

Всем привет, в данной статье мы затронем основные аспекты работы со спотовыми нодами AWS, как, что, и почему? А так же будут живые примеры инфраструктуры построенной на спотах, и в конце самое интересное это кол-во сэкономленных денег $. За подробностями прошу код кат.
Содержимое:
- Что такое споты, краткий принцип работы
- Что нужно для спотов, определится со стратегией
- Деплой CF стека со спотами + описание параметров
- Деплой Aws Node Termination Handler + дашборд + эвенты
- Как именно обрабатываются события и переезжают поды
- Cluster Autoscaler + Batch ETL живой пример
- Виндовые споты и IIS приложение
- Подсчет экономии на живом примере
1. Что такое споты, краткий принцип работы
Если простыми словами, то спотовые ноды это те же ec2 к которым вы привыкли, только они стоят на 50-70% дешевле чем обычный ec2, но есть нюанс — Амазон может "забрать" у тебя эти ноды в любой момент, при этом послав тебе уведомление за 2 минуты до его termination. А дальше уже ты должен обработать это событие перезапустить свои сервисы на соседней ноде и жить дальше, благо на все это есть автоматизация, которую мы детально рассмотрим ниже.
В данной статье мы будем говорить именно о AWS Spot Fleet это по сути коллекция нод в состав которой могут входить как спотовые так и on-demand ноды, а вот сколько и каких именно мы уже можем настраивать с помощью параметров этого Spot Fleet.
С этими параметрами нужно определиться на берегу, перед тем как заказывать споты, чтобы у вас и цена не ушла выше необходимой, и чтобы вы без нод в принципе не остались в самый неподходящий момент.
2. Что нужно для спотов, определится со стратегией
Spot Fleet параметры:
-
SpotInstancePools: 6
Начнем с первого параметра что такое пулы для спот инстансов? Каждый конфиг инстанса, зона доступности и их свободное кол-во, это и есть пул. Рассмотрим на примере:
Допустим мы используем все 3 зоны доступности для размещения наших нод, + мы выбрали как минимум 2 конфига для нашей коллекции Spot Fleet это t3.medium, t3a.medium Итого: 2 конфига * 3 зоны доступности = 6 пулов для спотов.Важный момент!
Кол-во пулов рекомендуется выставлять по максимуму, так же как и выбирать как минимум 4 конфига схожих по параметрам и цене, будет все равно деплоится самый дешевый а если его нет то пойдет следующей по цене, но это все равно будет дешевле чем on-demand ноды. Если пулов или конфигов выберете мало то можете попасть на такой момент когда у амазона не будет нод, под ваши требования, старые уйдут в терминейт, новые не поднимутся.
-
SpotAllocationStrategy: lowest-price
И так один из важных параметров это стратегия размещения, их бывает несколько, постараюсь коротко о каждом рассказать:priceCapacityOptimized — амазон выберет для вас пул спотовых нод где будет наименьшая вероятность в ближайшее время приход эвентов на terminate и следом из этих уже пулов выберет те где цена будет наименьшая, при этом вы балансируете якобы между capacity и низкой ценой, Такая консервативная стратегия, явно не для нас) надо выжать максимум чтобы быть как скрудж макдак на картинке)
capacityOptimized- этот вариант еще более устойчивый к частоте прерываний работы спотовых нод, его так же рекомендуют для более высоких нагрузок типа обработки видео, или deep learning, в общем там где частое прерывание работы ноды сказалось бы хуже чем более стабильная работа длительное время но при более высокой цене за спотовую ноду.
diversified — собственно из названия наверно уже догадались, диверсификация, это как в инвестициях, для более стабильного "портфеля", ваши ноды будут разбросаны по всем пулам равномерно, а в каждом пуле цена будет разнится, речь о самом дешевом варианта так же не идет.
lowestPrice — ну и собственной самый интересный и мой выбор это самая низкая цена, раз уж мы решились внедрять споты, нужно выжать по максимуму с них, прерываний все равно не избежать, а значит наши приложения уже потенциально готовы к этому. В этом случае амазон будет подбирать вам самые дешевые пулы для нод, и соответственно скидка будет максимальной, на некоторые типы инстансов она доходит до 90%.
InstancePoolsToUseCount — этот параметр используется только в комбинации с lowestPrice, мы можем как ограничивать кол-во пулов чтобы цена точно была низкой всегда, но тогда есть шанс что не будет свободных нод для заказа, либо выставить оптимальное кол-во пулов на основе наших зон доступности и конфигов инстансов, чтобы мы не остались совсем без нод и выбор был больше.
