
В первой части мы рассказывали, как нефтяные компании создают проектно‑технические документы (ПТД) на разработку месторождений, насколько это большая, трудоемкая и очень рутинная работа. Причем, помноженная на десятки выполняемых проектных документов в год. Умножим это количество документов на несколько разных сценариев, которые по закону мы должны рассматривать в каждом проекте, и получим просто колоссальный объем работ.

Поскольку «РН‑БашНИПИнефть» — крупнейший проектный институт «Роснефти», то мы делаем в среднем 100 проектных документов в год. Если вы пропустили первую часть этой статьи, то очень советуем ее прочитать — станет понятен масштаб деятельности и потребности в автоматизации.
Поскольку наш институт еще и ведущий центр разработки корпоративного программного обеспечения (ПО), в какой‑то момент мы решили автоматизировать и эту работу. Так появился проект «АвтоПТД», находящийся сейчас в активной разработке. О нем я и расскажу в этой статье.
На четырех столпах
После череды мозговых штурмов и нескольких прототипов, мы пришли к следующим столпам, на которых стоит наш АвтоПТД:
ПТД всегда готов! Это значит, в системе всегда присутствует собранный автоматом отчет, выполненный на актуализированных данных.
У готового ПТД есть метрики качества (в т.ч. учитывающие непротиворечивость поступивших новых данных).
В состав ПО включены инструменты для расчета параметров ПТД и исключения противоречий. Они влияют на метрику степени автоматизации.
Система контроля исполнения сроков, позволяющая видеть, все ли ПТД идут по плану.
Давайте расскажем более подробно о каждом столпе, чтобы была понятна наша идея.
ПТД всегда готов
Поскольку требования к составу проектного документа довольно хорошо стандартизированы и описаны, за счет интеграции с корпоративными системами мы можем генерировать отдельные его главы автоматически:
Типовые таблицы и графики;
Типовые блоки текста со ссылками на строки в БД;
Типовые шаблоны отчетов;
Типовую презентацию.
Таким образом, мы можем ввести метрику степени автоматизации, т. е. количества показателей, рассчитываемых автоматически. По мере того, как мы разрабатываем инструменты автоматизации и включаем их в общий пайплайн выполнения ПТД, наша метрика растет, в идеале стремясь к 100%.
После того как в системе появился хоть один «оцифрованный» ПТД, следующие создаются автоматически (ну, насколько это возможно в каждом отдельном случае). Как вы понимаете, это может работать только в случае, когда мы используем верные и непротиворечивые данные, на основе которых создается отчет. Поэтому у нас постоянно рассчитываются метрики качества, т. е. того, насколько наш автоматически созданный ПТД базируется на качественных и непротиворечивых данных. Также мы проверяем и результат (подробнее об этом в следующем разделе) поэтому у готового проекта метрика максимальная.
Понятно, что как только проект сделан и защищен в госорганах, его метрики качества максимальны. Со временем, по мере поступления новой информации, метрики могут ухудшаться и это потребует вмешательства человека.
«Живой ПТД», генерирующий отчет на основе данных из БД
Чтобы передать проектный документ (Word или PDF) на экспертизу в госорганы и согласовать предлагаемые изменения, нам надо сформировать отчет со всеми его приложениями. Причем, желательно сделать это максимально на автомате.
Если внимательно посмотреть на сам текст отчета, то условно его можно разделить на три составляющие:
Константы, т. е. текст, не меняющийся из отчета в отчет. К примеру, когда месторождение открыто и есть какие‑то вводные блоки текста, являющиеся обязательными.
Обязательные таблицы, графики и показатели, которые можно генерировать автоматически.
Аналитические блоки, которые специалист пишет на основании данных, полученных в пункте 2 и экспертного опыта.
Для формирования пунктов 1 и 2 мы используем модуль «Живой ПТД». Для этого в интерфейсе модуля пользователь вставляет кусок текста. В месте, где необходимо вставить переменную, вызывается контекстное меню, и пользователь может выбрать один из нескольких вариантов:
строковая переменная — выводит данные из базы в текстовом виде;
диаграмма — вставляет в документ график по выбранным данным;
таблица — вставляет в документ таблицу с выбранными данными;
условие — позволяет вставить условный блок. Отлично пригождается для формирования простых сценариев внутри отчета.
