
Основной пик пришёлся на период с 17:03 до 17:50, когда общие потери трафика достигали 40%. Кроме того, в период с 17:03 до 17:13 наблюдалась практически полная потеря IPv6 трафика. Инцидент удалось устранить к 21:30.
Как это произошло и какие выводы мы из этого извлекли — ответим на эти вопросы и поделимся нашим опытом.
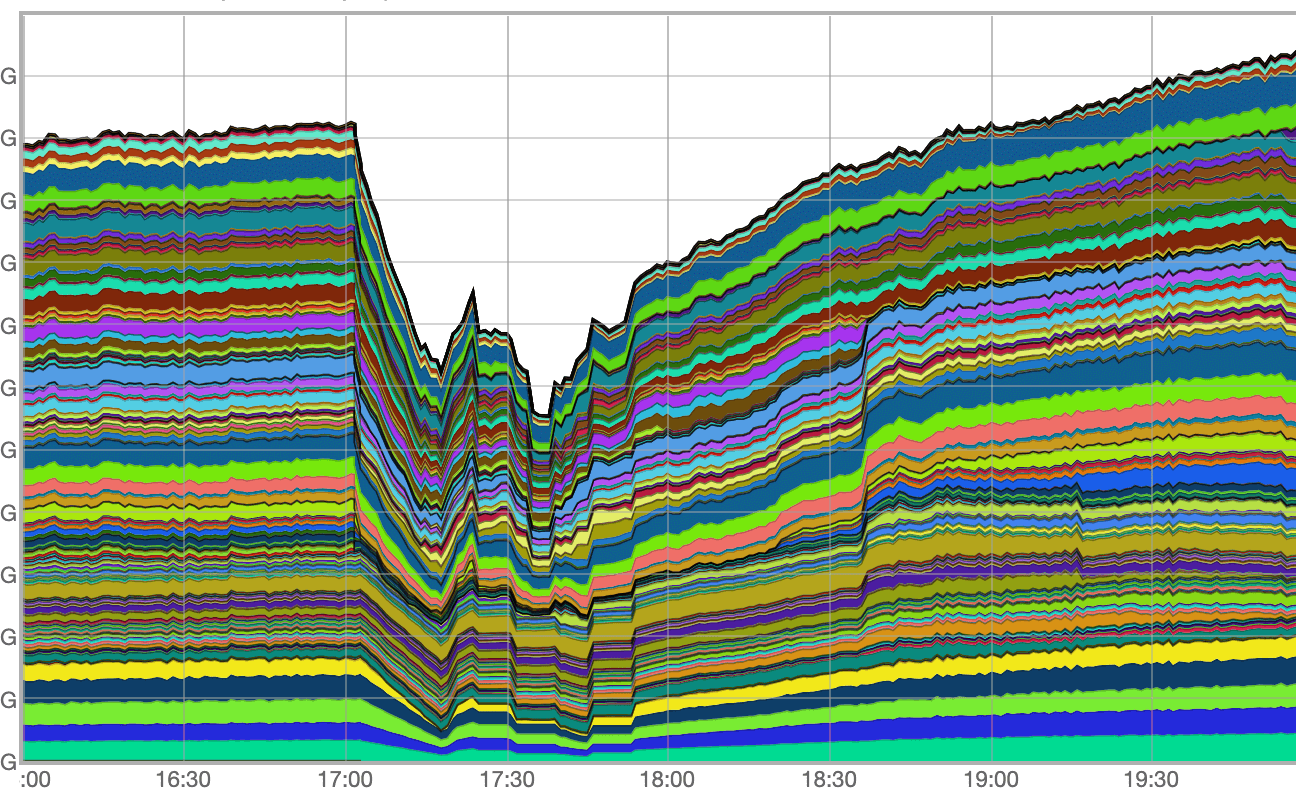
Ход инцидента
Граничные маршрутизаторы — это то место, где проходит граница между разными сетями связи. От их работы зависит связность между Яндексом и сетями, которые обеспечивают подключение конечных пользователей.
Мы столкнулись с четырьмя проблемами, три из которых связаны друг с другом, а четвёртая, похоже, просто произошла одновременно с ними:
- аппаратный сбой граничного маршрутизатора;
- последовавший за этим сбой подсистемы лукапа и аварийные перезагрузки линейных карт на трёх других георазнесённых граничных маршрутизаторах;
- сбой ПО на пяти маршрутизаторах внутри дата-центров Яндекса;
- нестабильность контрольного протокола BFD из-за флапа MAC-адресов внутри CLOS-фабрики на М9.
Проблема №1
Началом инцидента мы считаем аппаратный отказ на одном из граничных маршрутизаторов, который привёл к его полному отключению.
Немного теории. Современный маршрутизатор состоит из набора различных плат:
- управляющих,
- линейных, на которых есть интерфейсы,
- фабрик коммутации, которые соединяют всё воедино.
Кому интересно, более подробно можно почитать в блоге на linkmeup.
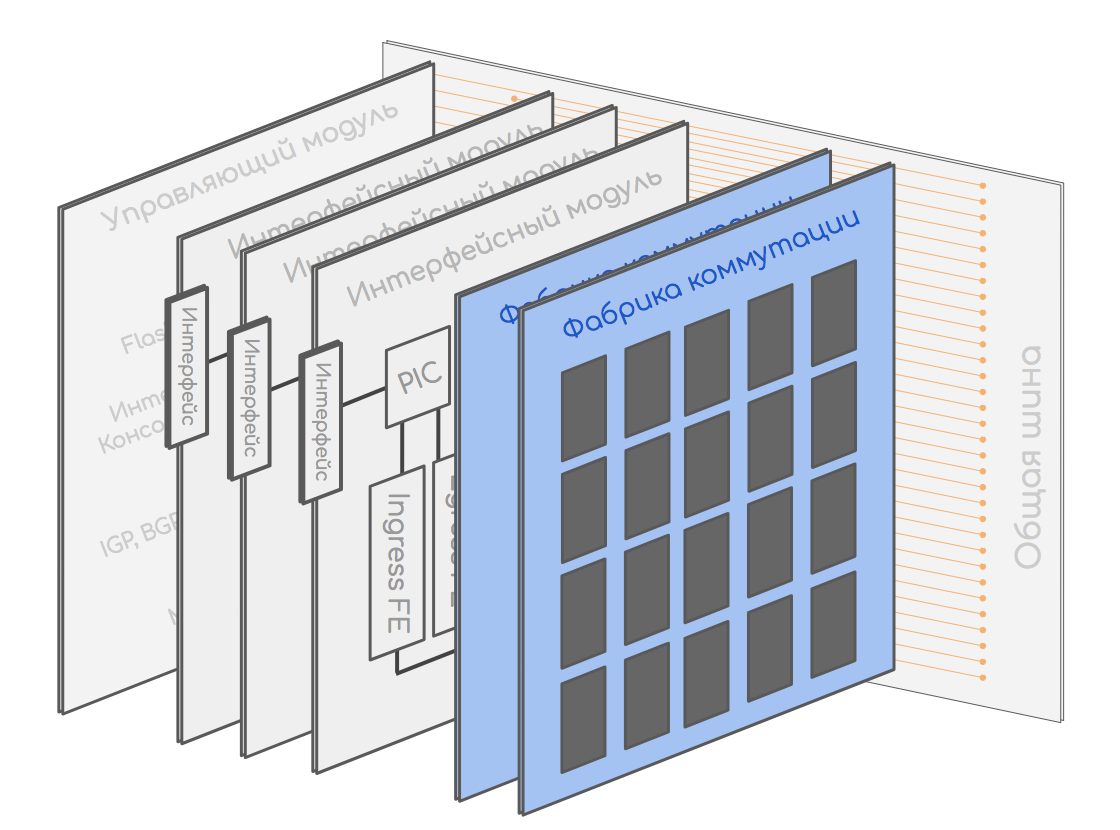
6 февраля в 17:03:30 на одном из наших граничных маршрутизаторов вышла из строя управляющая плата или её «ответная» часть, на которой расположена фабрика коммутации и вся машинерия для контроля состояния аппаратных компонентов. Мы до сих пор не знаем точной причины, потому что оживить коробку так и не удалось. По итогу маршрутизатор был потерян полностью.
Эту проблему могла бы предотвратить резервная управляющая плата, но она отказала ещё 22 января, а работы по её замене были запланированы, но не завершены. Вообще, отключение резервных плат не влияет на прохождение трафика, поэтому её заменили не сразу. Отчасти это связано с тем, что место расположения маршрутизатора обслуживается не нашей службой Smart Hands, а сторонними выездными инженерами. Кроме того, отказ одного маршрутизатора не должен был стать критичной проблемой, потому что все пиринги зарезервированы маршрутизаторами на других точках присутствия. В прошлом такие аварии не приводили к заметным для пользователей инцидентам, но не в этот раз.
