

Вы когда-нибудь задумывались, какой из фреймворков для многопоточки самый быстрый? Я вроде и знал ответ, но задумывался периодически. В определённый момент сама судьба просто-напросто заставила меня взять и проверить. Так что если вам тоже всегда было это интересно, то я постарался протестировать, сравнить и предоставить результаты для вас.
Задача
Для начала разберёмся, а для чего вообще я этим занялся. Передо мной встала простая задача. Есть система, которая должна выполнить несколько сотен обратных вызовов. При этом сложность и время, которое придётся затратить на каждый обратный вызов, нам неизвестно.
Внутри обратного вызова может быть как простое создание объектов, так и долгий поход на сервер или в базу данных. Надо выполнить все обратные вызовы как можно быстрее.
При этом можно и даже нужно из-за походов в базу или на сервер использовать многопоточку.
И во время решения этой задачи я неожиданно понял, что я вообще-то не очень в курсе, какой из фреймворков многопоточки быстрее и в каких ситуациях. А вдруг так случится, что какой-то из фреймворков сильно опережает остальных, и я могу сильно ускорить выполнение.
Мотивация
Но с ходу возникает вопрос: “А что, ещё никто это не померил?”. И вот я как-то не нашёл тестов, которые бы меня устраивали. Либо в тестах были только сравнение пары технологий, например, Rx vs Coroutines. Либо сами сценарии, на мой взгляд, были очень узкими, например, тестируют только арифметические операции или только походы в базу. Либо тесты уже достаточно старые. А ведь, например, корутины постоянно обновляются, да и Rx Java 3 вышел не так давно. В общем, я был не очень доволен и решил сделать свои тесты с блэкджеком и прочим.
Ну и логично, что я не смогу рассмотреть все сценарии использования многопоточки, а только лишь те, что были мне интересны для моей конкретной задачи. Так что считать эти тесты всеобъемлющими точно не стоит, но мне кажется, они достаточно исчерпывающие.
Инструмент
Начнём с инструмента измерения. Так как я Android-разработчик, то буду использовать инструменты, предоставляемые для Android (на самом деле они просто чуть удобнее для меня). В теории, конечно, работа многопоточки на JVM на компьютере может отличаться от работы на JVM на Android устройстве… Но на деле не сильно и глобально на результаты тестов не влияет.
Так вот. Для проверки производительности кода на Android-устройстве есть инструмент Jetpack Microbenchmark.
Выглядит измерение как обычный instrumentation тест. Разница только в том, что используется специфичная Rule — BenchmarkRule.
@get:Rule
val benchmarkRule = BenchmarkRule()
@Test
fun sampleTest() {
benchmarkRule.measureRepeated {
// Вот тут то, что будем мерить
}
}В результате мы увидим JSON, в котором содержится информация о самом тесте: минимальное, максимальное и самое важное для нас — медианное время.
"benchmarks": [
{
"name": "sampleTest",
"params": {},
"className": "com.test.benchmark.ExampleBenchmark",
"totalRunTimeNs": 85207217833,
"metrics": {
"timeNs": {
"minimum": 9.82149833E8,
"maximum": 1.019338584E9,
"median": 1.004151917E9,
"runs": [...]
},
"allocationCount": {
"minimum": 324.0,
"maximum": 324.0,
"median": 324.0,
"runs": [...]
}
},
"sampledMetrics": {},
"warmupIterations": 3200,
"repeatIterations": 5000,
"thermalThrottleSleepSeconds": 0
}
]В json полно и другой информации, вроде количества итераций, количество аллокаций объектов и прочее. Для нас это сейчас не очень важно.
Варианты
По сути, вся разница между фреймворками для нас будет в двух факторах:
время, которое тратится фреймворком на создание одного потока;
как хорошо и быстро фреймворк распределяет задачи между потоками.
Под проверку этих факторов и будем подбирать варианты.
Итак, теперь надо определиться, что мы будем тестировать. Начнём с тестовых данных.
Тестовые данные
Тут всё просто. Создаём список из 100 элементов от 0 до 99.
private fun createTestList(): List<Int> {
return List(100) { it }
}Затем над каждым из элементов будем делать какое-либо действие.
Теперь посмотрим на наши варианты тестов.
Один поток
Начнём с вариантов, которые основаны на одном потоке. В сравнении этих вариантов между собой мы хорошо рассмотрим разницу именно в первом факторе — время, которое тратится фреймворком на создание одного потока. Так как поток всего один, и можно голословно заявить, что разница между фреймворками и есть время, которое тратится на создание одного потока, плюс время инициализации фреймворка.
Самый первый вариант — просто вызов метода напрямую. Никаких фреймворков.
