

Мой open-source продукт. Rete neurale per la previsione di Dati tabulari. (it.)
Простая реализация архитектуры глубокой нейронной сети для табличных данных с автоматической генерацией слоев и послойным сокращением количества нейронов. С удобством использования, аналогичным классическим методам машинного обучения.
В данной статье рассмотрим причину создания данной библиотеки, проведем "туториал" и сравним точность прогнозирования DatRetClassifier и DatRetRegressor с классическими методами машинного обучения.
Введение
Для прогнозирования табличных данных чаще всего используются классические методы машинного обучения. Наиболее часто реализованные в scikit-learn. Одним из преимуществ данной библиотеки является простота использования. Предподготавливаем данные, делаем fit и predict, готово.
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(X, y)
print(clf.predict([[0, 0, 0, 0]]))Использование нейронных сетей, в частности библиотек Tensorflow или PyTorch предполагает построение архитектуры модели нейронной сети и затем обучение и прогнозирование. Требует более высокий порог вхождения.
Реализовано много готовых архитектур нейронных сетей для работы с изображениями, текстом, звуком. Не так много для работы с табличными данными - пример TabNet.
Основной целью создания DatRet ставил понижение порога вхождения для работы с нейронными сетями. Реализовал обучение и прогнозирование данных, как в классических методах, например RandomForestClassifier или CatBoostClassifier. Для этого создал автоматическую генерацию архитектуры нейронной сети, исходя из количества выбранных нейронов в первом полносвязном слое. Второй целью, ставил попытку приблизиться по точности прогнозирования структурированных табличных данных к классическим методам.
В модели реализовано три класса:
DatRetClassifier для задач классификации.
DatRetRegressor для задач регресии
DatRetMultilabelClassifier для "многометочной" классификации.
Преимущества
простота и удобство использования. Fit и predict et Voila!
автоматическая генерация архитектуры нейроннной сети
быстрая настройка параметров модели
поддержка GPU
высокая точность прогнозирования
поддержка multilabel классификации
Tensorflow под капотом ;)
Установка
Исходный код в настоящее время размещен на GitHub по адресу: GitHub — AbdualimovTP/datret: реализация Tensorflow для структурированных табличных данных Двоичные установщики последней выпущенной версии доступны на веб-сайте Python. Индекс пакетов (PyPI)
# PyPI
pip install datretЗависимости
Быстрый старт
Обучение и прогнозирование модели реализовано как в scikit-learn. Подготовьте трейновую и тестовую выборку и запустите обучение модели. Поддержка автоматической нормализации данных для нейронных сетей.
NB! Не забудьте установить зависимости перед использованием модели. Вам понадобятся установленные Tensorflow, Numpy, Pandas и Scikit-Learn.
NB! Нет необходимости выполнять one-hot encoding прогнозируюмых значений для задачи классификации. Модель сделает автоматически.
# load library
from datret.datret import DatRetClassifier, DatRetRegressor, DatRetMultilabelClassifier
# prepare train, test split. As in sklearn.
# for example
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=i)
# Call the regressor or classifier and train the model.
DR = DatRetClassifier() # DatRetRegressor works on the same principle
DR.fit(X_train, y_train)
# predict the actual label (or class) over a new set of data.
DR_predict = DR.predict(X_test)
# predict the class probabilities for each data point.
DR_predict_proba = DR.predict_proba(X_test) # Missing in DatRetRegressor, DatRetMultilabelClassifierНастраиваемые параметры модели
Параметры :
epoch: int, по умолчанию = 30. Количество эпох для обучения модели.
optimizer: str, (имя оптимизатора) или экземпляра оптимизатора. См. tf.keras.optimizers, по умолчанию =
Adam(learning_rate=0.001). В DatRetRegressor скорость обучения по умолчанию = 0,01.loss: функция потери. str. См. tf.keras.losses , значение по умолчанию для DatRetClassifier =
CategoricalCrossentropy(), для DatRetRegressor =MeanSquaredError().verbose: 'авто', 0, 1 или 2, по умолчанию = 0. Выводит обучение модели по эпохам.
number_neurons: int, по умолчанию = 500. Количество слоев в первом полносвязном слое. Последующие слои генерируются автоматически с вдвое меньшим количеством нейронов.
validation_split: float от 0 до 1, по умолчанию = 0. Доля данных обучения, которые будут использоваться в качестве данных проверки. Модель будет выделять эту часть обучающих данных, не будет обучаться на ней и будет оценивать потери и любые метрики модели на этих данных в конце каждой эпохи.
batch_size: int , по умолчанию = 1. Количество выборок на обновление градиента. Steps_per_epoch рассчитывается автоматически,
X_train.shape[0] // batch_sizeshuffle: True или False, по умолчанию = True. "Перемешивание" обучающей выборки.
callback:
[], по умолчанию =[EarlyStopping(monitor='loss', mode='auto', patience=7, verbose=1), ReduceLROnPlateau(monitor='loss', factor=0.2, patience=3, min_lr=0.00001, verbose=1)]. Сallbacks : утилиты, вызываемые в определенные моменты во время обучения модели.
