_sha256_metadata
В свойствах элемента «Поиск в индексе» (Index Seek) получили следующие данные:
Свойства элемента «Поиск в индексе» (Index Seek) действительного плана выполнения запроса при использовании индекса IX_sha256_metadata
То есть из плана видим, что нужный индекс IX_sha256_metadata используется правильно для поиска нужного значения. Также предполагаемое количество операций и количество строк совпадают с фактическим, то есть план «не поехал». Так как в выборке мы вытаскиваем только поле id — идентификатор записи, то нам не нужно обращаться к кластерному индексу за ним, так как все некластерные индексы содержат в себе ключевые поля кластерного индекса. А в нашем случае как раз поле id является ключевым полем кластерного индекса pk_metadata в таблице dbo.metadata.
Теперь узнаем, сколько весит сам индекс IX_sha256_metadata. Для этого воспользуемся следующим запросом:
DECLARE @index_id INT;
SELECT @index_id = i.[index_id]
FROM sys.indexes AS i
WHERE (i.[object_id] = OBJECT_ID('dbo.metadata'))
AND i.[name] = 'IX_sha256_metadata';
SELECT SUM(t.page_count) * 8/1024 AS SizeMB
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('dbo.metadata'), @index_id, NULL, 'DETAILED') AS t;В нашем случае получилось почти 6 ГБ для 1 млрд строк данных.
Способ 2. Добавить сохраняемый вычисляемый столбец sha256_checksum типа int как хэш-значение поля sha256
ALTER TABLE [dbo].[metadata] ADD sha256_checksum AS CHECKSUM(sha256) PERSISTED;
Здесь мы использовали системную функцию CHECKSUM, которая возвращает хэш по входящему значению.
Проиндексировать данное поле с включением поля sha256:
CREATE NONCLUSTERED INDEX [IX_sha256_checksum_metadata] ON [dbo].[metadata]
(
[sha256_checksum] ASC
)
INCLUDE([sha256])
GO
И по этому полю делать фильтрацию:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT t.id
FROM dbo.metadata AS t WITH (NOLOCK)
WHERE (t.sha256_checksum = CHECKSUM (0x05678DE1464B7184D1B81364A61E34FC24E555AD911787ECCE688EB78F401B66) AND (t. sha256 = 0x05678DE1464B7184D1B81364A61E34FC24E555AD911787ECCE688EB78F401B66));
Получили следующую статистику для запроса:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 516 ms, elapsed time = 542 ms.
(затронуто строк: 0)
Table 'metadata'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(затронута одна строка)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Время выполнения: 2022-12-10T21:03:53.9829006+03:00Получили следующий план запроса:
Действительный план выполнения запроса при использовании индекса IX_sha256_checksum_metadata
В свойствах элемента «Поиск в индексе» (Index Seek) получили следующие данные:
Свойства элемента «Поиск в индексе» (Index Seek) действительного плана выполнения запроса при использовании индекса IX_sha256_checksum_metadata
То есть из плана видим, что нужный индекс IX_sha256_checksum_metadata используется правильно для поиска нужного значения. Также предполагаемое количество операций и количество строк совпадают с фактическим, то есть план «не поехал». Так как в выборке мы вытаскиваем только поле id — идентификатор записи, то нам не нужно обращаться к кластерному индексу за ним, так как все некластерные индексы содержат в себе ключевые поля кластерного индекса. А в нашем случае как раз поле id является ключевым полем кластерного индекса pk_metadata в таблице dbo.metadata. Также, так как мы включили поле sha256 в индекс IX_sha256_checksum_metadata, мы можем данное поле использовать в запросе как в выборке, так и в фильтрации без обращений к кластерному индексу pk_metadata.
Теперь узнаем, сколько весит сам индекс IX_sha256_checksum_metadata. Для этого воспользуемся следующим запросом:
DECLARE @index_id INT;
SELECT @index_id = i.[index_id]
FROM sys.indexes AS i
WHERE (i.[object_id] = OBJECT_ID('dbo.metadata'))
AND i.[name] = ' IX_sha256_checksum_metadata';
SELECT SUM(t.page_count) * 8/1024 AS SizeMB
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('dbo.metadata'), @index_id, NULL, 'DETAILED') AS t;
В нашем случае получилось почти 10 ГБ для 1 млрд строк данных (то есть в 1,6 раз больше, чем занимает предыдущий рассматриваемый индекс IX_sha256_metadata в 6 ГБ).