@Test
fun directInvoke() {
val list = createTestList()
benchmarkRule.measureRepeated {
list.forEach { action(it) }
}
}Вторым вариантом станет Rx. Для тестирования выполним действие внутри Completable. То есть на каждое действие будет отдельный Completable. В качестве Scheduler будет Scheduler.single. Он как раз и будет отвечать за то, что все наши действия будут выполнены на одном потоке.
Ну и так как нам надо будет дождаться завершения, то на итоговый Completable вызовем blockingAwait.
@Test
fun rxOne() {
val list = createTestList()
val scheduler = Schedulers.single()
benchmarkRule.measureRepeated {
val completables = list.map {
Completable.fromAction {
action(it)
}.subscribeOn(scheduler)
}
Completable.merge(completables).blockingAwait()
}
} Ну и куда же без молодого и перспективного фреймворка Kotlin Coroutines. Тут, чтобы дождаться выполнения корутины, запустим действие через async и дождёмся её завершения через await. То есть на каждое действие будет отдельная корутина. Чтобы всё отработало на одном потоке, просто используем runBlocking без лишней мишуры.
@Test
fun coroutineOne() {
val list = createTestList()
benchmarkRule.measureRepeated {
runBlocking {
list.map {
async {
action(it)
}
}.forEach { it.await() }
}
}
}Ну и так как сравнивать корутины и Rx в лоб не очень красиво (так как обе технологии хоть и связаны с многопоточкой, они используют разный концепт и используются по-разному), то добавим в сравнение и Flow.
Создаём flow на action, объединяем их между собой и просто вызываем collect. На каждое действие будет отдельный Flow. Нигде при этом не указываем Dispatcher, чтобы всё происходило на одном потоке.
@Test
fun flowOne() {
val list = createTestList()
benchmarkRule.measureRepeated {
runBlocking {
val flows = list.map {
flow {
val result = action(it)
emit(result)
}
}
flows.merge().collect()
}
}
} Количество потоков равно количеству потоков процессора
Само собой, использовать всего один поток выглядит не очень оптимальным с точки зрения того, что… Ну, мы как бы затащили фреймворк для многопоточки.
Начнём с ситуации, когда у нас количество потоков в пуле равно количеству потоков процессора.
В разнице между этими варианты мы в идеале и должны увидеть второй фактор — как хорошо и быстро фреймворк распределяет задачи между потоками. Так как потоков на каждую из задач не хватит, то фреймворку в любом случае придётся их распределять.
Сразу предупрежу, что от количества потоков, равного количеству ядер, не стоит ожидать равномерного распределения наших задач на каждое из ядер процессора.
Операционная система и процессор сами определяют: что, когда и кем будет выполняться. Так ещё и железо вносит смуты.
В современных «больших» процессорах есть SMT/HyperThreading, которые создают по несколько логических потоков на одно ядро процессора.
На мобильных процессорах и в новых процессорах от Intel всё ещё веселее, так как используется подход с разным видом ядер процессора. Есть крупные для решения сложных задач, средние и энергоэффективные. Они в разы отличаются по производительности.
Так что просто воспринимаем этот пул — как пул с небольшим количеством потоков.
Для получения количества потоков процессора есть прекрасный метод:
Runtime.getRuntime().availableProcessors()В данных тестах возвращаемое им значение будет равно восьми.
Начнём с Rx. Для реализации нужного нам поведения у Rx есть отдельный Scheduler.Computation. По сути, весь код остаётся таким же, как и в случае с одним потоком. Только на каждый отдельный Completable мы сделаем subscribeOn() на computation.
@Test
fun rxCPU() {
val list = createTestList()
val scheduler = Schedulers.computation()
benchmarkRule.measureRepeated {
val completables = list.map {
Completable.fromAction {
action(it)
}.subscribeOn(scheduler)
}
Completable.merge(completables).blockingAwait()
}
}Теперь посмотрим на корутины. В них есть Dispatchers.Default, и в его документации сказано:
«It is backed by a shared pool of threads on JVM. By default, the maximal level of parallelism used by this dispatcher is equal to the number of CPU cores, but is at least two.»
То есть по умолчанию максимальный уровень «параллелизма» равен количеству ядер процессора. То, что нужно.
Тут тоже код не особо изменился по сравнению с одноядерным вариантом. Только теперь наша задача выполняется внутри withContext с Dispatchers.Default.
