

Как вы думаете, какие характеристики сильнее влияют на скорость сборки вашего проекта: частота CPU или частота оперативной памяти? Количество ядер CPU или количество оперативной памяти? Влияет ли скорость постоянной памяти на скорость сборки? Однажды у меня в голове возникли такие вопросы, и я решил найти на них ответы. Лучший способ для этого — провести тесты. Поэтому представляю вам их результаты и попытаюсь их объяснить в меру своих знаний. Если хотите узнать, что больше всего влияет на скорость сборки, ну или, может быть, хотите обновить компьютер для сборки, но не знаете, во что лучше вложится, то добро пожаловать в статью.
Начнём с того, что «А зачем вообще нам это знать?».
По сути, есть одна основная проблема — непонятно, какое железо стоит брать.
Обычно бюджет покупки ограничен. Будь это покупка компьютера для себя или же для CI. Хочется за свой бюджет получить максимум.
Из чего следуют основные цели статьи:
Понять, какие параметры и как влияют на скорость сборки.
Как следствие, понять, что лучше купить.
Как следствие, понять, как сэкономить.
Ну и косвенно заденем тему разницы во времени сборки между одномодульным и многомодульным проектами.
Для начала, чтобы результаты тестов для нас были простыми и понятными, давайте определим методологию.
Методология
Сразу предупреждаю: циферок будет много. Очень. Но что поделать, такой «жанр».
Компьютер
Начнём со стенда, над которым и будем издеваться.
Собственно, это мой домашний комп. Так что не ищите сакральной логики в подборе компонентов.
CPU: Ryzen 5 3600, 6 ядер, 12 потоков. Максимальная частота в бусте — 4200 МГц.
RAM: две планки по 8 Гб, две планки по 16 Гб. От Crucial.
Накопители: ноутбучный HDD 2.5”, конечно же, обычный HDD 3.5“, Sata SSD, NVMe SSD.
По умолчанию, если в описании теста не указано иное:
Процессор в режиме Auto. Базовая частота — 3600 МГц, буст до — 4200 МГц.
32 Гб оперативной памяти.
Накопитель NVMe SSD.
Ну и в качестве операционной системы у нас Windows 11.
Проект
В целом данные тесты можно спокойно интерпретировать к любым Gradle JVM проектам. В качестве тестового проекта возьмём наше Android приложение Циан.
На момент проведения тестов в нём: 410 Gradle модулей, 443 тысячи строк Kotlin, 113 тысяч строк Java и 175 тысяч строк XML. Что-то мне подсказывает, что мобильные приложения из тонких клиентов свернули куда-то не туда…
Инструменты измерения
Для проведения тестов будем использовать Gradle Profiler. Это специальный инструмент, который позволяет производить измерения времени сборки и отдельных её этапов. Также он позволяет писать кастомные сценарии. Что нам очень понадобится.
Затем он генерирует красивый отчёт, в котором сам определяет минимальное, максимальное и медианное время сборки и даже график рисует.

Сценарии
Всего их три:
Многомодульная горячая.
Многомодульная холодная.
Одномодульная холодная.
По названиям, естественно, ничего не понятно, поэтому давайте подробнее разберём каждый из них. Начнём с многомодульной горячей.
Горячая сборка приложения
Для её симуляции просто вносим изменения в Kotlin файл одного из фичёвых модулей и перезапускаем сборку. Этот модуль подключён только к главному (app) модулю, как runtimeOnly.
Опасным красным цветом отмечены модули, которые пересоберутся, а зелёным — те, что будут UP-TO-DATE. Выглядит это как-то так:

То есть при изменениях в нём ничего лишнего собираться не будет. Только модуль, в котором произошли изменения и app-модуль. На timeline сборки у нас большинство модулей будут UP-TO-DATE. Так как изменений в части модулей нет, значит и собирать их смысла нет. Модуль с изменениями и app-модуль будут собраны.

По сути, это самый частый сценарий. Я бы назвал его основным.
Холодная сборка приложения
Для её симуляции будем перед сборкой делать clean, а также передадим в Gradle аргумент --no-build-cache. Таким образом, кэши задействованы не будут. Как можно заметить — ни капелюшечки зелёного цвета. Всё красное. В итоге пересоберётся весь проект.

За счёт многомодульности clean и сборка будет осуществляться параллельно, насколько это возможно. Например, последний модуль app обычно собирается в полном одиночестве.

