
Рекомендации по ведению SQL-кода
- Все фильтрации применять сразу в запросе, т е не рекомендуется сначала вызвать функцию, а потом применять фильтр (лучше передать как параметр фильтр):
пример (плохо):SELECT t.ID FROM dbo.fn_func_table () AS t WHERE (t.IsActive = 1)
пример (хорошо):SELECT t.ID FROM dbo.fn_func_table (1) AS t
Здесь важно обратить внимание, что в ф-ии нужно определить параметр IsActive со значением по умолчанию следующим образом:CREATE OR ALTER FUNCTION dbo.fn_func_table (@IsActive INT = NULL)
и затем везде явно задавать этот параметр или передавать значение по умолчанию через ключевое слово DEFAULT:SELECT t.ID FROM dbo.fn_func_table (DEFAULT) AS t
- Все пользовательские типы рекомендуется делать оптимизированными в памяти.
Для этого нужно создать файловую группу оптимизированную в памяти:ALTER DATABASE [<DB_Name>] ADD FILEGROUP [<FG_Name>] CONTAINS MEMORY_OPTIMIZED_DATA; GO
через GUI: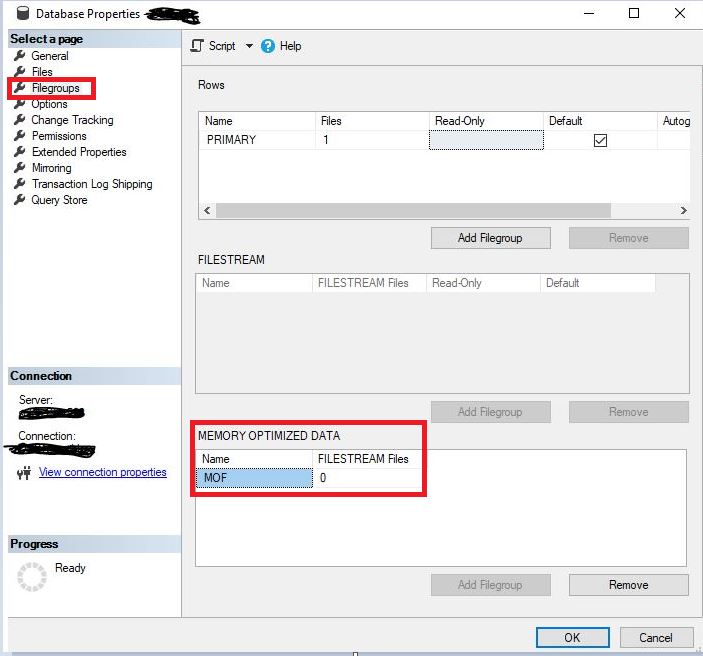
Создание файловой группы
Далее нужно создать файл в этой файловой группе:ALTER DATABASE [<DB_Name>] ADD FILE ( NAME = N'<File_Name>', FILENAME = N'<patch>\<File_Name>' ) TO FILEGROUP [<FG_Name>]; GO
И затем создается пользовательский тип оптимизированный в памяти (пример):IF TYPE_ID('dbo.IdIntList') IS NOT NULL BEGIN DROP TYPE dbo.IdIntList; END GO CREATE TYPE dbo.IdIntList AS TABLE (ID INT NOT NULL PRIMARY KEY NONCLUSTERED, INDEX hash_index_sample_memoryoptimizedtabletype_c2 HASH (ID) WITH (BUCKET_COUNT = 20000) ) WITH (MEMORY_OPTIMIZED = ON); GO
Здесь в BUCKET_COUNT нужно указать в 2 раза больше значение, чем предполагаемое кол-во обрабатываемых (передаваемых) строк в этом типе.
- Не рекомендуется на постоянной основе в запросах обращаться к нематериализованным представлениям.
- Не рекомендуется делать вычисления слева в условиях фильтрации и соединении (константы также справа, а слева-только одно индексируемое поле из таблицы).
- Рекомендуется в условиях фильтрации и соединении слева использовать только индексированные поля.
- Стараться в условиях не использовать оператор OR, а заменить его на IN или разбить на разные команды с помощью ветвления кода.
- Если в IN значений больше, чем несколько, то лучше создать временную таблицу или оптимизированную в памяти табличную переменную T, в нее сложить нужные значения для сравнения и затем ее использовать в условии через EXISTS или ANY:
DECLARE @AccountIDs dbo.IdIntList; INSERT INTO (ID) SELECT ... SELECT ... FROM tbl AS t WHERE EXISTS (SELECT 1 FROM @AccountIDs AS a0 WHERE (t.KeyID = a0.ID)); - Если из таблицы в SELECT не вытаскиваются поля, то вместо INNER/LEFT JOIN лучше использовать EXISTS/NOT EXISTS или ANY, что позволит использовать SEMI JOIN вместо INNER JOIN.
Пример:SELECT t1.ID, t1.[Name] FROM tbl AS t1 WHERE (t1.FK_ID = ANY (SELECT t2.ID FROM tbl AS t2 WHERE t2.IsAction = 1))
Замечание. ANY — это сокращенная форма EXISTS (эквивалентные конструкции).
- Стараться всегда максимально фильтровать сначала по первичным ключам, затем по кластерным индексам (первичный ключ и кластерный индекс в общем случае не обязаны совпадать), затем по некластерным индексам и соединения таблиц проводить сначала
по INNER JOIN. Если OUTER JOIN достаточно много (даже порой одного достаточно), то сначала выгрузить промежуточный результат во временную таблицу, а уже ее использовать с OUTER JOIN, если такое возможно. Не забыть во временной таблице проиндексировать
нужные поля для последующего запроса. Таких интераций может быть несколько. - Для юникода всегда явно ставить N перед значениями (N'<строка>').
- Вынести из запроса все, что можно посчитать и определить заранее, в переменные или во временные таблицы (например, один и тот же подзапрос в разных местах запроса), а также если можно сделать ветвление кода вместо унифицированного запроса.
- Вместо DISTINCT лучше использовать GROUP BY и его модификации (GROUPING SETS и т д) в том случае, если уникальность или группировка нужна не более чем по нескольким полям. Если уникальность нужна почти по всей или по всей строке и в ней значительно
больше, чем 5 полей, то лучше использовать DISTINCT. - При проектировании стараться делать так, чтобы первичные ключи и кластерные индексы (да и некластерные тоже) наполнялись значениями не в одном направлении (т е чтобы значения монотонно не возрастали и не убывали). Случайное значение — плохо для перфоманса (хотя в случае обновления 100% этого результата не достичь, но обычно PK не обновляют). Также плохо монотонное возрастание/убывание значений ключей и индексов.
- Не индексировать немаленькие поля (например, строки, длина которых превышает 8 символов). В таком случае лучше определить вычисляемое сохраняемое поле, которое будет рассчитывать хэш этого поля и по нему создать индекс. В запросе сначала делать условие по этому индексу, а затем уточняющее условие по самому полю. Аналогично и для комбинации полей, когда хэш вычисляется по кортежу, а не по конкретному полю. Подобное решение реализовано во всех языках программирования, где есть сборщик мусора (сначала ищется по хэш-коду в виде целочисленного числа все элементы и потом уже по каждому полю уточняется нужный ли это элемент). Для перфоманса это быстрее, чем сразу искать точное совпадение особенно для больших объектов в ООП (строк таблицы — в БД).
Замечание. Аналогично и для сортировки - Всегда указывать название схемы перед объектом БД.
- В создании синонимов (или при задании названий столбцов) в запросе не использовать =, а использовать ключевое слово AS, а вместо двойных кавычек использовать квадратные скобки (если это необходимо — например, название совпадает с ключевым словом или содержит спецсимвол (например, пробел)).
- Обращаться к индексированным представлениям с хинтом NOEXPAND.
- Всегда при вызове хранимых процедур явно указывать параметры.
- Всегда явно перечислять столбцы как в запросах, так и при вставках (не использовать * нигде в том числе в EXISTS, исключение только одно – COUNT(*)).
- В хранимых процедурах и везде, где можно вначале устанавливать флаги следующим образом:
SET NOCOUNT, XACT_ABORT ON
А в скриптах устанавливать флаги следующим образом:SET ANSI_NULLS, QUOTED_IDENTIFIER ON; SET NOCOUNT, XACT_ABORT ON; GO
В скриптах, где применяются DDL-инструкции, устанавливать флаги следующим образом:SET ANSI_NULLS, QUOTED_IDENTIFIER ON; SET NOCOUNT, XACT_ABORT ON; GO -- Устанавливаем приоритет при возникновении взаимоблокировки SET DEADLOCK_PRIORITY HIGH; GO - Всегда использовать блог BEGIN — END в IF – ELSE.
- Где можно всегда использовать EXISTS вместо COUNT.
- Вместо ISNULL лучше использовать COALESCE, т к COALESCE определено стандартом и поддерживается в других СУБД. Тип приводится к максимальному с более предсказуемым выполнением: Deciding between COALESCE and ISNULL in SQL Server.
- При использовании ключевого слова TOP не всегда нужно явно указывать ORDER BY, если нужен псевдослучайный порядок в результате. В остальных случаях — обязательно нужно указывать ORDER BY.
- У таблицы всегда должны быть определены кластерный индекс и первичный ключ (кроме очень редких и специфичных случаев). При этом кластерный индекс обычно уникальный, хотя и могут быть исключения.
- При указании строкового типа (в том числе и при конвертации) всегда нужно указывать длину этого типа в круглых скобках.
- Всегда явно указывать при создании таблицы (или при добавлении/изменении столбца) NULL или NOT NULL.
- Рекомендуется завершать выражение и строку точкой с запятой (“;”).
- Не рекомендуется использовать динамический SQL. Однако, если приходится, то вызывать его через системную процедуру sys.sp_executesql.
- Не используйте UNION, т к данный оператор должен выполнить сортировку или хэширование результирующего набора перед его возвращением, что значительно снижает производительность запроса.
- Из транзакции вынести все проверки и всё, что можно делать вне ее тела.
- Транзакции более высокого уровня, чем фиксированное чтение, лучше делать через специальные объекты, а не в буквальном смысле по таблицам-участницам (аналог введения синхронизирующих объектов в си-подобных языках).
- Рекомендуется использование функций в виде Table Inline Function вместо multistatement функций. Однако, возможны отдельные исключения.
- Запрещено объявлять переменные и временные таблицы внутри цикла.
- Рекомендуется определять все переменные и временные таблицы вначале скрипта/тела объекта БД.
- Временную таблицу необходимо удалять через конструкцию DROP TABLE IF EXISTS перед её созданием.
- Очистку всей таблицы делать через DDL-команду TRUNCATE вместо DELETE, если это возможно.
- При использовании временной таблицы кластерный индекс определять всегда до наполнения, а некластерные индексы всегда после (анализ).
- Изменение/удаление/вставку огромного числа строк необходимо разбивать на порции.
При удалении/изменении данных всегда стараться делать это по кластерному индексу. Для этого можно создать временную таблицу и туда складывать значения кластерного индекса по нужному условию. Затем производят непосредственно удаление/изменение.
Пример:DROP TABLE IF EXISTS #tbl; CREATE TABLE #tbl (ID INT NOT NULL PRIMARY KEY); INSERT INTO #tbl (ID) SELECT < > DELETE FROM t FROM <>.<> AS T WHERE t=ANY(SELECT t0.ID FROM #tbl AS t0);
или лучше через пользовательский табличный тип, оптимизированный в памяти, который в качестве примера был указан в п.2:DECLARE @IDs dbo.IdIntList; INSERT INTO @IDs (ID) SELECT < >; DELETE FROM t FROM <>.<> AS T WHERE t=ANY(SELECT t0.ID FROM @IDs AS t0); - При работе с последовательностями (SEQUENCE) при массовых вставках не рекомендуется использовать NEXT VALUE FOR.
Рекомендуется использовать sp_sequence_get_range. - При отсутствии ограничений, контролирующих отсутствие фантомных записей (UNIQUE или PRIMARY KEY), рекомендуется в инструкции MERGE указывать хинт SERIALIZABLE для целевой таблицы.
- Не рекомендуется использовать INSERT — EXEC.
- При работе с типом HIERARCHYID рекомендуется по возможности использование IsDescendantOf() в случае, если глубина поиска неизвестна. В этих ситуациях движение от родителя к потомкам эффективнее. В прочих ситуациях рекомендуется использовать комбинации GetAncestor() + GetLevel().
- Рекомендуется использование инструкции TRY_CAST вместо CAST с последующей проверкой результата на NULL.
- Не использовать SELECT INTO.
- Запрещено использование параметра SET ROWCOUNT при модификации данных. Необходимо заменять его на ключевое слово TOP.
- При присвоении значения переменной или полю всегда стоит учитывать факт возникновения более одного значения (если только это не явно по уникальному индексу/ключу) и разрешать его (TOP, MAX, MIN и т д) для предотвращения ошибок выполнения.
- Не забывать тот факт, что при SELECT если строк нет, то в переменную явно положится значение NULL (кроме COUNT(*) и COUNT(1)).
Поэтому лучше поступать следующим образом в случае, если NULL не нужен:SET @parameter = COALESCE(SELECT <запрос>, <значение_по_умолчанию>)
А ещё лучше <запрос> выполнить до COALESCE, чтобы избежать выполнения этого запроса более одного раза. - Рекомендуется НЕ использовать курсоры, в том числе неявные курсоры в виде циклов.
Если курсор все же необходим, то он должен соответствовать следующим требованиям:- Курсор должен быть явно объявлен как LOCAL READ_ONLY FORWARD_ONLY и открыт, а после использования — обязательно закрыт и уничтожен (DEALLOCATE)
- При объявлении курсора рекомендуется использовать инструкцию STATIC, кроме курсора по временным объектам
- Не рекомендуется использовать синтаксис в виде бесконечного цикла и одного FETCH’а
- Запрещены курсоры FOR UPDATE
- Не рекомендуется использовать курсоры-переменные
Примечание:
STATIC и FAST_FORWARD взаимоисключающие опции. К STATIC можно\нужно дописать только FORWARD_ONLY. Особенность STATIC курсора в том, что он делает копию данных в tempdb и всю работу ведет с этими данными, не отслеживая изменения данных в базовых таблицах запроса.
По поводу переменных. Отслеживание курсорных переменных — это дополнительная нагрузка на сервер, основная цель которой – это передача курсоров через параметры хранимой процедуры. Таким функционалом не рекомендуется пользоваться. - Запрещено делать DROP/TRUNCATE/DELETE по временным таблицам в конце процедуры (это произойдет само в фоне).
- Большие поля (более 2 КБ) лучше выносить в отдельные таблицы для минимизации нагрузки на чтение (когда нужно прочитать не все колонки). Например, сам документ держать в отдельной таблице, а его метаданные, по которым в том числе производится поиск, в основной. Также может потребоваться более 1-ой дополнительной таблицы, если нужно хранить более 1-й большой колонки (например, очень большое описание документа — в одну таблицу, сам документ — в другую, а метаданные документа — в основную таблицу).
- Желательно проверять оптимизацию до и после в том числе с помощью специальной тулы: plan-explorer.
- При наименовании объектов рекомендуется придерживаться стандарта де-факто.
- Не рекомендуется использовать (если есть, то убирать это) Нерекомендуемые функции ядра СУБД в SQL Server.
Комментарии (198)