Настраиваемые параметры метода fit .
Параметры:
normalize: True or False, по умолчание True. Автоматическая нормализация входящих данных. Используется MinMaxScaler.
Пример настройки модели:
# load library
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, Nadam
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from tensorflow.keras.losses import CategoricalCrossentropy, MeanSquaredError, BinaryCrossentropy
from datret.datret import DatRetClassifier, DatRetRegressor, DatRetMultilabelClassifier
# prepare train, test split. As in sklearn.
# for example
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=i)
# Call the regressor or classifier and train the model.
DR = DatRetClassifier(epoch=50,
optimizer=Nadam(learning_rate=0.001),
loss=BinaryCrossentropy(),
verbose=1,
number_neurons=1000,
validation_split = 0.1,
batch_size=100,
shuffle=True,
callback=[])
DR.fit(X_train, y_train, normalize=True)
# predict the actual label (or class) over a new set of data.
DR_predict = DR.predict(X_test)
# predict the class probabilities for each data point.
DR_predict_proba = DR.predict_proba(X_test)Архитектура модели
Модель генерирует архитектуру автоматически, исходя из количества нейронов в первом полносвязном слое. Например, при использовании number_neurons = 500в первом полносвязном слое и наличием 2-х прогнозируемых классов (0, 1) - нейронная сеть автоматически будет иметь данную архитектуру.
Model: "DatRet with number_neurons = 500"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, X_train.shape[0)] 0
dense (Dense) (None, 500) 150500
dense_1 (Dense) (None, 250) 125250
dense_2 (Dense) (None, 125) 31375
dense_3 (Dense) (None, 62) 7812
dense_4 (Dense) (None, 31) 1953
dense_5 (Dense) (None, 15) 480
dense_6 (Dense) (None, 7) 112
dense_7 (Dense) (None, 3) 24
dense_8 (Dense) (None, 2) 8
(2 predictable classes)
=================================================================
