

targetXML маленький экскурс в структуру дерева XML на примере работоспособного кода «pure C».
Структура сложно устроенных деревьев меня интересовала уже давно, все началось еще с изучения простого варианта бинарного дерева. Не хотел в этой статье углубляться в строение таких деревьев особенно «повернуть» в сторону самих поворотов при манипуляции с данными. А хотел прежде всего изучить более подробно что такое xml, как формировать файл xml, как он связан с деревом. Также хотел рассказать свои мысли по поводу того как же это все завязано на рекурсивном обходе xml дерева данных.
Содержание:
xml файл особенности
подготовительный этап
создание основы конструкторы и деструкторы работы с памятью
блуждаем по веткам, пробуем экспортировать данные
добавление функционала обработки тегов их содержимого и обработки атрибутов и их содержимого. Контент
экспорт в файл, а также сложнейший этап задачи парсинг из файла и построение дерева
Xml файл особенности
XML (Extensible Markup Language — расширяемый язык разметки) является потомком чрезвычайно обобщенного и сложного языка SGML, который был разработан в начале 1970-х под руководством Чарльза Голдфарба, работавшего в компании IBM. Предназначен SGML был для тех же целей, для которых сейчас применяется XML, - семантической (проще говоря, смысловой) и структурной разметки текстовых документов. Однако широкого распространения SGML не получил по причине своей сложности (его официальная спецификация — это 150 страниц одних лишь технических деталей). Он настолько сложен, что ни один программный пакет так и не смог реализовать его полностью. По этой причине в 1996 году началась работа над упрощенной версией SGML, в которой были бы сохранены основные идеи языка Голдфарба, однако были урезаны редко используемые и излишне запутанные возможности. В результате этой работы в 1998 году появился XML 1.0, сразу получившим широкое признание. На настоящий момент все системы, так или иначе связанные с обменом данными, поддерживают XML. Не является исключением и Flash.
Еще одним упрощенным потомком SGML является HTML. Однако будет большой ошибкой считать XML и HTML близкими языками.
Структура документа XML довольно таки проста. Информация которая транслируется при помощи XML предоставлена названиями частей - тегов, внутреннего содержимого — тела документа, атрибутов конкретного узла которые прописываются в виде шапки и хвоста рядышком с названием тега, и их может быть неограниченное количество. И неограниченного количества детей которые может содержать любой из узлов. Таким образом у разработчика в голове сразу же формируется образ структуры дерева из узлов где есть родители и дети.
Подготовительный этап
Естественно перед описанием такого «древовидного контейнера», необходимо тщательно изучить техники рекурсивного прохода. Также считаю, что надо отчетливо представлять как можно реализовать простейший двухсвязный список, и как «итерироваться» в нем ведь это очень важно при различных вариантах обхода. Важно знать как работать с динамической памятью и уметь работать с valgrind тщательно проверяя утечки на каждом этапе работы с самим деревом. Также для выполнения задачи необходимо хорошо знать С.
Создание основы, конструкторы и деструкторы взаимодействующие с памятью
Поскольку мы изначально пишем на чистом С, попрошу читателя углубится в особенности реализации объектно ориентированного подхода и особенности выделения памяти на этом языке в отдельные статьи освещающие эти вопросы. И по возврату с этими знаниями, можно продолжить ознакомление с текущим материалом.
Конструкторы и деструкторы наших нод для дерева мы будем строить на примере простых данных (integer value), чтобы не испортить имплементирующие свойства ознакомительного материала.
Все дело в том, чтобы понять в чем же является абстрактный фундамент механики для нашей структуры «дом», в первую очередь нужно понять, что весь дальнейший функционал будет опираться именно на эти первоначальные структуры и функционал их конструкторов. И воплощение такой довольно не тривиальной задачи, как реализация основы, содержит в себе много подводных камней, требующих в дальнейшем ремастерить код основы частично а иногда и целиком. Поэтому крайне важным на этом этапе является правильное планирование реализации. Успокоив себя словами: о сейчас я сяду и все быстренько напишу, сесть писать сразу готовый код не совсем хорошее решение в данном случае. Лучше в процессе планирования заглянуть вперед и спросить себя или старшего товарища: а что будет дальше?