Проблема №2
Обычно распределение нагрузки между оставшимися маршрутизаторами обрабатывается штатно: сессии и соседства контрольных протоколов (BGP, IS-IS) должны были уйти по таймауту, а трафик — перейти на резервный маршрут. Пользователи не должны такого замечать, но кое-что пошло не так — ниже разберёмся, что именно.
Полная потеря связности с отказавшим маршрутизатором привела к падению протокольных соседств IS-IS — это заняло около секунды. А вот отзыв BGP-маршрутов занял несколько больше: связность внутри нашей автономной системы организована с помощью рефлекторов, поэтому системе потребовалось некоторое время на обработку событий падения BGP-сессий между рефлекторами и отказавшим маршрутизатором, а также на отзыв маршрутов с других бордеров.
Таким образом, в течение нескольких секунд все оставшиеся в живых пограничные маршрутизаторы оказались в ситуации, когда BGP-маршрут ещё присутствовал, а вот IS-IS маршрут, необходимый для его корректного рекурсивного разрешения, — уже нет.
Рекурсивное разрешение маршрута в BGP — это процесс вычисления актуального выходного интерфейса и выходной инкапсуляции для BGP-маршрута. Он производится исходя из значений протокольного Next-hop маршрута и актуального состояния таблиц маршрутизации. Происходит однократно либо в момент создания маршрута, либо значимого изменения его атрибутов. Необходим для программирования корректной записи в FIB.
Lookup (или лукап) — это процесс поиска подходящей записи в таблицах маршрутизации, коммутации и других (например, FIB, LFIB, ARP Adjacencies, IPv6 ND Table) на основании значения адреса назначения IP-пакета. В современных аппаратных маршрутизаторах это происходит индивидуально для каждого пакета: то есть за короткое время — скажем, секунду — на высоконагруженном маршрутизаторе этот процесс повторяется огромное количество раз.
В таких условиях BGP-маршрут в нашей конфигурации рекурсивно разрешился не самым очевидным образом. Из-за отсутствия IS-IS маршрута разрешение происходило через маршрут по умолчанию, который, в свою очередь, был статическим. Он указывал в таблицу маршрутизации, с которой и начался процесс нашего рекурсивного лукапа.
Круг замкнулся: в FIB маршрутизаторов сформировалась замкнутая цепочка логических next-hop, приводившая к тому, что процесс лукапа над пакетом не завершался за разумное время.
С точки зрения способности пограничных маршрутизаторов отправлять трафик у этой ситуации были следующие последствия:
- у пакетов, которым выпадал этот маршрут, не было ни единого шанса «вынырнуть» из маршрутизатора;
- что ещё хуже — все имеющиеся аппаратные ресурсы линейных карт были заняты бесконечным лукапом крайне небольшого числа пакетов.
Это, мягко говоря, нештатное состояние линейных карт, когда подсистема лукапа фактически блокирована, спровоцировало ряд аварийных перезагрузок этих самых карт. И это только усугубило нестабильность и увеличило потери внешнего трафика.
Мы считаем такое поведение некорректным и связываем его с багом операционной системы вендора сетевого оборудования, потому что проблема возникла только на части маршрутизаторов и определённом типе линейных карт.
Локализация этой проблемы заняла около 10 минут. Ещё через 10 минут мы приняли решение вручную перезагрузить часть маршрутизаторов. Эти действия позволили восстановить связность. Мы воспроизвели похожую ситуацию в лаборатории днём позже, выработали для неё решение и раскатили его на весь парк устройств.
Проблема №3
Вскоре после того, как пограничные маршрутизаторы оправились от предыдущей проблемы и её прямых последствий, стала заметна частичная потеря трафика на маршрутизаторах на границе наших дата-центровых фабрик.
У этой проблемы была несколько иная природа: дело в том, что неделей ранее мы начали плановое обновление ПО на этих маршрутизаторах и к 6 февраля у нас было пять обновлённых устройств. В итоге мы выяснили, что потери трафика локализуются как раз на них.
Нестабильность в сети кратно увеличила количество изменяющейся маршрутной информации. Из-за этого появились маршруты, застрявшие в очереди от процесса, который реализовывал протоколы маршрутизации к ядру, которое, в свою очередь, должно было записать итоговые изменения в программный FIB, а затем и в аппаратный.
Мы продолжаем выяснять детали, но можем утверждать, что с высокой долей вероятности это ещё один баг в ПО одного из наших устройств. После даунгрейда проблема была решена.
Проблема №4
Но и это был ещё не конец инцидента: коллеги из Yandex Cloud сообщили о потерях части трафика сервиса объектного хранилища через одну из магистральных площадок. Сначала мы исследовали проблему на граничных маршрутизаторах, подозревая возврат первой проблемы с линейными картами, но эта гипотеза не подтвердилась.