LordDarklight
11.12.2023 12:294. явно нуждается в пояснении
5. Странная рекомендация. Ну понятно (надеюсь всем), что по индексированным полям обычно (кстати не в 100% но если не брать в расчёт затраты времени на индексирование то близко к 100%) фильтр выполняется быстрее. Вот только:
а. Всё не проиндексируешь - конечно можно но "цена" будет несоизмеримо более высокой, чем профит, а уж как запись будет проседать!
б. Условия фильтрации не часто определяются исключительно индексированными полями - чаще бизнес-логикой - и тут уже никуда не деться
Так что фильтровать надо так - как того требует бизнес-логика. Но искать пути задействовать как можно более полные индекскы - но это уже совсем другая тема, затрагивающая и проектирование самих индексов, и проектирование архитектуры бизнес-логики, и оптимизацию требованию бизнес-логики при трансляции в условия выборки базы данных. В один пункт это не уместить!
пункт нуждается в пояснениях насёт ветвления кода
пункт - плохо иллюстрирующий пример - тут бы что-то более конкретное и пактичное (менее абстрактное) и полностью определённое
Почти та же пустая рекомендация, что и 5. пункт. Но тут явно нужны пояснения - чем обусловлен такой порядок. Если говорить про MS SQL Server то, насколько я знаю, он уже давно научился сам правильно определять прядок фильтрации, не звисимо от порядка следования условий в SQL запросе. Вот другие СУБД да - не все так умеют. Иля я не правильно понял о каком порядке идёт речь?
пункт явно нуждается в пояснениях. Вообще надо не забывать - что формирование временных таблиц операция далеко не бесплатная - это важно и для малых и для больших выборок. И вообще - это оправдано только если имеется очень эффкективная фильтрация промежуточного результата для этих выборок (скажем в исходной таблице были миллиарды строк, в выбрали миллионы или хотя бы сотни) - в остальных случаях затраты формирования временной таблицы могут быть явно выше использования кеша уже прочитанных страниц.
хотелось бы пояснений для данной рекомендации - почему так?
Примерчики бы
Спорная рекомендация. Union достаточно частый оператор - и хорошая альтернатива менее прризводительным соединением. Но обычно да - используется "Union all" - Вы против уникального юниона или против всех?
Тоже очень спорная рекомендация. Зачастую проверки делаются в конце транзакции - и они влияют на её успех. Но, конечно, всё что можно проверить до транзакции надо проверить до. Но опять же - зачастую для целостности данных нужно соблюсти повторяемость чтения - чтобы, условно, к концу транзакции то, что было прочитано в начале соответствовало фиксируемой транзакции в её конце. И вот тут большинство (если не все) транзакционные СУБД сильно пасуют по своему функционалу!
пункт нуждается в пояснениях
пункт нуждается в пояснениях
Сложный и важный пункт. Явно не хватает примеров и альтернативных решений

jobgemws Автор
11.12.2023 12:29Это не столько чисто мои рекомендации, сколько объединение рекомендаций комитетов по SQL из разных компаний в MS SQL, проверенные временем. Большинство пунктов да, я и предложил.
В частности такие рекомендации есть в разработке Сбера, Альфа-Банка и ряда других крупных компаний (может не во всех департаментах, но точно есть).
LordDarklight
11.12.2023 12:29ИМХО, без корректных пояснений - грош цена этим рекомендациям
jobgemws Автор
11.12.2023 12:29Здесь написано очень просто и понятно. Например, ветвление кода: IF-ELSE как один из вариантов реализации ветвления кода. Аналогично по остальным пунктам. Где нетривиально были даны примеры кода.
jobgemws Автор
11.12.2023 12:29Для Вас возможно, потому что не понимаете тривиальных вещей.
LordDarklight
11.12.2023 12:29Тем кто всё понимает - рекомендации не нужны
jobgemws Автор
11.12.2023 12:29Всё знать, а тем более всё понимать невозможно. Здесь же написано лаконично и просто о нетривиальном в том числе

Zordhauer
11.12.2023 12:29По п.6 мне тож не хватает пояснений.
В том же Firebird, если не ошибаюсь, IN самой СУБД "под капотом" заменяется на череду OR перед выполнением запроса. И в таком случае единственная польза от данной рекомендации: удобство восприятия и меньший риск сломать запрос, добавив AND и забыв при этом заключить OR условия в общие скобки.

qw1
11.12.2023 12:29"под капотом" заменяется на череду OR
Кстати, исправили в FB 5.0, чтобы для каждого значения IN не открывать заново процесс сканирования индекса.
jobgemws Автор
11.12.2023 12:29Благодарю за информацию, прошу дать ссылки на источник, чтобы ознакомиться.
qw1
11.12.2023 12:29http://www.ibase.ru/files/articles/firebird5/Firebird_5_0_What_New_SQL.html
Абзац "Улучшение предиката IN"
jobgemws Автор
11.12.2023 12:29Спасибо! Как-то они запоздали с некоторыми введениями, особенно в части merge. И теперь понятно откуда фраза "частичные индексы")
qw1
11.12.2023 12:29Подробности сканирования индекса расписаны тут http://www.ibase.ru/cto-novogo-v-firebird-5-0-cast-1-optimizator
jobgemws Автор
11.12.2023 12:29Т е под капотом все что в IN он кладет во временную таблицу (список) и сравнивает с ним как было рекомендовано в публикации в ч.7
qw1
11.12.2023 12:29Если в SQL Server нет этой оптимизации, значит, каждый элемент IN начинает поиск с корня индекса. Опять же, если положить во временную таблицу, то неизвестно, какую стратегию выберет оптимизатор для джойна с ней. Если LOOP JOIN, то выйдет то же самое. А MERGE может быть не выбран по каким-то соображениям.
jobgemws Автор
11.12.2023 12:29Предпочитаю не надеяться на оптимизатор, а написать сразу так, чтобы код был предсказуем в выполнении.
qw1
11.12.2023 12:29Это вам нужно перед каждым join указывать его стратегию (loop/hash/merge), а после каждой таблицы - with (index (AAA))
jobgemws Автор
11.12.2023 12:29Достаточно писать через exists как указано в рекомендации публикации, тогда оптимизатор будет знать, что извлекать поля мы не собираемся из этой таблицы и сможет применить неполное соединение. В худшем случае применит внутреннее соединение.

IVNSTN
11.12.2023 12:29В целом со всем согласен, но есть пара моментов
DROP TABLE IF EXISTS перед её созданием
В ad-hoc скриптах может быть удобно, но в разработке это все-таки скорее антипаттерн. В хранимке такой код свою таблицу дропнуть никогда не сможет - она еще не создана. А распоряжаться внешним объектом неизвестного для текущей области видимости назначения он не имеет права - хп ничего про тот объект не знает, это не ее зона ответственности. Полезного этот фрагмент точно ничего не сделает, а навредить и сильно запутать поиск причины проблемы может.
пример
CREATE PROC dbo.level_three AS BEGIN SELECT 'level_three' AS [level_three], OBJECT_ID('tempdb..#aaa', 'U') obj_id, * FROM #aaa END; GO CREATE PROC dbo.level_two AS BEGIN SELECT 'level_two' AS [level_two], OBJECT_ID('tempdb..#aaa', 'U') obj_id DROP TABLE IF EXISTS #aaa; CREATE TABLE #aaa (a VARCHAR(10), b FLOAT); INSERT #aaa (a, b) VALUES ('22', 3.14); SELECT 'level_two' AS [level_two], OBJECT_ID('tempdb..#aaa', 'U') obj_id EXEC dbo.level_three; END; GO CREATE PROC dbo.level_one AS BEGIN CREATE TABLE #aaa (a INT, b VARCHAR(10)); INSERT #aaa (a, b) VALUES (1, 'b'); SELECT 'level_one' AS [level_one], OBJECT_ID('tempdb..#aaa', 'U') obj_id EXEC dbo.level_two; SELECT 'level_one' AS [level_one], * FROM #aaa; END; GO EXEC dbo.level_one; GO DROP PROC IF EXISTS dbo.level_one; GO DROP PROC IF EXISTS dbo.level_two; GO DROP PROC IF EXISTS dbo.level_three; GOПричем если закомментить дроп, то код вполне себе сможет выполниться и каждая область видимости будет работать со своим объектом. Хотя, честно признаюсь, до последнего времени был убежден, что без дропа будет ошибка вида "объект с таким именем уже существует" и вроде как так и работало и из-за этого, в том числе, и придумали дропать, если вдруг кто мешает текущему коду выполниться (что довольно самонадеянно). Может я что напутал когда-то давно, может упустил изменение, но суть в том, что дропать то, чего еще текущий контекст не создал точно не стоит.
А ещё лучше <запрос> выполнить до COALESCE
Предложил бы сразу рекомендацию и переписать, не предлагать то, что приносит в код новые потенциальные проблемы. Так-то и NULL может быть нужен, и не трогать переменную, если ничего не нашлось - по ситуации; рекомендация довольно абстрактная. И в SELECT-SET, и в SET-SELECT много чего нужно иметь ввиду и понимать, что ты делаешь.
И самый первый пункт очень неконкретный, абстрактный, спорный. В перечне есть гораздо более прямолинейные и однозначно позитивные рекомендации, возможно лучше с них бы и начать.
jobgemws Автор
11.12.2023 12:29Это как раз и сделано для того, чтобы при проверке увидеть есть ли пересечение в именах локальных временных таблицах. Пересечений в именах не должно быть. А если пересечение не выявлено, то потом проблем будет ещё больше. Хранимка должна работать только со своей уникальной по имени локальной временной таблицей в рамках всего стека вызовов в рамках одной сессии.
По остальным пунктам субъективно. Если нужен null, пишут по другому, а вообще лучше проектировать БД без null и значения получать конкретные. Например, я ввожу в справочник нулевой идентификатор, чтобы не использовать внешнее соединение. Null нужен больше в академических целях, а в практических в большинстве случаев нужно конкретное значение в итоге, но правильно обработать null нужно, о чем и написано выше.
IVNSTN
11.12.2023 12:29чтобы при проверке увидеть есть ли пересечение в именах локальных временных таблицах
А как кто-то или что-то это увидит? И "проверки" ведь нет, есть вышибание табуретки из под ног вложенных и внешнего батчей. Таблица спокойно подменится, понятной ошибки не будет ни в какой момент.
Условный THROW IF EXISTS - это да, это была бы проверка, которая вовремя бы дала понять разработчику, что есть пересечение по именованию.
jobgemws Автор
11.12.2023 12:29Как раз при вышибании табуретки сразу будет видна ошибка.
IVNSTN
11.12.2023 12:29Так не будет же, о чем и речь. Если структура будет создана несовместимая, то ошибка будет абсолютно непонятная и в месте никак не связанном с точкой "проверки" через DROP IF EXISTS. А если структура окажется совместимой, то код ниже по уровням вложенности молча и с удовольствием пойдет лопатить вообще не те данные. Этот DROP - почти то же самое, что
WHILE @@TRANCOUNT > 0 COMMITпотому что мне тут чужая транзакция не нужна. Мне тут ваши внешние таблицы не нужны - это точно не проверка и точно распоряжение объектом, про который текущий контекст ничего не знает.