В первую очередь нам нужно остановиться на том, а как же у нас устроена сама наша нода?
И в данном конструкторе есть что обсудить? В первую очередь наш узел устроен следующим образом имеется указатель на родителя federal и указатель на массив указателей на цепочки из детей chain. Таким образом мы уже можем понимать что нам понадобятся две переменные описывающие количество детей и описывающие размер нашей ноды, который будет позволять вносить в него изменения. Также для того чтобы наша система была тесто-пригодна, то в случае утерянных нодов или проблем с затерянными узлами при создании дерева, или манипуляции с ними в каждой ноде указывается значение того места в массиве которому эта нода принадлежит upyardPlaceHolder. Такая индексация в дальнейшем не окажется излишней, поскольку может существенно сократить поиск места где произошел обрыв в коде.
struct Node nullNode; //this is a null marking structure
struct Node
{
int value;
size_t eternalCount; //chain counter
size_t capacity; //reserved volume of chain
size_t upyardPlaceHolder; //the place in upyard chain
struct Node* federal;
struct Node** chain;
};Во фрагменте кода выше в строчке 1 создается статический узел который будет для нас ориентиром для нулевой ноды. В переменной capacity храниться размер нашей цепочки, а в переменной eternalCount содержится количество добавленных дочерних нод. Именно эти две ключевые переменные определят в дальнейшем то состояние когда необходимо будет переопределять память для цепочки узлов ** chain.
//try to make an empty node
struct Node* Node_Cnstr_Empty (struct Node* node, int val)
{
//Poke memory (two pointers)
node = (struct Node*) malloc(sizeof(struct Node));
node->capacity = 10;
node->chain = (struct Node**) malloc(node->capacity * sizeof(struct Node*));
for (int i=0; i<node->capacity; i++) node->chain[i] = &nullNode;
//engage value
node->value = val;
//press up counter
node->eternalCount = 0;
//adress federal null
node->federal = &nullNode;
//make upyard value -1 unchained
node->upyardPlaceHolder = -1;
my_Print_Hex("NODE_REPORT(cnstr): constructor empty throwing ", node);
return node;
};Сам конструктор для нашего дерева должен быть прост и составлен так, что позволит нам не переопределять память по каждому запросу, а выделить сразу удобный участок памяти.
//try to Engine - Widing capacity
struct Node* reEngineNode (struct Node* node)
{
if (node->capacity == node->eternalCount)
{
//Create temporary copy
struct Node** tmp_chain = (struct Node**)malloc(node->capacity * sizeof(struct Node*));
for (int i=0; i<node->eternalCount; i++)
{
tmp_chain[i] = node->chain[i];
}
//engage capacity
node->capacity = 2*node->capacity;
//Poke(free) memory
free(node->chain);
node->chain = (struct Node**)malloc(node->capacity * sizeof(struct Node*));
for (int i=0; i<node->capacity; i++)
{
if (i < node->eternalCount)
{
node->chain[i] = tmp_chain[i];
}
else
{
node->chain[i] = &nullNode;
node->chain[i]->upyardPlaceHolder = i; //mayBeNeedable in debug
}
}
//deleash temporary copy
free(tmp_chain);
//report
my_Print_Hex("NODE_REPORT(engine): sucsessfull reengined node", node);
//return engined node
return node;
}
else
{
return node;
};
}Здесь в участке кода выше описан функциональный метод расширяющий память reEngine. Будем увеличивать память просто вдвое это будет для нас удобно.