Потом мы посмотрели, что происходит на транзитных устройствах, и выяснили, что на подключении между магистралью и бордером циклически переустанавливается контрольный протокол BFD и это приводит к постоянному перестроению сети. Искать причину мы сразу стали на промежуточных коммутаторах CLOS-фабрики, потому что ранее уже наблюдали похожую проблему с пиринговыми партнёрами в той же локации.
Наша догадка подтвердилась: мы увидели MAC-флаппинг, только источником теперь был DHCP-пакет, прилетевший со стороны магистрали на М9. В обычной ситуации такого быть не должно — у нас нет DHCP серверов в локации M9.
Мы уже знали, как исправить эту проблему: выключить DHCP-протокол на коммутаторах CLOS-фабрики на точке присутствия М9, которую мы используем для увеличения количества пиринговых портов. В прошлом мы уже поставили заплатку в виде аксесс-листа на все внешние пиринговые порты, запрещающего DHCP-пакеты на вход в фабрику. Но мы не ожидали, что такие пакеты могут прийти изнутри, из-за чего эта проблема и возникла.
Чтобы избежать повторения данной проблемы, мы выключили функциональность DHCP на коммутаторах пиринговой фабрики. Защищаться на портах в сторону нашей сети мы не видим смысла, потому что не хотим блокировать пользовательский трафик.
Таким образом, этот инцидент не связан напрямую с тремя вышеописанными, но мог каким-то косвенным образом быть вызван ими. В любом случае в обновлённой конфигурации он больше не появится.
Итог
В ходе инцидента мы столкнулись с рядом нетривиальных проблем, которые мы смогли быстро детектировать и локализовать.
Мы приняли ряд мер, которые не позволят подобному инциденту произойти вновь. Заменили отказавший маршрутизатор на полностью рабочий. Научились воспроизводить аварийную ситуацию в нашей лаборатории. В будущем она будет исправлена на уровне операционной системы производителя сетевого оборудования.
Мы уже достаточно давно думаем над диверсификацией граничных маршрутизаторов, чтобы баги, специфичные для конкретной конфигурации, не приводили к каскадной аварии. Но, к сожалению, используемая нами функциональность медленно разрабатывается другими производителями. Стратегически мы планируем:
- внедрить второго вендора на этом участке сети;
- проработать вопрос упрощения сетевого дизайна;
- улучшить систему квалификации вендорского ПО.
Мы опубликовали этот разбор, потому что считаем важным объяснять причины серьёзных аварий. Полезно не только рассказывать о достижениях, но и признавать слабые места. В конечном счёте это поможет нам извлечь урок и защитить пользователей от подобных аварий в будущем, а также помочь другим компаниям в диагностике сложных сетевых сбоев.
Комментарии (73)