-
SpotMaxPrice: 0,5
Можно так же для вашей коллекции задать максимальную цену на ноду в час, если мы этот параметр не задаем то максимальная цена считается = цена on-demand ноды, если задаем этот параметр то спотовые ноды выше этого лимита не будут задеплоены. Тут так же есть шанс попасть на то что в какой то момент ваша autoscale группа с Spot Fleet просто не сможем наполнится из за этих ограничений.
-
OnDemandAllocationStrategy: prioritized
Теперь мы дошли до параметров которые отвечают за on-demand ноды в нашей Spot Fleet коллекции.
Этот параметр отвечает за стратегию выбора нод для on-demand, рассмотрим пример, если выставить prioritized и мы допустим укажем 3 типа инстансов:
m5.large – priority 1
m4.large – priority 2
m5a.large – priority 3
То ноды будут деплоится в порядке приоритета, если не выставлять параметр prioritized, то амазон возьмет из списка выше самую дешевую, это, m4.large к примеру.
-
OnDemandBaseCapacity: 2
Этот параметр отвечает за кол-во нод on-demand в вашей коллекции Spot Fleet. Опять же пример — если вы деплоете автоскейл группу с desired capacity 4, то в случае с этим параметром он вам задеплоит 2 ноды on-demand и 2 спотовых.
-
OnDemandPercentageAboveBaseCapacity: 0-100
Параметр аналогичен тому что выше, за исключение что кол-во нод on-demand в вашей коллекции будет определять в % соотношении.
3. Деплой CF стека со спотами + описание параметров
Итак мы прошлись по теории кратко, теперь время задеплоить автоскейл группу с теми самыми Spot Fleet, ниже будет код CloudFormation стека, который деплоит группу спотовых нод для подключения к AWS EKS кластеру.
---
AWSTemplateFormatVersion: 2010-09-09
Description: Amazon EKS - Linux Node Group
Parameters:
KeyName:
Description: The EC2 Key Pair to allow SSH access to the instances
Type: AWS::EC2::KeyPair::KeyName
NodeImageId:
Type: "AWS::SSM::Parameter::Value<AWS::EC2::Image::Id>"
Default: /aws/service/eks/optimized-ami/1.24/amazon-linux-2/recommended/image_id
Description: AWS Systems Manager Parameter Store parameter of the AMI ID for the worker node instances.
NodeInstanceType:
Description: EC2 instance type for the node instances
Type: String
ConstraintDescription: Must be a valid EC2 instance type
NodeAutoScalingGroupMinSize:
Description: Minimum size of Node Group ASG.
Type: Number
NodeAutoScalingGroupMaxSize:
Description: Maximum size of Node Group ASG. Set to at least 1 greater than NodeAutoScalingGroupDesiredCapacity.
Type: Number
NodeAutoScalingGroupDesiredCapacity:
Description: Desired capacity of Node Group ASG.
Type: Number
NodeVolumeSize:
Description: Node volume size
Type: Number
Default: 30
ClusterName:
Description: The cluster name provided when the cluster was created. If it is incorrect, nodes will not be able to join the cluster.
Type: String
OnDemandBaseCapacity:
Type: Number
Description: "on-demand base capacity"
Default: 0
OnDemandPercentageAboveBaseCapacity:
Type: Number
Description: "on-demand percentage above base capacity(0-100)"
Default: 0
SpotInstancePools:
Type: Number
Description: "spot instance pools(1-20)"
Default: 12
InstanceTypesOverride:
Type: String
Description: "multiple spot instances to override(seperated by comma, 4 counts) t3.medium,t2.medium,t3a.medium,t3.large"
BootstrapArgumentsForOnDemand:
Description: Arguments to pass to the bootstrap script. See files/bootstrap.sh in https://github.com/awslabs/amazon-eks-ami
Default: "--kubelet-extra-args --node-labels=lifecycle=OnDemand"
Type: String
BootstrapArgumentsForSpotFleet:
Description: Arguments to pass to the bootstrap script. See files/bootstrap.sh in https://github.com/awslabs/amazon-eks-ami
Default: "--kubelet-extra-args --node-labels=lifecycle=Ec2Spot"
Type: String
NodeGroupName:
Description: Unique identifier for the Node Group.
Type: String
ClusterControlPlaneSecurityGroup:
Description: The security group of the cluster control plane.
Type: AWS::EC2::SecurityGroup::Id
SharedNodeSecurityGroup:
Description: The security group for communication between all nodes in the cluster.
Type: AWS::EC2::SecurityGroup::Id
VpcId:
Description: The VPC of the worker instances
Type: AWS::EC2::VPC::Id
Subnets:
Description: The subnets where workers can be created.