//check reEngine and after that try to attaching child
void Node_Attach_Child(struct Node* parent, struct Node* chld)
{
//check and get ready tree to engine
if (parent->capacity == parent->eternalCount)
{
parent = reEngineNode(parent);
};
//adapt childrens (SIGNES::in all cases our eternalCount signs to needable range(0 to eternalCount-1))
parent->chain[parent->eternalCount] = chld;
chld->upyardPlaceHolder = parent->eternalCount;
chld->federal = parent;
//attach_report
printf("NODE_REPORT(atch): attach report P %x", parent);
printf(" hook on Ch %x", chld);
printf(" placed in [%d", parent->eternalCount);
printf("] \n");
//engage eternalCount
parent->eternalCount++;
return;
}В коде выше мы описали наш функциональный метод добавляющий ребенка. И в нем "подцепляем" наш узелок в цепочку родителя. Удобная проверка условия, при каждом добавлении, расширит наш контейнер на необходимое количество вместительности.
//nodes destructor
void Node_Destr_Curr(struct Node* node)
{
if (node->eternalCount > 0)
{
for (int i=0; i<node->eternalCount; i++)
{
Node_Destr_Curr(node->chain[i]);
}
printf("NODE_REPORT_RCS(dstr): destroy node %x with value %d \n", node, node->value);
free(node->chain);
free(node);
}
else
{
printf("NODE_REPORT_RCS(dstr): destroy node %x with value %d \n", node, node->value);
free(node->chain);
free(node);
}
return;
}Деструктор устроен сложно. И уже здесь появляется первые шаги к рекурсивному обходу. Он должен быть устроен так, чтобы за минимальное количество шагов рекурсивно обойти всю структуру, при этом не создавая проблем на стеке. И здесь точкой опоры будет количество детей, и если дети у родителя будут, то в цикле мы рекурсивно вызываемся для каждого ребенка в цепочке, и только после этого освобождаем память под указатели. В этом цикле запоминается итерация на каждый вызов и мы будто бы "ныряем рекурсией внутрь" нашего дерева и по проходу на крайний случай возвращаемся обратно на итерацию в цикл. Таким образом итерация вызовет итерацию уровень за уровнем и инструкции "разрешаются" издали к основе. В противном случае когда детей нет можно просто освободить цепочку и сам узел.
Вывод: Построить базу не легко, нужно многое обдумать наперед. К тому же, необходимо относится к этому так, будто бы вы начинали строить фундамент для вашего будущего дома. Поэтому важно, проверять правильность освобождения памяти в программе уже с первых шагов создания программы. Проверить деструктор и еще раз смотреть «нет ли каких либо утечек?». Механизм добавления в дерево должен быть настолько удобен, насколько это позволит считывая файл добавлять ноды в дерево, еще даже не зная сколько в нем будет узлов! Это и есть ключевой момент правильного подхода. Ну и еще, очень важно соблюсти правила расширения границ в памяти нашего дерева при перевыделении памяти, при этом не забыть проверить сохранность данных от такого перевыделения. Сделать ноду нужно с запасом по ширине, чтобы дерево работало быстрее чем это ожидалось от такой гибкой и динамической, на первый взгляд, структуры.
Блуждаем по веткам
Естественно, нужно предоставить пользователю механизм чтобы пройти в нужное для демонстрации или манипуляции с деревом место. Поэтому разработаем интерфейсные функции для хождения по нашему дереву.
Проход по ветке вверх осуществляется довольно просто.
Необходимо просто пройти по указателю указывающему на federal, в случае если он не указывает на &nullNode. В противном случае мы можем уверенно говорить о том, что дошли до рута.
А вот проход по ветке вниз уже ждет от нас некоторых особенностей алгоритма, которые будут отслеживать - правильны ли вводимые пользователям данные.
Для этого введем в фукнцию-обработчик переменную iN обозначающую именно точку входа по индексу в массиве ограниченную диапазоном от 0 до eternalCount-1. Где, естественно 0 это первый элемент в массиве. Для того чтобы этот функционал заработал необходимо тестировать два условия первое - это наличие детей (аргументируя эту информацию по количеству eternalCount) в самой ноде — и тогда нам нет необходимости ходить вниз., второе условие - нужно проверить нет ли выхода за границы массива — указывая пользователю через что произошел выход за границы диапазона. Ну и для того чтобы исключить ошибку прохождения в узел являющейся &nullNode, поскольку эта вероятность не исключена в случае расширения функционала где элементы дерева можно будет удалять. В этом случае желательно проверить еще и не является ли текущий узел ссылкой на нашу нулевую ноду.