ildarz
00.00.0000 00:00+26Эту проблему могла бы предотвратить резервная управляющая плата, но она отказала ещё 22 января
А через пару недель основная. "Штирлиц насторожился" (с). У вас еще есть такие маршрутизаторы? :)

Levitanus
00.00.0000 00:00+3Я думаю, здесь как с дисками в RAID1: пока они оба работают - вероятность отказа ниже 50%, но как падает 1 - вероятность того, что посыпится второй повышается.

sirota
00.00.0000 00:00Тут скорее всего ставка была сделана на то что у них достаточно связанностей с миром чтобы пережить выход из строя целиком одного из узлов. Да вполне себе провести аналогию с RAID1, но тогда там не 2 диска, а десяток и проценты там совсем другие.
ildarz
00.00.0000 00:00Аналогия с рейдом неверная, но причины близких по времени отказов в ряде сценариев иногда могут быть схожи (типа бага в прошивке, который превращает девайс в тыкву через определенное время аптайма или по накоплению какого-то другого счетчика). С учетом отказа двух одинаковых компонент одной железки в довольно короткий период времени и неизвестности точных обстоятельств произошедшего тут в любом случае есть над чем подумать, причина может в дальнейшем аукнуться на другом аналогичном оборудовании.

PeterBobrov
00.00.0000 00:00+1Но, к сожалению, используемая нами функциональность медленно разрабатывается другими производителями.
Выглядит что root cause на самом-то деле вот тут. Было бы очень интересно ознакомиться с оценкой рисков "уникальный функционал vs затраты на альтернативное массовое решение")

ammo
00.00.0000 00:00+4Но, к сожалению, используемая нами функциональность медленно разрабатывается другими производителями
И что это за особенная функциональность у секретного вендора (под кодовой буквой J, я полагаю), которой нет у других?

bDrwx
00.00.0000 00:00+29Мне кажется что по разбору этой аварии хорошо видно к каким последствиям приводит "срезание углов" при эксплуатации сложных систем. Проблема №1 - вышедшая из строя управляющая карта не была заменена в течении 2х недель! Понятно, что карты зарезервированы, стыки с внешней сетью тоже, но две недели менять вышедший из строя модуль - перебор. Проблема №2 - BGP, рефлектора, и т.д. сложно конечно говорить не зная деталей, но как по мне, на оборудовании не корректно настроены тайминги. При падении IGP нужно просто опустить BGP сессию. При помощи упомянутого в тексте BFD или костюмного скрипта. Проблема №3 - в работу выкачен софт полностью не оттестированный в лаборатории. Да, довольно сложно все проверить в лаборатории но факт остается фактом.
Проблема №4 - а устройствах не отключен не задействованный функционал.
ИТОГ: множество маленьких недочетов, совокупность которых привела к простою в 1 час.

radtie
00.00.0000 00:00+16Точно также происходят все техногенные аварии, авиакатастрофы и т.п.: каждое мелкое обстоятельство по отдельности несерьезное, но в один момент все они входят в резонанс с катастрофическими последствиями.

rexen
00.00.0000 00:00Да, достаточно, я не знаю, тот же Чернобыль или Фукусиму вспомнить. Ну или банальное рассыпание RAID-массива — как в статье — единственный резервный диск заместил полетевший и… дождались.

thevlad
00.00.0000 00:00+9Оставлю: https://how.complexsystems.fail/
Вот это вообще бессмертно и жиза:
Because overt failure requires multiple faults, there is no isolated
‘cause’ of an accident. There are multiple contributors to accidents.
Each of these is necessarily insufficient in itself to create an
accident. Only jointly are these causes sufficient to create an
accident. Indeed, it is the linking of these causes together that
creates the circumstances required for the accident. Thus, no
isolation of the ‘root cause’ of an accident is possible. The
evaluations based on such reasoning as ‘root cause’ do not reflect a
technical understanding of the nature of failure but rather the
social, cultural need to blame specific, localized forces or events
for outcomes.