Холодную сборку на локальной машине приходится делать довольно редко. Только когда в проекте что-то поменялось кардинально. Но всё же приходится. Поэтому проверяем.
Холодная сборка приложения, как будто оно одномодульное
Не все используют многомодульность. А вдруг результаты для одномодульных проектов могут сильно отличаться? Непорядок. Поэтому давайте попытаемся симулировать и такой тип сборки.
Для этого всё также перед сборкой будем делать clean, а также передадим в Gradle аргумент --no-build-cache. Но в дополнение к этому установим всего один Gradle Worker с помощью --max-workers 1 и передадим флаг --no-parallel.
С точки зрения структуры, относительно многомодульной сборки, у нас ничего не меняется.

А вот timeline изменится кардинально. Вместо параллельной сборки у нас все составляющие сборки будут выполняться последовательно.

За счёт этого получается симулировать одномодульное приложение, в котором также всё делается последовательно.
Предупрежу, что будь у нас реальное одномодульное приложение, то оно бы собралось быстрее, чем симуляция, так как не было бы задержек из-за конфигурации и запуска гораздо большего количества task. Но для нас это приемлемо, так как мы будем сравнивать получившиеся результаты только между собой.
Количество прогонов
Каждый сценарий прогоняется 6 раз: первый раз для «прогрева» и ещё пять раз происходят измерения. В качестве финального результата считаем медианное время сборок.

Это значит, что мы сортируем результат пяти прогонов от меньшего к большему и берём тот, что посередине.
Погрешность
В целом нужно понимать, что у всех железо разное, поэтому не стоит смотреть на абсолютные цифры. Основным критерием будет являться процент, на который стала быстрее собираться сборка. Так как у нас могут быть погрешности, то разницу меньше, чем в 2% не будем учитывать. «2%» — потому что примерно такая разница между значениями, полученными, если последовательно перезапускать сценарии без изменения конфигурации компьютера. Эта минимальная цифра, которую мне удалось достичь. Пришлось побаловаться с настройками Windows, антивируса и служб.
Также прикладываю текст файла со сценариями для Gradle Profiler. Мало ли кто-то захочет проверить или повторить тесты.
Сценарии Gradle Profiler
default-scenarios = ["clean_parallel", "cold_parallel", "hot_parallel", "clean_mono", "cold_mono"]
clean_parallel {
title = "Clean"
cleanup-tasks = ["clean"]
warm-ups = 1
iterations = 5
}
cold_parallel {
title = "Clean AssembleDebug without cache"
tasks = ["assembleDebug"]
warm-ups = 1
cleanup-tasks = ["clean"]
iterations = 5
daemon = none
gradle-args = ["--no-build-cache"]
}
hot_parallel {
title = "AssembleDebug with change kt file"
tasks = ["assembleDebug"]
warm-ups = 1
iterations = 5
apply-abi-change-to = "modules/feature/worktime_settings/impl/src/main/kotlin/ru/cian/worktime/settings/impl/domain/ports/WorkTimeSettingsRepository.kt"
}
clean_mono {
title = "Clean mono"
cleanup-tasks = ["clean"]
gradle-args = ["--no-parallel", "--max-workers", "1"]
warm-ups = 1
iterations = 5
}
cold_mono {
title = "Clean AssembleDebug without cache mono"
tasks = ["assembleDebug"]
gradle-args = ["--no-build-cache", "--no-parallel", "--max-workers", "1"]
warm-ups = 1
cleanup-tasks = ["clean"]
iterations = 5
daemon = none
}
Gradle Properties
Я постарался не включать настройки, которые бы сильно влияли на погрешность, хоть и ускоряли бы время сборки. Поэтому никаких кэшей. Да, это я про вас: Build Cache и Configuration Cache. Мы вас любим, но не сегодня.
Начнём с настроек, которые не будут меняться:
org.gradle.daemon=false
org.gradle.caching=false
org.gradle.configureondemand=false
kotlin.daemon.jvm.options=-Xmx4g
kotlin.incremental=true
kapt.use.worker.api=true
kapt.incremental.apt=true
kapt.include.compile.classpath=falseСобственно, это флаги отключения демона, кэшей и включения инкрементальной сборки для лучшей параллельности. Ничего особо интересного.
Поэтому посмотрим на те настройки, что будут менятся:
org.gradle.jvmargs=-Xmx24g -XX:+UseParallelGC
org.gradle.workers.max=12Начнём с org.gradle.jvmargs.
-XX:+UseParallelGC неплохо ускоряет время работы GC. Всё, что он делает, это включает параллельный GC. Делает он это стабильно, так что он, по сути, тоже постоянный.