Type: List<AWS::EC2::Subnet::Id>
UnlimitedCredits:
Type: String
Description: "Select yes if instance type t3,t2 family"
AllowedValues: [yes, no]
Default: yes
PauseTime:
Type: String
Description: "Select yes if you want pause node update"
AllowedValues: [yes, no]
Default: yes
SetPauseTime:
Type: String
Description: "Set delay for node update"
Default: PT15M
Metadata:
AWS::CloudFormation::Interface:
ParameterGroups:
- Label:
default: EKS Cluster
Parameters:
- ClusterName
- ClusterControlPlaneSecurityGroup
- Label:
default: Worker Node Configuration
Parameters:
- NodeGroupName
- NodeAutoScalingGroupMinSize
- NodeAutoScalingGroupDesiredCapacity
- NodeAutoScalingGroupMaxSize
- NodeInstanceType
- NodeImageId
- NodeVolumeSize
- KeyName
- Label:
default: Worker Network Configuration
Parameters:
- VpcId
- Subnets
Conditions:
UsePauseTime: !Equals [!Ref PauseTime, yes]
UseUnlimitedCredits: !Equals [!Ref UnlimitedCredits, yes]
Resources:
NodeInstanceProfile:
Type: AWS::IAM::InstanceProfile
Properties:
Path: "/"
Roles:
- !Ref NodeInstanceRole
NodeInstanceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: ec2.amazonaws.com
Action: sts:AssumeRole
Path: "/"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
- !Sub 'arn:aws:iam::${AWS::AccountId}:policy/ALB_Ingress_Controller'
NodeSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Security group for all nodes in the cluster
VpcId: !Ref VpcId
Tags:
- Key: !Sub kubernetes.io/cluster/${ClusterName}
Value: owned
NodeSecurityGroupIngress:
Type: AWS::EC2::SecurityGroupIngress
DependsOn: NodeSecurityGroup
Properties:
Description: Allow node to communicate with each other
GroupId: !Ref NodeSecurityGroup
SourceSecurityGroupId: !Ref NodeSecurityGroup
IpProtocol: -1
FromPort: 0
ToPort: 65535
NodeSecurityGroupFromControlPlaneIngress:
Type: AWS::EC2::SecurityGroupIngress
DependsOn: NodeSecurityGroup
Properties:
Description: Allow worker Kubelets and pods to receive communication from the cluster control plane
GroupId: !Ref NodeSecurityGroup
SourceSecurityGroupId: !Ref ClusterControlPlaneSecurityGroup
IpProtocol: tcp
FromPort: 1025
ToPort: 65535
ControlPlaneEgressToNodeSecurityGroup:
Type: AWS::EC2::SecurityGroupEgress
DependsOn: NodeSecurityGroup
Properties:
Description: Allow the cluster control plane to communicate with worker Kubelet and pods
GroupId: !Ref ClusterControlPlaneSecurityGroup
DestinationSecurityGroupId: !Ref NodeSecurityGroup
IpProtocol: tcp
FromPort: 1025
ToPort: 65535
NodeSecurityGroupFromControlPlaneOn443Ingress:
Type: AWS::EC2::SecurityGroupIngress
DependsOn: NodeSecurityGroup
Properties:
Description: Allow pods running extension API servers on port 443 to receive communication from cluster control plane
GroupId: !Ref NodeSecurityGroup
SourceSecurityGroupId: !Ref ClusterControlPlaneSecurityGroup
IpProtocol: tcp
FromPort: 443
ToPort: 443
ControlPlaneEgressToNodeSecurityGroupOn443:
Type: AWS::EC2::SecurityGroupEgress
DependsOn: NodeSecurityGroup
Properties:
Description: Allow the cluster control plane to communicate with pods running extension API servers on port 443
GroupId: !Ref ClusterControlPlaneSecurityGroup
DestinationSecurityGroupId: !Ref NodeSecurityGroup
IpProtocol: tcp
FromPort: 443
ToPort: 443
ClusterControlPlaneSecurityGroupIngress:
Type: AWS::EC2::SecurityGroupIngress
DependsOn: NodeSecurityGroup
Properties:
Description: Allow pods to communicate with the cluster API Server
GroupId: !Ref ClusterControlPlaneSecurityGroup
SourceSecurityGroupId: !Ref NodeSecurityGroup
IpProtocol: tcp