Naves
11.12.2023 12:2913 При проектировании стараться делать так, чтобы первичные ключи и
кластерные индексы (да и некластерные тоже) наполнялись значениями не в
одном направлении (т е чтобы значения монотонно не возрастали и не
убывали). Случайное значение — плохо для перфоманса (хотя в случае
обновления 100% этого результата не достичь, но обычно PK не обновляют).
Также плохо монотонное возрастание/убывание значений ключей и индексов.Несколько раз пытался понять, и не понял.
Auto increment PK ID - плохо?
GUID - тоже плохо?
jobgemws Автор
11.12.2023 12:29Инкремент конечно плохо, т к будет конкуренция.

Tzimie
11.12.2023 12:29Нет, потому что инкремент идёт в автономной транзакции
qw1
11.12.2023 12:29Тут видимо речь о записи в одну и ту же листовую страницу индекса. Если 50 параллельных коннектов одновременно записали значения ключа 100, 101, ... 149, они попадут в один лист индекса. А если просто рандомные значения ключа, они распылятся по разным страницам. С другой стороны, в первом случае придётся записать 1 страницу на диск, собрав все данные последовательно, а во втором случае - записать 50 страниц. Неизвестно, что хуже.
Tzimie
11.12.2023 12:29Это да. Но GUID рыхлит таблицу, увеличивая фрагментацию, плюс он много длиннее как primary key
qw1
11.12.2023 12:29Возможно, это было верно для старой парадигмы "быстрый cpu - медленный сторадж". А когда на сторажде 1M IOPS, у CPU 96 ядер, то может и пусть пишут больше страниц, лишь бы между ядрами было меньше синхронизации.
Конечно, это для сценария "100500 потоков параллельно пишут каждый свою 1 запись". Для сценария "10 потоков, и каждый записал 10к записей" инкрементальный ключ всегда выгоднее.
jobgemws Автор
11.12.2023 12:29Спасибо, что раскрыли п.13-да: и случайно - это плохо для деревьев, и последовательно - это плохо для конкуренции последней записи. Потому совет рабочий, а вот как реализовать зависит от нагрузки и чтений. Может нужно много писать и редко читать-ну так bulk insert и не мучаться. Может пишет только один сервис-тогда вообще инкремент и всё.
Naves
11.12.2023 12:29Фигасе, у вас там в ентерпрайзе 1М IOPS и storage, который быстрее CPU...
А по факту вопроса, ответа так и не увидел.
Опять же с моей колокольни (авто)инкрементные индексы обычно и являлись PK и/или clustered индексами. А тут теперь и так плохо, и эдак плохо. А как хорошо не говорите.

karb0f0s
11.12.2023 12:29Правильно. Хипы наше всё. Нужны случайно монотонные PK. Интересно, автор знает почему эти рекомендации существуют?
jobgemws Автор
11.12.2023 12:29Можно сделать так, чтобы было чередование возрастания/убывания значений. Например, через группу последовательностей: одна последовательность для каждого типа записей. Если просто значения будут монотонно возрастать/убывать, то будет конкуренция за последнюю страницу при параллельных вставках.

silvercaptain
11.12.2023 12:29Как по мне очень глупый поинт. Если индекс не монотонно возрастающий, то добро пожаловать в сплит страниц. (Никому не пожелаю в высоконагруженных приложениях)
jobgemws Автор
11.12.2023 12:29А если монотонно возрастающий, то добро пожаловать в конкуренцию последней записи при параллельных вставках. Никому не пожелаю в высоко нагруженных системах.

Fisher324
11.12.2023 12:29Вы утверждаете, что сплит страниц (со сплитом всех ссылающихся на них индексов) легче, чем конкуренция по вставке в последнюю запись?
Тестировали и замеряли или просто прочитали распространенную рекомендацию?
jobgemws Автор
11.12.2023 12:29Нет, и то и другое плохо. В п.13 описан идеальный вариант, но полностью не достижимый. Однако, как именно реализовать и на сколько близко или далеко подойти к рекомендации в п.13 зависит от требований к системе.


vagon333
11.12.2023 12:29Не индексировать немаленькие поля (например, строки, длина которых превышает 8 символов). В таком случае лучше определить вычисляемое сохраняемое поле, которое будет рассчитывать хэш этого поля и по нему создать индекс.
Индекс используется не только для уникальности, но и для сортировки значений.
Совет "индекс по хешу" нужно принимать с оговоркой использования.

sgmak
11.12.2023 12:29п. 45 - в чем проблема с SELECT INTO ? почему не использовать?
п. 50 - кем запрещено и почему?
да и в принципе по тексту, надо бы как то подтверждать свои утверждения, а не ставить их в ультимативной форме
jobgemws Автор
11.12.2023 12:29Если в пункте объяснено почему, значит искать и проверять дольше, чем 5-10 мин. Если дан пример-аналогично. Если не расписано почему/нет примера, значит можно самостоятельно это сделать менее, чем за те же 5-10 мин. У публикации не стояла цель все пункты разжевать. Конкретно по п.45 ответ очевиден-если нет, советую поучить всё-таки матчасть MS SQL (правда-очень просто). Но для разовых скриптов может и норм. Для п.50 аналогично.
sgmak
11.12.2023 12:29Хорошо, если я пишу такую конструкцию:
IF OBJECT_ID('tempdb..#tempTable') IS NOT NULL DROP TABLE #tempTable; SELECT <fields> INTO #tempTable FROM dbo.table where ... <do something with #tempTable> IF OBJECT_ID('tempdb..#tempTable') IS NOT NULL DROP TABLE #tempTable; <do something else>в чем конкретно здесь будет проблема?
и да, по матчасти, это оффициально декларируемые возможности SQL Server, они не запрещены.
может быть всё же дело в контексте - какую БД и для чего мы разрабатываем, что храним, и как используем? то что верно для транзакционных баз не всегда верно для DWHjobgemws Автор
11.12.2023 12:29В чем разница создавать таблицу SELECT INTO или определить её заранее? Много что есть в T-SQL как и в других языках программирования, но не все стоит использовать на постоянной основе и тем более при многократных вызовах.
silvercaptain
11.12.2023 12:29В скорости вставки.
SELECT INTO гораздо быстрей если вы накладываете эксклюзивную блокировкиу на читающую таблицуjobgemws Автор
11.12.2023 12:29Да Вы что. А если надо кластерный индекс определить по временной таблице? А статистику? А Вы всегда сможете контролировать нужные типы и их ограничения без четкого определения временной таблицы? Рисков слишком много, чтобы вот так использовать SELECT INTO. На самом деле очень спорный вопрос, что select into быстрее, т к оценивается только создание и наполнение временной таблицы, но не оценивается вся работа с ней.
silvercaptain
11.12.2023 12:29Если в этой таблице создавать еще кластерный индекс, то выигрыш через SELECT INTO будет еще на один порядок больше чем через таблицу с кластерным индексом
В любом случае, у нас есть кейс, в котором испльзование SELECT INTO предпочтительней исходя из времени.
Т.е у нас появляются варианты когда мы хотим использовать один или другой подход. И это то место, где универсализм неуместенjobgemws Автор
11.12.2023 12:29Кластерный индекс лучше создавать до вставки данных во временную таблицу, а некластерный после (см п.38 и там же ссыль на исследование). Универсализм это как раз SELECT INTO и быстрее он работает, потому что много чего не делает, как если бы сначала точно определяли сигнатуру временной таблицы. И это "быстрее" суммарно станет медленнее, если оценить время не только создание и наполнение таблицы, но все операции с ней. Тоже не раз проверено и не на одной БД.
silvercaptain
11.12.2023 12:29
Ну это ведь неправда...
Настолько неправда, что пришлось быстро тест подготовить.Имеем не самую большую таблицу(примерно 400 млн записей):
SELECT count(*) FROM [dbo].[SourceProviders] WITH (NOLOCK) --393222888ну и сам тест:
CREATE TABLE tempdb.dbo.SourceProviders1 ([StagingProviderID] [bigint] CONSTRAINT [PK_SourceProviders1] PRIMARY KEY CLUSTERED ([StagingProviderID] ASC)) GO SET STATISTICS TIME ON PRINT '--1 pre-created table --' INSERT INTO tempdb.dbo.SourceProviders1 SELECT [StagingProviderID] FROM [dbo].[SourceProviders] GO PRINT '-- END 1 --' PRINT '--2 Select Into table --' SELECT [StagingProviderID] INTO tempdb.dbo.SourceProviders2 FROM [dbo].[SourceProviders] WITH (TABLOCK) GO CREATE CLUSTERED INDEX IX_SourceProviders2_SourceProviders ON tempdb.dbo.SourceProviders2 ([StagingProviderID] ASC) WITH ( MAXDOP = 8 ,sort_in_tempdb = ON ) GO PRINT '-- END 2 --'Результат:
--1 pre-created table --
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 367485 ms, elapsed time = 496638 ms.(393222888 rows affected)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
-- END 1 --SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
--2 Select Into table --SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 200172 ms, elapsed time = 89096 ms.(393222888 rows affected)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 406719 ms, elapsed time = 82332 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
-- END 2 --SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.Completion time: 2023-12-11T14:51:57.2439988-05:00
Итого 500000 ms против примерно 200000 ms
jobgemws Автор
11.12.2023 12:29Опять же Вы провели тест только на создание и наполнение таблицы.