А вот -Xmx24g уже нет. Это количество оперативной памяти, которое мы выделяем куче для сборщика Gradle.

А почему не выдать ему всю доступную оперативную память и не париться? Не стоит забывать, что сама операционка жрёт оперативу, как беременная лошадь. Плюс у сборщика Gradle есть не только куча, но и стек. Он так-то тоже место занимает. Так ещё и компилятор Kotlin отжирает немножко. И при выставлении слишком большого значения сборка, наоборот, сильно замедлится, так как начнёт использоваться swap.
Экспериментально-эмпирическим методом выяснено, что наш проект не собирается с -Xmx4g. Собирается при -Xmx5g, но много времени тратится на GC. Ну а при -Xmx6g он вообще «сладкая булочка» работает стабильно и быстро. Поэтому минимально приемлемым является именно 6 Гб.
Идеальным для тестов вариантом стала сложнейшая формула: «общее количество оперативы» минус 8 Гб. Которые как раз и уйдут на ОС, stack и т.п. Так как в тестах мы будем использовать либо 16 Гб, либо 32 Гб, то это параметр будет либо -Xmx8g либо -Xmx24g соответственно.
Напоследок про org.gradle.workers.max. С ним всё просто. Это количество Gradle Worker, которые будет использовать Gradle. Выставлять будем по принципу: количество Gradle Worker равно количеству потоков процессора.
Что измеряем?
А что же мы в итоге будем измерять? Я долго думал, как можно поиздеваться над компьютером, и в голову мне пришли следующие варианты:
частота ядер CPU;
количество ядер/потоков CPU;
количество оперативной памяти;
частота оперативной памяти;
скорость чтения/записи постоянной памяти.
По итогу мы увидим общее время сборки, а также время её составляющих:
время конфигурации;
время clean, для холодных сборок;
время, которое затрачивает GC на очистку памяти во время сборки;
время самой сборки.
Пример
Ну и чтобы потом не путаться, взглянем на пример результатов теста.

Слева перечислены варианты теста. В самом верху — цветовая легенда, чтобы не запутаться. Справа — общее время сборки для варианта. По центру — timeline варианта. Он разбит по цветам, соответствующим легенде. И тут же рядом — количество процентов, на которое сборка стала собираться быстрее относительно первого варианта.
Приступим, наконец, к тестам.
Частота ядер
Тут всё просто. В BIOS убираем Turbo Boost и фиксируем частоту процессора. У нас будет: 3000 МГц в качестве минимума, 3600 МГц, что на 20% больше минимума, и 4200 МГц, что аж на 40% больше минимума.
Посмотрим на результаты:

И мы получаем +14.2% на 3600 МГц и +23.7% на 4200 МГц. Результат очень даже значительный.
Видно, что в холодной сборке большую часть времени занимает build (кто бы мог подумать). Следом по времени идёт GC. Затем конфигурация. И в самом конце плетётся clean.
Прирост от наращивания частоты большой, но можно заметить, что при переходе с 3000 МГц на 3600 МГц (прирост на 20%) мы ускорились на 14.2%. А вот при переходе с 3000 МГц на 4200 МГц (прирост на 40%) мы ускорились лишь на 23.7%. То есть зависимость частоты от скорости сборки нелинейная.

+15.7% на 3600 МГц и +25.8% на 4200 МГц. Прирост даже выше, чем в многомодульном варианте.
Но сразу бросается в глаза, что «типа одномодульная» сборка в абсолютных цифрах медленней в три с половиной раза. Применяя сложные технологии интерполяции и экстраполяции запатентованным алгоритмом «Пальцем в небо», мы можем предположить, что одномодульная сборка медленней где-то втрое. Разница колоссальная. Но в то же время…
Может возникнуть вопрос: «А почему не в 12 раз? Мы использовали для одномодульной сборки 1 Worker, а для многомодульной — 12. «Где мой прирост в 1200% Лебовски?». Всё дело в том, что Gradle довольно умненький, и его Tasks хорошо параллелятся. Даже при одном Worker он занимает все 12 потоков процессора. Пусть и всего на 30-40%. Поэтому вся суть ускорения сборки от многомодульности раскрывается в горячей сборке. К слову о ней.