ToPort: 443
FromPort: 443
NodeGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
DesiredCapacity: !Ref NodeAutoScalingGroupDesiredCapacity
MixedInstancesPolicy:
InstancesDistribution:
OnDemandAllocationStrategy: prioritized
OnDemandBaseCapacity: !Ref OnDemandBaseCapacity
OnDemandPercentageAboveBaseCapacity: !Ref OnDemandPercentageAboveBaseCapacity
SpotAllocationStrategy: lowest-price
SpotInstancePools: !Ref SpotInstancePools
# SpotMaxPrice: String
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref MyLaunchTemplate
# LaunchTemplateName: String
Version: !GetAtt MyLaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: !Select [0, !Split [ ",", !Ref InstanceTypesOverride ] ]
- InstanceType: !Select [1, !Split [ ",", !Ref InstanceTypesOverride ] ]
- InstanceType: !Select [2, !Split [ ",", !Ref InstanceTypesOverride ] ]
- InstanceType: !Select [3, !Split [ ",", !Ref InstanceTypesOverride ] ]
MinSize: !Ref NodeAutoScalingGroupMinSize
MaxSize: !Ref NodeAutoScalingGroupMaxSize
VPCZoneIdentifier:
!Ref Subnets
Tags:
- Key: Name
Value: !Sub "${ClusterName}-${NodeGroupName}-Node"
PropagateAtLaunch: 'true'
- Key: !Sub 'kubernetes.io/cluster/${ClusterName}'
Value: 'owned'
PropagateAtLaunch: 'true'
UpdatePolicy:
AutoScalingRollingUpdate:
MinInstancesInService: '1'
MaxBatchSize: '1'
PauseTime: !If [UsePauseTime, !Ref SetPauseTime, !Ref "AWS::NoValue"]
MyLaunchTemplate:
Type: AWS::EC2::LaunchTemplate
Properties:
LaunchTemplateName: !Sub "eksLaunchTemplate-${AWS::StackName}"
LaunchTemplateData:
CreditSpecification:
CpuCredits: !If [UseUnlimitedCredits, unlimited, !Ref "AWS::NoValue"]
TagSpecifications:
-
ResourceType: instance
Tags:
- Key: Name
Value: !Sub "${ClusterName}-${NodeGroupName}-ASG-Node"
- Key: KubernetesCluster
Value: !Ref ClusterName
- Key: !Sub 'kubernetes.io/cluster/${ClusterName}'
Value: 'owned'
BlockDeviceMappings:
- DeviceName: /dev/xvda
Ebs:
VolumeSize: !Ref NodeVolumeSize
VolumeType: gp3
DeleteOnTermination: true
UserData: !Base64
"Fn::Sub": |
#!/bin/bash
set -o xtrace
iid=$(curl -s http://169.254.169.254/latest/meta-data/instance-id)
export AWS_DEFAULT_REGION=${AWS::Region}
ilc=`aws ec2 describe-instances --instance-ids $iid --query 'Reservations[0].Instances[0].InstanceLifecycle' --output text`
if [ "$ilc" == "spot" ]; then
/etc/eks/bootstrap.sh ${ClusterName} ${BootstrapArgumentsForSpotFleet}
else
/etc/eks/bootstrap.sh ${ClusterName} ${BootstrapArgumentsForOnDemand}
fi
# /etc/eks/bootstrap.sh ${ClusterName} $BootstrapArgumentsForOnDemand
/opt/aws/bin/cfn-signal --exit-code $? \
--stack ${AWS::StackName} \
--resource NodeGroup \
--region ${AWS::Region}
IamInstanceProfile:
Arn: !GetAtt NodeInstanceProfile.Arn
KeyName: !Ref KeyName
NetworkInterfaces:
-
DeviceIndex: 0
AssociatePublicIpAddress: 'false'
SubnetId: !Select [0, !Ref Subnets]
Groups:
- !Ref NodeSecurityGroup
- !Ref SharedNodeSecurityGroup
ImageId: !Ref NodeImageId
InstanceType: !Ref NodeInstanceType
LCH:
Type: AWS::AutoScaling::LifecycleHook
Properties:
AutoScalingGroupName: !Ref NodeGroup
HeartbeatTimeout: 60
DefaultResult: CONTINUE
LifecycleHookName: !Sub "${NodeGroupName}-LCH"
LifecycleTransition: autoscaling:EC2_INSTANCE_TERMINATING
Outputs:
NodeInstanceRole:
Description: The node instance role
Value: !GetAtt NodeInstanceRole.Arn
NodeSecurityGroup:
Description: The security group for the node group
Value: !Ref NodeSecurityGroup
Пройдемся по основным параметрам которые задаем при деплое что касается Spot Fleet:
Кейс1 — деплой группы нод только спотовых для любых приложений.