//making a tree steps
struct Node* proceed_Up(struct Node* node)
{
printf ("<<< proceed_Up >>> ");
if (node->federal != &nullNode) { node = node->federal; my_Print_Hex(" in_da_hood ", node); }
else { printf("PRC_UP_ERR: sorry cant step upyard, i am exactly on root \n"); }
return node;
}
//making a steps downyard (iN here is a array index ranged from 0 to max < eternalCount)
struct Node* proceed_Down(struct Node* node, int iN)
{
if (node->eternalCount > 0)
{
printf ("<<<proceed_Down>>> ");
if (iN < node->eternalCount && iN >-1)
{
if (node->chain[iN] == &nullNode)
{
printf("PRC_DWN_ERR: cant step downyard, current note chain exactly linked nullNode \n");
}
else
{
node = node->chain[iN];
my_Print_Hex(" in_da_hood ", node);
}
}
else
{
printf("PRC_DWN_ERR: cant bind eternalCount and iN (out of range) \n");
}
}
else
{
printf("PRC_DWN_ERR: cant step downyard, empty Node! \n");
}
return node;
}Теперь в коде ниже пробуем первичный экспорт на экран и только после этого пытаемся создавать буферный поток для экспорта в файл.
На этом этапе нам вновь понадобится обойти дерево рекурсивно. Сама рекурсия это операция на стеке поэтому важно определить опорные точки на стеке (крайние случаи) при помощи которых мы можем построить взаимосвязь нашего алгоритма для осуществления прохода по данным так, как нам это необходимо.
//RECURSION EXPORT ----------------------------
void Export_Screen (struct Node* node)
{
if (node->eternalCount > 0)
{
for(int i=0; i<node->eternalCount; i++)
{
Export_Screen(node->chain[i]);
}
printf("EXPORT_SCR:: node adr %x value %d \n", node, node->value);
}
else
{
printf("EXPORT_SCR: node adr %x value %d \n", node, node->value);
return;
};
}К попытке вывести содержимое через поток в файл мы вернемся несколько позже при создании контента, а вот проверить деструктор валгриндом на утечку памяти уже необходимо прямо сейчас.
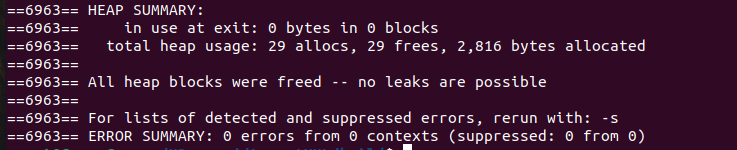
Вывод: как видно по результатам создание основы прошло успешно. Дерево можно не только строить но и разрушать без утечек. На этом этапе очень важно контролировать утечки памяти.
Добавление функционала обработки тегов их содержимого и обработки атрибутов и их содержимого. Контент
Конечно же, интеграция содержимого не может происходить моментально поскольку невозможно предугадать всевозможные проблемы с памятью, которые могут содержать такие утечки.
Поэтому такую интеграцию, даже в таком упрощенном виде, приходится производить в два этапа. На первом мы создаем отдельный вспомогательный проект, аллоцируемся и определяемся с утечками. На втором производим постепенное интегрирование основного кода кусками из проверенного проекта.
В результате проделанной работы было проведено много попыток пропустить исходный код через valgrind, с попыткой получить в результате необходимый нужный вариант. Ну а уже саму реализацию в общем коде я представляю в коде ниже.
Результатом проделанной работы после интеграции стала структура следующего вида описанную в следующем куске кода.