+17.9% на 3600 МГц и +24.7% на 4200 МГц. Моё почтение. В абсолютных цифрах это в 40 раз быстрее одномодульной холодной.
Сразу о слоне в комнате показателях теста: конфигурация занимает почти половину времени. Сама сборка 40% и 15% отбирает GC. Поэтому Configuration Cache и флаг
org.gradle.configureondemand=trueтак важны в горячих сборках.
Выводы
Разница между 3Ггц и 4.2 Ггц — 25% при приросте частоты на 40%. Прирост нелинейный.
Холодная многомодульная сборка быстрее одномодульной не в 12 раз, а в 3 раза. Если вы думали иначе, то передумайте. Вся скорость многомодульности в горячих сборках.
Горячая сборка очень любит Configuration Cache.
Количество ядер
В BIOS возвращаем Turbo Boost и ставим частоту на Auto (на удивление, это почти не влияет на погрешность). Вместо этого балуемся с количеством физических ядер, выбирая между четырьмя и шестью. Так как у нас есть SMT (аналог Hyper-Threading от Intel) который на каждое физическое ядро создаёт два логических потока, то и число потоков у нас варьируется от 8 до 12. То есть увеличивается на 50%.

Прирост, конечно, меньше, чем в случае с частотой. Но тоже очень хороший. Правда есть один нюанс… В данном случае сильно важно, насколько хорошо у вас всё разнесено на модули. Так как время сборки каждого отдельного модуля может отличаться. Есть модули, от которых зависит много других модулей, и если они имеют большой размер, либо большое количество кодогенерации, то прирост будет небольшим. Так как часть Gradle Worker будут простаивать в ожидании, когда же соберётся такой модуль. Создавая «бутылочное горлышко». Да и базовые модули никто не отменял. Для примера давайте взглянем, как соберётся проект на трёх Gradle Worker.

И тот же проект на шести Gradle Worker.

Итоговое время, безусловно, уменьшилось. В то же время количество и размеры простоев увеличились. В итоге, чем больше Gradle Worker и ядер, тем сильно меньше пользы приносит каждый из них. Поэтому чем меньше в вашем проекте таких блокирующих модулей, тем больший эффект вам даст прирост количества ядер.
Напомню, что у нас больше 400 модулей и прям огромных монолитов нет. А прирост всего навсего 19.3%.

Ожидаемо, что прирост в одномодульной сборке от количества ядер сильно меньше, чем для многомодульной, всего около пяти процентов. При увеличении числа ядер на 50% я напомню. Всё логично, так как меньше параллельных задач. Небольшой прирост опять же есть из-за того, что Gradle молодчина и пытается параллелить задачи даже в одномодульном режиме.

В горячей сборке тоже прирост не такой большой, как в холодной. Так как параллелить тоже особо нечего. Мы ведь изменили только один модуль. Есть, конечно, Gradle Task, которые не зависят друг от друга, и их можно выполнить параллельно, но, как мы видим, их не слишком много.
Также хорошо видно, что время GC существенно уменьшилось, и основной прирост в скорости именно от этого. У нас включён параллельный GC. И что логично, чем больше у параллельного GC есть потоков, тем лучше.
Выводы
Количество ядер сильно влияет только в многомодульной сборке.
Чем лучше распараллелен проект, тем больший прирост.
Слишком много ядер для сборки не нужно. Лучше вложится в частоту, там прирост будет выше.
Непонятный факт
Можно заметить, что сборка с частотой, выставленной в Auto режиме, в котором частоты должны доходить до 4200 МГц, собиралась 10:32, но когда мы руками выставляли 4200 МГц, то результат был 8:46. На деле результат в Auto режиме находится между 3000 МГц и 3600 МГц. Что как бы подозрительно.
Чтобы понять, в чём причина, я ещё раз прогнал тесты, и результат не поменялся.
Тогда я предположил, что, возможно, проблема в Turbo Boost, который выставляет слишком низкие частоты. Но прогон тестов с включенным мониторингом показал, что это не так. Частоты почти всегда были выше 4000 МГц.

Дополнительно проверил и в Doom 2016. Для полной надёжности результатов, наиграв несколько часов. Исключительно в научных целях, конечно же. В игре тоже с частотами всё было в порядке.

Самое занятное, что со временем я обновил процессор до Ryzen 7 5800X. У него тоже прослеживается подобное. На фиксированной частоте 4200 МГц результат получается лучше, чем в режиме Auto, в котором, судя по показаниям мониторинга, частоты доходят до 4700 МГц. Найти объяснение этому я так и не смог. Возможно, проблема в Turbo Boost, AMD, возможно, в Windows 11, в планировщике ядер, а может, и сам Gradle подлянки устраивает. Эта тема требует отдельного изучения.
Заканчиваем мучить процессор и переходим к памяти.
Количество памяти
Всё просто. Берём два комплекта памяти. На 16 Гб и на 32 Гб. Выставляем им одинаковые настройки: частоты, тайминги и напряжение. В моём случае это были два комплекта от одного производителя и из одной линейки. Поэтому ничего делать и не пришлось.