ioncorpse
11.12.2023 12:29Вы так лаконично всем отвечаете, что только на этом комменте понял, что вы хотите сказать.
Таки да, если потом крутить-вертеть темповой, то возможны неплохие тормоза.
jobgemws Автор
11.12.2023 12:29Порой сложно объяснить, если сам считаю, что просто написал. Т е не знаю как ещё проще/лучше написать. Это и не хорошо, и не плохо.
jobgemws Автор
11.12.2023 12:29про п.50-зачем чистить и удалять временную локальную таблицу, если это происходит автоматически как только блок кода, где она была определена, был завершен. Тем более что такие операции удерживают транзакцию, а значит сессия будет ждать окончания этого процесса.
sgmak
11.12.2023 12:29это прекрасно, если скрипт у нас небольшой.
А представим ситуацию, что у нас час идет пересчет большой таблицы, с активным использованием темпДБ, паралелльно выполняются еще пересчеты также с активным использованием темпДБ. Место на диске с темпДБ не бесконечное и может быстро закончится если вовремя не удалить временную таблицу, особенно если она для продолжения работы уже не нужна, а удалена автоматически она будет только после полной отработки всей ХП и вложенных кстати тоже:Локальная временная таблица, созданная в хранимой процедуре, удаляется автоматически по завершении хранимой процедуры. На таблицу могут ссылаться любые вложенные хранимые процедуры, выполняемые хранимой процедурой, создавшей таблицу. Процесс, вызвавший хранимую процедуру, создавшую таблицу, не может ссылаться на таблицу.
Все остальные локальные временные таблицы автоматически удаляются в конце текущего сеанса.
https://learn.microsoft.com/en-us/sql/t-sql/statements/create-table-transact-sql?view=sql-server-ver16#temporary-tablesи сразу отвечу на коммент ниже (ибо ограничен):
вы так говорите, будто рекомпиляция это всегда что-то плохое) таки бывают случаи когда это полезноjobgemws Автор
11.12.2023 12:29На самом деле холиварная тема, но в большинстве случаев важен именно отклик системы, а не что там ресурсы долго держит. Даже ОС сейчас пошли не "жадные", т е не спешат сразу отдавать тот объем ОЗУ, который уже не нужен закрытым сервисам/сессиям/потокам. Т е зная и даже сталкиваясь с такими ситуациями все равно рекомендация остаётся в силе. Даже со стороны DBA. Быстродействие системы важнее.
jobgemws Автор
11.12.2023 12:29Рекомпиляции на постоянной основе плохо, т к не решена причина проблемы, из-за которой эти рекомпиляции понадобилась.
jobgemws Автор
11.12.2023 12:29SELECT INTO вызовет неявную рекомпиляцию всей хранимой процедуры, в которой есть такая инструкция и не сможет повторно воспользоваться планом выполнения.
jobgemws Автор
11.12.2023 12:29IF OBJECT_ID('tempdb..#tempTable') IS NOT NULLлучше заменить на DROP TABLE IF EXISTS tbl1, tbl2, ...;
silvercaptain
11.12.2023 12:296. Стараться в условиях не использовать оператор OR, а заменить его на IN или разбить на разные команды с помощью ветвления кода.
Это вы никогда не попадали на эти ошибки видно в операторе INError 8623:
The query processor ran out of internal resources and could not produce a query plan. This is a rare event and only expected for extremely complex queries or queries that reference a very large number of tables or partitions. Please simplify the query. If you believe you have received this message in error, contact Customer Support Services for more information.
Error 8632:
Internal error: An expression services limit has been reached. Please look for potentially complex expressions in your query, and try to simplify them.
jobgemws Автор
11.12.2023 12:29Данные ошибки возникают не только и не столько из-за оператора IN. Если в запросе 2-3 значения, то IN-нормальное решение.

ptr128
11.12.2023 12:29Я бы не был столь категоричен. Порой нужны запросы между БД, и MERGE INTO. Да и параллелизм при вставке может перекрыть все выгоды от in memory OLTP. Бывают нужны geography и geometry типы. В общем, пока имеется масса ограничений для in memory OLTP, я бы рекомендовал пользоваться им с осторожностью.

ALexKud
11.12.2023 12:29Некоторые рекомендации, описанные в статье я использую, например не применяю курсоры, то есть применяю, но в виде агрегата min to min. Так как у меня не web приложения, то в основном в моих разработках использую хранимые процедуры, в которых делаю все обработки бизнес логики. Не использую временные таблицы, триггеры dml. Для хранения версий хранимых процедур и истории всего кода dml использую триггеры БД и таблицу а отдельной БД для хранения всей истории изменений северного кода. А статья полезная. Мои системы трудно назвать высоконагруженными, но в любом случае нужно по возможности придерживаться рекомендаций, связанных с быстродействием. Кстати, про быстроднйствие- пробовал использовать CTE в запросе вместо подзапросов, оказалось что с СТЕ запрос медленнее в 2 раза. То есть CTE тоже надо использовать с осторожностью, исходя из необходимости и требований к быстродействию.
jobgemws Автор
11.12.2023 12:29Круто! Для истории изменения данных тоже по возможности лучше делить БД, т е получается что-то вроде секционирования всей БД-разделение оперативных и исторических данных. Рад что публикация оказалась Вам полезной. Про CTE-в общем, рекурсивные CTE могут дать сильную просадку в производительности, т е лучше делать через временные таблицы. Сам же CTE (без рекурсии) эффективен только при небольшом количестве обрабатываемых данных. Но как отдельный пункт рекомендации еще не созрел в данном материале.
ALexKud
11.12.2023 12:29Я вообще стараюсь отделить данные от логики, то есть все таблицы хранятся в одной бд а хп в другой. Доступ к таблицам через синонимы. Это даёт возможность создать не только рабочую, но и тестовую БД. При разработке хп идентичны по коду xп, но работают с разными таблицами. В клиентском приложении просто выбираешь нужную базу тестирования и тестируешь изменения в хп. Это позволяет не создавать лишнюю тестовую БД, и к тому же использовать общие справочники для рабочей и тестовой БД. По такому принципу у меня построена система разработки карт протокола Modbus новых прошивок приборов. В тестовой БД новая карта тестируется и потом переносится в рабочую БД. Может возвращаться назад, дорабатывать и опять заменять я в рабочей БД или записываться как новая. В тестовую БД добавлены процедуры корректировки карт, в рабочей их нет. Доступ разграничения между пользователями разработчиками карт и пользователями настройками приборов. Естественно есть логи и мониторинг коннектов, который показывает в онлайн кто и что делает с БД.