NodeAutoScalingGroupDesiredCapacity: 5
#выставляем минимальное кол-во нод которое хотим видеть всегда к примеру 5
NodeAutoScalingGroupMinSize:3
#Можно выставить условно, если не планируете использовать какие то правила для автоскейлинга, тогда опираемся только на desired capacity
NodeAutoScalingGroupMaxSize: 10
#Можно выставить условно, если не планируете использовать какие то правила для автоскейлинга, тогда опираемся только на desired capacity
OnDemandBaseCapacity: 0
#Группа нод только спотовых
OnDemandPercentageAboveBaseCapacity: 0
#Группа нод только спотовых
InstanceTypesOverride: t3.medium,t2.medium,t3a.medium,t3.large
#Типы инстансов которые хотите видеть у себя в коллекции
SpotInstancePools: 12
#3 зоны доступности * 4 конфига инстансов = 12Кейс2 — деплой группы нод споты + on-demand для критически важных приложений где отсутствие нод грозит большими потерями.
Все те же параметры что и выше кроме:
OnDemandBaseCapacity: 2
#Группа нод только спотовыхИтого у нас будет 2 ноды on-demand всегда доступные и 3 спотовых по сниженной цене из того же набора конфигов что мы указали выше.
В Cloudformation стеке выше мы используем в итоге стратегию lowest-price для спотов и prioritized для on-demand нод.
OnDemandAllocationStrategy: prioritized
OnDemandBaseCapacity: !Ref OnDemandBaseCapacity
OnDemandPercentageAboveBaseCapacity: !Ref OnDemandPercentageAboveBaseCapacity
SpotAllocationStrategy: lowest-price
SpotInstancePools: !Ref SpotInstancePools4. Деплой Aws Node Termination Handler + дашборд + эвенты
И так ноды мы задеплоили, что дальше?! как обрабатывать события когда амазон шлет тебе весточку что через 2 минуты твоя нода выключится. Мы будем рассматривать на примере нод для AWS EKS, поэтому и события будем ловить и обрабатывать из кубера.
Aws Node Termination Handler GitHub
За вас уже все сделали, нужно только немного настроить и задеплоить все это в ваш кластер, сразу скажу что лучше всего настраивать этот микросервис в режиме Queue Processor, плюсы там же в гитхабе перечислены. Во первых он больше эвентов может обрабатывать, во вторых в этом режиме он будет запущен всего в 1 экземпляре и смотреть в вашу настроенную SQS очередь, вместо daemonset-а который на каждой спотовой ноде запустится и будет смотреть терминейшн эвенты по урлу http://169.254.169.254/latest/meta-data/spot/instance-action.
Перед тем как деплоить Aws Node Termination Handler нужно немного настроиться со стороны сервисов AWS, если коротко то нам нужно:
- IAM Role
- Openid Connect Provider for EKS
- SQS Queue & SQS Queue Policy
- EventBridge rules
Есть готовый terraform код для этого, можно посмотреть тут: Terraform code
Есть так же готовый хелм чарт, пройдемся немного по настройкам основным:
Прописываем аннотацию для serviceaccount.
serviceAccount:
# Specifies whether a service account should be created
create: true
# The name of the service account to use. If namenot set and create is true, a name is generated using fullname template
name:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::<YOUR ACCOUNT ID>:role/node-termination-handlerВключаем режим SQS Queue mode.
# enableSqsTerminationDraining If true, this turns on queue-processor mode which drains nodes when an SQS termination event is received
enableSqsTerminationDraining: trueНастраиваем нотификацию себе, ссылка + темплейт.
# webhookURL if specified, posts event data to URL upon instance interruption action.
webhookURL: "https://xxx"
# webhookTemplate if specified, replaces the default webhook message template.
webhookTemplate: '{"text":"[Instance Interruption] \nAWS Account: {{ .AccountId }} \nKind: {{ .Kind }} \nInstance: {{ .InstanceID }} \nNode: {{ .NodeName }} \nDescription: {{ .Description }} \nStart Time: {{ .StartTime }} \nEventID: {{ .EventID }}"}'Указываем ссылку на созданную очередь SQS.