Прирост весьма хорош. В основном от уменьшения времени GC. В целом понятно, что из-за большего объёма оперативной памяти у GC меньше причин срабатывать. Время непосредственно же build тоже стало меньше, но совсем на чуть-чуть.

Для одномодульной сборки показатели не очень впечатляющие. Где-то на границе погрешности. По всей видимости из-за того, что сборка более последовательная. Столько оперативной памяти ей и не нужно.

В горячей сборке тоже особого прироста нет. При изменениях в одном модуле много оперативной памяти не нужно, так как количество кода, который надо скомпилировать, тоже не велико. Опять же, весь прирост от GC.
Выводы
На локальной машине 16 Гб пока достаточно для проектов, сопоставимых с нашим. Если вы, конечно, не любитель держать приложения и вкладки браузера вечно открытыми.
Одномодульному проекту вообще плевать.
На CI Gradle можно дать больше памяти, так как всяческие проверки дополнительно подъедают память.
Частота памяти
Для комплекта на 32 Гб выбираем 2400МГц, 3000 МГц, что на 25% больше, и 3600 МГц, что аж на 50% больше. И самое главное — обязательно фиксируем тайминги. И вы подумали «Что ещё за тайминги и зачем их обязательно фиксировать?».
Самое простое объяснение, которое я слышал, звучит примерно так: «Представьте что оперативная память — это набор шкафов с книгами. Когда оперативной памяти нужно обратиться к своей ячейке, это равнозначно тому, что вам надо достать книгу из шкафа. У вас есть номер шкафа (номер чипа памяти), номер полки (номер строки) и номер книги на полке (номер столбца).».

Чтобы прочитать какую-либо книгу, вам потребуется:
Подойти к шкафу.
Пододвинуть лестницу к нужной полке.
Взять книгу.
Вернуть лестницу в начальное положение.
Каждое из этих действий отнимает разное количество времени. Подойти к шкафу — 17 секунд, сдвинуть лестницу — 20 секунд, вернуть обратно лестницу — опять же 20 секунд. Ну и, собственно, найти книгу на полке — 42 секунды.
В итоге ваш тайминг 17-20-20-42.
Также и в оперативной памяти. Только компьютер оперирует не секундами, а тактами. Вот тут в дело и вступает частота. Частота — это количество тактов в секунду.
И вот тут начинается интересное. Если тайминг не зафиксирован, то материнская плата сама его выбирает. Зачастую с запасом. И когда мы подняли частоту, то может выбрать, например, не 15, а 16.
В итоге, просто подняв частоту, мы не увидим существенного прироста.
Ведь 15/3000МГц = 16/3200МГц = 5 наносекунд.
Поэтому обязательно фиксируем их.
В итоге фиксируем тайминги на 20-20-20-42, и сабтайминги на то значение, при котором модули нормально работают на частоте 3600 МГц. Ну и дальше уменьшаем частоту до 3000 МГц и далее до 2400 МГц.
Пропускная способность памяти получилась следующей (медианное из 5-ти прогонов):
2400 МГц. Чтение 25586 MB/s. Запись 20170 MB/s.
3000 МГц. Чтение 36587 MB/s. Запись 25885 MB/s.
3600 МГц. Чтение 42427 MB/s. Запись 31510 MB/s.
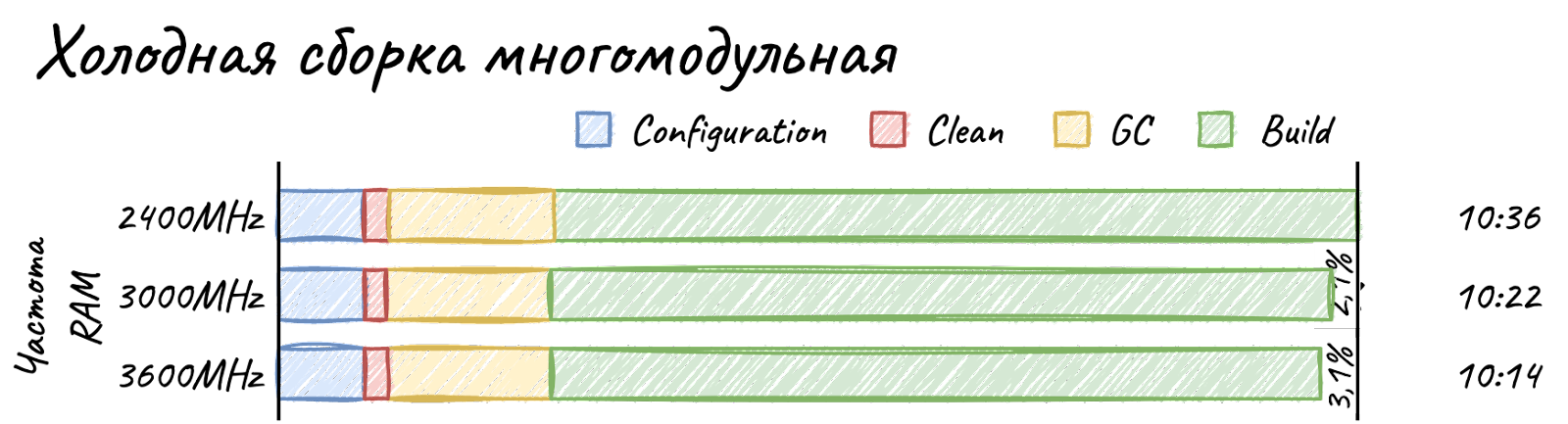
Ну-у-у. Честно говоря, результата то почти и нет. Видимо, Gradle не так сильно важна скорость памяти. Так как «голода памяти» не наступает, и процессор всегда занят делом. Я бы списал это на погрешность, но результат стабильный. Могу предположить, что для процессоров с большим количеством ядер частота памяти будет иметь чуть большее значение.