В результате, единожды расставив по тексту переменные, мы получаем всегда актуальный документ, учитывающий последние изменения в БД. При этом мы также решаем проблему масштабирования — наш шаблон можно использовать на схожих месторождениях, просто пакетно переопределив ссылки на переменные.
Шаблон представляет собой текст с разметкой для вставки переменных. Ниже представлен фрагмент работы такого шаблона.

Из забавного, с чем мы столкнулись при работе над живым ПТД, так это наличие склонений и падежей. т. е. шаблон оказался чувствителен к тому, какие числа приходят из базы и, соответственно, пришлось прикручивать Яндекс.API для склонений.
После того, как отчет по главам сформирован, он попадает в последний модуль, называемый «сборщиком». Именно тут отмечается, какая глава готова и формируется общий отчет.
Метрика «Качественные и непротиворечивые данные»
В рамках данной метрики мы контролируем и исходные данные, и результат работы. Поскольку данные всех типов поступают постоянно и их реально много, мы настроили систему регулярных проверок, называемую Data Quality.
Для понимания того, как это работает, давайте начнем с исходных данных. Всю информацию о добыче Компании, а также о свойствах пласта заносятся в корпоративную базу данных нашего ПО, называемого ИС «РН‑КИН».
В рамках данной системы мы контролируем:
наличие данных. Например: наличие данные о предыдущем проектном документе или наличие поскважинных данных о добыче с пласта, на котором фигурирует суммарная добыча;
достоверность. Например, если в БД случайно занесли данные не в тех единицах измерения (пористость не в д. ед., а в%), то расчет запасов и проектные уровни превысят ожидаемые показатели на порядок. Проверяя результат, мы это увидим за счет сниженной метрики качества;
дублирование.
Таким образом, мы контролируем и качество исходных данных, и результат, созданный на основе этих исходных данных.
Проверки реализованы в виде PL\SQL процедур или Python‑скриптов, которые выполняются автоматически при инициации нового ПТД или при переходе между формируемыми разделами. В настоящий момент реализовано около 76 таких проверок, и мы только вошли во вкус.

Дополнительно вводится еще один параметр — согласованность. К примеру, наш автоматически сделанный ПТД должен соответствовать бизнес‑плану дочернего общества. Как только бизнес‑план меняется, его соответствие автоматическому ПТД начинает ухудшаться.
Как только такое несоответствие достигнет предела допустимых отклонений, потребуется вмешательство специалиста для обновления параметров прогноза и, возможно, актуализации такого ПТД перед госорганами.
По текущей логике список таких ПТД будет направлен на утверждение в добывающее предприятие. После согласования стартуют работы по устранению несоответствий, формируется проектная группа и ПТД актуализируется с помощью расчетных инструментов.
Расчетные инструменты
Как мы говорили в предыдущей части, внутри одного ПТД мы рассчитываем множество вариантов разработки месторождения, получая их на базе цифровой гидродинамической модели и выбирая несколько лучших. Но прежде чем перейти к финальной выборке вариантов, нам необходимо поработать с гипотезами. Процитирую часть текста из предыдущей части:
Разработчик нефтяных месторождений пытается найти баланс между максимальным извлечением углеводородов на поверхность и экономической выгодой от этой деятельности, учитывая особенности геологической и гидродинамической моделей. Для этого он перебирает разные варианты размещения скважин. Эти варианты называются «системой разработки».
Во время перебора варьируются:
конфигурация размещения скважин (соотношение количества добывающих и нагнетательных);
расстояние между скважинами;
варианты заканчивания скважин (вертикальная, горизонтальная, многозабойная, фишбон и т. п.);
длина скважины после входа в целевой пласт, т. е. места расположения углеводородов (например, можно варьировать длину горизонтальной секции от 100 метров до 2 и более километров).