Сравнение двух способов оптимизации
В чем разница между использованием индекса IX_sha256_metadata и индекса IX_sha256_checksum_metadata? По статистике операций ввода-вывода видим, что все идентично, кроме следующей секции: SQL Server parse and compile time. Для индекса IX_sha256_metadata получили CPU time = 750 ms, elapsed time = 762 ms, а для индекса IX_sha256_checksum_metadata получили CPU time = 516 ms, elapsed time = 542 ms.
Давайте сымитируем нагрузку на таблицу dbo.metadata, а именно асинхронно включим вставки в 1000–10 000 строк в секунду синтетических данных. Тогда получим, что разница будет в использовании этих двух индексов между собой только опять в этой секции SQL Server parse and compile time, при этом значения будут следующими:
| Кол-во строк в таблице dbo.metadata |
Использование индекса IX_sha256_metadata |
Использование индекса IX_sha256_checksum_metadata |
| 1 000 000 000 |
CPU time = 750 ms, elapsed time = 762 ms |
CPU time = 516 ms, elapsed time = 542 ms |
| 2 000 000 000 |
CPU time = 938 ms, elapsed time = 939 ms |
CPU time = 732 ms, elapsed time = 732 ms |
| 5 000 000 000 |
CPU time = 1688 ms, elapsed time = 1723 ms |
CPU time = 982 ms, elapsed time = 984 ms |
| 10 000 000 000 |
CPU time = 2432 ms, elapsed time = 2453 ms |
CPU time = 1501 ms, elapsed time = 1506 ms |
Секция SQL Server parse and compile time говорит о том, что выигрыш будет, когда по каким-либо причинам плана запроса нет в кэше. Но в нагруженной системе нередко бывает, когда план запроса в кэше как раз находится недолго или вообще не гарантирует сохраняться.
Таким образом, видим, что лучше всего поиск сначала проводить не по значению большого поля sha256, а по его маленькой части (например, хэша) sha256_checksum. И затем уже из найденного множества значений искать по значению большого поля sha256.
Примечание. Такая же идея поиска лежит во многих языках программирования с управляемой памятью: C#, Java и т. д. То есть сначала сравниваются значения хэшей объектов ссылочного типа, и если они совпадают, то только тогда идет сравнение по заранее предопределенному кодом правилу (в нашем случае каждое поле).
Как можно оптимизировать ещё?
Можно пойти дальше в оптимизации. Тогда большое поле, такое как sha256, необходимо хранить отдельно от основной таблицы dbo.metadata. Например, определив для этого таблицу dbo.sha256_checksum следующим образом:
Определение таблицы dbo.sha256_checksum и ее связь с таблицей dbo.metadata
CREATE TABLE [dbo].[sha256_checksum](
[sha256_checksum] [int] NOT NULL,
[file_id] [bigint] NOT NULL,
[sha256] varbinary(32) NOT NULL
CONSTRAINT [pk_sha256_checksum] PRIMARY KEY CLUSTERED
(
[sha256_checksum] ASC,
[file_id] ASC
)
);
GO
Здесь получили следующую структуру таблицы dbo.sha256_checksum:
- sha256_checksum — это хэш значения sha256 (тип int). Это поле не может быть NULL;
- file_id — идентификатор записи (тип bigint). Это поле не может быть NULL. Ссылается на первичный ключ (поле id) таблицы dbo.metadata;
- sha256 — хэш записи (тип varbinary(32)). Это поле не может быть NULL.
Первичным ключом pk_sha256_checksum таблицы dbo.sha256_checksum, реализованным через уникальный кластерный индекс, является пара полей (sha256_checksum, file_id).
Тогда поиск нужного id записи будет осуществляться следующим запросом:
DECLARE @id BIGINT;
SELECT @id = t.[file_id]
FROM dbo. sha256_checksum AS t WITH (NOLOCK)
WHERE (t. sha256_checksum = CHECKSUM (0x05678DE1464B7184D1B81364A61E34FC24E555AD911787ECCE688EB78F401B66) AND (t. sha256 = 0x05678DE1464B7184D1B81364A61E34FC24E555AD911787ECCE688EB78F401B66));
Примечание. Здесь скорость чтения получили примерно такую же, как при использовании индекса IX_sha256_checksum_metadata в таблице dbo.metadata. Но, отделив большое поле от основной таблицы dbo.metadata, мы тем самым убрали его из хранения кластерного индекса pk_metadata таблицы dbo.metadata, что снизит нагрузку на операцию чтения и записи для этой таблицы. Данное разделение особенно полезно, если поле sha256 было бы очень большим, то есть свыше 4000 байт.