Опять же небольшой прирост. Ничего интересного.

В процентах это, конечно, неплохо, но в абсолютных значениях — около 5 секунд, что опять же не впечатляет.
Выводы
Наверное, самый разочаровывающий тест. Не знаю почему, но я ожидал гораздо-гораздо большего. Ведь в тех же играх за счёт частоты оперативной памяти удалось получить до 15% прироста.
В целом можно понять две вещи:
Покупать дорогую RAM не стоит.
Хватит и комплекта с базовой частотой.
Скорость накопителя
Возвращаем частоты и тайминги на значения по умолчанию и начинаем тест. Возьмём все типы накопителей, что есть у меня дома:
HDD 2.5”. Даже не помню, откуда он у меня. Возможно, из старого ноутбука, а возможно, он и не мой.
HDD 3.5”. Использовался как файлопомойка.
Sata SSD. Купил ради тестов, а потом запихал в Playstation 2, чтобы меньше шумела. Вот такой вот я странный.
NVMe SSD. Основной мой накопитель.
RAM Storage. Специальный гость. Делал с помощью программы ImDisk.
Чуть подробнее про RAM Storage. По сути, мы выделяем в оперативной памяти область, к которой мы будем обращаться как к накопителю. В теории оперативная память сильно быстрее, чем любой накопитель.

Ну и сравнительная таблица скоростей (всё в Мб/с):
Sequence Read |
Random Read |
Sequence Write |
Random Write |
|
HDD 2.5” |
80.845 |
0.629 |
67.491 |
0.727 |
HDD 3.5” |
155.733 |
1.614 |
142.615 |
1.619 |
Sata SSD |
446.519 |
163.999 |
353.164 |
126.276 |
NVMe SSD |
3567.495 |
1542.787 |
2325.665 |
1577.327 |
RAM Storage |
7841.693 |
1056.208 |
12537.931 |
658.770 |
Как мы видим, на деле всё чуть сложнее… Сначала от накопителя к накопителю скорость только растёт, но на RAM Storage вся логика ломается.
Скорость последовательного чтения ниже, чем скорость записи, а случайное чтение и запись медленнее, чем на NVMe SSD. Это связано как с самой эмуляцией, так и с файловой системой. К тому же работа с оперативной памятью ведётся постоянно. Из-за этого, пока процессору будут нужны какие-либо данные из оперативной памяти, наш RAM Storage будет подтормаживать.
Дальше всё просто. Запускаем ОС не с того накопителя, на котором находится проект. Не забывая при этом добавить папки с проектом в исключения индексатора и антивируса, как это рекомендует Google. Иначе придётся делать тест заново, так как результаты будут непонятными.
Погнали.