BlazeFox
11.12.2023 12:29Ну давайте по существу:
1. Вы не указали о каком типе функции идёт речь, будем считать, что это TVIF
В общем и целом это называется проблемой невозможности выполнить push-down предиката, (например при использовании в функции оконок), и в таком случае да - безусловно нужно вносить параметр явно и смотреть очень пристально на то, как оно компилируется.
НО в общем случае неприятности это может вам принести только в случае если вы используете функцию в качестве ограничивающего предиката с доп. условием вWHERE
2. Только ради этого не стоит заводит MOFG, к тому же: если вы создаетё HASH индекс, то зачем вам ещё и B-TREE? И почему HASH индекс не уникальный, если B-TREE уникальный?
В общем и целом могу порекомендовать следующее: если основной шаблон использования ID в типе - singleton lookup и вы знаете предполагаемый объем данных в этом конкретном TVP - создавайте HASH, иначе просто B-Tree и лишь в очень (ОЧЕНЬ) редких случаях нужны оба индекса.
3. Я перефразирую: нельзя использовать VIEW в качестве таблиц при написания запросов: оптимизатор гарантированно не будет счастлив, если вы сделаете соединение VIEW, которая ссылается на другое VIEW, которое содержит в определении APPLY на функцию и т.д. Т.е. суть кроется в следующем: VIEW это не таблица, при написании запросов к ней НУЖНО это учитывать.
4. Не понимаю при чём здесь "рекомендуется", речь идёт о SARGability, и в таком случае простой ссылки будет достаточно. п. 5 - то же самое
6. Нет ничего плохого в OR, просто надо знать меру (как и с IN btw), оценивайте приводит ли использование OR к излишним чтениям или проблемам с компиляцией запроса, если всё в порядке - оставляйте и даже не забивайте себе голову. Мы занимаемся разработкой, а не следованием мантрам в стиле "туда не ходи"
7. Это не совсем (и не всегда) верно, поскольку может ухудшать план исполнения, поскольку после вынесения в TVV этих значений план будет скомпилирован скорее всего как multiple seek of unknown value, это не столь критично при поиске уникальных значений, но может иметь сильнейший отридцательный эффект при поиске чего либо с cardinality > 1 строки.
9. За вас это делает оптимизатор (занимается оценкой), похоже на очередную мантру.
12. Если в ваших запросах DISTINCT SORT получается всегда дороже чем STREAM AGGREGATE, то значит оптимизатор ошибается в cardinality и вам нужно либо посмотреть что со статистикой, либо упростить запрос. (вообще к DISTINCT отношусь как жёлтому флагу, но кажется теперь начну так же относиться и к GROUP BY вместо DISTINCT).
13. Если изменить формулировку на "При проектировании таблицы в OLTP БД с сильной нагрузкой на вставку...", то это одно и допустимых решений, в остальном не очень, и да ссылки как всегда достаточно.
14. В качестве оптимизации или при проектировании seek-heavy таблицы - да, как исходное решение - нет. (у вас часто пользователи ищут строки по 50+ символов?)
17. Нет, оптимизатору в общем случае виднее, если есть проблемы - да, пробовать хинтовать, но НИКОГДА не делать этого "просто потому что принято", то же самое относится и к хинту NOLOCK.
18. Это не верно для NC модулей, поскольку может приводить к падению производительности.
23. Это просто разные функции и у каждой из них есть своя область применения:
COALESCE в T-SQL так вообще сахарок, она раскрывается:SELECT COALESCE(a, b) FROM tbl;
SELECT
CASE
WHEN a IS NOT NULL THEN a
WHEN b IS NOT NULL THEN b
END
FROM
tbl;
соответственно вы не будете вычислять b, если у вас есть a (в случае если a и b подзапросы), НО вы вычислите a дважды (!!! это важно), один раз для выполнения assert, второй для непосредственно получения значения (таков уж T-SQL),
Проверьте то же самое для ISNULL() - все выражения внутри будут вычислены (но только и ВСЕГДА один раз)
25. И зачем вам это в таблице log'ов например?
26. Должно звучать как указывать длину при работе с любыми var* типами: [n]varchar(), varbinary(), дополню от себя: не каждая строка это "по-умолчанию" [n]varchar(255) (подставьте сюда своё любимое число).
29. А если я точно знаю, что выполнение будет только одно и мне не нужно кэшировать план?
30. Мантра, безусловно утюгом гвозди забивать неудобно, но разве плох для этого молоток? Другой разговор про цепочки из UNION (из-за возможных сложностей у оптимизатора при оценке требуемого memory grant'а), но опять же - нельзя что-то делать или не делать только потому что "так принято".
31. Краткая выжимка: Keep transactions as small and as short as possible. Ничего более тут не требуется разъяснять (это относится и к другим похожим пунктам)
32. Если речь об applock'ах, то это ооочень специфический инструмент и не стоит добавлять его как "generic use pattern", их как правило используют только в том случае, если не удаётся обеспечить достаточную изоляцию используя стандартные механизмы блокировки MS SQL Server, или если их использование слишком затратно для системы. (например сильно нагружает pool блокировок, или вываливается за thershold'ы и приводит к эскалации)
35. ... и на 100-й строчке кода искать определение TVV в начале модуля
36. Временные таблицы и TVV это отдельная и очень большая тема, в общем случае стоит всегда задавать себе вопрос: хорошо ли выпонимаете разницу в них, и почему именно в этом конкретном случае вам нужна именно временная таблица, а не TVV (помним про deferred compilation) в версиях 150+
38. Нельзя смешивать DML и DDL код в одном модуле, поскольку это приводит к фантомным перекомпиляциям (не столь актуально для 150+, но всё-же), это в принципе допустимо в скриптах, но никогда в модулях, создаетё времянки - делайте полное её определение, для индексов (почти всех типов) сейчас допускается inline определение прямо в конструкцииCREATE TABLE / DECLARE @tvar AS TABLE
39. А ещё лучше - прочтите статью о том, что такое эскалация блокировок
41. Если вам необходимо обеспечить уникальность - поднимите ограничения UNIQUE/PK, а не изобретайте велосипед (кроме того при patter'не UPSERT через MERGE указывать SERIALIAZABLE это строго говоря правило, от которого лишь в некоторых случаях можно отказаться (например OLTP бд))44-45 - мантры, у TRY_CAST есть всего 2 адекватеных применения: проверка возможности приведения к XML и работа с sql_variant типами (у вас они есть?), select into в скриптах более чем допустим, в модулях нет - неявное создание временнной таблицы.
46. От использования SET ROWCOUNT стоит вообще отказываться, не только в DML. Были кстати кажется где-то тикеты про "а давайте просто объявим его как deprecated", но пока всё ограничилось следующей плашкой:Important
Using SET ROWCOUNT will not affect DELETE, INSERT, and UPDATE statements in a future release of SQL Server. Avoid using SET ROWCOUNT with DELETE, INSERT, and UPDATE statements in new development work, and plan to modify applications that currently use it. For a similar behavior, use the TOP syntax.
...
Setting the SET ROWCOUNT option causes most Transact-SQL statements to stop processing when they have been affected by the specified number of rows. This includes triggers. The ROWCOUNT option does not affect dynamic cursors, but it does limit the rowset of keyset and insensitive cursors. This option should be used with caution.т.е. на лицо "скрытый контекст исполнения", почему отвалился триггер? - кто-то в scope'е выше поставил SET ROWCOUNT
50. Не запрещено, скорее "не нужно", любителям рассказов про "немедленное освобождение места в tempdb обратно", а вы часто создаёте террабайтные таблицы в tempdb? Если да, то зачем, для этого есть обычные БД? А вообще место для "маленьких" (несколько extent'ов, я не помню точно и не смог найти источник) таблиц высвобождается мгновенно при выходе за scope, для больших - фоновым процессом за 10-20 секунд (слишком от многого зависит)
Ручная очистка таких таблиц противоречит следующей парадигме: Keep your transactions as small and as short as possible.jobgemws Автор
11.12.2023 12:29Круто! Спасибо за развернутую критику с детализацией и фактами. Большинство изложенного обсуждалось и не один раз и не один месяц прежде чем было формализовано в виде пунктов рекомендаций для этой публикации. Т е рассматривались все плюсы и минусы и выбраны оптимальные рекомендации для большинства встречающихся задач.
Tzimie
11.12.2023 12:29По поводу вьюх,вьюха вьюхе рознь. Есть синонимичные вьюхи, которые немного фильтруют, выбирают часть колонок и переименовывают их. Оптимайзер с ними прекрасно разбирается
А бывает вложенность из пяти вьюх с со сложными ,joins, group by и подзапросами
jobgemws Автор
11.12.2023 12:29Лучше вместо вьюх встраиваемые табличные функции или напрямую подзапрос написать
Tzimie
11.12.2023 12:29Это ещё почему? В случае простого вью это вью выступает не более чем синтаксическим сахаром и никак не влияет на оптимайзер
jobgemws Автор
11.12.2023 12:29Потому что потом со временем вью будут усложнять, добавляя подзапросы, соединения для вывода новых полей и т д и т п. Проходили уже-и будут менять ток вьюху, а оптимизацию делать потом-DBA же есть.
Tzimie
11.12.2023 12:29Тем не менее категоричной эта рекомендация быть никак не может
jobgemws Автор
11.12.2023 12:29Если так посудить, то вообще все правила условны и всегда есть кейсы, чтобы их нарушить. Потому полностью согласиться не могу. Рекомендации отрабатывались годами и менялись, и были формализованы такие какие описаны в статье не за месяц и даже не за один год. В разных проектах/командах/компаниях.
Naves
11.12.2023 12:29И зачем вам это в таблице log'ов например?
Вы логи не чистите что ли? А как вы ищете в логах без индекса хотя бы по дате?
А потом появляются статьи вида https://habr.com/en/articles/509322/
Можно, конечно, начать рассуждать про партиционирование таблиц, использование внешнего хранилища, но эти дополнительные меры усложнения реально нужны малому количеству проектов.
BlazeFox
11.12.2023 12:29В правильном (ну совсем правильном случае) логи хранят в секционированных таблицах с clustered columnstore индексами (если данным позволяют)
jobgemws Автор
11.12.2023 12:29Добавлю, что часто логи хранятся вообще в другой нереляционной СУБД, рассчитанной на огромные вставки данных типа сциллы. А если данные нужны оперативно и часто, то это уже не логи.
ptr128
11.12.2023 12:29Предпочитаю логи хранить в реляционной СУБД ClickHouse.
jobgemws Автор
11.12.2023 12:29Она не реляционная: https://clickhouse.com/docs/ru
ptr128
11.12.2023 12:29Не вижу этого по ссылке.
Зато тут: "ClickHouse uses the relational database model."
Тут тоже: "Clickhouse is a column-oriented relational database"
Благодаря поддержке SQL (декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных) - это реляционная БД. ClickHouse поддерживает не только реляционные структуры данные, но тоже самое можно сказать и про PostgreSQL.
jobgemws Автор
11.12.2023 12:29Мне казалось, что ClickHouse столбчатая СУБД, потому в нёё быстро все грузится и она шустрая для аналитики. Но чтобы она была реляционной... Скорее всего она поддерживает реляционную модель, но сама является не реляционной изначально. Слон-реляционная СУБД как и MS SQL, с поддержкой нереляционных возможностей.
ptr128
11.12.2023 12:29А почему Вы решили, что columnstore OLAP DBMS не может быть реляционной? Это независимые понятия. Можете найдете ссылку на компетентный источник информации, где утверждается обратное?
jobgemws Автор
11.12.2023 12:29Чем Вам не понравился официальный источник, который был дан выше?
https://clickhouse.com/docs/ru
"ClickHouse — столбцовая система управления базами данных (СУБД) для онлайн-обработки аналитических запросов (OLAP) " и там всё расписано как хранится. Да, он поддерживает возможности и реляционной модели, но хранит всё именно по другому не как это делают реляционные СУБД.ptr128
11.12.2023 12:29Там нет ни слова о том, что ClickHouse не реляционная БД. Зато указана поддержка реляционной модели данных и описаны реляционные операторы, ей поддерживаемые.
не как это делают реляционные СУБД
Вы пропустили слишком много. "Не так, как это делают традиционные реляционные СУБД со строковым хранением данных". И тут да, я соглашусь, что ClickHouse совсем не традиционная СУБД и тем более не со строковым хранением данных.
jobgemws Автор
11.12.2023 12:29Постараюсь раскрыть что там написано: данные хранятся по умолчанию не строками, а столбцами. Вот, подсветил. В реляционных СУБД по умолчанию хранение происходит строками, но также есть поддержка столбчатого хранения через специальные индексы. Но от этого реляционные СУБД не становятся не реляционными, а просто поддерживают нереляционные модели данных. Надеюсь объяснил.
ptr128
11.12.2023 12:29Нет конечно. Из того в реляционных СУБД по умолчанию хранение происходит строками совершенно не следует, что при их хранении столбцами модель данных перестанет быть реляционной.
Но от этого реляционные СУБД не становятся не реляционными, а просто поддерживают нереляционные модели данных.