hogstaberg
00.00.0000 00:00+4Таки, судя по тексту, проблема была ровно одна - подлый непродуманный статический маршрут на подхвате. Всё остальное - мелкие, относительно штатные ситуации. Отказ одного бордера их многих, как в статье правильно замечено, не должен приводить к такому. И не привёл бы, не будь этого статика.
Потому, уважаемые, и существует достаточно разумная практика делать "аварийные" статические маршруты в blackhole. Пусть лучше железо выкидывает пакеты при пропадании динамического маршрута, чем вот такое творится.

ankost
00.00.0000 00:00Именно так. Static default route - это 100% red flag. Static default в Null0 это тоже самое что его отсутствие, так что это просто засорение конфига.
ankost
00.00.0000 00:00Скорее всего этот статик им нужен для чего-то вроде возвращения траффика в сеть после scrubbing. Тут действительно потенциально возможны непредусмотренные ситуации при длительном перестроении BGP и чехарде с next hops. Обычно такие вещи topology- и situation-dependant. Без детального знания топологии и конкретных обстоятельств вряд ли стоит делать выводы.

vanxant
00.00.0000 00:00+3вышедшая из строя управляющая карта не была заменена в течении 2х недель
в силу известных причин логистика этой платы могла оказаться отнюдь не NBD

Derek_Hu
00.00.0000 00:00Проблема №3 - в работу выкачен софт полностью не оттестированный в лаборатории.
А какой вендор вам даст 100% гарантию что софт не кривой ?



LESH1972
00.00.0000 00:00+6Я бы еще сюда посмотрел "Из-за отсутствия IS-IS маршрута разрешение происходило через маршрут по умолчанию, который, в свою очередь, был статическим.", очень сомнительная конструкция

MRD000
00.00.0000 00:00Мне интересно, Яндекс использует или пробовал смотреть железки типа white label? Или это только реально для datacentre свичей?

EasyMoney322
00.00.0000 00:00+3>Чтобы избежать повторения данной проблемы, мы выключили функциональность DHCP на коммутаторах пиринговой фабрики.
У меня нет опыта взаимодействия с коммутаторами Enterprise-уровня, но зачем на них DHCP, и почему он не отключен, когда не используется?

Didimus
00.00.0000 00:00-4Если проблема только после обновления, не может ли она быть намеренно привнесена?
web3_Venture
00.00.0000 00:00+15"Наша сеть одна из самых сложных в мире, "
Гдето рядом ржет cloudflare , и магистрально континентальный дата центр в Амстердаме

Chupaka
00.00.0000 00:00+11Сложная — не значит большая. Cloudflare, емнимс, старается наоборот упрощать.

RTFM13
00.00.0000 00:00+4Самые сложные конструкции обычно состоят из костылей. Я бы в эту сторону смотрел.


maxalion
00.00.0000 00:00+3Проблему потери связности по BGP между коробками вследствие падения нижестоящего протокола , думается, вполне решило бы наличие аварийного статич. маршрута для общего префикса подсети опорных loopback интерфейсов со сбросом в Null (чуть выше в комментах упомянули о blackhole). В нормальном рабочем состоянии системы данный маршрут less specific, и ни на что не влияет. Кажется, этого было бы достаточно, чтобы п.п.2-3 не триггернули. По этой проблеме видится ошибка проектирования.
Интересно, для чего на коробках clos фабрики на М9 потребовался dhcp функционал

DesuRM
00.00.0000 00:00-1Заметил что когда у Яндекса что-то ломается/утекает/падает, то появляется представитель компании и говорит:
Ой, а мы но виноваты, это не мы, это другая организация отвечает
нас там нет.Верим.
DesuRM
00.00.0000 00:00-1Прибежали обиженки из Яндекса и накидали минусов, дети, ей богу дети.
Кстати, как там Алиса, микрофон не включает? А то в марте говорили что нет, такой функции нет, а в недавном сливе нашли что есть.

suricat404
00.00.0000 00:00+1На сколько я помню, когда-то у Яндекса уже была схожая авария на уровне сети, только тогда проблема пошла с глюкнувшего маршрутизатора по BGP..
Как я понимаю, тогда с выводами особо не заморачивались?)