# Listens for messages on the specified SQS queue URL
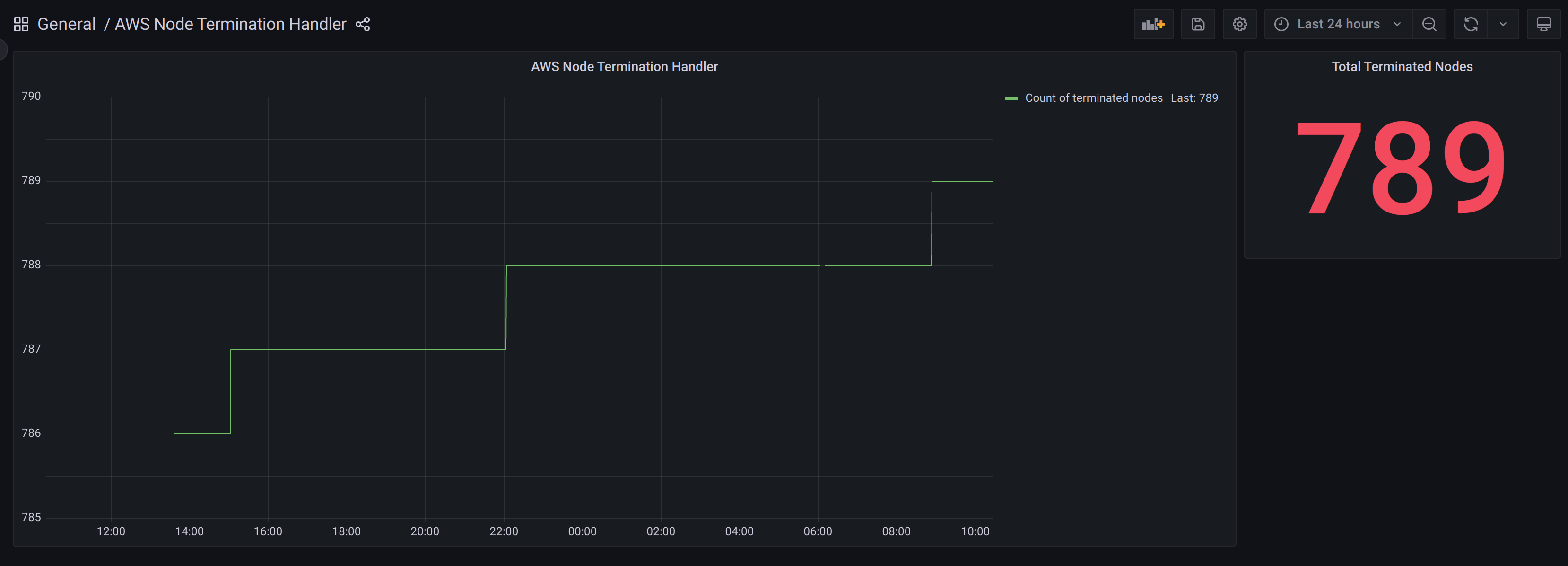
queueURL: "https://sqs.<region>.amazonaws.com/YOUR ACCOUNT ID/AWSTerminationHandlerQueue"Я так же включал метрики и сервис монитор, чтобы потом можно было на графике смотреть как часто у нас ноды уходят и в каком количестве.
Собственно дашборд очень простой, кому надо можете что по интереснее добавить, но мне главное чтобы было видно общее количество + статистика за день.
На скриншоте это общее кол-во нод которое забрал амазон за 78 дней, при общем количестве в 46 спотовых нод, амазон в день в среднем забирает по 10 штук, опять же всплески и кол-во нод зависит от нагрузку или каких либо праздников, когда многие расширяются.
Пример эвентов приходящих от AWS Node Termination Handler выглядит вот так:

5. Как именно обрабатываются события и переезжают поды
Попробую вкратце описать всю цепочку событий чтобы было понятней:
- AWS Node Termination Handler мониторит SQS Queue на наличие нужных нам эвентов
- Амазон посылает эвент о том что заберет ноду с id xxx
- AWS Node Termination Handler принял этот эвент из SQS Queue и тут же отправил cordon и drain этой ноде
- Ваши поды обязаны корректно завершится и запустится на соседней свободной ноде
- Нода ушла в Terminate, и так же удалится из списка нод в кубере
- Autoscale группа увидит что количество desired нод не совпадает, и закажет еще одну спотовую
- Нода задеплоится и подключится к кластеру взамен старой.
И все это происходит без вашего участия, вы можете наблюдать за этими событиями со стороны на графике или смотреть эвенты иногда которые AWS Node Termination Handler шлёт через вебхук.
Амазон так же предоставляет данные по частоте прерываний, или если проще, как часто амазон будет забирать у вас ноду с тем или иным конфигом, можно тут подобрать то что вам больше подходит:

Здесь очень важно все оттестировать заранее на какой ни будь тестовой коллекции нод, убедившись в том что ваше приложение готово к drain, и при этом вы не ловите 5хх ошибки в процессе рестарта пода.
Для этого есть много разных вариантов как правильно делать Graceful Shutdown для микросервисов написанных на разных языках.
Ну и второй вариант конечно тоже не исключаю, если при рестарте небольшое кол-во 5хх вас не беспокоит и не нарушает работу системы в целом, то можно так же использовать споты, это как минимум подходит для тестовых и дев сред, но это уже на ваше усмотрение, лучше все таки подготовить свое приложение к таким рестартам.