@Test
fun coroutineCPU() {
val list = createTestList()
val dispatcher = Dispatchers.Default
benchmarkRule.measureRepeated {
runBlocking {
list.map {
async {
withContext(dispatcher) {
action(it)
}
}
}.forEach { it.await() }
}
}
}Вот только есть нюанс… Если поглубже залезть внутрь Dispatchers.Default, то мы увидим следующий конструктор.
internal object DefaultScheduler : SchedulerCoroutineDispatcher(
CORE_POOL_SIZE, MAX_POOL_SIZE,
IDLE_WORKER_KEEP_ALIVE_NS, DEFAULT_SCHEDULER_NAME
)Уж больно подозрительно выглядит то, что мы передаём в него две константы: CORE_POOL_SIZE, которая в нашем случае и равна количеству потоков процессора, и MAX_POOL_SIZE, которая равна, на минуточку, двум миллионам.
Покопав чуть глубже, можно найти, что эти переменные нужны для создания CoroutineScheduler.
private fun createScheduler() =
CoroutineScheduler(corePoolSize, maxPoolSize, idleWorkerKeepAliveNs, schedulerName)И вот уже в его документации сказано:
«The scheduler does not limit the count of pending blocking tasks, potentially creating up to maxPoolSize threads. End users do not have access to the scheduler directly and can dispatch blocking tasks only with LimitingDispatcher that does control concurrency level by its own mechanism.»
Из чего следует, что созданный CoroutineScheduler по количеству потоков не ограничен количеством потоков процессора.
И получается, что не очень честно сравнивать Dispatchers.Default с Scheduler.Computation, так как первый может использовать дополнительные потоки в некоторых случаях. К счастью, тут же в документации написано, как сделать сравнение честнее. Просто использовать LimitingDispatcher. Для этого у Dispatchers.Default вызовем метод limitedParallelism с количеством потоков процессора.
@Test
fun coroutineCPULimit() {
val list = createTestList()
val dispatcher = Dispatchers.Default.limitedParallelism(Runtime.getRuntime().availableProcessors())
benchmarkRule.measureRepeated {
runBlocking {
list.map {
async {
withContext(dispatcher) {
action(it)
}
}
}.forEach { it.await() }
}
}
}Ну и по аналогии с корутинами поработаем и с flow. Используем Dispatchers.Default.
@Test
fun flowCPU() {
val list = createTestList()
val dispatcher = Dispatchers.Default
benchmarkRule.measureRepeated {
runBlocking {
val flows = list.map {
flow {
val result = action(it)
emit(result)
}.flowOn(dispatcher)
}
flows.merge().collect()
}
}
}И опять же по аналогии используем Dispatchers.Default с лимитом.
@Test
fun flowCPULimit() {
val list = createTestList()
val dispatcher = Dispatchers.Default.limitedParallelism(Runtime.getRuntime().availableProcessors())
benchmarkRule.measureRepeated {
runBlocking {
val flows = list.map {
flow {
val result = action(it)
emit(result)
}.flowOn(dispatcher)
}
flows.merge().collect()
}
}
}Ну и раз из-за корутин пришлось немного залезть в дебри, то почему бы эти самые дебри и не использовать. Поэтому попробуем и Executor.
Для начала создадим Executor через Executors.newFixedThreadPool. Он просто создаёт Executor, ограниченный по количеству потоков. В нашем случае это количество потоков процессора.
Создаём Executor за пределами повторений теста, так как само по себе создание Executor — дело непростое. Затем просто вызываем sumbit у Executor с нашей задачей. Чтобы дождаться завершения, просто воспользуемся методом get.
@Test
fun executorFixedCPU() {
val list = createTestList()
val executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors())
benchmarkRule.measureRepeated {
val futures = list.map { executorService.submit { action(it) } }
futures.forEach { it.get() }
}
}Второй, более интересный вид Executor мы создадим с помощью метода Executors.newWorkStealingPool. По сути, в нём также создаётся Executor с ограниченным числом потоков. Но слово Stealing в названии метода тут не просто так. Потоки данного Executor умеют подворовывать задачи у других потоков в случае, если текущий поток свободен, а у другого потока есть задачи в очереди. По простой крестьянской логике это может помочь под конец разгребания нашей общей очереди и в случае, если задачи сильно отличаются между собой по времени. Что как раз то, что нам нужно.
Тут по коду всё так же, как и в предыдущем варианте. Разве что метод создания Executor другой.
@Test
fun executorStealCPU() {
val list = createTestList()
val executorService = Executors.newWorkStealingPool(Runtime.getRuntime().availableProcessors())
benchmarkRule.measureRepeated {
val futures = list.map { executorService.submit { action(it) } }
futures.forEach { it.get() }
}
}По потоку на задачу
Теперь рассмотрим вариант, когда мы можем позволить выделить себе неограниченное (ну почти, просто очень много) число потоков. Так как задач у нас всего сто, то, по сути, сто потоков мы можем и выделить. Больше просто не нужно.