//*************** <Content> ******************
struct Content
{
char* head;
char* belly;
size_t head_length;
size_t belly_length
};Как видно по объявлению структуры, в ней находятся две строки — голова и брюшко, а также переменные выполняющие функцию хранителей размера аллоцируемого блока. Тег и тело нашей ноды будем хранить в нулевом индексе массива контентов, а в остальных будем хранить атрибуты и атрибут-содержимое.
struct Content* Content_Construct (struct Content* content, char* head, char* belly)
{
//build content space
content = (struct Content*)malloc(sizeof(struct Content));
//import strlengths
content->head_length = strlen(head) + 1;
content->belly_length = strlen(belly) + 1;
//Poke memory
content->head = (char*)malloc(content->head_length * sizeof(char)); //memLeak
content->belly = (char*)malloc(content->belly_length * sizeof(char)); //memLeak
if(strlen(head) != 0 && strlen(belly) != 0)
{
content->head = strcpy(content->head, head);
content->belly = strcpy(content->belly, belly);
}
else if (strlen(head) == 0 && strlen(belly) != 0)
{
content->head[0] = '\0';
content->belly = strcpy(content->belly, belly);
}
else if (strlen(head) != 0 && strlen(belly) == 0)
{
content->head = strcpy(content->head, head);
content->belly[0] = '\0';
}
else{};
printf("Content Report: construction of content %x \n", content);
return content;
};Не забываем определится с нуль терминатором. Естественно становится понятно, что «дописывать велосипед» по определению длинны нецелесообразно, так как намного безопаснее добавить string.h и это связано с необходимостью использовать более функциональные и протестированные годами методы стандартной библиотеки. Поэтому и будем определяется с длинной строки контента функцией strlen.
В самой же ноде массив указателей контент представляет из себя обыкновенный массив расширяемой длинны. Схема по расширению схожа со стандартным stl вектором. Таким образом заводим массив указателей который мы и будем расширять при необходимости, при этом ведя учет количества записей в массив.
struct Node nullNode; //this is a null marking structure
struct Node
{
int value;
size_t eternalCount; //chain counter
size_t capacity; //reserved volume of chain
size_t upyardPlaceHolder; //the place in upyard chain
struct Node* federal;
struct Node** chain;
size_t content_capacity; //important content capacity
size_t content_counter; //important content counter
struct Content** content;
};Конструктор ноды теперь будет выглядеть уже так.
//try to make an empty node
struct Node* Node_Cnstr_Empty (struct Node* node, int val, char* tag, char* belly)
{
//Poke memory (two pointers)
node = (struct Node*) malloc(sizeof(struct Node));
node->capacity = 10;
node->chain = (struct Node**) malloc(node->capacity * sizeof(struct Node*));
for (int i=0; i<node->capacity; i++) node->chain[i] = &nullNode;
//engage value
node->value = val;
//press up counter
node->eternalCount = 0;
//adress federal null
node->federal = &nullNode;
//make upyard value -1 unchained
node->upyardPlaceHolder = -1;
//construct content
node->content_capacity = 10;
node->content = (struct Content**) malloc(node->content_capacity * sizeof(struct Content*));
//genegate empty tag content
struct Content* tg = Content_Construct(tg, tag, belly);
node->content[0] = tg;
node->content_counter = 1;
my_Print_Hex("NODE_REPORT(cnstr): constructor empty throwing ", node);
return node;
};И в коде видно, что под контент аллоцируется необходимый резервный массив указателей на контенты, длинной 10. Сам первичный именной (теговый) контент с нулевым индексом инициируется уже здесь из char*. В нем будут хранится наши названия и содержания. Такой массив позволит нам в дальнейшем хранить данные емко и с возможностью однопроходной обработки в цикле.
Конечно, рассказать о всех изменениях в первоначальной основе в этой статье не представляется возможным, но при желании читатель может пройти по ссылке на открытый код на мой github, а также может оптимизировать написанный мной код.
Расширяем функционал основного типа данных ноды двумя добавочными функциями. Делающими наш контент массив расширяемым по необходимости.
//check and resize content
struct Node* Node_Content_Resize (struct Node* node)
{
if(node->content_counter == node->content_capacity)
{
printf("NODE REPORT(content_chk_and_rsz): resizing content node %x \n", node);
//copy for static pointers array
struct Content** temporary = (struct Content**) malloc(node->content_capacity * sizeof(struct Content*));
for (int i=0; i < node->content_capacity; i++) temporary[i] = node->content[i];
//engaging
node->content_capacity = 2 * node->content_capacity;
//reallocation
free(node->content);
node->content = (struct Content**) malloc (node->content_capacity * sizeof(struct Content*));
//reini
for (int i=0; i < node->content_capacity; i++)
{
if (i < (node->content_capacity/2)) node->content[i] = temporary[i];
else node->content[i] = NULL;
}
//deleash memory
free(temporary);
};
return node;
};В коде ниже добавляем функционал позволяющий добавлять атрибуты в контент.
