
После выхода ChatGPT только ленивый не написал о нём. Языковая модель GPT-3.5 от OpenAI привлекла широкое внимание общественности своими возможностями: создание текстов, возможности перевода, получения точных ответов и использования контекста для диалога. Но больше всего разработчиков впечатлила возможность написания работающего кода по запросу на естественном языке.
Обученная на доступном в open source коде модель прекрасно понимает запросы и выдаёт фрагменты кода, готовые к использованию. У впечатлительных разработчиков появились упаднические настроения: скоро компьютеры научатся писать промышленный код, программисты больше станут не нужны и всем нам придётся искать новую профессию. Как когда-то пришлось это делать машинисткам или лошадиным извозчикам.
В этой статье поговорим про новое поколение нейронных сетей, обсудим конкуренты ли они нам или союзники, какое будущее нам уготовано и пора ли обучаться новой профессии.
Современные модели и их результаты
В настоящее время есть как минимум 2 крупных игрока, которые занимаются передовыми исследованиями и разработками в области обучения AI написанию программного кода: OpenAI и DeepMind.
В феврале 2022 года Google DeepMind опубликовали статью "Competition-Level Code Generation with AlphaCode". Разработчики научили нейронную сеть AlphaCode решать задачи с соревнований по программированию на сайте CodeForces. AlphaCode умеет по описанию олимпиадной задачи предлагать код, который решает эту задачу. По словам разработчиков AlphaCode смог в соревновании обойти 54.3% программистов из 5000+ участников.
Когда я увидел это исследование, меня оно поразило. Звучит впечатляюще, что нейросеть действительно научилась писать программы без человека. Но действительно ли первое впечатление правильное?
На самом деле, если копнуть чуть глубже, то первый восторг проходит. Давайте посмотрим на распределение рейтинга участников на Codeforces:
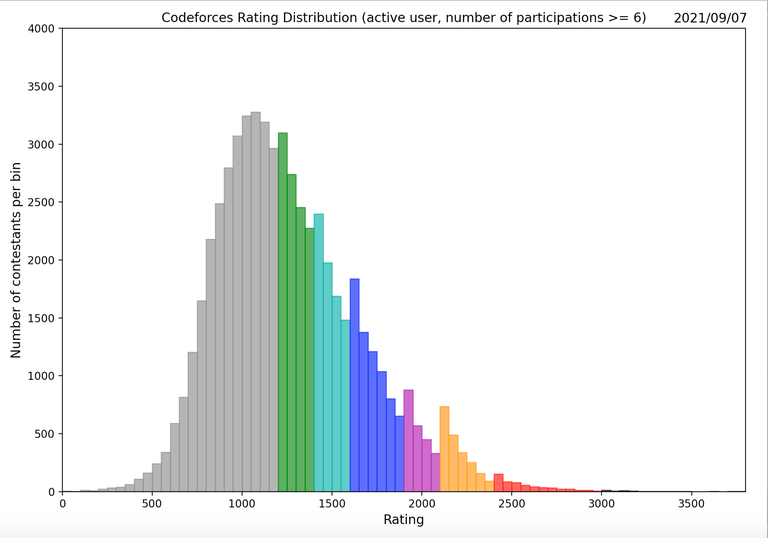
Этот график демонстрирует, что больше половины участников находятся в серо-зеленой зоне. И мой опыт участия в соревнованиях по программированию говорит, что эти зоны обычно состоят из участников, которые способны решить первые 1-2 задач из соревнований второго дивизиона. Эти задачи обычно из разряда "сделай то, что описано в условии". И это укладывается в то предположение, которое применили при разработке AlphaCode: описание задачи и есть выражение того, что должен сделать алгоритм, а программа - это изложение условия на другом языке. Отсюда можно сделать вывод, что AlphaCode не научилась решать задач по программированию, а научилась переводить текстовое описание алгоритма на другой язык - язык программирования. Это тоже впечатляет, но уже не звучит так круто.
Второй аспект, который стоит принимать во внимание, AlphaCode был обучен именно на решение олимпиадных задач и именно на специфике Codeforces. Олимпиадные задачи были выбраны не зря. Часто в описании задачи уже заложено то, что нужно буквально сделать, убрав шелуху из условия. Это ещё раз подтверждает, что нейросеть не научилась решать задачи в широком смысле понимания этого слова, а научилась транслировать текстовое описание задачи в программный код.