Обычно для экономии ресурсов во время массового перебора используется так называемый кубик — сектор гидродинамической модели с усредненными данными. Потом уже, когда какие‑то системы разработки выходят в полуфинал, расчеты лучших систем прогоняются на полномасштабной модели.
В концепции «ПТД всегда готов» мы можем быстро актуализировать ранее согласованные варианты, просто учтя новые данные. И можно было бы на этом остановиться. Но, как и в IT, технологии нефтянки развиваются быстро, и мы можем захотеть рассмотреть дополнительные варианты, потенциально интересные для рассматриваемого актива.
Увы, традиционный расчет на гидродинамической модели не всегда бывает быстрым. К тому же «кубик» из цитаты выше не равно всё месторождение. Поэтому в работе мы можем рассматривать десятки внутренних вариантов (и их комбинаций для разных пластов), из которых отбираем лучшие. Для этого нам нужен скоростной инструмент отработки гипотез, позволяющий получить набор вариантов с разными свойствами, чтобы выбрать оптимальные и уже их нести в модель.
. Каждый тип имеет свою окупаемость, что позволяет более вариативно составлять проектные варианты")
Раньше мы использовали специальные макросы в Excel. Но поскольку нам известно поведение уже пробуренных скважин и данные по ним уже хранятся в базе, то мы создали специальный модуль в корпоративной системе «РН‑КИН», позволяющий продолжить тренд поведения скважин и добавлять к ним «осредненные» новые скважины для быстрой оценки предложенных вариантов.
Плюс мы «оцифровали» несколько внутренних легаси‑инструментов, написанных на смеси VBA и дельфи, учли несколько самодельных поделок, используемых в разных проектных группах и увязали их в единый пайплайн ПТД. Получился базовый Workflow выполнения ПТД с целевой степенью автоматизации этого года выше 50%.
Как только мы начали реализовывать эти базовые вещи, открылся горизонт планирования инструментов для дальнейшей автоматизации создания проекта.
Контроль бизнес‑процессов