Похоже, что для холодной сборки многомодульных проектов использовать HDD категорически нельзя. Видимо, слишком большой объём данных нужно получить с накопителя. Так ещё и при сборке записываются сотни и тысячи мелких файлов, с которыми у HDD не очень. В итоге вся сборка упирается в него. Таким образом, HDD становится бутылочным горлышком. А вот разница между Sata SSD, NVMe SSD и RAM Storage не столь драматичная. Да, прирост есть, но не такой большой.
Разница между NVMe и RAM Storage — 22 секунды. Неплохо, но учитываем разницу в стоимости за 1 Гб... Да и разница в тестах оперативной памяти между 16 Гб и 32 Гб была в районе 30 секунд. Так что лучше пустить оперативу по прямому назначению.

Холодная одномодульная сборка меньше выигрывает от замены накопителя, но опять же от Sata SSD прирост прям хороший. Дальше прирост уже не такой заметный.

Для горячей сборки от смены накопителя не меняется ничего. По всей видимости, слишком малый объём данных считывается и записывается, чтобы скорость накопителя начала как-то влиять. Все результаты в рамках погрешности.
Выводы
HDD пока! Похоже, тесты показывают, что HDD в 2022 году лучше уже не использовать. Вместо него стоит взять SSD. Слишком уж много потенциальных плюсов он даёт.
Достаточно и обычного SSD. Относительно него от NVMe прирост не слишком большой, но и по цене они почти равны. Так что, всё решает наличие NVMe M2 слота.
RAM Storage для сборок — ненужный шик.
Самый-самый последний тест
Напоследок давайте попробуем сравнить наши результаты с результатами на Apple silicon.
К сожалению, я не настолько богат, чтобы сравнивать M2 с каким-нибудь Intel 12900K. Но я могу сравнить то железо, к которому у меня есть доступ.
Поэтому сравним:
Мой домашний комп на Ryzen 3600 c 32 Гб RAM.
MacBook Pro на M1 с 16 Гб RAM.
MacBook Pro на M1 Pro с 32 Гб RAM.
Как минимум мы поймём, как себя ведёт Apple silicon в разных видах сборки по сравнению с обычным домашним компьютером.

В данном виде сборки очень решает именно многопоточная производительность. Тут M1 немного проигрывает обычному компьютеру. А вот M1 Pro прямо разрывает всех напрочь. Напомню, что мы сравниваем, по сути, процессор в ноутбуке с десктопным вариантом.
M1 Pro так оторвался от обычного M1 за счёт того, что у него в два раза больше производительных ядер.
M1: 4 производительных и 4 энергоэффективных.
M1 Pro: 8 производительных и 2 энергоэффективных.

И мой любимый компьютер остаётся позади обычного M1… Зато он умеет запускать любые игры. Шах и мат Apple silicon. M1 таким похвастаться не может.
А если серьёзно, то в данном виде сборки производительность на 1 ядро является ключевым фактором. Ну и, как видно по тестам, у Apple silicon с этим всё прекрасно. При этом разница между M1 и M1 Pro — в районе погрешности. Что и логично, так как в M1 Pro просто больше производительных ядер. При этом они такие же, как и в обычном M1.

И опять Apple silicon быстрее. Вдвое. Сюда бы ещё Configuration Cache докинуть, вообще сказка будет.
Конечно, по итогу вопрос в стоимости. Но если у вас есть куча денег или лишняя почка, может, даже не своя, то выглядит так, что Apple среди рабочих ноутбуков впереди планеты всей. Так как не стоит забывать, что у него ещё и энергоэффективность на высоте.
Субъективное мнение
Вообще, выводы вы можете сделать самостоятельно. Все цифры в статье. Касаемо того, что думаю по поводу этого я…
Я был немного разочарован. Что 8 лет назад, когда я начинал карьеру, что сейчас — основным параметром является частота. Да, количество потоков тоже важно, но оно так и не стало решающим фактором.
Давайте подумаем, на что обратить внимание при сборке ПК.
В целом такая сильная зависимость от частоты ставит под сомнение сборку на ноутбуках без хорошего охлаждения, а таких большинство. Так как из-за нагрева процессор начнёт тротлить, сбрасывая частоты Turbo Boost. Если хотите использовать ноутбук — возможно стоит посмотреть в сторону Mainframer Ну, либо можно использовать технику на Apple silicon. Она очень хорошо показывают себя в сборке проектов. Но тут и бюджеты другие.
Самые топовые процессоры вроде Ryzen 7950X с его 32 потоками станут нужны, только если у вас проект очень хорошо разбит на модули и вам действительно есть чем их загрузить. В целом же — середнячки и чуть выше — наше всё.
Не стоит, конечно, забывать и поколения процессора. Какой-нибудь Ryzen 5 1600 будет сильно отставать от Ryzen 5 5600 на той же частоте. К сожалению, провести такие тесты, не имея у себя зоопарк из процессоров и материнских плат, нельзя. Так что извиняйте.
Касаемо CI, тут точно надо отказываться от HDD, если они у вас остались. Ну и если будет выбор между процессором с большой частотой и процессором с большим количеством ядер, то, думаю, лучше посмотреть в сторону более частотного процессора.
Если у вас есть идеи, что же можно ещё протестировать в конфигурации компьютера, то смело предлагайте в комментариях.
Комментарии (7)