Если посмотреть на разработки от OpenAI, то возможности очень похожи, хоть разработчики подошли с другого конца. Вы подаете на вход текстовое описание задачи, а нейросеть выводит исходный код. И тут не идет речь о тренировке на специальном олимпиадном виде задач, которые обычно имеют достаточное и полное описание, что нужно сделать, а также описание входных данных и их допустимых значений. В интернете сейчас есть множество примеров, когда ChatGPT успешно может написать примеры кода, которые используются в промышленном программировании с использованием популярных языков программирования, библиотек и прочих общедоступных инструментов. На мой взгляд, это может выглядеть даже более впечатляюще, чем натренированная под определенный формат задач модель.
Стоит отметить, что для олимпиадных задач, на которых обучалась AlphaCode, обычно есть достаточно полно покрывающий разные тестовые сценарии набор тестов. С их помощью можно получить подтверждение корректности сгенерированной программы. Для более широкого круга задач тоже можно сгенерировать наборы тестовых сценариев, но это может быть существенно сложнее. Без формального доказательства корректности написанного алгоритма и наличия существенного набора тестовых сценариев с покрытием краевых случаев, сложно верифицировать корректность сгенерированных программ.
Вопросом корректности и безопасности задались и специалисты из университета Нью-Йорка и университета Калгари. Они опубликовали статью Asleep at the Keyboard? Assessing the Security of GitHub Copilot's Code Contributions. В ней они проанализировали 89 различных сценариев и 1692 программы, которые сгенерировала нейросеть. Выяснилось, что в 40% случаев программы содержат ошибки, которые влияют на безопасность программы и могут быть использованы злоумышленниками.
Из всего вышесказанного можно сделать вывод, что в текущий момент популярные модели действительно умеют писать код и делают это на достаточно хорошем уровне, учитывая что AlphaCode обошёл 54.3% программистов на соревновании, а Copilot в 60% случаев выдаёт корректные программы. Но это недостаточно, чтобы заменить программистов целиком и нужны дальнейшие существенные улучшения, чтобы полноценно конкурировать с разработчиками.
Недостатки современных моделей
Кроме перечисленных выше очевидных проблем, у современных нейросетей, занимающихся написанием кода, есть и другие существенные недостатки, которые в ближайшее время не могут сделать их полноценной заменой программистов.
Во-первых, они обучены на огромных открытых текстовых датасетах из интернета и основной их принцип работы предугадать какое слово должно быть следующим в текстовой строке. Это означает, что нейросеть отлично справится с задачей, если ей предоставить множество примеров, как это было сделано до неё. И также это значит, что если данных ей не хватает, то решение найдено не будет.
Во-вторых, объемы доступных для обучения данных заканчиваются. Скотт Ааронсон из OpenAI в своей лекции говорит, что модели и так уже обучены на публично доступных текстах в интернете. И чтобы улучшать их дальше, может начать не хватать данных. Есть видео на youtube или в instagram, и они пока не использовались для обучения. Но не очевидно будет ли какая-то польза этих данных для обучения моделей. В общем сейчас не понятно есть ли существенные объемы данных, накопленные человечеством, и ещё не известные текущим моделям, которые легко доступны для их обучения.
В-третьих, стоит вспомнить на каких примерах кода нейросети обучаются. Это в основном opensource code, github, stackoverflow и т.д. И тут возникает следующая проблема. Общественно доступный код не означает корректный и хорошего качества код. По сути данными являются большое количество "домашних" проектов и сниппетов кода на разнообразных сайтах. В открытом доступе есть хорошие open source проекты, на которых можно поучиться. Но и там достаточно морально устаревшего кода, с подходами, которые уже вышли или выходят из обихода.
В-четвертых, чтобы компании начали полностью заменять программистов нейросетями для написания промышленного кода, их нужно обучить на кодовой базе организации. К данному моменту многими компаниями накоплены огромные объемы исходных кодов, которые являются интеллектуальной собственностью. И, конечно, они не захотят предоставлять доступ к своему коду для обучения, чтобы другие компании могли пользоваться этими наработками. А без обучения на специфике кодовой базы компании, инструментария, стиля по написанию кода и существующих внутренних библиотек, нейросеть не сможет выдавать более-менее существенные объемы программ, которые не только можно использовать без доработки человеком, но и более того, которые в принципе будут корректно работать. На самом деле доступ к кодовой базе топовых коммерческих ИТ компаний мог бы сильно пойти на пользу моделям. Качество их программ зачастую существенно отличается в лучшую сторону от публичного доступного кода в силу более пристального внимания к коду внутри компаний и масштабу проектов.