6. Cluster Autoscaler + Batch ETL на спотах живой пример
Расскажу где мы еше используем споты, это конечно же батчевые операции для построения отчетов и аналитики.
Описание задачи:
- Основная часть отчетов стартует после 1 ночи, и завершается где то в 10-11 утра
- После 11 утра до 21 00 ни чего не выполняется, ноды не нужны
- После 21 00 нужна только 1 нода максимум, до 1 ночи
- Перезапуск подов выполняющих отчетность не грозит сбоем всего отчета, рестарт в следующую попытку все продолжает.
Для выполнения задачи описанной выше как ни как, кстати подходит Cluster AutoScaler + спотовые ноды, благодаря спотовым нодам мы можем выбрать конфиг повыше при той же стоимости on-demand и отчеты будут строится быстрее.
Деплоим коллекцию нод под отчеты, и скейлим её в 0 по умолчанию, как только у нас появляются поды на запуск на этой группе нод, Cluster Autoscaler поднимает нам нужное количество нод, для размещения всех подов, как только поды отработали и больше нет задач для запуска, Cluster Autoscaler скейлит нашу коллекцию нод опять в 0.
Тут конечно важно подобрать requests & limits для ваших подов, а так же тайминги сколько будет ждать Cluster Autoscaler перед тем как скейлить коллекцию в 0. Приведу ниже ссылку на гитхаб Cluster Autoscaler и некоторые параметры из его хелм чарта при которых сценарий выше работает
autoscalingGroups:
- name: NODE GROUP NAME
maxSize: 3
minSize: 0
extraArgs:
logtostderr: true
stderrthreshold: info
v: 4
scale-down-utilization-threshold: 0.5
daemonset-eviction-for-empty-nodes: true
scale-down-unneeded-time: 30m
7. Виндовые споты и IIS приложение
Еще один кейс, спотовые ноды можно использовать не только в классических кластерах где линуксовые ноды только. Мы используем гибридный кластер AWS EKS где одновременно работают как линуксовые ноды так и ноды на windows server core.
Как всем известно виндовые ноды в амазоне стоят раза в 2 дороже, из за стоимости лицензии, и соответственно использовать их со скидкой в 50-70% это очень помогает снизить общие косты за инфраструктуру.
На виндовых нодах у нас в основном работают IIS приложения, которые надо так же готовить к корректному завершению соединений когда прилетает drain на ноду от Aws Node Termination Handler.
Можно использовать lifecycle preStop + terminationGracePeriodSeconds
lifecycle:
preStop:
exec:
command: [
"iisreset", "/stop", "/noforce"
]
terminationGracePeriodSeconds: 60Опять же зависит от вашего приложения, если у него есть привязка сессий, то тут надо уже другие варианты продумывать, вариант выше это как рекомендация лиж для начального этапа проверок.
Так же в случае использования спотовых нод для виндовых контейнеров, все мы знаем размеры виндовых контейнеров, да в 2022 винде они снизились, но все равно далеки от идеала. Поэтому нужно позаботится об AMI образе с залитым базовым докер образом для вашего микросервиса, чтобы процесс бутстрапа проходил в районе 10-12 минут максимум.
8. Подсчет экономии на живом примере
И так если вы дочитали или домотали до этого места, вам все таки интересно ради чего столько приседаний и обвязок, и стоит ли оно того.
Что имеем:
Общее кол-во спотовых нод: 46
Количество по конфигам:
Linux:
t3a.large — 3
m5.xlarge — 2
t3.xlarge — 4
m6i.xlarge — 4
t3.medium — 16
r6i.xlarge — 2
t3.large — 4
Windows:
c6i.xlarge — 6
t3.medium — 5
Тотал:
On-demand цена Linux: 2956.82$
On-demand цена Windows: 1964.75$
On-demand цена за все: 4921,57$
против
Spot цена Linux: 829,224$
Spot цена Windows: 1148,688$
Spot цена за все: 1977,912$
*Стоимость посчитана по 1 региону и по 1 зоне доступности, без разделения.