//content addition of atribute
struct Node* Node_Add_Atribute (struct Node* node, char* head, char* belly)
{
struct Content* attr = Content_Construct(attr, head, belly); //memLeak?
node = Node_Content_Resize(node);
if (attr != NULL)
{
node->content[node->content_counter] = attr;
node->content_counter++;
}
else
{
printf("pragma! return virgin knot \n");
}
return node;
};А также, что не удалось предугадать ранее, в дальнейшем в построении дерева при помощи парсинга, нам понадобится еще и эта функция позволяющая менять тело ноды.
//content adobt body
struct Node* Node_Adobt_Body (struct Node* node, char* compromete)
{
//find out size of compromete
size_t comprometeLength = strlen(compromete);
//engage capacity of char
int counter = 1;
while (node->content[0]->belly_length <= comprometeLength)
{
node->content[0]->belly_length = node->content[0]->belly_length * 2;
counter++;
}
//refresh Memory for string
if (counter > 1)
{
free(node->content[0]->belly);
node->content[0]->belly = (char*) malloc (node->content[0]->belly_length * sizeof(char));
}
//data copy
strcpy(node->content[0]->belly, compromete);
return node;
}Возникла необходимость переписать рекурсивный деструктор под контент. Теперь рекурсивный деструктор будет выглядеть у нас так:
//nodes destructor
void Node_Destr_Curr(struct Node* node)
{
if (node->eternalCount > 0)
{
for (int i=0; i<node->eternalCount; i++)
{
Node_Destr_Curr(node->chain[i]);
}
printf("NODE_REPORT_RCS(dstr): destroy node %x with value %d \n", node, node->value);
//deleashing content cycle
for (int j=0; j<node->content_counter; j++)
{
Content_Destruct(node->content[j]);
};
free(node->content); //MEM LEAK IS HERE!
free(node->chain);
free(node);
}
else
{
printf("NODE_REPORT_RCS(dstr): destroy node %x with value %d \n", node, node->value);
//deleashing content cycle
for (int j=0; j<node->content_counter; j++)
{
Content_Destruct(node->content[j]);
};
free(node->content); //MEM LEAK IS HERE!
free(node->chain);
free(node);
}
return;
}
Фришим контент пройдясь в цикле по всем указателем из массива, а далее освобождаем сам контент.
Дописываем рекурсивный функционал для вывода дерева на экран. И здесь мы должны осознать, что читабельный XML очевидно должен содержать отступы. Поэтому заводим глобальную переменную которая будет содержать количество отступов или попросту символов \t (табуляции). И прописываем функционал который будет инкрементировать и декрементировать эту глобальную переменнию, будто она указывает нам на этаж нашего дерева.
В этих кусочках кода, функция "хелпер" обнуляет наш "табшифтер", хранящий количество отступов и запускает рекурсию.
Здесь в описания кода описана точка входа в рекурсивный шаг из инструкции и закоментирована как \\recursive step. Заглушка рекурсии и возврат в инструкцию происходит в момент return. И таким образом алгоритм обходит все дерево при этом создавая нужное количество отступов и заключая контент в зарезервированные символы предназначенные для нашего XML дерева.