В-пятых, значительная часть работы современного программиста не начального уровня находится вне работы непосредственно с кодом. Нам приходится сталкиваться с проектированием новой архитектуры, внесением изменений в существующие, декомпозицией проектов, коммуникацией с коллегами, координацией проектов, планированием работ, ручными действиями в продакшн и так далее. В целом инженерная работа включает в себя много разных активностей. Конечно, написание кода остается ключевой и важнейшей активностью, но часто не основной для успешной работы.
В чем модели смогут помочь уже сейчас
А вот в чём современные модели могут помочь сейчас - это сделать нас более производительными при написании кода. AI помощники вида Github Copilot, ChatGPT и другие вполне могут упростить жизнь разработчика и сделать нас более продуктивными в ежедневной работе. Данные инструменты прекрасно справляются с запросами "как мне сделать X на инструменте Y", если X - типовая операция, а Y - популярная общественно доступная технология.
Думаю, не секрет, что индустрия ИТ пережила несколько сломов, которые кардинально повлияли на продуктивность разработчиков. Одним из таких примеров может быть появление новых более высокоуровневых языков программирования, чем были ранее. Язык C в свое время стал существенным шагом в индустрии и позволил писать портируемые с одной архитектуры на другие программы без переписывания всего кода, как это требовалось ранее для Assembler. Появление языков программирования с автоматической сборкой мусора было ещё одним шагом, который закрыл целый блок проблем, связанных с ручным управлением памятью и разрешением других ошибок в этой области. Механизм автоматической сборки мусора набрал популярность и сейчас многие современные языки содержат этот инструментарий.
Но не только развитие языков программирования приводило к повышению производительности разработчиков. Появление и совершенствование современных IDE, которые пришли на смену текстовым редакторам, было другим примером роста производительности разработчиков. Действительно, IDE существенно облегчают навигацию по проекту, помогают с массовыми рефакторингами, предлагают умные подсказки, генерируют шаблонный код и умеют делать многое другое. Основная цель IDE автоматизировать и упростить все настолько, чтобы разработчик не задумывался о рутине и мог сосредоточиться на главном в своей задаче.
Я думаю, что в ближайшие годы AI модели как раз пойдут в сторону повышения продуктивности разработчиков, а не их замены. Уже сейчас у них есть всё необходимое, чтобы сделать нашу работу сильно проще, интегрировавшись в IDE. AI может отвечать на вопросы "как сделать X на библиотеке Y" прямо в IDE без необходимости переключения в браузер и Google. В каком-то смысле это может выглядеть как в фильмах про будущее, когда человек задаёт вопросы своему электронному помощнику и получает от него ответы, персонализированные рекомендации и так далее. Действительно, разработчику необязательно держать в голове все детали и нюансы всех используемых инструментов, чтобы делать свою работу. Главное иметь возможность быстро получить правильный ответ на свой вопрос прямо в IDE, не выпадая из контекста.
Ещё одна область применения находится в другой плоскости. Разработчики часто знают достаточно глубоко основной свой язык программирования и поверхностно много других, с которыми им тем не менее приходится иметь дело. Например, большую часть времени вы пишете на Go, но иногда надо что-то посчитать в аналитической системе и для этого нужны разного рода агрегации, пересечения данных, трансформации на SQL. Или же нужно написать программу, которая регулярно обсчитывает данные на Spark + Scala и сохраняет результаты для дальнейшего использования. Или что-то нужно быстро наскриптовать на bash/python для локальной задачи. С одной стороны большинство знакомы с этими инструментами и время от времени пользуются ими. С другой стороны всё забывается, если не делать это каждый день. Если можно было бы сказать IDE: "Прочитай вот из этого файла логи в формате json, погруппируй по времени с периодом в 5 минут и нарисуй график в разрезе по ошибкам". Или "преобразуй вот этот SQL запрос в ежедневную джобу на Spark + Scala и оформи в pull request по примеру такого PR". И не нужно вспоминать как читать файл на python, как парсить json, какую библиотеку использовать для рисования графика, вспоминать синтаксис Scala. В этом случае AI модели могли бы обеспечить увеличение продуктивности разработчиков на порядки, если бы научились автоматизировать прямо в IDE простые операции, на которые нам до сих приходится тратить существенное время при работе над проектами.