Поскольку ПТД не просто должен быть актуализирован, но и должен быть выполнен в срок (ЦКР принимает работы до определенной даты, плюс должны быть пройдены внутренние экспертизы), а также должен содержать всю необходимую информацию и сделан без пропуска нужных действий/шагов, мы реализовали BPMS‑компонент для отслеживания этих пунктов.
Мы интегрировали в «АвтоПТД» Workflow‑контроллер, что позволило нам формализовать сам процесс, отслеживать шаги его выполнения, формировать отчетность по процессу его выполнения.
Ниже приведен фрагмент схемы формирования ПТД:
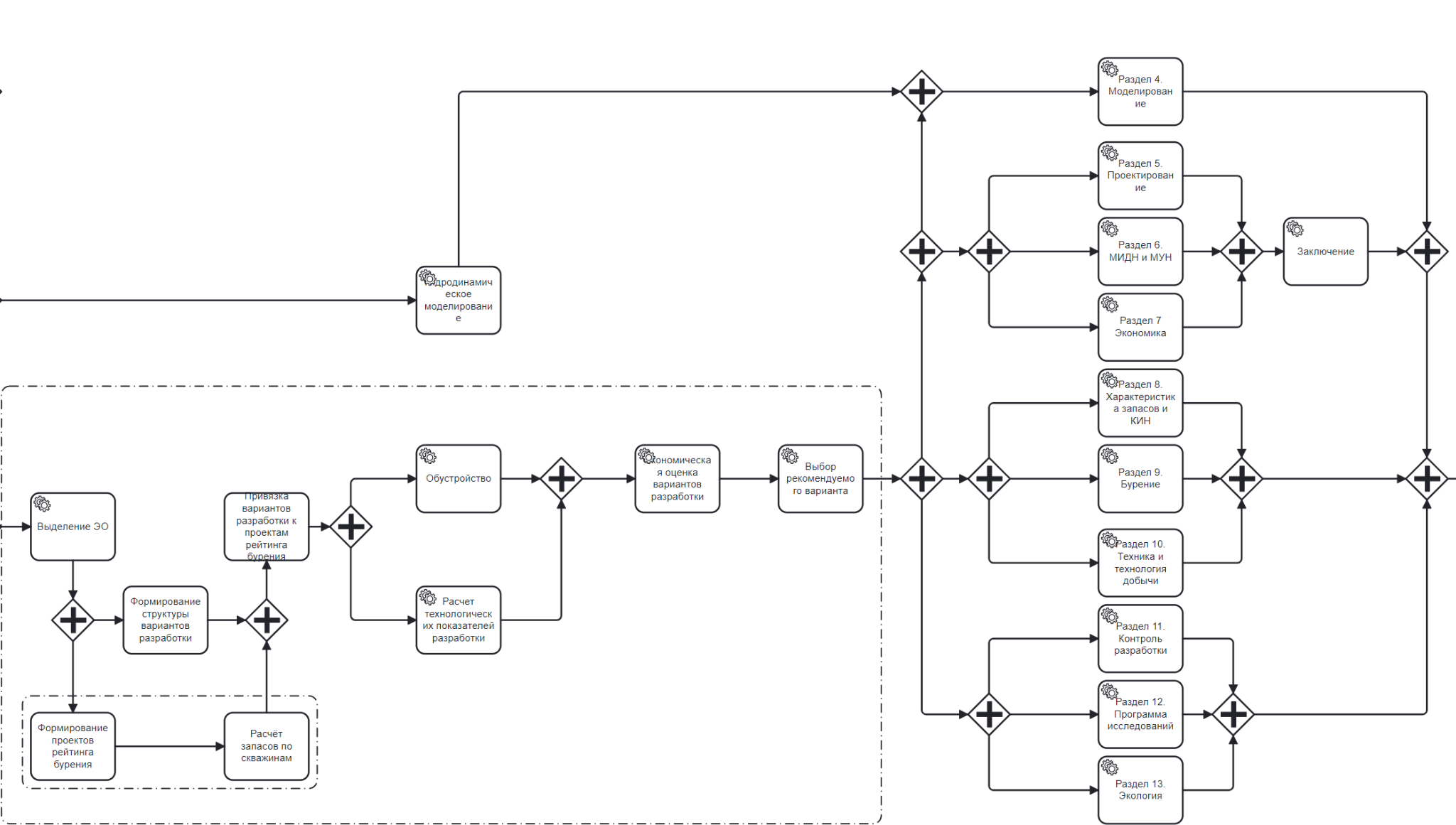
Каждый кубик BPMN‑схемы привязан к конкретному действию внутри «АвтоПТД», и процент завершения считается как процент «завершенных» кубиков. Важно, что система может не пускать на следующий шаг, пока не выполнен предыдущий, не давать «срезать углы» при составлении проекта и многое другое.
Информация из BPMS сводится в дашборд статуса выполнения ПТД. Прохождение каждого кубика процесса увеличивает прогресс, позволяя вывести статус выполнения.

Мы уже говорили выше, что наш институт является ведущим разработчиком корпоративного ПО для Роснефти. Сначала мы писали ПО, чтобы заместить выпавшее импортное. Сейчас, выстроив линейку программ, мы переходим к заполнению «белых пятен», т. е. цифровизации там, где импортного ПО не существовало в принципе.
АвтоПТД — хороший пример того, как можно выстроить сложную работу для повышения внутренней эффективности. Мы гордимся тем, что создаём сложное и наукоемкое ПО. Система еще находится в стадии активной разработки, но мы уже видим огромный интерес к ней.
И да, мы всегда ищем новых членов нашей команды. Нам нужны неравнодушные к результату программисты с опытом разработки на C# либо С++ (Qt). Свои резюме можно присылать на hr@bnipi.rosneft.ru с пометкой «АвтоПТД».
Николай Маслухин @Maslukhin

AlexXYZ
Скажите, для шаблона вы взяли какой-то известный формат или сделали свою островную грамматику с парсером? (Типа как php или asp).
Maslukhin
Грамматика своя на основе SGML. В качестве парсера использовался движок представлений Handlebars, а так же самописный парсер, который трансформирует SGML в формат FlowDocument и обратно.
AlexXYZ
Понял, спасибо.