Начнём с Rx. У него за подобные непотребства отвечает Scheduler.io. Он формирует кеш из потоков и если есть свободные потоки, то берёт из него. Если нет, то создаёт новый поток. По коду всё так же, как и в случае с Scheduler.computation, разве что меняем Scheduer на io.
@Test
fun rxIo() {
val list = createTestList()
val scheduler = Schedulers.io()
benchmarkRule.measureRepeated {
val completables = list.map {
Completable.fromAction {
action(it)
}.subscribeOn(scheduler)
}
Completable.merge(completables).blockingAwait()
}
}За ту же логику в корутинах отвечает Dispatcher.IO, поэтому просто подставляем его в уже привычный код.
@Test
fun coroutineIo() {
val list = createTestList()
val dispatcher = Dispatchers.IO
benchmarkRule.measureRepeated {
runBlocking {
list.map {
async {
withContext(dispatcher) {
action(it)
}
}
}.forEach { it.await() }
}
}
}Повторяем тоже самое и для flow.
@Test
fun flowIo() {
val list = createTestList()
val dispatcher = Dispatchers.IO
benchmarkRule.measureRepeated {
runBlocking {
val flows = list.map {
flow {
val result = action(it)
emit(result)
}.flowOn(dispatcher)
}
flows.merge().collect()
}
}
}У Executor, к сожалению, нет такого красивого API, чтобы указал IO и доволен. Поэтому просто выделяем ему сто потоков. Больше этого количества точно не понадобится, так как и задач всего сто.
@Test
fun executorFixedIo() {
val list = createTestList()
val executorService = Executors.newFixedThreadPool(100)
benchmarkRule.measureRepeated {
val futures = list.map { executorService.submit { action(it) } }
futures.forEach { it.get() }
}
}То же самое сделаем и для newWorkStealingPool.
@Test
fun executorStealIo() {
val list = createTestList()
val executorService = Executors.newWorkStealingPool(100)
benchmarkRule.measureRepeated {
val futures = list.map { executorService.submit { action(it) } }
futures.forEach { it.get() }
}
}Ну и наконец-то тесты.
Тесты
Обманул, но немного. Сначала разберёмся с тем, какие сценарии у нас будут.
По сути, их всего пять:
arithmetic — простые арифметические задачи;
listsManipulation — операции над объектами;
storage — имитация работы с хранилищами;
network — имитация работы с сетью;
mixed — смешение всех предыдущих групп, так как в изначальной задаче мы не знаем, какой сложности задачи нам предстоят.
Начнём с простого.
arithmetic
Напомню, что действия мы будем производить над каждым из элементов списка от 0 до 99.
В данном случае мы просто переводим число во Float, чтобы операция была чуточку сложнее, и возводим в степень самого себя. От 0 в степени 0 до 99 в степени 99. Мы, конечно, в определённый момент упрёмся в ограничение float, но это неважно.
private fun arithmetic(seed: Int): Int {
return seed.toFloat().pow(seed.toFloat()).toInt()
}В целом в данную категорию можно отнести операции, например, по созданию объектов через конструктор или обращению к переменным, которые тоже не занимают много времени.
Какие тут результаты?

Ожидаемо, прямой вызов рвёт всех в клочья. Он оторвался от второго места аж в семьдесят раз. Это логично, так как подобные операции очень простые, и любые накладные расходы на использование фреймворка многогопоточки в десятки раз выше, чем на сами операции.
А вот второе и третье место неожиданно удивили. Это оказались оба Executor с фиксированным количеством потоков. Изначально, я предполагал, что впереди будет прямой вызов, потом запуск на одном потоке, затем CPU и в самом конце будет плестись IO. Но Executor с фиксированным количеством потоков ломает эту логику напрочь.
При этом Executor, созданный с помощью Executors.newWorkStealingPool, с «бесконечным» количеством потоков показывает себя хуже.
Также не зря я запарился с выставления лимита для корутин и flow для CPU. Уже здесь видно, что Dispatcher, с лимитом и без, ведут себя по-разному. При этом в тестах без лимита время больше, что значит, что где-то под капотом лишние потоки всё-таки плодятся. В данной конкретной задаче это даже во вред.
Ещё из интересного можно увидеть, что у Flow самые большие накладные расходы на обработку задачи. Он медленней всех своих «одноклассников».
А также если на одном потоке корутины обходят Rx, то с повышением количества потоков Rx вырывается вперёд.
В целом видно, что прямой вызов в такого рода задачах наиболее эффективен, и надо стараться оптимизировать всё именно под его использование. Ну или использовать пул с небольшим количеством потоков.
listsManipulation
Теперь посмотрим на что-то более сложное. Манипуляции над объектами. Объекты эти будут в списке, так как в таком случае ими проще манипулировать. К подобного рода задачам можно отнести и маппинг POJO.