static int tabs_shifter;
void Export_Screen_Content_Tabs (struct Node* node)
{
if (node->eternalCount > 0)
{
//tabs_shifting
for (int sh=0; sh<tabs_shifter; sh++) printf("\t");
for (int t=0; t<node->content_counter; t++)
{
if (t==0) printf("<%s",node->content[t]->head);
else printf(" %s=\"%s\"",node->content[t]->head, node->content[t]->belly);
}
printf(">\n");
tabs_shifter++;
for(int i=0; i<node->eternalCount; i++)
{
Export_Screen_Content_Tabs(node->chain[i]); //RECURSIVE STEP
}
tabs_shifter--;
//tabs_shifting
for (int sh=0; sh<tabs_shifter; sh++) printf("\t");
//export belly
printf ("%s\n", node->content[0]->belly);
//tabs_shifting
for (int sh=0; sh<tabs_shifter; sh++) printf("\t");
//clossing taggy
printf("</%s>\n", node->content[0]->head);
}
else
{ //tabs_shifting
for (int sh=0; sh<tabs_shifter; sh++) printf("\t");
//export atribbutes
for (int t=0; t<node->content_counter; t++)
{
if (t==0) printf("<%s",node->content[t]->head);
else printf(" %s=\"%s\"",node->content[t]->head, node->content[t]->belly);
}
printf(">\n");
//tabs_shifting
for (int sh=0; sh<tabs_shifter; sh++) printf("\t");
//export belly
printf ("%s\n", node->content[0]->belly);
//tabs_shifting
for (int sh=0; sh<tabs_shifter; sh++) printf("\t");
//closing taggy
printf("</%s>\n", node->content[0]->head);
return; //PLUG
};
}
//helper
void Export_Screen_Content(struct Node* node)
{
tabs_shifter = 0;
Export_Screen_Content_Tabs(node);
}
Тут мы создаем простое дерево и печатаем его на экран нашей функцией экспорта.

Как видно экспорт проходит в успешный читабельный вид!
Вызываем деструктор дерева и «заверяемся на утечки» в valgrind.
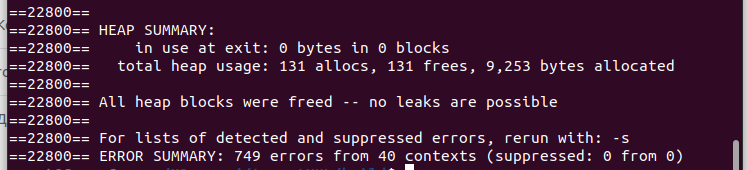
Пока все выглядит неплохо. Выходим на завершающий шаг нашей оптимизации.
Экспорт в файл
Создаем глобальную буферную переменную char* с названием xml_buffer, и она будет хранить экспортируемые данные в уже оформленном зарезервированными символами (формирующими теги) виде.
Первым этапом естественно необходимо разобраться с возможностью записи и кодировками и для этого нам понадобится библиотека locale.h.
Вторым этапом мы определяемся с потоками. Тут пользователю предоставляется простая возможность экспорта в файл без затруднений при помощи функции помощника, а также как альтернатива - возможность отправить поток в функцию. Опишем в комментарии подробно то, что во втором случае пользователю придется самому следить за буфером.
Первоначально при создании буфера. Мы можем пойти неверным путем обнуляя все символы в нуль терминаторы, и более правильным путем записывая лишь в первый байт нуль терминатор.
//stream exports
//write to file
char* xml_buffer;
void memXmlBuffer(size_t size)
{
xml_buffer = (char*)malloc(size*sizeof(char));
for (int i=0; i<size; i++) xml_buffer[i] = '\0';
return;
}
void deleashXmlBuffer()
{
for(int i=0; i<strlen(xml_buffer); i++) xml_buffer[i] = '\0';
return;
}
void dedicateBitZeroXmlBuffer()
{
xml_buffer[0] = '\0';
}
Уже невооруженным взглядом видно! Что метод dedicateBitZeroXmlBuffer намного быстрее попытки в цикле нультерминировать всю выделенную память.
Само устройство экспорта схожа с распечаткой на экран. Но при этом мы будем вызывать рекурсию с текущим состоянием потока, просто передавая в рекурсию текущее состояние потока. Также здесь понадобится функция-хелпер, которая будет открывать поток и вызывать саму рекурсивную функцию. Альтернативный вызов функции с потоком оставляем с комментарием о том, что пользователю самому придется заботится о длине буфера, о выделении под него памяти и освобождении этой памяти.