Gmugra
00.00.0000 00:00+2Спасибо за статью. Результаты более чем предсказуемые, но труд большой.
Вы тестировали, по сути, JVM на специфической задаче: интенсивная работа с большим количеством мелких фалов и компиляция. Понятно что для первого наибольший выигрыш дает SSD а для второго - частота ядер (и их количество если нагрузка для них есть). Threadripper лучший выбор процессора, для этой задачи, полагаю. Линус Торвальдс и Алексей Шипилёв не дадут соврать :)
И спасибо за подсказку выбрать другой GC - оно и с Maven заметно помогло (задача-то таже)

edo1h
00.00.0000 00:00+2Можно заметить, что сборка с частотой, выставленной в Auto режиме, в котором частоты должны доходить до 4200 МГц, собиралась 10:32, но когда мы руками выставляли 4200 МГц, то результат был 8:46
Это стандартная проблема с динамическим управлением частоты и короткими нагрузками.
Ядро простаивает — процессор сбрасывает частоту этого ядра. Потом нагрузка появляется, процессор начинает собираться почистить частоту, это дело не такое уж и быстрое. Когда он поднял частоту, может оказаться, что этот процесс уже отработал. Или планировщик перенёс его на другое ядро )
Все инструкции по обеспечению low latency начинаются с отключение понижений чистоты и там более переходов в спящие режимы.Достаточно и обычного SSD. Относительно него от NVMe прирост не слишком большой
Вообще немного странно сравнивать «sata ssd в целом» с «nvme ssd в целом», всё-таки в обоих семействах есть модели совершенно разного класса.
Но если сосредоточиваться на различии между интерфейсами, то время доступа примерно одинаково, особенно на чтение (тут оно вообще определяется nand памятью, а не интерфейсом).
Отличаются линейные скорости (сомневаюсь, что для этой задачи это особо актуально) и возможная глубина очереди/поведение при большой глубине очереди (это тут вообще неприменимо).

Lexa-89
00.00.0000 00:00Это то, чего мне реально не хватало: с каждым новым релизом студия жрёт всё больше ресурсов, и на ноуте становится тяжко проекты собирать. Теперь же знаю, на что сделать упор, при выборе нового железа, спасибо!
За одно посмотрю в сторону сборки без Gradle, хотя во многих компаниях умение с ним работать ну прям обязательное требование.
kovserg
Не хватает сравнения времени сборки тех же файлов без gradle. Там не % а порядки отличие.
ps: выводы совершенно странные.
1. Вся сборка очень много занимается перекладыванием из пустого в порожнее. По этому главным критерием будет количество каналов памяти у процессора и скорость и объём кэша процессора. Короче попробуйте на 12 канальном Xeon.
2. HDD по вашим тестам смотрится очень достойно 10% при отличии скорости в 60раз (120мб/c HDD и 7Гб/c у SSD).
princeparadoxes Автор
Количество каналов памяти, как я понимаю, в основном повысит пропускную способность памяти. Поднятие частоты памяти тоже на это влияет. Но по тестам частота/пропускная способность памяти почти не повлияла. Как будто увеличение количества каналов не должно помочь. Или я заблуждаюсь?
По поводу кэша - да. Чем его больше - тем лучше) Но тут сложно определить насколько именно. Наверно только если сравнить Ryzen 5800X и Ryzen 5800X3D которые только размером кэша и отличаются.
Тут речь скорее про то, что замена HDD на SSD достаточно дешёвый способ увеличить скорость сборки. Относительно замены процессора или оперативной памяти, конечно же. Так что, честно говоря, не вижу особого смысла собираться на HDD.
kovserg
В многоядерных процессорах многоканальная память значительно увеличивает пропускную способность. На обычных десктопах вы можете включить одноканальный режим и потом сравнить с 2х канальным.
ps: я к тому что «HDD пока!» преждевременно.
pps: и еще не смотря на все удобства gradle очень тормозной и избыточный. Время и ресурсов для сборки без gradle надо порядки меньше.
princeparadoxes Автор
Протестировать количество каналов хорошая идея. Спасибо!