Внутри действия создаём новый список размером с обрабатываемое число и просто маппим его, превращаем в Map, опять маппим и фильтруем… Манипулируем, в общем… Основу сложности здесь формируют даже не сами действия, а тот факт, что это обычный immutable список, а не Sequence. А значит, что после каждой операции создаётся новый список.
private fun listsManipulation(seed: Int): Int {
List(seed) { it }
.map { it.toFloat() }
.map { it + 0.3f }
.associateBy { it.toString() }
.mapValues { it.value * it.value }
.filter { it.value > 5f }
return seed
}Что там по результатам?
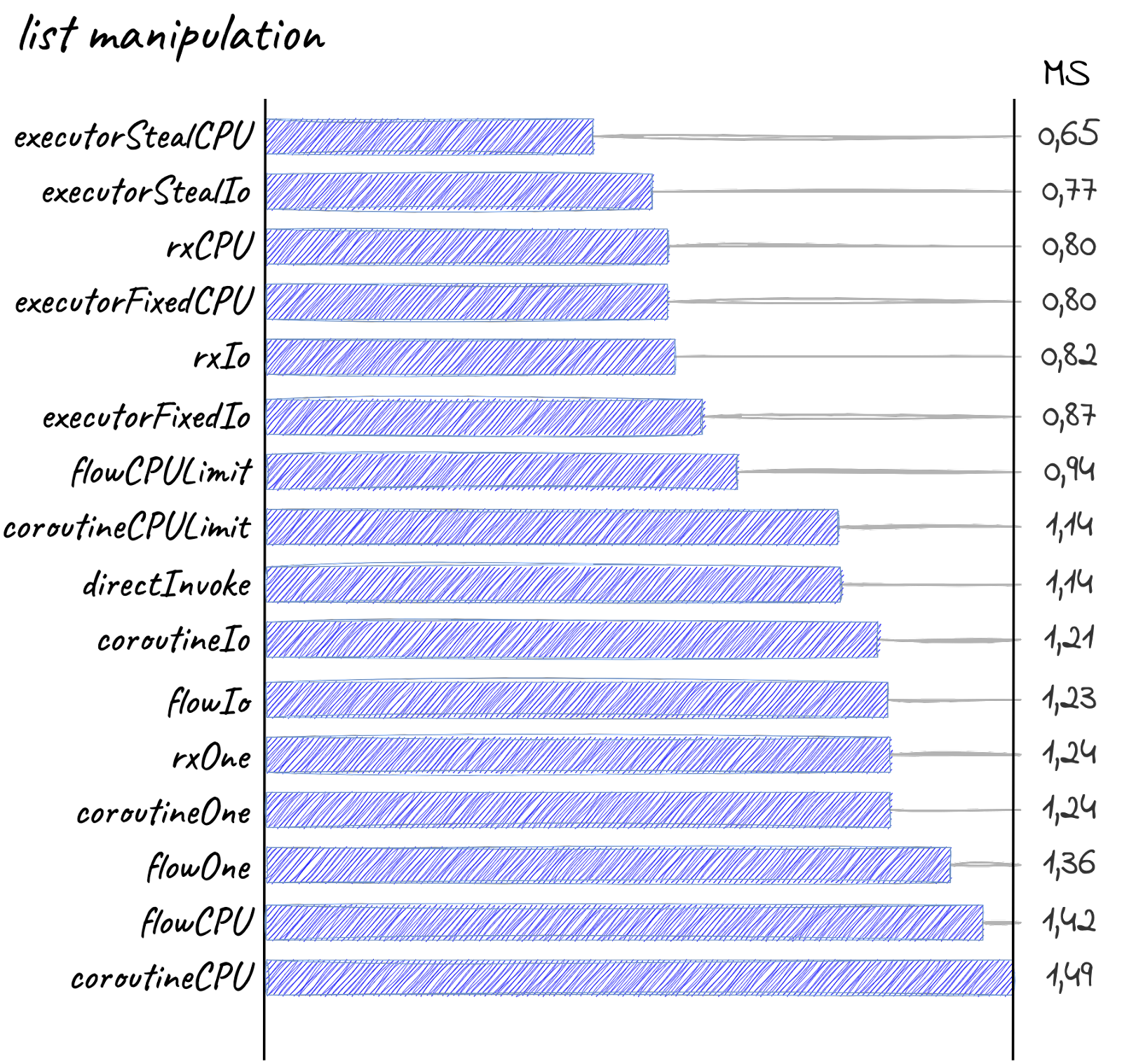
Прямой вызов как-то очень быстро оставил своё лидерство. Даже на таких простых задачах, как манипуляция объектами, он уже создаёт проблемы.