Заключение
Резюмируя, я считаю, что в текущий момент современные AI модели ещё на слишком раннем этапе своего развития, чтобы полностью попытаться заменить в работе разработчика среднего уровня и выше. И пока выглядит, что есть принципиальные сложности, чтобы перейти на следующий уровень.
Но если ваша работа более чем на половину состоит из обращений к Google, работе со StackOverflow и другими публичными источниками и компиляцией информации оттуда в код, то я бы серьезно озадачился. Кажется, что современные AI инструменты эту часть работы уже научились хорошо автоматизировать и уже выигрывают конкуренцию у людей.
В противном случае можно спокойно следить за новинками в этой области и активно интегрировать их в свою работу, чтобы становиться самим более эффективным и продуктивным. Да и просто переложить неинтересную, повторяющуюся и примитивную работу на компьютеры приятно.
Комментарии (26)

mirwide
00.00.0000 00:00+4Вот бы встроить в IDE AI, которая будет писать тесты к уже работающему коду, выглядит, что должно быть под силу. Не настоящий разработчик, но для меня это самая рутинная и не любимая часть.

Ipashelovo
00.00.0000 00:00Тогда перед этим надо удостовериться, что код действительно рабочий. Ведь если есть баг в каком-то редком случае, то система будет распознавать такое поведение как верное, на что честно напишет тест
mirwide
00.00.0000 00:00Человек так же попадётся на это и напишет тест на баг. А так, можно поревьювить за AI или AI учёт постановку задачи и найдет сам баг.

turboslon
00.00.0000 00:00Кстати, да: я пользуюсь CoPilot, и с ним очень помогает следующее: в начале теста я пишу, что буду проверять в виде комментария. При наличии уже написанных 2-3 тестов он «подхватывает» и очень экономит время, зачастую выдавая целые блоки подготовки моков и проверки результатов. Эдакий контекстно-зависимый интеллектуальный копипаст

YuryB
00.00.0000 00:00-1так а что вам мешает сделать плагин? я например видел для vscode кажется, где автор просит chatgpt объяснить что делает декопилированный код
mirwide
00.00.0000 00:00+1Мне мешает то что это нужно сделать в свободное от работы время, на TS/JS которые я не знаю и учить не планирую. А так норм.


Pastoral
00.00.0000 00:00+2Предпоследний абзац. Архиверно. А работа потому и может состоять из того наполовину, что понаписанные библиотеки и повыдуманные интерфейсы и API на столько плохо структурированы и дурно документированы, что лазание по Гуглу и Стеку может составлять половину работы. Помогая с этим, a.k.a. «автоматизируя часть», AI инструменты позволят им быть ещё хуже структурированными и ещё плоше документированными.
ИМХО проблема стартовала на пути к катастрофе в тот момент, когда в программирование пришли деньги и основным результатом работы программиста стало приложение а не библиотека.


PuerteMuerte
00.00.0000 00:00Резюмируя, я считаю, что в текущий момент современные AI модели ещё на слишком раннем этапе своего развития, чтобы полностью попытаться заменить в работе разработчика среднего уровня и выше.
Тут есть другой момент: эта штука уже в обозримом будущем будет мощным инструментом увеличения продуктивности в руках собственно опытного разработчика. А это означает, что он заберёт работу у кого-то другого, и это не обязательно будут не, кто предпочитает метод StackOverflow-Driven Development.comdivuz
00.00.0000 00:00+2До сих пор никакой корреляции между ростом продуктивности и снижением количества разработчиков не было, хотя на каждом витке развития средств разработки об этом начинают писать тонны статей. Иначе программистов должно было бы сейчас быть меньше чем в 2000-м.
PuerteMuerte
00.00.0000 00:00+1Иначе программистов должно было бы сейчас быть меньше чем в 2000-м.
Я программировал в 2000-м. Могу сказать, что период существенного роста продуктивности был за десятилетие до этого, он примерно совпал с ростом производительности компьютеров. С 2000-го года продуктивность существенно не выросла. Наоборот, когда в нулевых произошло смещение фокуса с десктопов в веб и мобильную разработку, продуктивность существенно упала, ввиду тогдашней отсталости инструментария на этих платформах. Только в последние годы оно как-то догнало десктопные средства разработки.