Pearl_Diver
00.00.0000 00:00+4Думаю, корень проблемы был тут:
маршрут по умолчанию, который, в свою очередь, был статическим.
Ну и замена отказавшей 22 января платы, котораяне была завершена 6 февраля...
Это - очень странно...
Xell79
00.00.0000 00:00Проблемы с заменой умершего оборудования будут встречаться всё чаще. Такова реальность


EvgenT
00.00.0000 00:00-4А вот теперь, хотелось бы услышать ответ на следующий вопрос:
когда у вас всё завалилось, мои пользователи, при входе в почту, стали получать вот такое сообщение:

У нас нет ни каких подписок. Что это было за вымогательство такое? На волне отказов сервисов заработать пытались?
У других пользователей (другой домен) вот такое:

Хочу каких-то объяснений. Хотя предполагаю, что это тоже не вы, а какой-то сторонний вендор или подрядчик....



prostoi1001
00.00.0000 00:00Дайте угадаю, мммм, скорее все железо которое не отработало dhcp пакетик, начинается на букву ж, ptx10000? 10016? Мне это напомнило фразу из фильма "если бы вы знали что искать, то увидели алгоритм на окне в мою спальню")))

Tannenfels
00.00.0000 00:00-5Лучше расскажите как недавно Яндекс сделал крупный вклад в опенсорс, кек

sergey-b
00.00.0000 00:00+2Осталась нераскрытой тема, что было аварией затронуто. Какие именно сервисы сколько времени не работали. Я, например, вообще не заметил никаких проблем. У меня есть сервера, с которых каждые 5 минут делается запрос на ya.ru, просто чтобы убедиться, что прокси работает, и этот мониторинг ни разу не мигнул.
Chupaka
00.00.0000 00:00+3Мне повезло меньше, я в этот момент вызывал такси. Сначала 5 минут поиска закончились ничем, потом чуть поглючило - и предложило машину через 35 минут за сумму раз в 7-8 выше изначальной. Пока мысленно матюгался и шёл до автобусной остановки - всё нормализовалось, вызвал оттуда по нормальной цене.
sergey-b
00.00.0000 00:00Сейчас посмотрел, действительно мигал мониторинг 6 февраля. Началось с того, ya.ru вернул 404. Через 3 часа пошли таймауты, 500-е статусы, потом 502-е и так 2,5 часа.

sfinks777
00.00.0000 00:00+1Он указывал в таблицу маршрутизации, с которой и начался процесс нашего рекурсивного лукапа.
Насколько я знаю, Juniper расскажет при коммите, что статик написан на ту же таблицу.
admin@mx5# show | compare [edit routing-instances VRF1] + routing-options { + static { + route 10.0.0.0/8 next-table VRF1.inet.0; + } + } [edit] admin@mx5# commit check error: [rib VRF1.inet.0 routing-options static] next-table may loop error: configuration check-out failed [edit] admin@mx5#То есть в лоб такое не удастся. Предположу, что статиков много было на пути из таблицы в таблицу и круг замкнулся. Такие конструкции применяются для сложносочиненного ликинга, который наблюдать на бордерах несколько непривычно.

remendado
00.00.0000 00:00-3Написано хорошо. А по факту - именно это и происходит, когда у руля финансисты, а не технари. Касается и крохоборства с подписками, кумулятивный эффект от которого тоже приносит ущерб, но более растянутый во времени.
Leo_null
00.00.0000 00:00+1@aglazkov отличная статья, спасибо что делитесь с подписчиками. Вы написали что "В современных аппаратных маршрутизаторах это (lookup) происходит индивидуально для каждого пакета" и это показывает недостаток аппаратных решений. Пробовали ли вы что-нибудь software-based что-то вроде TNSR от Netgate? Сейчас есть множество решений которые построены на open-source проектах как fd.io, DPDK, VPP что может во много раз ускорить скорость принятия решений. Одно едро может обрабатывать трафик 15 миллионов пакетов в секунду и даже больше. Если что-то подобное уже тестировали пожалуйста поделитесь. Спасибо.
zerberous
00.00.0000 00:00+1Потом мы посмотрели, что происходит на транзитных устройствах, и выяснили, что на подключении между магистралью и бордером циклически переустанавливается контрольный протокол BFD и это приводит к постоянному перестроению сети.
в вот можно детальней описать вот этот момент c mac-flapping и тп ?
maxalion
00.00.0000 00:00+1Mac флаппинг поверх какого-нибудь варианта оверлея , не реализующего соответствующий механизм защиты от него, может приводить к весьма неприятным последствиям. Некоторые вендоры отыгрывают такую ситуацию жёстким err.disable физич.интерфейса, с которого летит флапающий mac