Executor, созданный с помощью Executors.newWorkStealingPool, прям вырывает лидерство. Оставляя своего более простого собрата позади.
Rx немного вырывается вперёд. Впереди вариант с Scheduler.computation(). По идее, он отъедает меньше ресурсов и поэтому наиболее предпочтителен для таких операций.
Варианты с одним потоком в конце списка. Разве что прямой вызов всё ещё барахтается.
На удивление flowCPU и coroutineCPU оказались в самом конце. Напомню, что это тесты c количеством потоков равным количеству ядер процессора без лимита. Я не поверил и перепрогнал тесты. Результат оказался таким же. Я подумал, что это баг и обновил корутины, но ситуация не изменилась. Видимо, я умудрился найти краткий промежуток сложности, когда Dispatcher.Default крайне неэффективен. Могу считать это личным достижением.
В целом видно, что на такой сложности CPU наиболее предпочтительно, так как по времени либо опережает собратьев IO, либо на одном уровне. При этом, что логично, не плодятся лишние потоки.
storage
Тут всё очень просто. Так как обращение к БД или мелкому файлу — это блокирующая операция, то тупо переводим поток в sleep. Время засыпания будет — от 500 до 1490 микросекунд, что в переводе в более понятные единицы — от 0.5 до 1.5 миллисекунд.
К сожалению, на таких малых периодах привычный Thread.sleep() создаёт достаточно чувствительные погрешности. Поэтому для засыпания воспользуемся LockSupport.parkNanos.
private fun storage(seed: Int): Int {
val timeInMicroseconds = 500 + 10 * seed.toLong()
LockSupport.parkNanos(TimeUnit.MICROSECONDS.toNanos(timeInMicroseconds))
return seed
}Наконец результаты.
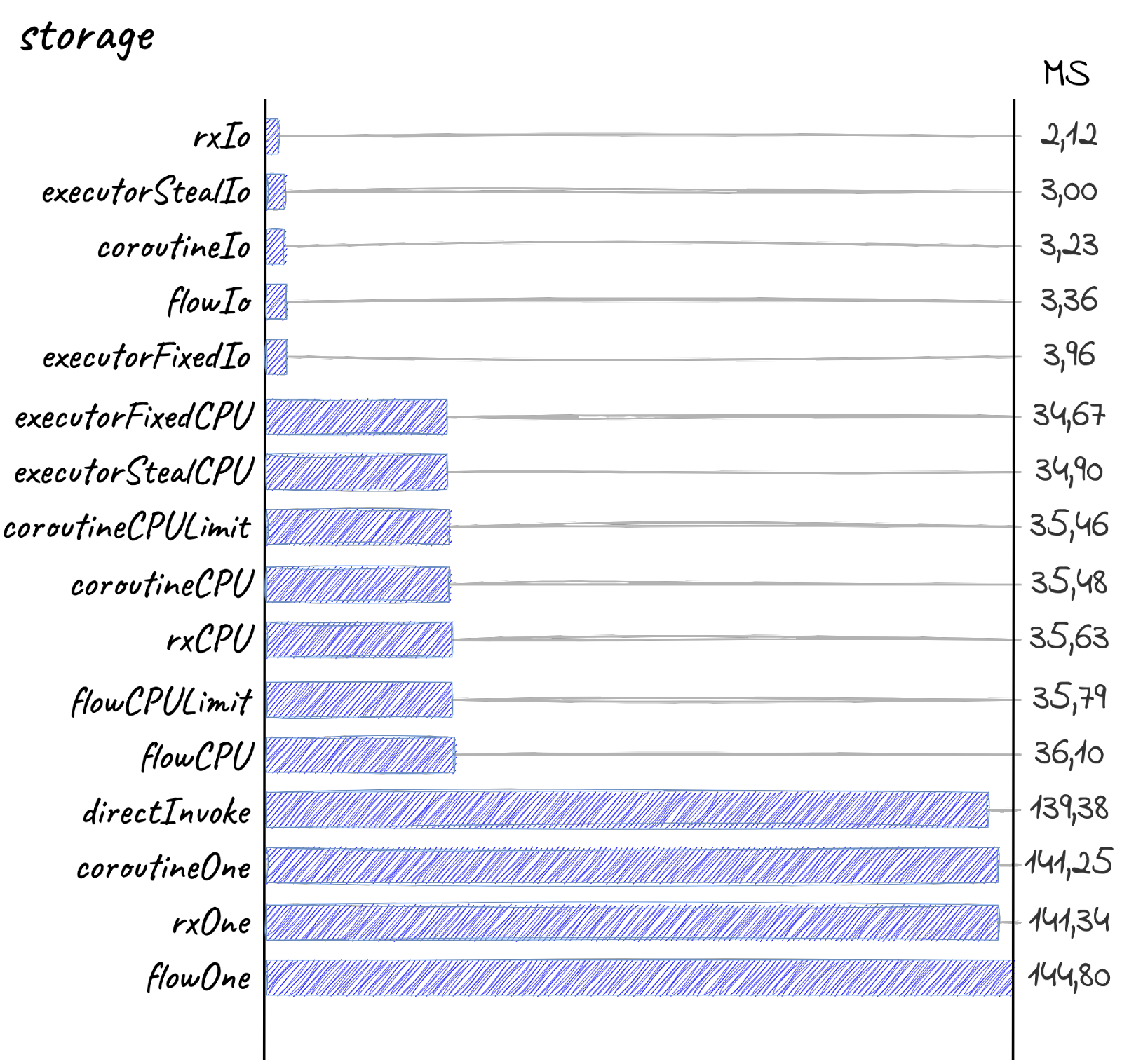
Впереди вся многопоточка с IO, затем вся многопоточка с CPU и в конце плетётся исполнение на одном потоке.