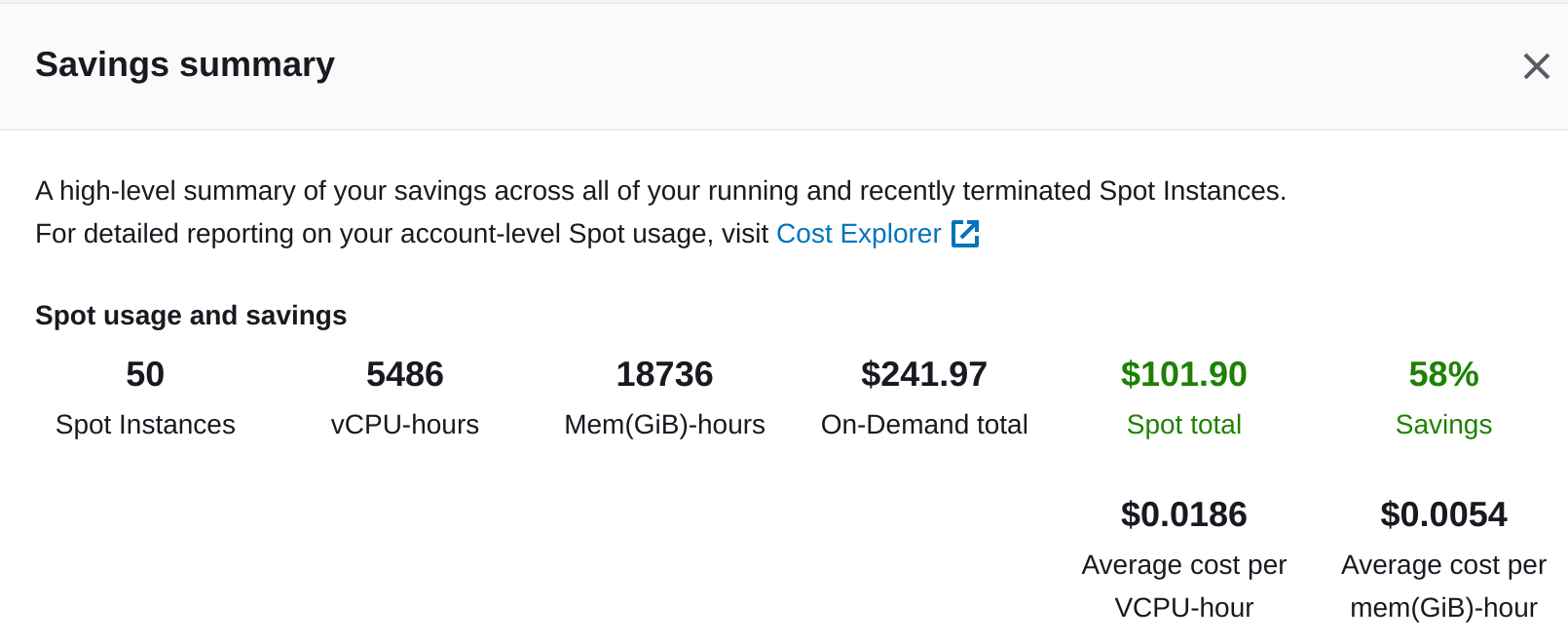
Можно так же посмотреть Saving Summary в разделе Spot Requests но он покажет только за последние 3 дня.
Заключение
И так я надеюсь после прочитанного вам захотелось попробовать как минимум свои приложения в работе со спотами. Что хотел бы сказать, даже если у вас с первого раза будет видно что ваше приложение плохо обрабатывает рестарт и корректное закрытие соединения, не отчаивайтесь, попробуйте оптимизировать его, допишите небольшие конструкции которое помогут сделать ваше приложение более stateless, или возьмите готовые примеры, на хабре так же была масса статей про Gracefull Shutdown.
Как только вы преодолеете эти трудности и внедрите споты, ваша инфраструктура встанет на ряду с такими же гигантами как Lyft, Dropbox, Skyscanner, которые уже давно используют споты повсеместно для теста и прода, для аналитики и батчевых операций, экономя при этом десятки тысяч долларов. Чем ты хуже?)
Комментарии (4)

vainkop
00.00.0000 00:00Используйте Karpenter (разработанный командой AWS) вместо Cluster autoscaler и ваша жизнь особенно со spot instances станет значительно легче! Никаких node pools не нужно, никаких заморочек с availability zone specific EBS volumes, ноды ровно такие, как нужны под нагрузки, а не какие заданы в node pool и т.д.

sam21vek Автор
00.00.0000 00:00Спасибо, потестим
vainkop
00.00.0000 00:00Для Karpenter+ EKS уже какое-то время существует нормальный сабмодуль в известном Terraform EKS модуле, рекомендую https://registry.terraform.io/modules/terraform-aws-modules/eks/aws/latest/submodules/karpenter
Чтобы не деплоить node group для Karpenter рекомендую посмотреть на пример с Fargate. Отлично работает.
term-it
Под определенные кейсы можно было бы добавить рекомендацию - использовать
nodeSelector, чтобы не запускать AWS NTH на спотовых, а только на on-demand. Если где-то было и я просмотрел - извиняюсь, мы у себя уже давно юзаем, правда не в QueueProcessing mode, поэтому читал бегло