scruff
00.00.0000 00:00О проблеме №5 забыли. Точнее это даже проблема №0 - которая превыше всех. Проблема, присущая всем крупным компаниям-толстосумам, проблема экономии на спичках. Срезали на квалифицированном персонале - поэтому и карта "менялась" две недели, и софт долго апдейтился, и флаппинг из-за проблемы №0 случился, и всё остальное. И никакая это не проблема в железе. Было бы больше людей - протестили бы девайсы где-то в песочнице на предмет всех фитч получше. Все стресс тесты прогнали бы. Представляю, как немногочисленные сетевики получили по бошке за. Когда уже до начальников дойдёт что сокращенный штат и перегруженность сотрудников рано или поздно приводит к тому что случилось.

FoxWMulder
00.00.0000 00:00Эту проблему могла бы предотвратить резервная управляющая плата, но она отказала ещё 22 января, а работы по её замене были запланированы, но не завершены.
Дальше, как говорится, можно не читать. Знаю, видел, что вот подобные "потом заменим" в замене резервного оборудования которое вышло из строя, потом и приводят к авариям. Мой опыт подсказывает о том, что подобный факт длительной замены оборудования, многое говорит о компании. Не стоило вам писать эту фразу.

CCNPengineer
00.00.0000 00:00а вендор J продолжает поддержку своих устройств в России и вендор C ?
и поставки новых устройств?
ankost
00.00.0000 00:00Не совсем ясно из текста, у них что-ли внешние BGP peerings подключены через CLOS switch fabric? Тем более IX?

socketpair
Назовите вендора сих великолепных девайсов!
barloc
А какая разница? Уж 10 тысяч раз говорили, что моновендор - крест на сети, не говоря о моножелезке на определенном уровне.
Со стороны закупа и сто вагон одинаковых железок одного вендора звучит великолепно, а получается в итоге вот такое.
Остается вспомнить эпичные аварии мегафона, когда у них несколько регионов лежали по вине хпе.
aglazkov Автор
Мы считаем что ошибки могут быть в любом ПО. Наша сеть одна из самых сложных в мире, о чем мы регулярно рассказываем на nexthop, мы сотрудничаем со многими производителями сетевого оборудования, и за, более чем 20 лет, встречали много разных ошибок, которые производители в последствии исправляли. Поэтому, из этических соображений, не хотим раскрывать имя производителя
V0ldemar
>>Поэтому, из этических соображений, не хотим раскрывать имя производителя
Готов сделать это за вас !)
Gor40
Ещё бы сервера Толоки сделали. Исполнители жалуются почти ежедневно.
ortemij
Здравствуйте! Подскажите, пожалуйста, на что конкретно жалуются исполнители? Мы посмотрим.
Gor40
Самозанятые жалуются что их банят как ботов, хотя они прошли через госуслуги. Остальные жалуются что приёмка заданий бывает дольше выполнения задания (это про задания с немедленной оплатой). А вообще советую почитать комментарии в вашей же группе в ВК, заодно может от троллей почистите.
Ну и на курс доллара жалуются, но к технической части это не относится.
vvpoloskin
Кто в теме по описанию поймет производителя.
navion
Явно не Ариста.
socketpair
Juniper ?
VLADbIKA
Видимо, как раз примерно столько они включаются)
SyRock
ну там и ссылка туда ведет, к J
Breathe_the_pressure
Ц?
KndK
Может Б?
socketpair
Да не. Ни Э ни Б не потянут. Да и незачем импортозамещаться.
socketpair
Х врядли они бы купили. зочем.