Прям как по учебнику. Внезапно, но для IO операций лучше всего использовать IO пулы потоков.
rxIo действительно быстрее, так как, видимо, меньше всех тратит ресурсов на создание потока, но… В данном случае это как будто не очень-то и важно. Разница-то в одну миллисекунду. И в целом разница между фреймворками почти стёрлась.
network
Ну и как же без похода в сеть. Всё, как и в предыдущем сценарии — засыпаем на некоторое время. В данном случае от 0 до 99 миллисекунд. На таких масштабах задержки от Thread.sleep уже не играют такой деструктивной роли, поэтому будем использовать его.
private fun network(seed: Int): Int {
TimeUnit.MILLISECONDS.sleep(seed.toLong())
return seed
}Вашему вниманию — результаты.
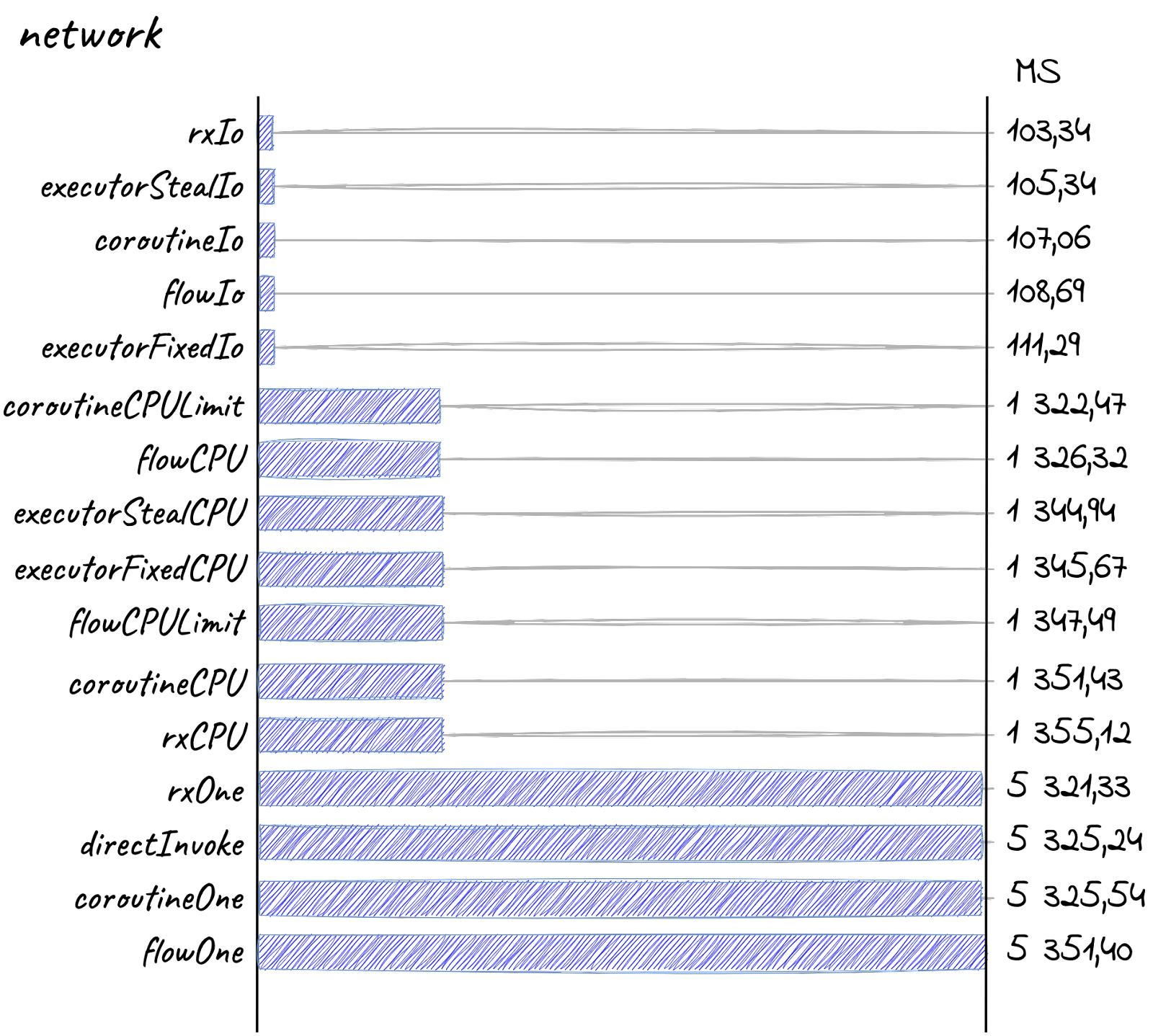
И тут грань между фреймворками вообще размылась. Да, rxIo всё ещё впереди, но опережает он меньше чем на 1%, что как бы вообще в рамках погрешности.