Также, есть и второй фактор, снижающий продуктивность, это усложнение библиотек, фреймворков и собственно кодовой базы существующих проектов. В 2000-е годы в скиллы одного программиста прекрасно помещались скиллы построения UI, логики приложения, знание используемой СУБД, и сопутствующие операции — сборка, создание дистрибутивов и так далее. Сейчас это всё разные специализации — фронт, бэк, дба, девопс.comdivuz
00.00.0000 00:00+1Ну то есть вы сами подтверждаете, что само по себе наличие библиотек уже готовых, софта уже написанного и каких то чудо тулзовин сказывается на специализации, а не на количестве нанятого персонала. А на количестве сказываются другие факторы. Тот же вздутый и усиленный ковидом массовый найм джунов на космические зарплаты, а сейчас схлопывание этого пузыря. При всей очевидности искуственности раздувания и естественности в схлопывании, наверняка найдутся умники чтобы связать сокращение наймов с чатгпт )))
PuerteMuerte
00.00.0000 00:00Ну то есть вы сами подтверждаете, что само по себе наличие библиотек уже готовых, софта уже написанного и каких то чудо тулзовин сказывается на специализации
Я не ставлю тулзовины, которые умеют сами писать код, в один ряд с тулзовинами, которые просят, чтобы для них писали больше кода.

event1
00.00.0000 00:00-1С 2000-го года продуктивность существенно не выросла
Конечно зависит от того, как считать продуктивность, но в целом нельзя согласиться с этим утверждением. Сегодня команда из 3-4х человек может слабать какой-то рабочий продукт буквально за пару недель. Есть удобные среды, готовые шаблоны и т.д. Да что там говорить, если в нулевых для контроля версий использовали, прости господи, VSS.
Кроме того, за счёт развития облаков, команда в несколько десятков человек может тянуть глобальный проект с миллионами и даже десятками миллионов пользователей. 20 лет назад такое даже представить было нельзя
PuerteMuerte
00.00.0000 00:00+1Сегодня команда из 3-4х человек может слабать какой-то рабочий продукт буквально за пару недель
А как вы думаете, двадцать лет назад рабочие продукты лабались как-то иначе? Откуда этот миф, что в каменном веке двадцать лет назад пещерные программисты на каких-то жутко неудобных штуках долго и мучительно собирали софт из каких-то мелких кусочков, а потом так же мучительно его отлаживали? Двадцать лет назад у вас был фреймворк, создающий каркас приложения в пару кликов, у вас был визуальный дизайнер, который позволял быстро мышкой набросать UI и прям в дизайнтайме смотреть на его поведение, у вас были ORMы для работы с данными, где можно было легко строить запросы, и всё это биндилось к UI опять же таки, в дизайнтайме. Для коммуникаций через веб у вас не было REST, но был SOAP, который делал всё то же самое пусть и с бОльшим оверхедом, но зато это была RPC-модель, да с самоописанием, да с контролем данных, и с возможностью автоматически генерировать код клиента по описанию. Для контроля версий был популярен VSS, ну опять же таки, он не так уж и плох, это просто другая парадигма. Да, вы не могли одновременно работать над одним и тем же файлом. Но зато вы не могли и внести конфликтующие изменения, которые потом надо мучительно больно мерджить, и благодаря вынужденной синхронизации девелоперов друг с другом все знали, кто что меняет.
Поэтому нет. Если вы отмотаете ещё на десятилетие назад, то да. Но качественный скачок произошёл между «30 лет назад» и «20 лет назад», и с начала нулевых продуктивность действительно практически не выросла, просто сместился фокус на другие платформы и другие задачи.Кроме того, за счёт развития облаков, команда в несколько десятков человек может тянуть глобальный проект с миллионами и даже десятками миллионов пользователей
Ну как… вы же не забываейте, что там где-то есть другая команда, которая обслуживает всю эту инфраструктуру. За очень немалые деньги.event1
00.00.0000 00:00-1Откуда этот миф, что в каменном веке двадцать лет назад пещерные программисты на каких-то жутко неудобных штуках долго и мучительно собирали софт из каких-то мелких кусочков, а потом так же мучительно его отлаживали?