Подробный код реализованного экспорта в файл в ссылке на github в конце ознакомительной статьи (смотри функции Export_by_FILEFlow и Export_By_FileName)
Сложный заключительный этап - парсинг данных из файла при помощи рекурсии
Один из самых трудоемких и затруднительных этапов при написании алгоритма такого дерева это и есть динамическое чтение xml файла. Это наверное самое сложное, то что я просто бы не смог реализовать без помощи своего старшего брата Аделя Чепкунова. Да собственно как и самостоятельно разобраться в оптимизации рекурсивных обходов, которая прошла под его чутким руководством. Я хотел выразить ему огромную благодарность за его объяснения и терпение. Очевидно, что без него эта статья просто бы не появилась, и многим новичкам просто бы не удалось окунуться в этот удивительный мир дерева. Иметь возможность заглянуть в будущие проблемы и это и есть то качество отличающее сильного специалиста от начинающего. Большое ему спасибо и за это в том числе.
Также такая тема не проходит без сложностей и на первоначальном этапе все достаточно просто - пытаемся считать содержимое из файла на экран.
Внимательный читатель заметит, что при создании дерева была использованы не те символы - кавычки были одинарными, а также была проставлена запятая в теге. Все это откорректировано в исходном коде на гитхаб и в нем уже все правильно.
В процессе парсинга в цикле while ((read = fgetc(flow)) != EOF) из за той особенности что тело самого атрибута есть не что иное как двойные кавычки, то в алгоритме я использовал не только символьную переменную read, но и запоминал предидущий read в символьную переменную in_mind.
Дабы не увеличивать объем статьи вы можете ознакомится с функцией парсинга по ссылке на github (смотри функцию Build_From_File)
Ну а здесь, вкратце, опишу случаи которые мне понадобились для реализации самого парсинга:
* (in_mind == '>' && read == '<') --- body reading
* (in_mind == '<' && (read == ' ' || read == '>')) --- tag reading [up level]
* (read == '=' && (in_mind == ' ' || in_mind == '\"')) --- atribute reading
* (in_mind == '=' && read == '\"') --- defeat quotes
* (in_mind == '\"' && read == '\"') --- read belly of atribute
* (in_mind == '\"' && read == '>') --- quotes closed case
* (in_mind == '<' && read == '/') --- closed tag start reading [down level]
* (read != 32 && read != 9 && read != 10) ---- and overall hasent wrote to buffer (tabs '\t', spaces ' ' or '\n' syblols)
Тут видно, что чтение и запись в буфер нужно осуществляется в последнем условии.
Как только получилось прочитать добавляем генерацию дерева из считываемого файла. Создаем указатель на Рут при помощи нашей функции генерации дерева Build_From_File. Обобщенно схема генерации заключается в следующем - прочитали тег, завели ноду с пустым телом, считали атрибуты и вписали атрибуты в текущий узел если они есть. Дальше идем до следующего тега заводим тут ноду и добавляем к текущему узлу в чайлды. Делаем наш current ссылающимся на добавленного чайлда. Когда встречаем закрывающийся тег в одном из описанных выше условий уходим вверх на родителя (federal), добавляем тело и идем дальше. Так до конца, нырками проходимся по всему файлу!
Вывод: Одним из важнейших моментов при обходе и манипуляции с XML деревом есть понимание основ программирования, а именно правильный подход к рекурсии. И становится очевидно понятно, как много всего в мире информации построенно на удивительных алгоритмах использующих грамотный рекурсивный подход.
Источники:
1. http://kharchuk.ru/home/21-flash-and-xml/141-xml-history, Аминев Марат Фуадович.
Комментарии (3)

KyHTEP
00.00.0000 00:00+1Не увидел самого важного: времени парсинга 100Mb файла в сравнении с, например, pugixml или tinyxml

domix32
00.00.0000 00:00+1Да чего уж там только не хватает, на самом деле. Тестов нет, entity нет, doctype, schema и xquery тоже. Разве что какой-нибудь рерайтер поверх этого писать.
Travisw
В дополнение можно было указать существующие библиотеки которые это делают типа libxml