И далее при необходимости с полученным идентификатором записи можно обратиться к основной таблице dbo.metadata для получения нужных полей со следующим запросом:
SELECT <нужные поля>
FROM dbo.metadata AS t
WHERE (t.id = @id);
Таким образом, мы разделили данные, что позволит более оптимально хранить, записывать и читать данные.
Еще большей оптимизации можно добиться в нашем примере, если вместо функции CHECKSUM использовать подстроку substring (sha256, 1, 8). Возвращаемый тип будет bigint:
- определить вычисляемое сохраняемое поле sha256_prefix следующим образом:
[sha256_prefix] AS (substring([sha256], 1, 8)) PERSISTED - создать индекс IX_sha256_prefix следующим образом:
CREATE NONCLUSTERED INDEX [IX_sha256_prefix] ON [dbo].[metadata] ( [sha256_prefix] ASC ) INCLUDE([sha256]); GO
Тогда поиск нужно осуществлять следующим запросом:
DECLARE @id BIGINT;
SELECT @id = t.[file_id]
FROM dbo.sha256_checksum AS t WITH (NOLOCK)
WHERE (t.sha256_prefix = SUBSTRING (0x05678DE1464B7184D1B81364A61E34FC24E555AD911787ECCE688EB78F401B66, 1, 8)
AND (t.sha256 = 0x05678DE1464B7184D1B81364A61E34FC24E555AD911787ECCE688EB78F401B66));
Получили следующую статистику для запроса:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 817 ms, elapsed time = 819 ms.
Table 'sha256_checksum'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(затронута одна строка)
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Время выполнения: 2022-12-11T00:01:26.1536684+03:00Получили следующий план запроса:
Действительный план выполнения запроса при использовании индекса IX_sha256_prefix
В свойствах элемента «Поиск в индексе» (Index Seek) получили следующие данные:
Свойства элемента «Поиск в индексе» (Index Seek) действительного плана выполнения запроса при использовании индекса IX_sha256_prefix
То есть из плана видим, что нужный индекс IX_sha256_prefix используется правильно для поиска нужного значения. Также предполагаемое количество операций и количество строк совпадают с фактическим, то есть план «не поехал». Так как в выборке мы вытаскиваем только поле file_id — идентификатор записи, то нам не нужно обращаться к кластерному индексу за ним, так как все некластерные индексы содержат в себе ключевые поля кластерного индекса. А в нашем случае как раз поле file_id является ключевым полем кластерного индекса pk_file_sha256_checksum в таблице dbo.sha256_checksum. Также, так как мы включили поле sha256 в индекс IX_sha256_prefix, мы можем данное поле использовать в запросе как в выборке, так и в фильтрации без обращений к кластерному индексу pk_sha256_checksum.
Напомню, что при 10 000 000 000 строк данных в таблице dbo.sha256_checksum и при использовании индекса IX_sha256_checksum_metadata мы получили время выполнения запроса 1506 мсек:
CPU time = 1501 ms, elapsed time = 1506 msА при использовании индекса IX_sha256_prefix таблицы dbo.sha256_checksum мы видим, что время выполнения почти в 2 раза меньше, то есть 800+ мсек:
CPU time = 817 ms, elapsed time = 819 ms
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 1 msТакую скорость удается достичь, только если значения столбца sha256 равномерно распределены, а метод как раз обеспечивает это.
Источники:

Alexrook
Может кто даст ссылку на статью по индексам, по их видам и принципам работы. Не в одном источнике хорошего объяснения для непрофессионалов не нашел. Я, конечно, понимаю, что они из себя представляют, но чувствую, что все равно есть какие-то пробелы, так как везде они описываются достаточно сжато и кратко, без особых подробностей. В книгах по базам данных обычно всего несколько страничек, где объясняется самая база. По некоторым типам индексов вообще может быть всего пара абзацев. Либо написано много, но очень сложным языком. Есть что-то более подробное и, самое главное, написанное простым языком? Чтобы человек, который не является большим специалистом в базах данных понял и навсегда уяснил, какие индексы бывают, как конкретно они работают и как ими правильно пользоваться, чтобы не переборщить, ибо избыток индексов тоже ничего хорошего базе не несет.
jobgemws Автор
Есть официальная дока (более подробного материала навряд ли кто-то даст):
1) MS SQL
2) PostgreSQL
3) MySQL
habrapinc
https://use-the-index-luke.com/ детально описаны b-tree индексы с примерами для разных баз.