Total params: 317,514
Trainable params: 317,514
Non-trainable params: 0Сравнение точности с классическими методами машинного обучения
DatRetClassifier для задач классификации
Чтобы оценить точность классификатора, мы будем использовать Pima Indians Diabetes Database | Kaggle. Метрика RocAucScore. Буду сравнивать DatRet с RandomForest и CatBoost «из коробки». Полная версия ноутбука реализована в GitHub.
for i in [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]:
X_train, X_test, y_train, y_test = train_test_split(data.drop(["Outcome"], axis=1), data["Outcome"],
random_state=10, test_size=i)
#RandomForest
RF = RandomForestClassifier(random_state=0)
RF.fit(X_train, y_train)
RF_pred = RF.predict_proba(X_test)
dataFrameRocAuc.loc['RandomForest'][f'{int(i*100)}%'] = np.round(roc_auc_score(y_test, RF_pred[:,1]), 2)
#Catboost
CB = CatBoostClassifier(random_state=0, verbose=0)
CB.fit(X_train, y_train)
CB_pred = CB.predict_proba(X_test)
dataFrameRocAuc.loc['CatBoost'][f'{int(i*100)}%'] = np.round(roc_auc_score(y_test, CB_pred[:,1]), 2)
#DatRet
DR = DatRetClassifier(optimizer=Adam(learning_rate=0.001))
DR.fit(X_train, y_train)
DR_pred = DR.predict_proba(X_test)
dataFrameRocAuc.loc['DatRet'][f'{int(i*100)}%'] = np.round(roc_auc_score(y_test, DR_pred[:,1]), 2)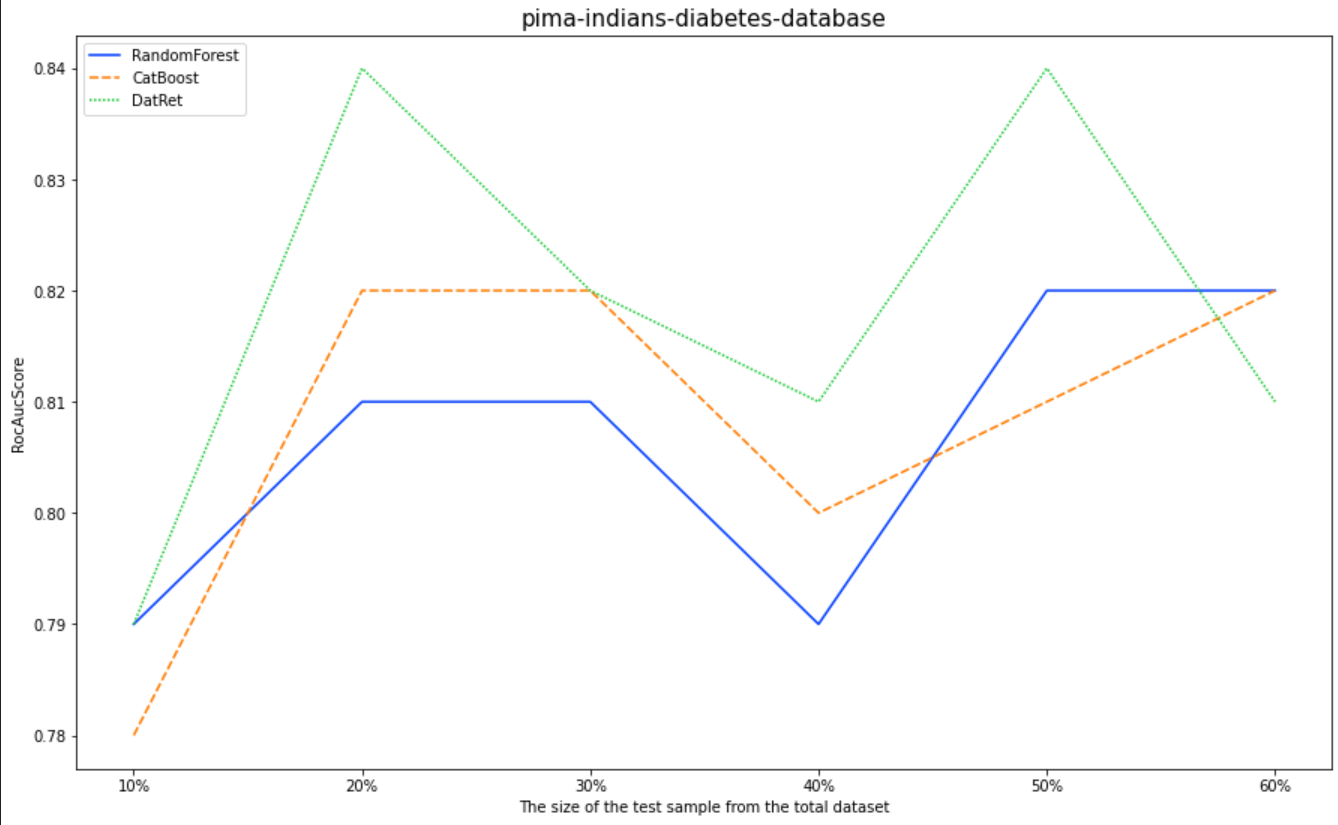
10% |
20% |
30% |
40% |
50% |
60% |
|
|---|---|---|---|---|---|---|
RandomForest |
0.79 |
0.81 |
0.81 |
0.79 |
0.82 |
0.82 |
CatBoost |
0.78 |
0.82 |
0.82 |
0.8 |
0.81 |
0.82 |
DatRet |
0.79 |
0.84 |
0.82 |
0.81 |
0.84 |
0.81 |
DatRetRegressor для задач регресии
Чтобы оценить точность регрессора, мы будем использовать наборы данных Medical Cost Personal Datasets | Kaggle. Метрика среднеквадратическая ошибка . Буду сравнивать DatRet с RandomForest и CatBoost «из коробки». Полная версия ноутбука реализована в GitHub.