Само собой. По определению СУБД является реляционной, если поддерживает реляционную модель данных. А от того, что она еще поддерживает она не перестает быть реляционной. И раз ClickHouse поддерживает реляционную модель данных, то он так же является реляционной СУБД.
Давайте все же не растекаться мыслею по древу. Я предоставил две ссылки, где однозначно сказано, что ClickHouse является реляционной СУБД. Могу еще добавить: "ClickHouse – колоночная реляционная СУБД". Предоставьте Ваши ссылки, где эти утверждения опровергаются.
jobgemws Автор
11.12.2023 12:29Все равно, что утверждать раз в MongoDB есть поддержка SQL-запросов, то она тоже может быть реляционной. На этом остановимся.
Колоночная реляционная...ужас: так можно и до документоориентированной реляционной модели дойти. Да нет такого в природе физически: либо колоночная, либо реляционная, либо документоориентированная, либо иерархическая и т д и т п
jobgemws Автор
11.12.2023 12:29Ссылки были и от меня, и от Вас, где написано прямо что за модель данных.
Вертика - реляционная СУБД с поддержкой колоночного хранения.
ptr128
11.12.2023 12:29Я не видел от Вас ссылки, где утверждалось, что ClickHouse не реляционная СУБД. Были лишь Ваши домыслы, что OLAP или ColumnStore СУБД не может быть реляционной. Дайте ссылку, как я, процитировав утверждение, что ClickHouse не реляционная СУБД.
jobgemws Автор
11.12.2023 12:29Поправка: Vertica как и ClickHouse - это колоночно-ориентированная аналитическая СУБД
ptr128
11.12.2023 12:29Вот и дайте ссылку, где доказывается, что эти два понятия не совместимы и не может быть Wide Column Stores реляционной СУБД. Зачем так много спорить и писать, если достаточно просто дать ссылки?
jobgemws Автор
11.12.2023 12:29https://ru.m.wikipedia.org/wiki/ClickHouse
Кстати, на счёт слона ошибался-это не реляционная СУБД, а...впрочем Вы просили ссылку: https://ru.m.wikipedia.org/wiki/PostgreSQL
И для сравнения: https://ru.m.wikipedia.org/wiki/Microsoft_SQL_Server
Надеюсь теперь Вы поняли в чем разница именно типов СУБД, которые поддерживают и другие типы моделей данных. Т е будучи одним типом, могут поддерживать и другие, но не могут являться сразу несколькими типами сразу. Это физически невозможно.
ptr128
11.12.2023 12:29Может я плохо читал, но в упор не вижу, где тут написано, что ClickHouse не реляционная СУБД. Можете процитировать эту фразу?
Надеюсь теперь Вы поняли в чем разница именно типов СУБД
Не понял. СУБД может быть одновременно множества типов. И только некоторые из них считаются взаимоисключающими, как OLAP и OLTP.
jobgemws Автор
11.12.2023 12:29Все 3 ссылки прочтите пожалуйста. Первые предложения и найдете разницу. СУБД может быть только одного типа, куда его конкретно относят, но также бывают надстройки для поддержки и других моделей данных. Но! Сама СУБД относится только к одной модели, а не к нескольким. Забудьте про маркетинговый ход о многомодельной модели данных. Такое физически не создать без скрещивания ужа с ежом. У Вас будет физически одна модель в зависимости какую СУБД Вы выберите+эта же СУБД будет иметь некие надстройки, которые позволяют поддерживать и другие модели. Например, в MS SQL для этого есть колоночные и пространственные индексы.
ptr128
11.12.2023 12:29Да прочитал я. Говорю же не вижу в упор, где написано, что ClickHouse не реляционная СУБД. Процитируйте и скрин сюда поместите с этой фразой.
Мы же не Ваши субъективные ассоциации обсуждаем, а просто факт, который должен быть явно зафиксирован. Я Вам четыре ссылки дал где открытым текстом написано что ClickHouse реляционная СУБД. Вот и от Вас жду ссылки с аналогичным текстом не допускающим двоякого толкования.
СУБД может быть только одного типа
Это лишь Ваше личное мнение, с которым я не согласен.
jobgemws Автор
11.12.2023 12:29Читаете и не видите в упор: "ClickHouse — это колоночная аналитическая СУБД" и "Microsoft SQL Server — система управления реляционными базами данных (РСУБД)" и "PostgreSQL (произносится «Пост-Грес-Кью-Эл»[7]) — свободная объектно-реляционная система управления базами данных (СУБД)".
Если и сейчас не видите разницу, то закончим на этом, т к я не знаю как ещё объяснить, что Земля круглая.
ptr128
11.12.2023 12:29Ну и где написано что ClikHouse не реляционная? Это колоночная реляционная аналитическая БД. И то, что где-то слово "реляционная" пропускают совершенно не доказывает, что она не реляционная.
Вы хотите чтобы я повторял Ваши ассоциативные заключения. А я не хочу.
qw1
11.12.2023 12:29Термин "Реляционная" относится к логической модели данных.
То есть, для пользователя данные представляются в виде кортежей с одинаковым набором полей в каждом. Когда в ClickHouse описывается таблицаCREATE TABLE example ( dt Date, ts DateTime, value Float32 CODEC(Delta, ZSTD) ) ENGINE = MEMORYэто автоматически переводит модель в класс реляционных. Как оно хранится под капотом - это вне классификации логических моделей.
Другой аргумент: если в CH - не реляционная модель, то какая? Выбор-то небольшой:
Иерархическая модель
Сетевая модель
Реляционная модель
Модель «сущность — связь» (ER)
Модель «сущность — атрибут — значение»[en] (EAV)
Объектно-ориентированная модель (из ООП)
Документная модель
Звёздная модель и модель снежинкиКроме "реляционной", к CH ничего больше не подходит.
jobgemws Автор
11.12.2023 12:29https://ru.m.wikipedia.org/wiki/ClickHouse
"ClickHouse — это колоночная аналитическая СУБД"
И да-она поддерживает реляционную модель, но сама не является реляционной СУБД.
qw1
11.12.2023 12:29Обратимся к словарю.
Реляционная система управления базами данных (РСУБД) — СУБД, управляющая реляционными базами данных.
Реляционная база данных — база данных, основанная на реляционной модели данных.
То есть, по определению, СУБД, поддерживающая реляционную модель данных, является РСУБД. Если есть другие определения - давайте, рассмотрим их.
jobgemws Автор
11.12.2023 12:29Нет, классифицируют не так СУБД. В данном случае ClickHouse и Vertica - это аналитические СУБД, поддерживающие в том числе реляционную модель, но сами СУБД колоночные (столбчатые) аналитические.
qw1
11.12.2023 12:29Нет, классифицируют не так СУБД
Поэтому я и попросил дать ваше определение, если вас не устраивает общепринятое, которое я привёл выше. Итак, РСУБД - это ...
поддерживающие в том числе реляционную модель
А какие ещё логические модели (кроме реляционной) поддерживает CH?
Выше перечислен их список. Кроме реляционной, ничего не подходит. Одна запись в CH - это кортеж.Если схема
example (dt Date, ts DateTime, value Float32)
То нельзя вставить dt без value. Запись - неделимый кортеж, как и требует реляционная модель.
qw1
11.12.2023 12:29Следуя этим ссылкам википедии, я пришёл к определениям на страницах википедии, которые выписал. А других определений там нет. Поэтому у вас и спрашивают цитаты.
qw1
11.12.2023 12:29Первые предложения из страниц, которые я тоже выше указал.
Хорошо. Попробуем.
Первая ссылка https://ru.m.wikipedia.org/wiki/Реляционная_СУБДРеляционная система управления базами данных (РСУБД) — СУБД, управляющая реляционными базами данных
Вроде это ровно то, что я цитировал, и с чем вы не согласны. Или нет?
Вторая ссылка https://ru.m.wikipedia.org/wiki/PostgreSQL
PostgreSQL (произносится «Пост-Грес-Кью-Эл»[7]) — свободная объектно-реляционная система управления базами данных (СУБД).
При CH тут ничего нет.
Третья ссылка
ClickHouse — это колоночная аналитическая СУБД с открытым кодом, позволяющая выполнять аналитические запросы в режиме реального времени на структурированных больших данных. Изначально разрабатывалась компанией Яндекс[4][5][6], но впоследствии разработка полностью перешла в отдельную компанию ClickHouse Inc[7].
Из чего вы сделали заключение, что "она поддерживает реляционную модель, но сама не является реляционной СУБД". Вот этот переход я не понимаю.
qw1
11.12.2023 12:29но сами СУБД колоночные (столбчатые) аналитические
Колоночная - способ хранения.
Аналитическая - предназначение.
Логической модели данных это перпендикулярно.
jobgemws Автор
11.12.2023 12:29Тогда почему не пишут аналогично про MS SQL, там ведь тоже есть колоночные индексы? Ах да, потому что СУБД поддерживает, а не является такой. В Википедии черно по белому дано определение каждой СУБД и не нужно натягивать модель данных на тип СУБД. Тип СУБД не тоже самое, что модель данных. Типов СУБД очень много и характеризуется в первую очередь реализацией хранения данных, а поддерживать может сколько угодно моделей данных.
qw1
11.12.2023 12:29Типов СУБД очень много
Вот они все:
https://ru.wikipedia.org/wiki/Система_управления_базами_данныхЧто вы здесь подразумеваете под "типом СУБД", если не классификацию по модели данных? По степени распределённости? По способу доступа?
РСУБД - это классификация по модели данных
jobgemws Автор
11.12.2023 12:29Весь этот холивар возник, т к утверждалось, что логирование идёт быстро в реляционную СУБД. Я же уточнил, что СУБД не реляционная, а колоночная.
qw1
11.12.2023 12:29Я же уточнил, что СУБД не реляционная, а колоночная
А вас поправили, что она и реляционная, и колоночная.
jobgemws Автор
11.12.2023 12:29Ещё раз читаем что в Вики написано. Устал спорить. Предлагаю закончить. В конце концов тема публикации не об этом. И какова цель спора,и если все равно каждый останется при своем мнении? Потому хватит.
qw1
11.12.2023 12:29Моя цель уточнить мои знания. Мне говорят: чёрное - это белое. Я спрашиваю: как так? Да вот же, на википедии написано. Спрашиваю: где написано? - Вот ссылка, читайте! А я по ссылке не вижу. Вот и думаю, то ли я дурак, то ли что?
Ну ладно, если вы не готовы для меня разжевать материал, чтобы я его понял, значит я своей цели не достигну.
ptr128
11.12.2023 12:29На мой взгляд, вопрос терминологии - это вопрос того, как удобней большинству. Если я легко нашел четыре ссылки где однозначно написано, что ClickHouse является реляционной СУБД, то для опровержения этого утверждения необходимо большее количество ссылок, где так же однозначно написано, что ClickHouse не является реляционной СУБД. Пока ни одной такой ссылки не увидел. Следовательно, для меня вопрос закрыт.
jobgemws Автор
11.12.2023 12:29Мы читаем с Вами одно и тоже и делаем разные выводы. Однако, к теме материала оно не имеет отношения. Потому и нет смысла дальше спорить.
silvercaptain
11.12.2023 12:29Отличная ссылка. Спасибо!
Я понимаю зачем автор статьи использует этот хинт, но в Enterprise версии сервера он не нужен. Во всех остальных да, его необходимо указывать, что бы Сиквел использовал вьюшку, зря что ли мы ее создавали? :)
На самом деле димамический SQL сильно помогает бороться с пунктом 6 (Оператоты OR and IN) и резко сокращает сложность запроса и время его выполнения.
Да писать его сложно, сопровождать еще сложнее, но порой без него (особенно в различных веб приложениях с множественными фильтрами) жизнь немыслима :)
jobgemws Автор
11.12.2023 12:29Работаю часто в Enterprise версии сервера и лучше его указать. Это не nolock.
в таком случае запрос лучше строить на стороне сервиса, а не на стороне СУБД или если вариантов немного, то сделать ветвление кода: либо через IF-ELSE, а еще лучше вызывать нужные хранимки, чтобы не раздувать саму хранимку.
ptr128
11.12.2023 12:29в таком случае запрос лучше строить на стороне сервиса, а не на стороне СУБД
Это легко делается на стороне СУБД с использованием нескольких сервисных функций и препроцессора при деплое. Подробно описывать - это уже на статью потянет. Может как-то соберусь и напишу. Клиенты, увы, бывают уж слишком тупы, чтобы на них динамически запросы формировать (камень в сторону SSRS и CrystalReports).
jobgemws Автор
11.12.2023 12:29Ссылка отличная, но как всегда рекомендации от Microsoft работают пока БД небольшая и под небольшой нагрузкой. В целом совет скорее вреден для сильно нагруженных систем, чем полезен. И да-все эти доки читал и применял тоже.
BlazeFox
11.12.2023 12:29про 29 уточняю: не всегда нужно использовать именно sys.sp_executesql
про динамику вообще на самом деле есть отличная статья - всем рекомендую: The Curse and Blessings of Dynamic SQL (sommarskog.se)
ptr128
11.12.2023 12:29Все фильтрации применять сразу в запросе, т е не рекомендуется сначала вызвать функцию, а потом применять фильтр
Зависит от функции. Например:
CREATE TABLE dbo.tmp_tmp ( ID int identity(1,1) PRIMARY KEY CLUSTERED, IsActive bit NOT NULL ) INSERT INTO dbo.tmp_tmp (IsActive) VALUES (1), (0), (0), (1), (0), (0), (1) CREATE INDEX IsActive_Idx ON dbo.tmp_tmp(IsActive)Создаем функцию:
CREATE FUNCTION dbo.fn_func_table() RETURNS TABLE AS RETURN ( SELECT ID, IsActive FROM dbo.tmp_tmp )Проверяем:
SELECT t.ID FROM dbo.fn_func_table() AS t WHERE (t.IsActive = 1) |--Index Seek(OBJECT:([test].[dbo].[tmp_tmp].[IsActive_Idx]), SEEK:([test].[dbo].[tmp_tmp].[IsActive]=(1)) ORDERED FORWARD) Table 'tmp_tmp'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Для сравнения:
DROP FUNCTION IF EXISTS dbo.fn_func_table GO CREATE FUNCTION dbo.fn_func_table (@IsActive bit) RETURNS TABLE AS RETURN ( SELECT ID, IsActive FROM dbo.tmp_tmp WHERE IsActive=@IsActive ) GO SELECT t.ID FROM dbo.fn_func_table(1) t |--Index Seek(OBJECT:([test].[dbo].[tmp_tmp].[IsActive_Idx]), SEEK:([test].[dbo].[tmp_tmp].[IsActive]=(1)) ORDERED FORWARD) Table 'tmp_tmp'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Иными словами, для inline функций никакой разницы нет.
Разница возникнет, как только функция перестанет быть inline (в ней появится блок BEGIN ... END).
jobgemws Автор
11.12.2023 12:29Верно, лучше использовать встраиваемые функции и ещё лучше если возможно фильтрацию делать в ней, а не выносить после вызова. Но это если можно по смыслу, не размазывая логику.
ptr128
11.12.2023 12:29Тут был простой случай. Но ведь на практике фильтрации требуется делать далеко не по одному полю и совсем не обязательно на равенство. Параметризация тут может привести к совершенно неудобной в использовании функции.
jobgemws Автор
11.12.2023 12:29Здесь имелось в виду, если можно сделать унификацию и фильтрацию по таблицам, которые есть в функции, чтобы не размазывать логику.
ptr128
11.12.2023 12:29Ну это вопрос не столько к кодированию на SQL, сколько к проблемной части. В общем случае, для inline функции производительность фильтрации в ней и вне её одинакова, что я показал выше. Поэтому смысл фильтровать в inline функции возникает только исходя из требований бизнес-логики.
jobgemws Автор
11.12.2023 12:29Не стоит в общем случае полагаться на оптимизатор. Лучше писать так, чтобы 100% работало без всяких но в надежде на встраиваемую функцию. Сегодня встроит, завтра поменяют чего и не встроит и т д и т п.
ptr128
11.12.2023 12:29А какое отношение это имеет к inline функциям? Они потому и inline, что оптимизатор сначала встраивает их в запрос, а только после этого строит его план. Поэтому для него нет никакой разницы, указана фильтрация в теле inline функции или вне её.
Нет, конечно, если Вы сможете привести пример, когда такая разница возникнет - тогда другое дело. Приведете?
ptr128
11.12.2023 12:29Рекомендуется в условиях фильтрации и соединении слева использовать только индексированные поля.
Наоборот, не рекомендую так делать, чтобы избежать огромного количества индексов и деградации производительности на операциях модификации таблицы.
А вот использовать в в условиях фильтрации и соединении слева выражение, полностью совпадающие с выражением в WHERE частичного индекса - очень хорошо.
Так же, вместо шести индексов (a,b,c,d,e), (a,b,e,c,d), (a,b,d,e,c), (a,b,d,c,e), (a,b,c,e,d), (a,b,e,d,c) часто эффективней один (a,b) INCLUDE (c,d,e), или, иногда, (a,b,c) INCLUDE (d,e)
jobgemws Автор
11.12.2023 12:29Огромное количество индексов не равно деградация системы, а вот без индексов будет беда. Нужно выбирать первичные ключи так, чтобы их значения не менялись или очень редко менялись.
ptr128
11.12.2023 12:29Претензия была не к использованию индексированных полей, а к использованию только индексированных полей. Я привел два примера, когда лучше, чтобы поля не были индексированы.
Могу ближе к проблемной части. Пусть у нас есть таблица, в которой записи по каким-то причинам не удаляются, а лишь помечаются удаленными, установкой в 1 поля IsDeleted bit DEFAULT 0.
В этом случае индекс (a,b) WHERE IsDeleted=0 будет эффективней, чем индекс (IsDeleted,a,b). Причем существенно, так как статистики для первого индекса будут заметно адекватней, чем для второго.
Огромное количество индексов не равно деградация системы
Я этого не писал. Перечитайте: "деградации производительности на операциях модификации таблицы"
jobgemws Автор
11.12.2023 12:29Здесь Вы затронули в том числе правило построения индекса, а именно брать первое ключевое поле, обладающее большей селективностью.
В любом случае у индексированного поля есть статистика, а вот у неиндексированного может и не быть. И когда будет соединение по полю, для которого нет индекса, а таблица при этом большая, то мало того что долго будет искать, так ведь ещё и заблочит больше, чем надо и дольше, чем надо.
По моему очевидно, что по индексируемому полю искать быстрее, чем не по индексируемому, если конечно таблица не меньше 10 000 строк (или такая, которая не может быстро вся быть загружена в оперативную память).
ptr128
11.12.2023 12:29Я уже не знаю, как выделить слово ТОЛЬКО
Претензия была не к использованию индексированных полей, а к использованию только индексированных полей.
Вы же сами написали:
Рекомендуется в условиях фильтрации и соединении слева использовать только индексированные поля.
А я уже третий раз пишу, что часто лучше, чтобы из 4-5 полей в условиях фильтрации одной таблицы, только 2-3 были индексированы, а остальные либо были включены в INCLUDE список, либо фильтровались в WHERE частичного индекса.
Более того, если из этих 4-5 полей в условиях фильтрации одной таблицы 1-2 уже составляют её уникальный кластерный индекс, то остальные три поля вообще не зачем в этот индекс включать и пусть они остаются не индексированными.
BlazeFox
11.12.2023 12:29Вот люблю я "magic numbers", откуда число 10000?
Не всегда index-seek быстрее scan'а: сильно ли быстрее будет seek, если плотность созданного вами индекса = 1/3 (3 уникальных занчения в колонке) при равномерном распределении значений по таблице и объеме ну, скажем 1M+ строк?
Не нужно "изобретать". Индексы это вполне конкретный инструмент, которым как и любым другим инструментом нужно уметь пользоваться. Их создание "на всякий случай" без обдумывания - жёсткий антипаттерн, принимать решение о создании индекса в таблице только на основании того, что у вас в запросе есть фильтр по этой колонке это такое себе.jobgemws Автор
11.12.2023 12:29Вы не туда ушли, но правы.
Если вообще вытаскивать почти все данные из таблицы, то проще уже просканировать всю таблицу. Но мой ответ был дан по другому вопросу, а Вы завернули не туда. Естественно индексы нужно использовать с умом, а именно когда seek будет быстрее скан. Обычно так и происходит при правильном индексирования и если не выгребать большую часть данных из этого индекса/таблицы.
BlazeFox
11.12.2023 12:29Вы здесь говорите о фильтрованном индексе (a, b) с предикатом фильтра IsDeleted = 0?
Индекс, начинающийся с IsDeleted у которого плотность = 0.5 это просто нонсенс, особенно учитывая, что в гистрограмме статистики будет только совершенно ненужный мусор. (leftmost column). При подобном "изобретении" нужно накладывать запрет на профессиию.ptr128
11.12.2023 12:29IsDeleted у которого плотность = 0.5
Не знаю что при чем тут плотность индекса и как Вы её посчитали не зная fillfactor или иные настройки его разреженности. А селективность и кардинальность тут может быть любая. Например, если в таблице из миллиона строк 990 тыс. помечены, как удаленные, то кардинальность выборки по IsDeleted=0 10000, а IsDeleted=1 990000. При этом по отдельности кардинальности a и b могут вполне быть 100000.
И если Вы действительно предлагаете тут индекс (a,b,IsDeleted), зная, что 99% выборок идут с условием IsDeleted=0, то соглашусь, что
При подобном "изобретении" нужно накладывать запрет на профессиию.
)))
jobgemws Автор
11.12.2023 12:29В таком случае вообще лучше таблицу разделить на две-те, где много данных и те, где мало. Или ввести секционирование с двумя секциями.
ptr128
11.12.2023 12:29Миллион записей - это все же очень мало. А если секционировать по IsDeleted, то при установке его в 1 это будет не только обновление индекса, но еще и физическое перемещение записи из одной секции в другую. Такие вещи лучше все же делать не на лету, а периодическим заданием по отдельному критерию.
На самом деле это был очень упрощенный пример. На практике чаще все сложнее. Например, таблица вида:
CREATE TABLE ttt ( ID bigint INDENTITY(1,1), SomeLot int NOT NULL, SomeItem int NOT NULL, Analytic1 int NULL, ... AnalyticN int NULL, ValidFrom datetime2 NOT NULL, ValidUntil datetime2 NULL, CONSTRAINT ttt_PK_Idx PRIMARY KEY CLUSTERED (SomeLot, SomeItem, ValidFrom) ) CREATE UNIQUE INDEX Valid_Idx ON ttt (SomeLot, SomeItem) WHERE ValidUntil IS NULLКогда вставляется запись с уже существующим сочетанием (SomeLot, SomeItem), то уже существующей записи с этим сочетанием и ValidUntil IS NULL присваивается значение из ValidFrom вставляемой записи. Вместо удаления записи, устанавливается только ValidUntil в текущее время.
С одной стороны, это позволяет по первичному ключу получить историю сочетаний (SomeLot, SomeItem) на любую дату. С другой стороны, текущие значения вынимаются моментально по частичному индексу. Ну и обновление кластерного индекса тогда идет только добавлением в него записей, что заметно снижает издержки на его модификацию и их последствия.
Если же записи по одному сочетанию (SomeLot, SomeItem) могут приходить чаще, чем раз в 100 наносекунд, то приходится уже вместо datetime2 использовать bigint с абстрактным временем.
jobgemws Автор
11.12.2023 12:29На практике логическое удаление так делают: сначала метят, затем физически удаляют/переносят как например в 1С.
Но есть и другой пример, активные записи. Это не те, что удалены или не удалены. А те, с которыми работают. Например, открытая сделка/проводка и т д. Таких записей обычно меньше 1 млн, порой даже меньше 100 000. Потому часто видел реализацию и сам так делаю, что такие записи хранят отдельно или в отдельной секции для быстрого доступа. Аналог реализации постоянного кэша данных. Затем когда закрывают сделку/проводку/документ, сразу же запись перемещают в основную таблицу, где много данных. Если там очень много данных, то там тоже свои секции. Очень удобно.
ptr128
11.12.2023 12:29Ну про 1С не надо. Там такими костылями аудиторский след делается, что я даже не представляю, как уважающие себя аудиторы это переваривают.
запись перемещают
Доступность системы при таком подходе страдает сильно. Можете проверить время обработки очередного пакета хотя бы из 100 тыс. записей по приведенной мной схеме и по Вашей. Я уже не в силах написать пример, так как спать хочу.
Естественно таблица секционируется. Естественно есть и архивные секции или даже архивные БД. Но перемещение записей между ними производится периодическими заданиями в периоды низкой нагрузки на систему.
такие записи хранят отдельно или в отдельной секции для быстрого доступа
В большинстве взрослых ERP, которые мне приходилось внедрять, так не делают. Обычно жертвуют нормализацией БД, поддерживая при разноске индексную таблицу только открытых операций, в которой дублируется и агрегируется ряд полей из основной таблицы операций. В финансовой части даже описанный мной выше подход не применим, так как запрещается модификация записей любых разнесенных операций. Ни удалить, ни изменить разнесенную финансовую операцию нельзя. Можно только сослаться на нее, например, в реверсирующей или корректирующей новой операции. В законодательстве ряда стран это жестко прописано.
Само собой, после закрытия периода, сдачи финансовой отчетности и получения аудиторского заключения все транзакции оказываются так покрыты перекрестными агрегатами сданной отчетности, что менять там что-либо самому не захочется. Архивировать - уже пожалуйста.
jobgemws Автор
11.12.2023 12:29Делают, и в NAV, и в CRM, и в 1С и во всех взрослых системах, которые я видел... В том числе в системах реального времени для слежения движения судов и самолётов.
BlazeFox
11.12.2023 12:29Темпоральные таблицы, нет?
Зачем хранить в одном месте и актуальные данные, и исторические? А как чистить то, что вам более не нужно?
ptr128
11.12.2023 12:29Темпоральные таблицы, нет?
Нет. В первую очередь из-за того, что в них время является всегда временем начала транзакции. Это вовсе не то время, которое требуется в бизнес смысле. Например, время снятия показаний с датчика.
Зачем хранить в одном месте и актуальные данные, и истрические?
Например затем, что исторические данные тоже нужны, хоть и реже, чем актуальные.
А как чистить то, что вам более не нужно?
Секционируя по ValidFrom. Но при этом, если из последней секции запись с ValidUntil IS NULL должна быть перемещена в новую архивную секцию, то она предварительно дублируется и закрывается фиктивной записью с более актуальным ValidFrom. Если сам оригинальный ValidFrom все же важен, что изредка случается, то для него выделяется отдельное поле.
BlazeFox
11.12.2023 12:29То, что время в темпоралках - всегда время транзакции это как раз таки офигительный бонус:
Представим себе ситуацию, вы отдали аудированный отчёт по допустим балансу счёта, который ведёте в таблице вроде вашей:
на время A (до секунду) баланс счёта - 100
И прилетает вам событие, которое по каким-л. причинам вы обрабатываете позже о том, что в момент А-1 со счёта было снято 50
И бежите вы доблестно задним числом править аудированные данные
Ну а потом, как водится, приходит аудиторская проверка.
В темпоралках вы храните именно состояние, с которого ваша система учла это событие, если нужна бизнес дата - пожалуйста, храните в той же таблице отдельной колонкой.
Чего вы достигаете:
1. Ваши запросы про баланс счёта на момент A всегда вернут один и тот же результат.
2. Не существует простого способа править данные в исторической части темпоралки - вы автоматически защищены от чьих-нибудь толстых пальцев.
3. Если уж совсем упороться - делаем не обычную темпоралку, а Ledger таблицу, с контрольными суммами, порядками операций аудитом из коробки и прочими прелестями.ptr128
11.12.2023 12:29То, что время в темпоралках - всегда время транзакции это как раз таки офигительный бонус:
Я Вам на пальцах объяснил бизнес-смысл, а Вы вдруг настаиваете на его изменении. Бизнесу надо знать, в какой момент времени эти показания были зафиксированы. Даже не когда они были получены концентратором. И, тем более, не когда они попали в БД.
вы отдали аудированный отчёт по допустим балансу счёта, который ведёте в таблице вроде вашей
прилетает вам событие
Аудит производится только закрытых периодов. А после закрытия периода все операции проводятся только датами открытого периода, даже если они корректируют данные прошлых периодов.
Ну и техника отражений финансовых транзакций настолько регламентирована, что темпоральные таблицы (включая вид описанный мной), тут вообще не применимы. Операция не может быть модифицирована или удалена. В том числе и в бизнес-смысле. Поэтому операций модификации или удаления в таблице финансовых операций не бывают. Бывают только реверсирующие операции (включая красное сторно, которое так не любят в МСФО) и/или корректирующие.
делаем не обычную темпоралку, а Ledger таблицу
Это уже в РФ вряд ли кому интересно. Я не знаю ни одного клиента, планирующего переход на MS SQL 2022. Но почти все планируют переход на PostgreSQL. Это даже не считая того, что как и любая фича, это требует годы для стабилизации. Кроме того, существует масса способов добиться полного аудиторского следа, не повышая нагрузку на продуктивную СУБД криптографией.
ptr128
11.12.2023 12:29Я не знаю ни одной. Купить официально лицензию сейчас невозможно. Поддержку - тем более. Сертификации нет и быть не может. Так что колбасит сейчас всех. И это относится далеко не только к MS SQL. Вот РЖД уже третью попытку делает с DB/2 и Oracle на PostgreSQL перейти. Все клиенты в шоке.
К тому же, по моему опыту, переходить на последнюю версию очень рискованно. Если бы не санкции, я бы сейчас, возможно, занимался переходом на 2019 с 2017 и 2016. Но уж точно не на 2022. Не помню, чтобы новая версия MS SQL ни на одной из клиентских БД не преподнесла сюрпризов. Вот когда выходит следующая версия, тогда уже можно накатывать последний CU и проверять.
Так что и Вам рекомендую больше смотреть на PostgreSQL и потихоньку забывать о приколах MS SQL )
jobgemws Автор
11.12.2023 12:29Лицензии покупают как-то, но покупают. На счёт опасений про последнюю версию верно, но не так страшно, начиная с 2019. И конечно сначала обновляют тестовый стенд и на нем проверяют весь функционал прежде, чем обновлять прод. Главное, использовать российское облако, а ещё лучше - свое корпоративное облако.
И все, что древнее 2019 версии уже старье.
ptr128
11.12.2023 12:29"Как-то" можно купить, чтобы все же поставить. Но официальным это "как-то" не назовешь. Поэтому и не знаю ни одного своего клиента, который покупал бы такие "серые" лицензии. Так же понятно, что 2022 не сертифицируют в ближайшем будущем. А действие сертификатов на более ранние версии, включая 2019, приостановлено. Аналогичная ситуация с Windows Server. Много ли клиентов согласятся переходить на не сертифицированную СУБД? Как минимум, персональные данные есть у всех, а штрафы платить желания мало.
И все, что древнее 2019 версии уже старье.
Подавляющее большинство клиентов соглашаются тратить деньги на переход на новые версии только под давлением поставщика, чтобы не остаться без поддержки. И я их понимаю. Работает - не трожь )
Например, вспоминаю года три назад попытку перейти на 2017-й для одного из клиентов. Даже до тестовой эксплуатации дошли. Вот на ней и обнаружили деградацию производительности tempdb с изоляцией транзакций снимками. Переход отменили. Вот и работают до сих пор на 2016 и вполне счастливы.
jobgemws Автор
11.12.2023 12:29Если следовать санкциям, то остаётся пользоваться только валенками и тулупами. Смартфонами и телевизорами нельзя равно как и транспортом, т к запчасти как минимум зарубежные.
ptr128
11.12.2023 12:29Дайте, пожалуйста, ссылки на законы, из которых Вы сделали такие странные выводы.
jobgemws Автор
11.12.2023 12:29В 2017 версии нужно правильно настроить, и все работает как надо. Там была проблема в другом, но деталей уже не помню.
ptr128
11.12.2023 12:29Ага, от изоляции снимками отказаться. Исправление этого вышло в CU через год одновременно для 2017 и 2019.
jobgemws Автор
11.12.2023 12:29Напр, вот так покупают лицензии: https://habr.com/ru/companies/ruvds/articles/726900/
ptr128
11.12.2023 12:29И что? В облако нельзя, так как ФСТЭК приостановил лицензии. Покупают "серые" лицензии только бедные, от безысходности и надеясь, что пронесет. Благо на проверки малых предприятий еще действует мораторий.
И какой смысл бизнесу тратить деньги на переход с проверенной в работе версии на не поддерживаемую? За последние два года ни одного желающего не видел.
jobgemws Автор
11.12.2023 12:29Ну да, зачем обновляться. Можно же сидеть и дальше на 2000 версии, все же работает. Такое ощущение, что Вы какой-то завод описываете.
ptr128
11.12.2023 12:29зачем обновляться
Я же писал выше зачем:
"Подавляющее большинство клиентов соглашаются тратить деньги на переход на новые версии только под давлением поставщика, чтобы не остаться без поддержки."
Такое ощущение, что Вы какой-то завод описываете.
Ну если Вы собрались за свои личные деньги обновляться - тогда совсем другой вопрос )))
Можно же сидеть и дальше на 2000
Его поддержка была прекращена лет 15 назад. И если расширенная поддержка (которую уже невозможно купить в РФ) доступна начиная с 2014-го, то базовая поддержка даже для 2017-го уже закончилась в прошлом году.
ptr128
11.12.2023 12:29Кстати, по поводу сертификатов тут все серьезно. Хранить персональные данные в любой версии MS SQL, купленной после марта 2022 года незаконно. В купленной ранее - можно. Но только пока, так как приостановка действия сертификата обратной силы не имеет. Для 2016-го срок истек в августе, но обещали не трогать до конца этого года. Для 2017-го - до конца февраля 2024 года. Для 2019-го - покрыто мраком, так я нашел приостановленный сертификат только для MS SQL Server IoT.
Так что упомянутые Вами крупные компании, рискнувшие перейти на MS SQL 2022, рискуют оказаться дойными коровами для бюджета, выплачивая не хилые штрафы.
jobgemws Автор
11.12.2023 12:29А как именно рискуют, если все ПО на своих корпоративных серверах со своим корпоративным облаком?
ptr128
11.12.2023 12:29В зависимости от категории риска, к которой отнесено предприятие, выездная проверка должна производится не реже, чем раз в 2-6 лет.
BlazeFox
11.12.2023 12:29Тяжело иногда с теми, кто не хочет слышать. Идём и курим, что такое index density и как она связана с cardinality.
Я не предлагал IsDeleted вносить в индекс, читайте внимательнее. Я говорил, что строить индекс по колонке в которой всего 2 уникальных значения это дурь сама по себе, если уж у вас так сильно перекошенны данные, что одного значения 10%, а другого 90, то по 10% надо строить именно фильтрованный индекс и не страдать историями про частичное покрытие.
ptr128
11.12.2023 12:29надо строить именно фильтрованный индекс
Ну если бы Вы удосужились читать, то что я пишу, то именно эту рекомендацию от меня бы и увидели )))
BlazeFox
11.12.2023 12:29Я слова "фильтрованный" не увидел в вашем посте вот совсем
ptr128
11.12.2023 12:29В SQL частичный индекс, который Вы назвали "фильтрованный", это индекс с выражением WHERE, что я и написал изначально:
"А вот использовать в в условиях фильтрации и соединении слева выражение, полностью совпадающие с выражением в WHERE частичного индекса - очень хорошо."
"индекс (a,b) WHERE IsDeleted=0"
jobgemws Автор
11.12.2023 12:29В документации есть понятие фильтрованного индекса, а не частичного в данном случае.
ptr128
11.12.2023 12:29А в стандарте употребляется словосочетание "partial index". Так что, если Вам это мешает, пишите MS, чтобы соответствовали стандарту )
ptr128
11.12.2023 12:29Не нашел, где скачать свежий стандарт. До 2011 года включительно индексы вообще не стандартизировались. Предлагаю пока удовлетвориться тем, что я не знаю ни одной СУБД, кроме MS SQL, где частичные индексы назывались бы фильтрованными. В Hana, PostgreSQL, Informix, SQLite, YugobyteDB, MongoDB и даже в django употребляется термин "partial index". Ну а при стандартизации работает правило большинства.
В принципе, с точки зрения семантики, "частичный индекс" намного лучше описывает результат применения выражения WHERE при создании индекса. Все же индекс строится не по всей таблице, а лишь по ее части, отфильтрованной выражением. Тогда как термин "фильтрованный индекс" приводит к когнитивному диссонансу. Ведь сам индекс никак не фильтруется. Фильтруются данные в таблице при построении индекса, а вовсе не индекс. Тогда уже надо было бы писать"индекс по фильтрованным данным"
jobgemws Автор
11.12.2023 12:29По англ да, а по русски лучше перевести до конца, а не тупо буквально, т е не частичный, а индекс с фильтром или фильтрующий индекс. И сразу всем всё понятно даже если человек не знает что такое индекс. Это как с партициями. Да, на англ так и звучит, но на русском правильно перевести как секции. А то какие-то партиции...непонятно так с ходу.
Бэкапы на англ, на русском-резервные копии. И т д
ptr128
11.12.2023 12:29По английски тогда "filtered data index". Но "partial index" лаконичней.
индекс с фильтром или фильтрующий индекс
"index with filter" или "filter index" - опять хрень.
jobgemws Автор
11.12.2023 12:29Нет, нужно правильно переводить по смыслу: https://learn.microsoft.com/ru-ru/sql/relational-databases/indexes/create-filtered-indexes?view=sql-server-ver16
ptr128
11.12.2023 12:29Машинный перевод на MS перевел, как "отфильтрованные индексы", несмотря на то, что фильтруются данные для индексации, а вовсе не сами индексы. И что Вы хотели этим сказать?
jobgemws Автор
11.12.2023 12:29Это не машинный перевод. При машинном переводе прямо пишут, что это машинный перевод. Еще раз почувствуйте разницу: частичный/кусочный индекс или индекс с фильтром/фильтрующий индекс. Второе сразу понятно что это, а первое? Нужно переводить на язык по смыслу. Или Вы и здесь спорить будете?
jobgemws Автор
11.12.2023 12:29Окс, но на самом деле на русском и правда пишут не частичный, а фильтрованный индекс или индекс с фильтром: https://sql--ex-ru.turbopages.org/turbo/sql-ex.ru/s/blogs/?pcgi=%2FFiltrovannye_indeksy.html
Даже в переведенной студии SSMS на русском и даже в книге по подготовке к сертификации MS SQL 2012. Да много где, только здесь первый раз встретил фразу "частичный индекс".
qw1
11.12.2023 12:29У переводчиков MS свой словарик. Например, мне было трудно привыкнуть к "секционированию", когда оно всегда было калькой с английского "партиционированием". Стараюсь избегать русских версий, что Visual Studio, что SSMS (одно только "Строй всё" чего стоит...)
jobgemws Автор
11.12.2023 12:29А причем тут переводчик MS? Секционирование - это перевод на русский в принципе, а "партиция" такого слова просто нет в русском языке.
Бэкапа тоже нет и фолдера нет, но есть резервная копия, папка/каталог. Даже звучат по русски. По мне либо писать на англ тогда уж эти слова/фразы, либо если на русском, то с правильным по смыслу переводом. А то прям уши режет.
BlazeFox
11.12.2023 12:29Позвольте я закончу ваш дискус - я переводил термины на русский просто для того, чтобы мои ответы не были целиком написаны на руслише. Пользую я ofc только en-us версии всех сред разработки, на этом же языке знаком из терминологией.
Получилось так, что мы друг-друга не поняли (хотя говорили об одном и том же) - бывает. Не думал что это вызовет такой сильный резонанс, sry.
jobgemws Автор
11.12.2023 12:29Тоже в основном использую англ версии ПО в работе, кроме ОС на ноуте. Просто когда англ слова пишут русскими буквами-режет глаза и слух.

Tzimie
Большинство из этого верно, но как всегда на почти каждый пункт существуют контрпримеры. Иначе бы нам, DBA, не платили бы)
jobgemws Автор
Конечно есть, но в каждом конкретном случае исключение должно быть оправдано и аргументировано.
sshikov
Вот кстати, мотивации иногда в этом списке не хватает. Некоторые советы правда очевидны, но некоторые вовсе нет. Один пример - что значит не используйте UNION? Этож почти тоже самое что не используйте where, а то будет медленно :) Более осмысленно было бы порекомендовать что-то на замену.
jobgemws Автор
Про UNION дан ответ почему в п.30. В данной публикации не было цели прям всё разжевать, а дать выжимку из обобщенного опыта как лучше делать (где-то раскрыто почему, а где-то нет-значит можно легко нагуглить или провести тест самостоятельно)