оттуда, что JUnit, например появился, как раз 20 лет назад. До этого юнит-тесты писать было нечем. Без юнит-тестов всё мероприятие скатывается к мучительной отладке.
Двадцать лет назад у вас был фреймворк, создающий каркас приложения в пару кликов
Но не было веб-приложений. Соответственно, прекрасный каркас приложение превращался в увлекательный квест под названием: "а почему это приложение у этого клиента работает, а у того — нет?"
Для коммуникаций через веб у вас не было REST, но был SOAP, который делал всё то же самое пусть и с бОльшим оверхедом, но зато это была RPC-модель, да с самоописанием, да с контролем данных, и с возможностью автоматически генерировать код клиента по описанию
Это если повезло. А если нет, то DCOM.
Для контроля версий был популярен VSS, ну опять же таки, он не так уж и плох, это просто другая парадигма.
Да, вы не могли одновременно работать над одним и тем же файлом
Вы опровергаете себя следующим же предложением.
Поэтому нет. Если вы отмотаете ещё на десятилетие назад, то да.
Туда уложился переход с перфокарт на персоналки. По-этому, там, конечно был просто тектонический сдвиг и он несомненно был куда больше чем между 20 лет назад и сейчас. Но это не делает последний мелочью.
Ну как… вы же не забываейте, что там где-то есть другая команда, которая обслуживает всю эту инфраструктуру. За очень немалые деньги.
Естественно. Рост производительности за счёт разделения труда. Столбовая дорога цивилизации.
PuerteMuerte
00.00.0000 00:00+1Без юнит-тестов всё мероприятие скатывается к мучительной отладке.
Хм. Почему? Я пользуюсь тестированием, но какой-то серебряной пули в TDD в упор не вижу. Существенная выгода есть на проектах определённой сложности, и главное — определённой связности.Но не было веб-приложений. Соответственно, прекрасный каркас приложение превращался в увлекательный квест под названием
Вы так пишете, как будто эта ситуация — обыденность, а не один из стапицот случаев, как и сейчас бывает.Это если повезло. А если нет, то DCOM.
Бывало. И что? Он вполне себе работал. Вот CORBA…Туда уложился переход с перфокарт на персоналки.
… эээ, какие перфокарты в 1990-е? Их даже в 1980-е уже далеко не в каждом ВЦ было можно найти.

SergeyTatevosyan
00.00.0000 00:00+1Со статьей полностью согласен, но в теории, в будущем, если грамотно обучить ИИ под конкретные узконаправленные задачи вашей компании, например, я думаю она вполне будет способна выдавать боевые решения. Но даже в этом сценарии кто то должен заниматься обучением и править код, доводя его до необходимого функционала. Тут история мне кажется как с конструкторами сайтов- можно конечно реализовать простой сайт на конструкторе, но как только нам нужно что то узконаправленное или максимально производительное на помощь приходит разработчик.

Ewrey
00.00.0000 00:00+1Но если ваша работа более чем на половину состоит из обращений к Google, работе со StackOverflow и другими публичными источниками и компиляцией информации оттуда в код, то я бы серьезно озадачился.
У меня у одного так? Все остальные знают какую-то магию программирования?
PuerteMuerte
00.00.0000 00:00У меня точно так же. Опытные программисты от неопытных отличаются тем, что знают, какие вопросы задавать гуглу, а не тем, что помнят в уме бесчисленное количество настроек, методов и кейсов использования библиотек и фреймворков их стека, которые к тому же постоянно изменяются.

Ingulf
00.00.0000 00:00вот это вот обучение на open source, а ведь в open source выкладывают и проекты закрытые к копированию и воспроизведению...
barloc
SO на батарейках и в режиме совсем черного ящика. Если на форуме вам еще напишут, почему оно так, то тут вы все делаете на свой страх и риск.
MTyrz
Да, но программирование методом копипастинга с SO, как говорят, довольно-таки распространено. Чем вкуривать, что делает этот кусок кода, можно его просто вставить и посмотреть, заработал ли. И так поступит… да большинство так и поступит, бери больше, кидай дальше, у нас дедлайн на носу. На что я далек от всего этого, но пирамиды вложенных циклов и прочие решения с (глазомерной) сложностью О3 — О4 встречаются довольно-таки регулярно.