for i in [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]:
X_train, X_test, y_train, y_test = train_test_split(data.drop(["charges"], axis=1), data["charges"],
random_state=10, test_size=i)
#RandomForest
RF = RandomForestRegressor(random_state=0)
RF.fit(X_train, y_train)
RF_pred = RF.predict(X_test)
dataFrameRMSE.loc['RandomForest'][f'{int(i*100)}%'] = np.round(mean_squared_error(y_test, RF_pred, squared=False), 2)
#Catboost
CB = CatBoostRegressor(random_state=0, verbose=0)
CB.fit(X_train, y_train)
CB_pred = CB.predict(X_test)
dataFrameRMSE.loc['CatBoost'][f'{int(i*100)}%'] = np.round(mean_squared_error(y_test, CB_pred, squared=False), 2)
#DatRet
DR = DatRetRegressor(optimizer=Adam(learning_rate=0.01))
DR.fit(X_train, y_train)
DR_pred = DR.predict(X_test)
dataFrameRMSE.loc['DatRet'][f'{int(i*100)}%'] = np.round(mean_squared_error(y_test, DR_pred, squared=False), 2)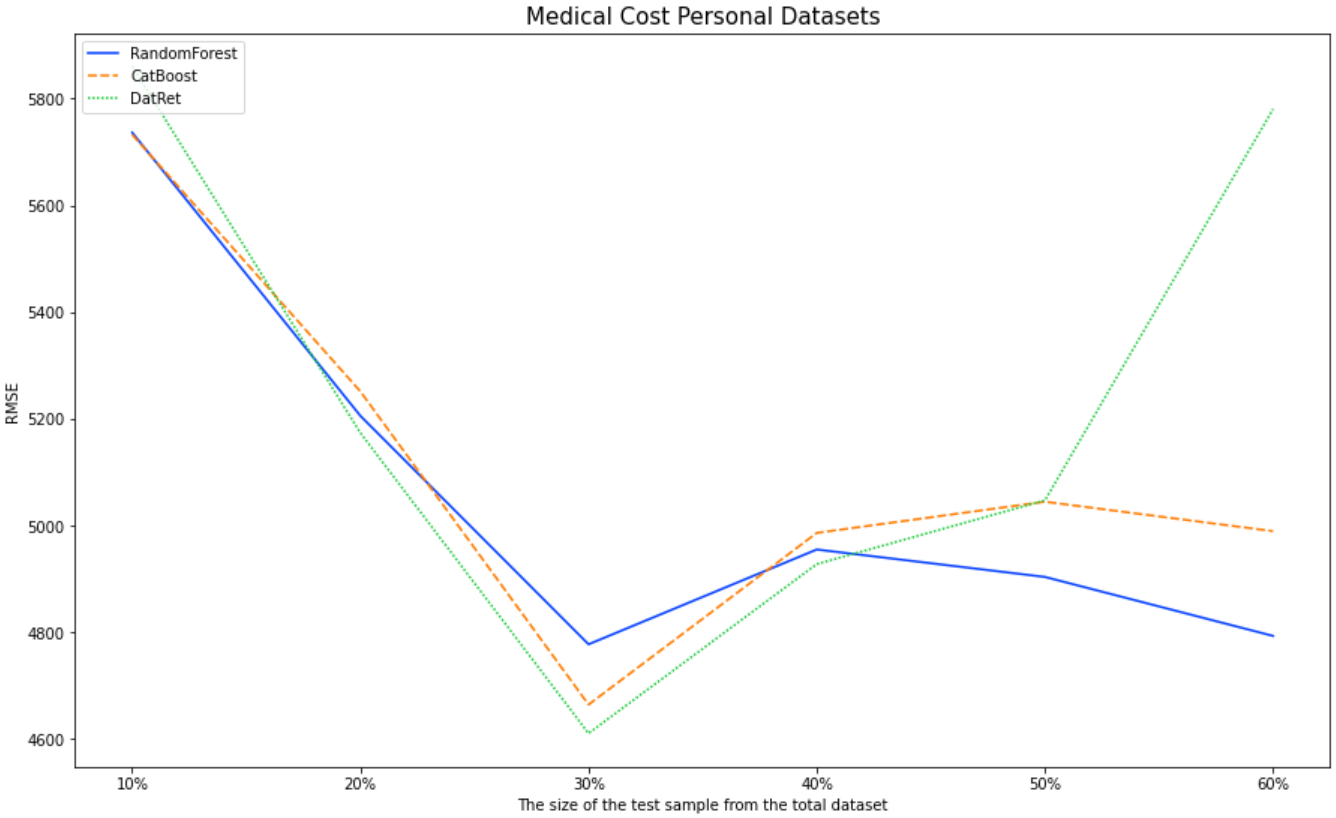
10% |
20% |
30% |
40% |
50% |
60% |
|
|---|---|---|---|---|---|---|
RandomForest |
5736 |
5295 |
4777 |
4956 |
4904 |
4793 |
CatBoost |
5732 |
5251 |
4664 |
4986 |
5044 |
4989 |
DatRet |
5860 |
5173 |
4610 |
4927 |
5047 |
5780 |
Неплохие результаты для работы модели "из коробки".
В задаче классификации на 10%, 20%, 30%, 40%, 50% от общего датасета тестовой выборки DatRet показал лучшие результаты.
В задаче регресии на 20%, 30%, 40% от общего датасета тестовой выборки DatRet выдает лучшую точность.
В дальнейшем планирую оценить точность модели на иных датасетах. Также вижу возможности для улучшения качества прогнозирования. Планирую реализовать в следующих версиях библиотеки.