mixed
Ну и, наконец, последний сценарий. Самый важный для меня и для изначальной задачи. Когда мы выполняем задачи абсолютно всех сложностей.
private fun mixed(seed: Int): Int {
return when {
seed % 5 == 0 -> network(seed)
seed % 3 == 0 -> storage(seed)
seed % 2 == 0 -> listsManipulation(seed)
else -> arithmetic(seed)
}
}По коду видно, что самая долгая задача у нас будет 90 миллисекунд.
Ну и результаты.

В целом наблюдаем всю ту же картину разбиения на три блока: IO, CPU, One.
Разве что с добавлением мелких задач Executor, созданный с помощью Executors.newWorkStealingPool, вырывает лидерство. Хоть и не-намного. Видимо, за счёт того самого «подворовывания» задач.
Выводы
Как можно увидеть, роль фреймворка с точки зрения производительности размывается уже на этапе работы с файловой системой. Чаще всего многопоточка используется именно для работы с IO. Так что выбирать фреймворк многопоточки по производительности — дело сомнительное. Лучше руководствоваться критериями удобства и всего остального, что для вас важно.
Просто если у вас есть задачи, которые проще, чем блокирование потока на 0.5 миллисекунды, то лучше использовать небольшой пул потоков, например, размером с количество ядер процессора.
Ну и в таких задачах лучше всего себя показывают старые добрые Executor’ы и Rx.
Исключение составляют разве что очень простые операции, вроде арифметики, создания объекта и т.п. Тут лучше не использовать фреймворки и многопоточку вообще. Так как время, затраченное на работу самого фреймворка или на создание потока, будет больше, чем время решения всех задач. Если их не триллиарды, конечно. Но тогда вам, кажется, надо идти в сторону вычислений на GPU.
Для решения нашей же задачи я поступил следующим образом:
Выделил все простые операции в отдельный пул задач и выполняю их прямым вызовом.
Все остальные задачи выполняются на корутинах с Dispatchers.IO. Просто из-за того, что с их помощью проще писать одновременно и синхронный, и асинхронный код.
А что думаете вы? Какой фреймворк используете?


ris58h
Блокирующая, если использовать блокирующие вызовы. Странно, что вы не проверили как себя ведёт non-blocking IO.
princeparadoxes Автор
non-blocking IO подход же реализует не фреймворк многопоточки, а конкретная сущность, которая делает IO вызов, например, сетевой клиент. Соответственно, от фреймворков многопоточки ничего зависеть не будет. Я хотел именно их между собой сравнить. И, как мне показалось, на сравнение фреймворков многопоточки, блокирующий IO или нет, не должно повлиять. Поэтому взял блокирующий, так как он сильно проще визуально и нагляднее.
Или я ошибся?
ris58h
Думаю, что проще, но контекст задачи был "выполнить все обратные вызовы как можно быстрее". Использование async IO изменит результаты тестов, что может повлиять на конечный выбор.
princeparadoxes Автор
Справедливо. Как-то не подумал об этом
AstarothAst
От фреймворка зависит, что он будет делать с потоком, в котором произошел блокирующий вызов — современные фреймворки способны понять, что поток простаивает, и отдать его под соседнюю задачу. Вот-вот зарелизится Project Loom, который это все завозит в джаву из коробки, а в котлине примерно тоже самое делают корутины.